Teoria logiki i wyszukiwania heurystyczne
Tuŋ przed warsztatami w Dartmouth Newell, Shaw i Simon mieli zaprogramowaģ wersję LT na komputerze w firmie RAND Corporation o nazwie JOHNNIAC (nazwany na czeķæ Johna von Neumanna). Póžniejsze artykuģy opisywaģy, w jaki sposób udowodniono niektóre twierdzenia w logice symbolicznej, które zostaģy udowodnione przez Russella i Whitehead w tomie I ich klasycznej pracy, Principia Mathematica. LT pracowaģ nad transformacjami pięciu aksjomatów logiki zdaniowej Russella i Whiteheada, reprezentowanych dla komputera przez "struktury symboli", aŋ do wytworzenia struktury odpowiadającej twierdzeniu, które ma zostaæ udowodnione. Poniewaŋ istnieje wiele róŋnych transformacji, które moŋna wykonaæ, znalezienie odpowiednich do udowodnienia danego twierdzenia wiąŋe się z tym, co ludzie informatyki nazywają "procesem wyszukiwania". Aby opisaæ dziaģanie LT i innych symbolicznych programów AI, muszę najpierw wyjaķniæ, co naleŋy rozumieæ przez "strukturę symboli", a co przez "ich przeksztaģcanie". W komputerze symbole moŋna ģączyæ w listy, takie jak (A; 7; Q). Symbole i listy symboli to najprostsze rodzaje struktur symboli. Bardziej zģoŋone struktury skģadają się z list symboli, takich jak ((B; 3); (A; 7; Q)), oraz list list list symboli i tak dalej. Poniewaŋ takie listy list itp. Mogą byæ doķæ zģoŋone, nazywane są "strukturami". Moŋna pisaæ programy komputerowe, które przeksztaģcają struktury symboli w inne struktury symboli. Na przykģad za pomocą odpowiedniego programu struktura "(suma siedmiu i pięciu)" moŋe zostaæ przeksztaģcona w strukturę "(7 + 5)", którą moŋna przeksztaģciæ w symbol "12." Przeksztaģcanie struktur symboli i poszukiwanie odpowiedniej sekwencji rozwiązywania problemów leŋy u podstaw pomysģów Newella i Simona dotyczących mechanizacji inteligencji. W póžniejszym artykule (tym, który dostali przy okazji otrzymania prestiŋowej nagrody Turinga), podsumowali proces w następujący sposób:
Rozwiązania problemów są reprezentowane przez struktury symboli. Za fizyczny system symboli æwiczy inteligencję w rozwiązywaniu problemów przez wyszukiwanie {to znaczy, generując i stopniowo modyfikując struktury symboli, aŋ wytworzy strukturę rozwiązania.
…
Stwierdzenie problemu oznacza wyznaczenie (1) testu dla klasy struktur symboli (rozwiązania problemu) i (2) generatora struktur symboli (potencjalne rozwiązania). Aby rozwiązaæ problem, naleŋy wygenerowaæ strukturę za pomocą (2), która speģnia test (1).
Zrozumienie szczegóģowo, w jaki sposób sam LT uŋyģ struktur symboli i ich transformacji do udowodnienia twierdzeņ, wymagaģoby matematycznego i logicznego tģa. Proces ten jest ģatwiejszy do wyjaķnienia przy uŋyciu jednego z ulubionych "problemów z zabawkami" AI - "piętnastu zagadek". Piętnaķcie ģamigģówek jest jednym z kilku rodzajów ģamigģówek. Problem polega na przeksztaģceniu tablicy pģytek z początkowej konfiguracji w "cel" konfiguracji przez kolejne ruchy pģytki do sąsiedniej pustej komórki.
Uŋyję prostszej wersji ukģadanki {takiej, która uŋywa tablicy 3 x 3 osiem przesuwanych pģytek zamiast ukģadu 4 x 4. (Badacze AI eksperymentowali równieŋ z programami do rozwiązywania większych wersji ukģadanki, takimi jak 5 x 5 i 6 x 6.). Zaģóŋmy, ŋe chcieliķmy przenieķæ pģytki z ich konfiguracji po lewej stronie na te po prawej. Zgodnie z podejķciem Newella i Simona musimy najpierw przedstawiæ pozycje kafelków dla komputera za pomocą struktur symboli, z którymi komputer moŋe sobie poradziæ. Będę reprezentowaæ pozycję początkową wedģug następującej struktury, która jest listą trzech podlist:
((2; 8; 3); (1; 6; 4); (7; B; 5)):
Pierwsza lista podrzędna, a mianowicie (2; 8; 3), wymienia osoby zajmujące pierwszy rząd tablicy ukģadanek i tak dalej. B oznacza pustą komórkę w ķrodku trzeciego rzędu. W ten sam sposób konfiguracja celu jest reprezentowana przez następującą strukturę:
((1; 2; 3); (8; B; 4); (7; 6; 5)):
