III.Wczesne eksploracje: lata 50. i 60. XX wieku
Jeķli maszyny mają staæ się inteligentne, muszą przynajmniej byæ w stanie robiæ rzeczy związane z myķleniem, które mogą zrobiæ ludzie. Pierwsze kroki w poszukiwaniu sztucznej inteligencji polegaģy na zidentyfikowaniu niektórych konkretnych zadaņ, które wedģug nich wymagają inteligencji, i znalezieniu sposobu na pozyskanie maszyn do ich wykonania. Rozwiązywanie zagadek, granie w szachy i warcaby, dowodzenie twierdzeņ, odpowiadanie na proste pytania i klasyfikowanie obrazów wizualnych byģy jednymi z problemów, z którymi zmagali się pierwsi pionierzy w latach 50. i 60. XX wieku. Chociaŋ większoķæ z nich to problemy w stylu laboratoryjnym, czasami nazywane "zabawkami", niektóre rzeczywiste problemy o znaczeniu komercyjnym, takie jak automatyczny odczyt wysoce stylizowanych znaków magnetycznych na brzegu, atakowano równieŋ kontrole i tģumaczenia językowe. (O ile mi wiadomo, Seymour Papert byģ pierwszym, który uŋyģ zdania "problem z zabawkami". "Podczas warsztatów AI z 1967 r., w Atenach w stanie Georgia, wyróŋniaģ między problemami tau lub "zabawkami ", problemami rho lub rzeczywistymi, oraz problemy theta lub "teorii" w sztucznej inteligencji. To rozróŋnienie wciąŋ dobrze nam sģuŋy. W tej częķci opiszę niektóre z pierwszych rzeczywistych prób budowy inteligentnych maszyn. Niektóre z nich zostaģy omówione lub zgģoszone na konferencje i sympozja - czyniąc te spotkania waŋnymi kamieniami milowymi w narodzinach AI. Zrobię równieŋ wszystko, aby wyjaķniæ podstawy dziaģania niektórych z tych wczesnych programów AI. Doķæ dramatyczne sukcesy w tym okresie pomogģy stworzyæ solidną podstawę dla kolejnych badania sztucznej inteligencji. Niektórzy badacze byli zaintrygowani (moŋna powiedzieæ, ŋe zostali schwytani) metodami, których uŋywali, poķwięcając się bardziej na poprawie mocy i ogólnoķci wybranych technik niŋ na zastosowaniu ich do zadaņ, które wedģug nich wymagają . Co więcej, poniewaŋ niektórzy badacze byli tak samo zainteresowani wyjaķnieniem, w jaki sposób mózg rozwiązuje problemy, jak przy pozyskiwaniu do tego maszyn, opracowywane metody byģy często proponowane jako wkģad w teorie na temat ludzkich procesów umysģowych. W ten sposób badania w psychologii poznawczej i badania nad sztuczną inteligencją staģy się ze sobą ķciķle powiązane.
Spotkania
We wrzeķniu 1948 r. W California Institute of Technology (Caltech) w Pasadenie w Kalifornii odbyģa się interdyscyplinarna konferencja na temat tego, jak ukģad nerwowy kontroluje zachowanie i jak mózg moŋna porównaæ do komputera. Nazywaģo się to Sympozjum Hixona na temat mechanizmów mózgowych w zachowaniu. Uczestniczyģo w nich kilku luminarzy i wygģaszaģo referaty, w tym Warren McCulloch, John von Neumann i Karl Lashley (1890 -1958), wybitny psycholog. Lashley wygģosiģ coķ, co wedģug niektórych byģo najwaŋniejszą przemową na sympozjum. Zarzuciģ behawioryzmowi jego statyczny obraz funkcji mózgu i twierdziģ, ŋe aby wyjaķniæ ludzkie moŋliwoķci planowania i języka, psychologowie musieliby zacząæ rozwaŋaæ dynamiczne, hierarchiczne struktury. Wystąpienie Lashleya poģoŋyģo podwaliny pod to, co staģoby się kognitywistyką. Pojawienie się sztucznej inteligencji jako peģnego pola badaņ zbiegģo się (i zostaģo zapoczątkowane) przez trzy waŋne spotkania - jedno w 1955 r., jedno w 1956 r. I jedno w 1958 r. W 1955 r. Odbyģa się "Sesja na temat uczenia się maszyn" zorganizowane w poģączeniu z Western Joint Computer Conference 1955 w Los Angeles. W 1956 r. W Dartmouth College zwoģano "Summer Research Project on Artiial Intelligence". W 1958 r. Sympozjum na temat "Mechanizacji procesów myķlowych" sponsorowaģo Narodowe Laboratorium Fizyczne w Wielkiej Brytanii.
Sesja na temat uczenia się maszyn
Cztery waŋne artykuģy zostaģy zaprezentowane w Los Angeles w 1955 roku. We wstępie swojego przemówienia do tej sesji Willis Ware napisaģ:
"Dokumenty te nie sugerują, ŋe przyszģe maszyny uczące się powinny byæ zbudowane zgodnie z ogólnym cyfrowym urządzeniem komputerowym; jest raczej tak, ŋe cyfrowy system komputerowy oferuje wygodne i wysoce elastyczne narzędzie do badania zachowania modeli. Ta grupa dokumentów sugeruje kierunki ulepszeņ dla przyszģych konstruktorów maszyn, których celem jest wykorzystanie cyfrowych maszyn obliczeniowych do tej konkretnej techniki modelowej. Szybkoķæ operacji musi byæ wielokrotnie zwiększana; jednoczesne dziaģanie w wielu trybach równolegģych jest silnie wskazane; wielkoķæ losowego dostępu pamięæ masowa musi przeskakiwaæ o kilka rzędów wielkoķci; potrzebne są nowe typy urządzeņ wejķciowych. Dzięki takim postępom i technikom omówionym w tych dokumentach istnieje znaczna obietnica, ŋe systemy mogą zostaæ zbudowane w stosunkowo bliskiej przyszģoķci, co będzie imitowaæ znaczną częķæ aktywnoķæ mózgu i ukģadu nerwowego "
Na szczęķcie poczyniliķmy znaczne postępy w zakresie produktów znajdujących się na liķcie "wskazówek dotyczących ulepszeņ" Ware'a. Szybkoķæ dziaģania wzrosģa wielokrotnie, w wielu systemach AI wykorzystywana jest praca równolegģa, pamięæ o dostępie swobodnym skoczyģa o kilka rzędów wielkoķci i dostępnych jest wiele nowych typów urządzeņ wejķciowych. Byæ moŋe konieczne będą dalsze usprawnienia. Pierwszy artykuģ sesji, autorstwa Wesleya Clarka i Belmonta Farleya z Lincoln Laboratory MIT, opisaģ niektóre eksperymenty z rozpoznawaniem wzorców na sieciach elementów podobnych do neuronów. Zmotywowani propozycją Hebba, aby zespoģy neuronów mogģy się uczyæ i dostosowywaæ poprzez dostosowanie siģy ich wzajemnych poģączeņ, eksperymentatorzy próbowali róŋnych schematów dostosowywania siģy poģączeņ w swoich sieciach, które zwykle byģy symulowane na komputerach. Niektórzy chcieli tylko zobaczyæ, co mogą zrobiæ te sieci, podczas gdy inni, tacy jak Clark i Farley, byli zainteresowani konkretnymi aplikacjami, takimi jak rozpoznawanie wzorców. Ku przeraŋeniu neurofizjologów, którzy skarŋyli się na nadmierne obciąŋenie, sieci te nazwano sieciami neuronowymi. Clark i Farley doszli do wniosku, ŋe "surowe, ale uŋyteczne wģaķciwoķci uogólniające posiadają nawet losowo poģączone sieci opisanego typu" .Kolejna para artykuģów, jedna autorstwa Geralda P. Dinneena (1924-), a druga Olivera Selfridge'a (1926-), obaj z Lincoln Laboratory firmy MIT przedstawiģy inne podejķcie do rozpoznawania wzorów. W artykule Dinneen opisa; techniki obliczeniowe przetwarzania obrazów. Obrazy zostaģy przedstawione komputerowi jako prostokątny zestaw wartoķci intensywnoķci odpowiadających róŋnym odcieniom szaroķci na obrazie. Dinneen byģ pionierem zastosowanie metod filtrowania w celu usunięcia przypadkowych kawaģków haģasu, pogrubienia linii i krawędzi. Rozpocząģ pracę od:
"W ciągu ostatnich miesięcy podczas serii spotkaņ po lunchu i lunchu grupa nas w laboratorium zastanawiaģa się nad problemami w tym obszarze. Nasze odczucie, niemal jednogģoķnie, byģo takie, ŋe istnieje potrzeba praktycznego dziaģania, wybrania prawdziwego problemu na ŋywo i zajęcia się nim ".
Tekst Selfridge'a byģ kawaģkiem towarzyszącym artykuģowi Dinneen. Operując na "oczyszczonych" obrazach (jak na przykģad program Dinneen), Selfridge opisaģ techniki podķwietlania "cech" na tych obrazach, a następnie klasyfikowania ich na podstawie cech. Na przykģad naroŋniki obrazu, o których wiadomo, ŋe są kwadratem lub trójkątem, są podķwietlone, a następnie zliczana jest liczba naroŋników w celu ustalenia, czy obraz jest kwadratem czy trójkątem. Selfridge powiedziaģ, ŋe "ostatecznie mamy nadzieję rozpoznaæ inne rodzaje cech, takie jak krzywizna, zestawienie pojedynczych punktów (tj. Ich względne poģoŋenie i odlegģoķci) i tak dalej".
Metody zapoczątkowane przez Selfridge'a i Dinneena mają fundamentalne znaczenie dla większoķci póžniejszych prac nad umoŋliwieniem maszynom "widzenia". Ich praca jest tym bardziej niezwykģa, gdy wežmie się pod uwagę, ŋe wykonano ją na komputerze, Lincoln Laboratory "Memory Test Computer", który dziķ moŋna by uznaæ za niezwykle prymitywny. [Komputer testowy pamięci (MTC) jako pierwszy uŋyģ moduģów pamięci o swobodnym dostępie z rdzeniem ferrytowym opracowanych przez Jaya Forrestera. Zostaģ zaprojektowany i zbudowany przez Kena Olsena w 1953 roku w Digital Equipment Corporation (DEC). MTC byģ pierwszym komputerem do symulacji dziaģania sieci neuronowych (tych Clarka i Farleya). Kolejny artykuģ dotyczyģ programowania komputera do gry w szachy. Zostaģ napisany przez Allena Newella, wówczas badacza z Rand Corporation w Santa Monica. Dzięki biograficznemu szkicowi Newella napisanemu przez jego kolegę, Herb'a Simona z Carnegie Mellon University, wiemy coķ o motywacji Newella i tym, jak zainteresowaģ się tym problemem:
"We wrzeķniu 1954 roku Allen wziąģ udziaģ w seminarium w RAND, w którym Oliver Selfridge z Lincoln Laboratory opisaģ dziaģający program komputerowy, który nauczyģ się rozpoznawaæ litery i inne wzory. Sģuchając Selfridge'a charakteryzującego jego raczej prymitywny, ale dziaģający system, Allen doķwiadczyģ tego, o czym zawsze mówiģ jako jego "doķwiadczenie konwersji". "Od razu staģo się dla niego jasne", ŋe moŋna zbudowaæ inteligentne systemy adaptacyjne, które byģy znacznie bardziej zģoŋone niŋ cokolwiek jeszcze. o przetwarzaniu informacji w organizacjach, o cybernetyki i propozycjach programów szachowych dodano teraz konkretną demonstrację wykonalnoķci komputerowej symulacji zģoŋonych procesów. W tym czasie zaangaŋowaģ się w zrozumienie ludzkiej nauki i myķlenia poprzez symulację ".
