Net Logo : Agenci i Ķrodowisko
Dawno, dawno temu … w przyszģoķci
Sztuczna inteligencja to zģoŋony, a jednoczeķnie intrygujący temat. Gdybyķmy posģuŋyli się analogią do opisu badaņ Sztucznej Inteligencji, moglibyķmy ewentualnie porównaæ do krajobrazu, w którym z biegiem czasu ksztaģtuje się i zmienia ksztaģt czģowieka (aby podkreķliæ jego ciągģą ewolucję). Lub moglibyķmy obserwowaæ piaski pustyni, które przesuwają się wraz z wiatrem (aby wskazaæ na jego dynamiczny charakter). Jeszcze inna analogia moŋe dotyczyæ efemerycznej natury chmur, kontrolowanych przez przewaŋające wiatry, których substancji nie da się jednak uchwyciæ. Te analogie są bogate w metaforę i są bliskie prawdy pod innymi względami. Język naturalny jest substancją, z którą piszemy, a metafory i analogie są waŋnymi urządzeniami, które my, jako uŋytkownicy i producenci języka sami, jesteķmy w stanie zrozumieæ i stworzyæ. To jedno z największych wyzwaņ w dziedzinie sztucznej inteligencji. Inne wyzwania obejmowaģy pokonanie mistrza ķwiata w szachach, prowadzenie samochodu w ķrodku miasta, wykonywanie operacji chirurgicznej, pisanie zabawnych historii i tak dalej; Sztuczna inteligencja to tak ciekawy temat.
Podobnie jak wspomniane wyŋej przesuwane piaski, przez wiele lat dokonywano wielu waŋnych zmian paradygmatu w Sztucznej Inteligencji. Tradycyjny lub klasyczny paradygmat sztucznej inteligencji (podejķcie "symboliczne") polega na projektowaniu inteligentnych systemów opartych na symbolach, stosując metaforę przetwarzania informacji. Przeciwny paradygmat sztucznej inteligencji (podejķcie "sub-symboliczne" lub onnektyczny) zakģada, inteligentne zachowanie w sposób nie symboliczny, przyjmujący ucieleķnione podejķcie behawiorystyczne. Takie podejķcie kģadzie nacisk na znaczenie fizycznego uziemienia, ucieleķnienia i usytuowania, jak podkreķlają prace Brooksa w dziedzinie robotyki i Lakoffa i Johnsona w dziedzinie językoznawstwa. Gģównym podejķciem przyjętym przez nas będzie gģównie to drugie podejķcie, ale zostanie równieŋ opisane poķrednie podģoŋe w oparciu o prace Gärdenforsa, które ilustrują, w jaki sposób systemy symboliczne mogą powstaæ w wyniku zastosowania ukrytego podliczbowego podejķcia. . Postęp wiedzy szybko się rozwija, szczególnie w dziedzinie sztucznej inteligencji. Co waŋne, istnieje równieŋ nowe pokolenie ludzi , którzy poszukują tej wiedzy - tych, dla których Internet i gry komputerowe istnieją juŋ od dzieciņstwa. Ci ludzie mają bardzo odmienną perspektywę i bardzo odmienny zestaw zainteresowaņ niŋ starsi .Na przykģad, nigdy nie sģyszeli nawet o grach planszowych takich, dlatego będą mieli trudnoķci z zrozumieniem znaczenia algorytmów wyszukiwania w tym kontekķcie. Kiedy jednak uczą się tych samych algorytmów wyszukiwania w kontekķcie gier komputerowych lub przeszukiwania sieci, szybko pojmują te pojęcia i przenoszą je do miejsca, w którym ty, jako ich nauczyciel, nie mógģbyķ odejķæ bez ich pomocy. To, czego potrzebuje sztuczna inteligencja, to "odrodzenie wyobražni", jak obecny trend w serialach science-fiction - opowiedzenie tej samej historii, ale z róŋnymi aktorami i róŋnymi akcentami, aby zaangaŋowaæ nowoczesną publicznoķæ.
AI i Języki Programowania : NetLogo
Przez lata proponowano kilka języków programowania, które dobrze pasują do budowy systemów komputerowych dla sztucznej inteligencji. Historycznie, najbardziej znanymi językami programowania AI byģy Lisp i Prolog
Lisp (i powiązane dialekty, takie jak Common Lisp i Scheme) ma doskonaģe moŋliwoķci przetwarzania list i symboli, z moŋliwoķcią ģatwej zamiany kodu i danych, i byģ szeroko wykorzystywany do programowania AI, ale jego dziwna skģadnia z zagnieŋdŋonym nawiasem czyni go trudnym język do opanowania, a jego uŋycie zmniejszyģo się od lat dziewięædziesiątych.
Prolog, logiczny język programowania, staģ się językiem wybranym w 1982 roku dla ostatecznie nieudanego japoņskiego projektu piątej generacji, który miaģ na celu stworzenie superkomputera z uŋytecznymi moŋliwoķciami sztucznej inteligencji.
NetLogo ( stworzony przez Wilensky'ego w 1999) zostaģ wybrany do dostarczania próbek kodu w naszych przykģadach, aby zilustrowaæ, w jaki sposób moŋna zaimplementowaæ algorytmy. Przyczyny dostarczenia rzeczywistego kodu są takie same jak przedstawione przez Segaran w jego ksiąŋce o zbiorowej inteligencji - ŋe jest to bardziej uŋyteczne i "prawdopodobnie ģatwiejsze do naķladowania", z nadzieją, ŋe takie podejķcie doprowadzi do pewnego rodzaju nowego "kompromisu" w ksiąŋkach technicznych, które "wprowadzają czytelników delikatnie w algorytmy", pokazując im dziaģający kod. Alternatywne opisy, takie jak pseudo-kod, wydają się byæ niejasne i mylące oraz mogą ukrywaæ bģędy, które stają się widoczne dopiero na etapie implementacji. Co waŋniejsze, rzeczywisty kod moŋna ģatwo uruchomiæ, aby zobaczyæ, jak dziaģa i szybko się zmieniģ, jeķli czytelnik chce dokonaæ ulepszeņ bez potrzeby pisania kodu od zera.
NetLogo (potęŋny dialekt Logo) to język programowania z dominującymi atutami agenta. Posiada wyjątkowe moŋliwoķci, które sprawiają, ŋe jest niezwykle potęŋny do tworzenia i wizualizacji symulacji systemów wieloagentowych i jest uŋyteczny do podkreķlania róŋnych problemów związanych z ich implementacją, która moŋe zaæmiģaby bardziej tradycyjny język, taki jak Java czy C / C ++. NetLogo jest implementowany w Javie i ma bardzo zwarty i czytelny kod, dlatego jest idealny do demonstrowania skomplikowanych pomysģów w zwięzģy sposób. Ponadto pozwala uŋytkownikom rozszerzyæ język, pisząc nowe polecenia i reportery w Javie. W rzeczywistoķci ŋaden język programowania nie jest odpowiedni do wdroŋenia peģnego zakresu systemów komputerowych wymaganych do sztucznej inteligencji. Rzeczywiķcie, nie istnieje jeszcze jeden język programowania, który sprosta zadaniu. W przypadku "sztucznej inteligencji opartej na zachowaniu" (i pokrewnych dziedzinach, takich jak ucieleķniona kognitywistyka), wymagany jest język w peģni zorientowany na agenta, który ma bogactwo języka Java, ale jest zorientowana na agentów prostota języka, takiego jak NetLogo.
Krótkie Wprowadzenie
1.1 Czym jest "Sztuczna inteligencja"?
Sztuczna inteligencja jest nauką, jak budowaæ systemy komputerowe, które wykazują inteligencję w pewien sposób. Sztuczna inteligencja przyniosģa wiele przeģomów w informatyce - wiele podstawowych tematów badawczych w dzisiejszej nauce informatyki rozwinęģo się z badaņ nad sztuczną inteligencją; na przykģad sieci neuronowe, obliczenia ewolucyjne, uczenie maszynowe, przetwarzanie języka naturalnego, programowanie obiektowe, aby wymieniæ tylko kilka. W wielu przypadkach gģównym tematem tych badaņ nie jest juŋ rozwój sztucznej inteligencji, staģy się dyscypliną samą w sobie, a w niektórych przypadkach nie są juŋ uwaŋane za związane z AI. Sama AI kontynuuje podróŋ w poszukiwaniu dalszych spostrzeŋeņ, które doprowadzą do kluczowych przeģomów, które są nadal potrzebne. Byæ moŋe czytelnik moŋe byæ tym, który dostarczy jeden lub więcej przeģomowych odkryæ w przyszģoķci. Jednym z najbardziej ekscytujących aspektów sztucznej inteligencji jest to, ŋe wciąŋ istnieje wiele pomysģów do wymyķlenia, wiele dróg wciąŋ jest do odkrycia. Sztuczna inteligencja jest ekscytującym i dynamicznym obszarem badaņ. Szybko się zmienia, a badania na przestrzeni lat rozwijają i wciąŋ rozwijają wiele genialnych i interesujących pomysģów. Jednak musimy jeszcze osiągnąæ ostateczny cel sztucznej inteligencji. Wiele osób kwestionuje, czy kiedykolwiek osiągniemy to z powodów wymienionych poniŋej. Dlatego kaŋdy, kto studiuje lub bada sztuczną inteligencję, powinien zachowaæ otwarty umysģ na temat stosownoķci przedstawionych pomysģów. Powinni zawsze zastanawiaæ się, jak dobrze dziaģają te pomysģy, pytając, czy istnieją lepsze pomysģy lub lepsze podejķcia
1.2 Ķcieŋki do sztucznej inteligencji
Zróbmy analogię między badaniami nad sztuczną inteligencją a eksploracją niezbadanego terytorium; na przykģad wyobražmy sobie czas, kiedy kontynent póģnocnoamerykaņski byģ eksplorowany po raz pierwszy, a mapy nie byģy dostępne. Pierwsi odkrywcy nie mieli wiedzy o terenie, który badali; ruszają w jednym kierunku, aby dowiedzieæ się, co tam jest. W tym procesie mogą zapisywaæ to, co odkryli, pisząc w dziennikach lub rysując mapy. Pomogģoby to póžniejszym odkrywcom, ale dla większoķci wczesnych odkrywców teren byģ zasadniczo nieznany, chyba ŋe mieli trzymaæ się tych samych ķcieŋek, z których korzystali pierwsi odkrywcy. Obecnie badania nad sztuczną inteligencją wciąŋ znajdują się na wczesnym etapie eksploracji. Większoķæ terenu do zbadania jest wciąŋ nieznana. Eksplorator sztucznej inteligencji ma wiele moŋliwych ķcieŋek, które mogą odkrywaæ w poszukiwaniu metod, które mogą prowadziæ do inteligencji maszyny. Niektóre z tych ķcieŋek będą ģatwe i prowadzą do ŋyznych ziem; inne doprowadzą do górzystego i trudnego terenu lub do pustyņ. Niektóre ķcieŋki mogą prowadziæ do nieprzebytych klifów. Bez względu na to, jaką konkretną ķcieŋkę stwarza badaczom sztucznej inteligencji, poszukiwania będą ekscytujące, poniewaŋ w naszej ludzkiej naturze chcemy odkrywaæ i znajdowaæ rzeczy. Moŋemy spojrzeæ na ķcieŋki wybrane przez dawnych "odkrywców" w Sztucznej Inteligencji. Na przykģad analiza pytania "Czy komputery potrafią myķleæ?" doprowadziģa do wielu intensywnych debat w przeszģoķci, które zaowocowaģy róŋnymi ķcieŋkami podjętymi przez badaczy sztucznej inteligencji. Nilsson zwróciģ uwagę, ŋe moŋemy podkreķliæ kaŋde sģowo po kolei, aby przedstawiæ inne spojrzenie na to pytanie. (Uŋyģ sģowa "maszyny", ale zamiast tego uŋyjemy sģowa "komputery"). Wež pierwsze sģowo - "Czy komputery mogą myķleæ?" Czy mamy na myķli: "Czy komputery mogą myķleæ (kiedyķ)?" lub "Czy mogą myķleæ (teraz)?" Czy mamy na myķli, ŋe mogą (w zasadzie) byæ w stanie, ale nigdy nie bylibyķmy w stanie go zbudowaæ? Czy teŋ prosimy o rzeczywistą demonstrację? Niektórzy uwaŋają, ŋe maszyny myķlące mogą byæ tak skomplikowane, ŋe nigdy nie moglibyķmy ich zbudowaæ. Nilsson czyni analogię z próbą zbudowania systemu, który na przykģad powielaģby ziemską pogodę. Byæ moŋe będziemy musieli zbudowaæ system nie mniej zģoŋony niŋ faktyczna powierzchnia Ziemi, atmosfera i pģywy. Podobnie, ludzka inteligencja na peģną skalę moŋe byæ zbyt skomplikowana, aby istnieæ poza jej ucieleķnieniem u ludzi usytuowanych w otoczeniu. Na przykģad, w jaki sposób maszyna moŋe zrozumieæ, czym jest "drzewo" lub czym "jabģko" smakuje bez ucieleķnienia w prawdziwym ķwiecie? Lub moŋemy podkreķliæ drugie sģowo - "Czy komputery mogą myķleæ?", Ale co rozumiemy przez "komputery"? Definicja komputerów zmienia się z roku na rok, a definicja w przyszģoķci moŋe byæ bardzo róŋna od dzisiejszej, a najnowsze osiągnięcia w dziedzinie komputerów molekularnych, komputerów kwantowych, komputerów z moŋliwoķcią noszenia na ciele, komputerów przenoķnych i wszechobecnych komputerów zmieniają sposób myķlimy o komputerach. Byæ moŋe moŋemy zdefiniowaæ komputer jako maszynę. Znaczna częķæ literatury AI uŋywa sģowa "maszyna" zamiennie ze sģowem komputer - więc pytanie "Czy maszyny myķlą?" jest często uwaŋane za synonim "Czy komputery mogą myķleæ?" Ale czym są maszyny? I czy ludzie są maszyną? (Jeķli są, jak mówi Nilsson, wtedy maszyny mogą myķleæ!) Nilsson wskazuje, ŋe naukowcy zaczynają teraz wyjaķniaæ rozwój i funkcjonowanie organizmów biologicznych w taki sam sposób, jak maszyny (badając genomowy "plan" kaŋdego organizmu). Oczywiķcie, "biologiczne" maszyny wykonane z biaģek mogą myķleæ (my!), Ale czy "krzemowe" maszyny mogģyby kiedykolwiek myķleæ? I wreszcie moŋemy podkreķliæ trzecie sģowo - "Czy komputery mogą myķleæ?" Ale co to znaczy myķleæ? Byæ moŋe chcemy myķleæ "jak" my (ludzie). Alan Turing, brytyjski matematyk i jeden z pierwszych badaczy AI, opracowaģ sģynny (a takŋe kontrowersyjny) test empiryczny na inteligencję, która nosi jego imię - test Turinga. W tym teķcie maszyna próbuje przekonaæ ludzkiego ķledczego ŋe jest czģowiekiem . (Patrz poniŋej). Ten test zostaģ poddany intensywnej krytyce w literaturze AI, byæ moŋe niesprawiedliwie, poniewaŋ nie jest jasne, czy test jest prawdziwym testem na inteligencję. W przeciwieņstwie do wczeķniejszego celu AI podobnego rodzaju, cel polegający na tym, ŋe system AI pokonaģ mistrza ķwiata w szachach, spotkaģ się z duŋo mniejszą krytyką.
Test Turinga
Wyobražcie sobie sytuację, w której prowadzicie oddzielne rozmowy z dwoma innymi osobami, których nie moŋecie zobaczyæ w oddzielnych pokojach, byæ moŋe za pomocą teletropii (jak u Alana Turinga), lub moŋe w pokoju rozmów przez Internet (jeķli mielibyķmy zmodernizowaæ ustawienie) . Jedna z tych osób to męŋczyzna, a drugim jest kobieta - nie wiesz którym. Twoim celem jest ustalenie, kto jest kim , poprzez rozmowę z kaŋdym z nich i zadawanie im pytaņ. Częķcią gry jest to, ŋe męŋczyzna próbuje cię nakģoniæ do uwierzenia, ŋe jest kobietą, a nie odwrotnie (inspiracja dla pomysģu Turinga pochodziģa z popularnej wiktoriaņskiej gry o nazwie Imitacja). Teraz wyobraž sobie, ŋe sytuacja się zmieniģa, a zamiast męŋczyzny i kobiety, bohaterami są komputer i czģowiek. Celem komputera jest przekonanie Cię, ŋe jest czģowiekiem, a więc dzięki temu zdaæ ten test na inteligencję, teraz nazywany "testem Turinga". Jak realistyczny jest ten test? Joesph Weizenbuam zbudowaģ jeden z pierwszych chatbotów, zwany ELIZA, w 1966 roku. Jego sekretarka znalazģa program uruchomiony na jednym komputerze i zaczęģa ģuskaæ historię swojego ŋycia przez okres kilku tygodni i byģa przeraŋona, gdy Weizenbaum powiedziaģa jej, ŋe to byģo tylko program. Jednak nie byģa to sytuacja, w której zdano test Turinga. Test Turinga jest testem kontradyktoryjnym w tym sensie, ŋe jest to gra, w której jedna strona próbuje oszukaæ drugą, ale druga strona jest tego ķwiadoma i stara się nie daæ się oszukaæ. To wģaķnie sprawia, ŋe test jest trudnym testem dla systemu sztucznej inteligencji. Podobnie, istnieje wiele stron internetowych w Internecie, które twierdzą, ŋe ich chatbot zdaģ test Turinga; jednak do niedawna ŋaden chatbot nawet się do tego nie zbliŋyģ. Istnieje otwarty (i często oczerniany) konkurs, zwany Konkursem Loebnera, który odbywa się co roku, gdzie programiķci mogą przetestowaæ swoje chatboty AI, aby sprawdziæ, czy mogą zdaæ test Turinga. Konkurencja z 2008 roku byģa godna uwagi, poniewaŋ najlepsza sztuczna inteligencja byģa w stanie oszukaæ jedną czwartą sędziów w przekonaniu, ŋe jest czģowiekiem, co stanowi znaczny postęp w stosunku do wyników w poprzednich latach. Zapewnia to nadzieję, ŋe komputer będzie mógģ zdaæ test Turinga w niezbyt odlegģej przyszģoķci. Czy jednak test Turinga jest naprawdę dobrym testem na inteligencję? Byæ moŋe, gdy komputer przeszedģ ostateczne wyzwanie, jakim jest oszukiwanie panelu ekspertów AI, moŋemy oceniæ skutecznoķæ tego komputera w zadaniach innych niŋ test Turinga. Następnie, dzięki tym dalszym ocenom, będziemy w stanie okreķliæ, na ile naprawdę jest test Turinga (lub nie). W koņcu komputer pokonaģ juŋ mistrza ķwiata w szachach, ale tylko za pomocą metod wyszukiwania z funkcjami oceny, które wykorzystują minimalną "inteligencję". I co tak naprawdę nauczyliķmy się o inteligencji - poza tym, jak budowaæ lepsze algorytmy wyszukiwania? Warto zauwaŋyæ, ŋe cel, jakim jest zdobycie komputera do pokonania mistrza ķwiata, jest znacznie mniej krytykowany niŋ zdanie testu Turinga, a mimo to ten pierwszy zostaģ osiągnięty, podczas gdy drugi nie (jeszcze). Debatę wokóģ testu Turinga dobrze pokazuje praca Roberta Horna. Zaproponowaģ język wizualny jako formę wizualnego myķlenia. Częķæ jego pracy objęģa produkcję siedmiu plakatów, które podsumowują debatę Turinga w AI, aby zademonstrowaæ jego wizualny język i wizualne myķlenie. Siedem plakatów obejmuje następujące pytania:
1. Czy komputery mogą myķleæ?
2. Czy test Turinga moŋe okreķliæ, czy komputery mogą myķleæ?
3. Czy mogą myķleæ fizyczne systemy symboli?
4. Czy chiņskie pokoje mogą myķleæ?
5. (i) Czy sieci ģączące mogą myķleæ? oraz (ii) Czy komputery mogą myķleæ obrazami?
6. Czy komputery muszą byæ ķwiadome, aby myķleæ?
7. Czy myķlenie komputerów jest moŋliwe matematycznie?
Te plakaty są nazywane "mapami", poniewaŋ zapewniają mapę 2D, której pytania pokrywają się z innymi pytaniami, uŋywając analogii badaczy odkrywających niezbadane terytorium. Pierwszy plakat mapuje eksploracje pytania "Czy komputery myķlą?" I pokazuje ķcieŋki prowadzące do dalszych pytaņ wymienionych poniŋej:
• Czy komputery mają wolną wolę?
• Czy komputery mogą mieæ emocje?
• Czy powinniķmy udawaæ, ŋe komputery nigdy nie będą w stanie myķleæ?
• Czy Bóg nie pozwala komputerom myķleæ?
• Czy komputery rozumieją arytmetykę?
• Czy komputery mogą narysowaæ analogie?
• Czy komputery są z natury wyģączone?
• Czy komputery mogą byæ kreatywne?
• Czy komputery mogą się logicznie nauczyæ?
• Czy komputery mogą byæ osobami?
Drugi z nich omawia debatę na temat testu Turinga: "Czy test Turinga moŋe decydowaæ o tym, czy komputery mogą myķleæ?". Inne pytania, które zostaģy zmapowane na tym plakacie, to:
• Czy gra symulacyjna moŋe decydowaæ, czy komputery mogą myķleæ?
• Czy symulowana inteligencja przemija, czy jest inteligentna?
• Ile maszyn zdaģo test?
• Czy niepowodzenie testu jest decydujące?
• Czy zdanie testu jest decydujące?
• Czy test, rozumiany behawioralnie lub operacyjnie jest legalnym testem inteligencji?
Jedną ze szczególnych ķcieŋek do sztucznej inteligencji, którą będziemy stosowaæ, jest zasada projektowania, ŋe system sztucznej inteligencji powinien byæ zbudowany przy uŋyciu zorientowanego na agenta wzorca projektowego, a nie alternatywy, takiej jak zorientowany obiektowo wzór projektowy. Agenci uosabiają silniejsze pojęcie autonomii niŋ obiektów, sami decydują o tym, czy wykonaæ dziaģanie na ŋądanie innego agenta i są zdolni do zachowania elastycznego (reaktywnego, proaktywnego, spoģecznego), podczas gdy standardowy model obiektu nie ma nic wspólnego z powiedz o tych typach zachowaņ, a obiekty nie mają kontroli nad tym, kiedy są wykonywane. Kolejna ķcieŋka, którą będziemy ķledziæ, to poģoŋenie silnego nacisku na znaczenie AI opartej na zachowaniach oraz na wcielenie i usytuowanie agentów w zģoŋonym ķrodowisku. Wczesne przeģomowe prace w tej dziedzinie dotyczyģy Brooksa w robotyce oraz Lakoffa i Johnsona w dziedzinie językoznawstwa. Architektura podsieci Brooksa, obecnie popularna w robotyce i wykorzystywana w innych dziedzinach, takich jak animacja behawioralna i inteligentni wirtualni agenci, adoptuje moduģową metodologię dzielenia inteligencji na warstwy zachowaņ, które kontrolują wszystko, co robi agent, na podstawie faktycznego fizycznego usytuowania w jego otoczeniu i dynamicznej reakcji z nim. Lakoff i Johnson podkreķlają znaczenie metafory pojęciowej w języku naturalnym (np. Uŋycie sģów "przeģomowe" na początku tego paragrafu) i jak jest ona powiązana z naszym postrzeganiem poprzez naszą ucieleķnienie i fizyczne uziemienie. Prace te poģoŋyģy podwaliny pod obszary badawcze ucieleķnionej nauki kognitywnej i poznania usytuowanego, a spostrzeŋenia z tych obszarów zostaną równieŋ zaczerpnięte z tych podręczników.
IX Zastrzeŋeņ Alana Turinga wobec Sztucznej Inteligencji
1.3 Zastrzeŋenia wobec sztucznej inteligencji
Przez lata byģo wiele zastrzeŋeņ do Sztucznej Inteligencji. Jest to zrozumiaģe, do pewnego stopnia, poniewaŋ pojęcie inteligentnej maszyny, która moŋe potencjalnie wyprzedziæ i przeķcignąæ nas w przyszģoķci, jest przeraŋające. Byæ moŋe jest to napędzane przez wiele nierealistycznych powieķci science fiction i filmów wyprodukowanych w ciągu ostatniego stulecia, które koncentrują się na popularnym motywie robotów niszczących ludzkoķæ lub przejmujących ķwiat. Sztuczna inteligencja moŋe zakģóciæ kaŋdy aspekt naszego obecnego ŋycia, a ta niepewnoķæ moŋe równieŋ zagraŋaæ ludziom, którzy martwią się, jakie zmiany mogą przynieķæ w przyszģoķci. Następujące technologie zostaģy okreķlone jako wschodzące, potencjalnie "destrukcyjne" technologie, które oferują "nadzieję na poprawę kondycji ludzkiej", w raporcie zatytuģowanym "Future Technologies, Today's Choices", zleconym Greenpeace Environmental Trust:
• Biotechnologia;
• Nanotechnologia;
• Kognitywistyka;
• Robotyka;
• Sztuczna inteligencja.
Ostatnie trzy z nich odnoszą się bezpoķrednio do obszaru inteligencji maszyn i wszystkie moŋna scharakteryzowaæ jako potencjalnie destrukcyjne, umoŋliwiające i interdyscyplinarne. Gģównym efektem tych nowych technologii będzie róŋnorodnoķæ produktów ("oczekuje się, ŋe ich pojawienie się na rynku" wpģynie na prawie kaŋdy aspekt naszego ŋycia "w nadchodzących dziesięcioleciach"). Technologie zakģócające przenoszą starsze technologie i "umoŋliwiają przejęcie radykalnie nowych generacji istniejących produktów i procesów" oraz umoŋliwiają zupeģnie nowe klasy produktów, które wczeķniej nie byģy moŋliwe do zrealizowania. Jak napisano w raporcie: "Implikacje dla przemysģu są znaczne: firmy, które nie dostosowują się szybko, stają w obliczu przestarzaģoķci i upadku, podczas gdy te, które zajmują się i zauwaŋają, będą mogģy robiæ nowe rzeczy w niemal kaŋdej moŋliwej dyscyplinie technologicznej". Aby zilustrowaæ gģęboki wpģyw destrukcyjnej technologii na spoģeczeņstwo, naleŋy jedynie wziąæ pod uwagę przykģad komputera, a ostatnio takŋe wyszukiwarki takie jak Google i wpģyw, jaki te technologie wywarģy na wspóģczesne spoģeczeņstwo. John Searle opracowaģ wysoce dyskutowany sprzeciw wobec Sztucznej Inteligencji. Zaproponowaģ eksperyment myķlowy, zwany obecnie "pokojem chiņskim", aby przekonaæ się, w jaki sposób system sztucznej inteligencji nigdy nie miaģby umysģu podobnego do tego, który ma ludzkoķæ, lub miaģ zdolnoķæ zrozumienia naszego sposobu dziaģania
Chiņski pokój Searle′a
Wyobraž sobie, ŋe masz program komputerowy, który moŋe przetwarzaæ znaki chiņskie jako dane wejķciowe i produkowaæ chiņskie znaki jako dane wyjķciowe. Ten program, jeķli jest wystarczająco dobry, będzie miaģ zdolnoķæ do zaliczenia testu Turinga dla Chiņczyków - to znaczy, moŋe przekonaæ czģowieka, ŋe jest native speakerem chiņskim. Wedģug zwolenników testu Turinga, oznaczaģoby to, ŋe komputery mają zdolnoķæ rozumienia języka chiņskiego. Teraz wyobraž sobie jeszcze jeden moŋliwy sposób dziaģania programu. Osoba, która zna tylko angielski, zostaģa zamknięta w pokoju. Pokój jest peģen pudeģek chiņskich symboli ("baza danych") i zawiera ksiąŋkę z instrukcjami w języku angielskim ("program") o tym, jak manipulowaæ strunami chiņskich znaków. Osoba otrzymuje oryginalne chiņskie znaki za poķrednictwem jakiegoķ urządzenia do komunikacji wejķciowej. Następnie konsultuje się z ksiąŋką i postępuje zgodnie z instrukcjami, i produkuje strumieņ wyjķciowy chiņskich znaków, które następnie wysyģa przez wyjķciowe urządzenie komunikacyjne. Celem tego eksperymentu myķlowego jest twierdzenie, ŋe chociaŋ program komputerowy moŋe mieæ zdolnoķæ do konwersacji w języku naturalnym, nie ma prawdziwego zrozumienia, jakie ma miejsce. Komputery mają jedynie moŋliwoķæ uŋywania reguģ syntaktycznych do manipulowania symbolami, ale nie mają zrozumienia znaczenia (lub semantyki) z nich. Searle powiedziaģ: "Argumentacja jest następująca: jeķli czģowiek w pokoju nie rozumie chiņskiego na podstawie wdroŋenia odpowiedniego programu do zrozumienia chiņskiego, to ŋaden inny komputer cyfrowy nie jest na tej podstawie, poniewaŋ nie ma komputera , który ma wszystko, czego czģowiek nie ma. "
Byģo wiele odpowiedzi na argument Searle'a. Podobnie jak w przypadku wielu eksperymentów z myķlą o sztucznej inteligencji, takich jak ten, argument moŋna po prostu uznaæ za niestanowiący problemu. Naukowcy zajmujący się sztuczną inteligencją zwykle go ignorują, poniewaŋ argumentacja Searle'a nie powstrzymuje nas od budowania uŋytecznych systemów AI, które dziaģają inteligentnie, i czy mają umysģ, czy myķlą w ten sam sposób jak nasz mózg, są nieistotne. Stuart Russell i Peter Norvig zauwaŋają, ŋe większoķæ badaczy AI "nie dba o silną hipotezę sztucznej inteligencji - tak dģugo, jak program dziaģa, nie obchodzi go, czy nazywacie to symulacją inteligencji czy prawdziwej inteligencji." Turing sam przedstawiģ dziewięæ zastrzeŋeņ wobec sztucznej inteligencji, które stanowią dobre podsumowanie większoķci zarzutów, które pojawiģy się w kolejnych latach od opublikowania jego pracy.
1.3.1 Zarzut teologiczny
Argument ten powstaje wyģącznie z perspektywy teologicznej - tylko ludzie z nieķmiertelną duszą mogą myķleæ, a Bóg daģ nieķmiertelną duszę tylko ludziom, a nie zwierzętom czy maszynom. Turing nie pochwalaģ takich argumentów teologicznych, ale argumentowaģ przeciwko temu z teologicznego punktu widzenia. Kolejnym problemem teologicznym jest to, ŋe stworzenie Sztucznej Inteligencji uzurpuje sobie rolę Boga jako stwórcy dusz. Turing uŋyģ analogii ludzkiej prokreacji, aby wskazaæ, ŋe mamy takŋe rolę do odegrania w tworzeniu dusz.
1.3.2 Zastrzeŋenie "Gģowy w piasku"
Dla niektórych ludzi myķlenie o konsekwencjach maszyny, która moŋe myķleæ, jest zbyt przeraŋające, aby o tym myķleæ. Ten argument jest skierowany do osób, które lubią chowaæ "gģowy w piasku", a Turing pomyķlaģ, ŋe argument jest tak faģszywy, ŋe nie zadaģ sobie trudu, aby temu zapobiec.
1.3.3 Zarzut matematycznym
Turing uznaģ ten zarzut oparty na matematycznym rozumowaniu za substancję większą niŋ dwie pierwsze. Zostaģ on podniesiony przez wiele osób, od czasu wģączenia filozofa Johna Lucasa i fizyka Rogera Penrose'a. Zgodnie z twierdzeniem Gödla o niezupeģnoķci, istnieją granice oparte na logice na pytania, na które komputer moŋe odpowiedzieæ, a zatem komputer musiaģby uzyskaæ bģędne odpowiedzi. Jednak ludzie często mylą się, więc omylna maszyna moŋe oferowaæ bardziej wiarygodną iluzję inteligencji. Dodatkowo sama logika jest ograniczoną formą rozumowania, a ludzie często nie myķlą logicznie. Sprzeciwianie się sztucznej inteligencji w oparciu o ograniczenia rozwiązania opartego na logice ignoruje fakt, ŋe istnieją alternatywne rozwiązania nie oparte na logice (takie jak na przykģad przyjęte w ucieleķnionej kognitywistyce), w których argumenty matematyczne oparte na logice nie mają zastosowania.
1.3.4 Argument ze ķwiadomoķci
Ten argument mówi, ŋe komputer nie moŋe mieæ ķwiadomych doķwiadczeņ ani zrozumienia. Odmianą tego argumentu jest eksperyment myķlowy Johna Searlea w chiņskim pokoju. Geoffrey Jefferson w 1949 podsumowuje argument: "Dopóki maszyna nie napisze sonetu lub nie skomponuje koncertu z powodu odczuwanych myķli i emocji, a nie przez przypadkowy skģad symboli, moŋemy zgodziæ się, ŋe maszyna równa się mózgowi - to znaczy , nie tylko napisze, ale wiesz, ŋe to on napisaģ. Ŋaden mechanizm nie mógģby odczuwaæ (i nie tylko sztucznie sygnalizowaæ, ģatwą manipulację) przyjemnoķci z sukcesów, ŋalu, gdy zawory się topią, ocieplają pochlebstwa, staje się nieszczęķliwy przez swoje bģędy, oczarowany seksem, gniewa się lub jest przygnębiony, kiedy nie moŋe dostaæ to, czego chce. "Turing zauwaŋyģ, ŋe ten argument wydaje się zaprzeczeniem waŋnoķci testu Turinga:" jedynym sposobem, dzięki któremu moŋna byæ pewnym, ŋe maszyna myķli, jest bycie maszyną i myķlenie ". Jest to oczywiķcie niemoŋliwe do osiągnięcia, tak jak nie moŋna tego byæ pewnym , ŋe ktokolwiek inny myķli, ma emocje i jest ķwiadomy w taki sam sposób jak my sami. Niektórzy twierdzą, ŋe ķwiadomoķæ jest nie tylko domeną ludzi, ale takŋe ma ķwiadomoķæ. Zatem brak powszechnie akceptowanej definicji ķwiadomoķci stwarza problemy dla tego argumentu.
1.3.5 Argumenty z róŋnych rodzajów uģomnoķci
Te argumenty przyjmują postaæ, ŋe komputer moŋe robiæ wiele rzeczy, ale nigdy nie byģby zdolny do X. W przypadku X, Turing zaproponowaģ następującą selekcję: "bądž miģy, zaradny, piękny, przyjazny, z inicjatywą, poczuciem humoru, odróŋniaj dobro od zģa, popeģniaj bģędy, zakochaj się, ciesz się truskawkami i ķmietaną, spraw, aby ktoķ się w nim zakochaģ, ucz się z doķwiadczenia, uŋywaj sģów poprawnie, bądž przedmiotem wģasnej myķli, bądž tak róŋnorodny w zachowaniu jak czģowiek Zróbcie coķ naprawdę nowego".Turing zauwaŋyģ, ŋe zazwyczaj uzasadnione jest uzasadnienie tych argumentów, a niektóre z nich są po prostu odmianami argumentu ķwiadomoķci. Ten argument pomija takŋe wszechstronnoķæ maszyn i czystą pomysģowoķæ ludzi, którzy je budują. Większoķæ listy Turinga zostaģa juŋ osiągnięta w róŋnym stopniu, z wyjątkiem zakochania się i cieszenia truskawkami i ķmietaną. (Turing uznaģ to za "idiotyczną" rzecz, którą moŋna zrobiæ maszyna). Agenci afektywni zostali juŋ zbudowani, aby byæ ŋyczliwym i przyjaznym. Niektórzy wirtualni agenci i gry komputerowe mają inicjatywę i są niezwykle zaradni. Ageni konwersacyjni wiedzą, jak poprawnie uŋywaæ sģów; niektórzy mają poczucie humoru i potrafią odróŋniæ dobro od zģa. Bardzo ģatwo jest zaprogramowaæ maszynę, aby popeģniģa bģąd. Niektóre generowane komputerowo twarze kompozytowe i twarz Julesa , androgenicznego robota są statystycznie doskonaģe, dlatego moŋna je uznaæ za piękne. Samoķwiadomoķæ, czyli bycie przedmiotem wģasnych myķli, zostaģo juŋ osiągnięte przez robota Nico w ograniczonym sensie. Pojemnoķæ pamięci masowej i moŋliwoķci przetwarzania wspóģczesnych komputerów nakģadają niewiele ograniczeņ na liczbę zachowaņ, jakie moŋe wykazywaæ komputer. (Trzeba tylko graæ w grę komputerową ze zģoŋoną sztuczną inteligencją, aby zaobserwowaæ duŋą róŋnorodnoķæ sztucznych zachowaņ). Aby komputery zrobiģy coķ naprawdę nowego, zobacz następny zarzut.
1.3.6 Zastrzeŋenie Lady Lovelace
Ten zarzut stwierdza, ŋe komputery nie są zdolne do oryginalnego myķlenia. Lady Loveless napisaģa wspomnienie w 1842 r. (Zawarte w szczegóģowej informacji z Analitical Engine Babbage′a) stwierdzając, ŋe: "Silnik Analityczny nie ma ŋadnych pretensji aby coķ zainicjowaæ. Moŋe zrobiæ wszystko, jeķli wiemy, w jakiej kolejnoķci to wykonaæ". Turing argumentowaģ, ŋe pamięæ mózgu jest podobna do pamięci komputera i nie ma powodu, aby sądziæ, ŋe komputery nie są w stanie zaskoczyæ ludzi. Rzeczywiķcie, zastosowanie programowania genetycznego stworzyģo wiele nowych wynalazków posiadających zdolnoķæ patentową. Na przykģad NASA uŋywaģ programowania genetycznego w celu opracowania anteny, która zostaģa zastosowana na statku kosmicznym w 2006 r. . Antena ta zostaģa uznana za konkurencyjną dla ludzi, poniewaŋ zapewniaģa podobną wydajnoķæ, co antena zaprojektowana przez czģowieka, ale jej konstrukcja byģa caģkowicie nowa.
1.3.7 Argument z ciągģoķci ukģadu nerwowego
Turing przyznaģ, ŋe mózg nie jest cyfrowy. Neurony strzelają impulsami, które mają komponenty analogowe. Turing sugeruje, ŋe kaŋdy system analogowy moŋe byæ ģatwo symulowany do dowolnego stopnia dokģadnoķci. Inną formą tego argumentu jest to, ŋe mózg przetwarza sygnaģy (z bodžców), a nie symbole. Istnieją dwa paradygmaty w sztucznej inteligencji - symboliczne i subsymboliczne (lub koneksjonistyczne) - które protagoniķci uwaŋają za najlepszy sposób rozwoju inteligentnych systemów. Pierwsza z nich kģadzie nacisk na podejķcie do przetwarzania symboli z góry na dóģ (systemy oparte na wiedzy są jednym z przykģadów), podczas gdy drugi kģadzie nacisk na podejķcie oddolne z symbolami fizycznie uziemionymi w pewien sposób (na przykģad sieci neuronowe). Paradygmaty symboliczne i subimienne staģy się zaciekģą debatą w sztucznej inteligencji i naukach kognitywnych na przestrzeni lat, i podobnie jak w przypadku wszystkich debat, zwolennicy często przyjmowali wzajemnie wykluczające się punkty widzenia. Metody ģączące aspekty obu podejķæ mają pewne zalety, takie jak przestrzenie pojęciowe, co podkreķla, ŋe reprezentujemy informacje na poziomie koncepcyjnym - to znaczy, ŋe pojęcia są kluczowym elementem i zapewniają poģączenie między bodžcami i symbolami.