Następnie musimy pokazaæ, w jaki sposób komputer moŋe przeksztaģcaæ struktury, które skonfigurowaliķmy w sposób, który odpowiada dozwolonym ruchom ukģadanki. Zauwaŋ, ŋe kiedy kafelek jest przenoszony, zamienia miejscami pustą komórkę; to znaczy, ŋe pusta komórka równieŋ się porusza. Pusta komórka moŋe się poruszaæ w obrębie wiersza lub zmieniaæ wiersze. Odpowiednio do tych ruchów pustej komórki, gdy kafelek przesuwa się w swoim rzędzie, B zamienia miejsca z liczbą na lewo na liķcie (jeķli jest) lub na prawo (jeķli jest). Komputer moŋe ģatwo wykonaæ dowolną z tych transformacji. Gdy pusta komórka przesuwa się w górę lub w dóģ, B zamienia miejsca z liczbą na odpowiedniej pozycji na liķcie po lewej stronie (jeķli istnieje) lub na liķcie po prawej stronie (jeķli istnieje). Przeksztaģceņ tych moŋna równieŋ dokonaæ doķæ ģatwo za pomocą programu komputerowego. Stosując podejķcie Newella i Simona, zaczynamy od struktury symboli reprezentującej początkową konfigurację oķmiu puzzli i stosujemy dozwolone transformacje, aŋ do osiągnięcia celu. Istnieją trzy transformacje początkowej struktury symboli. Tworzą one następujące struktury:
((2; 8; 3); (1; 6; 4); (B; 7; 5));
((2; 8; 3); (1; 6; 4); (7; 5; B));
i
((2; 8; 3); (1; B; 4); (7; 6; 5)):
Ŋadne z nich nie reprezentuje konfiguracji celu, dlatego nadal stosujemy transformacje do kaŋdego z nich i tak dalej, aŋ do osiągnięcia struktury reprezentującej cel. My (i komputer) moŋemy ķledziæ dokonane transformacje, ustawiając je w strukturze przypominającej treble, takiej jak pokazano w
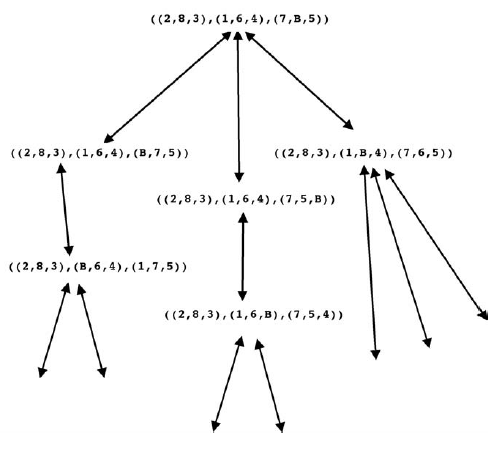
(Groty strzaģek na obu koņcach linii reprezentujących transformacje wskazują, ŋe kaŋda transformacja jest odwracalna)
Ta wersja ósemki jest stosunkowo prosta, więc nie trzeba próbowaæ wielu transformacji, zanim cel zostanie osiągnięty. Zazwyczaj jednak (szczególnie w większych wersjach ukģadanki) komputer byģby zalany przez wszystkie moŋliwe transformacje {tak bardzo, ŋe nigdy nie generowaģby wyraŋenia celu. Aby ograniczyæ coķ, co póžniej nazwano "eksplozją kombinatoryczną" transformacji, Newell i Simon zasugerowali uŋycie "heurystyki" do wygenerowania tylko tych transformacji, które prawdopodobnie są na drodze do rozwiązania. W jednym ze swoich artykuģów na temat LT napisali: "proces, który moŋe rozwiązaæ problem, ale nie daje ŋadnych gwarancji, nazywa się to heurystyką dla tego problemu". Zamiast ķlepo uderzaæ we wszystkie strony w poszukiwaniu dowodu, LT uŋyģ wyszukiwania kierowanego heurystyką lub \ heurystycznego wyszukiwania. "Zwykle, tak jak w przypadku LT, nie ma gwarancji, ŋe wyszukiwanie heurystyczne zakoņczy się powodzeniem, ale kiedy jest skuteczny (i to doķæ często) eliminuje wiele innych bezowocnych poszukiwaņ
. Poszukiwanie rozwiązania problemu zģoŋonego z oķmiu puzzli polega na powiększeniu drzewa struktur symboli poprzez zastosowanie transformacji do "liķci" drzewa, a tym samym przedģuŋenie Aby ograniczyæ wzrost drzewa, powinniķmy uŋyæ heurystyki, aby zastosowaæ transformacje tylko do tych liķci, które są na drodze do rozwiązania. Jednym z takich heurystyk moŋe byæ zastosowanie transformacji do tego liķcia z najmniejszą liczbą pģytek pozycji w porównaniu do konfiguracji bramkowej. Poniewaŋ problemy z przesuwanymi pģytkami zostaģy dokģadnie zbadane, istnieje szereg heurystyk, które okazaģy się przydatne - te znacznie lepsze niŋ prosta liczba pģytek z pozycją poza pozycją, którą wģaķnie zasugerowaģem. Wykorzystanie heurystyki kluczem do rozwiązania problemu staģo się gģównym tematem sztucznej inteligencji, co daģo początek tak zwanemu programowaniu heurystycznemu. "Byæ moŋe idea poszukiwania heurystycznego byģa juŋ w powietrzu" w czasie warsztatów w Dartmouth. Byģo to dorozumiane we wczeķniejszej pracy Claude'a
Shannona. W marcu 1950 r. Zapalony szachista Shannon opublikowaģ artykuģ proponujący pomysģy na zaprogramowanie komputera do gry w szachy. W swoim artykule Shannon rozróŋniaģ strategie nazywane "typem A" i "typem B". Strategie typu A badają kaŋdą moŋliwą kombinację ruchów, podczas gdy strategie typu B wykorzystują specjalistyczną wiedzę o szachach, aby skupiæ się na liniach gry, które są uwaŋane za najbardziej produktywne. Strategie typu B zaleŋaģy od tego, co Newell i Simon nazwali póžniej heurystyką. A Minsky jest cytowany jako "
. Juŋ uwaŋaģem pomysģ poszukiwaņ heurystycznych za oczywisty i naturalny, tak więc teoretyk logiki nie byģ dla mnie imponujący". Doķæ wczeķnie w AI stwierdzono, ŋe sposób skonfigurowania problemu, jego "reprezentacja" ma kluczowe znaczenie dla jego rozwiązania. Jednym z przykģadów wpģywu reprezentacji na rozwiązywanie problemów jest John McCarthy i nazywa się to problemem "okaleczonej szachownicy". Oto problem: "Dwa szachownice po przeciwnych rogach są usuwane z szachownicy. Czy