Simon podsumowuje artykuģ Newella na temat szachów:
"[Przedstawiģ] wymyķlny projekt programu komputerowego do gry w szachy w humanoidalny sposób, obejmujący pojęcia celów, poziomy aspiracji do zakoņczenia poszukiwaņ, satysfakcję z" wystarczająco dobrych "ruchów, wielowymiarowe funkcje oceny, generowanie subceli do realizacji celów, i coķ w rodzaju najlepszego pierwszego wyszukiwania. Informacje o tablicy miaģy byæ wyraŋone symbolicznie w języku przypominającym rachunek predykatów. Projekt nigdy nie zostaģ wdroŋony, ale póžniej zapoŋyczono z niego pomysģy do wykorzystania w NSS [Newell, Shaw i Simon] program szachowy w 1958 r. "
Newell zasugerowaģ, ŋe jego cele wykraczają poza szachy. W swoim artykule napisaģ: "Zatem celem tego wysiģku jest zaprogramowanie obecnego komputera do nauki dobrej gry w szachy. Jest to sposób na lepsze zrozumienie rodzajów komputerów, mechanizmów i programów niezbędnych do obsģugi ultraskomplikowanych problemów ". Proponowane techniki Newella moŋna uznaæ za jego pierwszą próbę uzyskania dowodów na to, co on i Simon nazwali póžniej hipotezą fizycznego systemu symboli. Walter Pitts, komentator tej sesji, zakoņczyģ ją mówiąc: "Jednak, podczas gdy panowie Farley, Clark, Selfridge i Dinneen naķladują ukģad nerwowy, pan Newell woli naķladowaæ hierarchię pierwotnych przyczyn, zwanych tradycyjnie umysģem. Ostatecznie dojdzie do tego samego, bez wątpienia… " Aby dojķæ do tego samego, "te dwa podejķcia, modelowanie neuronowe i przetwarzanie symboli, naleŋy uznaæ po prostu za róŋne poziomy opisu tego, co dzieje się w mózgu. Róŋne poziomy są odpowiednie do opisywania róŋnych rodzajów zjawisk mentalnych
Letni projekt Dartmouth
W 1954 roku John McCarthy (1927-) doģączyģ do Dartmouth College w Hanover, New Hampshire, jako adiunkt matematyki. McCarthy stale interesowaģ się czymķ, co nazwano by sztuczną inteligencją. Zostaģo "uruchomione", mówi, "biorąc udziaģ w Sympozjum Hixon na temat mechanizmów mózgowych w zachowaniu we wrzeķniu 1948 r., Które odbyģo się w Caltech, gdzie zaczynaģem pracę magisterską z matematyki". Podczas pobytu w Dartmouth zostaģ zaproszony przez Nathaniela Rochestera (1919-2001) do spędzenia lata 1955 r. w dziale badaņ informacyjnych Rochester w IBM w Poughkeepsie w Nowym Jorku. Rochester byģ projektantem komputera IBM 701 i braģ równieŋ udziaģ w badaniach sieci neuronowych. W IBM tego lata McCarthy i Rochester przekonali Claude'a Shannona i Marvina Minsky'ego (1927-), wówczas mģodszego adiunkta Harvarda z matematyki i neurologii, aby przyģączyli się do nich, proponując warsztaty, które odbędą się w Dartmouth następnego lata. Shannon, o którym wczeķniej wspomniaģem, byģ matematykiem w Bell Telephone Laboratories i juŋ sģynąģ z pracy nad teorią przeģączania i teorią informacji statystycznych. McCarthy przejąģ inicjatywę, pisząc propozycję i organizując coķ, co nazwano "Letnim projektem badawczym na temat sztucznej inteligencji". Propozycja zostaģa przedģoŋona Fundacji Rockefellera w sierpniu 1955 r.
Fragmenty wniosku brzmią następująco:
"Proponujemy przeprowadzenie 2-miesięcznego, 10-osobowego badania sztucznej inteligencji latem 1956 r. W Dartmouth College w Hanover, New Hampshire. Badanie ma byæ przeprowadzone na podstawie przypuszczenia, ŋe kaŋdy aspekt uczenia się lub jakakolwiek inna cecha inteligencji moŋe byæ w zasadzie tak precyzyjnie opisana, ŋe moŋna stworzyæ maszynę do jej symulacji. Zostanie podjęta próba znalezienia sposobu, w jaki maszyny będą uŋywaæ języka, tworzyæ abstrakcje i koncepcje, rozwiązywaæ rodzaje problemów zarezerwowanych obecnie dla ludzi i poprawiaæ się. Uwaŋamy, ŋe moŋna dokonaæ znacznego postępu w zakresie jednego lub więcej z tych problemów, jeķli starannie wybrana grupa naukowców będzie pracowaæ nad tym razem przez lato ".
…
W obecnym celu przyjmuje się, ŋe problemem sztucznej inteligencji jest sprawienie, aby maszyna zachowywaģa się w sposób, który nazwano by inteligentnym, gdyby tak zachowywaģ się czģowiek ".
Fundacja Rockefellera zapewniģa fundusze na to wydarzenie, które odbyģo się w ciągu szeķciu tygodni lata 1956 r. Okazaģo się jednak, ŋe jest to bardziej ciągģy szeķciotygodniowy warsztat niŋ letnie "studium". Wķród osób biorących udziaģ w warsztatach tego lata, oprócz McCarthy'ego, Minsky'ego, Rochestera i Shannona, byli Arthur Samuel (1901-1990), inŋynier w korporacji IBM, który napisaģ juŋ program gry w warcaby, Oliver Selfridge, Ray Solomonoff z MIT, który byģ zainteresowany automatyzacją indukcji, Allen Newell i Herbert Simon. Newell i Simon (wraz z innym naukowcem Rand, Cliffem Shawem) opracowali program do dowodzenia twierdzeņ w logice symbolicznej. Kolejnym naukowcem IBM byģ Alex Bernstein, który pracowaģ nad programem szachowym. McCarthy podaģ kilka powodów, dla których uŋyģ terminu "sztuczna inteligencja". Pierwszym byģo odróŋnienie tematyki zaproponowanej na warsztaty w Dartmouth od wczeķniejszego tomu zamówionych artykuģów, zatytuģowanych Automata Studies, wspóģredagowanych przez McCarthy'ego i Shannona, które (ku rozczarowaniu McCarthy'ego) w duŋej mierze dotyczyģy ezoterycznego i raczej wąskiego przedmiotu matematycznego zwany teorią automatów. Drugi, wedģug McCarthy'ego, polegaģ na "uniknięciu skojarzenia z" cybernetyką ". Skoncentrowanie się na sprzęŋeniu analogowym wydawaģo się mylące i chciaģem uniknąæ akceptacji Norberta Wienera jako guru lub kģótni z nim. "
Ta nazwa byģa (i nadal jest) kontrowersyjna. Wedģug doskonaģej historii Pameli McCorduck o początkach sztucznej inteligencji, Art Samuel zauwaŋyģ: "Sģowo" sztucznoķæ "sprawia, ŋe myķlisz ,ŋe jest w tym coķ faģszywego, albo brzmi, jakby to wszystko byģo sztuczne i nie ma w tym nic prawdziwego. McCorduck mówi dalej, ŋe " Newellowi lub Simonowi spodobaģo się to zdanie i nazwali je wģasnym pracując przez lata przy zģoŋonym przetwarzaniu informacji. "Ale większoķæ osób, które zapisaģy się do pracy w tym nowym polu (w tym ja), uŋywaģa nazwy" sztuczna inteligencja "i tak nazywa się to dzisiaj. (Póžniej, Newell pogodziģ się z tą nazwą. Komentując treķæ pola, stwierdziģ: "Więc pielęgnuj nazwę sztuczna inteligencja. To dobra nazwa. Jak wszystkie nazwiska naukowców, będzie rosģo, aby staæ się dokģadnie tym, czym jest pole jakie ma na myķli. ") Podejķcia i motywacje ludzi na warsztatach róŋniģy się. Rochester przybyģ na konferencję z doķwiadczeniem w sieci elementów podobnych do neuronów. Newell i Simon stosowali (a wģaķciwie pomogli stworzyæ) podejķcie do przetwarzania symboli.
Jednym z tematów, o których Shannon chciaģ pomyķleæ (zgodnie z propozycją), byģo zastosowanie koncepcji teorii informacji w komputerach i modelach mózgu. "(Po warsztatach Shannon odwróciģ jednak uwagę od sztucznej inteligencji.) McCarthy napisaģ ŋe chciaģ zbudowaæ "sztuczny język, który moŋna zaprogramowaæ w komputerze do rozwiązywania problemów wymagających przypuszczeņ i samodzielnego odniesienia. Powinien on odpowiadaæ językowi angielskiemu w tym sensie, ŋe krótkie angielskie wypowiedzi na dany temat powinny mieæ krótkich korespondentów w języku, podobnie jak krótkie argumenty lub przypuszczenia. Mam nadzieję, ŋe spróbuję sformuģowaæ język posiadający te wģaķciwoķci. . . "
Chociaŋ McCarthy powiedziaģ póžniej, ŋe jego pomysģy na ten temat są nadal zbyt "žle sformuģowane" do prezentacji na konferencji, nie minęģo wiele czasu, zanim przedstawiģ konkretne propozycje uŋycia języka logicznego i jego mechanizmów wnioskowania do reprezentowania i rozumowania wiedzy. Chociaŋ rozprawa doktora Minsky'ego i niektóre z jego póžniejszych prac koncentrowaģy się na sieciach neuronowych, w czasie warsztatów w Dartmouth zacząģ zmieniaæ kierunek. Teraz, jak napisaģ, chciaģ rozwaŋyæ maszynę, która miaģaby tendencję do tworzenia w sobie abstrakcyjnego modelu ķrodowiska, w którym jest umieszczona. Gdyby napotkano problem, mógģby najpierw zbadaæ rozwiązania w ramach wewnętrznego abstrakcyjnego modelu ķrodowiska, a następnie podjąæ próbę eksperymentów zewnętrznych. "Podczas warsztatów Minsky kontynuowaģ prace nad szkicem, który póžniej zostaģ opublikowany jako praca podstawowa, "Kroki Ku inteligencji sztucznej. "Jednym z najwaŋniejszych technicznych wkģadów ze spotkania w 1956 r. Byģa praca Newella i Simona nad ich programem" Logic Theorist (LT) "sģuŋącym do udowodnienia twierdzeņ w logice symbolicznej. LT byģ konkretnym dowodem na to, ŋe przetwarzanie "struktury symboli "i wykorzystanie tego, co Newell i Simon nazywali "heurystyką" byģy fundamentem inteligentnego rozwiązywania problemów. Opiszę niektóre z tych pomysģów bardziej szczegóģowo w następnej częķci. Newell i Simon pracowali nad pomysģami na LT dla kilka miesięcy i przekonaģ się pod koniec 1955 r., ŋe moŋna je wcieliæ w dziaģający program. Wedģug Edwarda Feigenbauma (1936 -), który odbywaģ kurs u Herb Simona w Carnegie na początku 1956 r., "To tuŋ po ķwiętach Boŋego Narodzenia - styczeņ 1956 r. -kiedy Herb Simon wszedģ do klasy i powiedziaģ: "W czasie ķwiąt Allen Newell i ja wynaležliķmy maszynę myķlącą." "To, co wkrótce miaģo zostaæ zaprogramowane jako LT, byģo maszyną myķlącą" Simon mówiģ o niej. Nazywaģ to tak, bez wątpienia, poniewaŋ myķlaģ, ŋe tak się staģo ,ŋe niektóre z tych samych metod rozwiązywania problemów, z których korzystają ludzie. Simon napisaģ póžniej: "W czwartek, 15 grudnia. Udaģo mi się ręcznie zasymulowaæ pierwszy dowód ... Zawsze 15 grudnia 1955 roku obchodziģem urodziny heurystycznego rozwiązywania problemów przez komputer". Zgodnie z autobiografią Simona "Modele mojego ŋycia" LT rozpoczęģo się od symulacji ręcznej, wykorzystując swoje dzieci jako elementy komputerowe, jednoczeķnie pisząc i trzymając karty notatek jako rejestry zawierające zmienne stanu programu. Kolejnym tematem omawianym w Dartmouth byģ problem udowodnienia twierdzeņ w geometrii. (Byæ moŋe niektórzy czytelnicy przypomną sobie swoje zmagania z dowodami geometrii w liceum). Minsky juŋ myķlaģ o programie do udowodnienia twierdzeņ geometrii. McCorduck cytuje go, mówiąc:
"Prawdopodobnie waŋnym wydarzeniem w moim rozwoju - i wyjaķnieniem mojej byæ moŋe zaskakująco przypadkowej akceptacji pracy Newella-Shawa - Simon - byģo to, ŋe naszkicowaģem heurystyczną procedurę poszukiwania maszyny geometrycznej, a następnie byģem w stanie podaæ ją - naķladuj to na papierze w ciągu okoģo godziny. Pod moją ręką powstaģ nowy dowód twierdzenia o trójkącie równoramiennym, dowód, który byģ nowy i elegancki dla uczestników - póžniej odkryliķmy, ŋe dowód byģ dobrze znany. . ."