1.3.8 Argument z nieformalnoķci zachowania
Ludzie nie mają skoņczonego zestawu zachowaņ - improwizują w oparciu o okolicznoķci. W związku z tym, jak moglibyķmy opracowaæ zestaw zasad lub praw, które opisywaģyby, co dana osoba powinna robiæ w kaŋdej moŋliwej sytuacji? Turing przedstawiģ tę argumentację w następujący sposób: "jeķli kaŋdy czģowiek miaģby okreķlony zestaw zasad postępowania, które regulowaģby jego ŋycie, nie byģby lepszy od maszyny. Ale nie ma takich zasad, więc ludzie nie mogą byæ maszynami. "Turing twierdzi, ŋe tylko dlatego, ŋe nie wiemy, jakie są prawa, nie oznacza to, ŋe nie istnieją takie prawa. Argument ten ujawnia takŋe bģędne przekonanie, do czego zdolny jest komputer. Jeķli myķlimy o komputerach jako 'maszynach' moŋemy ģatwo popeģniæ bģąd uŋywając pojęcia, które moŋemy kojarzyæ z wieloma maszynami, których uŋywamy w codziennym ŋyciu (takimi jak wiertarka lub samochód). Ale niektóre maszyny - tj. komputery - są zdolne do znacznie więcej niŋ te prostsze maszyny. Są zdolne do zachowania autonomicznego i mogą obserwowaæ i reagowaæ na zģoŋone ķrodowisko, powodując w rezultacie poŋądaną zģoŋonoķæ zachowania. Niektóre z nich wykazują równieŋ emergentne (niezaprogramowane) zachowania ze swoich interakcji ze ķrodowiskiem, takie jak stukanie stóp przez wirtualne pająki, które odzwierciedla zachowanie pająków w prawdziwym ŋyciu.
1.3.9 Argument z percepcji pozazmysģowej
Ten ostatni zarzut ma dziķ mniejsze znaczenie, poniewaŋ odzwierciedla zainteresowanie dodatkową percepcją sensoryczną (ESP), które byģo szeroko rozpowszechnione w czasie, gdy Turing opublikowaģ swój artykuģ. Argument jest taki, ŋe jeķli ESP jest moŋliwe u ludzi, to moŋna to wykorzystaæ do uniewaŋnienia testu Turinga. (Komputer moŋe byæ w stanie dokonaæ losowych przewidywaņ w grze zgadującej karty, podczas gdy czģowiek z umiejętnoķciami czytania umysģu moŋe byæ w stanie odgadnąæ lepiej niŋ przypadek.) Turing omówiģ sposoby, w których warunki testu mogą zostaæ zmienione w celu przezwycięŋenia to. Kolejny zarzut dotyczy postrzegania braku konkretnych wyników, które badania AI wytworzyģy w ponad póģ wieku staraņ. Wspomniany wczeķniej raport wyjaķniaģ ciągģą poraŋkę badaņ nad sztuczną inteligencją: "Uwaŋa się, ŋe obecne systemy AI są zasadniczo niezdolne do ujawnienia inteligencji, tak jak ją rozumiemy." Termin "AI Winter" odnosi się do poglądu, ŋe badania i rozwój Sztucznej Inteligencji sģabnie i trwa to juŋ od jakiegoķ czasu. Powiązane z tym jest przekonanie, ŋe Sztuczna Inteligencja nie jest juŋ godnym miejscem badawczym, poniewaŋ (w niektórych umysģach) nie speģniģa się spektakularnie w speģnianiu swoich obietnic, odkąd termin zostaģ sformuģowany na konferencji Dartmouth w 1956 roku (tej konferencji teraz przypisuje się wprowadzenie terminu "Sztuczna inteligencja"). Wbrew mitowi, ŋe istnieje AI Winter, tempo badaņ gwaģtownie roķnie. Jednym z gģównych czynników przyszģych badaņ będzie branŋa rozrywkowa - potrzeba realistycznej interakcji z postaciami niezaleŋnymi (NPC) w branŋy gier oraz dąŋenie do większej wiarygodnoķci w powiązanych sektorach filmowych i telewizyjnych. Branŋe te mają znaczne wpģywy finansowe i mają prawie nieograniczony potencjaģ do zastosowania technologii sztucznej inteligencji. Na przykģad przeksztaģcenie rzeczywistoķci telewizyjnej w gry komputerowe online moŋe doprowadziæ do w peģni interaktywnej telewizji w niezbyt odlegģej przyszģoķci gdzie widzowie będą zanurzani i będą mogli wpģywaæ na historię, którą oglądają (poprzez gģosowanie na moŋliwe wyniki - np. czy zabiæ jednego z gģównych aktorów). Alternatywną moŋliwoķcią moŋe byæ poģączenie animacji komputerowej, symulacji i technologii sztucznej inteligencji ,prowadziæ do filmów, które moŋna oglądaæ wiele razy, za kaŋdym razem z róŋnymi wynikami, w zaleŋnoķci od tego, co wydarzyģo się podczas symulacji. Pomimo tych interesujących wydarzeņ w branŋy rozrywkowej, gdzie AI nie jest postrzegana jako zagroŋenie, coraz większe zaangaŋowanie technologii sztucznej inteligencji w inne aspekty naszego codziennego ŋycia budzi coraz większy niepokój wielu osób. Kevin Warwick w swojej ksiąŋce "The March of the Machines" z 1997 roku przewidziaģ, ŋe roboty lub super-inteligentne maszyny przemocą przejęģyby ludzkoķæ za następne 50 lat. Jednym z powodów takiego myķlenia jest projekcja, ŋe komputery wyprzedzą moc przetwarzania ludzkiego mózgu juŋ w 2020 r. Na przykģad w tej projekcji przewidziano, ŋe komputery mają juŋ zdolnoķæ przetwarzania pająków - a niedawne symulacje stawonogów Sztucznego Ŋycia pokazaģy, jak moŋna obecnie uzyskaæ wiarygodną animację dynamiczną pająków w czasie rzeczywistym. Te same ramy uŋywane do symulacji zostaģy rozszerzone na jaszczurki. Zarówno jaszczurka jak i odpowiednik pająka, zostaģ przewidziany przez Moraveca aby juŋ zostaģ osiągnięty. Jednak w przeciwieņstwie do wykresu Moraveca róŋnica między wirtualnymi pająkami a wirtualnymi jaszczurkami byģa znacznie mniejsza. Jeķli takie ramy mogą byæ dostosowane do naķladowania ssaków i ludzi, wówczas wiarygodne ludzkie symulacje mogą byæ bliŋsze niŋ początkowo sądzono. Nieporozumienia dotyczące maszyn przejmujących rasę ludzką, które grają na niepoinformowanych niepokojach i obawach ludzi, mogą niestety mieæ wpģyw na politykę publiczną wobec badaņ i rozwoju. Na przykģad, petycja z Instytutu Wynalazków Spoģecznych stwierdza: "W związku z prawdopodobieņstwem, ŋe na początku następnego tysiąclecia komputery i roboty będą rozwijane ze zdolnoķcią i zģoŋonoķcią większą niŋ ludzki mózg, a takŋe z potencjaģem aby dziaģaæ zģowrogo w stosunku do ludzi, my, niŋej podpisani, wzywamy polityków i stowarzyszenia naukowe do powoģania międzynarodowej komisji monitorującej i kontrolującej rozwój systemów sztucznej inteligencji. ".
Chris Malcolm dostarcza przekonujących argumentów w serii artykuģów, dlaczego roboty nie rządzą ķwiatem. Podkreķla, ŋe tempo wzrostu inteligencji jest znacznie wolniejsze niŋ tempo wzrostu mocy obliczeniowej. Na przykģad Moravec przewiduje, ŋe będziemy mieli w peģni inteligentne roboty w 2050, chociaŋ do 2020 roku będziemy mieæ komputery o większej mocy obliczeniowej niŋ mózg. Malcolm podkreķla takŋe niebezpieczeņstwa związane z "antropomorfizmem i interpretowaniem wszystkiego". Na przykģad, trudno uniknąæ nie przypisywania emocji i uczuæ, obserwując zadziwiająco ŋywy, sztuczny klon Hiroshi Ishiguro, zwany Geminoidem, lub androgenicznego androida Hansona Roboticsa. Joseph Weizenbaum, który opracowaģ Elizę, chatbota z umiejętnoķcią symulowania Rogeriana i jedną z pierwszych prób przejķcia testu Turinga, byģ tak zaniepokojony niedoinformowanymi odpowiedziami osób, które nalegaģy, by traktowaæ Elizę jako prawdziwą osobę, ŋe "rasa ludzka po prostu nie byģa intelektualnie dojrzaģa, by mieszaæ się z tak kuszącą nauką, jak sztuczna inteligencja"
Eksperymenty konceptualnej metafory, analogii i myķlowe
Duŋa częķæ języka skģada się z metafory pojęciowej i analogii. Na przykģad analogia między badaniami sztucznej inteligencji a fizyczną eksploracją wykorzystuje przykģady metafory pojęciowej, która ģączy pojęcia "badania nad sztuczną inteligencją" i "eksploracja". Lakoff i Johnson podkreķlają waŋną rolę, jaką metafora pojęciowa odgrywa w języku naturalnym i jak są one powiązane z naszymi fizycznymi doķwiadczeniami. Twierdzą, ŋe metafora jest wszechobecna nie tylko w języku potocznym, ale w naszych myķlach i dziaģaniu, będąc podstawową cechą ludzkiego systemu pojęciowego. Rozpoznanie uŋycia metafory i analogii w języku moŋe pomóc w zrozumieniu i uģatwieniu uczenia się. Na przykģad opracowano koncepcyjne ramy metaforyczne dla biologii i nauczania matematyki. Analogia i metafora pojęciowa są waŋnymi językowymi narzędziami do wyjaķniania związków między pojęciami. Metaforę rozumie się przez znalezienie analogii odwzorowania między dwiema domenami - między bardziej abstrakcyjną docelową domeną koncepcyjną, którą próbujemy zrozumieæ, a žródģową koncepcyjną domeną, która jest žródģem wyraŋeņ metaforycznych. Lakoff i Johnson dokģadnie zbadali powszechnie uŋywane pojęciowe metafory, takie jak "ŊYCIE TO PODRÓŊ", i "CZAS TO PIENIĄDZE", które pojawiają się w codziennych zwrotach, których uŋywamy w języku. Oto kilka przykģadów: "Mam przed sobą swoje ŋycie", "Zaatakowaģ mój argument" i "Zainwestowaģem w to duŋo czasu". Zrozumienie tych zdaņ wymaga od czytelnika lub sģuchacza zastosowania cech z bardziej zrozumiaģych pojęæ, takich jak PODRÓŊ, WOJNA i PIENIĄDZE, do mniej zrozumiaģych, bardziej abstrakcyjnych pojęæ, takich jak ŊYCIE, i CZAS. W wielu przypadkach bardziej zrozumiaģa lub bardziej "konkretna" koncepcja pochodzi z dziedziny odnoszącej się do naszego fizycznie wcielonego ludzkiego doķwiadczenia (np. Metafora "UP IS GOOD" uŋyta w wyraŋeniu "Things is lookup up"). Innym przykģadem jest metafora kartograficzna, która jest podstawą "map" Roberta Horna. Analogia, podobnie jak metafora, rysuje podobieņstwo między rzeczami, które początkowo mogą wyglądaæ inaczej. Pod pewnymi względami moŋemy uznaæ analogię za formę argumentu, którego celem jest przybliŋenie relacji między parami porównywanych pojęæ, podkreķlenie dalszych podobieņstw i pomoc przez porównanie nieznanego podmiotu z bardziej znanym. Analogia wydaje się byæ podobna do metafory w roli, w której gra, więc jak się róŋnią? Wedģug internetowego sģownika Merriam-Webster metafora jest "figurą wypowiedzi, w której sģowo lub fraza dosģownie oznaczają jeden rodzaj przedmiotu lub idei jest uŋywany zamiast innego, aby zasugerowaæ podobieņstwo lub analogię między nimi (jak przy topieniu pieniędzy). "Analogię definiuje się jako" wnioskowanie, ŋe jeķli dwie lub więcej rzeczy zgadzają się ze sobą pod pewnymi względami, prawdopodobnie zgodzą się w innych " a takŋe "podobieņstwo w niektórych szczegóģach między rzeczami innymi w odróŋnieniu. Zasadnicza róŋnica polega na tym, ŋe metafora jest postacią mowy, w której jedna rzecz ma na myķli inną, podczas gdy analogia nie jest jedynie figurą - moŋe byæ logicznym argumentem, ŋe jeķli dwie rzeczy są podobne pod pewnymi względami, będą one podobne na inne sposoby. Język uŋywany do opisywania informatyki i sztucznej inteligencji jest często bogaty w uŋycie metafory pojęciowej i analogii. Jednak rzadko są one wyražnie okreķlone, a zamiast tego czytelnik często jest pozostawiony do wywnioskowania z uŋytych sģów, powstaje niejawny związek. My uŋyjemy analogii (i metafory pojęciowej), aby wyražnie podkreķliæ, jak dwa pojęcia są ze sobą powiązane, jak pokazano poniŋej:
• Wirus komputerowy w informatyce jest analogiczny do "wirusa" w prawdziwym ŋyciu.
• "Robak komputerowy" w informatyce jest analogiczny do "robaka" w prawdziwym ŋyciu.
• "Pająk internetowy" w informatyce jest analogiczny do "pająka" w prawdziwym ŋyciu.
• "Internet" w informatyce jest analogiczny do "sieci pajęczej w prawdziwym ŋyciu.
• "Strona internetowa" w informatyce jest analogiczna do "ķrodowiska" w prawdziwym ŋyciu.
W tych przykģadach wyražnie stwierdzono między wirusami komputerowymi pojęcia "wirus komputerowy", "robak komputerowy", "pająk internetowy" i "Internet" oraz ich rzeczywiste odpowiedniki. Wiele funkcji (ale nie wszystkie) związanych z nimi koncepcji (takich jak wirus w prawdziwym ŋyciu) są często uŋywane do opisania cech abstrakcyjnego pojęcia (wirus komputerowy), który jest wyjaķniony. Te analogie naleŋy pamiętaæ w porządku zrozumieæ język uŋywany do opisu pojęæ. Na przykģad, gdy uŋywamy wyraŋenia "przeszukiwanie sieci", moŋemy zrozumieæ jego ukryte znaczenie w kontekķcie trzeciej i czwartej analogii powyŋej. Alternatywne analogie (np. piąta analogia) kryją się za znaczeniem róŋnych metafor wykorzystywanych w wyraŋeniach takich jak "gubienie się podczas wyszukiwania w Internecie" i "surfowanie po Internecie". Kiedy ktoķ mówi, ŋe zgubiģ się podczas eksplorowania sieci, nie jest fizycznie zagubiony. Poza tym byģoby dziwnie mówiæ o prawdziwym pająku "surfującym" po sieci, ale moŋemy mówiæ o osobie surfującej po Internecie, poniewaŋ robimy analogię, ŋe sieæ jest jak fala w prawdziwym ŋyciu. Przykģadowe metafory związane z tą analogią to wyraŋenia takie jak "powódž informacji" i "zalewanie przez przeciąŋenie informacji". Analogia to próba utrzymania równowagi na fali informacji nad którą nie masz kontroli. Dwie waŋne analogie stosowane w sztucznej inteligencji dotyczące algorytmów genetycznych i sieci neuronowych mają podstawę biologiczną:
• "Algorytm genetyczny" w Sztucznej Inteligencji jest analogiczny do ewolucji genetycznej w biologii.
• "Sieæ neuronowa" w Sztucznej Inteligencji jest analogiczna do neuronowego przetwarzania w mózgu.
Są to przykģady "naturalnych obliczeņ" - komputerów inspirowanych naturą. W niektórych przypadkach w języku uŋywane są konkurencyjne analogie iw tym przypadku musimy wyjaķniæ kaŋdą analogię dalej, okreķlając punkty podobieņstwa i odmiennoķci (gdzie kaŋda analogia jest silna lub zaģamuje się odpowiednio) i dostarczając przykģady metafor uŋyte w tekķcie, który wyciąga analogię. Na przykģad moŋna dokonaæ analogii między docelową koncepcją "badania" i konkurującymi pojęciami žródģowymi "eksploracja" i "budowa" w następujący sposób:
Analogia 1 "Badania" w nauce są analogiczne do "eksploracji" w prawdziwym ŋyciu.
Punkty podobieņstwa: samo sģowo "badanie" równieŋ stosuje analogię eksploracji: moŋemy myķleæ o tym jako o procesie z powrotem (powtórzenie) wyszukiwania, które juŋ zrobiliķmy. Punkty niepodobieņstwa: wymyķlanie nowych pomysģów jest bardziej skomplikowane niŋ poszukiwanie nowej ķcieŋki. Musisz budowaæ na istniejących pomysģach, tworzyæ lub konstruowaæ coķ nowego z istniejących częķci. Przykģady metafor uŋytych w tym rozdziale: "Pģywamy po tym nowym morzu, poniewaŋ jest nowa wiedza, którą moŋna zdobyæ", "Ķcieŋki do sztucznej inteligencji", "Większoķæ terenów do zbadania jest wciąŋ nieznana".
Analogia 2 "Badania" w nauce są analogiczne do "konstrukcji" w prawdziwym ŋyciu.
Punkty podobieņstwa: Często mówimy, ŋe nowe pomysģy są tworzone lub budowane na podstawie istniejących pomysģów; mówimy takŋe o strukturach, które zapewniają wsparcie lub strukturę dla konkretnego pomysģu. Punkty niepodobieņstwa: wymyķlanie nowych pomysģów jest bardziej skomplikowane niŋ tylko konstruowanie lub budowanie czegoķ nowego. Czasami musisz iķæ tam, gdzie nigdy wczeķniej nie byģeķ; czasem gubisz się po drodze (coķ, co wydaje się dziwne, jeķli budujesz budynek). Przykģady metafor uŋytych w tym rozdziale: "jak budowaæ lepsze algorytmy wyszukiwania", "Zróbmy analogię", "bazuj na istniejących pomysģach", "zazwyczaj uzasadnione jest uzasadnienie tych argumentów".
Eksperymenty myķlowe
Zapewniają alternatywną metodę opisywania nowego pomysģu lub opracowywania problemów z istniejącym pomysģem. Analogią do terminu "eksperyment myķlowy" jest to, ŋe przeprowadzamy pewien eksperyment (jak naukowiec w laboratorium), ale eksperyment ten przeprowadzany jest tylko w naszym umyķle. Podobnie jak w przypadku wszystkich eksperymentów, wypróbowujemy róŋne rzeczy, aby zobaczyæ, co moŋe się wydarzyæ, jedyną róŋnicą jest to, ŋe rzeczy, które wypróbowywaliķmy, są w większoķci wykonywane tylko w naszych wģasnych myķlach. Nie ma rzeczywistych eksperymentów - to tylko proces rozumowania, który jest uŋywany przez osobę proponującą eksperymenty. W eksperymencie myķlowym zasadniczo stawiamy pytania "co jeķli" w naszych wģasnych umysģach. Na przykģad "Co jeķli X?" Lub "Co stanie się, jeķli X?", Gdzie X moŋe byæ "moŋemy daæ się zwieķæ przekonaniu, ŋe komputer to czģowiek" w eksperymencie myķlowym Turinga. Ponadto osoba, która proponuje tę myķl eksperyment polega na tym, aby inni ludzie przeprowadzili ten sam proces myķlowy we wģasnym umyķle, wyobraŋając sobie konkretną sytuację i prawdopodobne konsekwencje. Często eksperyment myķlowy wymaga postawienia się w sytuacji (w twoim umyķle), a następnie wyobraŋenia sobie, co by się staģo. Cel tego eksperymentu myķlowego polega na przedstawianiu argumentów za lub przeciw okreķlonemu punktowi widzenia, podkreķlając waŋne kwestie. Niemiecki termin eksperymentu myķlowego to Gedankeneximentiment - na przykģad istnieje wiele przykģadów stosowanych w fizyce. Jednym z najsģawniejszych postawionych przez Alberta Einsteina byģo ķciganie wiązki ķwiatģa i doprowadzenie do rozwoju Teorii Szczególnej Względnoķci. Sztuczna inteligencja ma równieŋ wiele przykģadów eksperymentów myķlowych, a kilka z nich opisano w tych podręcznikach, aby zilustrowaæ waŋne idee i koncepcje.
Zasady projektowania autonomicznych agentów
Pfeifer and Scheier proponują kilka zasad projektowania dla autonomicznych agentów:
Projekt 1.1 Zasady projektowania Pfeifer i Scheier dla autonomicznych agentów.
Design Meta-Principle: "Zasada trzech skģadników". Ta pierwsza zasada jest klasyfikowana jako meta-zasada, poniewaŋ definiuje kontekst rządzący innymi zasadami. Stwierdza on, ŋe projektowanie autonomicznych czynników obejmuje trzy skģadniki: (1) niszę ekologiczną; (2) poŋądane zachowania i zadania; i (3) sam agent. "Ķrodowisko zadaņ" obejmuje razem (1) i (2).
Zasada projektowania 1: Zasada "peģnych agentów". Agenci muszą byæ kompletni: autonomiczni; samowystarczalny; wcieleni; i poģoŋeni.
Zasada projektowania 2 : "zasada równolegģych, lužno powiązanych procesów". Inteligencja wyģania się z interakcji między agentem a ķrodowiskiem poprzez równolegģe, lužno powiązane procesy powiązane z mechanizmami zmysģowo-motorycznymi.
Zasada projektowania 3 : "zasada koordynacji sensoryczno-motorycznej". Wszystkie inteligentne zachowania (np. Percepcja, kategoryzacja, pamięæ) są wynikiem koordynacji czuciowo-ruchowej, która strukturyzuje dane zmysģowe.
Zasada projektowania 4 : "Zasada tanich projektów". Projekty są oszczędne i wykorzystują fizykę nisz ekologicznych.
Zasada projektowania 5 : "Zasada redundancji". Nadmiar jest uwzględniany w projekcie agenta z nakģadaniem się informacji między róŋnymi kanaģami sensorycznymi.
Zasada projektowania 6 : "Zasada równowagi ekologicznej". Zģoŋonoķæ agenta odpowiada zģoŋonoķci ķrodowiska zadaņ. Musi byæ dopasowanie zģoŋonoķci czujników, ukģadu ruchowego i podģoŋa neuronowego.
Zasada projektowania 7 : "Zasada wartoķci". Agent ma system wartoķci, który opiera się na mechanizmach samo-nadzorowanego uczenia się i samoorganizacji.
Te dobrze opracowane zasady mają znaczący wpģyw na projektowanie autonomicznych czynników. W przewaŋającej częķci postaramy się przestrzegaæ tych zasad podczas projektowania naszych wģasnych agentów. Będziemy takŋe wielokrotnie przeglądaæ aspekty tych zasad, gdzie będziemy bardziej szczegóģowo analizowaæ konkretne pojęcia, takie jak pojawienie się i samoorganizacja. Jednakŋe nieco zmienimy niektóre aspekty tych zasad, aby lepiej dopasowaæ terminologię i podejķcie. Zamiast odróŋniaæ trzy skģadniki, jak w metodzie projektowania i odnosiæ się do "niszy ekologicznej", wolimy uŋywaæ tylko dwóch: agentów i ķrodowisk. Ķrodowiska są waŋne dla agentów, poniewaŋ interakcja agent-ķrodowisko jest niezbędna do zģoŋonego zachowania agenta. W następnej częķci omówimy, co rozumiemy przez ķrodowisko, i spojrzymy na niektóre ķrodowiska odzwierciedlające zģoŋonoķæ realnego ķwiata. Przedstawiając rozwiązania problemów, będziemy trzymaæ się gģównie zasad projektowania opisanych powyŋej, ale z następującymi dalszymi zasadami projektowania.
Dalsze zasady projektowania dla agentów i ķrodowisk w NetLogo
Zasada projektowania 8 : Projekt powinien byæ prosty i zwięzģy (zasada "Keep It Simple Stupid" lub KISS).
Zasada projektowania 9 : Projekt powinien byæ wydajny obliczeniowo.
Zasada projektowania 10 : Projekt powinien byæ w stanie modelowaæ tak szeroką gamę zģoŋonych zachowaņ agenta i zģoŋonych ķrodowisk, jak to moŋliwe.
Gģównym powodem, dla którego projekt jest prosty i zwięzģy, jest ze względów pedagogicznych. Jednakŋe, jak zobaczymy w ostatnich rozdziaģach, prostota projektu niekoniecznie wyklucza zģoŋonoķæ zachowania agenta lub zģoŋonoķæ w ķrodowisku. Na przykģad język programowania NetLogo ma bogaty zestaw modeli, mimo ŋe większoķæ z nich ogranicza się do prostego ķrodowiska 2D uŋywanego do symulacji i wizualizacji.
Podsumowanie
Cytat z początku tej częķci odnosi się do czasu, kiedy ludzkoķæ jeszcze nie pokonaģa "ostatecznej granicy" przestrzeni. Póģ wieku póžniejszej eksploracji przestrzeni kosmicznej, byæ moŋe moŋemy uznaæ, ŋe przestrzeņ nie jest juŋ "ostateczną" granicą. Mamy wiele więcej moŋliwoķci do zbadania, chociaŋ nie jest to kwestia fizyczna tak jak przestrzeņ. Są to granice nauki i inŋynierii oraz granice umysģu. Moŋemy albo zdecydowaæ się na konfrontację z tymi trudnymi granicami, albo zignorowaæ je, utrzymując nasze "gģowy w piasku". Ta częķæ stanowi wprowadzenie do dziedziny Sztucznej Inteligencji (AI) i pozycjonuje AI jako wschodzącą, ale potencjalnie destrukcyjną technologię na przyszģoķæ. Jest to analogia między badaniem SI a eksploracją niezbadanego terytorium, oraz opisuje kilka ķcieŋek, które zostaģy podjęte w przeszģoķci w celu zbadania tego terytorium, niektóre z nich są ze sobą w konflikcie. Pojawiģo się wiele zastrzeŋeņ do sztucznej inteligencji, z których wiele zostaģo zrobionych z ludzi, którzy są žle poinformowani. W niniejszym rozdziale podkreķlono równieŋ zastosowanie metafory pojęciowej i analogii w języku naturalnym i sztucznej inteligencji. Podsumowanie waŋnych pojęæ, które moŋna wyciągnąæ z tej częķci, pokazano poniŋej:
• Istnieje wiele dróg do Sztucznej Inteligencji. Istnieje równieŋ wiele zastrzeŋeņ.
• Test Turinga jest kontrowersyjnym testem sztucznej inteligencji.
• Argument Chiņskiego Pokoju Searles'a mówi, ŋe komputer nigdy nie będzie w stanie myķleæ i rozumieæ tak, jak my. Badacze sztucznej inteligencji zwykle ignorują to i dalej budują uŋyteczne systemy sztucznej inteligencji.
• Komputery najprawdopodobniej będą miaģy moŋliwoķci przetwarzania danych do 2020 roku, ale na komputery z inteligencją prawdopodobnie poczekamy dģuŋej.
• AI Winter - nie w tej chwili.
• Konceptualna metafora i analogia - to waŋne urządzenia językowe, których powinniķmy byæ ķwiadomi, aby to zrozumieæ język naturalny.
• Pfeifer i Scheier zaproponowali kilka waŋnych zasad projektowania dla autonomicznych agentów.
Agenci i Ķrodowisko
2.1 Co to jest agent?
Systemy zorientowane na agenta staģy się jednym z najbardziej ŋywych i waŋnych obszarów informatyki. Historycznie, jednym z gģównych obszarów zainteresowania w sztucznej inteligencji byģo budowanie inteligentnych systemów. Standardowy podręcznik w AI napisany przez Russella i Norviga przyjmuje koncepcję racjonalnych agentów jako centralnych dla ich podejķcia do sztucznej inteligencji. Nacisk kģadziony jest na rozwój systemów agentów, które moŋna rozsądnie nazwaæ inteligentnymi. Systemy zorientowane na klienta są równieŋ waŋnym obszarem badaņ, który leŋy u podstaw wielu innych obszarów badawczych w dziedzinie technologii informatycznych. Na przykģad, twórcy programu Agentlink III, który jest siecią doskonaģoķci dla systemów opartych na agentach, twierdzą, ŋe agenci stanowią podstawę wielu aspektów szerszego europejskiego programu badawczego oraz ŋe "agenci stanowią najwaŋniejszy nowy paradygmat rozwoju oprogramowania od momentu orientacji". Istnieje jednak wiele nieporozumieņ dotyczących tego, co ludzie rozumieją przez "agenta". Poniŋej przedstawiono kilka perspektyw dla znaczenie terminu "agent".
Perspektywa : Sztuczna Inteligencja
Kluczowa Idea : Agent jest ucieleķniony (tj. Usytuowany) w otoczeniu i podejmuje wģasne decyzje. Odbiera on otoczenie poprzez czujniki i dziaģa na otoczenie poprzez siģownik
Obszary Zastosowania : Inteligentni agenci. Inteligentne systemy. Robotyka.
Perspektywa : Przetwarzanie Rozproszone
Kluczowa Idea : Agent to autonomiczny proces programowy lub wątek.
Obszary Zastosowania : Model trójwymiarowy (przy uŋyciu agentów). Sieci peer-to-peer. Przetwarzanie równolegģe i gridowe.
Perspektywa : Obliczenia Internetowe
Kluczowa Idea : Agent wykonuje zadanie w imieniu uŋytkownika. tj. agent dziaģa jako proxy; uŋytkownik nie moŋe wykonaæ (lub nie chce wykonaæ) zadania samodzielnie.
Obszary Zastosowania : Pająki i roboty sieciowe. Skrobaczki internetowe. Gromadzenie, filtrowanie i pobieranie informacji.
Perspektywa : Symulacja i modelowanie
Kluczowa Idea : Agent udostępnia model do symulacji dziaģaņ i interakcji autonomicznych osób w sieci.
Obszary Zastosowania : Teoria gry. Zģoŋone systemy. Systemy wieloagentowe. Programowanie ewolucyjne
Termin "bot" - skrót od robota - staģ się powszechny jako zamiennik terminu "agent". W publikacjach akademickich zwykle preferowany jest ten drugi - na przykģad agent konwersacyjny, a nie chatbot lub chatterbot - choæ są one synonimami. Lista botów jest pokazana poniŋej w nazwie zgodnie z zadaniami, które wykonują.
Nazwa(-y) botów : Opis
Chatterbots : Sģuŋą do czatowania w sieci.
Annoybots : Uŋywane do niszczenia pokojów rozmów i grup dyskusyjnych.
Spamboty : Którzy generują niepoŋądane wiadomoķci e-mail "spam") po zebraniu internetowych adresów e-mail.
Mailbots : Zarządzający i filtrującymi wiadomoķci e-mail (np. W celu sunięcia spamu).
Spiderbots : Przeszukują sieæ w celu pobrania zawartoķci do bazy danych (np. Googlebot). Do wyszukiwania silników (np. Google) jest to następnie indeksowane w pewien sposób.
Infobots : Zbierają informacje. na przykģad "Newsbots" bierają wiadomoķci; "Hotboty" znajdują najgorętsze lub najnowsze strona dla informacji; "Jobbots" zbierają informacje o pracy.
Knowbots lub Knowledgebots : Szukają konkretnej wiedzy. na przykģad "Shopbot"
Inne nazwy agentów i botów to: agenci programowi, kreatory, pająki, inteligentne roboty programistyczne, softboty i róŋne dalsze kombinacje sģów "oprogramowanie", "inteligentny", "bot" i "agent". Zamieszanie moŋe równieŋ powstaæ, poniewaŋ ludzie często przyjmują terminy z innych obszarów i przenoszą znaczenie w swoje wģasne obszary zainteresowaņ. W trakcie procesu pierwotne znaczenie tego terminu często moŋe ulec zmianie lub pomieszaniu. Na przykģad "robot" to inne okreķlenie, takie jak "agent", w którym dokģadne znaczenie jest trudne do ustalenia. Termin "robot" jest teraz mylony z terminem "bot" - wiele osób uwaŋa teraz "robot" za niekoniecznie maszynę fizyczną, poniewaŋ w ich definicji są takie rzeczy jak pająki internetowe (uŋywane w wyszukiwarkach), i konwersacyjne roboty (takie, jakie moŋna napotkaæ w tych dniach podczas dzwonienia na infolinię). Jeszcze więcej nieporozumieņ powstaje, poniewaŋ dla niektórych osób oba te mogą byæ równieŋ uwaŋane za agentów. Co moŋe takŋe powodowaæ zamieszanie z uŋyciem terminu agent, jest często związane z pojęciem "agencji", które samo w sobie moŋe mieæ wiele znaczeņ. Jednym z aspektów pojęcia agencji jest zdolnoķæ agenta do dziaģania w ķwiecie - dla ludzi wiąŋe się to z ich zdolnoķcią do dokonywania wģasnych wyborów, które będą miaģy wpģyw na ķwiat, w którym ŋyją. Znaczenie to jest ķciķle związane z znaczenie agenta, który przyjmujemy w tych ksiąŋkach. Jednak innym znaczeniem agencji jest upowaŋnienie do dziaģania w imieniu innej osoby - na przykģad biuro podróŋy jest upowaŋnione do dziaģania w imieniu swoich klientów w celu znalezienia najbardziej konkurencyjnej firmy z opcjami podróŋy. Sģownik online Merriam-Webster podaje następujące znaczenia terminu agent:
1. Który dziaģa lub wywiera moc;
a: coķ, co wytwarza lub moŋe wywoģaæ efekt: czynną lub wydajną
b: zasada chemiczna, fizyczna lub biologicznie czynna;
3. ķrodek lub narzędzie, za pomocą którego prowadząca inteligencja osiąga wynik;
4. ten, kto jest upowaŋniony do dziaģania w imieniu lub w miejsce innego: jak
a: przedstawiciel, emisariusz lub urzędnik rządu < agent korony > < agent federalny >
b: jeden zaangaŋowany w tajne dziaģania (jako szpiegostwo): szpieg
c: przedstawiciel handlowy (jako sportowiec lub artysta) < a theatrical agent >;
5. aplikacja komputerowa przeznaczona do automatyzacji niektórych zadaņ (takich jak zbieranie informacji online).
Czwarte znaczenie agenta odnosi się do znaczenia agenta często uŋywanej w ogólnym języku angielskim, takiej jak uŋywane w popularnych zwrotach "agent ubezpieczeniowy", "agent modelujący", "agent reklamowy", "tajny agent" i "agent sportowy". To moŋe wywoģaæ najwięcej zamieszania, poniewaŋ róŋni się od znaczenia agenta przyjętego i nas (co jest bardziej związane z piątym znaczeniem). Wszystkie te podobne, ale nieco inne znaczenia wywodzą się z podstawowej koncepcji "agenta". Najlepiej moŋna to zrozumieæ, zauwaŋając, ŋe agent lub system zorientowany na agenta jest analogiczny do czģowieka w prawdziwym ŋyciu. Biorąc pod uwagę tę analogię, moŋemy dokonaæ porównania między zorientowanymi na agentów systemami, które projektujemy, a atrybutami ludzi w prawdziwym ŋyciu. Ludzie podejmują wģasne decyzje, istnieją w nich, wchodzą w interakcję z otaczającym je ķrodowiskiem i wpģywają na nie. Podobnie, celem projektantów agentów jest wyposaŋenie ich systemów zorientowanych na agenta podobnymi zdolnoķciami decyzyjnymi i podobną zdolnoķcią do interakcji i wpģywania na ķrodowisko. W tym ķwietle róŋne znaczenia wymienione w definicji sģownika są powiązane ze sobą za pomocą podstawowej analogii podmiotu, który ma zdolnoķæ dziaģania dla siebie, lub w imieniu innego, lub z moŋliwoķcią wywoģania efektu, z niektórymi moŋliwoķci czģowieka. Agent istnieje (znajduje się) w ķrodowisku i jest w stanie wyczuwaæ, poruszaæ się i wpģywaæ na to ķrodowisko, podejmując wģasne decyzje, które mają wpģyw na przyszģe zdarzenia. Agent jest analogiczny do osoby w prawdziwym ŋyciu, posiadającej pewne zdolnoķci danej osoby. Z punktu widzenia sztucznej inteligencji kluczową ideą jest to, ŋe agent jest ucieleķniony (tj. Usytuowany) w ķrodowisku. Franklin i Graesser definiują autonomicznego agenta jako "system usytuowany wewnątrz i częķæ ķrodowiska, które wyczuwa to ķrodowisko i dziaģa na nie, z biegiem czasu, w dąŋeniu do wģasnej agendy i aby osiągnąæ to, co wyczuwa w przyszģoķæ". Na przykģad agent oparty na grach znajduje się w ķrodowisku wirtualnej gry, podczas gdy roboty są zlokalizowane w rzeczywistym (lub prawdopodobnie symulowanym) ķrodowisku. Agent postrzega ķrodowisko za pomocą czujników (rzeczywistych lub wirtualnych) i dziaģa na nie za pomocą siģowników (ponownie, rzeczywistych lub wirtualnych). Znaczenie terminu "agent" moŋe jednak zmieniæ nacisk, gdy stosowana jest alternatywna perspektywa, co moŋe prowadziæ do zamieszania. Ludzie często będą równieŋ uŋywaæ definicji, którą znają z wģasnego tģa i zģa. Na przykģad, przetwarzanie rozproszone, przetwarzanie w Internecie i symulacja oraz modelowanie zapewniają trzy dalsze perspektywy definiowania, czym jest "agent". W sensie przetwarzania rozproszonego agenty są autonomicznymi procesami programowymi lub wątkami, w których waŋne są atrybuty mobilnoķci i autonomii. W rozumieniu agentów internetowych, pojęcie agencja jest kryterium nadrzędnym, tj. agenci dziaģają w imieniu kogoķ (tak jak robi to biuro podróŋy, udzielając pomocy w organizowaniu podróŋy w naszym imieniu, gdy nie mamy wiedzy, ani ochoty, ani czasu, aby to zrobiæ sami ). W symulacji i modelowaniu model oparty na agentach (ABM) to model obliczeniowy, którego celem jest symulacja dziaģaņ i interakcji autonomicznych jednostek w sieci lub ķrodowisku, a tym samym ocena ich wpģywu na system jako caģoķæ
Projektowanie zorientowane na agenta a projektowanie zorientowane na obiekt
Czym róŋni się projektowanie zorientowane na agentów od projektowania obiektowego? Aby odpowiedzieæ na to pytanie, najpierw musimy zbadaæ, co to znaczy, aby projekt systemu byģ zorientowany obiektowo. Programowanie obiektowe (OOP) jest obecnie gģównym paradygmatem programowania obsģugiwanym przez większoķæ języków programowania. "Obiekt" to encja oprogramowania, która jest abstrakcją osoby, miejsca lub rzeczy w realnym ķwiecie. Obiekty są zwykle powiązane z rzeczownikami, które pojawiają się w wymaganiach systemowych i są ogólnie definiowane przy uŋyciu klasy. Celem zajęæ jest scalenie wszystkich danych i procedur (zwanych "metodami") w jednym miejscu. Przedmiot skģada się z: toŋsamoķci, która pozwala na jednoznaczną identyfikację przedmiotu - na przykģad atrybuty takie jak imię i nazwisko, data urodzenia, miejsce urodzenia mogą jednoznacznie identyfikowaæ osobę; stany, takie jak "door = open" lub "switch = on"; i zachowanie, takie jak "wyķlij wiadomoķæ" lub "otwarte drzwi" (są one powiązane z czasownikami
+ rzeczownikami w wymaganiach systemowych). Jakie wģaķciwoķci potrzebuje system, aby byģ zorientowany na obiekt? Niektóre definicje stwierdzają, ŋe tylko wymagane są abstrakcje i enkapsulacja wģaķciwoķci. Inne definicje stwierdzają, ŋe wymagane są równieŋ dalsze wģaķciwoķci: dziedziczenie, polimorfizm,
wiązanie dynamiczne i trwaģoķæ.
