Języki naturalne i sceny naturalne
Widzieliķmy waŋną rolę danych i technik uczenia maszynowego w destylacji i wykorzystaniu tych danych. Jeķli jeden pojedynczy temat zacząģ ostatnio ģączyæ kilka róŋnych podejķæ do sztucznej inteligencji, od logicznych reprezentacji i rozumowania w Cyc, po decyzje i oszacowania przez sieci neuronowe, jest to ich zaleŋnoķæ od ogromnych iloķci danych. Wyjķcie poza problemy z zabawkami i proste ģamigģówki w ķwiecie rzeczywistym problemy wymagają rzeczywistych danych. Tu zbadamy, w jaki sposób najnowsze systemy przetwarzania języka naturalnego i wizji komputerowej wykorzystują dane reprezentatywne dla danych wejķciowych, z którymi muszą sobie radziæ.
Przetwarzanie języka naturalnego
Rosnące zapotrzebowanie na systemy potrafiące radziæ sobie z językami pisanymi i mówionymi, wraz z nowymi osiągnięciami technicznymi, duŋymi bazami danych i zwiększoną mocą obliczeniową, doprowadziģy do ulepszenia systemów do wykonywania takich zadaņ, jak podsumowywanie fragmentów tekstu, odpowiadanie na zapytania, i tģumaczenia języków. W tej sekcji opiszę niektóre zmiany techniczne w NLP w ciągu ostatnich dwóch lub trzech dekad. Choæ są imponujące, nie pozwoliģy nam jeszcze uķwiadomiæ sobie nadziei Terry′ego Winograda w 1971 r., ŋe "Porozmawiamy z [systemami komputerowymi], tak jak rozmawiamy z asystentem naukowym, bibliotekarzem lub sekretarką, i przeprowadzą nasze polecenia i przekaŋ nam informacje, o które prosimy ". Wiele osób twierdzi, ŋe problemem związanym z realizacją takich systemów jest "kompletna sztuczna inteligencja", w tym sensie, ŋe muszą one byæ na ogóģ tak inteligentne jak ludzie, byæ w stanie rozumowaæ i rozwiązywaæ problemy, a ludzie robią te rzeczy. W kaŋdym razie jest prawdopodobne, ŋe takie systemy, gdy je mamy, będą wykorzystywaæ częķæ lub caģoķæ technologii
Gramatyki i algorytmy parsowania
Wczeķniej opisano niektóre podstawowe idee teorii językoznawstwa. Na przykģad wspomniano, ŋe zdania moŋna analizowaæ pod kątem ich struktury skģadniowej przy uŋyciu gramatyk bezkontekstowych (CFG). Wspomniano równieŋ o bardziej zģoŋonych gramatykach, takich jak gramatyki skoņczonych klauzul (DCG), gramatyki systemowe, gramatyki sieci przejķciowej i DIAGRAM. Systemy wykorzystujące gramatykę do analizy zdaņ w języku naturalnym muszą uŋywaæ algorytmów parsowania do wyszukiwania wķród kandydujących "drzew parsujących" w celu znalezienia jednego lub więcej niŋ jednego zdania wejķciowego. W przypadku realistycznych gramatyk, które "akceptują" te ciągi sģów, które uwaŋamy za legalne zdania i odrzucają te ciągi, które uwaŋamy za nonsensy, często zdarza się, ŋe istnieje wiele moŋliwych analiz, z których kaŋda ma inne znaczenie. Wybór jednego z "najlepszych" drzew parsowania spoķród nich wszystkich następnie zaleŋy od analiz semantycznych i pragmatycznych, które uwzględniają kontekst, w którym