W lipcu 2006 r. W Dartmouth odbyģa się kolejna konferencja z okazji pięædziesiątej rocznicy pierwszej konferencji. Kilku zaģoŋycieli i innych wybitnych badaczy sztucznej inteligencji wzięģo udziaģ w ankiecie i dokonaģo przeglądu tego, co osiągnięto od 1956 r. McCarthy przypomniaģ, ŋe gģównym powodem warsztatów Dartmouth w 1956 r. nie byģo speģnienie moich oczekiwaņ, poniewaŋ AI jest trudniejsze niŋ się spodziewaliķmy. , warsztaty z 1956 r. są uwaŋane za oficjalny początek powaŋnej pracy w sztucznej inteligencji, a Minsky, McCarthy, Newell i Simon zostali uznani za "ojców" AI. W bibliotece Baker Library w Dartmouth poķwięcono tablicę upamiętniającą początek sztucznej inteligencji jako dyscypliny naukowej.
Mechanizacja procesów myķlowych
W listopadzie 1958 r. Sympozjum na temat "Mechanizacji Procesu Myķli "odbyģo się w National Physical Laboratory w Teddington, Middlesex, Anglia. Zgodnie z przedmową z konferencji, sympozjum odbyģo się" w celu zgromadzenia naukowców badających myķlenie sztuczne, rozpoznawanie znaków i wzorów, naukę, mechaniczne tģumaczenie języka, biologia, programowanie automatyczne, planowanie przemysģowe i mechanizacja biurowa. "
Wķród osób, które zaprezentowaģy referaty na tym sympozjum byģo wielu, o których juŋ wspomniaģem w tej historii. Naleŋą do nich Minsky (wówczas czģonek personelu w Lincoln Laboratory i na drodze do zostania profesorem matematyki na MIT), McCarthy (wówczas asystent profesora nauk o komunikacji na MIT), Ashby, Selfridge i McCulloch. (John Backus, jeden z twórców komputerowego języka programowania FORTRAN, i Grace Murray Hopper, pionier "programowania automatycznego" równieŋ wygģosili referaty.) Obrady tej konferencji zawierają artykuģy, które staģy się bardzo wpģywowe w historii sztucznej inteligencji. Wķród nich wymienię te autorstwa Minsky'ego, McCarthy'ego i Selfridge'a. Artykuģ Minsky'ego "Niektóre metody sztucznej inteligencji i programowania heurystycznego" byģ najnowszą wersją utworu, nad którym pracowaģ tuŋ przed warsztatami w Dartmouth. W artykule opisano róŋne metody, które byģy (i mogģyby byæ) wykorzystane w programowaniu heurystycznym. Obejmowaģ takŋe metody rozpoznawania wzorców, uczenia się i planowania. Ostateczna wersja, która wkrótce miaģa zostaæ opublikowana jako "Kroki w kierunku sztucznej inteligencji", miaģa staæ się obowiązkową lekturą dla nowych rekrutów do pól. Wspomniaģem juŋ o nadziei McCarthy'ego na opracowanie języka sztucznej inteligencji dla AI. Podsumowaģ swój artykuģ konferencyjny "Programy ze zdrowym rozsądkiem" w następujący sposób:
"W tym artykule omówione zostaną programy do manipulacji w odpowiednim języku formalnym (najprawdopodobniej częķæ rachunku predykatów) typowymi stwierdzeniami instrumentalnymi. Program podstawowy wyciągnie natychmiastowe wnioski z listy przesģanek. Wnioski te będą zdaniami deklaratywnymi lub imperatywnymi. Kiedy wydane zostanie zdanie rozkazujące, program podejmuje odpowiednie dziaģanie. "
W swoim artykule McCarthy zasugerowaģ, ŋe fakty potrzebne programowi AI, który nazwaģ "przyjmującym porady", moŋe byæ reprezentowany jako wyraŋenie w matematycznym (i przyjaznym dla komputera) języku zwanym "logiką pierwszego rzędu". Na przykģad fakty "Jestem przy biurku" i "Moje biurko jest w domu" byģyby reprezentowane jako wyraŋenia na (ja, biurko) i na (biurko, dom). Te, wraz z podobnie reprezentowanymi informacjami o tym, jak osiągnąæ zmianę lokalizacji (na przykģad pieszo i samochodem), mogą byæ następnie wykorzystane przez proponowanego (ale jeszcze nie zaprogramowanego) doradcę, aby dowiedzieæ się, jak osiągnąæ jakiķ cel, taki jak będąc na lotnisku. Proces wnioskowania doradcy wytworzyģyby logiczne wyraŋenia, które wymagaģyby przejķcia do samochodu i jazdy na lotnisko. Reprezentowanie faktów w języku logicznym ma kilka zalet. Jak to póžniej ująģ McCarthy:
"Wyraŋanie informacji w zdaniach deklaratywnych jest o wiele bardziej moduģowe niŋ wyraŋanie ich w segmentach programu komputerowego lub w tabelach. Zdania mogą byæ prawdziwe w znacznie szerszych kontekstach, niŋ konkretne programy mogą byæ przydatne. Dostawca faktu nie musi wiele rozumieæ na temat jak dziaģa odbiorca lub jak lub czy będzie go uŋywaæ. Ten sam fakt moŋna wykorzystaæ do wielu celów, poniewaŋ logiczne konsekwencje zbiorów faktów mogą byæ dostępne "
McCarthy rozwinąģ te pomysģy w memorandum towarzyszącym. Jak wspomnę póžniej, niektóre z propozycji McCarthy'ego zostaģy ostatecznie wdroŋone przez absolwenta Stanforda, C. Cordella Greena. Wspomniaģem juŋ o pracy Olivera Selfridge'a z rozpoznawaniem wzorów w 1955 roku. Na sympozjum Teddington w 1958 r. Selfridge przedstawiģ artykuģ na temat nowego modelu rozpoznawania wzorców (i prawdopodobnie takŋe innych zadaņ poznawczych). Nazwaģ go "Pandemonium", co oznacza miejsce wszystkich demonów. Jego model jest szczególnie interesujący, poniewaŋ jego komponenty, które Selfridge nazywa "demonami", mogą byæ tworzone zarówno jako speģniające funkcje komórek nerwowych niŋszego poziomu, jak i funkcje poznawcze wyŋszego poziomu (odmiany przetwarzającej symbole). Tak więc Pandemonium moŋe przybieraæ formę sieci neuronowej, hierarchicznie zorganizowanego zestawu procesorów symboli {wszystkie pracujące równolegle lub jakiejķ kombinacji tych form. Jeķli to drugie, model jest prowokującą propozycją poģączenia tych dwóch odmiennych podejķæ do sztucznej inteligencji. We wstępie do swojej pracy Selfridge podkreķliģ znaczenie obliczeņ wykonywanych równolegle:
"Podstawowym motywem naszego modelu jest koncepcja przetwarzania równolegģego. Sugeruje się to z dwóch powodów: po pierwsze, często ģatwiej jest przetwarzaæ dane w sposób równolegģy i rzeczywiķcie jest to zwykle bardziej naturalny sposób postępowania to w; a po drugie, ģatwiej jest zmodyfikowaæ zespóģ quasi-niezaleŋnych moduģów niŋ maszyna, której wszystkie częķci wchodzą w interakcję natychmiastowo i w zģoŋony sposób ".