Opis : Wģaķciwoķci
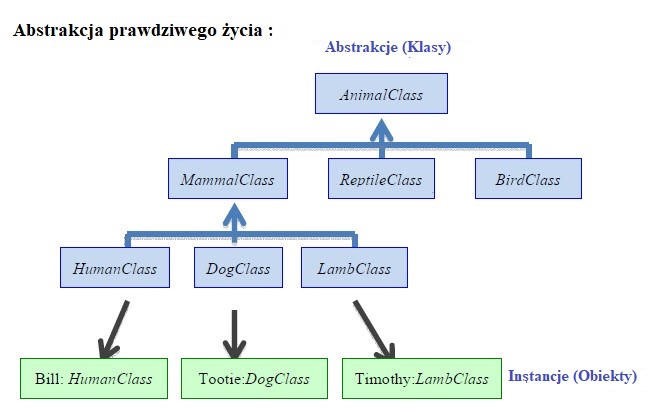
Abstrakcja : Obiekty oprogramowania to wirtualne reprezentacje obiektów ķwiata rzeczywistego. Na przykģad klasa HumanClass moŋe byæ abstrakcją ludzi w prawdziwym ķwiecie. Moŋemy uwaŋaæ klasę za definiującą analogiczny związek między nią a ludžmi w prawdziwym ķwiecie.
Enkapsulacji : Obiekty obejmują wszystkie dane i metody związane z klasą, a dostęp do nich jest dozwolony tylko poprzez ķciķle wymuszony interfejs, który definiuje to, co jest widoczne dla innych klas,pozostaģa częķæ pozostaje ukryta (zwana "ukrywaniem informacji"). Na przykģad klasa HumanClass moŋe mieæ metodę talk (), której kod okreķla dokģadnie, co i jak mówiosiągnięty. Jednak kaŋdy, kto chce wykonaæ metodę talk () nie jest zainteresowany tym, w jaki sposób mówienie zostaģo osiągnięte.
Dziedziczenie : Projektant moŋe zdefiniowaæ podklasy, które są specjalizacjami klas nadrzędnych. Podklasy dziedziczą atrybuty i zachowanie swoich klas nadrzędnych, ale mają dodatkową funkcjonalnoķæ. Na przykģad HumanClass dziedziczy wģaķciwoķci swojej macierzystej MammalClass, która z kolei dziedziczy wģaķciwoķci od rodzica AnimalClass.
Polimorfizm : To dosģownie oznacza "wiele form". Metoda o tej samej nazwie zdefiniowana przez klasę nadrzędną moŋe przyjmowaæ róŋne formy podczas wykonywania w zaleŋnoķci od definicji podklasy. Na przykģad, MammalClass moŋe mieæ metodę talk () - spowoduje to wykonanie róŋnych procedur dlaobiekt naleŋący do HumanClass w porównaniu do obiektów naleŋących do DogClass lub LambClass (ten pierwszy moŋe zacząæ czatowaæ, podczas gdy drugi moŋe zacząæ szczekaæ lub beczeæ).
Dynamiczne wiązanie : Okreķla, która metoda jest wywoģywana w ķrodowisku wykonawczym. Na przykģad, jeķli d jest obiektem klasy DogClass, wtedy odpowiednia metoda do jej aktualnej klasy zostanie wywoģana w czasie wykonywania, gdy d.talk () jest wykonany. (Szczekanie zostanie stworzone zamiast czatowania lub beczenia).
Persistence : Obiekty i klasy obiektów pozostają, dopóki nie zostaną jawnie usunięte, nawet po ich zakoņczeniu wykonania.
Rysunek poniŋszy ilustruje, w jaki sposób obiekty są abstrakcjami dla podmiotów w prawdziwym ŋyciu. Są przedstawione trzy obiekty - Bill, który jest instancją HumanClass, Tooty, który jest instancją klasy DogClass i Timothy, która jest instancją LambClass. (Obiekty są równieŋ nazywane "instancjami" danej klasy).

Czym róŋni się agent od obiektów? Wooldridge zapewnia następującą odpowiedž:
• Agenci mają większy stopieņ autonomii niŋ obiekty.
• Obiekty nie mają kontroli nad tym, kiedy są wykonywane, podczas gdy agenci decydują samodzielnie, czy wykonaæ jakąķ akcję. Innymi sģowy, obiekty wywoģują metody innych obiektów, podczas gdy agenty proszą innych agentów o wykonanie niektórych akcji.
• Agenci są zdolni do zachowania elastycznego (reaktywnego, proaktywnego, spoģecznego), podczas gdy obiekty nie okreķlają takich zachowaņ.
• System wieloagentowy jest z natury wielowątkowy - zakģada się, ŋe kaŋdy agent ma co najmniej jeden wątek kontroli.
Moŋemy przyjrzeæ się dwóm przykģadowym zadaniom, aby dokģadniej zilustrowaæ rozróŋnienie między agentami i obiektami: zadanie 1, czyszczenie podģogi w kuchni; i zadanie 2, pranie. Jakie są zorientowane na klienta i obiektowe rozwiązania tych dwóch zadaņ? Krótka odpowiedž brzmi, ŋe dla ŋadnego z zadaņ nie istnieje rozwiązanie caģkowicie obiektowe, poniewaŋ musimy uŋyæ agenta, aby wykonaæ zadania. W przypadku zadania 1 osoba czyszcząca podģogę moŋe byæ uwaŋana za przedstawiciela. W przypadku rozwiązania obiektowego tę osobę moŋna uznaæ za analogiczną do twórcy oprogramowania - podejmie on decyzje o tym, kiedy rozpocząæ czyszczenie, i wybierze odpowiednie narzędzia (przedmioty) oraz sposób ich uŋycia. Sam wybierze najbardziej odpowiednie ustawienia - odpowiadają one parametrom, które programista wybiera podczas pisania kodu (np. Stan, metody i argumenty przekazywane metodom). Niektóre przykģadowe obiekty to: miotģa - jej kierunek uŋycia, prędkoķæ i częstotliwoķæ przeciągnięæ; wiadro - ile wody, jej temperatura, rozmiar wiadra; lub odkurzacz - ustawienie mocy, ustawienie dywanu lub twardej posadzki, jej kierunek uŋytkowania i tak dalej. W przeciwieņstwie do tego, jednym z moŋliwych rozwiązaņ zorientowanych na agentów jest sprawienie, by robot wykonaģ zadanie - na przykģad zrobotyzowany odkurzacz (patrz zdjęcie po prawej). W przeciwieņstwie do rozwiązania obiektowego, robot dziaģa sam, a nie ktoķ inny. Sam decyduje, gdzie, kiedy i jak to zrobiæ. Na ryzyko antropomorfizacji, co jest oczywiķcie maszyną, moŋemy
wziąæ pod uwagę samego robota, który podejmuje decyzje, takie jak: "Nie muszę tego teraz robiæ - zrobię to jutro"; "Koņczą mi się moce - lepiej się ģaduję ponownie"; "Podģoga jest trochę brudna - lepiej ją zmoczyæ"; "Utknąģem - lepiej poprosiæ o pomoc". W przypadku zadania 2, obiektowe rozwiązanie polega na tym, aby czynnik ludzki uŋywaģ pralki do prania odzieŋy. Pralka ma wiele ustawieņ, które czģowiek moŋe wybraæ. W większoķci przypadków dosģownie nie wie, jak dziaģa pralka - jej dziaģania są ukryte przed nim. Po naciķnięciu przycisku start (to jest analogicznie do rozpoczęcia wykonywania kodu programu), pozostaje niewiele kontroli nad tym, co dzieje się póžniej. Obiekt pralki ma metody - na przykģad szybki cykl, cykl wirowania i tak dalej. Ma takŋe stan - na przykģad czas do zakoņczenia, temperaturę i tak dalej. W przeciwieņstwie do tego, czynniki ludzkie są jedynym rozwiązaniem zorientowanym na agent, dostępnym obecnie dla tego problemu. W przyszģoķci, robot domowy moŋe wykonaæ to zadanie dla ludzi. W tym przypadku z jego perspektywy moŋe podjąæ następujące decyzje: "teraz zrobię pranie dla ciebie"; "Ja sam zabiorę brudne ubrania"; "Teraz się doģaduję". Zwróæ uwagę, ŋe sģowa "ja" i "mnie" zostaģy wyróŋnione kursywą dla dwóch powyŋszych zadaņ. Ma to na celu podkreķlenie pierwszoosobowej perspektywy projektowej agenta - podejmuje decyzje z wģasnego osobistego punktu widzenia. Obiekty przeciwnie, są zaprojektowane z perspektywy trzeciej osoby, będąc przywoģywanymi zewnętrznie - wewnętrznie, nie ma pojęcia "ja". Programowanie i projektowanie obiektowe jest dominującym paradygmatem inŋynierii oprogramowania; kilka gģównych języków programowania obsģuguje obecnie programowanie zorientowane na agentów. Na przykģad Python jest wieloparadygmatem, ale nie obsģuguje programowania zorientowanego na agenta. Obecnie deweloper jest zmuszony uciekaæ się do hybrydowego projektu - za pomocą platform zorientowanych na agenta zaimplementowanych na platformie zorientowanej obiektowo. Róŋne struktury agentów omówiono w następnym rozdziale. W międzyczasie przyjrzymy się róŋnym rodzajom agentów, ich wģaķciwoķciom i rodzajom ķrodowisk, w których mogą one istnieæ.
Taksonomia autonomicznych agentów
Powszechną metodą stosowaną w badaniach naukowych jest klasyfikowanie pojęæ w taksonomię. Często są one przydatne w tworzeniu struktury uģatwiającej organizację tematu dyskusji. Wiele przykģadów moŋna podzieliæ na wiele kategorii lub istnieją one między granicami dwóch powiązanych ze sobą pojęæ. Dlatego naleŋy ostroŋnie stosowaæ klasyfikację taksonomiczną. Rysunek pokazuje taksonomię autonomicznych agentów w oparciu o taksonomię zaproponowaną przez Franklina i Graessera (1998).
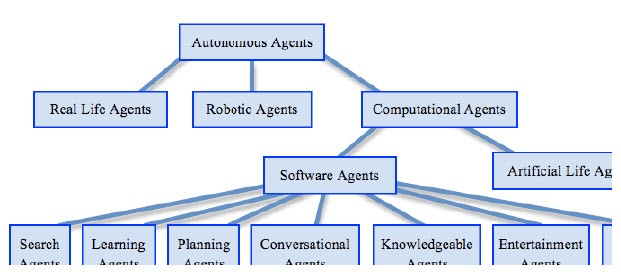
Biorąc pod uwagę powyŋsze komentarze na temat ograniczeņ klasyfikacji taksonomicznej, naleŋy podkreķliæ, ŋe nie jest to ostateczna lub wyczerpująca taksonomia. Dolny wiersz na poprzednim rysunku róŋni się od taksonomii Franklina i Graessera, która skģada się tylko z trzech podkategorii w kategorii "Agenci oprogramowania" - są to "Agenci specyficzni dla zadaņ", "Agenci rozrywki" i "Wirusy". Te ostatnie nie są uwzględnione - chociaŋ wirusy komputerowe są formą agenta, nie są dobroczynne (to jest,zwykle szkodliwe) i są lepiej traktowane jako osobny przedmiot. "Agent specyficzny dla zadaņ" zostaģ rozszerzony w celu dokģadniejszego zbadania poszczególnych zadaņ, takich jak przetwarzanie języka ludzkiego i zbieranie informacji. Zauwaŋ, ŋe ostatni wiersz nie jest w ŋadnym wypadku wyczerpujący - kolejne kategorie agentów obejmują wirtualnych ludzi, interakcje międzyludzkie, mobilne i wszechobecne czynniki. Inna kategoria agentów, o której często się mówi, to "Inteligentni agenci". Niestety, ten termin jest często naduŋywany. Często system jest oznaczony jako inteligentny agent z niewielkim uzasadnieniem, dlaczego jest "inteligentny". Ocena moŋe następnie polegaæ na pomiarze, jak dobrze agent wykonuje zadania, dla których zostaģ zaprojektowany. To, czy osiągi są wystarczające, aby agent zostaģ zaklasyfikowany jako "inteligentny", zaleŋy od obserwatora, który obserwuje wykonywane zadanie. Omówimy teraz kaŋdy z typów agentów, aby pomóc w wyjaķnieniu definicji. "Real Life Agents" oznacza ŋywe zwierzęta, takie jak ssaki, gady, ryby, ptaki, owady i tak dalej. Franklin i Graesser uŋyli terminu "agenci biologiczni" zamiast tej kategorii, ale moŋna to pomyliæ z czynnikami biologicznymi, którymi są toksyny, choroby zakažne (takie jak wirusy w prawdziwym ŋyciu; na przykģad Denga Fever i Ebola) i bakterii (takich jak Anthrax i Plague). "Sztuczni agenci ŋycia" to agenci, którzy tworzą sztuczną formę ŋycia lub symulują prawdziwą istotę ŋyciową. Robotyczne mechanizmy mechaniczne (zamiast robotów programistycznych) są równieŋ agentami z punktu widzenia sztucznej inteligencji - na przykģad roboty uŋywane do misji Mars Rover, takie jak Spirit i Opportunity, dziaģają jako "agenci" dla NASA na Marsie, ale mają takŋe pewien stopieņ autonomii, aby dziaģaæ samodzielnie. Agenci oprogramowania, którzy istnieją wyģącznie w ķrodowisku wirtualnym lub opartym na oprogramowaniu. Moŋna je podzieliæ na wiele róŋnych kategorii - na przykģad agentów przetwarzających język ludzki, agentów zbierających informacje, agentów posiadających wiedzę, agentów, którzy uczą się i agentów przeznaczonych do celów rozrywkowych, takich jak uŋywane w grach komputerowych i na specjalne potrzeby efekty w filmach. "Human Agents" naturalnie naleŋą do kategorii "Real Life Agents". Murch i Johnson (1999) wskazują, ŋe obecnie ludzie są agentami, którzy są najlepsi w wykonywaniu najbardziej zģoŋonych zadaņ na ķwiecie i będą tak przez jakiķ czas. Ludzie agenci o specjalistycznych umiejętnoķciach (np. biuro podróŋy lub agent piģki noŋnej lub gwiazda filmowa) ķwiadczą usģugi w imieniu innych ludzi, którzy nie byliby w stanie uzyskaæ tej usģugi w inny sposób, lub którzy nie mają czas lub umiejętnoķci, aby zrobiæ to samemu. Mają kontakty, aby ķwiadczyæ tę usģugę, mają dostęp do odpowiednich informacji i często mogą ķwiadczyæ tę usģugę za uģamek kosztów. Jednak ludzie są ograniczeni liczbą godzin pracy w tygodniu; w ciągu 12 godzin mogą pracowaæ maksymalnie 84 godziny w tygodniu, a przy tym szybko wypalą! Dlatego istnieje moŋliwoķæ, aby agenci komputerowi mogli nam przezwycięŋyæ te ograniczenia. Próbując sklasyfikowaæ, czym jest agent, moŋemy równieŋ zadaæ przeciwne pytanie - "Czym nie są agenci?" Nwana (1996) zauwaŋyģ, ŋe Minsky w swojej ksiąŋce "Towarzystwo Umysģu" uŋyģ tego terminu do sformuģowania swojej teorii ludzkiej inteligencji:
…aby wyjaķniæ umysģ, musimy pokazaæ, jak umysģy są budowane z bezmyķlnych rzeczy, z częķci, które są znacznie mniejsze i prostsze niŋ wszystko, co uwaŋalibyķmy za mądre …Ale jakie mogģyby byæ te prostsze cząstki -" agenci ", którzy tworzą nasz umysģy? To jest temat naszej ksiąŋki… " (Minsky)
Nazwa definiuje agentów w taki sposób, ŋe pojęcie Minsky′ego o agencie nie speģnia jej kryteriów. Uŋywa trzech minimalnych cech, by wyprowadziæ cztery typy agentów w oparciu o typologię pokazaną na poniŋszym rysunku : wspóģpracujący agent, wspóģpracujący agent uczący się, agenci interfejsu i prawdziwi inteligentni agenci. Ta ostatnia rozszerza tę listę, aby uwzględniæ trzy dalsze typy: agentów informacji / Internetu, agentów reaktywnych i agentów hybrydowych
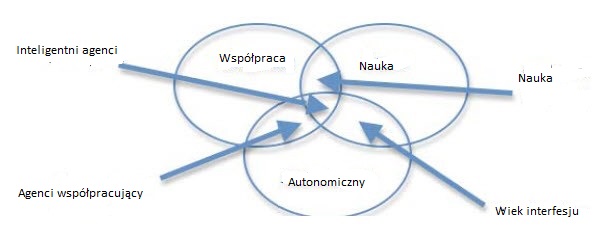
Jej definicja mówi, ŋe agenci dziaģają bardziej na poziomie wiedzy niŋ na poziomie symboli i wymagają "komunikacji na wysokim poziomie" [jej sģów] (w przeciwieņstwie do "komunikatów niskiego poziomu" uŋywanych w systemach rozproszonych). Dlatego agenci Minsky′ego, systemy eksperckie, większoķæ opartych na wiedzy aplikacji systemowych i moduģy w aplikacjach rozproszonych nie kwalifikują się. Ani agenci ŋóģwi nie uŋywali języka programowania NetLogo, języka zaprojektowanego po jej opublikowaniu. Termin proto-agent jest często uŋywany w modelowaniu agentów i symulacji w celu objęcia agentów "niŋszego poziomu", takich jak agenci ŋóģwi w NetLogo, aby odróŋniæ je od agentów, do których naleŋą. Slniejsze definicje, takie jak Nwana. Póģnoc i Macal definiują proto-agenta jako jednostkę uŋywaną w modelowaniu i symulacji, która zachowuje zestaw wģaķciwoķci i zachowaņ, które nie muszą wykazywaæ zachowania uczenia się. Jeķli uzyskają oni zdolnoķæ uczenia się, stają się agentami. Do celów tych ksiąŋek, zamiast dokonywania arbitralnego rozróŋnienia między proto-agentem i agenta, uwaŋamy, ŋe wszystkie powyŋsze przykģady mają pewien stopieņ agresywnoķci zdefiniowany w podrozdziale 2.1. Dlatego uŋyjemy terminu agent zamiast raczej proto-agenta, poniewaŋ w rzeczywistoķci obecnie nie istnieje ŋaden system zorientowany na agenta, który osiągnąģ jeszcze peģny zestaw wģaķciwoķci zgodnie z definicją Nwana lub zestaw poŋądanych wģaķciwoķci opisanych bardziej szczegóģowo w następnym dokumencie.
Poŋądane wģaķciwoķci agentów
Pojęcie agenta moŋna zdefiniowaæ, wyszczególniając poŋądane wģaķciwoķci, które chcemy wystawiaæ agentom. Russell i Norvig zidentyfikowali pierwsze cztery wģaķciwoķci w tabeli jako kluczowe atrybuty agenta z perspektywy sztucznej inteligencji: autonomię (dziaģanie we wģasnym imieniu bez interwencji); reaktywnoķæ (reagowanie na bodžce); proaktywnoķæ (bycie proaktywnym); i zdolnoķci spoģeczne (w stanie komunikowaæ się w jakiķ sposób z innymi agentami). Autonomia jest w szczególnoķci waŋną kluczową cechą - w rzeczywistoķci termin "niezaleŋni agenci" jest często uŋywany w literaturze jako synonim systemów zorientowanych na agenta, aby podkreķliæ ten punkt. Szeķæ wģaķciwoķci w Tabeli 2 często okreķla się jako naleŋące do sģabego agenta, dodając zdolnoķæ do wyznaczania celów i ciągģoķci czasowej jako dwa dalsze kluczowe atrybuty. Wģaķciwoķci w tabeli 3 są związane z silnym pojęciem ķrodka, poniewaŋ są to wģaķciwoķci zwykle stosowane u ludzi. Taskin i in. wymieņ trzy dalsze wģaķciwoķci w tabeli , które są kombinacjami podstawowych wģaķciwoķci: koordynacja, umiejętnoķæ wspóģpracy i zdolnoķæ planowania.
Wģaķciwoķæ : Opis
Autonomia : Agent sprawuje kontrolę nad wģasnymi dziaģaniami; dziaģa asynchronicznie.
Reaktywnoķæ : Agent reaguje w odpowiednim czasie na zmiany w ķrodowisku i sam decyduje o tym kiedy dziaģaæ.
Proaktywnoķæ : Agent reaguje w najlepszy moŋliwy sposób na moŋliwe przyszģe dziaģania, które są oczekiwane zdarzyæ.
Zdolnoķci spoģeczne (Zdolnoķæ do porozumienia się) : Agent ma moŋliwoķæ komunikowania się w sposób zģoŋony z innymi agentami, w tym ludzi, w celu uzyskania informacji lub uzyskania pomocy w osiąganiu celów.
Umiejętnoķæ wyznaczania celów : Agent ma cel.
Czasowa ciągģoķæ : Agent jest ciągle dziaģającym procesem.
Wģaķciwoķæ : Opis
Mobilnoķæ : Agent moŋe się przemieszczaæ w swoim otoczeniu.
Adaptacyjnoķæ : Agent ma zdolnoķæ uczenia się. Jest w stanie zmieniæ swoje zachowanie na podstawie swojego poprzedniego doķwiadczenia.
Ŋyczliwoķæ : Agent wykonuje swoje dziaģania dla dobra innych.
Racjonalnoķæ : Agent podejmuje racjonalne, ķwiadome decyzje.
Umiejętnoķæ wspóģpracy : Agent wykonuje wspóģpracę z innymi agentami lub ludžmi w celu wykonania swoich zadaņ.
Elastycznoķæ : Agent jest w stanie dynamicznie reagowaæ na zewnętrzny stan ķrodowiska wybór wģasnych dziaģaņ.
Osobowoķæ : Agent ma dobrze zdefiniowaną, wiarygodną osobowoķæ i stan emocjonalny.
Zdolnoķci poznawcze : Agent jest w stanie jednoznacznie uzasadniæ wģasne intencje lub stan i plany innych agentów.
Wszechstronnoķæ : Agent moŋe mieæ wiele bramek jednoczeķnie.
Wiarygodnoķæ : Agent nie będzie ķwiadomie przekazywaæ faģszywych informacji.
Wytrwaģoķæ : Agent będzie nieprzerwanie dąŋyæ do realizacji jakiegokolwiek planu.
Wģaķciwoķæ : Opis
Koordynacja : Agent ma moŋliwoķæ zarządzania zasobami, gdy trzeba je rozprowadziæ lub zsynchronizowaæ.
Wspóģpraca : Agent wykorzystuje protokoģy interakcji poza prostymi dialogami, na przykģad negocjacje dotyczące znalezienia wspólnego stanowiska, rozwiązywania konfliktów lub dystrybucji zadaņ
Umiejętnoķæ planowania : Agent ma zdolnoķæ aktywnego planowania i koordynowania swoich reaktywnych zachowaņ w obecnoķci dynamicznego ķrodowiska stworzonego przez innych agentów.
Te definicje są interesujące z filozoficznego punktu widzenia, ale ich znaczenie jest często niejasne i nieprecyzyjne. Na przykģad, jeķli ktoķ spróbuje sklasyfikowaæ istniejące systemy agentowe za pomocą tych etykiet, okaŋe się, ŋe zadanie jest obarczone trudnoķciami i niespójnoķciami. Proste æwiczenie w stosowaniu tych wģaķciwoķci w celu klasyfikacji przykģadów systemów zorientowanych na agenta ujawni niektóre niedociągnięcia takiego systemu klasyfikacji. Na przykģad Googlebot, robot sieciowy uŋywany przez Google do tworzenia indeksu sieci, ma autonomię wģaķciwoķci, reaktywnoķæ, ciągģoķæ czasowa, mobilnoķæ i ŋyczliwoķæ, ale to, czy przejawia inne wģaķciwoķci, jest niejasne - na przykģad nie ma wģaķciwoķci racjonalnoķci (podejmowane przez nią ķwiadomie decyzje nie są jego wģasnymi). Dlatego wykazuje zarówno sģabe, jak i silne wģaķciwoķci, ale moŋe byæ interpretowany jako nie. Chatbot z drugiej strony wykazuje wszystkie te wģaķciwoķci w róŋnych mocach. Byæ moŋe najdziwniejsza z wģaķciwoķci jest ŋyczliwoķcią.
Nie jest jasne, dlaczego jest to niezbędna wģaķciwoķæ systemu zorientowanego na agenta - wirusy komputerowe wyražnie nie są ŋyczliwe; interakcja pomiędzy konkurującymi wieloma agentami moŋe równieŋ nie byæ dobroczynna, ale moŋe prowadziæ do stabilnoķci w caģym systemie. Ponadto, podstawą wielu z tych wģaķciwoķci jest ukryte zaģoŋenie, ŋe agent ma pewien stopieņ ķwiadomoķci - na przykģad, ŋe ķwiadomie podejmuje racjonalne decyzje, ķwiadomie wyznacza cele i planuje je osiągnąæ, i ŋe nie komunikuje ķwiadomie informacje i tak dalej. W związku z tym moŋe nie byæ moŋliwe zbudowanie agenta obliczeniowego z tymi wģaķciwoķciami bez uprzedniego posiadania zdolnoķci, które posiada czģowiek z peģną ķwiadomoķcią. Drugą wadą jest to, ŋe są to atrybuty jakoķciowe, a nie iloķciowe. Inŋynier wolaģby mieæ bardziej precyzyjnie zdefiniowane atrybuty - na przykģad, co to znaczy, ŋe agent jest racjonalny? Jednak klasyfikacja ma zalety w tym sensie, ŋe podkreķla niektóre z atrybutów, które moŋemy zaprojektowaæ w naszych systemach. Na przykģad, moŋemy wykorzystaæ wģaķciwoķci od 1 do 3 jako punkt wyjķcia do zasugerowania pewnych minimalnych zasad projektowania, które system musi przestrzegaæ, zanim będzie moŋna go zastosowaæ uwaŋany za system zorientowany na agenta w następujący sposób:
System zorientowany na agenta powinien byæ zgodny z następującymi celami projektowymi agenta - jest autonomiczny; jest reaktywny; jest proaktywny (przynajmniej):
Zasada projektowania 2.1: System zorientowany na agenta powinien byæ autonomiczny.
Zasada projektowania 2.2: System zorientowany na agenta powinien byæ reaktywny.
Zasada projektowania 2.3: System zorientowany na agenta powinien byæ proaktywny
Jednak zamiast iķæ dalej i zasugerowaæ listę žle zdefiniowanych wģaķciwoķci jako definiujących stopnie inteligencji (to znaczy, czy są sģabe lub silne), te ksiąŋki przyjmują inne podejķcie ukierunkowane na projekt. W częķci 10 opisano róŋne poŋądane cele projektowe, aby zapewniæ "najsilniejsze" pojęcie agenta: wiedzę, inteligencję, racjonalnoķæ, samoķwiadomoķæ, ķwiadomoķæ i zamyķlenie (tj. Czynnik, który myķli tak jak my). Zamiast mówiæ, ŋe sztuczna inteligencja musi mieæ te wģaķciwoķci, aby moŋna byģo je uznaæ za "inteligentne", proponujemy kilka celów projektowych - wģaķciwoķci, które my, jako projektanci, ŋyczymy naszemu systemowi. Uwaŋamy, ŋe aby agent mógģ myķleæ, musi najpierw znaæ ķrodowisko, w którym się znajduje, oraz wiedzę o tym, jak dziaģaæ w jego obrębie, aby utrzymaæ przewagę konkurencyjną (pod względem zdolnoķci do przetrwania w porównaniu z innymi agentami). Agent musi równieŋ byæ inteligentny, tzn. Byæ w stanie zrozumieæ znaczenie swojej wiedzy, byæ w stanie wyciągnąæ dalsze wnioski, aby dodaæ do swojej wiedzy i dziaģaæ w "inteligentny" sposób, aby zareagowaæ na wszystko, co dzieje się w jego otoczeniu lub cokolwiek moŋe się wydarzyæ (ponownie w celu utrzymania lub poprawy swojej kondycji). Samoķwiadomoķæ, ķwiadomoķæ i zamyķlenie odpowiadają cechom ludzkim, które wszyscy znamy, ale brakuje nam prawdziwego zrozumienia tego, jak się one mają lub tego, w jaki sposób moŋemy opracowaæ sztuczne systemy, które mają te wģaķciwoķci. Te rozdziaģy będą stanowiæ scenariusz dla wyjaķnienia tej opartej na projektach perspektywy sztucznej inteligencji. Pozostaģa częķæ tego rozdziaģu zajmie się tym, jakie są ķrodowiska i podkreķli ich znaczenie dla projektowania systemów sztucznej inteligencji.
Co to jest ķrodowisko?
Moŋemy postrzegaæ ķrodowisko jako wszystko, co otacza agenta, ale które róŋni się od agenta i jego zachowania. Ķrodowisko to wszystko na ķwiecie, które co otacza agenta, co nie jest częķcią samego agenta. W tym miejscu agent "ŋyje" lub dziaģa i dostarcza agentowi coķ, co moŋna wyczuæ i gdzie się przemieszcza. Ķrodowisko jest analogiczne do ķwiata w prawdziwym ŋyciu, ma pewne jego wģaķciwoķci. Ķrodowisko to nie to samo, co termin "nisza ekologiczna", który jest uŋywany do opisania, w jaki sposób organizm lub ludnoķæ reaguje na dystrybucję zasobów i konkurentów i zaleŋy nie tylko od tego, gdzie organizm ŋyje i co go otacza, ale takŋe od tego, co robi. . Odum (1959) uŋywa analogii, ŋe siedliskiem organizmu jest jego "adres" lub lokalizacja, podczas gdy niszą jest jego "zawód". Na przykģad dąb moŋe byæ siedliskiem lasów dębowych - moŋe to byæ "Dąb, Nowy Las", a tym, co robi dąb, i jak zarabia, reagując na dystrybucję zasobów i konkurentów, jest jego nisza. Zamiast tego wolimy uŋywaæ terminu "ķrodowisko", poniewaŋ bardziej odpowiada to pojęciom znanym w informatyce (takim jak termin "ķrodowisko wirtualne" -
Ponadto rozróŋnienie między agentem a jego niszą ekologiczną jest związane z jego zachowaniem, z tym, ŋe oba są ze sobą powiązane, to znaczy niszą, w której znajduje się agent, który dyktuje jej zachowanie, a jego zachowanie w pewnym stopniu okreķla jego niszę. Z drugiej strony, ķrodowisko jest wyražnie odróŋnialne od agenta, jako wszystko w bezpoķrednim ķwiecie lub w ķrodowisku agenta, który nie jest częķcią samego agenta. Chcielibyķmy równieŋ przyjąæ perspektywę projektowania z perspektywy pierwszoosobowej, aby bezpoķrednio opisaæ zachowanie agenta w oparciu o punkt widzenia samego agenta, w przeciwieņstwie do perspektywy obserwatora z perspektywy trzeciej osoby. Innymi sģowy, chcemy zaprojektowaæ zachowanie jako funkcję samego agenta, poniewaŋ oddziaģuje on na swoje otoczenie (które moŋe zawieraæ inne czynniki), a nie musi go projektowaæ w odniesieniu do swojej niszy. Ķrodowisko moŋe mieæ róŋne atrybuty od punkt widzenia agenta. Są one wymienione w kolejnoķci rosnącej zģoŋonoķci w tabeli:
Obserwowalne i częķciowo obserwowalne.
Agenta moŋna uznaæ za agenta tylko wtedy, gdy ma on zdolnoķæ obserwowania swojego ķrodowiska (i odwrotnie, samo ķrodowisko musi byæ zatem moŋliwe do zaobserwowania). W niektórych przypadkach, zazwyczaj w prostych ķrodowiskach lub ķrodowiskach generowanych przez oprogramowanie, caģe ķrodowisko moŋe byæ obserwowalne. Jednak ķrodowisko moŋe byæ tylko częķciowo obserwowalne.
Deterministyczne, stochastyczne i strategiczne.
W peģni deterministyczne ķrodowisko to takie, w którym kaŋdy przyszģy stan ķrodowiska moŋe byæ caģkowicie okreķlony z poprzedniego stanu i dziaģaņ agenta. Ķrodowisko jest stochastyczne, jeķli występuje jakiķ element niepewnoķci lub wpģyw zewnętrzny. Zwróæ uwagę, ŋe jeķli deterministyczne ķrodowisko jest tylko częķciowo obserwowalne dla agenta, to wygląda na stochastyczne z punktu widzenia agenta. Ķrodowisko strategiczne jest w peģni zdeterminowane przez stan poprzedzający w poģączeniu z dziaģaniami wielu agentów.
Epizodyczne i sekwencyjne.
Ķrodowisko zadaņ jest epizodyczne, jeķli kaŋde zadanie agenta nie opiera się na wczeķniejszej wydajnoķci lub nie moŋe wpģywaæ na przyszģe wyniki. Jeķli nie, to jest sekwencyjne. Statyczny i dynamiczny. Ķrodowisko statyczne się nie zmienia. W dynamicznym ķrodowisku, jeķli agent nie reaguje na zmianę, jest to uwaŋane za wybór, aby nie robiæ nic.
Dyskretne i ciągģe.
Dyskretne ķrodowisko ma skoņczoną liczbę moŋliwych stanów, podczas gdy liczba stanów w ciągģym ķrodowisku jest nieskoņczona.
Pojedynczy agent i wiele agentów .
Ķrodowisko z wieloma agentami, agent dziaģający wspólnie lub konkurencyjnie z innym agentem. Jeķli tak nie jest, to z perspektywy agenta, inni agenci mogą byæ postrzegani jako częķæ ķrodowiska, które zachowuje się stochastycznie.
Analogia otoczenia podobnego do ķwiata, w którym ŋyjemy, jest często poķrednio stosowana, gdy termin "ķrodowisko" jest uŋywany w szczególnoķci w informatyce i sztucznej inteligencji. Agent moŋe eksplorowaæ, zagubiæ się i mapowaæ ķrodowisko wirtualnego komputera tak samo, jak czģowiek w ķrodowisku realnym - zdolnoķæ obserwacji / odczuwania i poruszania się po ķrodowisku są kluczowymi wģaķciwoķciami obu. Jednak ķrodowiska komputerów wirtualnych nie muszą byæ ograniczone do interpretacji geograficznej, w której fizyczna lokalizacja jest związana z okreķloną pozycją w ķrodowisku. Fizykę ķrodowiska wirtualnego moŋna zmieniæ tak, aby pasowaģa do celów projektanta. Na przykģad awatar (komputerowo generowany agent reprezentujący operatora) moŋe lataæ w wirtualnych ķrodowiskach, takich jak Second Life, aw niektórych grach komputerowych awatary i boty mogą się teleportowaæ, z których oba są niemoŋliwe dla ludzi w prawdziwym ŋyciu. Alternatywnie ķrodowisko moŋe byæ reprezentacją czegoķ, co moŋe nie byæ ģatwo lub wygodnie reprezentowane geograficznie, na przykģad w sieci komputerowej, Internecie, a nawet w sieci londyņskiego metra. Ķrodowisko moŋe byæ równieŋ symulacją rzeczywistego ķrodowiska, w którym celem jest moŋliwie dokģadne symulowanie wybranych rzeczywistych wģaķciwoķci fizycznych. Problem z symulowanymi ķrodowiskami jest jednak taki, ŋe często trudno jest osiągnąæ realizm w symulacji, poniewaŋ symulacja moŋe odbiegaæ od rzeczywistoķci w nieprzewidywalny sposób.