to moŋliwe aby pokryæ pozostaģe kwadraty domino? "(Domino to prostokątna pģytka, która pokrywa dwa sąsiednie kwadraty.) Naiwnym sposobem poszukiwania rozwiązania byģoby próba umieszczenia domina na wszystkie moŋliwe sposoby nad szachownicą. Ale jeķli ktoķ uŋywa informacja, ŋe szachownica skģada się z 32 kwadratów jednego koloru i 32 innego koloru oraz, ŋe przeciwlegģe naroŋne kwadraty są tego samego koloru, wtedy uķwiadomimy sobie, ŋe okaleczona deska skģada się z 30 kwadratów jednego koloru i 32 drugiego. domino obejmuje dwa kwadraty przeciwnych kolorów, nie ma sposobu, aby zestaw ich mógģ pokryæ pozostaģe kolory. McCarthy byģ zainteresowany tym, czy ludzie mogą wymyķliæ "kreatywne" sposoby na uģoŋenie ukģadanki, aby moŋna ją byģo rozwiązaæ przez komputery wykorzystujące metody oparte na logicznej dedukcji. Kolejną klasyczną ģamigģówką, która zostaģa wykorzystana do badania efektów róŋnych reprezentacji, jest problem "misjonarzy i kanibali": Trzej kanibale i trzej misjonarze muszą przekroczyæ rzekę. Ich
ģódž moŋe pomieķciæ tylko dwie osoby. Jeķli liczba kanibali przewyŋszy liczbę misjonarzy, po obu stronach rzeki, misjonarze po tej stronie zginą. Kaŋdy misjonarz i kaŋdy kanibal moŋe wiosģowaæ ģodzią. Jak caģa szóstka moŋe bezpiecznie przeprawiæ przez rzekę? Większoķæ ludzi nie ma problemów z sformuģowaniem tej ukģadanki jako problemu wyszukiwania, a rozwiązanie jest stosunkowo ģatwe. Ale wymaga to jednego nieintuicyjnego kroku. Informatyk i badacz sztucznej inteligencji Saul Amarel (1928-2002) napisaģ obszerny artykuģ analizujący tę ģamigģówkę i róŋne jej rozszerzone wersje, w których moŋe byæ róŋna liczba misjonarzy i kanibali. (Wydaje się, ŋe wersje rozszerzone nie są takie proste.) Po przejķciu z jednej reprezentacji do drugiej Amarel ostatecznie opracowaģ reprezentację dla uogólnionej wersji problemu, którego rozwiązanie praktycznie nie wymagaģo wyszukiwania. Naukowcy zajmujący się sztuczną inteligencją wciąŋ badają, jak najlepiej przedstawiaæ problemy, a co najwaŋniejsze, w jaki sposób zmusiæ systemy
AI do stworzenia wģasnych reprezentacji.
Udowadnianie twierdzeņ w geometrii
Nathan Rochester powróciģ do IBM po warsztatach Dartmouth podekscytowanych dyskusjami, które prowadziģ z Marvinem Minsky′m na temat pomysģów Minsky′ego na temat moŋliwego programu komputerowego do dowodzenia twierdzeņ w geometrii. Opisaģ te pomysģy nowemu pracownikowi IBM, Herbowi Gelernterowi. Gelernter wkrótce rozpocząģ projekt badawczy mający na celu opracowanie maszyny do dowodzenia twierdzeņ geometrycznych. Przedstawiģ artykuģ na temat pierwszej wersji swojego programu na konferencji w Paryŋu w czerwcu 1959,8, potwierdzając, ŋe sam projekt badawczy jest konsekwencją Letniego Projektu Badawczego Inteligencji Sztucznej Dartmouth z 1956 r., podczas którego M. L. Minsky wskazaģ potencjalną uŋytecznoķæ schematu dla maszyny dowodzącej twierdzeņ geometrycznych. Program Gelernter wykorzystaģ dwa waŋne pomysģy. Jednym z nich byģo jawne uŋycie subgoals (czasem nazywanych "rozumowaniem wstecznym lub "dziel i rządž"), a drugim byģo uŋycie diagramu do zamykania daremnych ķcieŋek wyszukiwania.
trategia nauczana w szkole ķredniej w celu udowodnienia twierdzenia z geometrii wiąŋe się z ustaleniem dodatkowych faktów geometrycznych, z których, jeķli to prawda, twierdzenie powstaģoby natychmiast. Na przykģad, aby udowodniæ, ŋe dwa kąty są równe, wystarczy wykazaæ, ŋe odpowiadają one kątom dwóch "przystających" trójkątów. (Trójkąt jest zgodny z innym, jeķli moŋna go przetģumaczyæ i obróciæ, a nawet obróciæ, w taki sposób, aby dokģadnie pasowaģ do drugiego.) Tak więc pierwotny problem przeksztaģca się w problem pokazania, ŋe dwa trójkąty są przystające . Jednym ze sposobów (między innymi) pokazania, ŋe dwa trójkąty są zgodne, jest pokazanie, ŋe dwa odpowiadające boki i zamknięty kąt dwóch trójkątów mają te same rozmiary. Ten proces rozumowania wstecznego koņczy się, gdy to, co pozostaje do wykazania, naleŋy do przesģanek twierdzenia. Czytelnicy zaznajomieni z geometrią będą mogli podąŋaæ za ilustracyjnym przykģadem pokazanym na rysunku.