Selfridge przedstawiģ kilka sugestii dotyczących tego, jak Pandemonium moŋe się uczyæ. Warto opisaæ niektóre z nich, poniewaŋ zapowiadają póžniejszą pracę w uczeniu maszynowym. Ale najpierw muszę powiedzieæ nieco więcej o strukturze Pandemonium. Struktura Pandemonium przypomina schemat organizacyjny firmy. Na najniŋszym poziomie są pracownicy, których Selfridge nazwaģ "demonami danych". Są to procesy obliczeniowe, które "patrzą na" dane wejķciowe, powiedzmy obraz drukowanej litery lub cyfry. Kaŋdy demon szuka czegoķ konkretnego na obrazie, byæ moŋe poziomego paska; inny moŋe szukaæ pionowego paska; inny dla ģuku koģa i tak dalej. Kaŋdy demon "krzyczy" swoimi ustaleniami do zestawu demonów znajdujących się wyŋej w organizacji. (Pomyķl o tych demonach na wyŋszych szczeblach jako menedŋerach ķredniego szczebla). Gģoķnoķæ krzyku demona zaleŋy od tego, jak pewne jest to, ŋe widzi to, czego szuka. Oczywiķcie Selfridge mówi metaforycznie, kiedy uŋywa okreķleņ takich jak "szuka" i "krzyczy". Wystarczy powiedzieæ, ŋe programowanie komputerów nie jest zbyt trudne szukaj "pewnych cech na obrazie. (Selfridge juŋ pokazaģ, jak moŋna to zrobiæ w swoim artykule z 1955 r., o którym wspominaģem wczeķniej). A" krzyk "jest tak naprawdę siģą wyjķciową procesu obliczeniowego. Kaŋdy z następnych poziom demonów specjalizuje się w sģuchaniu okreķlonej kombinacji krzyku z demonów danych. Na przykģad jeden z demonów na tym poziomie moŋe zostaæ dostrojony, aby nasģuchiwaæ okrzyków danych demon 3, demon danych 11 i demon danych 22. Jeķli okaŋe się, ŋe te konkretne demony krzyczą gģoķno, odpowiada wģasnym krzykiem demonom o jeden poziom wyŋej w hierarchii i tak dalej. Tuŋ poniŋej najwyŋszego poziomu organizacji znajdują się tak zwane przez Selfridge "demony poznawcze". Podobnie jak na innych poziomach, sģuchają one okreķlonych kombinacji okrzyków demonów na niŋszym poziomie i odpowiadają wģasnymi okrzykami na ostatecznego "demona decyzyjnego" na górze - ogólnego bossa. W zaleŋnoķci od tego, co sģyszy od swojego "personelu", demon decyzji ostatecznie ogģasza, co uwaŋa za toŋsamoķæ obrazu {byæ moŋe litera "A" lub litera "R" lub cokolwiek innego. Rzeczywisty projekt demona zaleŋy od tego, jakie zadanie ma wykonaæ Pandemonium. Ale nawet bez sprecyzowania, co ma zrobiæ kaŋdy demon, Selfridge przedstawiģ bardzo interesujące propozycje dotyczące tego, jak Pandemonium moŋe nauczyæ się osiągaæ lepsze wyniki we wszystkim, co powinno robiæ. Jedna z jego propozycji dotyczyģa wyposaŋenia kaŋdego demona w coķ, co stanowiģo "megafon", przez który wydaģ swój okrzyk. Poziom gģoķnoķci megafonu moŋna regulowaæ. (Pandemonium Selfridge'a jest nieco bardziej skomplikowane niŋ wersja, którą opisuję. W jego wersji kaŋdy demon uŋywa róŋnych kanaģów do komunikowania się z kaŋdym z róŋnych demonów powyŋej. Gģoķnoķæ krzyku dochodzącego do kaŋdego kanaģu jest indywidualnie dostosowywana przez naukę mechanizm). Demonom nie wolno byģo jednak ustawiaæ wģasnego poziomu gģoķnoķci. Wszystkie poziomy gģoķnoķci miaģy zostaæ ustawione w procesie uczenia się zewnętrznego, który ma na celu poprawę wydajnoķci caģego zestawu. Wyobraž sobie, ŋe poziomy gģoķnoķci są początkowo ustawiane losowo lub wedģug tego, co wedģug projektantów będzie odpowiednie. Następnie urządzenie jest testowane na pewnej próbce danych wejķciowych i odnotowywana jest jego ocena wydajnoķci. Powiedzmy, ŋe dostaje wynik 81%. Następnie dokonuje się drobnych korekt poziomów gģoķnoķci na wszystkie moŋliwe sposoby, aŋ do znalezienia zestawu korekt, który najbardziej poprawi wynik, powiedzmy do 83%. Ten szczególny zestaw drobnych korekt jest następnie wprowadzany, a proces jest powtarzany w kóģko (byæ moŋe w przypadku dodatkowych danych), dopóki nie będzie moŋna dokonaæ dalszej poprawy. (Poniewaŋ w organizacji moŋe byæ wiele megafonów, wprowadzanie korekt na wszystkie moŋliwe sposoby i testowanie kaŋdego z tych sposobów w celu znalezienia wyniku moŋe wydawaæ się niepraktyczne. Proces moŋe rzeczywiķcie zająæ trochę czasu, ale komputery są szybkie {nawet tym bardziej dzisiaj. Póžniej pokaŋę, jak to zrobiæ ,moŋemy obliczyæ, a nie eksperymentalnie, najlepsze poprawki, które naleŋy wprowadziæ w sieciach neuronowych zorganizowanych jak Pandemonium.) Jeķli myķlimy o wyniku jako wysokoķci jakiegoķ krajobrazu i dostosowaniach jako ruchach nad krajobrazem, proces ten moŋna porównaæ do wspinaczki wzgórze, zawsze wykonując kroki w kierunku najbardziej stromego wejķcia. Gradient wspinaczka (lub metody wspinaczki, jak się je czasami nazywa) są dobrze znane w matematyce. Selfridge miaģ do powiedzenia na temat niektórych puģapek ich uŋywania:
"Moŋna to opisaæ jako jeden z problemów treningu, a mianowicie zachęcenie maszyny lub organizmu do wystarczającej iloķci stoków, aby niewielkie zmiany. . . spowoduje zauwaŋalną poprawę jego wysokoķci lub wyniku. Moŋna opisaæ sytuacje uczenia się, w których większoķæ trudnoķci w zadaniu polega na znalezieniu jakiegokolwiek sposobu poprawy swojego wyniku, na przykģad na uczeniu się jazdy na monocyklu, gdzie utrzymanie się przez sekundę trwa dģuŋej niŋ poprawa tego sekunda do minuty; i inne, w których ģatwo jest zrobiæ trochę dobrze, a bardzo dobrze, na przykģad nauczyæ się graæ w szachy. Prawdą jest równieŋ to, ŋe często gģównym szczytem jest pģaskowyŋ, a nie izolowany szczyt."
Selfridge opisaģ inną metodę uczenia się w Pandemonium. Metodę tę moŋna porównaæ do zastępowania menedŋerów w organizacji, która nie osiąga dobrych wyników. Jak to ująģ Selfridge, przy koncepcji naszego demonicznego zgromadzenia zebraliķmy nieco arbitralnie duŋą liczbę subdemonów, które naszym zdaniem byģyby przydatne. . . ale nie mamy ŋadnej pewnoķci, ŋe wybrane przez nas pod-demony są dobre. Wybór subdemonów generuje nowe subdemony do prób i eliminuje te nieefektywne, czyli takie, które niewiele pomagają poprawiæ wynik. Proces selekcji demonów rozpoczyna się po pewnym czasie dziaģania mechanizmu uczenia się dostosowującego gģoķnoķæ, bez dalszej poprawy wyników. Następnie "wartoķæ" kaŋdego demona jest oceniana przy uŋyciu, jak sugeruje Selfridge, metody opartej na wyuczonym poziomie gģoķnoķci ich krzyków. Demony o wysokim poziomie gģoķnoķci mają duŋy wpģyw na koņcowy wynik i dlatego moŋna uznaæ, ŋe mają duŋą wartoķæ. Po pierwsze, demony o niskim poziomie gģoķnoķci są caģkowicie eliminowane. (Ten krok nie moŋe bardzo zaszkodziæ wynikowi.) Następnie niektóre demony przechodzą losowo "mutacje "i są ponownie wprowadzane do uŋytku. Następnie wybrane są niektóre pary godnych demonów i, jak mówi Selfridge," sprzęŋone " w demony potomków. Precyzyjna metoda koniugacji Selfridge zaproponowana tutaj nie musi nas dotyczyæ, ale duchem tego procesu jest wytwarzanie potomstwa, które, jak moŋna się spodziewaæ, ma uŋyteczne wģaķciwoķci rodziców. Potomstwo zostaje następnie oddane do uŋytku. Teraz caģy proces dostosowywania poziomów gģoķnoķci ocalaģych i "ewoluujących" demonów moŋe rozpocząæ się od nowa, aby sprawdziæ, czy wynik nowego zestawu moŋna jeszcze poprawiæ.
Rozpoznawanie wzorców
Większoķæ uczestników letniego projektu Dartmouth byģa zainteresowana naķladowaniem wyŋszych poziomów ludzkiej myķli. Ich praca polegaģa na pewnej introspekcji dotyczącej tego, jak ludzie rozwiązują problemy. Jednak wiele naszych zdolnoķci umysģowych wykracza poza naszą zdolnoķæ introspekcji. Nie wiemy, jak rozpoznajemy džwięki mowy, czytamy kursywę, odróŋniamy filiŋankę od talerza lub identyfikujemy twarze. Robimy te rzeczy automatycznie, nie myķląc o nich. Nie mając wskazówek z introspekcji, wczeķni badacze zainteresowani automatyzacją niektórych naszych zdolnoķci percepcyjnych oparli swoją pracę na intuicyjnych pomysģach dotyczących postępowania, na sieci prostych modeli neuronów i na technikach statystycznych. Póžniej pracownicy uzyskali dodatkowe informacje z badaņ neurofizjologicznych dotyczących widzenia zwierząt. W tej częķci opiszę pracę z lat 50. i 60. XX wieku nad tzw. rozpoznawaniem wzorców. To zdanie odnosi się do procesu analizy obrazu wejķciowego, segmentu mowy, sygnaģu elektronicznego lub innej próbki danych i zaklasyfikowanie go do jednej z kilku kategorii. Na przykģad do rozpoznawania znaków kategorie odpowiadaģyby kilkudziesięciu literom alfanumerycznym. Większoķæ prac nad rozpoznawaniem wzorów w tym okresie dotyczyģa materiaģów dwuwymiarowych, takich jak drukowane strony lub zdjęcia. Moŋna byģo juŋ skanowaæ obrazy w celu przeksztaģcenia ich w tablice liczb (zwanych póžniej "pikselami"), które następnie mogģy byæ przetwarzane przez programy komputerowe, takie jak Dinneen i Selfridge. Russell Kirsch i wspóģpracownicy z National Bureau of Standards (obecnie Narodowy Instytut Standardów i Technologii) równieŋ byģ jednym z pierwszych pionierów przetwarzania obrazu. W 1957 r. Kirsch zbudowaģ skaner bębnowy i wykorzystaģ go do zeskanowania zdjęcia swojego trzymiesięcznego syna Waldena. Mówi się, ŋe jest to pierwsza zeskanowana fotografia, mierząca 176 pikseli z boku. Za pomocą swojego skanera eksperymentowaģ z programami do obróbki zdjęæ dziaģającymi na komputerze SEAC (Standards Eastern Automatic Computer).