Ķrodowiska jako przestrzenie n-wymiarowe
Istnieje wiele przypadków, w których moŋemy chcieæ reprezentowaæ ķrodowisko, które w ogóle nie ma odpowiednika geograficznego, takie jak zbiór dokumentów tekstowych w systemie wyszukiwania informacji lub dane w bazie danych, w którym to przypadku abstrakcyjna reprezentacja ķrodowiska jest wymagany. W takim przypadku dokumenty tekstowe lub wiersz w tabeli bazy danych mogą byæ reprezentowane przez krotki odpowiadające punktom w przestrzeni n-wymiarowej, przy czym kaŋdy wymiar reprezentuje jeden okreķlony atrybut (gdzie n oznacza caģkowitą liczbę atrybutów uŋytych we wszystkich krotki, które są wykreķlane w przestrzeni). Na przykģad, następujące dwie krotki, A i B, mogą byæ reprezentowane w trójwymiarowej przestrzeni, jak pokazano na rysunku poniŋej, poniewaŋ istnieją trzy atrybuty - gra, gracz i wzrost:
Krotko A: (gra: "Rugby", gracz: "Jonah Lomu", wzrost: 196)
Tuple B: (gra: "Rugby", gracz: "David Kirk", wzrost: 173)
Na osi "Gracz", "DK" oznacza miejsce reprezentujące "David Kirk"; podobnie "JL" oznacza "Jonah Lomu". Na osi "Gry", "Rugby" oznacza miejsce reprezentujące grę w rugby. Oķ "Wysokoķæ" jest ciągģym wymiarem przedstawiającym wzrost w centymetrach ≥ 0. Pozostaģe dwa wymiary są dyskretne. Dwa punkty reprezentujące krotki A i B są oznaczone czerwonymi krzyŋami. N-wymiarowa przestrzeņ, jak ilustruje to prosty przykģad, moŋe byæ wyražnie uznana za ķrodowisko: istnieje przestrzeņ, którą moŋna badaæ i mapowaæ, gdzie obiekty takie jak krotki A i B mogą mieæ lokalizacje; ruch z jednej lokalizacji do drugiej moŋe mieæ znaczenie i byæ wykreķlany za pomocą ķcieŋki; a lokalizacje mogą byæ uwaŋane za bliskie lub odlegģe od siebie. W rzeczywistoķci wszystkie ķrodowiska moŋna ģatwo przedstawiæ jako przestrzeņ n-wymiarową - poruszamy się w ķrodowisku rzeczywistego ķwiata, które moŋe byæ reprezentowane w 3D - dģugoķæ, wysokoķæ i szerokoķæ. Potrzebne są dalsze wymiary, aby opisaæ atrybuty obiektów i agentów, które moŋna znaležæ w lokalizacjach w rzeczywistym ķrodowisku 3D - ale zasadniczo te atrybuty moŋna po prostu uznaæ za dalsze wymiary w przestrzeni n-wymiarowej. Jako kolejny przykģad moŋemy spojrzeæ na większy zestaw danych, taki jak wymieniony w tabeli 2.8. Tabela zawiera zestaw krotek zawierających informacje o graczach rugby z Nowej Zelandii, zwanych All Blacks. Dane są 5-wymiarowe, poniewaŋ kaŋda krotka (wiersz w tabeli) zawiera pięæ atrybutów dotyczących kaŋdego gracza - pozycję, w której grają, ich nazwę, wysokoķæ w cm, wagę w kg i rok, w którym po raz pierwszy grali All Blacks
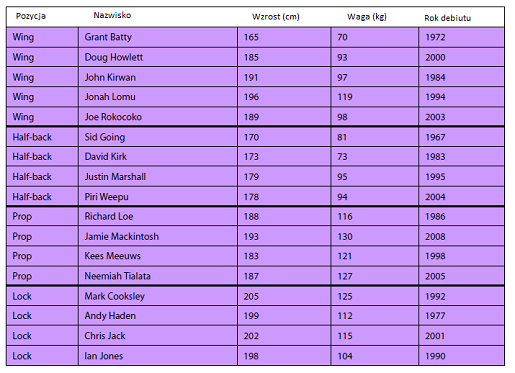
Wizualizacja danych n-wymiarowych moŋe często byæ trudna, nawet jeķli liczba wymiarów jest stosunkowo niewielka - większoķæ danych rzeczywistych jest jednak zwykle wysoce wielowymiarowa. Jeķli uŋywamy kartezjaņskiego ukģadu wspóģrzędnych, wówczas jednym z rozwiązaņ, do których moŋemy się odwoģaæ, jest uŋycie wielu wykresów (jak pokazano na lewym wykresie poniŋej). Alternatywnym rozwiązaniem jest uŋycie równolegģego ukģadu wspóģrzędnych, w którym osie są umieszczone równolegle do siebie, a pojedyncza krotka jest narysowana jako polilinia, która ģączy punkty na kaŋdej osi, które reprezentują kaŋdą wartoķæ atrybutu. Dlatego krotka w tym ķrodowisku jest reprezentowana jako linia, a nie jako pojedynczy punkt (jak pokazano na prawym wykresie rysunku)
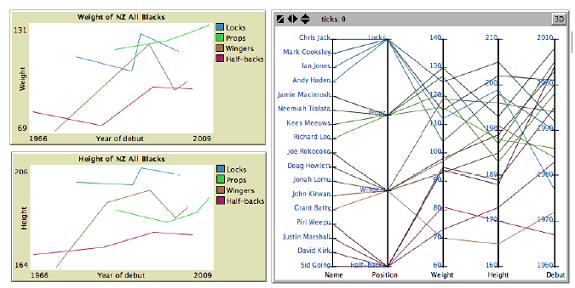
Obydwa systemy wspóģrzędnych do wizualizacji danych n-wymiarowych mają swoje wady i zalety, co widaæ na wykresach pokazanych na powyŋszym rysunku. Na przykģad, wszystkie wykresy są przydatne do pokazywania tendencji i podkreķlających wģaķciwoķci danych, takich jak obroņcy All Blacks, którzy mają tendencję do bycia krótszymi niŋ blokujący. Niemniej jednak, wspóģrzędne kartezjaņskie mają tendencję do ograniczania iloķci informacji, które moŋna przekazaæ (na przykģad dodanie nazw na lewych dziaģkach spowodowaģoby znaczny baģagan). Podobnie, równolegģy wykres wspóģrzędnych po prawej stronie jest ograniczony do okreķlonej kolejnoķci, w której wybrane są osie równolegģe, a zatem moŋe byæ trudniej wykryæ konkretny trend, jeķli dwie okreķlone osie są od siebie oddalone. Ma jednak tę zaletę, ŋe uģatwia doģączanie danych dla wszystkich wymiarów na tym samym wykresie. Wykresy pokazane na rysunku belo zostaģy utworzone przy uŋyciu NetLogo. Ten język będzie opisany bardziej szczegóģowo póžniej. Celem pokazania tego jest podkreķlenie powiązania między danymi, informacjami i otoczeniem, a takŋe podkreķlenie, ŋe istnieją róŋne sposoby wizualizacji informacji. Fabuģy skģadają się z szeregu punktów i ķcieŋek i mogą byæ uwaŋane za mapy, które w pewien sposób reprezentują aspekty ķrodowiska realnego ķwiata (jak mapa topograficzna stara się reprezentowaæ rzeczywisty ķwiat, jak moŋna to zobaczyæ w system nawigacji samochodowej, lub uŋywaæ podczas wędrówek lub orientacji). Punkty, ķcieŋki i ich relacje (takie jak bliskoķæ i dalekoķæ) i mapy, są waŋnymi pojęciami dla ķrodowisk i ich wizualizacji i będą uŋywane jako podstawowe wzorce projektowe w próbkach kodu w innych miejscach i mogą byæ uwaŋane za analogiczne do ich topograficznych odpowiedników w prawdziwe ŋycie. Moŋemy zdefiniowaæ punkt jako lokalizację w ķrodowisku lub w przestrzeni n-wymiarowej. Ķcieŋkę moŋna zdefiniowaæ jako jeden z moŋliwych sposobów, w jaki agent moŋe poruszaæ się między dwoma lub więcej punktami. Mapa jest schematyczną reprezentacją ķrodowiska lub przestrzeni n-wymiarowej. Będą one stanowiæ podstawowe elementy konstrukcyjne, które wykorzystamy w kolejnych rozdziaģach, aby zademonstrowaæ róŋne aspekty projektowania zorientowanego na agenta dla sztucznej inteligencji. Moŋemy równieŋ uwaŋaæ punkty, ķcieŋki i mapy za analogiczne do tych samych terminów uŋywanych w topologii matematycznej.
Wirtualne ķrodowiska
Wirtualne ķrodowiska to immersyjne ķwiaty online, które ludzie uŋywają odwiedzając i modyfikując awatary, lub mogą byæ ķwiatami generowanymi komputerowo, takimi jak te przedstawione w grach komputerowych lub w symulacjach (na przykģad do symulacji medycznych lub wojskowych). Inne nazwy obejmują "wirtualne ķwiaty", "zespoģowe wirtualne ķrodowiska" (CVE), "wirtualne ķrodowiska dla wielu uŋytkowników" (MUVE) i "masowo wieloosobową grę online" (MMOG). "Wirtualna wycieczka" to komputerowo wygenerowana trasa, która zapewnia wraŋenia ruchu w oglądanej przestrzeni. Istnieje wiele praktycznych zastosowaņ wirtualnego zwiedzania w takich sektorach, jak: biznes, edukacja, architektura, nauka, medycyna, robotyka, wojsko, sztuka, rozrywka i sport. Wirtualne ķrodowiska są skonfigurowane do róŋnych celów, takich jak:
• komercyjne - na przykģad Second Life (http://www.secondlife.com), które ma w peģni konfigurowalne awatary oraz wbudowany język skryptowy i budowlany, w którym uŋytkownicy wytwarzają i sprzedają produkty rzeczywiste;
• edukacja - na przykģad Forterra Systems (http://www.forterrainc.com) z domenami takimi jak szkolenia w zakresie e-learningu, szkolenia wojskowego i bezpieczeņstwa wewnętrznego oraz opieka zdrowotna;
• spoģeczny - na przykģad Kaneva (http://www.kaneva.com), który ģączy ķrodowisko wirtualne z sieciami spoģecznoķciowymi;
• rozrywka - na przykģad gry komputerowe takie jak Everquest i World of Warcraft
(http://everquest.station.sony.com/ i http://www.worldofwarcraft.com/index.xml);
• sport - na przykģad wirtualna orientacja (http://www.catchingfeatures.com);
• symulacja - w sytuacjach, w których testowanie w prawdziwym ŋyciu moŋe byæ zbyt kosztowne lub niebezpieczne, takie jak szkolenie w locie, operacje medyczne i wojskowe gry wojenne.
Mogą równieŋ mieæ róŋnych odbiorców docelowych, takich jak:
• wojskowe - takie jak na gry wojenne i szkolenie w zakresie bezpieczeņstwa wewnętrznego;
• akademicki - do celów edukacyjnych;
• architektura - do wirtualnego przeglądania ķrodowiska zbudowanego;
• doroķli - na przykģad Second Life i The Sims Online (http://www.thesimsonline.com);
• nastolatki - na przykģad Barbie Girls (http://www.barbiegirls.com), ķwiat o tematyce Barbie gdzie dziewczęta kupują modę, grają muzykę, czatują, projektują pokoje i grają w gry; i
• dzieci - na przykģad Neopets (http://www.neopets.com), w którym dzieci grają w gry, towarzysko i kupują rzeczy dla zwierząt domowych.
Wdraŋanie ķrodowisk wirtualnych moŋna podzieliæ na następujące trzy pozycje:
1. Pseudo-realistyczny;
2. Fotorealistyczne;
3. Nierealne.
Pseudo-realistyczne ķrodowiska wirtualne są najbardziej rozpowszechnione. Są one renderowane w caģoķci przez komputer i często nie mają odpowiednika w rzeczywistoķci. Niektóre przykģady przedstawiono na rysunku.

Zrzut ekranu pokazany w lewym górnym rogu, utworzony za pomocą silnika gry, pokazuje wyrafinowanie pod względem szczegóģów. W prawym górnym rogu ekranu znajduje się zrzut ekranu z gry symulacyjnej sportów biegowych o nazwie Catching Features. Innym miejscem, w którym znajdują się ķrodowiska wirtualne, są wirtualne ķwiaty 3D, takie jak Second Life zaprojektowane przez Linden Lab i stworzone przez jego mieszkaņców (jak pokazano na dwóch dolnych zrzutach ekranu). To są ludzie, którzy odwiedzają wirtualny ķwiat za pomocą awatarów, które sami wybrali. Pseudo-realistyczne ķrodowiska są ograniczone jedynie przez wyobražnię projektanta (-ów) ķrodowiska i wysiģek, który wģoŋyģ w ich tworzenie. Wymagają znacznego czasu, aby stworzyæ realizm, który odzwierciedla rzeczywisty realizm, poniewaŋ często bardzo potrzebny jest niezwykle szczegóģowy szczegóģ, aby stworzyæ wiarygodne, pseudo-realistyczne ķrodowisko wirtualne. Jedną z metod stosowanych w celu uniknięcia tego wysiģku jest powielanie wspólnych obiektów, ale moŋe
to umniejszaæ realizm i wiarygodnoķæ. Byæ moŋe najczęstsze przykģady pseudo-realistycznych ķrodowisk znajdują się w nowoczesnych grach komputerowych. Coraz częķciej są one równieŋ uŋywane do replikowania rzeczywistych ķrodowisk. Na przykģad mogą byæ wykorzystane do zapewnienia wirtualnego widoku ķcieŋki dydaktycznej. Wymagaģoby to jednak znacznego wysiģku, aby dokģadnie przedstawiæ wszystkie drzewa i roķliny, które moŋna zobaczyæ na szlaku, aby uzyskaæ fotorealistyczne wyniki (tj. ķciķle pasujące do tego, co jest widoczne w rzeczywistoķci) i zazwyczaj taki realizm nie jest wymagany w takich zastosowaniach. Inne aplikacje mogą wymagaæ dokģadnego odtworzenia rzeczywistych scen, takich jak ķledztwa kryminalne lub symulacja przetargów, w których naleŋy wczeķniej okreķliæ linie ognia. Fotorealistycznie renderowane ķrodowiska wirtualne stanowią alternatywę, w której konieczne jest dokģadne powielenie rzeczywistego ķrodowiska. Rzeczywiķcie, dģugoterminowym celem grafiki komputerowej jest uzyskiwanie
fotorealistycznych rezultatów przy uŋyciu pseudo-realistycznych technik. Jedną z metod jest wykorzystanie statycznych panoram perspektywicznych, które zapewniają widok 360 ° ķrodowiska, i są one często uŋywane w Internecie, aby umoŋliwiæ uŋytkownikowi zobaczenie, jak scena moŋe wyglądaæ w rzeczywistoķci. Czasami te statyczne reprezentacje staģoprzecinkowe są ze sobą poģączone, aby zapewniæ wirtualną wycieczkę, ale w większoķci przypadków zdolnoķæ dynamicznego poruszania się po wszystkich częķciach sceny z wielu punktów nie jest moŋliwa. Moŋliwoķæ przejķcia z jednej panoramy do następnej w okreķlony sposób ogranicza uŋytkownika i często trudno jest zorientowaæ się, gdzie on się porusza w stosunku do miejsca, z którego się wywodzi. Zasadniczo wirtualna trasa to zbiór niezaleŋnych punktów widzenia, wzdģuŋ wczeķniej ustalonej ķcieŋki, a panoramy są niezaleŋnie od siebie zaleŋne od kontekstu. Oprócz zwykle kģopotliwego interfejsu, panoramy mogą byæ kosztowne w stworzeniu, wymagając specjalistycznego sprzętu z
ekstremalnym obiektywem szerokokątnym lub soczewką typu "rybie oko". Alternatywą jest uŋycie specjalistycznego oprogramowania do ģączenia wielu nakģadających się obrazów w celu utworzenia panoramicznego widoku. Jednak proces ten jest związany z bģędem, poniewaŋ zwykle nakģadające się obrazy nie pasują do siebie, gdzie zachodzą na siebie z powodu róŋnych kątów ,obrazy są pobierane z róŋnych ķwiateģ. Google Street View, jak widaæ w Mapach Google i Google Earth, to alternatywne podejķcie wyķwietlające obrazy scen z kamer zamontowanych na flocie samochodów. Umoŋliwia uŋytkownikom wyķwietlanie częķci wybranych miast na poziomie gruntu i zapewnia panoramiczne widoki na poziomie ulicy w poziomie 360 ° i 290 ° w pionie. Uŋytkownicy mogą poruszaæ się po scenie za pomocą kliknięæ myszy i klawiszy strzaģek na klawiaturze, a obrazy moŋna wyķwietlaæ w róŋnych rozmiarach, w dowolnym kierunku i pod róŋnymi kątami. Wyķwietlane są równieŋ linie wskazujące kierunek, w którym samochód z kamery widoku ulicy zostaģ
zarejestrowany podczas robienia zdjęæ. Chociaŋ te fotorealistyczne ķrodowiska są najbliŋsze nam do dokģadnych reprezentacji otaczającego nas ķwiata, nie zapewniają mechanizmu oprogramowania do ģatwego okreķlania tego, co jest faktycznie przedstawione w samym ķrodowisku wirtualnym, na przykģad w miejscu, w którym znajdują się obiekty, które moŋna zobaczyæ. wzajemny szacunek. Dlatego te typy ķrodowisk wirtualnych mają ograniczoną wartoķæ, gdy rozwaŋa się zadanie opracowania inteligentnych agentów, które mogą wykrywaæ, poruszaæ się i wchodziæ w interakcje wewnątrz niego, chyba ŋe ķrodowisko zostanie wzbogacone o dodatkowe informacje o tym, co w nim zawarte. Trudnoķæ z dostarczeniem tych dodatkowych informacji jest jednak równowaŋna ze zģoŋonoķcią w tworzeniu pseudorealistycznej kopii ķrodowiska rzeczywistego. Trzecią metodą jest renderowanie ķrodowisk w sposób inny niŋ fotorealistyczny, na przykģad w postaci rycin, szkiców lub krajobrazów przypominających kreskówki. Obiekty są renderowane przy uŋyciu
uproszczonej reprezentacji szczegóģów, koncentrując się raczej na stylu niŋ na realizmie, a szczegóģy są pomijane lub podkreķlane w celu skuteczniejszego przekazywania informacji. Często ķrodowisko budowane jest z samych konturów obiektów za pomocą stylizowanych tekstur. W związku z tym moŋliwe są szybkie algorytmy renderowania i bardzo duŋa liczba klatek na sekundę, która umoŋliwia bardzo pģynny ruch, umoŋliwiając nawigację w ķrodowisku przy duŋych prędkoķciach. Jednak zarówno w ķrodowisku pseudo-realistycznym, jak i fotorealistycznym, naleŋy doģoŋyæ staraņ, aby zaprojektowaæ ķrodowiska o wystarczającej zģoŋonoķci, aby mogli istnieæ inteligentni agenci.
Jak moŋemy opracowaæ i przetestowaæ system sztucznej inteligencji?
Podczas budowania dowolnego systemu inŋynier musi zmierzyæ się z pytaniem, jak najlepiej oceniæ jego efektywnoķæ. Jeķli inŋynierowie zignorują fazę ewaluacji, mogą popeģniæ te same bģędy, które popeģnili wczeķni badacze AI, gdy często pomijali peģną ocenę swojego systemu. (Często jest to pomyģka równieŋ z obecnymi systemami AI). Ocena to coķ więcej niŋ testowanie systemu, aby sprawdziæ, czy dziaģa poprawnie. Testowanie jest niezbędnym krokiem w procesie inŋynierii oprogramowania, którego nie naleŋy pomijaæ. Jednakŋe ocena idzie dalej i analizuje wyniki uzyskane przez system i porównuje wyniki z wynikami uzyskanymi przez inne systemy. Bez tej analizy niemoŋliwe jest stwierdzenie, czy dokonano prawdziwego postępu. To znaczy, czy nastąpiģy ulepszenia w dowolnych kryteriach uŋywanych do oceny systemów lub czy cele projektowe zostaģy osiągnięte. Jak zatem moŋemy opracowaæ i oceniæ system sztucznej inteligencji? Jednym ze sposobów jest stworzenie wirtualnego ķrodowiska o tak duŋej szczegóģowoķci i zģoŋonoķci, jakie ma rzeczywisty ķwiat, w odróŋnieniu od ķrodowisk, które oprogramowanie Catching Features jest w stanie stworzyæ, i posiada fizycznie wbudowaną sztuczną inteligencję. Są dwie zalety:
1. Ķrodowisko jest generowane komputerowo. Oznacza to, ŋe komputer juŋ wie wszystko na ten temat, poniewaŋ zostaģ juŋ wygenerowany i istnieją struktury danych, które reprezentują kaŋdy jego aspekt. W prawdziwym sensie moŋemy starannie pominąæ kwestię reprezentacji wiedzy (jak przedstawiæ wiedzę o fizycznych aspektach ķrodowisko), które są opisane póžniej.
2. Jeķli wizualizuje się ķrodowisko wirtualne, zarówno czģowiek, jak i sztuczna inteligencja mogą wspóģdziaģaæ ze sobą w tym samym ķrodowisku. Moŋe to byæ przydatne, jeķli chcemy wziąæ tę rolę nauczycieli do nauczania agentów sztucznej inteligencji, aby pomóc im w poznawaniu ķwiata i jak najlepiej z nim wspóģpracowaæ. Rola nauczyciela moŋe byæ niekonkurencyjna - bardziej jako ŋyczliwego nauczyciela, który nadzoruje proces uczenia się - lub moŋe byæ konkurencyjna, tak jak w symulacji orientacji, gdzie celem jest doprowadzenie do tego, aby agent komputerowy odtworzyæ zachowanie ludzkich graczy i osiągnąæ ten sam poziom wydajnoķci, a moŋe nawet go przekroczyæ. Jeķli to drugie jest moŋliwe, agent komputerowy moŋe przejąæ rolę nauczyciela lub pomóc graczom w osiągnięciu lepszych wyników (moŋe się to zdarzyæ po prostu czģowiekowi, który próbuje konkurowaæ na tym samym poziomie co agenci komputerowi).
Podsumowanie i dyskusja
Projektowanie zorientowane na agenta stanowi alternatywę dla bardziej znanego projektowania obiektowego podczas budowania systemów komputerowych. Podczas projektowania moŋemy konceptualizowaæ systemy komputerowe za pomocą analogii agentów istniejących w ķrodowisku. Ta charakterystyka pozwala nam skoncentrowaæ nasz projekt na konkretnych poŋądanych wģaķciwoķciach, takich jak autonomia (agenci w systemie muszą podejmowaæ wģasne decyzje), reaktywnoķæ (reagują na zdarzenia zachodzące w ķrodowisku) i proaktywnoķæ (reagują na prawdopodobne przyszģe zdarzenia) . Agenci nie istnieją poza swoim ķrodowiskiem. Ķrodowisko ma zasadnicze znaczenie w okreķlaniu zachowania agenta. Zģoŋonoķæ systemu zorientowanego na agenta wynika nie tylko z interakcji agentów z innymi agentami, ale równieŋ z interakcji między agentami a ķrodowiskiem. Wirtualne ķrodowiska są doskonaģym ķrodkiem do testowania systemów sztucznej inteligencji. Podsumowanie waŋnych pojęæ, które naleŋy wyciągnąæ z tej sekcji, pokazano poniŋej:
• Agenci są autonomiczni, reaktywni i proaktywni.
• Ķrodki mają równieŋ inne wģaķciwoķci, które okreķlają, czy są one sģabymi lub silnymi ķrodkami.
• Agenci podejmują decyzję o tym, co robiæ, podczas gdy obiekty są wywoģywane zewnętrznie.
• Agentów nie moŋna rozpatrywaæ niezaleŋnie od ich otoczenia.
• Ķrodowiska, zarówno rzeczywiste, jak i abstrakcyjne, mogą byæ reprezentowane jako przestrzenie n-wymiarowe.
• Wirtualne ķrodowiska mogą byæ wykorzystywane do testowania systemów sztucznej inteligencji
Struktura dla Agentów i Ķrodowisk
NetLogo to programowalne ķrodowisko modelowania do symulacji zjawisk naturalnych i spoģecznych ... NetLogo szczególnie dobrze nadaje się do modelowania zģoŋonych systemów rozwijających się w czasie. Modele mogą wydawaæ polecenia setkom lub tysiącom "agentów", którzy dziaģają niezaleŋnie. Dzięki temu moŋna zbadaæ związek między zachowaniem na poziomie mikro poszczególnych osób a wzorcami na poziomie makro, które wynikają z interakcji wielu osób. Uri Wilensky, 1999.[twórca NetLogo]
Architektury i ramy dla agentów i ķrodowisk
Jeķli mamy budowaæ systemy zorientowane na agentów, potrzebujemy platformy komputerowej i niektórych frameworków programowych, na których moŋna je zbudowaæ. Kiedy mówimy o platformach i frameworkach, uŋywamy analogii konstrukcji, która wiąŋe się z koncepcją stworzenia systemu komputerowego z budowaniem w prawdziwym ŋyciu. Sģowa takie jak "architektura", "struktura", "platforma", "zestaw narzędzi" i "struktura" są uŋywane w celu zwrócenia uwagi na leŋącą u podstaw analogię konstrukcyjną. Ich precyzyjne znaczenie jest trudne do okreķlenia, poniewaŋ terminy są często uŋywane zamiennie ze względu na ukrytą podstawową analogię. Moŋemy odnieķæ się do architektury systemu zorientowanego na agenta jako ogólnego projektu koncepcyjnego i struktury operacyjnej systemu. Celem struktury jest uproszczenie projektowania systemu poprzez zapewnienie wyŋszego poziomu abstrakcji niezbędnych komponentów i funkcji systemu, tak aby mniej czasu poķwięcano na szczegóģy niŋszego poziomu niezbędne do uruchomienia systemu. Platforma jest platformą sprzętową lub programową, która umoŋliwia uruchamianie oprogramowania. Naleŋą do nich architektura, system operacyjny, języki programowania, biblioteki uruchomieniowe i graficzne interfejsy uŋytkownika. W tej częķci omówimy róŋne struktury dostępne dla systemów zorientowanych na agentów budowlanych. Takie struktury mają róŋne problemy projektowe, które naleŋy pokonaæ, takie jak ("Software Agent", 2008): planowanie, synchronizacja i ustalanie priorytetów zadaņ agenta; wspóģpraca między agentami; przydziaģ zasobów i rekrutacja; powtórne tworzenie instancji agentów w róŋnych ķrodowiskach; przechowywanie stanów wewnętrznych agentów; badanie ķrodowiska; przesyģanie wiadomoķci i komunikacja; interakcja agent-ķrodowisko w obliczu zmieniającego się, dynamicznego ķrodowiska; i taksonomia agenta - która hierarchia jest odpowiednia dla zadania, np. Agenci wykonywania zadaņ, agenci planowania, dostawcy zasobów i tak dalej.
Standardy dla technologii opartych na agentach
Kolejną waŋną kwestią jest standaryzacja. Jeķli mamy na przykģad opracowaæ autonomiczne agenty z moŋliwoķcią komunikowania się ze sobą, waŋne jest, aby zgodziæ się na zestaw standardów dotyczących sposobu komunikacji. FIPA (dla Fundacji na rzecz inteligentnych agentów fizycznych) jest organizacją normalizacyjną IEEE Computer Society zajmującą się technologią opartą na agentach i jej interoperacyjnoķcią z innymi technologiami (FIPA, 2008). Specyfikacje FIPA stanowią zbiór standardów, których celem jest promowanie wspóģdziaģania heterogenicznych agentów i usģug, które reprezentują. W 2002 r. FIPA zakoņczyģa standaryzację podzbioru 25 wszystkich specyfikacji.
Podzbiór oraz peģny zestaw specyfikacji obejmuje róŋne kategorie, takie jak: komunikacja z agentem; transport agentów; zarządzanie agentami; abstrakcyjna architektura; i aplikacje. Podstawowe specyfikacje FIPA dotyczą komunikacji agentów, która definiuje język zwany ACL (dla języka komunikacji agenta). Zajmuje się komunikatami komunikacyjnymi, protokoģami wymiany wiadomoķci między agentami i reprezentacjami treķci wiadomoķci. Specyfikacje są dobrze dostosowane do aplikacji agentów, w których komunikacja jest waŋna i coraz częķciej, wiele architektur i struktur agenta staje się teraz zgodna z FIPA. Komunikacja jest jednak tylko jednym aspektem inteligencji, a specyfikacje pomijają waŋne kwestie agenta, takie jak ucieleķnienie i usytuowanie - cechy, które zostaģy zidentyfikowane w Częķci 1 (i rozwinięte w Częķci 5), jako waŋne dla inteligencji. Na przykģad zaskakujące jest to, ŋe nie ma osobnej kategorii w specyfikacjach dla ķrodowiska i jak agenci są w stanie wyczuæ i poruszaæ się w nich. Dlatego te specyfikacje mają mniejsze znaczenie w zastosowaniach, w których wiarygodna interakcja ze ķrodowiskiem jest kluczowa - na przykģad w animacji komputerowej, grach komputerowych oraz symulacji i modelowaniu ķrodowiska.
Języki programowania zorientowane na agenta
Jednym z bezpoķrednich problemów dla systemów zorientowanych na agentów jest znalezienie odpowiedniej platformy języka programowania. Obecnie stosunkowo niewiele języków programowania ma wbudowane wsparcie dla programowania zorientowanego na agentów i nie ma w peģni zorientowanego na agenta gģównego języka programowania. Zaproponowano róŋne języki programowania zorientowane na agenta, takie jak:
• 3APL na wdraŋanie czynników poznawczych i kontrolę na wysokim poziomie robotów kognitywnych z przekonaniami, obserwacjami, dziaģaniami, celami, komunikacją i zasadami rozumowania
• AgentSpeak, pozwala na zapisywanie i interpretowanie programów agentów BDI (dla wierzeņ, pragnieņ i intencji) w ramach ograniczonego programu logicznego pierwszego rzędu ze zdarzeniami i dziaģaniami, i moŋe byæ postrzegany jako uproszczony język tekstowy Systemu Reakcji Proceduralnej (PRS) oraz system rozproszenia rozproszonego dla wielu agentów (dMARS) . Jason jest tģumaczem open-source dla AgentSpeak napisanym w Javie, który pozwala programistom budowaæ systemy wieloagentowe w zģoŋonych ķrodowiskach.
• SPADES, system oprogramowania poķredniego do tworzenia symulacji opartych na agentach.
• SPLAW, oparty na KQML, standardowym języku komunikacji między agentami.
• STAPLE, na podstawie teorii wspólnej zamiaru
Ta lista nie jest wyczerpująca. Jego celem jest zilustrowanie róŋnorodnoķci opracowanych rozwiązaņ. Rysunek przedstawia schematyczną klasyfikację wybranych platform i języków do modelowania opartych na agentach.
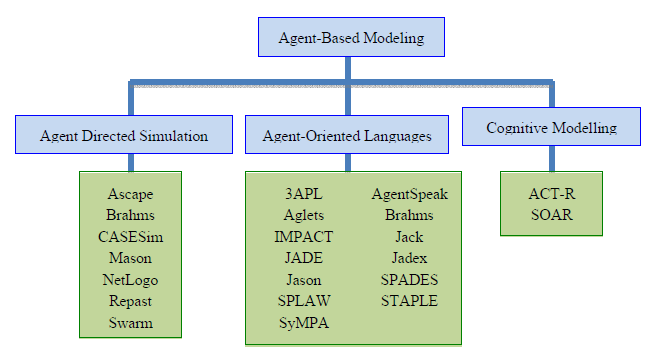
Klasyfikacja na diagramie dzieli modelowanie oparte na agentach na trzy kategorie - symulacja ukierunkowana na agenta, języki zorientowane na agenta i modelowanie kognitywne. Pierwsza kategoria obejmuje języki, które ģączą modelowanie agentów z symulacją. W pozostaģych sekcjach tej częķci przyjrzymy się konkretnemu przykģadowi w tej kategorii - NetLogo. Wedģug Zhanga, Lewisa i Sierhuusa, zaletą Netlogo jest to, ŋe ma maģą krzywą uczenia się dla początkującego programisty, ģatwo jest debugowaæ, i zapewnia ģatwy dostęp do podstawowej wizualizacji, poniewaŋ zostaģ "zaprojektowany z myķlą o niedoķwiadczonym programiķcie". Kolejną zaletą jest to, ŋe programy NetLogo są bardzo kompaktowe i ģatwe do odczytania, a zatem w razie potrzeby są znacznie ģatwiejsze do konwersji na inne języki programowania. Oczywistą cechą rysunku jest przewaga wystąpieņ w drugiej kategorii, z bardzo nielicznymi w trzeciej kategorii. Jak wspomniano powyŋej, nie ma jeszcze języka programowania zorientowanego na agenta gģównego nurtu w posób, w jaki C, Java i Python staģy się gģównym nurtem. Byæ moŋe ich powszechnym bģędem jest taki sam bģąd, jaki ma Prolog - zbyt duŋy nacisk na oparty na logice paradygmat - który moŋe byæ trudny do zrozumienia i debugowania dla początkujących programistów. Na przykģad Huget umieķciģ desideratę dla zorientowanego na agenta języka programowania, który zawiera funkcje do obsģugi logiki (takie jak BDI dla racjonalnych agentów); ale wymieniģ takŋe inne poŋądane cechy, takie jak: wiedza i komunikacja; definicje organizacji i ķrodowisk; abstrakcja w celu uniknięcia zģoŋonoķci w projektowaniu; zgodnoķæ z normami; umiejętnoķæ mieszania formalizmów takich jak automaty i sieci Petriego; oraz architektura sterowana zdarzeniami (uŋywana przez czynniki reaktywne, które reagują na zdarzenia w momencie ich wystąpienia). Mimo ŋe języki oparte na logice są interesujące i same w sobie są potęŋne, nie pasują one do tego, co programiķci lubią robiæ najlepiej - uzyskując uŋyteczne rzeczy, aby dobrze dziaģaģy przy minimalnym zamieszaniu. Zamiast opracowywaæ zupeģnie nowy język programowania zorientowany na agenta, alternatywnym podejķciem jest opracowanie systemu hybrydowego w języku programowania, który nie jest zorientowany na agenta. Jak stwierdzono, większoķæ języków programowania nie obsģuguje programowania zorientowanego na agenta. Typowym rozwiązaniem jest opracowanie struktury agenta w obiektowym języku programowania, poniewaŋ jest to obecnie dominujący paradygmat programowania w modzie. Opracowano wiele frameworków agentów, a większoķæ koncentruje się na kwestiach związanych z rozumowaniem przy uŋyciu rozwiązania opartego na logice (takiego jak BDI), a takŋe innych moŋliwoķciach, takich jak komunikacja agent-agent, zwykle przy uŋyciu standardowego języka komunikacji KQML . Jak wyglądaģaby obiektowa struktura agentów? Obiekty mogą byæ uŋywane do reprezentowania agentów w systemie lub aplikacji, takich jak agenci planowania, agenci interfejsu uŋytkownika, agenci wyszukiwania i tak dalej. Agenci zorientowani obiektowo są definiowane za pomocą klasy ("AgentClass" lub "RootAgentClass"), a wszyscy agenci mają róŋne wspólne cechy, takie jak nazwa lub identyfikator, inne globalne atrybuty oraz podstawowy zestaw protokoģów komunikacyjnych i obsģugi bģędów. Podklasy sģuŋą do definiowania bardziej konkretnych typów agentów - na przykģad "TextSearchAgent" - które będą miaģy okreķlone atrybuty i protokoģy. Kaŋdy obiektowy agent ma atrybuty, które definiują stan agenta i operacje / metody definiujące zachowanie agenta Jakie są zalety rozwoju agentów wykorzystujących technologie obiektowe? Knapik i Johnson wymieniają te same korzyķci, które wynikają z paradygmatu programowania obiektowego: kod wielokrotnego uŋytku; zmniejszone koszty rozwoju agentów; elastyczna struktura projektu agenta; ģatwoķæ konserwacji; rozciągliwoķæ; wyrozumiaģoķæ; obsģuga poģączonych hierarchii agentów i domen; wiedza systemowa jest wewnętrzna; oraz ģatwo dostępne ķrodowisko programistyczne do modelowania i symulacji. Rosnąca liczba obiektowych struktur agentów zostaģa opracowana przy uŋyciu języka Java. (NetLogo jest równieŋ zaimplementowany w Javie). Java oferuje obiektowe rozwiązanie, które jest juŋ zintegrowane z uniwersalnym klientem - przeglądarkami sieciowymi - i obsģuguje takie pakiety, jak java.net, które mogą byæ uŋywane przez agentów do uzyskiwania dostępu i wydobywania informacji ze stron internetowych. Java ma olbrzymi potencjaģ jako język programowania agenta ze względu na jego szerokie zastosowanie w sieci. Podobnie Python jest
innym językiem, który jest coraz częķciej uŋywany w sieci i ma wsparcie dla paradygmatu programowania obiektowego, ale do tej pory opracowano dla niego mniej frameworków niŋ Java. Omówimy teraz kilka innych frameworków agenta. Ponownie, celem nie jest wyczerpujące i udokumentowanie dostępnych struktur, poniewaŋ jest ich zbyt wiele. Celem jest przede wszystkim zilustrowanie róŋnorodnoķci moŋliwych rozwiązaņ i podkreķlenie, ŋe ŋadne pojedyncze rozwiązanie nie uchwyciģo wyobražni i zainteresowaņ programistów na caģym ķwiecie, aby staæ się gģównym nurtem. W Javie aplety i servelety moŋna uznaæ za nieco podobne do agentów. Aplety migrują z serwera do klienta, więc wykonaj je na kliencie, a tym samym zwalniaj serwer, a więc wykorzystaj pewien stopieņ mobilnoķci, co jest waŋną cechą agentów. Serwlety Java pozwalają równieŋ uŋytkownikom przesyģaæ do sieci program wykonywalny, dzięki czemu uŋytkownik lub aplikacja kliencka moŋe uruchomiæ agenta dziaģającego na serwletach w celu wyszukiwania informacji w sieci lub automatycznego reagowania lub okresowych aktualizacji. Aglety IBM (dla agile agentów) to platforma agenta Java dla urządzeņ mobilnych, która dodaje do Javy dodatkowe funkcje, które są szczególnie ukierunkowane na zadania agenta. Pierwotnie opracowany w IBM Tokio Research Laboratory, technologia Aglets jest teraz hostowana na sourceforge.net. Aglet jest agentem Java zdolnym do autonomicznego i spontanicznego przechodzenia z jednego hosta na drugi wędrując po Internecie. Dostępna jest kompletna platforma agenta Java Mobile wraz z autonomicznym serwerem o nazwie Tahiti, a takŋe biblioteka umoŋliwiająca programistom tworzenie agentów mobilnych lub umieszczanie kodu agletowego w aplikacji. Aglety mogą byæ zatrzymywane, pakowane wraz z ich bieŋącym stanem w innym obiekcie wysyģanym do innego ķrodowiska, i ich wykonanie jest wznawiane. Java API ma róŋne klasy, takie jak: klasa Aglet, streszczenie klasy, która jest uŋywana do definiowania agletów; AgletContext, który jest interfejsem, którego uŋywa aglet, aby zdobyæ wiedzę o swoim ķrodowisku; AgletProxy, która jest klasą, która hermetyzuje prawdziwą plamę, chroniąc przed bezpoķrednim dostępem do publicznego interfejsu programu; AgletIdentifier, który jest klasą, która ustawia unikalny identyfikator dla agletu; klasa Itinerary reprezentuje trasę do planów podróŋy dla agletu; oraz klasa Message, która umoŋliwia komunikację między agentami.
JADE (dla Java Agent DEvelopment Framework) to kolejna platforma w peģni zaimplementowana w Javie i jest wolnym oprogramowaniem dystrybuowanym przez Telecom Italia. Wspiera rozwój systemów wieloagentowych zgodnych ze specyfikacjami FIPA. Dostępne są narzędzia graficzne, które wspomagają fazy debugowania i wdraŋania, a zdalny interfejs GUI moŋe byæ uŋywany do kontrolowania konfiguracji agenta, która moŋe byæ dystrybuowana między komputerami i która moŋe byæ zmieniana w czasie wykonywania poprzez przenoszenie agentów z jednego komputera na drugi.
LEAP (dla Light Extensible Agent Platform) jest rozszerzeniem JADE, które pozwala na zgodnoķæ z FIPA ,platformą o zmniejszonym zasięgu zgodna z mobilnymi ķrodowiskami Java do uruchamiania na urządzeniach bezprzewodowych i urządzeniach PDA, takich jak telefony komórkowe i komputery przenoķne. WADE (Workflows and Agents Development Environment) to rozszerzenie JADE, które umoŋliwia agentom wykonywanie zadaņ zdefiniowanych zgodnie z metaforą przepģywu pracy.
Przepģyw pracy WADE to klasa Java o dobrze zdefiniowanej strukturze, która umoŋliwia programistom zdefiniowanie procesu pod względem wykonywanych czynnoķci, ich aktywacji i kryteriów zakoņczenia oraz relacji między nimi. Moŋna podaæ dalsze informacje, takie jak uczestnicy przepģywu pracy, narzędzia programowe, które będą wywoģywane, wymagane dane wejķciowe i oczekiwane wyniki oraz dane wewnętrzne, które zostaną zmanipulowane podczas wykonywania. Zaletą podejķcia opartego na przepģywie pracy jest to, ŋe wszystkie etapy wykonania oraz ich sekwencjonowanie są jawne. WADE zawiera platformę programistyczną o nazwie WOLF, która jest wtyczką Eclipse.