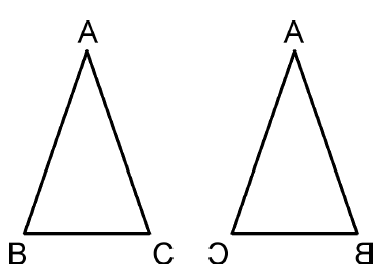
Tam po lewej stronie otrzymujemy trójkąt ABC o boku AB równym boku AC i musimy udowodniæ, ŋe kąt ABC jest równy kątowi ACB. Trójkąt po prawej stronie to odwrócona wersja trójkąta ABC. Oto dowód: jeķli moglibyķmy udowodniæ, ŋe trójkąt ABC jest przystające do trójkąta 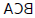 , wówczas nastąpiģoby to twierdzenie, poniewaŋ dwa kąty są odpowiednimi kątami dwóch trójkątów. Te dwa trójkąty moŋna udowodniæ, ŋe są zgodne, gdybyķmy mogli ustaliæ, ŋe bok AB (trójkąta ABC) jest równy bokowi
, wówczas nastąpiģoby to twierdzenie, poniewaŋ dwa kąty są odpowiednimi kątami dwóch trójkątów. Te dwa trójkąty moŋna udowodniæ, ŋe są zgodne, gdybyķmy mogli ustaliæ, ŋe bok AB (trójkąta ABC) jest równy bokowi 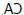 (trójkąta ) i ten bok AC (trójkąta ABC) jest równy bokowi
(trójkąta ) i ten bok AC (trójkąta ABC) jest równy bokowi 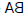 (trójkąta ) i ŋe kąt A (trójkąta ABC) jest równy kątowi A (trójkąta ). Ale przesģanki twierdzą, ŋe bok AB jest równy bokowi AC, a te dģugoķci nie zmieniają się w trójkącie ipped-over. Podobnie, kąt A jest równy jego wersji ipped-over {więc mamy nasz dowód. Przed kontynuowaniem mojego opisu programu Gelerntera, krótka historia dygresja jest w porządku. Udowodnione wģaķnie twierdzenie o geometrii jest sģynne {jest piątą propozycją w Księdze I Elementów Euklidesa. Poniewaŋ dowód twierdzenia Euklidesa byģ trudnym problemem dla początkujących, staģ się znany jako most pons asinorum lub most gģupców. "Dowód podany tutaj jest prostszy niŋ Euklidesa - jego wersję podaģ Pappus z Aleksandrii (okoģo 290-350 lat) "Symulacja ręki" Minsky'ego programu do dowodzenia twierdzeņ w geometrii, omówiona w Dartmouth, przyniosģa ten wģaķnie dowód (pomijając to, co uwaŋam za pomocny krok do przeskoczenia trójkąta). Minsky napisaģ
(trójkąta ) i ŋe kąt A (trójkąta ABC) jest równy kątowi A (trójkąta ). Ale przesģanki twierdzą, ŋe bok AB jest równy bokowi AC, a te dģugoķci nie zmieniają się w trójkącie ipped-over. Podobnie, kąt A jest równy jego wersji ipped-over {więc mamy nasz dowód. Przed kontynuowaniem mojego opisu programu Gelerntera, krótka historia dygresja jest w porządku. Udowodnione wģaķnie twierdzenie o geometrii jest sģynne {jest piątą propozycją w Księdze I Elementów Euklidesa. Poniewaŋ dowód twierdzenia Euklidesa byģ trudnym problemem dla początkujących, staģ się znany jako most pons asinorum lub most gģupców. "Dowód podany tutaj jest prostszy niŋ Euklidesa - jego wersję podaģ Pappus z Aleksandrii (okoģo 290-350 lat) "Symulacja ręki" Minsky'ego programu do dowodzenia twierdzeņ w geometrii, omówiona w Dartmouth, przyniosģa ten wģaķnie dowód (pomijając to, co uwaŋam za pomocny krok do przeskoczenia trójkąta). Minsky napisaģ
"W 1956 roku napisaģem dwie notatki o ręcznie symulowanym programie do dowodzenia twierdzeņ w geometrii. W pierwszej notatce procedura znalazģa prosty dowód, ŋe jeķli trójkąt ma dwa równe boki, to odpowiednie kąty są równe. zauwaŋając, ŋe trójkąt ABC przystaje do trójkąta CBA z powodu "boku-kąta-boku". Co ciekawe, znaleziono to po bardzo krótkim wyszukiwaniu {bo przecieŋ nie byģo wiele rzeczy do zrobienia. moŋe powiedzieæ, ŋe program byģ zbyt gģupi, aby zrobiæ to, co ktoķ mógģby zrobiæ, to znaczy pomyķleæ: "Och, oba są tym samym trójkątem. Na pewno nic dobrego nie wyniknie z nadania mu dwóch róŋnych nazw. "(Program posiada zbiór heurystycznych metod dowodzenia twierdzeņ podobnych do Euklidesa, a jednym z nich byģo to, ŋe jeķli chcesz udowodniæ, ŋe dwa kąty są równe, pokaŋ, ŋe są to odpowiadające sobie częķci przystających trójkątów. "Wtedy miaģ teŋ kilka sposobów na zademonstrowanie zgodnoķci. Nie byģo nic więcej w tym pierwszym niŋ symulacja.) Ale nigdzie nie mogę znaležæ tej notatki. "
Jak powiedziaģ Minsky, jest to bardzo ģatwy problem dla komputera. Program Gelernter okazaģ się znacznie trudniejszymi twierdzeniami, a do tego jego uŋycie diagramu byģo niezbędne. Program dosģownie nie narysowaģ i nie spojrzaģ na schemat. Zamiast tego, jak napisaģ Gelernter,
"[Program] jest dostarczany ze schematem w postaci listy moŋliwych wspóģrzędnych dla punktów wymienionych w twierdzeniu. Tej liķcie punktów towarzyszy kolejna lista okreķlająca punkty poģączone segmentami. Wspóģrzędne są wybierane, aby odzwierciedliæ największa moŋliwa ogólnoķæ w postaciach. "
Na przykģad punkty wymienione w problemie dotyczącym udowodnienia równoķci dwóch kątów są wierzchoģkami trójkąta ABC, a mianowicie punkty A, B i C. Wybrano wspóģrzędne dla kaŋdego z tych punktów i zadbano o to, aby upewniæ się, ŋe wspóģrzędne te nie speģniają ŋadnych specjalnych nienazwanych wģaķciwoķci. Program Gelerntera dziaģaģ, konfigurując podzadania i podzadania, takie jak te, których uŋyģem w podanym przykģadzie, a następnie szukaģ ģaņcucha tych zakoņczonych podzadaniami, które moŋna byģoby ustaliæ bezpoķrednio z lokalu. Jednak zanim program zostaģ wybrany do pracy z jakimkolwiek podzadaniem, najpierw przetestowano go, aby sprawdziæ, czy jest on utrzymany na schemacie. Jeķli tak się stanie, moŋe byæ moŋliwe do udowodnienia i dlatego moŋe byæ uwaŋany za moŋliwą drogę do dowodu. Ale gdyby nie byģo tego na schemacie, nie mogģoby byæ prawdą. W ten sposób moŋna go wyeliminowaæ z dalszych rozwaŋaņ, tym samym "przycinając" drzewo wyszukiwania i oszczędzając, co z pewnoķcią byģoby bezowocnym wysiģkiem. Póžniejsze prace w AI wykorzystywaģyby równieŋ tego rodzaju "semantyczne" informacje. Widzimy podobieņstwa między strategiami stosowanymi w programie geometrii a strategiami stosowanymi przez ludzi podczas rozwiązywania problemów. Powszechne jest dla nas dziaģanie wstecz - przeksztaģcanie trudnego problemu w podproblemy i te w podproblemy i tak dalej, aŋ w koņcu problemy są trywialne. Kiedy podproblem skģada się z wielu częķci, wiemy, ŋe musimy rozwiązaæ je wszystkie. Rozumiemy równieŋ, kiedy proponowany podproblem jest ewidentnie niemoŋliwy i dlatego moŋemy go odrzuciæ. Następny program, który opisuję, opieraģ się wyražnie na tym, co jego autorzy uwaŋali za ludzkie strategie rozwiązywania problemów.