Rozpoznawanie znaków
Wczesne starania o postrzeganie obrazów wizualnych koncentrowaģy się na rozpoznawaniu znaków alfanumerycznych na dokumentach. Pole to staģo się znane jako "optyczne rozpoznawanie znaków". Sympozjum poķwięcone informowaniu o postępach w tym temacie odbyģo się w Waszyngtonie w styczniu 1962 r. Podsumowując, w tym czasie istniaģy urządzenia umoŋliwiające doķæ dokģadne rozpoznawanie czcionek staģych (pisanych na maszynie lub drukowanych) na papierze. Byæ moŋe stan rzeczy najlepiej wyraziģ jeden z uczestników sympozjum, J. Rabinow z Rabinow Engineering, który powiedziaģ: "W naszej firmie myķlimy, ŋe moŋemy przeczytaæ wszystko, co jest drukowane, a nawet niektóre rzeczy, które są napisane. Jedynym haczykiem jest to, ile dolarów trzeba wydaæ? ". Znaczącym sukcesem w latach 50. byģ system rozpoznawania atramentu magnetycznego (MICR) opracowany przez naukowców z SRI International (zwany wówczas Stanford Research Institute) do czytania stylizowanych znaków atramentu magnetycznego na dole czeków. MICR byģ częķcią systemu SRI ERMA (Electronic Recording Method of Accounting) sģuŋącego do automatyzacji przetwarzania czeków oraz zarządzania rachunkami i zarządzania księgowaniem. Wedģug strony internetowej SRI "W kwietniu 1956 r. Bank of Ameryka ogģosiģa, ŋe General Electric Corporation zostaģa wybrana do produkcji modeli produkcyjnych ... W 1959 r. General Electric dostarczyģ pierwsze 32 systemy obliczeniowe ERMA do Bank of America. ERMA sģuŋyģ jako komputer księgowy i system obsģugi czeków do 1970 r" . Większoķæ metod rozpoznawania w tym czasie polegaģa na dopasowaniu znaku (po jego wyizolowaniu na stronie i przekonwertowaniu go na tablicę zer i jedynek) z prototypowymi wersjami znaku zwanymi "szablonami" (równieŋ przechowywanymi jako tablice na komputerze) . Jeķli znak pasuje do szablonu dla "A", powiedzmy, wystarczająco lepiej niŋ inne szablony, dane wejķciowe zostaģy zadeklarowane jako "A." Dokģadnoķæ rozpoznania ulegģa pogorszeniu, jeķli znaki wejķciowe nie byģy prezentowane w standardowej orientacji, nie byģy tej samej czcionki co szablon lub miaģy niedoskonaģoķci. Artykuģy z 1955 r autorstwa Selfridge i Dinneen zaproponowaģy kilka pomysģów na wyjķcie poza dopasowywanie szablonów. Praca Olivera Selfridge'a i Ulricha Neissera z 1960 r. posunęģa tę pracę dalej. Ten artykuģ jest waŋny, poniewaŋ byģ udaną, wczesną próbą uŋycia przetwarzania obrazu, ekstrakcji funkcji i wyuczonych wartoķci prawdopodobieņstwa w rozpoznawaniu znaków odręcznie wydrukowanych. Znaki zostaģy zeskanowane i przedstawione na "siatkówce" 32 x 32 lub tablicy zer i jedynek. Zostaģy one następnie przetworzone przez róŋne operacje odnawiania (podobne do tych, o których wspominaģem w związku z artykuģem Dinneena z 1955 r.) W celu usunięcia przypadkowych kawaģków szumu, luk, linii pogrubienia i wzmocnienia krawędzi. "Oczyszczone" obrazy zostaģy następnie sprawdzone pod kątem występowania "cech" (podobnych do cech, o których wspomniaģem w związku z artykuģem Selfridgea z 1955 r.). W sumie uŋyto 28 funkcji -takich jak maksymalna liczba przypadków linia pozioma przecinaģa obraz, względne dģugoķci róŋnych krawędzi i czy obraz miaģ "wklęsģoķæ skierowaną na poģudnie". Przywoģując system Pandemonium Selfridge′a, moŋemy myķleæ o procesie wykrywania cech jako wykonywanym przez "demony". Na wyŋszym poziomie hierarchii niŋ demony cechowe byģy "demony rozpoznające" - po jednym na kaŋdą literę. (Wersja tego systemu przetestowana przez Worthie Doyle z Lincoln Laboratory zostaģa zaprojektowana do rozpoznawania dziesięciu róŋnych ręcznie drukowanych znaków, a mianowicie: A, E, I, L, M, N, O, R, S i T.) Kaŋde rozpoznanie demon otrzymaģ jako dane wejķciowe od kaŋdego z demonów wykrywających cechy. Ale po pierwsze, dane wejķciowe do kaŋdego demona rozpoznającego zostaģy pomnoŋone przez wagę, która uwzględniaģa znaczenie wkģadu odpowiedniej cechy w podejmowaniu decyzji. Na przykģad, jeķli cecha 17 byģa waŋniejsza niŋ cecha 22 przy podejmowaniu decyzji, ŋe znakiem wejķciowym jest "A", wówczas dane wejķciowe do rozpoznającego "A" z cechy 17 byģyby waŋone bardziej niŋ dane wejķciowe z cechy. Po tym, jak kaŋdy demon rozpoznania zsumowaģ sumę swoich waŋonych danych wejķciowych, ostateczny "demon decyzyjny" zdecydowaģ na korzyķæ tego, ŋe postaæ ma największą sumę. Wartoķci wag zostaģy okreķlone w procesie uczenia się, podczas którego analizowano 330 obrazów "treningowych". Zliczenia zestawiono w tabelach, ile razy wykryto kaŋdą cechę dla kaŋdej innej litery w zestawie szkoleniowym. Te dane statystyczne wykorzystano do oszacowania prawdopodobieņstwa wykrycia danej cechy dla kaŋdej litery. Te oszacowania prawdopodobieņstwa wykorzystano następnie do waŋenia cech sumowanych przez rozpoznające demony. Po szkoleniu system zostaģ przetestowany na próbkach ręcznie drukowanych znaków, których jeszcze nie widziaģ. Wedģug Selfridge′a i Neissera: "Ten program sprawia, ŋe tylko okoģo 10 procent mniej jest poprawnych identyfikacji, niŋ czytelnicy ludzcy robią {na pewno przyzwoitą wydajnoķæ."
Sieci neuronowe
Perceptrony
W 1957 r. Frank Rosenblatt (1928-1969, psycholog z Cornell Aeronautical Laboratory w Buffalo w stanie Nowy Jork) rozpocząģ pracę nad sieciami neuronowymi w ramach projektu o nazwie PARA (Perceiving and Recognizing Automaton). Motywowaģ go wczeķniejsza praca McCullocha. Pitts i Hebb zainteresowali się tymi sieciami, które nazwaģ perceptronami, jako potencjalnymi modelami ludzkiego uczenia się, poznania i pamięci. Kontynuując na początku lat 60. jako profesor na Cornell University w Ithaca w Nowym Jorku, eksperymentowaģ z wieloma róŋnych rodzajów perceptronów. Jego praca, bardziej niŋ Clarka i Farleya oraz innych pionierów sieci neuronowych, byģa odpowiedzialna za zainicjowanie jednej z gģównych alternatyw dla metod przetwarzania symboli w AI, a mianowicie sieci neuronowych. Perceptrony Rosenblatta skģadaģy się z McCulloch {Elementy neuronowe w stylu Pittsa, takie jak ten pokazany poniŋej 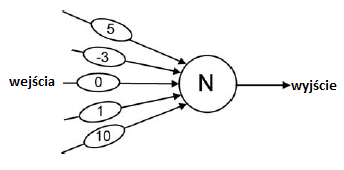
Kaŋdy element miaģ dane wejķciowe (przychodzące od lewej strony w górę), \ wagi "(pokazane przez wybrzuszenia na liniach wejķciowych) i jedno wyjķcie (wychodzące w prawo). Dane wejķciowe miaģy wartoķci 1 lub 0, i kaŋde wejķcie zostaģo pomnoŋone przez związaną z nim wartoķæ wagi. Element neuronowy obliczyģ sumę tych waŋonych wartoķci. Na przykģad, jeķli wszystkie dane wejķciowe do elementu neuronowego na rysunku byģy równe 1, suma wynosiģaby 13. Gdyby suma byģa większa niŋ (lub po prostu równa) "wartoķæ progowa", powiedzmy 7, powiązana z elementem, wówczas dane wyjķciowe elementem neuronowym będzie 1, co byģoby w tym przykģadzie. W przeciwnym razie wynik wyniósģby 0. Perceptron skģada się z sieci tych elementów neuronowych, w których wyjķcia jednego elementu są danymi wejķciowymi dla innych. (Jest tu analogia do Pandemonium Selfridge'a, w którym demony ķredniego poziomu otrzymują "krzyki" demony niŋszego poziomu. Cięŋary na liniach wejķciowych elementu neuronowego moŋna traktowaæ jako analogiczne do "kontroli siģy" zwiększającej lub zmniejszającej siģę w Pandemonium.) Przykģadowy perceptron pokazano poniŋej.
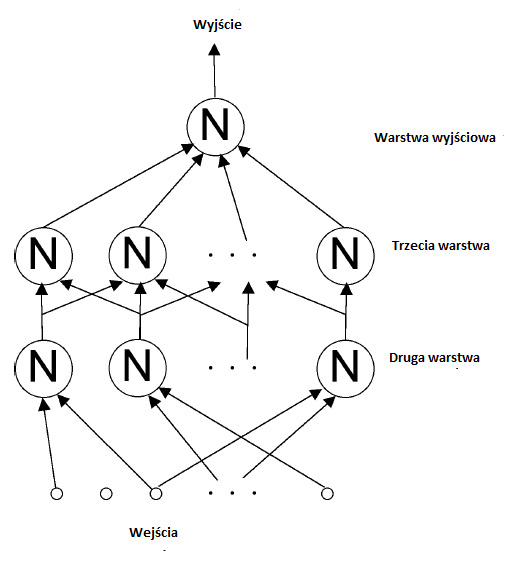
[Rosenblatt narysowaģ schematy perceptronów w formacie poziomym (styl elektrotechniczny), z wejķciami po lewej i wyjķciami po prawej. Tutaj uŋywam stylu pionowego ogólnie preferowanego przez informatyków do hierarchii, z najniŋszym poziomem u doģu i najwyŋszym u góry. Aby uproķciæ schemat, wybrzuszenia wagi nie są pokazane.] Chociaŋ przedstawiony perceptron, z tylko jedną jednostką wyjķciową, jest zdolny tylko do dwóch róŋnych wyjķæ (1 lub 0), wiele wyjķæ (zestawy 1 i 0) moŋna uzyskaæ przez uģoŋenie dla kilku jednostek wyjķciowych.