Symulacja ukierunkowana na agenta w NetLogo
NetLogo uŋywa podejķcia, które róŋni się od klasycznego podejķcia opartego na logice, z którego zazwyczaj korzystają języki programowania i frameworki zorientowane na agenta. Obrazuje siģę podejķcia zorientowanego na agentów w rozwiązywaniu problemów w nietradycyjny sposób i ma potencjaģ przezwycięŋenia niektórych barier w rozwoju przydatnych systemów wieloagentowych. NetLogo, zaprojektowany po raz pierwszy przez Uri Wilensky′ego w 1999 r., Jest wieloplatformowym, programowanym, programowalnym ķrodowiskiem modelowania pod ciągģym rozwojem w CCL (Center for Connected Learning and Computer-Based Modeling) na Northwestern University. NetLogo moŋe sģuŋyæ do szybkiego prototypowania symulacji zjawisk naturalnych i spoģecznych. Opiera się na wczeķniejszym języku zorientowanym na grafikę o nazwie Logo, opracowanym przez Seymoura Paperta w latach 60. XX wieku i odróŋnia się od bardziej tradycyjnych, zorientowanych na agenta języków programowania, poniewaŋ nie obsģuguje formalizmów opartych na logice. NetLogo przyjmuje architekturę opartą na zdarzeniach, w której agenci o prostych reakcjach reaktywnych mogą uzyskaæ zadziwiająco zģoŋone symulacje, mimo ŋe znajdują się w ograniczonym dwuwymiarowym (2D) ķrodowisku sieciowym (obecnie opracowywana jest wersja ze ķrodowiskiem siatki 3D). NetLogo opisuje ķrodowisko, którego uŋywa do wizualizacji swoich symulacji jako "ķwiata" (innymi sģowy, czyni analogię między swoim ķrodowiskiem a rzeczywistym ķwiatem). Ten ķwiat skģada się z "agentów" wykonujących czynnoķci wedģug instrukcji okreķlonych metodami zaprogramowanymi w języku programowania NetLogo. Te dziaģania są przeprowadzane jednoczeķnie dla wszystkich agentów na ķwiecie. NetLogo ma cztery typy agentów: ŋóģwie, ģaty, linki i obserwatora. Ŋóģwie to agenci, którzy poruszają się i wchodzą w interakcje ze ķwiatem. Powód, dla którego nazywane są ŋóģwiem, zostaģ odziedziczony z języka programowania Logo - analogia do wyobraŋonego robota, który ma zdolnoķæ poruszania się i podnoszenia lub upuszczania wirtualnego, kolorowego dģugopisu, który ma na plecach na pģótnie do rysowania. Siatka 2D skģada się równieŋ z ģat, które są kwadratowymi kawaģkami ziemi, przez które ŋóģwie mogą się przesuwaæ i poruszaæ (patrz prawe okienko na rysunku poniŋej). Linki to agenci ģączący dwa ŋóģwie. Obserwator patrzy na ķwiat ŋóģwi i ģat, ale nie ma okreķlonej lokalizacji (w pewnym sensie nie jest ucieleķniony jak inni agenci)
NetLogo zawiera bogaty zestaw przykģadowych "modeli" (lub programów) symulujących zjawiska naturalne lub spoģeczne w wielu dziedzinach, takich jak: sztuka, biologia, chemia i fizyka, informatyka, nauka o ziemi, matematyka i nauki spoģeczne . Na przykģad model Predatora owcy i wilka bada stabilnoķæ ekosystemów drapieŋników-ofiar. W symulacji występują dwa typy ras (róŋne rodzaje ŋóģwi) - wilki i owce, a takŋe ģaty traw. Wilki jedzą owce, a owce jedzą trawę. W zaleŋnoķci od warunków początkowych (liczba wilków, liczba owiec, wskažniki reprodukcji wilków i owiec, ile energii uzyskują z jedzenia, gdzie są losowo umieszczone w ķrodowisku, i czas ponownego wzrostu trawy), Symulacja spowoduje niestabilny system, w którym albo wilki albo oba wilki i owce wyginą, lub to spowoduje stabilny system, w którym będzie dąŋyģ do utrzymania się pomimo wahaņ wielkoķci populacji w czasie. Zrzut ekranu modelu pokazano na rysunku powyŋej. Kod NetLogo jest bardzo czytelny i kompaktowy. Poniŋej znajduje się kod procedury gģównej
go, która okreķla, co się dzieje, gdy uruchomiona jest symulacja Wolf Sheep.
to go
if not any? turtles [ stop ]
ask sheep [
move
if grass? [
set energy energy 1 ;; odejmij energię dla owiec tylko wtedy, gdy
;; przeģącznik trawy jest wģączony
eat-grass
]
reproduce-sheep
death
]
ask wolves [
move
set energy energy - 1 ;; wilki tracą energię podczas ruchu
catch-sheep
reproduce-wolves
death
]
if grass? [ ask patches [ grow-grass ] ]
tick
update-plot
display-labels
end
Polecenie ask sģuŋy do okreķlania zachowania agentów ŋóģwia, poprawek i linków. W powyŋszym kodzie zachowanie owiec najpierw się porusza, potem je trawę, rozmnaŋa się i umiera. Zachowanie wilków polega na poruszaniu się, chwytaniu owiec (i jedzeniu), reprodukcji, a następnie umieraniu. Wiele róŋnorodnych modeli, które pojawiają się w NetLogo, pokazuje, ŋe zorientowany na agentów paradygmat programowania, który stosuje, jest zdolny do modelowania zaskakującego zakresu zjawisk w nieskomplikowany sposób. Na przykģad na poniŋszym rysunku pokazano model nowotworu, który symuluje wzrost guza i jego odpornoķæ na leczenie chemiczne. Guz skģada się z dwóch rodzajów komórek: komórek macierzystych reprezentowanych przez niebieskie ķrodki ŋóģwia; i komórki przejķciowe reprezentowane przez wszystkie inne ŋóģwie. Rysunek ilustruje, w jaki sposób komórka rozwija się w odlegģe miejsca i jak tworzy kolejną kolonię nowotworową, proces zwany przerzutami pokazano na czerwono.
NetLogo to doskonaģe narzędzie do zilustrowania zasady, ŋe zģoŋonoķæ moŋe wynikaæ z interakcji agentów, którzy indywidualnie stosują proste zachowania reaktywne, ale zbiorowo wykazują duŋo więcej - to znaczy, ŋe system jako caģoķæ jest większy niŋ suma jego częķci.
Ķrodowisko programistyczne NetLogo
Czytelnik powinien zapoznaæ się z dokumentacją doģączoną do ķrodowiska programistycznego NetLogo. Będziesz musiaģ się do tego często odwoģywaæ, jeķli chcesz tworzyæ wģasne programy. Po uruchomieniu aplikacji NetLogo wybierz menu Pomoc, a następnie wybierz "Podręcznik uŋytkownika NetLogo". Moŋesz wykonaæ następujące samouczki, aby dowiedzieæ się więcej o NetLogo:
• Sample Model: Party
• Tutorial #1: Models
• Tutorial #2: Commands
• Tutorial #3: Procedures
W przypadku odniesieņ językowych dostępne są następujące opcje:
• Interface Guide
• Programming Guide
• Transition Guide
• NetLogo Dictionary
Przewodnik po interfejsie zawiera podsumowanie interfejsu uŋytkownika NetLogo i sposób poruszania się po nim. Większoķæ interfejsu uŋytkownika jest doķæ oczywista, więc nie będziemy tutaj powtarzaæ tego materiaģu. Jeķli masz trudnoķci ze znalezieniem rzeczy w interfejsie uŋytkownika, to jest to miejsce, w którym moŋna znaležæ informacje o menu uŋytkownika i dostępne opcje uŋytkownika. Byæ moŋe najbardziej uŋyteczną rzeczą, którą naleŋy wiedzieæ na temat interfejsu uŋytkownika, jest zaģadowanie biblioteki modeli i wybranie konkretnego modelu. W menu kartę Plik wybierz "Biblioteka modeli", a to zaģaduje duŋą bibliotekę modeli podzielonych na róŋne obszary tematyczne, takie jak Sztuka, Biologia, Informatyka, Chemia i Fizyka i tak dalej. Aby zapoznaæ się z interfejsem, wybierz obszar tematyczny Biologia, a następnie wybierz model Termity. Po kliknięciu przycisku Ustawienia na ekranie powinny pojawiæ się następujące elementy:
Zwróæ uwagę na trzy przyciski menu u góry - Interfejs, Informacje i Procedury. Po wybraniu przycisku Interfejs otrzymasz interfejs do programu i wizualizację bieŋącego stanu ķrodowiska NetLogo (zwykle 2D), jak pokazano na powyŋszym rysunku. Będzie się to róŋniæ w zaleŋnoķci od aktualnie wykonywanego modelu lub aplikacji. Zwykle jest przycisk konfiguracji, aby ustawiæ początkowy stan ķrodowiska, i przycisk Go, aby rozpocząæ symulację. Czasami moŋna podaæ przycisk jednorazowego uruchomienia - spowoduje to wykonanie modelu przez pojedynczy krok symulacji lub zaznaczenie. W innych przypadkach pojawi się przycisk "na zawsze", który będzie wykonywaģ model w nieskoņczonoķæ. Te elementy interfejsu moŋna dodaæ, klikając menu przycisku i wybierając spoķród wielu elementów,
takich jak przyciski, suwaki i wybieracze:
Róŋne z tych elementów interfejsu definiują zmienne globalne lub wymagają okreķlonego polecenia (tj. Procedury) gdzieķ zdefiniowanego w programie. Na przykģad przycisk go wymaga zdefiniowania w kodzie polecenia o nazwie go, ale etykieta wyķwietlana na przycisku moŋe zostaæ w razie potrzeby zastąpiona. Przycisk Information przeģączy się na ekran, na którym wyķwietlane są informacje o modelu dostarczonym przez programistę. Przycisk Procedure przeģączy się w tryb ekranu, w którym wyķwietlany jest kod NetLogo modelu i który moŋna edytowaæ. W przypadku modelu Termites dwa pierwsze polecenia okreķlają kod, który ma zostaæ wykonany po kliknięciu przycisku setup i go:
to setup
clear-all
set-default-shape turtles "bug"
;; losowo rozprowadzaæ zrębki
ask patches
[ if random-float 100 < density
[ set pcolor yellow ] ]
;; losowo rozmieszczaj termity
create-turtles number [
set color white
setxy random-xcor random-ycor
set size 5 ;; easier to see
]
end
to go ;; procedura ŋóģwia
search-for-chip
find-new-pile
put-down-chip
end
NetLogo jest bardzo zwięzģy i ģatwy do odczytania. Procedura instalacji losowo rozprowadza wióry i termity (widziana jako ŋóģte ģatki i biaģe ikony ant-podobne odpowiednio w ķrodowisku po kliknięciu przycisku instalacji). Procedura go wykonuje trzy dalsze procedury - szukanie wiórów drewnianych, znajdowanie nowego stosu i ukģadanie zrębków - które definiują zachowanie wszystkich czynników termitów na kaŋdym kleszczu. Kod dla tych trzech procedur moŋna znaležæ w pozostaģej częķci kodu doģączonego do modelu. Przewodnik programowania zawiera podsumowanie kluczowych elementów języka programowania NetLogo. Zapewnia przegląd waŋnych funkcji języka i moŋe byæ uŋytecznym žródģem dla przykģadów programowania. Warto czytaæ, zwģaszcza gdy zaczynasz od języka. Jednak sģownik NetLogo to miejsce, w którym programiķci NetLogo spędzają większoķæ czasu i zawierają linki do wszystkich poleceņ dostępnych w tym języku. Przewodnik "Transition Guide" opisuje wczeķniejsze wersje NetLogo i to, co zmieniģo się w ostatnich wersjach, więc jest mniej korzystne dla kogoķ uczącego się programowania w NetLogo.
Agenci i ķrodowiska w NetLogo
Spojrzymy teraz na sposób implementacji agentów i ķrodowisk w NetLogo. Technicznie rzecz biorąc, ŋóģwie wdroŋone w NetLogo moŋna by sklasyfikowaæ jako "proto-agentów", a nie peģnowymiarowych "agentów", poniewaŋ nie są one autonomiczne i nie mają wyražnych moŋliwoķci wykrywania (muszą one byæ zaprogramowane) , chociaŋ mają charakterystyczne zachowanie w ograniczonym sensie i znajdują się w prymitywnym ķrodowisku 2D. Jednak uznamy, ŋe rozróŋnienie proto-agent / agent jest arbitralne i wolimy zamiast tego odnosiæ się do ŋóģwi jako agentów, tak jak są one opisane w dokumentacji NetLogo, a takŋe dlatego, ŋe mają one potencjaģ projektowy w celu uzyskania bardziej zģoŋonych wģaķciwoķci agenta, jeķli są zaprogramowane w bardziej wyrafinowany sposób, taki jak uŋycie nici dla kaŋdego ŋóģwia i / lub zapewnienie ŋóģwiom większych moŋliwoķci wykrywania. Jednym ze sposobów myķlenia o nich jest zestaw wstępnie zaprogramowanych "robotów" oprogramowania, nad którymi sprawujemy kontrolę nad programistą. Moŋemy jawnie zaprogramowaæ zestaw instrukcji lub poleceņ, które kontrolują to, co robią, gdy są wykonywane, więc nie ma nic naprawdę odmiennego od standardowego podejķcia obiektowego. Potęga NetLogo wynika jednak z ģatwoķci, z jaką umoŋliwia jednoczesne tworzenie i wykonywanie wielu agentów (w wielu przypadkach setek lub nawet tysięcy). Jak stwierdzono, w NetLogo istnieją cztery typy agentów:
1. ŋóģwie
2. ģaty
3. powiązani
4. obserwatorzy
Agenci ŋóģwi to agenci, którzy znajdują się w ķrodowisku i poruszają się w nim. Ķrodowisko 2D skģada się z siatki ģat, nad którymi mogą się poruszaæ agenci. Uŋywając analogii ze ķrodowiskiem reallife, moŋemy pomyķleæ, ŋe ģaty są kwadratowymi kawaģkami ziemi uģoŋonymi w wzór siatki przypominający bloki na Manhattanie. Agenci powiązani ģączą ze sobą dwóch agentów ŋóģwia. Agent obserwujący to pojedynczy agent, który nadzoruje (lub "obserwuje") ķrodowisko i agentów, ale nie ma okreķlonej lokalizacji, takiej jak pozostaģe trzy typy agentów. W NetLogo zestaw agentów nazywa się agentsetem. Język ma bogaty zestaw poleceņ, które pozwalają nam ģatwo ustawiæ atrybuty dla caģego zestawu agentów (takich jak ich kolor, jak w poniŋszym przykģadzie kodu NetLogo). Wbudowane zmienne ŋóģwie, ģatki i linki utrzymują zestawy wszystkich ŋóģwi, ģatek i ģączą agentów, które obecnie istnieją w ķrodowisku. Deweloper ma takŋe moŋliwoķæ zdefiniowania agentów ŋóģwi i ģączników jako nowych ras agentów. Na przykģad poniŋsze polecenie definiuje dwie rasy agentów, lisów i królików:
breed [foxes fox]
breed [rabbits rabbit]
turtles-own [age gender]
Polecenie z ŋóģwiami okreķla, ŋe wszystkie ŋóģwie (w tym lisy i króliki) posiadają atrybuty wiek i pģeæ. Atrybuty związane z okreķloną rasą moŋna zdefiniowaæ za pomocą komendy specyficznej dla rasy
breed [foxes fox]
breed [rabbits rabbit]
turtles-own [age gender]
to setup
clear-all ;; clear everything
create-foxes 100 [
set age 0
set size 2
set color brown
ifelse random 2 = 0
[set gender "Male"]
[set gender "Female"]
setxy random-xcor random-ycor
]
create-rabbits 1000 [
set age 0
set size 2
set color white
ifelse random 2 = 0
[set gender "Male"]
[set gender "Female"]
setxy random-xcor random-ycor
]
end
Zrzut ekranu przedstawiający wynikowe ķrodowisko pokazano na rysunku
Poniŋszy kod dostarcza kolejnego przykģadu, jak zdefiniowaæ rasę agenta ŋóģwia zwaną all-blacks z czterema atrybutami - name, pos, weight, height i debut - i zainicjowaæ te atrybuty za pomocą wyboru dostarczonych danych
breed [all-blacks all-black]
all-blacks-own [name pos weight height debut]
to initialise-all-blacks
create-all-blacks 1 [set name "Sid Going" set pos "Half-back"
set weight 81 set height 170 set debut 1967]
create-all-blacks 1 [set name "David Kirk" set pos "Half-back"
set weight 73 set height 173 set debut 1983]
create-all-blacks 1 [set name "Justin Marshall" set pos "Half-back"
set weight 95 set height 179 set debut 1995]
create-all-blacks 1 [set name "Piri Weepu" set pos "Half-back"
set weight 94 set height 178 set debut 2004]
create-all-blacks 1 [set name "Grant Batty" set pos "Winger"
set weight 70 set height 165 set debut 1972]
create-all-blacks 1 [set name "John Kirwan" set pos "Winger"
set weight 97 set height 191 set debut 1984]
create-all-blacks 1 [set name "Jonah Lomu" set pos "Winger"
set weight 119 set height 196 set debut 1994]
create-all-blacks 1 [set name "Doug Howlett" set pos "Winger"
set weight 93 set height 185 set debut 2000]
create-all-blacks 1 [set name "Joe Rokocoko" set pos "Winger"
set weight 98 set height 189 set debut 2003]
end
Atrybuty agentów moŋna ģatwo zmieniæ. Na przykģad moŋna zmieniæ tģo, ustawiając kolor ģaty dla wszystkich poprawek na biaģy (zamiast domyķlnej czerni) w następujący sposób:
ask patches
[set pcolor white] ;; make background full of white patches
Niektóre wbudowane atrybuty poprawek są wspóģrzędnymi okreķlonymi przez pxcor i pycor, a takŋe ich kolorowymi kolorami. Podobnie, ŋóģwie i linki mają wbudowane zmienne xcor, ycor i color. Zauwaŋ, ŋe chociaŋ agenci ģaty nie mogą poruszaæ się jak agenci ŋóģwia, ģatki mają zdefiniowane przez uŋytkownika atrybuty, a takŋe mają zdolnoķæ do kieģkowania agentów (analogia moŋe dotyczyæ nowych królików wychodzących z dziury w ziemi). Z tego powodu ģaty są uwaŋane za rodzaj agenta, który jest statyczny (pozostaje w jednym miejscu), a nie dynamiczny (ma zdolnoķæ poruszania się jak robią to ŋóģwie). Zwróæ teŋ uwagę, ŋe rozmiar ģatek moŋna zmieniæ. Programista moŋe zmieniæ rozmiar, klikając przycisk Ustawienia na ekranie interfejsu. Pojawi się lista ustawieņ modelu, które okreķlają rozmiar (w liczbie poprawek) ķrodowiska i jego ukģadu wspóģrzędnych, czy ķrodowisko owija się poziomo i / lub pionowo, rozmiar poprawki w pikselach, ksztaģty ŋóģwia, rozmiar czcionki dla etykiet na agentach i to, czy licznik jest
widoczny, czy nie. Jako kolejny przykģad, poniŋszy kod rysuje zewnętrzną częķæ pustego labiryntu 2D, który jest wyķrodkowany na wspóģrzędnych (0,0) i ma wejķcie na ķrodku dna labiryntu i wyjķcie w ķrodkowym szczycie. Kod wykorzystuje pięæ globalnych zmiennych - lewych kolców, prawych kolejek, górnych wierszy, dolnych i wejķciowych - które okreķlają liczbę kolumn (poziome ģatki) po lewej i prawej stronie linii x = 0, liczbę rzędy (pionowe ģatki) powyŋej i poniŋej linii y = 0 oraz szerokoķæ w ģatach wejķcia. Wartoķci tych zmiennych moŋna zmieniæ na ekranie Interfejsu, jak pokazano na rysunku
; Empty Maze Demo
;
; Demo Pustego Labiryntu
;
; Rysuje pusty labirynt z wejķciem na ķrodkowym dole i wyjķciem
; na ķrodku góry
; ustaw pusty labirynt na (0,0)
to setup-empty-maze
ca ;; clear everything
ask patches
[
set pcolor white ;; zrób tģo peģne biaģych ģat
if (pxcor >= (- left-cols - entrance-cols) and
pxcor <= (- entrance-cols) and pycor = (- below-rows))
[set pcolor blue] ;; rysuje dolną lewą poziomą ķcianę na niebiesko
if (pxcor >= (entrance-cols) and
pxcor <= (right-cols + entrance-cols) and pycor = (- below-rows))
[set pcolor blue] ;; rysuje dolną prawą poziomą ķcianę na niebiesko
if (pxcor >= (- left-cols - entrance-cols) and
pxcor <= (- entrance-cols) and pycor = (above-rows))
[set pcolor blue] ;; rysuje lewą górną poziomą ķcianę na niebiesko
if (pxcor >= (entrance-cols) and
pxcor <= (right-cols + entrance-cols) and pycor = (above-rows))
[set pcolor blue] ;; rysuje lewą górną poziomą ķcianę na niebiesko
if (pxcor = (- left-cols - entrance-cols) and
pycor >= (- below-rows) and pycor <= (above-rows))
[set pcolor blue] ;; rysuje lewą pionową ķcianę na niebiesko
if (pxcor = (right-cols + entrance-cols) and
pycor >= (- below-rows) and pycor <= (above-rows))
[set pcolor blue] ;; rysuje prawą pionową ķcianę na niebiesko
]
end
Dane wyjķciowe generowane przez program przedstawiono na rysunku powyŋej. Ustawienia to max-pxcor 50, maxpycor 50 i Patch size 3
Rysowanie labiryntów za pomocą Agentów Ģaty NetLogo
"Labirynt to celowo myląca seria ķcieŋek lub przejķæ prowadzących do okreķlonego punktu i zaprojektowana tak, aby ŋycie byģo trudne, z duŋą iloķcią faģszywych wiórów, ķlepych zauģków i puģapek. Labirynty są bardzo stare - w mitologii greckiej Minotaur zostaģ uwięziony w labiryncie - i nadal moŋna go znaležæ w ogrodach wielkich domów, takich jak sģynny labirynt w Hampton Court Palace".Juliet i Charles Snape, The Fantastic Book Book. Labirynt ŋywopģotu w Chevening House, Anglia, ok. 1820, byģ jednym z pierwszych ķwiadomie zaprojektowanych, by zapewniæ bardziej zģoŋoną ģamigģówkę i udaremniæ zasadę "rąk na ķcianie" do rozwiązywania labiryntów. Rysowanie labiryntów wymaga zazwyczaj więcej wysiģku niŋ proste kod podany w NetLogo Code do rysowania pustego labiryntu. Cytat na górze tego rozdziaģu odnosi się do Labiryntu Paģacu Hampton Court, sģynnego labiryntu ogrodowego w Anglii. Stylizowany widok z lotu ptaka labiryntu bliŋej jego rzeczywistego ksztaģtu pokazano na rysunku poniŋej . Zamiast rysowaæ na zewnątrz tego labiryntu najpierw i byæ moŋe wciągnąæ do ķrodka w pewien sposób moŋemy przyjąæ inne rozwiązanie. W NetLogo moŋemy uŋywaæ ģatek do rysowania ķcian i okreķlaæ kaŋdą ķcianę tam i z powrotem przez labirynt w sposób zygzakowaty, najpierw definiując wszystkie poziome ķciany, a następnie wszystkie pionowe ķciany. Kod NetLogo, który wykorzystuje to rozwiązanie do narysowania schematu mapy obiektu Hampton Court Place Maze pokazanego po lewej stronie rysunku poniŋej, jest wymieniony w NetLogo Code.
; Demo labiryntu w Hampton Court
;
; Rysuje schematyczną mapę labiryntu Hampton Court
; ustaw labirynt na (0,0)
to setup-row [row colour segments]
foreach segments
[
if pycor = row * row-patches-width and
(pxcor >= col-patches-width * (item 0 ?)) and
(pxcor <= col-patches-width * (item 1 ?))
[set pcolor colour]
]
end
to setup-col [col colour segments]
foreach segments
[
if pxcor = col * col-patches-width and
(pycor >= row-patches-width * (item 0 ?)) and
(pycor <= row-patches-width * (item 1 ?))
[set pcolor colour]
]
end
to setup-hampton-maze
ca ;; clear everything
ask patches
[
if (pxcor >= min-pxcor and pxcor <= max-pxcor and
pycor >= min-pycor and pycor <= max-pycor)
[set pcolor white] ;; zrób tģo peģne biaģych ģat
setup-row 5 blue [[-9 10]]
setup-row 4 blue [[-8 -5] [-3 -1] [0 3] [5 9]]
setup-row 3 blue [[-7 -4] [-2 2] [4 8]]
setup-row 2 blue [[-6 -1] [1 4] [5 7]]
setup-row 1 blue [[-3 3] [8 9]]
setup-row 0 blue [[-8 -7] [9 10]]
setup-row -1 blue [[-9 -8]]
setup-row -2 blue [[-8 -7] [-3 0] [1 3]]
setup-row -3 blue [[-4 -1] [2 4] [6 8]]
setup-row -4 blue [[-7 -1] [1 9]]
setup-row -5 blue [[-8 10]]
setup-row -6 blue [[-9 0] [1 10]]
setup-col 10 blue [[-6 5]]
setup-col 9 blue [[-4 -1] [1 4]]
setup-col 8 blue [[-3 1] [2 3]]
setup-col 7 blue [[-2 2]]
setup-col 6 blue [[-4 1]]
setup-col 5 blue [[-3 2]]
setup-col 4 blue [[-3 2] [3 5]]
setup-col 3 blue [[-2 1] [2 4]]
setup-col 1 blue [[-4 -2]]
setup-col 0 blue [[-5 -2] [1 3]]
setup-col -1 blue [[-4 -3] [4 5]]
setup-col -3 blue [[-2 1] [2 4]]
setup-col -4 blue [[-3 2] [3 5]]
setup-col -5 blue [[-4 1]]
setup-col -6 blue [[-3 2]]
setup-col -7 blue [[-4 -3] [-2 0] [1 3]]
setup-col -8 blue [[-5 -2] [0 4]]
setup-col -9 blue [[-6 5]]
]
end
Patrząc na mapę i obraz na powyŋszym rysunku , jest oczywiste, ŋe mapa nie przedstawia dokģadnie prawdziwego labiryntu ŋycia. (Czytelnik moŋe to ģatwo zweryfikowaæ za pomocą Google Earth). Mapa jest "schematem", który znieksztaģca relacje między obiektami istniejącymi w rzeczywistym ķrodowisku ŋycia, które reprezentuje, w podobny sposób, jak Londyņska Mapa Podziemna nie odzwierciedla dokģadnie prawdziwych odlegģoķci i relacji geograficznych w systemie kolei podziemnej Londynu. Odksztaģcenia są wyražnie widoczne, ale waŋne jest, aby zdaæ sobie sprawę, ŋe znieksztaģcenia są charakterystyczne dla wszystkich map, których celem jest przedstawienie rzeczywistego ķrodowiska ŋycia. Nawet dokģadne mapy topograficzne lub orientacyjne będą miaģy znieksztaģcenia ze względu na skalę, w wyniku szerokoķci wymaganej do narysowania kaŋdego z symboli na mapie. Na przykģad autostrady rysowane na mapach topograficznych nie są narysowane w skali - gdyby tak byģo, to w rzeczywistoķci autostrady musiaģyby mieæ setki metrów ķrednicy. Ponadto kaŋda mapa będzie zawieraģa bģędy (i zwykle wiele). Na przykģad mapa po lewej stronie na Rysunku 3.7 ma krótką ķcianę wystającą pod kątem prostym w poģowie wysokoķci ķciany lewej labiryntu, podczas gdy w rzeczywistoķci ŋywopģot jest ciągģy bez ostrych kątów. Jednak pomimo tych znieksztaģceņ i bģędów, mapa moŋe byæ ģatwo wykorzystana jako pomoc w nawigacji - osoby korzystające z mapy mają wiedzę, jak szybko dostaæ się do centrum labiryntu (celu), nie popeģniając bģędu. Zauwaŋ, ŋe będziemy uŋywaæ map jako podstawowego bloku konstrukcyjnego w rozdziale 9 do opisywania wiedzy i koncepcji - dwóch waŋnych aspektów budowania agenta ze sztuczną inteligencją. Przeanalizujmy teraz kod w powyŋszym kodzie NetLogo , który rysuje mapę na rysunku powyŋszym. Moŋemy uproķciæ, definiując najpierw ogólne procedury narysowania linii poziomych lub pionowych, z lukami w nich. Procedury setup_row i setup_col przyjmują cztery parametry jako dane wejķciowe - numer wiersza (wiersza) lub kolumny (col), gdzie narysowana jest linia segmentów ģatki, szerokoķæ wiersza i szerokoķæ_kolumny, czyli szerokoķæ liczby poprawek okreķlających szerokoķæ zarówno wierszy, jak i kolumn w labiryncie (zachowamy je tak samo dla tego przykģadu), a segmenty - listę pozycji początkowych i koņcowych, które okreķlają, gdzie kaŋdy segment ģat zaczyna się i koņczy w tej samej linii. Reszta kodu rysuje kaŋdy wiersz i kolumnę w labiryncie (poziome i pionowe linie, które przedstawiają ŋywopģoty w labiryncie). Zauwaŋ, ŋe istnieje wiele sposobów na narysowanie labiryntu. W NetLogo nie musimy korzystaæ z agentów ģatek do rysowania - moŋemy zamiast tego uŋyæ agenta z ŋóģwiami, aby ŋóģw przesunąģ się bezpoķrednio nad liniami ŋywopģotu, rysując je tak, jak to się dzieje. Ograniczeniem NetLogo jest jednak to, ŋe to co rysuje agent ŋóģwia, nie moŋe byæ "widziane" przez inne ŋóģwie i ģaty - nie mają one zdolnoķci wyczuwania rysunków ani reagowania na nie. Poniewaŋ chcemy w przyszģoķci wykorzystaæ te labirynty aby zademonstrowaæ, w jaki sposób moŋna zaprogramowaæ ucieleķnionego agenta, aby je przeszukaæ, wymagamy umiejętnoķci, aby inni agenci mogli wyczuæ, gdzie są ŋywopģoty w ķrodowisku wirtualnym. Równieŋ przyjęta tutaj metoda rysowania poziomych ŋywopģotów, po których następują pionowe ŋywopģoty, nie musi byæ najskuteczniejsza na pokrytej odlegģoķci, poniewaŋ ŋóģw przemieszcza się dwukrotnie w ķrodowisku 2D. Jednakŋe, jeķli czynnik ŋóģwia jest widoczny (to znaczy, ŋe ŋóģw jest animowany), zachowanie czynnika ŋóģwia jest ģatwo zauwaŋalne dla obserwatora - uŋyteczna cecha, która pomaga uczyniæ rozwiązanie ģatwiejszym do zrozumienia i debugowania. Rozszerzeniem moŋe byæ uŋycie wielu agentów - na przykģad jeden ŋóģw moŋe zostaæ uŋyty do narysowania poziomych ķcian, a drugi do narysowania pionowych. Jeķli kaŋdy agent jest zaimplementowany jako wątek, oba mogą byæ wykonywane jednoczeķnie, co zmniejsza o poģowę czas wykonania, jeķli liczba poziomych ķcieŋek jest równa liczbie pionowych ķcieŋek. Jednak NetLogo nie implementuje agentów ŋóģwia jako osobnych wątków, więc nie ma przewagi przy korzystaniu z wielu agentów w tym przypadku. Labirynt Hampton Court to po prostu poģączony labirynt. Ludzki agent, który przyjmuje zachowanie ręki na ķcianie, zawsze będzie mógģ dostaæ się do ķrodka labiryntu (celu). Labirynt Chevening House w Anglii zbudowany w 1820 roku byģ jednym z pierwszych labiryntów, które byģy wielokrotnie poģączone (to znaczy, ŋe w labiryncie jest jedna lub więcej "wysp", które są odizolowane od siebie, caģkowicie odģączone od zewnętrznej ķciany) . Schematyczną mapę labiryntu pokazano na rysunku

Labirynt zostaģ narysowany przy uŋyciu kodu NetLogo wymienionego w poniŋszym kodzie NetLogo
to setup-chevening-house-maze
ca ;; wyczyķæ wszystko
ask patches
[
if (pxcor >= min-pxcor and pxcor <= max-pxcor and
pycor >= min-pycor and pycor <= max-pycor)
[set pcolor white] ;; zrób tģo peģne biaģych ģat
setup-row 12 blue[[-11 12]]
setup-row 11 blue [[-10 11]]
setup-row 10 blue [[-9 10]]
setup-row 9 blue [[-8 0] [1 9]]
setup-row 8 blue [[-7 -1] [2 8]]
setup-row 7 blue [[-6 0] [1 7]]
setup-row 6 blue [[-5 0] [1 6]]
setup-row 5 blue [[-4 -1] [2 5]]
setup-row 4 blue [[-3 0] [1 4]]
setup-row 3 blue [[-2 3]]
setup-row 2 blue [[-1 2]]
setup-row 1 blue [[-9 -5] [-4 -2] [3 5] [6 8] [10 11]]
setup-row -0 blue [[-9 -7] [3 5] [6 10]]
setup-row -1 blue [[-1 0] [1 2] [7 9]]
setup-row -2 blue [[-2 0] [1 3]]
setup-row -3 blue [[-3 -1] [1 4]]
setup-row -4 blue [[-4 -2] [2 5]]
setup-row -5 blue [[-5 -3] [2 6]]
setup-row -6 blue [[-6 -3] [1 7]]
setup-row -7 blue [[-7 -2] [0 8]]
setup-row -8 blue [[-8 1] [3 9]]
setup-row -9 blue [[-9 0] [3 10]]
setup-row -10 blue [[-10 -1] [2 11]]
setup-row -11 blue [[-11 0] [1 12]]
setup-col 12 blue [[-11 12]]
setup-col 11 blue [[-10 1] [2 11]]
setup-col 10 blue [[-9 0] [1 10]]
setup-col 9 blue [[-8 -1] [0 9]]
setup-col 8 blue [[-7 -2] [1 8]]
setup-col 7 blue [[-6 -1] [2 7]]
setup-col 6 blue [[-5 0] [1 6]]
setup-col 5 blue [[-4 0] [1 5]]
setup-col 4 blue [[-3 -1] [2 4]]
setup-col 3 blue [[-2 0] [1 3]]
setup-col 2 blue [[-10 -7] [-1 2]]
setup-col 1 blue [[-11 -8] [-6 -1] [4 6] [7 9]]
setup-col 0 blue [[-11 -9] [-7 -1] [4 6] [7 9]]
setup-col -1 blue [[-8 -3] [-1 2]]
setup-col -2 blue [[-7 -4] [-2 0] [1 3]]
setup-col -3 blue [[-3 1] [2 4]]
setup-col -4 blue [[-4 0] [1 5]]
setup-col -5 blue [[-5 6]]
setup-col -6 blue [[-6 0] [2 7]]
setup-col -7 blue [[-7 0] [1 8]]
setup-col -8 blue [[-8 -1] [2 9]]
setup-col -9 blue [[-9 0] [1 10]]
setup-col -10 blue [[-10 11]]
setup-col -11 blue [[-11 12]]
]
end-
przy uŋyciu tego samego podejķcia, co powyŋej, do rysowania poziomych zabezpieczeņ, a następnie pionowych zabezpieczeņ. Jedyną róŋnicą jest to, ŋe szerokoķæ rzędów ģat i szerokoķci kolumn zostaģa wybrana jako dwa razy większa niŋ globalna wielkoķæ poprawki, aby mapa bardziej odzwierciedlaģa schematyczne mapy prawdziwego labiryntu, które moŋna znaležæ w Internecie. Jeķli podąŋymy za wszystkimi ķcianami wychodzącymi ze ķrodka labiryntu, okaŋe się, ŋe te ķciany nie są w ŋaden sposób poģączone z zewnętrzną ķcianą. W konsekwencji zachowanie "ręka w ķcianę" nie będzie juŋ wystarczająco dobre dla rozwiązania labiryntu. Celem tego drugiego przykģadowego labiryntu jest zilustrowanie, w jaki sposób zachowanie wģaķciwe dla jednego ķrodowiska moŋe nie byæ odpowiednie dla innego ķrodowiska (takiego jak nowe ķrodowisko lub kiedy zmieniģo się oryginalne ķrodowisko). Aby agent mógģ nadal osiągaæ okreķlony cel, agent musi dostosowaæ (lub nauczyæ się), aby poradziæ sobie ze zmienionym ķrodowiskiem. Zbadamy zachowanie i
istotną rolę, jaką będzie odgrywaæ póžniej dla autonomicznych agentów
Podsumowanie
Ta sekcja stanowi wprowadzenie do języka programowania NetLogo. NetLogo to przykģad typu modelowania opartego na agentach zwanego symulacją ukierunkowaną na agenta, która ģączy agentów z symulacją. NetLogo jest ģatwy do nauczenia i debugowania, zaprojektowane z myķlą o niedoķwiadczonych programistach.
Ruch
"Zmiana oznacza ruch. Ruch oznacza tarcie. Jedynie w pozbawionej tarcia próŋni nieistniejącego abstrakcyjnego ķwiata ruch lub zmiana moŋe nastąpiæ bez tego tarcia ķcierającego się konfliktu. " Saul Alinsky.
Ruch
Ruch jest podstawowym zadaniem wykonywanym przez autonomicznego agenta znajdującego się w otoczeniu. Sposób, w jaki agent przesuwa swoje ciaģo i sposób, w jaki porusza się po swoim otoczeniu, determinuje wiele jego zachowaņ. Typy interakcji agent-ķrodowisko i interakcji między agentami moŋliwe są równieŋ w wyniku rodzajów ruchów, które są moŋliwe dla agenta. W fizyce ruch odnosi się do ciągģej zmiany poģoŋenia ciaģa w wyniku uŋycia siģy lub siģ, które są do niego przyģoŋone. Ciaģo w ruchu moŋna scharakteryzowaæ przez jego prędkoķæ, przyspieszenie, przemieszczenie i czas. Ciaģo, które się nie porusza, mówi się, ŋe jest w spoczynku lub nieruchomo (nieruchomo). Ruch jest mierzony (obserwowany) zgodnie z ukģadem odniesienia w oparciu o ruch obserwatora. Nie ma bezwzględnego ukģadu odniesienia - zgodnie z danym ukģadem odniesienia ciaģo moŋe wydawaæ się nieruchome, ale porusza się takŋe względem nieskoņczonej liczby innych ram odniesienia. Dlatego wszystko we wszechķwiecie moŋna uwaŋaæ za ciągģe. Ruch jest podstawą wielu powszechnych metafor uŋywanych w ludzkim języku. Nasze zrozumienie jako czģowieka wywodzi się z podstawowych pojęæ przestrzeni, względnej pozycji, ruchu i ruchu, w tym takŋe z ruchu wģasnego, który jest związany z naszym fizycznym ucieleķnieniem i usytuowaniem w rzeczywistym ķwiecie. Często wyraŋamy i rozumiemy abstrakcyjne pojęcia, których nie moŋemy dotknąæ ani zobaczyæ w oparciu o te podstawowe pojęcia.
Ruch agentów ŋóģwia w NetLogo
Programowanie ŋóģwia w NetLogo w celu wykonywania róŋnych poleceņ jest proste i bardzo intuicyjne. Polecenie "pen-up" sģuŋy do przesuwania pióra do góry, więc dopóki nie zostanie wywoģane polecenie, nic nie zostanie narysowane na ekranie. Metody wielkoķci pisaka i koloru okreķlają szerokoķæ i kolor pisaka. Polecenie w przód powoduje, ŋe ŋóģw przesuwa się o okreķloną liczbę kroków w kierunku, w którym jest skierowany, a lewy i prawy powoduje, ŋe ŋóģw obraca się o okreķlony kąt odpowiednio w lewo lub w prawo. Tabela poniŋej zawiera listę dostępnych metod
Metoda : Opis
Aby zmieniæ ķrodowisko
clear-all (ca) : Czyķci wszystko w ķrodowisku, w tym wszystkie ŋóģwie, ģaty, linki, wykresy i rysunki oraz resetuje zmienne do 0.
clear-drawing : Usuwa wszystkie rysunki wykonane przez agentów ŋóģwia
Do przemieszczania ŋóģwia
forward d or fd d : Przesuwa ŋóģwia przed krokami d w zaleŋnoķci od bieŋącego kierunku.
back d or bk d : Powoduje cofnięcie ŋóģwia o krok d na podstawie bieŋącego kierunku.
right a or rt a : Wģącza ŋóģw w prawo o podany kąt a w stopniach.
left a or lt a : Obróæ ŋóģwia o okreķlony kąt a w stopniach.
setxy x y : Przenosi ŋóģwia z bieŋącej pozycji do pozycji absolutnej na wspóģrzędnych (x, y) i rysuje linię, jeķli pióro jest opuszczone.
set xcor x : Ustawia wspóģrzędną x ŋóģwia na x (utrzymuj wspóģrzędną y niezmienioną).
set ycor y : Ustawia wspóģrzędną y ŋóģwia na y (zachowaj wspóģrzędną x niezmienioną).
set heading a : S Ustawia kierunek, w którym ŋóģw stoi zwrócony pod kątem ? w stopniach.
move-to agent : Ustawia wspóģrzędne (x, y) na takie same, jak dla agenta.
face agent : Ustawia nagģówek w kierunku agenta.
facexy x y : Ustawia nagģówek na wspóģrzędne (x, y)
Aby powróciæ lub ustawiæ stan ŋóģwia
xcor : Wbudowana zmienna ŋóģwia. Posiada x wspóģrzędną ŋóģwia.
ycor : Wbudowana zmienna ŋóģwia. Zawiera wspóģrzędną ŋóģwia.
heading : Wbudowana zmienna ŋóģwia. Zawiera bieŋący kurs ŋóģwia.
towards agent lub towardsxy x y : Podaje nagģówek od bieŋącego agenta w kierunku danego agenta lub nagģówek do wspóģrzędnych (x, y).
distance agent lub distancexy x y : Zwraca odlegģoķæ do ŋóģwia lub ģatki lub odlegģoķæ do wspóģrzędnych (x, y).
show-turtle lub st : Sprawia, ŋe ŋóģw jest widoczny.
hide-turtle lub ht : Sprawia, ŋe ŋóģw jest niewidoczny.
hidden? : Zwraca True, jeķli ŋóģw nie jest widoczny, Faģsz w przeciwnym razie
Aby kontrolowaæ pióro do rysowania
pen-down lub pd : Przesuņ pióro tak, aby ŋóģw rysowaģ, gdy się porusza.
pen-up lub pu : Pociągnij pióro tak, aby ŋóģw nie narysowaģ niczego podczas ruchu.
pen-erase lub pe : Pchnij gumkę w dóģ, aby ŋóģw usunąģ linie podczas ruchu.
pen-mode : Wbudowana zmienna ŋóģwia. Posiada stan pióra ŋóģwia - wartoķci są "up", "down" i "erase".
pemn-size : Wbudowana zmienna ŋóģwia. Utrzymuje szerokoķæ pióra ŋóģwia w pikselach.
color : Wbudowana zmienna ŋóģwia. Posiada kolor ŋóģwia lub ogniwa.