występuje zdanie, i zdrową wiedzę ķwiata. Jako humorystyczny przykģad tego, jak moŋna wpaķæ w kģopoty, nie biorąc pod uwagę zdrowego rozsądku, Daniel Jurafsky i James Martin cytują zdanie z filmu Animal Crackers z 1930 r .: Groucho Marks mówi: "Pewnego ranka zastrzeliģem sģonia w mojej piŋamie Nie wiem, jak dostaģ się do mojej piŋamy." Prace nad przetwarzaniem języka naturalnego trwają w celu poznania nowych i bardziej zģoŋonych gramatyk, algorytmów parsowania i technik przetwarzania semantycznego. Nowsze gramatyki potrafią skuteczniej radziæ sobie z większymi podzbiorami języka angielskiego, a wiele z nich obsģuguje języki inne niŋ angielski. Niektóre przykģady to leksykalne gramatyki funkcjonalne (LFG), gramatyki przylegające do drzew (TAG), gramatyki zaleŋnoķci, gramatyki struktury fraz kierowanych gģowami (HPSG) 4, gramatyka rządowa i wiąŋąca oraz gramatyki kategorialne. Wprowadzono równieŋ wiele ulepszeņ w algorytmach parsowania. W przypadku uŋycia z realistycznymi gramatykami pierwsze wyszukiwanie szerokoķci (metodą "od doģu do góry" lub "z góry na dóģ") szybko wyczerpuje miejsce do przechowywania. Gģębokoķæ cofania - pierwsze wyszukiwanie, choæ bardziej oszczędne w stosunku do pamięci, wiąŋe się z ryzykiem, ŋe trzeba będzie wykonaæ większoķæ z wyszukiwania, jeķli wyszukiwanie ma problemy i musi cofnąæ się do wczeķniejszych częķci zdania. Aby uniknąæ koniecznoķci ponownej analizy częķci zdania po rozwinięciu, opracowano parsery wykorzystujące wykresy i inne konstrukcje, w których moŋna przechowywaæ, w celu ewentualnego ponownego uŋycia, juŋ obliczone parsy segmentów zdaņ. Martin Kay opracowaģ pierwszy parser wykresów. Inne parsery wykorzystujące struktury podobne do wykresów to parser Earleya (opracowany przez Jaya Earleya) i algorytm Cocke {Younger - Kasami (CYK). Nowoczesne parsery uŋywają jednej lub drugiej wersji programowania dynamicznego, techniki o której wspomniaģem wczeķniej. Umoŋliwia zapisywanie wyników poķrednich. Wymieniam te przykģady gramatyk i parserów, nie próbując opisów (które są doķæ techniczne), aby zilustrowaæ zakres i gģębię aktywnoķci w tych aspektach NLP. Badania i aplikacje w zakresie przetwarzania języka naturalnego przyniosģy znaczne korzyķci dzięki posiadaniu duŋych plików tekstowych. Takie pliki zawierają miliony zdaņ i istnieją w wielu językach. Obejmują artykuģy w gazetach, teksty literackie i inne materiaģy. Duŋe pliki zdaņ nazywane są ciaģami (liczba mnoga korpusu, co oznacza ciaģo). Zdania z tych plików mogą byæ analizowane i opatrzone adnotacjami przez ludzi, czasami wspomagane algorytmami parsowania, a analizy mogą byæ przechowywane wraz z powiązanymi zdaniami w strukturach zwanych "bankami drzew". Wybitnymi przykģadami są te opracowane na University of Pennsylvania, zwane "Penn Treebanks". Banki drzew wraz z ich adnotacjami mogą byæ uŋyte do wywoģania silniejszych gramatyk obejmujących zawarte w nich zdania. Jak zwykle, im większy jest bank drzew, tym lepsza jest indukowana gramatyka. W tym procesie wykorzystywane są techniki uczenia maszynowego oparte na statystykach, co prowadzi mnie do następnego tematu