Ogólne rozwiązanie problemu
Na tej samej konferencji w Paryŋu w 1959 r., Na której Gelernter przedstawiģ swój program, Allen Newell, J.C. Shaw i Herb Simon napisali artykuģ opisujący ich ostatnie prace nad mechanizacją rozwiązywania problemów. Ich program, który nazwali "General Problem Solver (GPS)", byģo ucieleķnieniem ich pomysģów na temat rozwiązywania problemów przez ludzi. Rzeczywiķcie twierdzili, ŋe sam program byģ teorią ludzkich zachowaņ związanych z rozwiązywaniem problemów. Newell i Simon byli wķród tych, którzy byli równie zainteresowani (byæ moŋe nawet bardziej zainteresowani) wyjaķnianiem inteligentnego zachowania ludzi podczas budowania inteligentnej maszyny Napisali
"Często twierdzi się, ŋe naleŋy wytyczyæ ostroŋną granicę między próbą wykonania na maszynach tych samych zadaņ, które wykonują ludzie, a próbą symulacji procesów, których ludzie faktycznie uŋywają do osiągnięcia tych celów zadania ... GPS maksymalnie myli oba podejķcia - z obopólną korzyķcią. "
GPS byģ rezultatem wczeķniejszej pracy nad teorią logiki, poniewaŋ polegaģ na manipulowaniu strukturami symboli (w co, jak wierzyli, ludzie równieŋ). Ale GPS miaģ waŋny dodatkowy mechanizm wķród swoich strategii manipulacji symbolami. Podobnie jak program geometrii Gelerntera, GPS przeksztaģciģ problemy w podproblemy i tak dalej. Innowacja GPS polegaģa na obliczeniu "róŋnicy" między problemem do rozwiązania (przedstawionym jako struktura symbolu) a tym, co juŋ byģo znane lub podane (przedstawione równieŋ jako struktura symbolu). Następnie program próbowaģ zmniejszyæ tę róŋnicę poprzez zastosowanie operatora manipulującego symbolami (znanego jako istotny dla tej róŋnicy) do początkowej struktury symboli. Newell i Simon nazywali tę strategię "oznacza - koņczy analizę." (Naleŋy zwróciæ uwagę na podobieņstwo do systemy kontroli sprzęŋenia zwrotnego, które nieustannie starają się zmniejszyæ róŋnicę między bieŋącym ustawieniem a poŋądanym ustawieniem.) Aby to zrobiæ, musiaģby wykazaæ, ŋe speģniono warunki zastosowania operatora {podproblem. Następnie program uruchomiģ kolejną wersję pracowaæ nad tym podproblemem, szukam róŋnicy i tak dalej. Zaģóŋmy na przykģad, ŋe celem jest, aby Sammy byģ w szkole, gdy wiadomo, ŋe Sammy jest w domu. GPS oblicza róŋnicę, a mianowicie, ŋe Sammy jest w niewģaķciwym miejscu i szuka operatora odpowiedniego do zmniejszenia tej róŋnicy, a mianowicie: kierowanie Sammy do szkoģy. Aby prowadziæ Sammy′go do szkoģy, samochód musi byæ sprawny. Aby problem byģ interesujący, przypuszczamy, ŋe akumulator samochodu jest rozģadowany, więc GPS nie moŋe zastosowaæ operatora samochodu, poniewaŋ ten operator wymaga dziaģającej baterii. Uzyskanie dziaģającej baterii jest podproblemem, do którego GPS moŋe zastosowaæ wģasną wersję. Ta "niŋsza" wersja GPS oblicza róŋnicę, a mianowicie zapotrzebowanie na dziaģającą baterię, i okreķla operatora, a mianowicie , wzywając mechanika, by przyszedģ i zainstalowaģ nową baterię. Aby zadzwoniæ do mechanika, trzeba mieæ numer telefonu (i zaģóŋmy, ŋe go mamy), więc GPS stosuje operatora mechanika wywoģywania, co powoduje, ŋe mechanik nadchodzi, aby zainstalowaæ nową baterię. Niŋsza wersja GPS z powodzeniem rozwiązaģa problem, więc nadrzędny GPS moŋe teraz wznowiæ {zauwaŋając, ŋe warunek prowadzenia samochodu, a mianowicie posiadanie dziaģającego akumulatora, jest speģniony. Tak więc GPS stosuje tego operatora, Sammy dostaje się do szkoģy, a pierwotny problem zostaģ rozwiązany. (Ten przykģad ilustruje ogólne dziaģanie GPS. Prawdziwy, wykorzystujący rzeczywiste struktury symboli, róŋnice i operatorów z ich warunkami itd. Byģby uciąŋliwy, ale nie bardziej odkrywczy.) Gdy GPS dziaģa na podproblemy, uruchamiając nową wersję siebie , wykorzystuje bardzo waŋny pomysģ w informatyce (i matematyce) o nazwie "rekurencja". Byæ moŋe znasz pomysģ, ŋe programiķci komputerowi organizują zģoŋone programy w sposób hierarchiczny. Oznacza to, ŋe programy gģówne ponownie uruchamiają podprogramy, które mogą ponownie uruchamiaæ podprogramy i tak dalej. Kiedy program gģówny "wywoģuje" podprogram, program gģówny zawiesza się, dopóki podprogram nie dokoņczy tego, co powinien zrobiæ (ewentualnie przekazując dane do programu gģównego), a następnie program gģówny wznowi pracę. W sztucznej inteligencji (a takŋe w innych aplikacjach) często program gģówny wywoģuje swoją wersję - uwaŋając, aby nowa wersja dziaģaģa na prostszym problemie, aby uniknąæ niekoņczących się powtórzeņ i "zapętlania". Samo wywoģanie programu nazywa się "rekurencją". Czy ludzie uŋywają podprogramów i rekurencji we wģasnym myķleniu? Caģkiem moŋliwe, ale ich zdolnoķæ do przypominania sobie, jak wznowiæ to, co robiģ pewien proces myķlowy wyŋszego poziomu, gdy proces ten rozpoczyna ģaņcuch procesów niŋszego poziomu, jest z pewnoķcią ograniczona. Nie wierzę, ŋe GPS próbowaģ naķladowaæ to ograniczenie ludzkiego myķlenia. Newell i Simon wierzyli, ŋe metody stosowane przez GPS mogą byæ wykorzystane do rozwiązania wielu róŋnych problemów, tworząc w ten sposób pojęcie "ogólne". Aby zastosowaæ go do konkretnego problemu, naleŋaģoby dostarczyæ "tabelę róŋnic" dla tego problemu. W tabeli wymieniono wszystkie moŋliwe róŋnice, które mogą się pojawiæ, i dopasowano je do operatorów, co w przypadku tego problemu zmniejszyģoby odpowiadające róŋnice. GPS zostaģ w rzeczywistoķci zastosowany do szeregu róŋnych problemów logicznych i zagadek i zainspirowaģ póžniejsze prace zarówno w zakresie sztucznej inteligencji, jak i kognitywistyki. Jego dģugowiecznoķæ jako samego programu rozwiązywania problemów i jako teorii rozwiązywania problemów ludzkich byģa jednak krótka i przetrwaģa tylko dzięki róŋnym potomkom (o których więcej omówimy póžniej). W wielu programach AI opracowanych na początku lat 60. XX wieku zastosowano procedury wyszukiwania heurystycznego. Na przykģad inny doktor Minsky'ego studenci, James Slagle, zaprogramowali system o nazwie SAINT, który moŋe rozwiązywaæ problemy rachunku róŋniczkowego, odpowiednio reprezentowanego jako struktury symboli. Rozwiązano 52 z 54 problemów zaczerpniętych z rachunku pierwszego stopnia MIT. Wiele programów heurystycznych wykorzystano w programach, które mogģy graæ w gry planszowe, a teraz zajmę się nimi.
Programy gier
Wspomniaģem juŋ o niektórych wczesnych pracach Shannona i Newella, Shawa i Simona nad programami do gry w szachy. Gra w doskonaģe szachy wymaga inteligencji. W rzeczywistoķci Newell, Shaw i Simon napisali, ŋe "jeķli moŋna opracowaæ udaną maszynę do gry w szachy, wydaje się, ŋe przeniknąģ do rdzenia ludzkich wysiģków intelektualnych". Myķlenie o programach do gry w szachy wraca przynajmniej do Babbage. Wedģug Murraya Campbella, badacza IBM, który pomógģ zaprojektowaæ mistrzowski program do gry w szachy (o którym wspomnę póžniej), ksiąŋka Babbag′a z 1845 r., ŋycie filozofa, zawiera pierwszą udokumentowaną dyskusję na temat programowania komputera do gry w szachy . Konrad Zuse, niemiecki projektant i konstruktor komputerów Z1 i Z3, wykorzystaģ swój język programowania o nazwie Plankalkul do zaprojektowania programu do gry w szachy na początku lat 40. XX wieku. W 1946 r. Turing wspomniaģ o komputerze pokazującym "inteligencję", którego paradygmatem jest gra w szachy. W 1948 r. Turing i jego byģy kolega ze
studiów, D. G. Champernowne, zaczęli pisaæ program do gry w szachy w 1952 r., nie mając komputera wystarczająco mocnego, aby uruchomiæ program, Turing graģ w grę, w której symulowaģ komputer, zabierając okoģo póģ godziny na ruch. (Gra zostaģa nagrana. Moŋna ją zobaczyæ na stronie :
http://www.chessgames.com/perl/chessgamegid=1356927.