Metody zostaģy pogrupowane w metody związane ze ķrodowiskiem, przemieszczaniem się ŋóģwia, jego stanem i rysunkiem. Te trzy ostatnie grupy metod wpģywają lub determinują zachowanie ŋóģwia. Pomimo prostoty projektu, skomplikowane ksztaģty i obrazy są bardzo ģatwe do zaprogramowania. Programowanie z grafiką ŋóģwia jest intuicyjne, poniewaŋ wykorzystuje zorientowaną na agenta pierwszą perspektywę projektowania - wszystko jest rysowane z perspektywy samego ŋóģwia.
Zachowanie i podejmowanie decyzji w zakresie ruchu
Moŋemy przyjąæ perspektywę projektowania, ŋe kaŋde zachowanie agenta moŋe byæ zdefiniowane lub scharakteryzowane pod względem ruchów, które eksponuje w otoczeniu. Aspekty zachowania agenta obejmują sposób poruszania się agenta, dokąd agent się przemieszcza, kiedy agent decyduje się przenieķæ, co wybiera agent, i dlaczego agent decyduje się wykonaæ konkretny ruch związany z podejmowaniem decyzji. Z punktu widzenia projektowania moŋemy przyjąæ analogię przy projektowaniu naszych systemów zorientowanych na agentów, ŋe podejmowanie decyzji to ruch z jednego miejsca do innego otoczenia i jest podobne do ruchu w prawdziwym ŋyciu. Przemieszczanie się w prawdziwych ķrodowiskach wyražnie prowadzi do zmiany poģoŋenia geograficznego. Ruch w ķrodowiskach wirtualnych spowoduje, ŋe stan wewnętrzny ķrodowiska zostanie w jakiķ sposób zmieniony (na przykģad zmieniana jest wirtualna pozycja bota gry). W oparciu o tę analogię moŋemy zdefiniowaæ sposób podejmowania decyzji w następujący sposób. Agent przejawia zachowanie przy podejmowaniu decyzji, gdy zdecyduje się przejķæ wzdģuŋ jednej konkretnej ķcieŋki, gdy dostępne są dla niej ķcieŋki alternatywne. Jest to analogiczne do ruchu w prawdziwym ŋyciu. Moŋemy równieŋ uŋyæ n-wymiarowego ķrodowiska przestrzeni do reprezentowania procesu decyzyjnego w agentach w sposób abstrakcyjny. Moŋemy rozwaŋyæ proces podejmowania decyzji dla agenta jako przechodzenia z jednego stanu wewnętrznego do drugiego, gdzie stan jest reprezentowany jako pojedynczy punkt w przestrzeni n-wymiarowej. Jest to równowaŋne reprezentowaniu zachowania za pomocą skoņczonej maszyny stanów (FSM) (zwanej równieŋ automatem skoņczonym lub FSA). FSM jest modelem zachowania z ograniczoną pamięcią wewnętrzną, którą moŋna konceptualizowaæ jako skierowany wykres skģadający się z wielu stanów (wierzchoģków lub węzģów na wykresie), przejķæ między tymi stanami (krawędzie na wykresie) oraz czynnoķci wykonywane przy wchodzeniu lub wychodzeniu ze stanu lub podczas przejķcia. Prosty FSM do opisu zachowania samochodu jest przedstawiony na rysunku poniŋej.
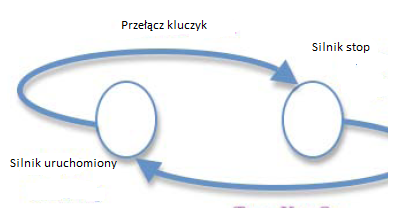
Istnieją dwa stany - oznaczone jako "Silnik uruchomiony" i "Silnik stop - oznaczające, kiedy silnik samochodu jest uruchomiony lub zatrzymany, oraz dwie akcje przejķcia - oznaczone "Przeģącz kluczyk" - w celu przeniesienia FSM z jednego stanu do drugiego. Ograniczymy się do dziaģaņ, które mają miejsce tylko podczas przemian, aby wzmocniæ analogię między podejmowaniem decyzji a ruchem. Moŋemy myķleæ o punkcie w ķrodowisku decyzyjnym agenta, analogicznym do stanu w maszynie o skoņczonym stanie. Moŋemy równieŋ myķleæ o poruszaniu się po ķcieŋce w ķrodowisku decyzyjnym agenta jako analogii do przejķcia i przeprowadzania przejķcia dziaģanie w skoņczonej maszynie stanów. Decyzje, w których agent po osiągnięciu okreķlonego punktu lub stanu nie ma innego wyboru, jak wykonaæ okreķlone dziaģanie, nazywa się determinizmem. Decyzje, w których agent moŋe dokonaæ wyboru między zestawem alternatywnych dziaģaņ, są okreķlane jako niedeterministyczne.
Rysowanie FSM i drzew decyzyjnych za pomocą agentów linków w NetLogo
Moŋemy uŋywaæ agentów linków w NetLogo do rysowania FSM. Będziemy takŋe uŋywaæ podobnego kodu do rysowania drzew decyzyjnych, co stanowi kolejną metodę reprezentowania zachowania. W tym tomie okaŋe się to przydatne, szczególnie w opisie wykorzystania animacji do zademonstrowania dynamicznego zachowania i do reprezentowania wiedzy. Przykģadowy kod do wizualizacji prostego dwustanowego FSM pokazano w kodzie NetLogo.
breed [agents agent]
breed [points point]
directed-link-breed [curved-paths curved-path]
agents-own [location] ;; ma rację
to setup
clear-all ;; wyczyķæ wszystko
set-default-shape points "circle"
create-points 1 [setxy -15 0 set label "Light off "] ;; punkt 0
create-points 1 [setxy 15 0 set label "Light on "] ;; punkt 1
ask points [set size 5 set color blue]
ask point 0 [create-curved-path-to point 1]
ask point 1 [create-curved-path-to point 0]
ask curved-paths [set thickness 0.5]
set-default-shape curved-paths "curved path"
ask patches [
;; nie pozwól widzowi zobaczyæ tych poprawek; sģuŋą tylko
;; do wyķwietlania etykiet w osobnych wierszach
set plabel-color brown
if (pxcor = 11 and pycor = 8) [set plabel "Move light switch down"]
if (pxcor = 11 and pycor = -8) [set plabel "Move light switch up"]
]
create-agents 1 [
set color lime
set size 5
set location point 0 ;; start od punktu 0
move-to location
]
Zrzut ekranu przedstawiono na rysunku poniŋej.
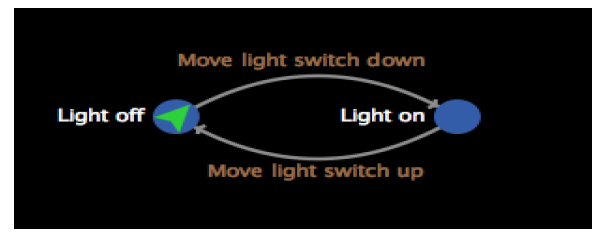
Dwustanowy FSM przedstawia, co się dzieje, gdy ķwiatģo musi byæ wģączane i wyģączane. W pierwszym stanie ķwiatģo jest wyģączone, a przejķcie do drugiego stanu, gdy ķwiatģo jest wģączone, wymaga od agenta wykonania czynnoķci przesunięcia przeģącznika ķwiatģa w dóģ. Gdy ķwiatģo jest wģączone, wymagane jest przeciwne dziaģanie przeģączania ķwiatģa, aby ponownie powróciæ do pierwszego stanu . FSM narysowany przez kod skģada się z dwóch stanów oznaczonych odpowiednio "Light off" i "Light on". Stany są reprezentowane jako agenci ŋóģwia, którzy się nie poruszają - to jest mają ustalony punkt w ķrodowisku (stąd te są zdefiniowane jako naleŋące do punktów rasy agenta ŋóģwia.) Są dwa ogniwa, reprezentowane jako zakrzywione ķcieŋki od pierwszego punktu stanu 0 do drugiego punktu stanu 1, a następnie z powrotem. Te linki są oznaczone jako "Przenieķ przeģącznik ķwiatģa w dóģ" i "Przenieķ przeģącznik ķwiatģa w górę" odpowiednio i reprezentują czynnoķæ, którą agent musi wykonaæ, przechodząc z jednego stanu do następnego. Kod definiuje równieŋ agenta zwanego agentem ŋóģwia. Moŋemy uŋyæ tego agenta do animacji FSM przy uŋyciu kodu wymienionego w NetLogo Code , pokazując, w jaki sposób agent moŋe poruszaæ się w obie strony między dwoma stanami.
to go
ask links [ set thickness 0.5 ]
ask agents [
let new-location one-of [out-link-neighbors] of location
;; zmieņ gruboķæ ģącza, które przekroczę
ask [link-with new-location] of location [ set thickness 1.1 ]
face new-location
move-to new-location
set location new-location
]
tick
end
Kod dziaģa poprzez wybranie jednego z out-outów bieŋącego stanu odwiedzanego przez agenta ŋóģwia (w tym przykģadzie zawsze będzie tylko jeden link wychodzący). Następnie program zwiększa gruboķæ ģącza, do którego wkrótce się przeniesie, a agent znajdzie się w nowej lokalizacji, a następnie przeniesie się do niego. Bardziej zģoŋony przykģad FSM pokazano na rysunku
FSM modeluje etapy cyklu ŋycia, które ludzie przechodzą w swoim ŋyciu, i opiera się na modelu zaproponowanym przez Jobbera. (Model Jobbera dziaģa od lewej do prawej, podczas gdy poniŋszy model przebiega od góry do doģu, aby zmieķciæ się w granicach ķrodowiska graficznego 2D NetLogo). W modelu osoba zaczyna się na etapie "Pojedynczy, w domu", a następnie moŋe przejķæ do etapu "Mģody, na swoim" lub etapu "Mģoda, para, bez dzieci". Stamtąd osoba moŋe przejķæ do wielu dalszych etapów, ostatecznie koņcząc na etapie "Samotny, na emeryturze" na dole. Ŋycie to nie tylko linearny postęp. Celem tego modelu jest zrozumienie, jak to zrobiæ. Model NetLogo uŋyty do wytworzenia tego FSM oŋywia model, tworząc liczbę agentów dla kaŋdego tiknięcia (suwak pokazany w lewym górnym rogu Figury 3 moŋe byæ uŋyty do kontrolowania zmiennej "narodziny-kaŋdy-tyk", na figurze to zostaģo ustawione w 2). Kaŋdy agent przechodzi następnie z jednego stanu do drugiego - groty koloru wapna narysowane w niektórych stanach pokazują ich bieŋącą
lokalizację. Agenci losowo dokonują wyboru, gdy dostępnych jest więcej niŋ jedno przejķcie wychodzące. Wykres po lewej pokazuje, jak ogólna populacja (oznaczona "Wszystkie") zmienia się w zaleŋnoķci od kleszczy. Na dziaģce pokazane są równieŋ aktualne liczby agentów zlokalizowanych na etapie "Mģodzi, rodzice" oraz na etapach "Samotni, emeryci". Drzewo decyzyjne jest często uŋywane do reprezentowania zachowaņ decyzyjnych. Drzewo to skierowany wykres bez pętli w sieci, z tylko jedną ķcieŋką między dwoma węzģami i z kaŋdym węzģem mającym jeden lub więcej węzģów podrzędnych, ale pojedynczy węzeģ nadrzędny lub węzeģ gģówny, bez ŋadnego rodzica. Liķcie drzewa są węzģami bez ķcieŋek wychodzących. W drzewie decyzyjnym podejmowanie decyzji przez agenta rozpoczyna się od węzģa gģównego drzewa i wybiera ķcieŋki wychodzące w oparciu o konkretną decyzję związaną z bieŋącym węzģem i trwa do momentu, aŋ zostaną osiągnięte liķcie drzewa. Liķæ, który jest osiągnięty, zwykle reprezentuje w pewien sposób wynik podjętych
decyzji - na przykģad, moŋe byæ uŋyty do klasyfikacji, gdzie drzewo decyzyjne dziaģa w podobny sposób do popularnej gry towarzyszącej Twenty Questions (np. przez postacie z powieķci Charlesa Dickensa "A Christmas Carol"). W tej grze pierwszy gracz musi odgadnąæ obiekt - zwykle zwierzęcy, roķlinny lub mineralny - o którym drugi gracz myķli. Pierwszy gracz moŋe zadaæ do dwudziestu pytaņ dotyczących danego obiektu, podczas gdy drugi gracz musi podaæ tylko odpowiedzi "Tak" lub "Nie". Pierwszy gracz musi opracowaæ odpowiednie pytania, aby wystarczająco zawęziæ obszar poszukiwaņ, aby odgadnąæ, o co chodzi w danym obiekcie, zanim uŋyje swoich dwudziestu pytaņ, w przeciwnym razie gra zostanie utracona. Przykģad drzewa decyzyjnego pokazano na rysunku poniŋej
Tego drzewa decyzyjnego moŋna uŋywaæ do odgadywania ptaków nowozelandzkich. W grze Dwadzieķcia pytaņ moŋe to byæ poprzedzone zestawem oķmiu pytaņ i odpowiedzi w następujący sposób: "Czy to zwierzę?" [Tak], "Czy to ssak?" [Nie] "Czy to ptak?" [Tak], "Czy to ptak z póģkuli póģnocnej?" [Nie], "Czy to ptak afrykaņski czy poģudniowoamerykaņski?" [Nie], "Czy to ptak Australasian?" [Tak], "Czy to ptak australijski? ? "[Nie]," Czy to ptak nowozelandzki? "[Tak]. Drzewo decyzyjne zadaje kolejne cztery pytania do odgadnięcia między oķmioma nowozelandzkimi ptakami wymienionymi na dole drzewa. Moŋemy uŋyæ kodu NetLogo podobnego do tego, który zostaģ opracowany do rysowania FSM, aby takŋe rysowaæ drzewa decyzyjne. Kaŋdy węzeģ w drzewie moŋe byæ reprezentowany w podobny sposób do stanu w FSM, ze ķcieŋkami między węzģami reprezentowanymi przez przejķcia między linkami. W kodzie pokazanym w NetLogo Code poniŋej
breed [agents agent]
breed [points point]
directed-link-breed [straight-paths straight-path]
agents-own [location] ;; ma rację
points-own [question] ;; to jest pytanie związane z węzģem
straight-paths-own [answer] ;; ķcieŋki przejķcia definiują odpowiedzi na pytanie do skonfigurowania
clear-all ;; wyczyķæ wzystko
set-default-shape points "circle 2"
create-points 1 [setxy 5 35 set question "Czy ptak lata?"]
;; punkt 0, level 0 (root)
create-points 1 [setxy -25 25 set question "Czy to papuga?"]
;; punkt 1, level 1
create-points 1 [setxy 35 25 set question "Czy ptak wyginąģ?"]
;; punkt 2, level 1
create-points 1 [setxy -40 15 set question "Ptak alpejski?"]
;; punkt 3, level 2
create-points 1 [setxy -10 15 set question "Pokrzewka"]
;; punkt 4, level 2
create-points 1 [setxy 20 15 set question "Czy to jest duŋe?"]
;; punkt 5, level 2
create-points 1 [setxy 50 15 set question "Dģugi dziób?"]
;; punkt 6, level 2
create-points 1 [setxy -50 5 set question "Kea?"]
;; punkt 7, level 3
create-points 1 [setxy -30 5 set question "Kaka?"]
;; punkt 8, level 3
create-points 1 [setxy -20 5 set question "Tui?"]
;; punkt 9, level 3
create-points 1 [setxy 0 5 set question "Pukeko?"]
;; punkt 10, level 3
create-points 1 [setxy 10 5 set question "Moa?"]
;; punkt 11, level 3
create-points 1 [setxy 30 5 set question "Huia?"]
;; punkt 12, level 3
create-points 1 [setxy 40 5 set question "Kiwi?"]
;; punkt 13, level 3
create-points 1 [setxy 60 5 set question "Weka?"]
;; punkt 14, level 3
ask patches [
;; nie pozwól widzowi zobaczyæ tych poprawek; sģuŋą tylko do
;; wyķwietlania etykiet w osobnych wierszach
if (pxcor = 1 and pycor = 35) [set plabel [question] of point 0]
if (pxcor = -29 and pycor = 25) [set plabel [question] of point 1]
if (pxcor = 30 and pycor = 25) [set plabel [question] of point 2]
if (pxcor = -44 and pycor = 15) [set plabel [question] of point 3]
if (pxcor = -14 and pycor = 15) [set plabel [question] of point 4]
if (pxcor = 16 and pycor = 15) [set plabel [question] of point 5]
if (pxcor = 46 and pycor = 15) [set plabel [question] of point 6]
if (pxcor = -48 and pycor = 0) [set plabel [question] of point 7]
if (pxcor = -27 and pycor = 0) [set plabel [question] of point 8]
if (pxcor = -18 and pycor = 0) [set plabel [question] of point 9]
if (pxcor = 4 and pycor = 0) [set plabel [question] of point 10]
if (pxcor = 12 and pycor = 0) [set plabel [question] of point 11]
if (pxcor = 32 and pycor = 0) [set plabel [question] of point 12]
if (pxcor = 42 and pycor = 0) [set plabel [question] of point 13]
if (pxcor = 63 and pycor = 0) [set plabel [question] of point 14]
]
ask points [set size 5 set color blue]
ask point 0 [create-straight-path-to point 1]
ask point 0 [create-straight-path-to point 2]
ask point 1 [create-straight-path-to point 3]
ask point 1 [create-straight-path-to point 4]
ask point 2 [create-straight-path-to point 5]
ask point 2 [create-straight-path-to point 6]
ask point 3 [create-straight-path-to point 7]
ask point 3 [create-straight-path-to point 8]
ask point 4 [create-straight-path-to point 9]
ask point 4 [create-straight-path-to point 10]
ask point 5 [create-straight-path-to point 11]
ask point 5 [create-straight-path-to point 12]
ask point 6 [create-straight-path-to point 13]
ask point 6 [create-straight-path-to point 14]
ask straight-paths [set label-color lime]
ask straight-path 0 1 [set answer "Yes" set label answer]
ask straight-path 0 2 [set answer "No" set label answer]
ask straight-path 1 3 [set answer "Yes" set label answer]
ask straight-path 1 4 [set answer "No" set label answer]
ask straight-path 2 5 [set answer "Yes" set label answer]
ask straight-path 2 6 [set answer "No" set label answer]
ask straight-path 3 7 [set answer "Yes" set label answer]
ask straight-path 3 8 [set answer "No" set label answer]
ask straight-path 4 9 [set answer "Yes" set label answer]
ask straight-path 4 10 [set answer "No" set label answer]
ask straight-path 5 11 [set answer "Yes" set label answer]
ask straight-path 5 12 [set answer "No" set label answer]
ask straight-path 6 13 [set answer "Yes" set label answer]
ask straight-path 6 14 [set answer "No" set label answer]
;; pytaj punkty [stwórz ķcieŋkę z jednym z innych punktów]
;; uģóŋ go tak, aby linki się nie nakģadaģy
ask straight-paths [ set thickness 0.5 ]
a
create-agents 1 [
set color lime
set size 5
set location point 0 ;; start at point 0
move-to location
]
ask links [ set thickness 0.5 ]
end
jest piętnaķcie stanów reprezentowanych przez punkty agenta ŋóģwia od 0 do punktu 14, które definiują węzģy w drzewie i czternaķcie przejķæ poķrednich, które definiują ķcieŋki między węzģami. Tak jak poprzednio, kod definiuje agenta zwanego agentem agenta ŋóģwia, a my moŋemy równieŋ uŋyæ tego agenta, aby pokazaæ, w jaki sposób drzewo decyzyjne jest wykonywane w zaleŋnoķci od decyzji podjętych przy uŋyciu kodu wymienionego w poniŋszym kodzie NetLogo.
to go
ask agents [
let neighbours [out-link-neighbors] of location
let user-question [question] of location
let answers [] ;; all the answers for current node
let answers-points []
;; (punkty, do których agent powinien przejķæ w zaleŋnoķci od odpowiedzi)
let parent-point location
ask [out-link-neighbors] of location [
let this-link in-link-from parent-point
let this-answer [answer] of this-link
set answers fput this-answer answers
set answers-points fput self answers-points
]
ifelse empty? answers
;; jesteķmy w węžle liķcia
[ let user-answer user-one-of user-question ["No" "Yes"]
ifelse user-answer = "Yes"
[ user-message "Excellent! Let's try another bird."]
[ user-message "Sorry, I cannot guess what the bird is."
user-message "Let's try another bird." ]
set location point 0 ;; Go back to the beginning
ask links [ set thickness 0.5 ]
;; (zresetuj przejķcia, aby nie wyķwietlaģa się wybrana ķcieŋka)
]
;;w przeciwnym razie jesteķmy w węžle wewnętrznym
[ let user-answer user-one-of user-question answers
let pos position user-answer answers
let new-location item pos answers-points
;; zmieņ gruboķæ ģącza, które skrzyŋuję, aby pokazaæ
;; wybraną ķcieŋkę
ask [link-with new-location] of location [ set thickness 1.1 ]
face new-location
move-to new-location
set location new-location
]
]
tick
end
Kod dziaģa poprzez wybranie ģącza wyjķciowego, które odpowiada odpowiedzi udzielonej przez odpowiedž uŋytkownika na pytanie związane z bieŋącym stanem odwiedzanym przez agenta ŋóģwia. Jeķli zostanie osiągnięty węzeģ liķcia i przypuszczenie jest poprawne, program odpowiada komunikatem "Excellent! Spróbujmy innego ptaka". "W przeciwnym razie odpowiada wiadomoķciami uŋytkownika" Przepraszam, nie mogę odgadnąæ, co to jest ptak. "I" Spróbujmy innego ptaka. Drzewa decyzyjne i FSM to dwa sposoby reprezentowania zachowania autonomicznych agentów. W powyŋszych przykģadach kodu NetLogo, jeķli postrzegamy zachowanie jako ruch przeprowadzony w abstrakcyjnym ķrodowisku, to związek między ruchem a zachowaniem jest jasny. Ramka odniesienia lub punkt obserwacji obserwatora jest zatem waŋnym aspektem zachowania, który naleŋy wziąæ pod uwagę. Na przykģad, jeķli agent ma zdolnoķæ podejmowania decyzji, to ma pewną autonomię i dlatego ma moŋliwoķæ poruszania się. Istnieją róŋne rodzaje zachowaņ, takie jak komunikacja, wyszukiwanie i rozumowanie, które chcemy zbadaæ. Chcemy widzieæ, ŋe ruch agentów w ķrodowisku jest wspólnym elementem wszystkich tych zachowaņ.
Animacja komputerowa
Animacja komputerowa to proces manipulowania wyķwietlanymi obrazami, aby stworzyæ iluzję ruchu. Zģudzenie optyczne jest spowodowane zjawiskiem oka zwanym "uporczywoķcią widzenia", w którym oko zachowuje wraŋenie obrazu przez krótki czas po jego zniknięciu. Animacja komputerowa wykorzystuje róŋnorodne techniki. Tradycyjne podejķcie polega na pokazaniu kolejnych obrazów z kaŋdym obrazem nieznacznie róŋniącym się od jednego obrazu do drugiego. Animacja komputerowa jest waŋna dla badaņ nad sztuczną inteligencją, poniewaŋ moŋe sģuŋyæ nie tylko do tworzenia symulacji agentów komputerowych w celu sprawdzenia wiarygodnoķci ich zachowania w ķrodowiskach wirtualnych, ale takŋe do tworzenia modeli umoŋliwiających przewidywanie zachowania agentów rzeczywistych, takich jak ludzie i roboty. W powyŋszych przykģadach NetLogo zastosowaliķmy juŋ podstawowe techniki animacji komputerowej, aby podkreķliæ związek między ruchem a zachowaniem

Biblioteka modeli NetLogo udostępnia model przykģadu Animacja ksztaģtu, aby zilustrowaæ, jak uŋywaæ ksztaģtów do tworzenia animacji. Edytor ksztaģtów ŋóģwi zostaģ uŋyty do stworzenia dziewięciu róŋnych ksztaģtów osób i szesnastu róŋnych ksztaģtów kwiatów. Model dziaģa poprzez sukcesywne pokazywanie róŋnych ksztaģtów z jednej ramki do drugiej. Zapewnia to prymitywną formę animacji podobną do tej, która jest tworzona przy uŋyciu podręcznego podręcznika (zwanego takŋe flip book), często uŋywanego w ilustrowanych ksiąŋkach dla dzieci, które zawierają serię obrazów, które zmieniają się stopniowo z jednej strony na drugą i które stają się animacją, kiedy szybko się zmienia.
Kod modelu znajduje się poniŋej w Kodzie NetLogo. Model definiuje dwatypyy - kwiaty i osoby. Po naciķnięciu przycisku Go program wywoģuje procedurę animacji wielokrotnie z prędkoķcią okreķloną przez zmienną globalną secinds-per-frame. Animowana procedura najpierw wywoģuje polecenie move-person , która po prostu wybiera następny ksztaģt osoby do wyķwietlenia i przesuwa się do przodu o niewielką iloķæ, następnie wywoģuje procedurę age-flower, który ustawia ksztaģt kaŋdego ŋóģwia kwiatowego do następnego ksztaģtu w sekwencji, a następnie w koņcu kieģkuje nowy kwiat 20% czasu wywoģania procedury.
breed [ flowers flower ]
breed [ people person ] ;; putting people last ensures people appear
;; przed kwiatami w widoku
people-own [frame] ;; zakres od 1 do 9
flowers-own [age] ;; zakres od 1 do 16
to setup ;; wykonywane po naciķnięciu przycisku SETUP
clear-all ;; usuņ wszystkie ģatki i ŋóģwie
create-people 1 [
set heading 90 ;; tj. w prawo
set frame 1
set shape "person-1"
]
end
to go
every seconds-per-frame [
animate
tick
]
end
to animate
move-person
ask flowers [ age-flower ]
if random 100 < 20
[ make-flower ]
end
to move-person
ask people [
set shape (word "person-" frame)
forward 1 / 20
;; Edytor ksztaģtów ma siatkę podzieloną na 20 kwadratów, które przy ustawieniu
;; rysunek wykonany dla uŋytecznych punktów odnoszących się do nogi i buta, do
;; sprawiają, ŋe stopa przesuwa się o jeden kwadrat do tyģu
;; w kontakcie z ziemią (w stosunku do osoby), ale
;; z prędkoķcią względną 0, gdy porusza się do przodu o 1/20 przesunięcia w przód
;; zaģataæ kaŋdą ramkę
set frame frame + 1
if frame > 9
[ set frame 1 ] ;; wróæ do początku cyklu klatek animacji
]
end
to age-flower ;; procedura kwiatowa
set age (age + 1)
; wiek sģuŋy do ķledzenia, ile lat ma kwiat
;; kaŋda starsza roķlina jest nieco wyŋsza z odrobiną
;; większe liķcie i kwiat.
if (age >= 16) [ set age 16 ]
;; mamy tylko 16 klatek animacji, więc przestaņ mieæ 16 lat6
set shape (word "flowexr-" age)
end
to make-flower
;; jeķli na kaŋdej ģatce jest kwiat, zabij ich wszystkich
;; i zacząæ od nowa
if all? patches [any? flowers-here]
[ ask flowers [ die ] ]
;; teraz, gdy jesteķmy pewni, ŋe mamy miejsce, w rzeczywistoķci zrobimy nowy kwiat
ask one-of patches with [not any? flowers-here] [
sprout 1 [
set breed flowers
set shape "flower-1"
set age 0
set color one-of [magenta sky yellow]
]
]
end
Jako kolejny przykģad, poniŋszy kod NetLogo ilustruje, w jaki sposób zapewniæ iluzję ludzkiej postaci stick idącej po ekranie. Program polega na ciągģym losowaniu szeķciu nieznacznie róŋnych figurek, z których kaŋda róŋni się tylko pozycją dģoni i nóg.
breed [paths path] ;; ŋóģwie, które rysują koņczyny i prostą ciaģa
;; postaæ jako poģączona ķcieŋka
breed [circle-paths circle-path] ;; do rysowania gģowy
to setup
clear-all
create-paths 5 [initialize-paths] ;; ķrodki do rysowania ķcieŋek dla czterech koņczyn
;; (dwie nogi, dwie ręce) oraz ciaģo
set-default-shape paths "circle" ;; to jest ksztaģt ŋóģwia dla
;; rysowanie ķcieŋki
ifelse forward-movement-increment > 0
[draw-stick-figure -56 0 [160 7 170 7] [190 7 200 7] [165 7 130 5]
[19 7 130 5] [0 0 0 12]]
;;jeszcze
[draw-stick-figure 56 0 [160 7 170 7] [190 7 200 7] [165 7 130 5]
[195 7 130 5] [0 0 0 12]]
end
to initialize-paths
pen-up
set size 0
set pen-size 4
end
to initialize-circle-paths
pen-up
set size 0
set pen-size 8
end
to go
let frame 1
let xpos forward-movement-increment
ifelse forward-movement-increment > 0
[set xpos xpos - 56]
;;jeszcze
[set xpos xpos + 56]
while [xpos > -57 and xpos < 57]
[
if clear-display-in-between
[clear-drawing]
let front-leg item (frame mod 6) [[160 7 170 7] [170 7 180 7]
[180 7 190 7] [190 7 200 7] [180 7 190 7] [170 7 180 7]]
let back-leg item (frame mod 6) [[190 7 200 7] [180 7 190 7]
[170 7 180 7] [160 7 170 7] [170 7 180 7] [180 7 190 7]]
let front-arm item (frame mod 6) [[165 7 130 5] [173 7 125 5]
[187 7 125 5] [195 7 130 5] [187 7 125 5] [173 7 125 5]]
let back-arm item (frame mod 6) [[195 7 130 5] [187 7 125 5]
[173 7 125 5] [165 7 130 5] [173 7 125 5] [187 7 125 5]]
let body [0 0 0 12] ;; body does not change orientation
draw-stick-figure xpos 0 front-leg back-leg front-arm back-arm body
set frame frame + 1
set xpos xpos + forward-movement-increment
tick
]
end
to draw-limb [limb-color top-x top-y specs]
;; rysuje koņczynę dla sylwetki kija zgodnie ze specyfikacjami
;; góra koņczyny jest na wspóģrzędnych top-x, top-y
;; zģącze ķrodkowe jest rysowane w nagģówku [specyfikacja pozycji 0] o dģugoķci
;; [specyfikacja pozycji 1]
;; spód koņczyny jest rysowany w nagģówku [specyfikacja pozycji 2] od zģącza z
;; dģugoķæ [specyfikacja pozycji 3]
let dir-to-joint item 0 specs
let joint-length item 1 specs
let dir-to-bot item 2 specs
let bot-length item 3 specs
pen-up
set color limb-color
set size 1.5
setxy top-x top-y
pen-down
stamp
if joint-length > 0 [
set heading dir-to-joint
forward joint-length
stamp
]
set heading dir-to-bot
forward bot-length
stamp
pen-up
end
to draw-stick-figure [xpos ypos front-leg back-leg front-arm back-arm body]
;; narysuj figurę w następującej kolejnoķci, tak aby przednia noga
;; a ramiona pojawiają się przed tylną nogą i rękami
ask path 0 [draw-limb gray xpos ypos back-leg] ;; tylna noga
ask path 3 [draw-limb gray xpos ypos + 12 back-arm] ;; tylen ramię
ask path 1 [draw-limb white xpos ypos front-leg] ;; przednia ręka
ask path 2 [draw-limb white xpos ypos body] ;; ciaģo
ask path 4 [draw-limb white xpos ypos + 12 front-arm] ;; przednie ramie
create-circle-paths 1 [initialize-circle-paths]
set-default-shape circle-paths "circle 2"
ask circle-path 5 [setxy xpos 15 set size 6 set color white stamp]
end
Program wykorzystuje dwa typy ŋóģwi do rysowania ķcieŋek, jedną za pomocą linii prostych do rysowania koņczyn i ciaģa, a drugą za pomocą okrągģej ķcieŋki do rysowania gģowy. Kod opiera się na dwóch podstawowych procedurach - draw-limb i l draw-stick-figure. Procedura draw-limb sģuŋy do rysowania koņczyny, ręki lub nogi, poprzez narysowanie ķcieŋki skģadającej się z trzech punktów - punktów początkowych, ķrodkowych i koņcowych - z dwiema liniami prostymi ģączącymi punkt ķrodkowy z pozostaģymi dwoma punktami. Parametr limb-color sģuŋy do okreķlenia, jaki kolor rysowane są punkty i linie. Moŋna go uŋyæ do nadania gģębi figurze przy uŋyciu jaķniejszego koloru (na przykģad white) dla koņczyn przednich i jaķniejszego koloru dla koņczyn tylnych (gray). Dla wygody procedura jest równieŋ stosowana jako rysunek ciaģa jako pojedynczej linii. Procedura draw-stick-figure rysuje figurkę, najpierw rysując tylną nogę i ramię, a następnie przednią nogę, następnie ciaģo i przednie ramię, a na koņcu gģowę. W procedurze gģównej go wielokrotnie powtarzana jest procedura draw-stick-figure z szeķcioma róŋnymi specyfikacjami, które okreķlają nieco inne pozycje koņczyn. Model Stick Figure Animation idzie dalej i pozwala uŋytkownikowi tworzyæ wiele figurek i przemieszczaæ je tak, jak pokazano na rysunku 4.8. Program pozwala uŋytkownikowi zarejestrowaæ migawkę ekranu jako "ramkę", a następnie odtworzyæ wszystkie klatki na raz w celu utworzenia sekwencji animacji.
Model dziaģa poprzez nagrywanie klatek w nowatorski sposób. Zamiast przechowywaæ informacje o ŋóģwiach i linkach w kaŋdej klatce osobno, tworzone są nowe kopie ŋóģwia i agentów linków, a stare kopie są następnie ukrywane przed przeglądarką. Innymi sģowy, wszystkie stare ramki nadal istnieją w ķrodowisku - uŋytkownik po prostu nie widzi ich wszystkich. Powiązany z kaŋdym agentem jest dodatkowa informacja do przechowywania numeru klatki podczas jej nagrywania. To jest następnie uŋywane do okreķlenia, kiedy kaŋdy agent powinien byæ wizualizowany podczas sekwencji animacji. Sposób wykonania tej czynnoķci przedstawiono w kodzie NetLogo
breed [points point] ; punkty związane z postacią prostej
breed [heads head] ; dla rysowania gģowy
breed [sides side] ; cztery boki kwadratu wyboru
turtles-own
[ frame ; numer klatki ŋóģw jest powiązany z
child ] ; kopią ŋóģwia dla następnej klatki
links-own [link-frame] ; liczba ramek, z którymi link jest powiązany
globals
[ frames ; ile ramek do tej pory
selected ] ; zestaw agenta aktualnie wybranych obiektów
to start-recording
clear-all
set frames 0 ; jak dotąd brak ramek
set-default-shape points "circle" ; to jest ksztaģt punktów
set-default-shape heads "circle 2"
;aki jest ksztaģt gģowy postaci
set-default-shape sides "line"
; jest to ksztaģt boków wybranego regionu
;; początkowo nie wybrano ŋadnych ŋóģwi
set selected no-turtles
end
to record-this-frame
; rejestruje bieŋącą ramkę, kopiując wszystkich agentów i ģącza,
; czyniąc ich wszystkich niewidocznymi, a następnie zwiększając ich liczbę klatek
let this-child nobody
let that-child nobody
let this-colour white
let this-thickness 1
let this-frame 0
ask turtles with [frame = frames]
[ ; nagraj wszystkie ŋóģwie w tej ramce dla potomnoķci
hatch 1 ; zrób nową kopię tego ŋóģwia na następną klatkę
[ set frame frames + 1
set this-child self ]
set child this-child
hide-turtle ; uczyņ starą kopię niewidoczną
]
ask turtles with [frame = frames]
[ ; nagraj równieŋ wszystkie ich linki dla potomnoķci
set this-child child
ask my-links
[ ; skopiuj ten link
set that-child [child] of other-end
set this-colour color
set this-thickness thickness
ask this-child ; zrób nową kopię tego linku do następnej klatki
[ setup-link that-child this-colour this-thickness (frames + 1) ]
hide-link ; uczyņ starą kopię niewidoczne
]
]
set frames frames + 1
end
to setup-link [ this-turtle colour this-thickness this-frame ]
; do skonfigurowania ģącza
create-link-with this-turtle
[
set link-frame this-frame
set thickness this-thickness
set color colour
]
end
to play-frames
; tworzy animację, odtwarzając wszystkie klatki, które zostaģy
; zarejestrowane jako niewidzialne ŋóģwie i linki
let this-frame 0
while [this-frame <= frames]
[ ; wyķwietl wszystkie klatki po kolei
ask turtles [ hide-turtle ] ; najpierw ukryj wszystkie ŋóģwie
ask links [ hide-link ] ; ukryj równieŋ poģączonych
ask turtles with [frame = this-frame]
[ show-turtle ]
ask links with [link-frame = this-frame]
[ show-link ]
display
wait frame-delay
set this-frame this-frame + 1
]
end
Kod definiuje trzy typy agentów: points, okreķlające, gdzie ręce, ģokcie, stopy, kolana, szyja i dóģ są dla postaci; head, do okreķlenia, gdzie jest gģowa; i sides, uŋywane do wybierania agentów ŋóģwia podczas edycji. Następnie definiuje trzy procedury związane z przyciskami start-recording, record-frame i play-frames w lewym górnym rogu interfejsu modelu. Wszyscy agenci ŋóģwie (tj. gģowy i punkty) posiadają dwie zmienne: frame, która jest numerem ramki podczas tworzenia obiektu; i child, które jest uŋywane przez procedurę record-this-frame, aby pomóc w kopiowaniu powiązaņ między agentami ŋóģwia. W efekcie jest to wskažnik od napastnika do agenta podrzędnego, gdy agenci i ģącza są kopiowane podczas tej procedury. Sģuŋy do zapewnienia powiązaņ między agentami potomnymi równolegle do ģączy między agentami macierzystymi po ich skopiowaniu. Macierzyķci agenci stają się niewidzialni. Procedura play-frames wykonuje następnie animację, zwiększając liczbę klatek i wyķwietlając tylko tych agentów i ģącza, które mają
bieŋący numer klatki, podczas gdy wszystko inne staje się niewidoczne. Chociaŋ kod dla tego jest stosunkowo prosty, nie jest to najbardziej efektywny sposób wykonywania animacji - cyklicznie przechodzi przez wszystkich agentów z kaŋdej klatki, co moŋe spowolniæ animację, jeķli liczba agentów i ramek jest duŋa. Opóžnienie jest równieŋ dodawane w celu spowolnienia animacji - moŋna to kontrolowaæ za pomocą suwaka frame-delay w interfejsie modelu. Procedura start_recording po prostu usuwa ķrodowisko, ustawia domyķlne ksztaģty dla kaŋdego z agentów i ustawia zmienną globalną selected na pusty zestaw agentów ŋóģwi. Ta zmienna jest uŋywana podczas edycji, gdy mysz jest kliknięta lub przeciągnięta, aby pokazaæ, które ŋóģwie zostaģy wybrane do przemieszczania się lub do usunięcia. Kod do tego moŋna znaležæ w modelu, podąŋając za linkiem URL poniŋej. Zwróæ uwagę, ŋe ten model uŋywa tego samego kodu, co w przypadku mapy.