Warstwa wejķciowa, pokazana na dole rysunku, byģa zazwyczaj prostokątnym ukģadem 1 i 0 odpowiadających komórkom zwanym "pikselami" czarno-biaģego obrazu. Jedną z aplikacji, którymi interesowaģa się Rosenblatt, byģo, podobnie jak Selfridge, rozpoznawanie znaków. Uŋyję prostej algebry i geometrii, aby pokazaæ, jak elementy neuronowe w sieciach perceptronowych moŋna "szkoliæ" w celu uzyskania poŋądanych wyników. Rozwaŋmy na przykģad pojedynczy element neuronowy, którego danymi wejķciowymi są wartoķci x1, x2 i x3 i których powiązanymi wartoķciami wagowymi są w1, w2 i w3. Gdy suma obliczona przez ten element jest dokģadnie równa jego wartoķci progowej, powiedzmy t, mamy równanie w1x1 + w2x2 + w3x3 = t:
W algebrze takie równanie nazywa się równaniem "liniowym. "Okreķla granicę liniową, czyli pģaszczyznę, w przestrzeni trójwymiarowej. Pģaszczyzna oddziela te wartoķci wejķciowe, które spowodowaģyby, ŋe element neuronowy miaģby wynik 1 z tych, które spowodowaģyby, ŋe miaģby wynik 0. Pokazuję typową pģaską granicę na rysunku
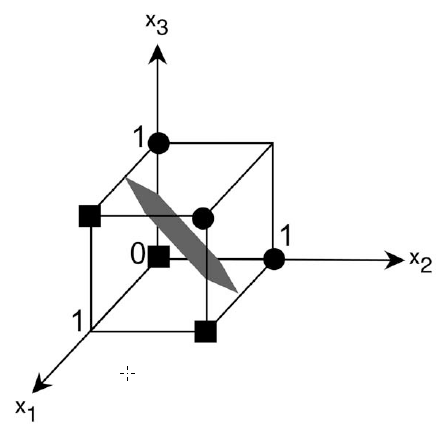
Wejķcie do elementu neuronowego moŋe byæ przedstawione jako punkt (to znaczy wektor) w tej trójwymiarowej przestrzeni. Jego wspóģrzędne to wartoķci x 1 , x 2 i x 3 , z których kaŋda moŋe wynosiæ 1 lub 0. Gure pokazuje szeķæ takich punktów, trzy z nich (powiedzmy maģe kóģka) powodujące, ŋe element ma moc wyjķciową 1, a trzy (powiedzmy maģe kwadraty) powodujące, ŋe ma moc wyjķciową 0. Zmiana wartoķci progu powoduje, ŋe pģaszczyzna poruszaæ się na boki w kierunku równolegģym do siebie. Zmiana wartoķci cięŋarów powoduje obrót pģaszczyzny. Tak więc, zmieniając wartoķci cięŋaru, punkty, które kiedyķ znajdowaģy się po jednej stronie pģaszczyzny, mogģy skoņczyæ się po drugiej stronie. "Szkolenie" odbywa się poprzez wykonanie takich zmian. Będę miaģ więcej do powiedzenia na temat procedur szkoleniowych. W wymiarach większych niŋ trzy (co zwykle ma miejsce), liniowa granica nazywana jest "hiperpģaszczyzną". Chociaŋ nie jest moŋliwe zwizualizowanie tego, co dzieje się w przestrzeniach o duŋych wymiarach, matematycy wciąŋ mówią o punktach wejķciowych w tych przestrzeniach oraz obrotach i ruchach hiperpģaszczyzn w odpowiedzi na zmiany wartoķci wag i progów. Rosenblatt zdefiniowaģ kilka rodzajów perceptronów. Nazwaģ ten pokazany na schemacie "czteropowģokowym perceptronem sprzęŋonym szeregowo". (Rosenblatt liczyģ dane wejķciowe jako pierwszą warstwę.) Nazywano to "sprzęŋeniem szeregowym", poniewaŋ moc wyjķciowa kaŋdego elementu neuronowego przekazywana byģa do elementów neuronowych w kolejnej warstwie. W najnowszej terminologii zamiast wyraŋenia "sprzęŋony szeregowo" uŋyto wyraŋenia "informacje zwrotne". Natomiast perceptron "sprzęŋony krzyŋowo" moŋe mieæ wyjķcia elementów neuronowych w jednej warstwie jako dane wejķciowe do elementów neuronalnych w tej samej warstwie. Perceptron sprzęŋony "krzyŋowo" moŋe mieæ dane wyjķciowe elementów neuronowych w jednej warstwie elementy neuronowe w warstwach o niŋszych numerach. Rosenblatt pomyķlaģ o swoich perceptronach jako o modelach okablowania częķci mózgu. Z tego powodu nazwaģ elementy neuronowe we wszystkich warstwach, ale w warstwie wyjķciowej, "jednostkami asocjacji" (A-units), poniewaŋ zamierzaģ je modelowaæ asocjacje wykonywane przez sieci neuronów w mózgu. Szczególnie interesujące byģy badania Rosenblatta to, co nazwaģ "perceptronem alfa". Skģadaģo się z trójwarstwowej sieci sprzęŋenia zwrotnego z warstwą wejķciową, warstwą asocjacyjną i jedną lub więcej jednostkami wyjķciowymi. W większoķci jego eksperymentów dane wejķciowe miaģy wartoķci 0 lub 1, odpowiadające czarnym lub biaģym pikselom na obrazie wizualnym przedstawionym na tak zwanej "siatkówce". Kaŋda jednostka A otrzymaģa dane wejķciowe (które nie zostaģy pomnoŋone przez wartoķci masy) z jakiegoķ losowo wybranego podzbioru pikseli i wysģaģa swój wynik , poprzez zestawy regulowanych wag, do koņcowych jednostek wyjķciowych, których wartoķci binarne moŋna interpretowaæ jako kod dla kategorii obrazu wejķciowego. Próbowano zastosowaæ róŋne "procedury szkoleniowe" w celu dostosowania wag jednostek wyjķciowych perceptronu alfa , W najbardziej dla tych (dla celów rozpoznawania wzorców) wagi prowadzące do jednostek wyjķciowych wynosiģy korygowane tylko wtedy, gdy jednostki te popeģniģy bģąd w klasyfikacji danych wejķciowych. Korekty byģy takie, aby wymusiæ na wyjķciu prawidģową klasyfikację dla tego konkretnego wejķcia. Ta technika, która wkrótce staģa się standardem, zostaģa nazwana "procedurą korekcji bģędów". Rosenblatt z powodzeniem wykorzystaģ ją w szeregu eksperymentów do szkolenia perceptronów do klasyfikowania sygnaģów wizualnych, takich jak znaki alfanumeryczne lub sygnaģów akustycznych, takich jak džwięki mowy. Profesor H. David Block, matematyk Cornell wspóģpracujący z Rosenblattem, byģ w stanie udowodniæ, ŋe procedura korekcji bģędów gwarantuje znalezienie hiperpģaszczyzny, która doskonale oddzieli zestaw danych treningowych, gdy taka hiperpģaszczyzna istniaģa. wykonane za pomocą symulacji komputerowych, Rosenblatt wolaģ budowaæ wersje sprzętowe swoich perceptronów (symulacje byģy wczesne na wczesnych komputerach, co wyjaķniaģo zainteresowanie budowaniem specjalnego sprzętu perceptronowego). MARK I byģ alfa-perceptronem zbudowanym w Cornell Aeronautical Laboratory pod sponsorowanie Oddziaģu Systemów Informatycznych Offce of Naval Research i Rome Air Development Center. Zostaģo to publicznie zademonstrowane 23 czerwca 1960 r. MARK I uŋywaģ regulatorów gģoķnoķci (zwanych przez inŋynierów elektryków "potencjometrami") do waŋenia. Mają one przymocowane do nich maģe silniki w celu wykonania regulacji w celu zwiększenia lub zmniejszenia wartoķci masy.
W 1959 roku Frank Rosenblatt przeniósģ swoją pracę perceptronową z Cornell Aeronautical Laboratory w Buffalo w stanie Nowy Jork na Cornell University, gdzie zostaģ profesorem psychologii. Wraz z Blockiem i kilkoma studentami Rosenblatt kontynuowaģ eksperymentalne i teoretyczne prace nad perceptronami. Jego ksiąŋka Principles of Neurodynamics szczegóģowo opisuje jego teoretyczne pomysģy i wyniki eksperymentów. Ostatni system Rosenblatta, zwany Tobermory, zostaģ zbudowany jako urządzenie do rozpoznawania mowy. [Tobermory to imię kota, który nauczyģ się mówiæ w The Chronicles of Clovis, grupie opowiadaņ Saki (H. H. Munro).] Kilka doktorantów studenci, w tym George Nagy, Carl Kessler, R. D. Joseph i inni, ukoņczyli projekty perceptronowe pod Rosenblattem w Cornell. W ostatnich latach pobytu w Cornell Rosenblatt zająģ się badaniem transferu pamięci chemicznej u robaków i innych zwierząt {temat caģkowicie usunięty z pracy nad perceptronem. Niestety, Rosenblatt zginąģ w wypadku podczas ŋeglugi w zatoce Chesapeake w 1969 roku. Mniej więcej w tym samym czasie co alfa-perceptron Rosenblatta, Woodrow W. (Woody) Bledsoe (1921 {1995) i Iben Browning (1918-1991), dwaj matematycy z Sandia Laboratories w Albuquerque w Nowym Meksyku, równieŋ prowadzili badania nad rozpoznawaniem znaków, które wykorzystywaģy losowe próbki obrazów wejķciowych. Eksperymentowali z systemem, który wyķwietlaģ obrazy znaków alfanumerycznych na mozaice 10 x 15 fotokomórek i próbkowaģ stany 75 losowo wybranych par fotokomórek. Wskazując, ŋe pomysģ moŋna rozszerzyæ na próbkowanie większych grup pikseli, powiedzmy N z nich, nazwali swoją metodę metodą "N-krotki". Wykorzystali wyniki tego próbkowania do podjęcia decyzji o kategorii litery wejķciowej
ADALINESY I MADALINES
Niezaleŋnie od Rosenblatt, grupa kierowana przez profesora inŋynierii elektrycznej Stanforda Bernarda Widrowa równieŋ pracowaģa nad systemy sieci neuronowych na przeģomie lat 50. i 60. XX wieku. Widrow niedawno doģączyģ do Stanford po ukoņczeniu doktoratu z teorii sterowania na MIT. Chciaģ wykorzystaæ systemy sieci neuronowej do czegoķ, co nazwaģ "kontrolą adaptacyjną". Jedno z urządzeņ zbudowanych przez Widrow nazwano "ADALINE "(dla adaptacyjnej sieci liniowej). Byģ to pojedynczy element neuronowy, którego regulowane cięŋary byģy realizowane przez przeģączalne (w ten sposób regulowane) obwody rezystorów. Widow i jeden z jego uczniów, Marcian E. "Ted" Hoff Jr. (który póžniej wynalazģ pierwszy mikroprocesor w firmie Intel), opracowali regulowaną wagę, którą nazywali "a" "memistor". Skģadaģ się z grafitowego pręta, na którym warstwa miedzi mogģa byæ powlekana i nieplaterowana - zmieniając w ten sposób jej opór elektryczny. Widrow i Hoff opracowali procedurę szkolenia dla ich elementu neuronowego ADALINE, który nazwano algorytmem adaptacyjnym najmniejszych ķrednich kwadratów Widrowa-Hoffa. Większoķæ eksperymentalnych prac Widrowa zostaģa wykonana przy uŋyciu symulacji na komputerze IBM1620. Ich najbardziej skomplikowany projekt sieci nazwano "MADALINE" (dla wielu ADALINE). Procedurę szkoleniową opracowaģ dla niego w Stanford student William Ridgway.
Systemy MINOS w SRI
Sukces Rosenblatta z perceptronami w problemach z rozpoznawaniem wzorców doprowadziģ do wzmoŋenia wysiģków badawczych innych osób w celu powielenia i rozszerzenia jego wyników. W latach szeķædziesiątych byæ moŋe najbardziej znaczące prace w zakresie rozpoznawania wzorców z wykorzystaniem sieci neuronowych zostaģy wykonane w Stanford Research Institute w Menlo Park w Kalifornii. Tam Charles A. Rosen (1917-2002) kierowaģ laboratorium, które próbowaģo wytrawiæ mikroskopijne lampy próŋniowe na podģoŋu póģprzewodnikowym. Rosen spekulowaģ, ŋe obwody zawierające te lampy mogą byæ ostatecznie "podģączone" do wykonywania przydatnych zadaņ przy uŋyciu niektórych procedur szkoleniowych opisanych przez Franka Rosenblatta. SRI zatrudniģo Rosenblatta jako konsultanta do pomocy w projektowaniu eksploracyjnej sieci neuronowej. Kiedy w 1960 roku przeprowadziģem wywiad na stanowisko w SRI, zespóģ w laboratorium Rosen pod kierownictwem Alfreda E. (Teda) Brain (1923-2004) wģaķnie zakoņczyģ budowę maģej sieci neuronowej o nazwie MINOS. (W mitologii greckiej Minos byģ królem Krety i synem Zeusa i Europy. Po ķmierci Minos byģ jednym z trzech sędziów w podziemiu). Brain uwaŋaģ, ŋe symulacje komputerowe sieci neuronowych są zbyt wolne do praktycznych zastosowaņ, co prowadzi do decyzji o budowie zamiast programowania. (Komputer IBM 1620 uŋywany w tym samym czasie przez grupę Widrowa w Stanford do symulacji sieci neuronowych miaģ podstawowy cykl maszynowy wynoszący 21 mikrosekund i maksymalnie 60 000 "cyfr "pamięci o swobodnym dostępie.) W celu regulacji cięŋarów MINOS zastosowaģ magnetyczny urządzenia zaprojektowane przez Brain. Rosenblatt pozostawaģ w bliskim kontakcie z SRI, poniewaŋ byģ zainteresowany wykorzystaniem tych urządzeņ magnetycznych jako zamienników swoich potencjometrów napędzanych silnikiem. Entuzjazm i optymizm Rosen odnoķnie potencjaģu sieci neuronowych pomógģ mu doģączyæ do SRI. Po moim przybyciu w lipcu 1961 r. dostaģ szkic ksiąŋki Rosenblatta do przeczytania. Zespóģ Brain dopiero zaczynaģ prace nad budową duŋej sieci neuronowej, zwanej MINOS II, kontynuacją mniejszego systemu MINOS. wspierany przede wszystkim przez Korpus Sygnaģowy Armii USA w latach 1958-1967. Celem pracy MINOS byģo "przeprowadzenie badaņ naukowych i eksperymentalnych badaņ technik i sprzętu cechy odpowiednie do praktycznego zastosowania w graficznym przetwarzaniu danych dla potrzeb wojskowych. "Gģównym celem projektu byģo automatyczne rozpoznawanie symboli na mapach wojskowych. Podjęto równieŋ próby innych zastosowaņ - takich jak rozpoznawanie pojazdów wojskowych, takich jak czoģgi, na zdjęciach lotniczych i rozpoznawanie ręcznie drukowanych znaków - w pierwszym etapie przetwarzania przez MINOS II obraz wejķciowy byģ replikowany 100 razy za pomocą matrycy plastikowej 10 x 10. Kaŋdy z tych identycznych obrazów zostaģ następnie przesģany przez wģasną optyczną maskę wykrywającą cechy, a ķwiatģo przez maskę zostaģo wykryte przez fotokomórkę i porównane z progiem. Rezultatem byģ zestaw 100 wartoķci binarnych (wyģączone - wģączone). Wartoķci te stanowiģy dane wejķciowe do zestawu 63 elementów neuronowych ("jednostek A" w terminologii Rosenblatta), kaŋdy o 100 zmiennych wagach magnetycznych. 63 wyjķcia binarne z tych elementów neuronowych zostaģy następnie przetģumaczone na jedną z 64 decyzji dotyczących kategorii oryginalnego obrazu wejķciowego. (Zbudowaliķmy 64 równie odlegģe "punkty" w szeķædziesięciu trójwymiarowych przestrzeniach i przeszkoliliķmy sieæ neuronowa, dzięki czemu kaŋdy obraz wejķciowy tworzy punkt bliŋszy wģasnemu punktowi prototypu niŋ innemu. Kaŋdy z tych prototypowych punktów byģ jedną z 64 "sekwencji rejestru przesuwnego o maksymalnej dģugoķci" o 63 wymiarach).