Statystyczny NLP
A. Bezkontekstowe reguģy z prawdopodobieņstwami
Jak wspomniaģem wczeķniej, gramatyka powinna rozróŋniaæ zdania, które są akceptowane w języku, od zdaņ, które nie są. Ale, jak zauwaŋają Christopher Manning i Hinrich Schze, "po prostu nie jest moŋliwe dokģadne i peģne scharakteryzowanie dobrze sformuģowanych wypowiedzi, które czynią je czysto od wszystkich innych sekwencji sģów, które są uwaŋane za wypowiedzi žle sformuģowane. Jest tak, poniewaŋ ludzie zawsze rozciągają i naginają "reguģy", aby zaspokoiæ swoje potrzeby komunikacyjne ". Fakt ten zostaģ zauwaŋony doķæ wczeķnie w nauce języka. W swojej ksiąŋce z 1921 roku lingwista i antropolog Edward Sapir napisaģ: "Niestety lub na szczęķcie ŋaden język nie jest spójny tyranicznie. Wszystkie gramatyki przeciekają". Sapir miaģ oczywiķcie na myķli, ŋe kaŋda gramatyka, bez względu na to, jak zģoŋona, zaakceptuje niektóre zdania, których ludzie nie mogą zaakceptowaæ, i odrzuci niektóre, które ludzie będą akceptowaæ. Eugene Charniak, jeden z pierwszych badaczy AI, który rozpoznaģ tę trudnoķæ, zaproponowaģ, aby analizy skģadniowe byģy kwalifikowane przez prawdopodobieņstwa. Niektóre zdania są "prawdopodobnie" ok, a niektóre prawdopodobnie nie, a pomiędzy nimi są wszystkie gradacje. Bezpoķrednią zaletą takiego podejķcia jest to, ŋe prawdopodobieņstwo analizy moŋe zostaæ uŋyte do wyboru spoķród alternatywnych analiz dla dwuznacznych zdaņ. Rozwaŋmy na przykģad dwa alternatywne sposoby odczytania zdania w stylu Groucho "John zastrzeliģ sģonie w piŋamie":
• John (będąc w piŋamie) strzelaģ do sģoni
• John strzelaģ do sģoni (które byģy w piŋamie).
Kaŋda z tych interpretacji zdania ma inne drzewo analizy. Czy istnieje sposób, aby uznaæ jeden z nich za bardziej prawdopodobny od drugiego? W 1969 r. teoretyk automatów Taylor L. Booth zaproponowaģ odmianę gramatyk bezkontekstowych, która przypisuje prawdopodobieņstwa reguģom stosowanym do definiowania gramatyki. Takie gramatyki nazywane są "probabilistycznymi gramatykami bezkontekstowymi" (PCFG). Wykorzystam następującą bardzo prostą (i doķæ niekompletną) gramatykę, aby zilustrowaæ ten pomysģ:
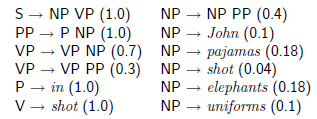
Liczba w nawiasach następujących po regule reprezentuje prawdopodobieņstwo tej reguģy. Tak więc, na przykģad, zgodnie z tą gramatyką, prawdopodobieņstwo wynosi 0,18, ŋe fraza rzeczownikowa w zdaniu jest sģowem "sģonie". Poniewaŋ fraza rzeczownikowa musi byæ czymķ, suma wszystkich prawdopodobieņstw rzeczownikowych wynosi 1,0
B. Prawdopodobieņstwa parsowania drzew