Program przegraģ z kolegą Turinga, Alickem Glennie; mówi się jednak, ŋe program wygraģ mecz z ŋoną Champernowne. Po tych wczesnych programach prace nad komputerowymi programami szachowymi byģy kontynuowane, z wysiģkiem od początku do koņca, przez następne kilka dekad. Wedģug Johna McCarthy'ego Alexander Kronrod, rosyjski badacz sztucznej inteligencji, powiedziaģ: "Szachy to Drosophila AI" - co oznacza, ŋe sģuŋy lepiej niŋ bardziej otwarte zadania intelektualne jako przydatny okaz laboratoryjny do badaņ. Jak powiedziaģ Minsky:
"Nie chodzi o to, ŋe gry i problemy matematyczne są wybierane, poniewaŋ są jasne i proste; raczej dlatego, ŋe dają one najmniejszym strukturom początkowym największą zģoŋonoķæ, dzięki czemu moŋna zaangaŋowaæ się w naprawdę grožne sytuacje po względnie minimalnym przejķciu na programowanie "
. Szachy stanowią bardzo trudne problemy dla AI i dopiero w poģowie lat 60. pojawiģy się pierwsze kompetentne programy szachowe. Bardziej wczesny sukces osiągnięto jednak w przypadku prostszej gry w warcaby (lub warcabów, jak ta gra znana jest w brytyjskim angielskim). Arthur Samuel zacząģ myķleæ o programowaniu komputera do gry w warcaby pod koniec lat 40. na University of Illinois, gdzie byģ profesorem inŋynierii elektrycznej. W 1949 roku doģączyģ do laboratorium Poughkeepsie Laboratory w IBM i ukoņczyģ swój pierwszy program sprawdzania dziaģania w 1952 roku na komputerze IBM 701. Program zostaģ przekodowany dla IBM 704 w 1954 r. Wedģug Johna McCarthy′ego, "Thomas J. Watson Sr., zaģoŋyciel i prezes IBM, zauwaŋyģ, ŋe demonstracja [programu Samuela] podniesie cenę akcji IBM o 15 punktów. Tak. ". [Najwyražniej Samuel nie byģ pierwszym, który napisaģ program do gry w warcaby. Wedģug Encyklopedii Brittanica, Online," Pierwszy udany program sztucznej inteligencji zostaģ napisany w 1951 r. przez Christophera Stracheya, póžniejszego dyrektora Programming Research Group w University of Oxford. Program warcabów (szkiców) Stracheya dziaģaģ na komputerze Ferranti Mark I na University of Manchester, Anglia. Do lata 1952 r. Program ten mógģ zagraæ w peģną grę w warcaby z rozsądną prędkoķcią"] .Gģównym zainteresowaniem Samuela w programowaniu komputera do grania w warcaby byģo zbadanie, jak zdobyæ komputer do nauki. Uznanie" czasochģonnej i kosztownej procedury " "zaangaŋowany w programowanie, Samuel napisaģ:" Programowanie komputerów w celu uczenia się na podstawie doķwiadczenia powinno ostatecznie wyeliminowaæ potrzebę znacznej częķci tych szczegóģowych prac programistycznych. "Wysiģki Samuela byģy jednymi z pierwszych, które miaģy staæ się bardzo waŋną częķcią sztucznej inteligencji, a mianowicie: "uczenie maszynowe". Jego pierwszy program obejmujący uczenie się zostaģ ukoņczony w 1955 r. i zademonstrowany w telewizji 24 lutego 1956 r. Przed opisaniem jego metod uczenia się opiszę ogólnie, w jaki sposób Program Samuela wybraģ ruchy. Technika ta jest bardzo podobna do tego, w jaki sposób wybrano ruchy w oķmiu puzzlach opisanych wczeķniej. Z wyjątkiem teraz naleŋy przewidzieæ fakt, ŋe przeciwnik równieŋ wybiera ruchy. Ponownie powstaje drzewo wyraŋeņ symbolicznych reprezentujących pozycje na planszy. Począwszy od konfiguracji początkowej, rozwaŋane są wszystkie moŋliwe ruchy programu (przy zaģoŋeniu, ŋe program porusza się jako pierwszy). Rezultatem są wszystkie moŋliwe wynikające z tego konfiguracje rozgaģęziające się od konfiguracji początkowej. Następnie z kaŋdego z nich brane są pod uwagę wszystkie moŋliwe ruchy przeciwnika - w wyniku czego powstaje więcej gaģęzi i tak dalej. Gdyby takie drzewo moŋna byģo zbudowaæ dla caģej gry, ruch wygrywający moŋna by obliczyæ na podstawie badania drzewa. Niestety oszacowano, ŋe istnieje okoģo 5 x 1020 moŋliwych pozycji kontrolerów. Wiodący ekspert w programowaniu komputerów do grania w gry, Jonathan Schaeffer, byģ w stanie "rozwiązaæ" warcaby (pokazując, ŋe optymalna gra obu graczy koņczy się remisem) poprzez czasochģonną analizę okoģo 1014 pozycji. Napisaģ mi, ŋe "Byģ to wynik licznych ulepszeņ ukierunkowanych na wyszukiwanie w tych częķciach przestrzeni wyszukiwania, w których najprawdopodobniej znaležliķmy to, czego potrzebowaliķmy". Program Samuela mógģ koniecznie skonstruowaæ tylko częķæ drzewa - to znaczy, mógģ patrzeæ tylko o kilka ruchów do przodu. To, jak daleko to wyglądaģo, wzdģuŋ róŋnych gaģęzi, zaleŋaģo od wielu czynników, które nie muszą nas tutaj dotyczyæ. (Dotyczyģy one takich kwestii, czy moŋliwe byģo natychmiastowe zģapanie). Typowe jest patrzenie w przyszģoķæ z wykorzystaniem trzech ruchów, chociaŋ niektóre gaģęzie mogą byæ eksplorowane (rzadko) na gģębokoķæ aŋ dziesięciu ruchów. Schemat z pracy Samuela przedstawia ogólny pomysģ. Samuel powiedziaģ, ŋe "faktyczne rozgaģęzienia są znacznie liczniejsze". Jak więc program wybiera ruch z tak niekompletnego drzewa? Problem ten napotykają wszystkie programy do grania i wszystkie wykorzystują metody polegające na obliczaniu wyniku dla pozycji na koņcach lub "liķciach" drzewa (to znaczy liķci niekompletnego drzewa wygenerowanych