W latach 60. grupa sieci neuronowych SRI, zwana wówczas
Grupa Learning Machines badaģa wiele róŋnych organizacji sieciowych i procedur szkoleniowych. Poniewaŋ komputery staģy się zarówno bardziej dostępne, jak i potęŋniejsze, coraz częķciej korzystaliķmy z symulacji (w róŋnych centrach komputerowych) na komputerach Burroughs 220 i 5000 oraz na IBM 709 i 7090. W poģowie lat 60. otrzymaliķmy wģasny edytowany komputer, SDS 910 (SDS 910, opracowany w Scienti c Data Systems, byģ pierwszym komputerem, w którym zastosowano tranzystory krzemowe). Uŋyliķmy tego komputera w poģączeniu z najnowszą wersją naszego sprzętu sieci neuronowej (teraz z wykorzystaniem zestawu 1024 soczewek wstępnego przetwarzania), poģączenie nazwaliķmy MINOS III. Jednym z najbardziej udanych rezultatów w systemie MINOS III byģo automatyczne rozpoznawanie ręcznie drukowanych znaków na arkuszach kodujących FORTRAN. (W latach 60. programy komputerowe byģy zwykle pisane ręcznie, a następnie konwertowane na karty dziurkowane przez operatorów uderzeņ kluczowych). Pracami tymi kierowali John Munson
(19391972), Peter Hart i Richard Duda. Neuronowa częķæ MINOS III zostaģa wykorzystana do stworzenia rankingu moŋliwych klasyfikacji dla kaŋdej postaci z miarą siģy dla kaŋdej postaci. Na przykģad, pierwszy znak napotkany w ciągu znaków moŋe zostaæ rozpoznany przez sieæ neuronową jako D o sile 90 i jako O o sile 10. Ale akceptując najbardziej pewną decyzję dla kaŋdego znaku nie moŋe powstaæ ciąg znaków, który jest prawnym oķwiadczeniem w języku FORTRAN {wskazując, ŋe co najmniej jedna decyzja byģa bģędna (przy zaģoŋeniu, ŋe ktokolwiek napisaģ oķwiadczenie na arkuszu kodowym napisaģ oķwiadczenie prawne). Zaakceptowanie drugiego lub trzeciego najbardziej bezpiecznego wyboru dla niektórych znaków moŋe byæ wymagane do utworzenia prawidģowego ciągu znaków. Caģkowitą stęSenie peģnego ciągu znaków obliczono, dodając stany poszczególnych znaków w ciągu. Następnie potrzebny byģ sposób uszeregowania tych liczb liczb caģkowitych dla kaŋdego z moŋliwych ciągów wynikających ze wszystkich róŋnych wyborów dla kaŋdego
znaku. Spoķród tego rankingu wszystkich moŋliwych ciągów system następnie wybraģ najbardziej pewny ciąg prawny. Jednak, jak napisaģ Richard Duda, Problem znalezienia pierwszego, drugiego, trzeciego
najbardziej zģoŋonego ciągu znaków nie jest wcale trywialnym problemem. Kluczem do skutecznego obliczenia rankingu byģo zastosowanie metody zwanej programowaniem dynamicznym. Ilustracja próbki oryginalnego žródģa i ostatecznego wyjķcia pokazano poniŋej.

Po przeszkoleniu częķci sieci neuronowej systemu, caģy system (który zdecydowaģ się na najbardziej pewny ciąg prawny) byģ w stanie osiągnąæ dokģadnoķæ rozpoznawania wynoszącą nieco ponad 98% na duŋej próbce materiaģu, który nie byģ częķcią tego, na co szkolono system. Rozpoznawanie odręcznych postaci z takim poziomem dokģadnoķci byģo znaczącym osiągnięciem w latach szeķædziesiątych. Rozszerzając swoje zainteresowania poza sieci neuronowe, Learning Machines Group ostatecznie przeksztaģciģo się w Centrum Sztucznej Inteligencji SRI, które do dziķ jest wiodącym przedsiębiorstwem badawczym zajmującym się AI.
Metody statystyczne
W latach pięædziesiątych i szeķædziesiątych istniaģo kilka zastosowaņ metod statystycznych do problemów z rozpoznawaniem wzorców. Wiele z tych metod byģo bardzo podobnych do niektórych technik sieci neuronowych. Przypomnij sobie, ŋe wczeķniej wyjaķniģem, jak zdecydowaæ, który z dwóch tonów będzie obecny w gģoķnym sygnale radiowym. Podobną technikę moŋna zastosowaæ do rozpoznawania wzorów. Do klasyfikowania obrazów (lub innych danych percepcyjnych) zwykle reprezentowano dane wejķciowe za pomocą listy wyróŋniających "cech", takich jak te uŋywane przez Selfridge'′a i jego wspóģpracowników. Na przykģad w rozpoznawaniu znaków alfanumerycznych jedną z pierwszych cech wyodrębniono z obrazu znaku, który ma zostaæ sklasyfikowany. Zazwyczaj cechy miaģy wartoķci liczbowe, takie jak liczba razy, gdy linie o róŋnych kątach przecinaģy znak lub dģugoķæ obwodu najmniejszego koģa, które caģkowicie otaczaģo znak. Wybór odpowiednich funkcji byģ często bardziej sztuką niŋ nauką, ale miaģ kluczowe znaczenie dla dobrej wydajnoķci. Potrzebujemy trochę elementarnej notacji matematycznej, aby pomóc opisaæ te statystycznie zorientowane metody rozpoznawania wzorców. Zaģóŋmy, ŋe lista funkcji wyodrębnionych ze znaku to {f1; f2; … ; fi;… :; fN}. Skrócę tę listę za pomocą pogrubionego symbolu X. Zaģóŋmy, ŋe istnieje k kategorii, C1; C2;… ; Ci; … ; Ck, do którego moŋe naleŋeæ znak opisany przez XUŋywając reguģy Bayesa w sposób podobny do opisanego wczeķniej, reguģa decyzyjna jest następująca:
Zdecyduj na korzyķæ tej kategorii, dla której p(X |Ci)p(Ci) jest największe, gdzie p(Ci jest prawdopodobieņstwem a priori kategorii Ci i p(p(Cii) to prawdopodobieņstwo X dla Ci. Prawdopodobieņstwa te moŋna wywnioskowaæ, zbierając dane statystyczne z duŋej próbki znaków.
Jak wspomniaģem wczeķniej, badacze w rozpoznawaniu wzorów często opisują proces decyzyjny w kategoriach geometrii. Wyobraŋają sobie, ŋe wartoķci cech uzyskanych z próbki obrazu moŋna przedstawiæ jako punkt w przestrzeni wielowymiarowej. Jeķli mamy kilka próbek dla kaŋdej powiedzmy dwóch znanych kategorii danych, moŋemy reprezentowaæ te próbki jako rozproszenie punktów w przestrzeni. W rozpoznawaniu znaków rozproszenie moŋe wystąpiæ nie tylko dlatego, ŋe obraz postaci moŋe byæ haģaķliwy, ale takŋe dlatego, ŋe postacie z tej samej kategorii mogą byæ rysowane nieco inaczej. Pokazuję dwuwymiarowy przykģad z funkcjami f1 i f2 na rysunku.
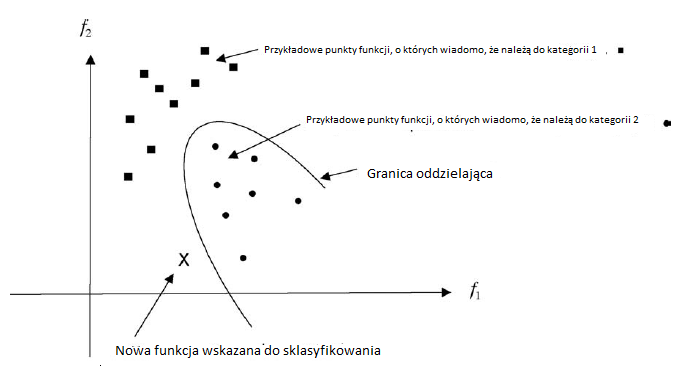
Na podstawie rozproszenia punktów w kaŋdej kategorii moŋemy obliczyæ oszacowanie prawdopodobieņstw potrzebnych do obliczenia prawdopodobieņstw. Następnie moŋemy wykorzystaæ prawdopodobieņstwa i wczeķniejsze prawdopodobieņstwa do podjęcia decyzji. Pokazuję tutaj granicę, obliczoną na podstawie prawdopodobieņstw i wczeķniejszych prawdopodobieņstw, która dzieli przestrzeņ na dwa regiony. W jednym regionie decydujemy się na kategorię 1; z drugiej wybieramy kategorię 2. Pokazuję takŋe nowy punkt funkcji, X, który ma zostaæ sklasyfikowany. W tym przypadku pozycja X względem granicy narzuca, ŋe klasyfikujemy X jako czģonka kategorii 1. Istnieją równieŋ inne metody klasyfikacji punktów charakterystycznych. Ciekawym przykģadem jest metoda \ najbliŋszego sąsiada. W tym schemacie, wynalezionym przez E. Fixa i JL Hodgesa w 1951,nowy punkt cechy jest przypisany do tej samej kategorii, co ten przykģadowy punkt cechy, do którego jest najbliŋej. na powyŋszym rysunku nowy punkt X zostaģby sklasyfikowany jako naleŋący do kategorii 2. przy uŋyciu metody najbliŋszego sąsiada.