Animowane mapowanie i symulacja
Celem map jest przedstawienie sposobu reprezentowania tego, co istnieje w ķrodowisku. Wiele map, takich jak mapy topograficzne, to statyczne reprezentacje ķrodowiska - reprezentują tylko obiekty, których poģoŋenia się nie zmieniają. Jednak ķrodowiska są zwykle dynamiczne z punktu odniesienia obserwatora, gdzie pozycje agentów i obiektów zmieniają się stale wraz z upģywem czasu. Oczywiķcie, potrzebujemy jakiejķ metody reprezentowania agentów i obiektów w ruchu, jeķli chcemy odpowiednio reprezentowaæ ķrodowisko, kiedy je mapujemy. Jednym z rozwiązaņ opracowanych od 1950 roku jest "animowane mapowanie", które ģączy animację komputerową z mapowaniem. Animację moŋna zdefiniowaæ jako szybkie wyķwietlanie obrazów 2D lub 3D w celu stworzenia iluzji scen ruchu. W mapowaniu animowanym mapa sģuŋy do reprezentowania statycznych relacji istniejących w ķrodowisku, a następnie nakģadana jest na animację w celu odzwierciedlenia zmian zachodzących w ķrodowisku w czasie. Wizualizacja umoŋliwia oglądanie historycznych wydarzeņ i zmianę skali czasowej - albo poprzez przyspieszenie animacji, aby byģa szybsza niŋ w czasie rzeczywistym, albo poprzez jej spowolnienie. Zmieniając sekwencję zdarzeņ i wypróbowując róŋne scenariusze (to znaczy pytając pytania typu "co jeķli", takie jak "co by się staģo, gdyby do tego doszģo ...?"), Wizualizacja bardziej przenosi się w symulację niŋ odwzorowywanie. Rola symulacji polega na naķladowaniu lub modelowaniu systemów naturalnych lub ludzkich lub na okreķleniu moŋliwych konsekwencji zestawu dziaģaņ wykonywanych przez agentów lub moŋliwych przyszģych pozycji obiektów w ruchu. Gģówną rolą mapowania jest reprezentowanie jak najbliŋszej istniejącej relacji ķrodowiskowej, ale kolejną rolą jest wykorzystanie jej do przewidywania, co moŋe nastąpiæ w przyszģoķci za pomocą symulacji. Niektóre przykģady animowanego mapowania to wizualizacja spadku Arktyki Lodowiec i Lodowa Grenlandia w ostatnich latach, rozprzestrzenianie się cywilizacji i wzrost populacji w ciągu ostatnich dwóch stuleci, oraz przewidywane ķcieŋki huraganów, jak często są pokazywane na kanaģach pogodowych. Animacja zapewnia moŋliwoķæ dodania kolejnego wymiaru czasu, który jest trudny do przedstawienia na mapach statycznych, i obejmuje zmienne, takie jak czas trwania, szybkoķæ zmiany i jej poģoŋenie, zdarzenia kolejnoķci, czas wystąpienia zmian, częstotliwoķæ i synchronizacja. Korzystanie z animowanych map w Internecie zwiększa się, gdy uŋytkownik ma moŋliwoķæ obserwowania, jak zmiany zachodzą w czasie i gdzie uŋytkownik moŋe równieŋ manipulowaæ róŋnymi parametrami, takimi jak punkt widzenia, szybkoķæ zmian i typ danych wizualizowanych. . Biblioteka modeli w NetLogo zawiera równieŋ przykģady animowanego mapowania. Model Wielkiego Kanionu symuluje opady na wschodnim kraņcu Wielkiego Kanionu (gdzie Kanion Szalonego Dziadka i Saddle Canyon spotykają się, tworząc Kanion Tapeats). Kaŋda ģata w symulowanym ķrodowisku odpowiada obszarowi okoģo 32 m na kaŋdej stronie i jest oparta na danych z National Elevation Dataset dostępnego pod adresem http://seamless.usgs.gov.
Na rysunku poniŋej pokazano dwa zrzuty ekranu po tym, jak model w oddzielnych symulacjach wykonano odpowiednio dla 50 tików i 100 tików, przy oporze ustalonym na 10 kropli na zaznaczenie. Symulacja reprezentuje wyŋsze poziomy w lŋejszych kolorach i niŋszych rzędach w ciemniejszych kolorach. jak krople deszczu pģyną od jaķniejszej do ciemniejszej, i zacznij tworzyæ kaģuŋe wody w miejscach, gdzie niŋsza kraina jest otoczona wyŋszym lądem.
Kolejnym modelem NetLogo, który wykorzystuje animowane mapowanie, jest model Continental Divide. Celem tego modelu jest wykazanie, w jaki sposób dzieli się kontynentalny kontynent, oddzielający kontynent od tego, w jaki sposób deszcz w oddzielnych regionach wpģywa do dwóch zbiorników wodnych. Przykģadem uŋytym w symulacji jest kontynent póģnocnoamerykaņski, a dwa zbiorniki wodne to oceany Pacyfiku i Atlantyku. Rysunek 4.10 pokazuje cztery zrzuty ekranu przy róŋnych tikach - przy 0 kleszczach (górny lewy), 407 kleszczach (prawy górny róg), 791 tyknięæ (lewy dolny róg) i 1535 tyknięæ (prawy dolny róg). W symulacji model jest inicjowany za pomocą mapy elewacji, a następnie oba oceany wzrastają przyrostowo, a dwie równiny zalewowe stopniowo zbliŋają się ku sobie wzajemnie na kontynencie, aŋ ostatecznie zderzają się ze sobą. Tam, gdzie zderzają się ze sobą, jest miejsce podziaģu kontynentalnego. Animowane mapowanie i symulacja równieŋ dają moŋliwoķæ przedstawienia wiedzy, która jest bardziej zbliŋona do usytuowania i realizacji w Sztucznej Inteligencji przyjętej u nas. Dalsze szczegóģy tego znajdują się w częķci 9. W następnych kilku częķciach będziemy równieŋ badaæ, w jaki sposób moŋemy uzyskaæ podstawowych agentów w NetLogo, aby wykonywaæ animowane ruchy i ruchy w prostych ķrodowiskach 2D oraz tworzyæ animowane labirynty. Przykģady z labiryntu zostaną wykorzystane w kolejnych rozdziaģach, aby pomóc w wyjaķnieniu waŋnych typów zachowaņ agenta, takich jak wyszukiwanie. Ponadto wszystkie modele NetLogo opisane w tych ksiąŋkach i znalezione w Bibliotece modeli moŋna uznaæ za przykģady animowanego mapowania i symulacji
Podsumowanie
Podkreķlono znaczenie przepģywu dla poģoŋonych agentów. Z perspektywy projektowania moŋemy scharakteryzowaæ zachowanie agenta i podejmowanie decyzji z punktu odniesienia obserwatora w kategoriach ruchów, które on eksponuje. Jeķli mamy mapowaæ ķrodowiska i zachowania w celu zaprojektowania zorientowane na agenta systemy sztucznej inteligencji, a następnie ruch musi zostaæ uwzględniony. Animacja map przedstawia jeden ze sposobów osiągnięcia tego. Podsumowanie waŋnych pojęæ, które naleŋy wyciągnąæ z tego rozdziaģu, pokazano poniŋej:
• *Ruch dla agenta dotyczy tego, w jaki sposób agent porusza swoim ciaģem i jak wybiera poruszanie się po ķrodowisku.
• *Ruch odnosi się do ciągģej zmiany poģoŋenia ciaģa w wyniku przyģoŋonych siģ. Ruch jest obserwowany od
• szczególny ukģad odniesienia. Wszystko jest w ciągģym ruchu w stosunku do nieskoņczonej liczby ram odniesienia.
• *Zachowanie usytuowanego agenta moŋna scharakteryzowaæ pod względem ruchu i ruchu w otoczeniu.
• *Animacja komputerowa opiera się na zjawisku oka zwanym "uporczywoķcią widzenia", aby zapewniæ iluzję ruchu.
• *Animowane mapy i symulacja są przydatnymi narzędziami do reprezentowania i wizualizacji dynamicznych ķrodowisk
Ucieleķnienie
"Nigdy tak naprawdę nie rozumiesz osoby, dopóki nie rozwaŋasz rzeczy z jego punktu widzenia - dopóki nie wejdziesz w jego skórę i nie przejdziesz przez nią. "Atticus Finch w "Zabiæ drozda" Harper Lee. 1960.
"Zasada koordynacji czuciowo-ruchowej stwierdza, ŋe wszelkie inteligentne zachowanie (na przykģad percepcja, kategoryzacja, pamięæ) ma byæ rozumiane jako koordynacja sensoryczno-ruchowa ... Zasada ma dwa gģówne aspekty. Pierwszy dotyczy przykģadu wykonania. Percepcja, kategoryzacja i pamięæ, procesy, które do tej pory byģy postrzegane tylko z perspektywy przetwarzania informacji, muszą byæ teraz interpretowane z perspektywy obejmującej procesy sensoryczne i motoryczne ...
Praktyczna realizacja odgrywa waŋną rolę w tej koordynacji ...
Drugim i bardziej szczegóģowym punktem tej zasady jest to, ŋe poprzez koordynację zmysģowo-ruchową ucieleķnione czynniki mogą strukturowaæ swój wkģad i tym samym wywoģywaæ regularnoķci, które znacznie upraszczają uczenie się. "Strukturyzacja danych wejķciowych" oznacza, ŋe poprzez interakcję z otoczeniem generowane są dane sensoryczne, które nie są po prostu dane." Rolf Pfeifer i Christian Scheier.
Nasze ciaģo i nasze zmysģy
Podobnie jak w przypadku ruchu w poprzedniej częķci, nasze ciaģo, umysģ i zmysģy stanowią podstawę wielu powszechnych metafor uŋywanych w ludzkim języku. Nasze zrozumienie jako czģowieka wywodzi się z podstawowych pojęæ związanych z naszym fizycznym ucieleķnieniem w realnym ķwiecie i zmysģów, których uŋywamy, aby je postrzegaæ. Często wyraŋamy i rozumiemy abstrakcyjne pojęcia, których nie moŋemy bezpoķrednio wyczuæ na podstawie tych podstawowych pojęæ. Tradycyjnie, stosując klasyfikację najpierw przypisaną Arystotelesowi, za pięæ gģównych zmysģów uwaŋa się za wzrok, sģuch, węch, smak i dotyk. Czasami ludzie odnoszą się równieŋ do "szóstego zmysģu" (czasami nazywanego takŋe pozazmysģową percepcją lub ESP) - moŋemy uznaæ to okreķlenie za metaforę, którą ludzie uŋywają w języku naturalnym do opisu nieķwiadomych procesów myķlowych w terminach innego sensu. Bģędem jest uwaŋanie "szóstego zmysģu" za rzeczywiste, poniewaŋ istnieje bardzo maģo naukowych dowodów na poparcie tego. Jednak nasze ciaģa faktycznie mają o
wiele więcej niŋ tylko pięæ podstawowych zmysģów, jak pokazuje wybór poniŋej
Zmysģ : Opis
Wzrok(widzenie) : Zdolnoķæ oka do wykrywania fal elektromagnetycznych. Mogą to w rzeczywistoķci byæ dwa lub trzy zmysģy jako róŋne recptory które sģuŋą do wykrywania koloru i jasnoķci oraz gģębokoķci percepcji (stereopsis) moŋe byæ funkcją poznawczą mózgu (to znaczy post-sensorycznego).
Sģuch (przesģuchanie) : Zdolnoķæ ucha do wykrywania wibracji spowodowanych džwiękiem.
Zapach (węch) : Zdolnoķæ nosa do wykrywania róŋnych cząsteczek zapachu.
Smak : Zdolnoķæ języka do wykrywania wģaķciwoķci chemicznych substancji takich jak ŋywnoķæ.Moŋe to byæ pięæ lub więcej róŋnych zmysģów, poniewaŋ do wykrywania sģuŋą róŋne receptory sģodki, kwaķny, sģony i gorzki smak.
Dotyk (mechanorecepcja) : Zdolnoķæ zakoņczenia nerwów, zwykle w skórze, do reagowania na zmiany ciķnienia (na przykģad, jak jest twardy, czy trwa lub czyķci się).
Ból (nocycepcja) : Zdolnoķæ odczuwania uszkodzenia lub uszkodzenia tkanki. Istnieją trzy rodzaje receptorów bólu - w skórze (skórne), w stawach i koķciach (somatyczne) i w ciele narządy (trzewne).
Równowaga (ekwilibriocepcja) : Zdolnoķæ ukģadu bģędnika przedsionkowego w uszach wewnętrznych do wyczuwania ciaģa ruch, kierunek i przyspieszenie oraz utrzymanie równowagi. Są dwa oddzielne zmysģy zaangaŋowane, aby wykryæ moment pędu i przyspieszenie liniowe (a takŋe grawitację).
Propriocepcja (zmysģ kinestetyki) : Zdolnoķæ do bycia ķwiadomym względnych pozycji częķci ciaģa (takich jak gdzie ręka jest w stosunku do nosa nawet przy zamkniętych oczach).
Poczucie czasu : Zdolnoķæ częķci mózgu do ķledzenia czasu, na przykģad dobowego (dziennego) rytmy lub krótkoterminowy (ultrasyjski) czasomierz.
Poczucie temperatury (termocepcja) : Zdolnoķæ skóry i wewnętrznych przejķæ skórnych do wykrywania ciepģa i jego braku ciepģo (na zimno).
Zmysģy wewnętrzne (interocepcja) : Zmysģy wewnętrzne, które są pobudzane z wnętrza ciaģa z licznych receptorów w narządy wewnętrzne (takie jak pģucne receptory rozciągające znajdujące się w pģucach, które kontrolują częstoķæ oddechów i inne wewnętrzne receptory związane z rumieņcem, poģykaniem, wymioty, rozszerzenie naczyņ krwionoķnych, rozszerzenie gazu w przewodzie pokarmowym i odruch wymiotny podczas jedzenia, na przykģad).
Kilka cech autonomicznych agentów
Z perspektywy projektowania moŋemy uznaæ kaŋdego agenta za w pewien sposób ucieleķniony, uŋywając zmysģów, aby uzyskaæ informacje o jego otoczeniu. Moŋemy zdefiniowaæ wykonanie w następujący sposób. Autonomiczny agent jest ucieleķniony poprzez jakąķ manifestację, która pozwala mu wyczuæ jego otoczenie. Jego ucieleķnienie dotyczy jego fizycznego ciaģa, które wykorzystuje do poruszania się po swoim otoczeniu, jego czujników, które wykorzystuje do uzyskiwania informacji o sobie w stosunku do ķrodowiska i jego mózgu który wykorzystuje do przetwarzania informacji zmysģowych. Agent istnieje jako częķæ ķrodowiska, a jego percepcja i dziaģania są okreķlane przez sposób, w jaki wspóģdziaģa on ze ķrodowiskiem i innymi agentami poprzez jego realizację w dynamicznym procesie. Wcielenie agenta moŋe polegaæ na fizycznej manifestacji w rzeczywistym ķwiecie, takim jak czģowiek, robot przemysģowy lub pojazd autonomiczny, lub moŋe mieæ symulowaną lub sztuczną manifestację w ķrodowisku wirtualnym. Jeķli zajmuje się wyģącznie abstrakcyjnymi informacjami, na przykģad agentem indeksowania stron WWW, takim jak Googlebot, to jego ķrodowisko moŋna z perspektywy projektowania reprezentowaæ jako przestrzeņ n-wymiarową, a jego moŋliwoķci wykrywania odnoszą się do ruchu wokóģ tej przestrzeni. Podobnie, rzeczywiste ķrodowisko dla czynnika ludzkiego lub zrobotyzowanego moŋe byæ uwaŋane za przestrzeņ n-wymiarową, a ucieleķnienie agenta odnosi się do jego zdolnoķci do uzyskiwania informacji o rzeczywistym ķrodowisku podczas poruszania się. Moŋemy uwaŋaæ ciaģo agenta za zmysģowe urządzenie do przechwytywania danych wejķciowych. Na przykģad zmysģy w ludzkim ciele są dyktowane przez jego ucieleķnienie - to znaczy, ŋe caģe ciaģo ma wiele czujników, które występują w caģym ciele, umoŋliwiając naszemu umysģowi uzyskanie "obrazu" caģego ciaģa, gdy oddziaģuje ono na ķrodowisko . Pfeiffer i Scheier podkreķlają waŋną rolę, jaką musi speģniaæ ucieleķnienie i koordynacja sensoryczno-motoryczna w okreķlaniu inteligentnego zachowania. Craig Reynolds opisuje dalsze cechy autonomicznych czynników, które moŋna wykorzystaæ do rozróŋnienia róŋnych klas autonomicznych czynników, takich jak usytuowanie i zachowanie reaktywne. Moŋemy zdefiniowaæ usytuowanie w następujący sposób. Autonomiczny agent znajduje się w swoim ķrodowisku, dzieląc się nim z innymi agentami i obiektami. Dlatego jego zachowanie jest okreķlane z perspektywy pierwszoosobowej przez jego interakcje między agentami oraz interakcje między agentami. Autonomous agents wykazują a zakres zachowaņ, od czysto reaktywnych do bardziej deliberatywnych lub kognitywnych. Mówi się, ŋe autonomiczny agent znajduje się w ķrodowisku wspóģdzielonym przez innych agentów i / lub innych obiekty. Agent moŋe byæ wyizolowany samodzielnie, na przykģad agent wyszukiwania danych wyszukujący wzorce w bazie danych znajdującej się w abstrakcyjnej n-wymiarowej przestrzeni reprezentującej ķrodowisko bazy danych. Umieszczony agent moŋe mieæ wiele zachowaņ, od czysto reaktywnych, gdy czynnik jest regulowany przez bodziec, który otrzymuje od swoich zmysģów, po funkcje poznawcze, gdzie agent rozwaŋa bodziec, który otrzymuje i decyduje o odpowiednich dziaģaniach. Przy czysto reaktywnym podejķciu agent nie musi utrzymywaæ reprezentacji ķrodowiska - ķrodowisko jest wģasną bazą danych, którą moŋe po prostu "sprawdziæ", bezpoķrednio z nią wspóģpracując. Z kolei agent poznawczy uŋywa reprezentacji tego, co dzieje się w ķrodowisku, aby podejmowaæ decyzje. Reynolds zauwaŋa, ŋe kombinacje atrybutów zawartych, usytuowanych i reaktywnych definiują odrębne klasy autonomicznych czynników, z których niektóre przedstawiono w tabeli poniŋej. Jednak, w przeciwieņstwie do Reynoldsa, będziemy uwaŋaæ, ŋe wszyscy agenci znajdują się w jakimķ ķrodowisku (czy jest to rzeczywiste, wirtualne lub abstrakcyjne ķrodowisko, reprezentowane przez jakąķ n-wymiarową przestrzeņ) i ucieleķnione dzięki zdolnoķci do odczuwania i interakcji ze swoim ķrodowiskiem w w jakiķ sposób, jawnie lub niejawnie
Typ agenta : Opis : Przykģad (y)
Ludzie i inni prawdziwi,ŋywi ,agenci : Organiczne byty, które istnieją w realnym ķwiecie. :My sami; stworzenia biologiczne.
Rzeczywiste autonomiczne roboty : Urządzenia mechaniczne, które znajdują się w prawdziwym ķwiecie. : Roboty w fabryce samochodów; pojazdy autonomiczne (AV).
Prawdziwe póģautonomiczne roboty : Urządzenia mechaniczne, które są częķciowo autonomiczne, a częķciowo obsģugiwany przez ludzie, usytuowani w prawdziwym ķwiecie. : Roboty marsjaņskie, Spirit i Opportunity; Roboty do usuwania bomb.
Agenci wirtualni : Prawdziwi agenci, którzy znajdują się w wirtualnym ķwiecie. : Nieodtwarzane postacie (NPC) w grach komputerowych
Wirtualni póģ-autonomiczni agenci : Ķrodki częķciowo autonomiczne, oraz częķciowo obsģugiwany przez ludzi, usytuowany w ķwiecie wirtualnym : Awatary; strzelanki pierwszoosobowe w gry komputerowe; agenci w sportowych grach symulacyjnych
Symulowani agencji : Agenci, którzy są badani metodami obliczeniowymi, symulacja usytuowana w wirtualnym ķwiecie. : Symulacje sztucznego ŋycia; symulacje robotów.
Dodanie moŋliwoķci wykrywania do Turtle Agents w NetLogo
Moŋemy zaprojektowaæ agentów ŋóģwi NetLogo wprowadzone w poprzedniej częķci, aby uwzględniæ moŋliwoķci wykrywania za pomocą wcielonej, usytuowanej perspektywy projektowania. Jednym z powodów tego jest to, ŋe chcielibyķmy uŋyæ agentów ŋóģwia do przeszukiwania labiryntów (a nie tylko ich narysowania), aby zademonstrowaæ zachowanie podczas wyszukiwania za pomocą animowanych technik mapowania. Wyszukiwanie jest waŋnym procesem, który agent musi wykonaæ, aby odpowiednio wykonywaæ wiele zadaņ. Jednak zanim agent będzie mógģ wyszukiwaæ, musi najpierw mieæ moŋliwoķæ wykrywania obiektów i innych agentów istniejących w ķrodowisku w celu znalezienia obiektu lub agenta, którego szuka. Bez trudu moglibyķmy zastosowaæ bezcielesne rozwiązanie do wyszukiwania w labiryncie. W tym podejķciu agent ŋóģwia przeprowadzający wyszukiwanie po prostu podąŋa ķcieŋkami, których ruch zostaģ wstępnie zdefiniowany w programie (podobnie jak w modelach rysunkowych labiryntu). Alternatywne, ucieleķnione podejķcie polega na tym, ŋe agent ŋóģwia jest zaprogramowany z moŋliwoķcią "patrzenia" w ķrodowisko labiryntu, interpretowania tego, co "widzi", a następnie wybierania ķcieŋki, którą chce podąŋaæ, nie ograniczając się do wstępnie zdefiniowanych ķcieŋek które byģy wymagane do rozwiązania bezcielesnego. Ģatwo zaprogramowane funkcje wykrywania często spotykane w animacjach komputerowych i silnikach gier komputerowych opierają się na detekcji bliskoķci. Tutaj agent "wyczuwa", czy w pobliŋu znajduje się obiekt, a następnie decyduje o odpowiednim zachowaniu w odpowiedzi. Model Look Ahead Example, który jest dostarczany wraz z biblioteką modeli NetLogo, implementuje agentów ŋóģwia z podstawową formą wykrywania bliskoķci, skutecznie symulując elementarną formę widzenia, przez co agenci "patrzą" przed siebie na niewielką odlegģoķæ w kierunku podróŋy, zanim zaczną się poruszaæ . Proces patrzenia w przyszģoķæ pozwala kaŋdemu agentowi ŋóģwia okreķliæ, co znajduje się przed nim, a następnie, w razie potrzeby, zmieniæ jego kierunek. Zrzut ekranu modelu pokazano na rysunku

Na obrazie pokazano pięæ agentów ŋóģwi podąŋających róŋnymi ķcieŋkami, jak przedstawiają to czerwone linie zygzakowate, z grotem strzaģki wskazującym aktualną pozycję ŋóģwia i wskazującą aktualny kierunek podróŋy. Kiedy ŋóģw wykryje przeszkodę przed nim, zmieni swój kierunek na nowy losowy nagģówek. Kod modelu przedstawiono w kodzie NetLogo
;; Ta procedura konfiguruje ģatki i ŋóģwie
to setup
;; Wyczyķæ wszystko.
clear-all
;; Spowoduje to utworzenie szachownicy z niebieskimi ģatami. Co trzeci patch
;; będzie niebieski (pamiętaj, ŋe modulo daje resztę podziaģu).
ask patches with [pxcor mod 3 = 0 and pycor mod 3 = 0]
[ set pcolor blue ]
;; To sprawi, ŋe najbardziej zewnętrzne ģaty będą niebieskie. Ma to na celu zapobieganie
;; ŋóģwie z owijania na caģym ķwiecie. Zauwaŋ, ŋe uŋywa liczby
;; ģatki sąsiada zamiast lokalizacji. To jest lepsze, poniewaŋ to
;; pozwoli ci zmieniæ zachowanie ŋóģwi poprzez zmianę
;; ksztaģtu ķwiata (i jest mniej podatny na pomyģki)
ask patches with [count neighbors !
[ set pcolor blue ]
;; Spowoduje to utworzenie ŋóģwi na losowo wybranej liczbie ŋóģwi
;; czarne ģaty.
ask n-of number-of-turtles (patches with [pcolor = black])
[
sprout 1
[ set color red ]
]
end
;; Ta procedura powoduje ruch ŋóģwi
to go
ask turtles
[
;; Ten waŋny warunek okreķla, czy mają zamiar wejķæ do
;; niebieska ģatka. To pozwala nam podjąæ decyzję, co robiæ PRZED
;; ŋóģw wchodzi w niebieską plamę. To dobry sposób na symulację obrazu
;; ķciana lub bariera, na którą ŋóģwie nie mogą się poruszaæ. Zauwaŋ, ŋe nie
;; uŋyj jakichkolwiek informacji o kursie lub pozycji ŋóģwia. Pamiętaj,
;; ģatka z wyprzedzeniem 1 to ģatka, na której byģby ŋóģw, gdyby się poruszyģ
;; naprzód 1 w bieŋącym nagģówku.
ifelse [pcolor] of patch-ahead 1 = blue
[ lt random-float 360 ] ;; We see a blue patch in front of us. Turn a
;; losowa iloķæ
[ fd 1 ] ;; W przeciwnym razie przejķcie do przodu jest bezpieczne.
]
tick
end
Jeķli uruchomimy model dģuŋej (400 cykli lub więcej) przy zmiennej liczbie ŋóģwi ustawionej na 50 zamiast 5, wówczas czerwone ķcieŋki szybko pokrywają większoķæ pustej przestrzeni w otoczeniu, jak pokazano na rysunku

Ten przykģad pokazuje, jak stosunkowo skromna liczba agentów o bardzo ograniczonych moŋliwoķciach wykrywania wciąŋ moŋe bardzo szybko caģkowicie pokryæ caģe ķrodowisko. Taka zdolnoķæ do grupy prawdziwych agentów jest często bardzo uŋyteczną cechą, na przykģad owady, takie jak mrówki, które muszą znaležæ žródģa poŋywienia. Z punktu widzenia obserwatora podczas uruchamiania modelu moŋna ģatwo dojķæ do bģędnego wniosku, ŋe agenci celowo przeszukują swoje ķrodowisko, ale analiza kodu NetLogo ujawnia, ŋe agenci w tym przykģadzie są po prostu bardziej reaktywni niŋ poznawczy - oni nie celowo przeszukuj otoczenie, ale w wyniku ich prostego, poģączonego zachowania, osiągnij taki sam efekt, jaki osiągają agenci o bardziej ķwiadomym zachowaniu w wyszukiwaniu dzięki ich zdolnoķci do koordynowania i ģączenia wyników. Dzięki detekcji bliskoķci moŋemy równieŋ symulowaæ czujniki do "dotykania" i "patrzenia". Model Ķciana po przykģadzie w Bibliotece modeli NetLogo przybliŋa akcję dotykania agenta, ķciķle ķledząc obiekt w ķrodowisku. Zrzut ekranu modelu pokazano na rysunku.

Ķcieŋki ŋóģwi są pokazane na rysunku, poniewaŋ w interfejsie modelu wybrano przycisk przewijania. Zachowanie agenta ŋóģwia jest nazywane "ķcianą", poniewaŋ jest analogiczne do prawdziwego agenta utrzymującego bliski kontakt z zewnętrzną stroną budynku podobną do ręki na ķcianie zachowanie labiryntów. Widoczne na obrazie ķrodowisko 2D NetLogo moŋna traktowaæ jako mapę, która zapewnia widok z lotu ptaka na wyimaginowane ķrodowisko 3D zawierające budynki, a krawędzie obiektów na obrazie reprezentują zewnętrzne ķciany budynku. Na obrazie niebieskie ŋóģwie podąŋają za prawą ķcianą, podczas gdy zielone ŋóģwie podąŋają za lewą ķcianą. Ŋóģwie wolą zachowaæ ķcianę, którą podąŋają po okreķlonej stronie ciaģa - dla niebieskich ŋóģwi wolą prawą stronę; zielone ŋóģwie wolą lewą stronę. Kod modelu jest pokazany w NetLogo Code
turtles-own [direction] ;; 1 podąŋa za prawą ķcianą,
;; -1 podąŋa za ķcianą po lewej stronie
to setup
clear-all
;; stwórz losowe ķciany, za którymi podąŋą ŋóģwie.
;; szczegóģy nie są waŋne
ask patches [ if random-float 1.0 < 0.04 [ set pcolor brown ] ]
ask patches with [pcolor = brown]
[ ask patches in-radius random-float 3 [ set pcolor brown ] ]
ask patches with [count neighbors4 with [pcolor = brown] = 4]
[ set pcolor brown ]
;; teraz zróbcie ŋóģwie. SPROUT stawia ŋóģwie na ķrodkach ģat
ask n-of 40 patches with [pcolor = black] [
sprout 1 [
if count neighbors4 with [pcolor = brown] = 4
[ die ] ;; trapped!
set size 2 ;; większe ŋóģwie są lepiej widoczne
set pen-size 2 ;; grubsze linie są lepiej widoczne
face one-of neighbors4 ;; twarzą na póģnoc, poģudnie, wschód lub zachód
ifelse random 2 = 0
[ set direction 1 ;; podąŋaj za prawą ķcianą
set color blue ]
[ set direction -1 ;; podąŋaj za lewą ķcianą
set color green ]
]
]
end
to go
ask turtles [ walk ]
tick
end
to walk ;; procedura ŋóģwia
;; obroæ w prawo jeķli konieczne
if not wall? (90 * direction) and wall? (135 * direction)
[ rt 90 * direction ]
;; w razie potrzeby skręæ w lewo (czasami więcej niŋ raz)
while [wall? 0] [ lt 90 * direction ]
;; ruszaj naprzód
fd 1
end
to-report wall? [angle] ;; turtle procedure
;; zwróæ uwagę, ŋe kąt moŋe byæ dodatni lub ujemny. jeķli kąt jest równy
;; pozytywne, ŋóģw wygląda dobrze. jeķli kąt jest ujemny,
;; ŋóģw wygląda w lewo.
report brown = [pcolor] of patch-right-and-ahead angle 1
end
Procedura chodzenia okreķla chodzenie agentów ŋóģwia. Kaŋdy agent ma zmienną kierunku, która definiuje stronę, którą woli utrzymaæ na ķcianie. Jeķli po preferowanej stronie nie ma ķciany, ale po tej stronie znajduje się ķciana, to ŋóģw musi zwróciæ się do preferowanej strony aby nie zgubiæ ķciany. Jeķli ķciana znajduje się bezpoķrednio z przodu, to ŋóģw przesuwa się zawsze w stronę przeciwną do preferowanej strony, aŋ znajdzie przed sobą otwartą przestrzeņ, w której moŋe się przesunąæ do przodu. Zarówno model Look Ahead Example jak i Wall Following demonstrują wspólny modus operandi dla ucieleķnionych, usytuowanych agentów, który skģada się z pierwszego wykrywania, po którym następuje selekcja i wykonanie zachowania. Ten modus operandi jest jedną z moŋliwych metod dziaģania dla czynnika reaktywnego, który polega na tym, ŋe agent najpierw wyczuwa, co dzieje się w ķrodowisku, a następnie decyduje się wykonywaæ okreķlone zachowania w oparciu o to, co wyczuwa. W przypadku modelu Look Ahead Example agent ŋóģwia najpierw wyczuwa, czy jest przed nami niebieska ģata, a następnie wybiera pomiędzy obracaniem a poruszaniem się do przodu w oparciu o to, czego się dowie. W przypadku modelu Wall Following Example agent najpierw wyczuwa, czy straciģ ķcianę i reaguje, obracając, jeķli to konieczne. Wtedy agent wielokrotnie wyczuwa, czy przed nim jest ķciana, a następnie się obraca, aŋ wreszcie wyczuwa, ŋe nie ma juŋ przed nią ķciany, po której porusza się do przodu. Aparatura sensoryczna czynnika jest waŋnym czynnikiem przy okreķlaniu moŋliwego wyniku zachowania agenta. Jeķli agent nie ma moŋliwoķci wykrywania, nie ma moŋliwoķci reagowania na jego otoczenie. Podobnie, jeķli moŋliwoķci wykrywania są pod pewnymi względami ograniczone, agent nie będzie w stanie odpowiadaæ zdarzeniom, które występują w ķrodowisku, które wykracza poza zakres lub zakresy, które moŋe wykryæ. Na przykģad, dla wzroku, koty mogą widzieæ w sģabym ķwietle ze względu na specjalne mięķnie oka, niektóre węŋe mają specjalne narządy i nietoperze mają czujniki węzģowe, które pozwalają im wykryæ ķwiatģo podczerwone, a niektóre ptaki widzą w ultrafiolecie do 300 nanometrów. Natomiast ludzie mają węŋszy zakres widzenia niŋ te przykģady, które ograniczają i definiują naszą zdolnoķæ reagowania na to, co widzimy. Interakcja między agentem a ķrodowiskiem ma równieŋ waŋną rolę do odegrania w okreķlaniu tego, co agent wyczuwa. Zostaģo to zilustrowane za pomocą przykģadowego modelu linii widzenia w bibliotece modeli NetLogo. Zrzut ekranu modelu pokazano na rysunku

Obraz pokazuje niektórych agentów ŋóģwi poruszających się po losowych nagģówkach, a ich obecna linia wzroku jest narysowana kropkami w tym samym kolorze, co kolor agenta. Ķrodowisko jest wirtualną reprezentacją krajobrazu, z wykorzystaniem reprezentacji często uŋywanej w grafice komputerowej nazywanej mapą wysokoķci. Zielone cieniowanie kaŋdego ģaty odzwierciedla jego wysokoķæ - im jaķniejsze cieniowanie, tym wyŋsza jest wysokoķæ ģaty. Na przykģad znaczący pik występuje w lewym dolnym rogu ķrodowiska 2D; ciemnozielony obszar natychmiast po prawej stronie szczytu wskazuje gģęboką depresję. Linia wzroku jest obliczana z perspektywy pierwszej osoby kaŋdego agenta. Biorąc pod uwagę aktualny kurs i lokalizację agenta, linia prosta jest wyķwietlana do przodu, okreķlając, czy ģatki przed agentem nie są zasģaniane przez nic na wyŋszych wysokoķciach po drodze. W lewej ręce figury przedstawiono wykres tego, co pomaraņczowy agent moŋe "zobaczyæ" przed nim. Prawie lewa pionowa kolumna na wykresie pokazuje wysokoķæ ģaty, na której stoi pomaraņczowy agent. Pionowe kolumny po prawej stronie pokazują elewacje ģat z przodu agenta zgodnie z jego aktualną pozycją. Poniewaŋ kolejne dwie poprawki są niŋsze od aktualnej wysokoķci agenta, zostaģy one pomalowane na kolor pomaraņczowy, aby wskazaæ, ŋe agent będzie w stanie "zobaczyæ" tę częķæ terenu. Widok trzeciej ģatki jest jednak zasģonięty przez wyŋszą elewację drugiego plastra, więc kolor
ten jest czarny, co oznacza, ŋe agent nie będzie w stanie "spojrzeæ" bezpoķrednio na tę częķæ krajobrazu. Podobnie, oglądanie tego, co jest na czwartej i szóstej ģatce, jest moŋliwe, poniewaŋ nie są zasģaniane przez wyŋsze wysokoķci jakichkolwiek poķrednich ģat, ale pozostaģe ģatki są zasģonięte od linii wzroku. Jako analogię do rzeczywistej sytuacji, rozwaŋ czģowieka próbującego zlokalizowaæ punkt kontrolny (np. czerwoną flagę) w biegu na orientację w terenie wydm piaszczystych. Często czerwona flaga będzie zasģonięta z linii wzroku osoby, dopóki osoba nie znajdzie się doķæ blisko flagi, szczególnie jeķli jest ona umieszczona w zagģębieniu. Jednakŋe, gdy osoba porusza się w terenie zbliŋając się do flagi, stanie się widoczna, gdy dana osoba osiągnie punkt widokowy, który nie ma interweniujących wzniesieņ lub wyŋszych nachylonych terenów blokujących widok. Ten przykģad ilustruje znaczenie wykorzystania usytuowanej z perspektywy pierwszoosobowej perspektywy do projektowania ucieleķnionych agentów. Wynikowe zachowanie agentów jest bardziej wiarygodne z punktu odniesienia obserwatora, a interakcja agent-ķrodowisko dodaje do realizmu. Kod modelu jest pokazany w NetLogo Code
breed [walkers walker]
breed [markers marker]
patches-own [elevation]
to setup
ca
set-default-shape markers "dot"
;; ustaw teren
ask patches [ set elevation random 10000 ]
repeat 2 [ diffuse elevation 1 ]
ask patches [ set pcolor scale-color green elevation 1000 9000 ]
create-walkers 6 [
set size 1.5
setxy random-xcor random-ycor
set color item who [orange blue magenta violet brown yellow]
mark-line-of-sight
]
end
to go
;; pozbyæ się wszystkich starych markerów
ask markers [ die ]
;; move the walkers
ask walkers [
rt random 10
lt random 10
fd 1
mark-line-of-sight
]
;;nakreķliæ tylko pomaraņczowe urządzenie
ask walker 0 [ plot-line-of-sight ]
tick
end
to mark-line-of-sight ;; procedura chodzika
let dist 1
let a1 0
let c color
let last-patch patch-here
;; powtarzaj wszystkie ģatki
;; zaczynając od ģaty bezpoķrednio przed nami
;; przechodząc przez MAKSYMALNĄ WIDOCZNOĶÆ
while [dist <= maximum-visibility] [
let p patch-ahead dist
;; jeķli patrzymy ukoķnie w poprzek
;; ģatka jest moŋliwe, ŋe dostaniemy
;; ta sama ģatka dla odlegģoķci x i x + 1
;; ale nie musimy sprawdzaæ ponownie
if p != last-patch [
;; znajdž kąt między pozycją ŋóģwia
;; i na górze ģaty.
let a2 atan dist (elevation - [elevation] of p)
;; jeķli kąt ten jest mniejszy niŋ kąt w kierunku
;; ostatnia widoczna ģatka nie ma bezpoķredniej linii od ŋóģwia
;; do danej ģatki, która nie jest zasģonięta przez inną
;; ģata.
if a1 < a2
[ ask p [ sprout-markers 1 [ set color c ] ]
set a1 a2 ]
set last-patch p
]
set dist dist + 1
]
end
W gģównej metodzie, agenci ŋóģwie wykonują maģą losową prawą, a następnie lewą turę (zmieni to lekko ich nagģówek), przesuwają się do przodu o 1 stopieņ, a następnie wyznaczają linię wzroku, wykonując procedurę mark-line-of-sight. Procedura ta przechodzi przez wszystkie ģatki przed agentem do maksymalnej odlegģoķci zdefiniowanej przez zmienną interfejsu maximum-visibility. Dla kaŋdej odrębnej ģatki wzdģuŋ linii bieŋącego nagģówka agenta, najpierw znajduje kąt między poģoŋeniem ŋóģwia a wierzchoģkiem ģaty. Jeķli kąt do ostatniej widocznej ģaty jest mniejszy niŋ ten kąt, to jej widok ģaty nie jest zatkany i rysuje znacznik w ķrodowisku, aby pokazaæ, ŋe widzi dany patch. Zakres widzenia moŋna rozszerzyæ aby obejmowaģ stoŋek zamiast pojedynczej linii za pomocą wbudowanego reportera in-cone NetLogo. Ten reporter zgģasza zestaw agentów, które mieszczą się w stoŋku widzenia zdefiniowanym przez parametry odlegģoķci i kąta patrzenia. Stoŋek skupia się wokóģ bieŋącego kursu ŋóģwia. Jeķli kąt wynosi 360 °, wyniki są równowaŋne z promieniem leŋącym w polu widzenia. Model Vision Cone Example dostarczony przez bibliotekę modeli NetLogo demonstruje uŋycie tego reportera, jak pokazują zrzuty ekranu na rysunku
Lewy zrzut ekranu na rysunku zostaģ uzyskany w wyniku ustawienia zmiennej Interfejsu vision-radius na 50 i vision-angl na 40; prawy zrzut ekranu zostaģ uzyskany przez ustawienie tych zmiennych odpowiednio na 20 i 360. Kod tego modelu przedstawiono w kodzie NetLogo.
breed [ wanderers wanderer ] ;; duŋy czerwony ŋóģw, który się porusza
breed [ standers stander ] ;; maģe szare ŋóģwie, które po prostu tam stoją
to setup
clear-all
;; zrobiæ tģo wielu losowo rozrzuconych obrazów
;; stacjonarne szare ŋóģwie
create-standers 6000
[
setxy random-xcor random-ycor
set color gray
]
;; zrób jednego wielkiego czerwonego ŋóģwia, który będzie się poruszaģ
create-wanderers 1
[
set color red
set size 15
]
;; uczyniæ początkowo stoŋek wizji
go
end
to go
ask standers [ set color gray ]
ask wanderers
[
rt random 20
lt random 20
fd 1
;; mógģby uŋyæ tutaj IN-CONE-NOWRAP zamiast IN-CONE
ask standers in-cone vision-radius vision-angle
[
set color white
]
]
tick
end
Model wykorzystuje dwa typy agentów - typu wanderer dla duŋego czerwonego agenta, który bada otoczenie z jego siģą widzenia, jak pokazano na zrzutach ekranu i typ stander, która sģuŋy do narysowania 6000 losowo rozmieszczonych szarych agentów w ķrodowisku w procedurze instalacji. W metodzie gģównej, tak jak w przypadku przykģadu Line of Sight, agenci ŋóģwi wykonują maģe losowe prawo, następnie lewy obrót, a następnie krok 1 w przód. Następnie ustawienie koloru wszystkich kolumn w stoŋku widzenia, zdefiniowanych przez zmienne vision-radius i vision-angle, pokazuje ich aktualne pole widzenia. Wyczuwanie w agentach nie musi ograniczaæ się do tradycyjnych zmysģów, takich jak widzenie lub dotyk. Na przykģad, równowaga równowagi lub równowaga w poģączeniu z innymi zmysģami, takimi jak system wzrokowy i propriocepcja, pozwalają ludziom i zwierzętom uzyskaæ informacje o ich pozycji ciaģa w stosunku do najbliŋszego otoczenia. Wraŋanie moŋe obejmowaæ wykrycie dowolnego aspektu ķrodowiska, takiego jak obecnoķæ, nieobecnoķæ lub zmiana w danym atrybucie. Dzięki temu agent moŋe ķledziæ gradient w ķrodowisku związanym z atrybutem. Na przykģad, przydatny sens dla prawdziwych agentów to zdolnoķæ do wykrywania zmian w elewacji, aby móc w razie potrzeby kierowaæ się w górę lub w dóģ. Przykģad modelu Hill Climbing w bibliotece modeli NetLogo pokazuje, w jaki sposób moŋna wdroŋyæ taki sens. Zrzut ekranu modelu pokazano na rysunku , a kod pokazano w NetLogo Code

turtles-own
[
peak? ;; wskazuje, czy ŋóģw osiągnąģ szczyt,
;; to znaczy, ŋe nie moŋe juŋ iķæ pod górę z miejsca, w którym stoi
]
to setup
clear-all
;; zrobiæ krajobraz ze wzgórzami i dolinami
ask n-of 100 patches [ set pcolor 120 ]
;; lekko wygģadziæ krajobraz
repeat 20 [ diffuse pcolor 1 ]
;; umieķæcie ŋóģwie na centrach ģat w krajobrazie
ask n-of 800 patches [
sprout 1 [
set peak? false
set color red
pen-down
]
]
end
to go
;; zatrzymaj się, gdy wszystkie ŋóģwie osiągną szczyt
if all? turtles [peak?]