przez program ), a następnie "migruje" ten wynik z powrotem do pozycji wynikających z ruchów z bieŋącej pozycji. Najpierw opiszę, jak obliczyæ wynik, a następnie jak go przenieķæ z powrotem, a następnie w jaki sposób Samuel zastosowaģ metody uczenia się w celu poprawy wydajnoķci. Program Samuela najpierw obliczyģ punkty, które mają byæ przyznane pozycjom na liķciach drzewa na podstawie ich ogólnej \ dobroci "z punktu widzenia programu. Wķród cech, które przyczyniģy się do punktów, byģa względna przewaga w kawaģkach (królowie byli warti więcej niŋ zwykģe elementy), ogólna "mobilnoķæ" (swoboda poruszania się) elementów programu i sterowanie centralne (program miaģ dostęp do 38 takich funkcji, ale wykorzystaģ tylko 16 z nich w tym samym czasie.) Punkty wniesione przez kaŋda cecha zostaģa następnie pomnoŋona przez "wagę" (odzwierciedlając względną waŋnoķæ odpowiadającej jej cechy), a wynik zostaģ zsumowany, aby daæ ogólny wynik dla pozycji. Zaczynając od pozycji bezpoķrednio powyŋej pozycji na koņcu drzewa, jeķli jest to pozycja, dla której nadeszģa kolej na program, moŋemy zaģoŋyæ, ŋe program chciaģby przejķæ do tej pozycji z najwyŋszym wynikiem, aby najwyŋszy wynik zostaģ przeniesiony z powrotem do tej pozycji "bezpoķrednio powyŋej". Jeķli jednak , jest to pozycja, z której kolej ruchu przeciwnika, zakģadamy, ŋe przeciwnik chciaģby przejķæ do tej pozycji z najniŋszym wynikiem. W takim przypadku najniŋszy wynik jest migrowany z powrotem do tego miejsca bezpoķrednio powyŋej pozycji. Ta naprzemiennie "najwyŋsza - najniŋsza" strategia migracji jest kontynuowana aŋ do koņca drzewa i nazywa się strategią minimax. [Prosta modyfikacja tej strategii, zwana procedurą "alpha -beta", sģuŋy do wnioskowania ( poprawnie) z juŋ migrowanych wyników, ŋe niektóre gaģęzie nie muszą byæ wcale badane {umoŋliwiając w ten sposób gģębsze zbadanie innych gaģęzi. Róŋni się opinie na temat tego, kto pierwszy pomyķlaģ o tej waŋnej modyfikacji. McCarthy, Newell i Simon wszyscy roszczą o uznanie. Samuel powiedziaģ mi, ŋe go uŋyģ, ale ŋe jest zbyt oczywiste, aby o nim pisaæ.] Jeķli zaģoŋymy, ŋe koleją programu jest przejķcie z bieŋącej pozycji i ŋe wyniki zostaģy juŋ przeniesione z powrotem do pozycji tuŋ pod nią, program przesunąģby się na tę pozycję z najwyŋszym wynikiem. A potem gra będzie kontynuowana, gdy przeciwnik wykona ruch, kolejny etap wzrostu drzewa, obliczania wyniku i migracji itd., Dopóki jedna strona nie wygra lub przegra. Jedna z metod uczenia się w programie Samuela dostosowaģa wartoķci wag stosowanych przez system punktacji. (Przypomnijmy, ŋe korekty masy w Pandemonium i sieciach neuronowych byģy sposobami uczenia się tych systemów). Wagi zostaģy dostosowane tak, aby wynik pozycji planszy (obliczony na podstawie sumy waŋonych ocen cech) zbliŋyģ się do wartoķci f migrowany wynik po zakoņczeniu wyszukiwania. Na przykģad, jeķli wynik początkowej pozycji zostaģ obliczony (przy uŋyciu wag przed dostosowaniem) jako 22, a migrowany wynik tej pozycji po wyszukiwaniu wynosiģ 30, to wagi uŋyte do obliczenia wyniku początkowej pozycji zostaģy dostosowane w sposób, dzięki któremu nowy wynik (przy uŋyciu skorygowanej wartoķci wag) zostaģ przybliŋony do 30, powiedzmy 27. (Ta technika zapowiedziaģa bardzo waŋną metodę uczenia się, sformuģowaną póžniej przez Richarda Suttona, zwaną "uczeniem się róŋnic czasowych"). Pomysģ tutaj migracja wyniku, zaleŋnie od tego, jak wyglądaģo w przyszģoķci, byģa lepsza niŋ pierwotna ocena. W ten sposób poprawiono procedurę szacowania, dzięki czemu uzyskano wartoķci bardziej spójne z wynikiem "wybiegającym w przyszģoķæ". Samuel zastosowaģ takŋe inną metodę zwaną "rote learning", w której program zapisywaģ róŋne pozycje planszy i migrowane wyniki napotkane podczas rzeczywistej gry. Następnie, pod koniec wyszukiwania, czy napotkana pozycja liķcia byģa taka sama jak jedna z tych zapisanych pozycji , jego wynik byģ juŋ znany (i nie musiaģby byæ obliczany przy uŋyciu wag i cech). Znany wynik, oparty na poprzednim badaniu, prawdopodobnie byģby lepszym wskažnikiem wartoķci pozycji niŋ wynik obliczony. Program Samuela równieŋ skorzystaģ z uŋycia \ book games, które są zapisami gier gģównych graczy w warcaby. Komentując pracę Samuela, John McCarthy napisaģ, ŋe gracze w warcaby mają wiele gier z komentarzami, w których dobre ruchy odróŋniają się od zģych. Program edukacyjny Samuela wykorzystaģ Przewodnik po warcabach Lee, aby dostosowaæ kryteria wyboru ruchów, tak aby program wybraģ te dobrze przemyķlane przez ekspertów sprawdzania tak często, jak to moŋliwe. " Program Samuela graģ bardzo dobrze w warcaby, a latem 1962 roku pokonaģ Roberta Nealeya, mistrza niewidomych warcabów z Connecticut. (Moŋesz zobaczyæ grę rozgrywaną pomiędzy Mr. Nealey a programem Samuela na stronie http: // www. Erz.ch/samuel.htm.) Ale, wedģug Jonathana Schaeffera i Roberta Lake'a: "W 1965 r. Program graģ po cztery gry przeciwko Walterowi Hellmanowi i Derekowi Oldbury (następnie grając w meczu o mistrzostwo ķwiata) i przegrali wszystkie osiem gier "