Waŋne opracowanie metody najbliŋszego sąsiada przypisuje nowy punkt do tej samej kategorii co większoķæ k najbliŋszych punktów. reguģa decyzyjna wydaje się prawdopodobna (w przypadku, gdy istnieje wiele, wiele punktów próbnych kaŋdej kategorii), poniewaŋ istnieje więcej punktów próbnych kategorii Ci bliŋej nieznanego punktu, X, niŋ punkty próbne kategorii Cj jest dowodem, ŋe p(X | Ci) p (Ci) jest większy niŋ p(X | Cj)) p (Cj) W oparciu o tę ogólną obserwację Thomas Cover i Peter Hart rygorystycznie przeanalizowali skutecznoķæ metod najbliŋszego sąsiedztwa. Kaŋda technika rozpoznawania wzorców, nawet wykorzystująca sieci neuronowe lub najbliŋszych sąsiadów, moŋe byæ uwaŋana za konstruowanie granic oddzielających w wielowymiarowej przestrzeni cech. Inną metodę konstruowania granic przy uŋyciu "funkcji potencjalnych" zasugerowali rosyjscy naukowcy M. A. Aizerman, E. M. Braverman i L. I. Rozonoer w latach 60. Niektóre waŋne wczesne ksiąŋki na temat stosowania metod statystycznych w rozpoznawaniu wzorców to George Sebestyen, Richard Duda i Peter Hart. Technologia rozpoznawania wzorów pod koniec lat 60. XX wieku zostaģa dobrze oceniona przez George'a Nagy'a (który wczeķniej byģ jednym z doktorantów Franka Rosenblatta).
Zastosowania rozpoznawania wzorów w rozpoznaniu lotniczym
Sieæ neuronowa i metody statystyczne rozpoznawania wzorców przyciągnęģy wiele uwagi w wielu firmach z branŋy lotniczej i lotniczej na przeģomie lat 50. i 60. XX wieku. Firmy te miaģy duŋy budŋet na badania i rozwój wynikające z umów z Departamentem Obrony USA. Wiele z nich byģo szczególnie zainteresowanych problemem zwiadu powietrznego, tj. lokalizacją i identyfikacją "celów" na zdjęciach lotniczych. Wķród firm prowadzących szeroko zakrojone programy badawcze poķwięcone temu zagadnieniu i powiązanych z nimi problemami byģ Dziaģ Aeronutronic Ford Motor Co., Douglas Aircraft Company (jak wtedy byģo znane), General Dynamics, Lockheed Missiles and Space Division oraz Philco Corporation (Philco zostaģ póžniej przejęty przez Forda pod koniec 1961 r.) Wspomnę o niektórych pracach w Philco , Laveen N. Kanal, Neil C. Randall i Thomas Harley pracowali zarówno nad teorią, jak i metodami statystycznego rozpoznawania wzorców. Opracowane przez nich systemy sģuŋyģy do przeglądania zdjęæ lotniczych pod kątem interesujących celów wojskowych, takich jak czoģgi. ilustracja jednego z ich systemów pokazano na rysunku
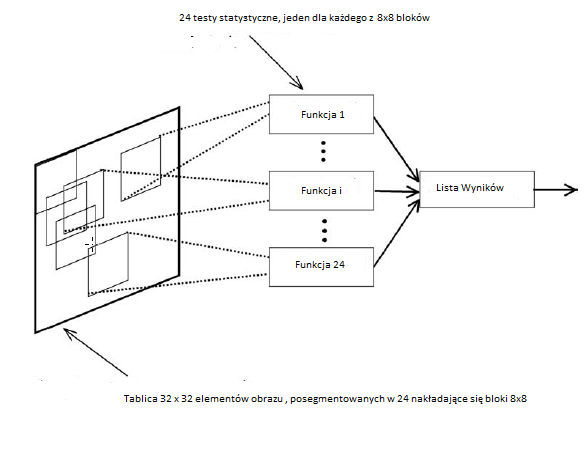
Aparat Philco zeskanowaģ materiaģ z 9-calowych negatywów zebranych przez samolot rozpoznawczy U2 podczas manewrów czoģgów armii amerykaņskiej w Fort Drum w Nowym Jorku. Niewielka częķæ zeskanowanego zdjęcia, prawdopodobnie zawierająca czoģg M-48 (w standardowej pozycji i rozmiarze), zostaģa najpierw przetworzona w celu wzmocnienia krawędzi, a wynik zostaģ przedstawiony systemowi wykrywania celu jako ukģad zer i jedynek. Pierwszy z ich systemów uŋywaģ tablicy 22 x 12; póžniej uŋywali tablicy 32 x 32, jak pokazano na powyŋszym rysunku. Tablica zostaģa następnie podzielona na 24 nakģadające się 8 x 8 "bloków cech". Dane w kaŋdym bloku obiektów są następnie poddawane testowi statystycznemu, aby zdecydowaæ, czy maģy obszar obrazu reprezentowany przez ten blok zawiera częķæ zbiornika. Testy statystyczne oparto na "próbce szkoleniowej" 50 obrazów zawierających zbiorniki i 50 próbek terenu niezawierającego zbiorników. Dla kaŋdego bloku cech 8 x 8 opracowano parametry statystyczne z tych próbek w celu ustalenia (liniowej) granicy w szeķædziesięciu - czterowymiarowa przestrzeņ, która najlepiej rozróŋnia próbki zbiorników od próbek nieczoģgowych. Korzystając z tych granic, system zostaģ następnie przetestowany na innym zestawie 50 obrazów zawierających zbiorniki i 50 obrazów niezawierających zbiorników. Dla kaŋdego obrazu testowego liczba cech bloki decydujące o "obecnoķci czoģgu" zostaģy obliczone, aby uzyskaæ koņcowy "wynik" liczbowy (np. 21 z 24 bloków zdecydowaģo, ŋe czoģg byģ obecny). Wynik ten moŋe byæ następnie wykorzystany do podjęcia decyzji, czy obraz zawiera czoģg. Autorzy stwierdzili, ŋe "wyniki eksperymentalne procedury klasyfikacji statystycznej przekroczyģy wszelkie oczekiwania". Prawie poģowa próbek testowych miaģa doskonaģe wyniki (to znaczy, wszystkie 24 bloki cech prawidģowo rozróŋniaģy zbiornik i zbiornik). Ponadto wszystkie próbki testowe zawierające zbiorniki miaģy wynik większy lub równy 11, a wszystkie próbki testowe niezawierające zbiorników miaģy wynik mniejszy lub równy 7. System wczesnego wykrywania zbiorników w Philco zostaģ zbudowany z analogowym zespóģ obwodów - nie zaprogramowany na komputerze. Jak póžniej opracowaģ Thomas Harley, lider projektu tego systemu, waŋne jest, aby pamiętaæ o technologicznym kontekķcie epoki, w której ta praca zostaģa wykonana. Wdroŋony przez nas system nie miaģ wbudowanych moŋliwoķci obliczeniowych. Cięŋarami liniowej funkcji dyskryminacyjnej byģy rezystory, które kontrolowaģy prąd pochodzący z (binarnego) žródģa napięcia w elementach rejestru przesuwnego. Prądy te zostaģy zsumowane i kaŋda cecha zostaģa rozpoznana lub nie w zaleŋnoķci od tego, czy suma tych prądów przekroczyģa wartoķæ progową. Te decyzje dotyczące funkcji binarnych zostaģy następnie zsumowane, ponownie w analogowym obwodzie elektrycznym, a nie w komputerze, i ponownie podjęto decyzję [zbiornik lub brak zbiornika] w zaleŋnoķci od tego, czy suma przekroczyģa wartoķæ progową
W innym systemie klasyfikacja statystyczna zostaģa wdroŋona przez program o nazwie MULTINORM, dziaģający na komputerze Philco 2000. W innych eksperymentach Philco zastosowaģ dodatkowe testy statystyczne, aby w większym stopniu obliczyæ niektóre bloki cech niŋ inne przy obliczaniu wyniku koņcowego. Kanal powiedziaģ, ŋe te eksperymenty z waŋeniem wyników bloków charakterystycznych "przewidywaģy ideę klasyfikacji maszyny wektorów noķnych (SVM) [...] przy uŋyciu pierwszej warstwy do identyfikacji próbek szkoleniowych blisko granicy między zbiornikami i innych czoģgi."
Oczywiķcie systemy te miaģy doķæ ģatwe zadanie. Wszystkie czoģgi byģy w standardowej pozycji i byģy juŋ odizolowane na zdjęciu. (Autorzy wspominają jednak o tym, w jaki sposób system moŋna dostosowaæ do radzenia sobie z czoģgami występującymi w dowolnej pozycji lub orientacji na obrazie. System uwaŋam za interesujący nie tylko ze względu na jego wydajnoķæ, ale takŋe poniewaŋ jest to system warstwowy (podobny do Pandemonium i do alfa-perceptronu) i poniewaŋ jest to przykģad, w którym oryginalny obraz jest podzielony na nakģadające się podobrazy, z których kaŋdy jest przetwarzany niezaleŋnie. Jak wspomnę póžniej, nakģadające się podobrazy odgrywają znaczącą rolę w niektórych modelach obliczeniowych kory nowej. Niestety raporty Philco zawierające szczegóģy tej pracy nie są ģatwo dostępne. Co więcej, Philco i niektóre inne grupy zaangaŋowane w tę pracę zniknęģy. Oto, co napisaģ mi Tom Harley o raportach Philco i o samym Philco:
Większoķæ prac związanych z rozpoznawaniem wzorów wykonanych w Philco w latach 60. XX wieku byģa sponsorowana przez Departament Obrony, a raporty nie byģy dostępne do publicznej dystrybucji. Od tego czasu sama firma naprawdę rozpģynęģa się w powietrzu. Firma Phil Motor zostaģa kupiona przez Ford Motor Company w 1961 r., A do 1966 r. Wyeliminowali laboratoria badawcze Philco, w których pracowaģ Laveen Kanal. Ford próbowaģ przenieķæ tą maģą grupę do rozpoznawania wzorów do Newport Beach w Kalifornii [lokalizacja firmy Aeronutronic Division, której grupa do rozpoznawania wzorów równieŋ się póžniej zģoŋyģa], a kiedy wszyscy postanowili nie iķæ, przenieķli ich do dziaģu komunikacji i powiedzieli aby zamknąæ nasze projekty rozpoznawania wzorców. Laveen ostatecznie przeszedģ na University of Maryland. W póžniejszych latach to, co byģo Philco, zostaģo sprzedane Loralowi, a większoķæ z nich zostaģa póžniej sprzedana Lockheedowi Martinowi.
Podejķcie do problemów AI związanych z sieciami neuronowymi i technikami statystycznymi nazwano "niesymbolicznymi" w celu zestawienia ich z pracą "przetwarzania symboli" przez osoby zainteresowane udowodnieniem twierdzeņ, graniem w gry i rozwiązywaniem problemów . Te niesymboliczne podejķcia znalazģy zastosowanie gģównie w rozpoznawaniu wzorców, przetwarzaniu mowy i widzeniekomputerowe. Warsztaty i konferencje poķwięcone szczególnie tym tematom zaczęģy się w latach 60. XX wieku. Podgrupa IEEE Computer Society (podkomitet ds. Rozpoznawania wzorców w komitecie ds. Pozyskiwania i przeksztaģcania danych) zorganizowaģa pierwsze "rozpoznawanie wzorców"
Warsztat ", który odbyģ się w Puerto Rico w paždzierniku 1966 r. Drugi (w którym uczestniczyģem) odbyģ się w Delft w Holandii w sierpniu 1968 r. W 1966 r. Ta podgrupa staģa się IEEE Computer Society Pattern Analysis and Machine Intelligence (PAMI) ) Komitet techniczny, który nadal organizowaģ konferencje i warsztaty. Tymczasem pod koniec lat 50. i na początku lat 60. ludzie przetwarzający symbole wykonywali swoją pracę gģównie na MIT, na Carnegie Mellon University, IBM i na Uniwersytecie Stanforda. przejdž dalej do opisu niektórych z tego, co zrobili.