[ stop ]
ask turtles [
;; pamiętaj, gdzie zaczęliķmy
let old-patch patch-here
;; aby uŋyæ UPHILL, ŋóģwie okreķlają zmienną ģatki
uphill pcolor
;; czy wciąŋ jesteķmy tam, gdzie zaczęliķmy? jeķli tak, nie zrobiliķmy tego
;; ruszaj się, więc musimy byæ na szczycie
if old-patch = patch-here [ set peak? true ]
]
tick
end
Zrzut ekranu pokazuje agenty ŋóģwia, które rozpoczynają się w przypadkowych miejscach, a następnie przesuwają się stopniowo w górę do najwyŋszego lokalnego punktu w ich bezpoķrednim otoczeniu (tj. W kierunku ģat z najjaķniejszym cieniowaniem). Poniewaŋ pojedynczy punkt wysoki sģuŋy jako najwyŋszy punkt dla wielu otaczających ģat, powoduje to, ŋe ķcieŋki agentów ģączą się w liniowe wzory linii, jak pokazano na rysunku. Pionowa linia na lewo od figury przedstawia na przykģad wierzchoģek ridgeline w ķrodowisku 2D. Jako analogię do prawdziwych agentów ludzkich, moŋemy wyobraziæ sobie, ŋe wielu piechurów wspinaģo się z róŋnych pozycji startowych w górę grzbietu, a kiedy dotrą do linii grzbietowej, wszystkie koņczą się po jednej ķcieŋce na szczyt. Model wykorzystuje polecenie uphill w NetLogo, które kieruje agenta do przeniesienia do sąsiedniej ģaty, która ma najwyŋszą wartoķæ dla konkretnej zmiennej ģatki. Zmienna w tym przypadku jest ģatka color. Metoda go kaŋe kaŋdemu ŋóģwiowi kierowaæ się w kierunku do góry, dopóki nie będzie to juŋ moŋliwe, w którym to przypadku zmienna peak ŋóģwia? jest ustawiona na true, aby wskazaæ, ŋe ŋóģw osiągnąģ szczyt. Kiedy wszystkie ŋóģwie osiągną szczyt, wtedy nie jest juŋ wykonywane ŋadne przetwarzanie. Pokazuje, jak róŋne zachowania ŋóģwi "eksplorują" pusty labirynt. Dziaģanie Hand On The Wall powoduje, ŋe agent ŋóģwia podąŋa za lewą ķcianą lub prawą ręką (jak na rysunku), w zaleŋnoķci od losowego wyboru, jaki agent wykonuje zaraz po wejķciu do labiryntu. Agent ŋóģwia bardzo szybko dotrze do wyjķcia z labiryntu na szczycie. Natomiast zachowanie Random Forward 0 spowoduje, ŋe agentowi ŋóģwia nigdy nie uda się znaležæ wyjķcia do labiryntu. Będzie on wielokrotnie podąŋaģ za ķcianami w kierunku przeciwnym do ruchu wskazówek zegara (jak na rysunku), jeķli agent obraca się natychmiast po pierwszym wejķciu do labiryntu lub w kierunku zgodnym z ruchem wskazówek zegara, jeķli najpierw skręca w lewo. Jednak nigdy nie zdoģa wydostaæ się z nieskoņczonej pętli, w której jest uwięziony. Taki bezowocny wynik jest typowy dla czynnika reaktywnego. Nie moŋe dojķæ do wniosku, ŋe žle się dzieje, a następnie odpowiednio dostosowaæ swoje zachowanie, aby osiągnąæ poŋądany stan - po prostu reaguje. Z punktu widzenia obserwatora bezowocnoķæ zachowania jest mniej widoczna niŋ w przypadku pozostaģych dwóch zachowaņ zaimplementowanych w modelu, poniewaŋ wydaje się, ŋe agent ma jakiķ plan, powtarzając te same kroki w kóģko. (To oczywiķcie byģoby bģędne zaģoŋenie, agent nie ma ŋadnego planu). Jednak agenci wykonujący dwa pozostaģe zachowania wykazują podobny do siebie wzór, ŋe "bezmyķlnie" migoczą wokóģ otoczenia w pozornie bez celu, losowo, w przeciwieņstwie do maģego ptaka lub æmy (jak w przypadku zachowania Random Forward 2). w realnym ŋyciu lub mucha wielokrotnie uderzająca o zamknięte okno (jak w przypadku zachowania Random Forward 1). Oba mogą byæ frustrujące, poniewaŋ oba mogą dotrzeæ do wyjķcia z wystarczającą iloķcią czasu, ale często, gdy zbliŋają się do wyjķcia, mogą udaæ się caģkowicie w niewģaķciwym kierunku. Rysunek pokazuje, jak róŋne zachowania ŋóģwi badają Labirynt Paģacu Hampton Court.
Hand On The Wall Behaviour doskonale nadaje się do tego ķrodowiska, poniewaŋ agent ŋóģwia wykonujący takie zachowanie zawsze osiągnie cel będący centrum labiryntu, niezaleŋnie od tego, czy agent najpierw wybraģ skręt w lewo, czy w prawo (jak pokazano na rysunku). ). Z kolei zachowanie Random Forward 0 spowoduje, ŋe agentowi uda się tylko odkryæ pierwszą trzecią częķæ labiryntu, poniewaŋ nie moŋe on skręciæ w prawo lub w lewo w poģowie korytarza. Pozostaģe dwa zachowania spowodują w koņcu sukces dla agentów, którzy je wykonują, ale wymaga to czasu i wysiģku ze strony agentów i ogromnego szczęķcia. Rysunek 5.10 pokazuje, jak róŋne zachowania ŋóģwi badają labirynt Chevening House.
W The Wall Behaviour ten czas nie jest dobrze dopasowany do tego ķrodowiska, poniewaŋ labirynt zostaģ zaprojektowany specjalnie w celu udaremnienia takiego zachowania. Natomiast zachowanie Random Forward 0 moŋe z powodzeniem zakoņczyæ labirynt w niektórych przypadkach, podczas gdy w poprzednim labiryncie zawsze koņczyģo się niepowodzeniem. To pokazuje, jak ķrodowisko odgrywa kluczową rolę w okreķlaniu sukcesu (lub jego braku) agentów o róŋnych zachowaniach. Zachowanie się jednak nad wszystkim nie jest zbyt skuteczne, poniewaŋ przez większoķæ czasu agent zostaje uwięziony, bez koņca odbijając się od centrum labiryntu. Pozostaģe dwa zachowania ponownie dają sukces agentom, którzy je wykonują, ale to wymaga czasu i wysiģku (i szczęķcia) ze strony agentów. Alternatywną moŋliwoķcią wykonania pojedynczego zachowania jest poģączenie dwóch lub więcej zachowaņ. Jest to bardzo ģatwe do przetestowania w modelu Mazes - po prostu wybierz inne zachowanie, uŋywając selektora turtle-behaviour w interfejsie podczas wykonywania programu. Na przykģad dla w prawym dolnym rogu trzeciego rysunku, początkowe zachowanie zostaģo ustawione na Random Forward 0, a następnie w odpowiednim czasie (aby pomóc agentowi ŋóģwia dotrzeæ do ķrodka labiryntu), zachowanie zostaģo zmienione na Hand On The Wall . Ta kombinacja zachowaņ jest zwykle bardziej skuteczna niŋ jakiekolwiek pojedyncze zachowanie, nawet jeķli przeģączanie odbywa się losowo, poniewaŋ Hand On The Wall jest najbardziej skuteczny w robieniu postępu, ale wymaga czasowego wyģączenia, aby umoŋliwiæ agentowi w pewnym momencie przeskocz na wyspę poķrodku labiryntu. Z tego moŋna wyciągnąæ wnioski, ŋe poģączone zachowania mogą byæ bardziej skuteczne niŋ pojedyncze zachowanie, a to moŋe staæ się konieczne, gdy zmieni się otoczenie, jeķli agent chce zachowaæ skutecznoķæ w danym zadaniu
Ucieleķnione, poģoŋone poznanie
Sposób, w jaki proste reaktywne ķrodki ŋóģwiowe w modelu Mazes powyŋej poruszają się wokóģ labiryntów, moŋna porównaæ do wyników dla agentów zachowujących się poznawczo - czyli agentów, którzy wiedzą, ŋe muszą dotrzeæ do centrum lub wyjķcia z labiryntu i którzy są w stanie rozpoznają, kiedy dotarli do miejsca w labiryncie, które ma wiele ķcieŋek do przeszukania. Innymi sģowy, mają zdolnoķæ rozpoznania, ŋe istnieje wybór, gdy wybór pojawia się w ķrodowisku (np. kiedy agent osiąga skrzyŋowanie w labiryncie). Ten akt rozpoznania jest podstawową częķcią poznania, a takŋe zasadniczą częķcią poszukiwaņ. Jest to związane z sytuacją, w której znajduje się agent, sposobem poruszania się jego ciaģa i interakcji ze ķrodowiskiem. Jest to równieŋ związane z tym, co dzieje się w ķrodowisku zewnętrznym i / lub co dzieje się z innymi agentami w tym samym ķrodowisku, jeķli takie istnieją. Tradycyjne podejķcie do poznania zajmuje punkt widzenia przetwarzania informacji, ŋe percepcja i ukģady ruchowe są urządzeniami wejķciowymi i wyjķciowymi. Na przykģad jedna konkretna metoda charakteryzowania Poznania jest jak cykl "zmysģ - myķl - dziaģanie": najpierw agent postrzega coķ (zmysģ), potem przetwarza to, co postrzega (myķli), potem wykonuje dziaģanie (akt). Ostatnie badania dotyczące ucieleķnionych nauk kognitywnych zakwestionowaģy jednak takie uproszczone podejķcie do charakteryzowania zachowaņ poznawczych i kģadą większy nacisk na dynamiczne oddziaģywanie ciaģa z otoczeniem poprzez koordynację czuciowo-ruchową. Alternatywne podejķcie, zwane ucieleķnionym, usytuowanym poznaniem, zakģada, ŋe wszystkie aspekty poznania agenta ksztaģtowane są przez interakcję ciaģa agenta ze ķrodowiskiem, w którym się znajduje, oraz z innymi czynnikami, które wspóģistnieją w tym ķrodowisku. W tym podejķciu ciaģo i umysģ poķrednika oddziaģują jednoczeķnie ze sobą i ze ķrodowiskiem. Nie ma wewnętrznych reprezentacji, które charakteryzowaģyby ruchy agenta i jego ciaģa jako oddzielnych i odrębnych zdarzeņ w "sensie - myķl - dziaģaniu". Zamiast tego, odczuwanie, myķlenie i dziaģanie zachodzą i wpģywają na siebie jednoczeķnie. W rezultacie wszystkie aspekty poznania, takie jak kategorie, pojęcia, idee i myķli oraz wszystkie aspekty zachowaņ poznawczych, takie jak podejmowanie decyzji, wyszukiwanie, planowanie i uczenie się, są ksztaģtowane przez interakcję między umysģem, ciaģem i otoczeniem. Wcielona, usytuowana perspektywa poznania jest metodą de rigueur dla pola ucieleķnionej naukikognitywnej. Zostaģo to przyjęte na przykģad przez badaczy z dziedziny językoznawstwa opartych na wczesnej pracy Lakoffa i Johnsona, które uwypukliģo znaczenie metafory pojęciowej w ludzkim języku i która pokazaģa, jak jest ona powiązana z naszym postrzeganiem poprzez nasz wcielenie i fizyczne uziemienie. . Jest równieŋ szeroko stosowany w robotyce, wynikającej z przeģomowych prac Rodneya Brooksa w tej dziedzinie, którzy twierdzą, ŋe maszyny muszą byæ fizycznie uziemione w ķwiecie rzeczywistym poprzez zmysģowe i motoryczne umiejętnoķci poprzez ciaģo. Dzieģo to dzieli inteligencję na warstwy zachowaņ, które opierają się na fizycznym usytuowaniu agenta w jego otoczeniu i dynamicznej reakcji z nim. Takie podejķcie zyskaģo popularnoķæ takŋe w innych obszarach, takich jak animacja behawioralna i inteligentni agenci wirtualni.
Podsumowanie i dyskusja
Ciaģo agenta odgrywa kluczową rolę w poznaniu. Sposób, w jaki ciaģo agenta wchodzi w interakcje i znajduje się w jego otoczeniu w poģączeniu z jego systemami wykrywania i motorycznymi, determinuje wiele jego zachowaņ. Moŋe wydawaæ się oczywiste, ŋe autonomiczne czynniki mają ciaģo i znajdują się w otoczeniu, ale z perspektywy projektowania nie moŋna zaniŋaæ znaczenia projektowania inteligentnego zachowania opartego na tych atrybutach; na przykģad uŋycie perspektywy projektowania z perspektywy pierwszej osoby zmusza projektanta do rozwaŋenia aspektów z punktu widzenia agenta, zamiast narzucania projektu z zewnętrznego punktu widzenia. Tradycyjne podejķcie do charakteryzowania poznania - cyklu "sensu - myķlenia - aktu" zakģada, ŋe poznawanie odbywa się w oddzielnych odczuciach, myķlach i zachowaniach aktorskich. Chociaŋ podejķcie to jest odpowiednie do projektowania prostych ķrodków reaktywnych, ma ono ograniczenia przy projektowaniu agentów wykazujących inteligentne zachowanie. Podkreķla się alternatywne podejķcie, zwane ucieleķnionym, usytuowanym poznaniem jednoczesne odczuwanie, myķlenie i dziaģanie. W niniejszym rozdziale przedstawiono wiele modeli w NetLogo, aby zademonstrowaæ róŋne aspekty dotyczące wdraŋania ucieleķnionych, usytuowanych agentów. Agenty wymagają jakiegoķ sposobu wyczuwania ķwiata, a modele pokazaģy, w jaki sposób moŋna symulowaæ róŋne zmysģy, takie jak: wzrok (przykģad z wyprzedzeniem, przykģad z linią wzroku i modele z przykģadem stoŋka widzenia); i dotknij (model Wall Po przykģadach). Agenci nie muszą ograniczaæ się do tradycyjnego ludzkiego sensu. Mogą równieŋ uŋywaæ zmysģów dostosowanych do rozpoznawania zmian w otoczeniu, takich jak podniesienie terenu (model Hill Climbing Example) lub chemikalia wprowadzone do otoczenia (model Ants). Ķrodowisko wyražnie ma waŋną rolę do odegrania w okreķlaniu zachowania agenta w tych przykģadach, ale moŋe równieŋ wpģywaæ na to, co agent jest w stanie wyczuæ w oparciu o sytuację; na przykģad dla modelu linii wzroku teren okreķla, co jest widoczne dla agenta w dynamicznym procesie, który jest związany z bieŋącą lokalizacją i ruchem agenta; w przypadku modelu Mazes niektóre czynniki zostają uwięzione, poniewaŋ ich odczuwane zachowanie pomija sensowną ķcieŋkę. Jednakŋe dwa waŋne aspekty ucieleķnionego, usytuowanego poznania nie zostaģy wykazane przez ŋaden z tych modeli. Po pierwsze, aby realistyczne i wiarygodne zachowanie rozwijaģo się w peģnych, poģoŋonych wirtualnych agentach, ymagana jest fizyczna symulacja ciaģa agenta i sposób, w jaki wspóģdziaģa on ze ķrodowiskiem wirtualnym. Po drugie, aby poznanie mogģo mieæ miejsce w zdrowym tego sģowa znaczeniu, agent powinien ķwiadomie przetwarzaæ informacje zmysģowe, podejmowaæ decyzje, zmieniaæ swoje preferencje i stosowaæ dowolną istniejącą wiedzę, jaką moŋe mieæ podczas wykonywania zadania lub procesu myķlenia umysģowego; innymi sģowy, wiedzą, co robią. Podsumowanie waŋnych pojęæ, które naleŋy wyciągnąæ z tego rozdziaģu, pokazano poniŋej:
• *Realizacja dla autonomicznego agenta dotyczy ciaģa, z którego korzysta agent, do poruszania się, odczuwania i interakcji ze ķrodowiskiem.
• " *Usytuowanie dotyczy autonomicznego agenta znajdującego się w otoczeniu z innymi agentami i obiektami, a jego zachowanie zaleŋy od tego, co dzieje się w ķrodowisku.
• *Reaktywne zachowanie dotyczy agenta reagującego bez ķwiadomej myķli na zdarzenie, które ma miejsce. Natomiast zachowania poznawcze wymagają bardziej deliberatywnego podejķcia - agent ķwiadomie przetwarza informacje zmysģowe, podejmuje decyzje, zmienia swoje preferencje i stosuje dowolną istniejącą wiedzę, jaką moŋe mieæ podczas wykonywania zadania lub procesu myķlowego myķlenia.
• *Cykl "zmysģ - myķl - akt" odnosi się do szczególnego modus operandi dla autonomicznego czynnika wykazującego inteligentne zachowanie. Cykl ten polega na tym, ŋe agent stosuje kolejno trzy zachowania: agent najpierw wyczuwa, co dzieje się w ķrodowisku, a następnie zastanawia się, co mówią jego zmysģy, w tym decyduje, co robiæ dalej, a następnie robi to, co postanowiģ zrobiæ. w oparciu o odpowiednie dziaģania.
• *Wcielona, usytuowana perspektywa poznania zakģada, ŋe wszystkie aspekty poznania agenta ksztaģtowane są przez interakcję ciaģa agenta ze ķrodowiskiem, w którym się znajduje. Wyczuwanie, myķlenie i dziaģanie odbywa się jednoczeķnie i w poģączeniu ze sobą, a nie osobno
Wykonanie zadaņ w sposób reaktywny bez poznania
Czy agent moŋe wykonaæ nieģatwe zadanie, nie wiedząc, ŋe je wykonuje? Innymi sģowy, czy agent moŋe "rozwiązaæ" problem bez poznawczo bycia ķwiadomym, ŋe rozwiązuje problem? Aby odpowiedzieæ na to pytanie, najpierw musimy zapytaæ, co rozumiemy przez "poznawczo bycie ķwiadomym". Poznanie odnosi się do procesów umysģowych czynnika inteligentnego, naturalnego lub sztucznego, takich jak rozumienie, rozumowanie, podejmowanie decyzji, planowanie i uczenie się. Moŋna ją równieŋ zdefiniowaæ w szerszym znaczeniu, ģącząc ją z aktem mentalnym poznania lub rozpoznania agenta w odniesieniu do myķli, którą on myķli lub dziaģania, które wykonuje. Tak więc zachowanie poznawcze zachodzi, gdy agent ķwiadomie przetwarza swoje myķli lub dziaģania. Zgodnie z tą definicją, autonomiczny agent wykazuje zachowania poznawcze, jeķli ķwiadomie przetwarza informacje zmysģowe, podejmuje decyzje, zmienia swoje preferencje i stosuje dowolną istniejącą wiedzę, jaką moŋe mieæ podczas wykonywania zadania lub procesu myķlowego myķlenia. Poznanie wiąŋe się równieŋ z percepcją. Postrzeganie agenta jest mentalnym procesem uzyskiwania zrozumienia lub ķwiadomoķci informacji zmysģowych. Powróæmy teraz do pytania postawionego na początku tego rozdziaģu. Rozwaŋ zdolnoķæ owada do ŋerowania na jedzenie. Mrówki, na przykģad, mają moŋliwoķæ szybkiego znalezienia žródeģ poŋywienia, ale robią to wyczuwając zapach chemiczny ustanowiony przez inne mrówki, a następnie odpowiednio reagują, stosując maģy zestaw zasad. Pomimo, ŋe nie są poznawczo ķwiadomi tego, co robią, osiągają cel, jakim jest peģne zbadanie ķrodowiska, sprawne lokalizowanie pobliskich žródeģ ŋywnoķci i powrót do gniazda. Model Ants dostępny w bibliotece modeli NetLogo symuluje jeden ze sposobów, w jaki moŋe się to zdarzyæ. Zrzut ekranu modelu pokazano na rysunku

Pokazuje kolonię mrówek rozproszonych w caģym ķrodowisku, a jej gniazdo jest pokazane przez purpurowy obszar w ķrodku obrazu. Początkowo istniaģy trzy žródģa poŋywienia, ale na tym etapie symulacji poprzednie dwa zostaģy juŋ pochģonięte, a pozostaģe žródģo ŋywnoķci zostaģo znalezione i jest w trakcie zbierania w celu powrotu do gniazda. Biaģo-zielony zacieniony region przedstawia, jak duŋo chemicznego zapachu zostaģo obciąŋone w ķrodowisku, a biaģy przedstawia największa iloķæ. Kod częķci modelu definiującej zachowanie mrówek jest przedstawiony w kodzie NetLogo
patches-own [
chemical ;; iloķæ chemikaliów na tej ģatce
food ;; iloķæ jedzenia na tej ģatce (0, 1 lub 2)
nest? ;; prawda na ģatach gniazd, faģsz gdzie indziej
nest-scent ;; liczba, która jest bliŋej gniazd
food-source-number ;; numer (1, 2 lub 3) w celu identyfikacji žródeģ ŋywnoķci
]
to recolor-patch ;; procedura ģatania
;; nadaj kolor gniazdom i žródģom pokarmu
ifelse nest?
[ set pcolor violet ]
[ ifelse food > 0
[ if food-source-number = 1 [ set pcolor cyan ]
if food-source-number = 2 [ set pcolor sky ]
if food-source-number = 3 [ set pcolor blue ] ]
;; kolor skali, aby pokazaæ stęŋenie chemiczne
[ set pcolor scale-color green chemical 0.1 5 ] ]
end
to go ;; przycisk na zawsze
ask turtles
[ if who >= ticks [ stop ] ;; opóžniæ początkowy odlot
ifelse color = red
[ look-for-food ] ;; nie niosąc jedzenia? Szukaj tego
[ return-to-nest ] ;; niosącego jedzenie? zabierz go z powrotem do gniazda
wiggle
fd 1 ]
diffuse chemical (diffusion-rate / 100)
ask patches
[ set chemical chemical * (100 - evaporation-rate) / 100
;; powoli odparuj chemikalial
recolor-patch ]
tick
do-plotting
end
to return-to-nest ;; procedura ŋóģwia
ifelse nest?
[ ;; upuķæ jedzenie i idž dalej
set color red
rt 180 ]
[ set chemical chemical + 60;; upuķæ trochę chemikaliów
uphill-nest-scent ] ;; zmierzaj w kierunku największej wartoķci zapachu gniazdat
end
to look-for-food ;; procedura ŋóģwia
if food > 0
[ set color orange + 1 ;;odebraæ jedzenie
set food food - 1 ;; zmniejsz žródģo ŋywnoķci
rt 180 ;; i odwróæ się
stop ]
;; idž w kierunku, w którym zapach chemiczny jest najsilniejszy
if (chemical >= 0.05) and (chemical < 2)
[ uphill-chemical ]
end
;; wąchaj w lewo iw prawo i idž tam, gdzie jest najsilniejszy zapach
to uphill-chemical ;; procedura ŋóģwia
let scent-ahead chemical-scent-at-angle 0
let scent-right chemical-scent-at-angle 45
let scent-left chemical-scent-at-angle -45
if (scent-right > scent-ahead) or (scent-left > scent-ahead)
[ ifelse scent-right > scent-left
[ rt 45 ]
[ lt 45 ] ]
end
;; wąchaj w lewo iw prawo i idž tam, gdzie jest najsilniejszy zapach
to uphill-nest-scent ;; turtle procedure
let scent-ahead nest-scent-at-angle 0
let scent-right nest-scent-at-angle 45
let scent-left nest-scent-at-angle -45
if (scent-right > scent-ahead) or (scent-left > scent-ahead)
[ ifelse scent-right > scent-left
[ rt 45 ]
[ lt 45 ] ]
end
to wiggle ;; procedura ŋóģwia
rt random 40
lt random 40
if not can-move? 1 [ rt 180 ]
end
to-report nest-scent-at-angle [angle]
let p patch-right-and-ahead angle 1
if p = nobody [ report 0 ]
report [nest-scent] of p
end
to-report chemical-scent-at-angle [angle]
let p patch-right-and-ahead angle 1
if p = nobody [ report 0 ]
report [chemical] of p
end
Peģną listę kodów moŋna znaležæ, wybierając model Mrówki z Biblioteki modeli, a następnie klikając przycisk Procedure u góry interfejsu NetLogo. Kaŋdy agent ģatki ma wiele zmiennych związanych z nim - na przykģad, chemical przechowują iloķæ substancji chemicznych, którą mrówki uģoŋyģy na wierzchu, a nest-scent odzwierciedla, jak blisko jest ģatka do gniazda. Procedura recolor-patch pokazuje, jak kolor plastra jest zmieniany zgodnie z iloķcią naģoŋonego związku chemicznego. Procedura go okreķla zachowanie mrówek. Jeķli mrówka nie będzie jadģa, będzie szukaģa poŋywienia (wykonując procedurę look-for-food), w przeciwnym razie zabierze ŋywnoķæ z powrotem do gniazda (wykonując procedurę return-to-nest). Gdy agent wraca do gniazda, upuszcza substancję chemiczną, która się porusza. Mrówki uŋywają węchu, aby wirtualnie "powąchaæ" ten związek chemiczny, aby poprowadziæ go w kierunku žródģa poŋywienia. Poniewaŋ coraz więcej mrówek przenosi ŋywnoķæ z powrotem gniazdo wzmacnia siģę substancji chemicznej, ale ta choroba równieŋ ulega rozproszeniu w miarę upģywu czasu, poniewaŋ siģa substancji chemicznej zmniejsza się w kaŋdym teķcie w procedurze go. Dwie procedury uphill-chemical i uphill-nest-scent okreķlają reaktywne zachowania mrówek podąŋając za chemicznym zapachem žródģa pokarmu i wracając do gniazda. Mrówki zasadniczo stosują podobne zachowanie do agentów ŋóģwi wspinaczkowych na powyŋszym modelu Hill Climbing przykģad (który jest zgodny z gradientem zdefiniowanym przez zmienną pcolor w odniesieniu do terenu w ķrodowisku 2D). Z kolei czynniki przeciw mrówkom w modelu Ants podąŋają za gradientem zdefiniowanym przez zmienną zmienną chemical, jeķli szukają poŋywienia i wracają wzdģuŋ gradientu zdefiniowanego przez zmienny nest-scent, jeķli wracają do gniazda. Robią to przez "wąchanie" najpierw w lewo, potem w prawo, a następnie podąŋanie ķcieŋką z najsilniejszym zapachem. Procedura poruszania zapewnia element losowy ruchowi mrówek, co zapewnia, ŋe będą one bardzo skuteczne w badaniu caģego ķrodowiska, podobnie jak czynniki ŋóģwia w Przykģadzie 2 Look Ahead. W tym przykģadzie wielu agentów zatrudniających proste zachowanie reaktywne jest w stanie wykonaæ nietrywialne zadanie, po prostu jako skutek uboczny ich wzajemnej interakcji ze ķrodowiskiem. Gdyby pojedynczy agent miaģ wykazywaæ tę samą zdolnoķæ - w peģni odkrywaæ swoje ķrodowisko dla jedzenia i odnajdywaæ drogę powrotną do domu, gdy tylko znajdzie jakieķ - wtedy my jako obserwatorzy moglibyķmy przypisaæ pewien stopieņ inteligencji agentowi. Mrówki uŋywają formy zbiorowej inteligencji - inteligencja pochodzi z kolektywnego wyniku wielu agentów wspóģdziaģających ze sobą. Jest takŋe moŋliwe, aby pojedynczy agent reaktywny (a nie zbiór agentów) pomyķlnie ukoņczyģ nietrywialne zadanie bez wiedząc, ŋe to robi? Na przykģad, czy pojedynczy agent moŋe przejķæ przez labirynt przez zastosowanie prostego zachowania reaktywnego, gdy nie jest w stanie rozpoznaæ, ŋe istnieją alternatywne ķcieŋki do zbadania? Opracowano model o nazwie Mazes, aby pokazaæ, jak to jest moŋliwe. Zrzuty ekranu tego modelu pokazano na trzech rysunkach . Pokazują ŋóģwie uŋywające prostych zachowaņ reaktywnych do poruszania się po trzech labiryntach zdefiniowanych w Częķci 3 - pusty labirynt, Labirynt Paģacu Hampton Court i labirynt Chevening House. Zwróæ uwagę, ŋe musimy uwaŋaæ, jak omawiamy zachowanie i dziaģania agenta ŋóģwia w modelu. Nie moŋemy powiedzieæ, ŋe agent "eksploruje" labirynt - eksploracja zakģada pewien stopieņ woli ze strony agenta prowadzącego eksplorację. Podobnie, nie moŋemy powiedzieæ, ŋe agent "rozwiązaģ" labirynt, kiedy dotarģ do centrum lub doszedģ do wyjķcia. Rozwiązywanie wymaga poznania - czyli rozpoznania danego zadania. Wszystko, co moŋemy powiedzieæ, to to, ŋe agent porusza się po labiryncie, a dzięki temu udaje mu się osiągnąæ pewien stan (np. centrum lub wyjķcie) jako efekt uboczny jego zachowania. Model zapewnia selektor interfejsów o nazwie zachowanie ŋóģwia, które pozwala nam zdefiniowaæ reaktywne zachowanie agenta ŋóģwia, gdy porusza się po labiryncie. Są zdefiniowane cztery zachowania: Hand On the Wall, Random Forward 0, Random Forward 1 i Random Forward 2. Kod NetLogo definiujący te zachowania
jest pokazany w kodzie NetLogo
to walk ;; procedura ŋóģwiaturtle procedure
;; w razie potrzeby skręæ w prawo
ifelse set-pen-down [ pen-down ] [ pen-up ]
if count neighbors4 with [pcolor = blue] = 4
[ user-message "Trapped!"
stop ]
let xpos [goal-x] of maze 0
if xcor >= xpos and xcor <= xpos + [goal-width] of maze 0 and
ycor = [goal-y] of maze 0
[ ifelse [goal-type] of maze 0 = "Exit"
[ user-message "Found the exit!" ]
[ user-message "Made it to the centre of the maze!" ]
stop ]
if (turtle-behaviour = "Hand On The Wall") [behaviour-wall-following]
if (turtle-behaviour = "Random Forward 0") [behaviour-random-forward-0]
if (turtle-behaviour = "Random Forward 1") [behaviour-random-forward-1]
if (turtle-behaviour = "Random Forward 2") [behaviour-random-forward-2]
end
t′to-report wall? [angle dist]
;; zwróæ uwagę, ŋe kąt moŋe byæ dodatni lub ujemny. jeķli kąt jest równy
;; pozytywne, ŋóģw wygląda dobrze. jeķli kąt jest ujemny,
;; ŋóģw wygląda w lewo.
let patch-color [pcolor] of patch-right-and-ahead angle dist
report patch-color = blue or patch-color = sky
; niebieski, jeķli jest to ķciana, niebo, jeķli jest to zamknięte wejķcie
end
to behaviour-wall-following
; klasyczne zachowanie na ķcianie
if not wall? (90 * direction) 1 and wall? (135 * direction) (sqrt 2)
[ rt 90 * direction ]
;; ķciana prosto: w razie potrzeby skręæ w lewo (czasami więcej niŋ raz)
while [wall? 0 1] [ lt 90 * direction]
;; ruszaj naprzód
fd 1
end
to behaviour-random-forward-0
; przesuwa się do przodu, chyba ŋe jest ķciana, a następnie próbuje skręciæ w lewo, a następnie w prawo
; następnie losowo zamienia się w ostatecznoķæ
if wall? 0 1
[ ifelse wall? 90 1
[ lt 90 ]
[ ifelse wall? 270 1
[ rt 90 ]
[ ifelse random 2 = 0 [lt 90] [rt 90] ]]]
;; ruszaj naprzód
fd 1
end
to behaviour-random-forward-1
; porusza się gģównie w liniach prostych
ifelse wall? 0 1
[ bk 1 ]
;jeszcze
[ let r random 20
ifelse r = 0
[ if not wall? 90 1 [rt 90 fd 1] ]
;jeszcze
[ ifelse r = 1
[ if not wall? 270 1 [lt 90 fd 1] ]
[ let f random 5
while [not wall? 0 1 and f > 0]
[ fd 1
set f f - 1]]]]
end
to behaviour-random-forward-2
; porusza się w przypadkowych maģych krokach
let r random 3
ifelse r = 0
[ if not wall? 90 1 [rt 90 fd 1] ]
[ ifelse r = 1
[ if not wall? 270 1 [lt 90 fd 1] ]
[ if not wall? 0 1 [fd 1] ]]
end
Procedura walk okreķla sposób poruszania się agenta ŋóģwia w labiryncie. Agent ma moŋliwoķæ wyczucia, czy w pobliŋu znajduje się wall (wykorzystująca prymitywny zmysģ oparty na detekcji bliskoķci), a to jest zdefiniowane przez wall? reporter w kodzie. Kod definiuje następnie cztery róŋne rodzaje zachowaņ. Procedura behaviour-wall-following okreķla klasyczne zachowanie "ręka na ķcianie" - agent próbuje trzymaæ rękę na ķcianie podobnej do agentów ŋóģwia w poniŋszym przykģadzie. W przypadku procedury behaviour-random-forward-0 agent ŋóģwia najpierw wyczuwa, czy jest ķciana, a następnie próbuje skręciæ w lewo, a potem w prawo, a następnie losowo zmienia się w ostatecznoķci przed przejķciem do przodu o 1 stopieņ. W przypadku procedury behaviour-random-forward-1 agent ŋóģwia przemieszcza się gģównie w linii prostej, chyba ŋe jest zablokowany przez ķcianę. W procedurze behaviour-random-forward-2 agent ŋóģwia przemieszcza się losowo maģymi krokami. Definicje tych zachowaņ są stosunkowo proste, ale niektóre z nich są bardzo zģoŋone ruchy w wyniku. Nigdzie jednak w definicjach nie ma ŋadnego poznania ze strony agenta - agent realizujący te zachowania ķwiadomie nie robi tego ķwiadom, wiedząc, ŋe pewne dziaģanie lub dziaģania doprowadzą do poŋądanego rezultatu.