Zakģadając, ŋe prawdopodobieņstwa tych reguģ są niezaleŋne (bardzo niewģaķciwe zaģoŋenie dla realistycznych gramatyk), moŋemy obliczyæ prawdopodobieņstwo parsowania drzewa, biorąc iloczyn prawdopodobieņstwa wszystkich reguģ zastosowanych w drzewie. Dwa drzewa parsowania dla tego zdania pokazano na rysunku
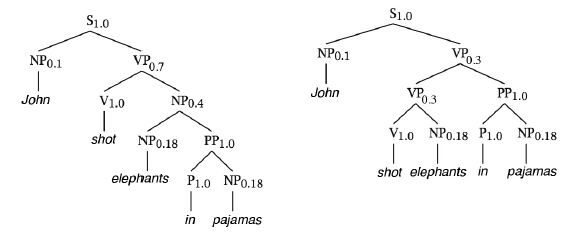
Ta po prawej, w której to John jest w piŋamie podczas strzelania, wydaje się byæ bardziej odpowiednia w większoķci ustawieņ innych niŋ, byæ moŋe, bajki. Liczby indeksujące kaŋdy termin gramatyczny w drzewach są prawdopodobieņstwami odpowiednich reguģ. Drzewo analizy po lewej stronie ma prawdopodobieņstwo
Prob lewy = 1: 0 x 0: 1 x 0: 7 x 1: 0 x 0: 4 x 0:18 x 1: 0 x 1: 0 0:18 = 0: 0009072:
Drzewo analizy po prawej stronie ma prawdopodobieņstwo
Prob prawy = 1: 0 x 0: 1 x 0: 3 x 0: 7 x 1: 0 x 0:18 x 1: 0 x 1: 0 x 0:18 = 0: 0006804:
Preferowany byģby zatem ten po lewej. (Cóŋ, nie chciaģbym mówiæ o strzelaniu do sģoni. Miaģem na myķli sģonie z kreskówek, które miaģy na sobie piŋamę.) Innym waŋnym aspektem PCFG jest to, ŋe moŋna je wykorzystaæ do przewidywania ogólnego prawdopodobieņstwa zdania. To znaczy, jak prawdopodobne jest zdanie: "John zastrzeliģ sģonie w piŋamie"? Moŋemy obliczyæ to prawdopodobieņstwo, po prostu dodając prawdopodobieņstwa wszystkich moŋliwych parów tego zdania. W tym przypadku dodajemy dwa prawdopodobieņstwa, aby uzyskaæ 0: 0015876. Prawdopodobieņstwa w tym przykģadzie zostaģy opracowane wyģącznie w celach ilustracyjnych i nie naleŋy ich traktowaæ powaŋnie. Bardziej realistyczne wartoķci prawdopodobieņstwa byģyby oparte na znacznie większej gramatyce i korpusie zdaņ, co prowadzi do następnego tematu.
C. Nauka PCFG
Jak uzyskaæ wartoķci prawdopodobieņstwa reguģ w PCFG? W szczególnoķci, w jaki sposób moŋna uzyskaæ wartoķci, które odpowiednio modelują rzeczywiste zdania? Bank drzew z adnotacjami zapewnia sposób uzyskania wartoķci odpowiednich dla zdaņ w banku drzew, poniewaŋ kaŋde z jego zdaņ ma powiązane drzewo analizy. Drzewa parsowania uŋywają reguģ w caģej formie l → r, gdzie l jest lewą stroną reguģy (np. VP), a r jest prawą stroną reguģy (np. VP NP). Aby uzyskaæ wartoķæ prawdopodobieņstwa dla reguģy l → r, zliczamy, ile razy ta sama reguģa występuje w banku drzew i dzielimy tę liczbę przez liczbę wystąpieņ l. Tak otrzymany PCFG moŋna następnie wykorzystaæ aby analizowaæ nowe zdania. PCFG moŋna równieŋ wygenerowaæ bez banku drzew, jeķli ma się zwykģy (nieprobabilistyczny) bez kontekstowy analizator skģadni, który moŋna zastosowaæ do zbioru zdaņ. Jednak w odróŋnieniu od banku drzew, kaŋde zdanie w korpusie będzie miaģo wiele parsów, a niektóre z nich zawierają wiele. Jak licząc występowanie reguģ, w jaki sposób moŋemy uniknąæ przewaŋania reguģ w tych zdaniach wieloma parsami? Oto metoda, która wydaje się dziaģaæ dobrze:
1. Przeksztaģæ oryginalny CGF w PCGF z jednakowymi prawdopodobieņstwami reguģ.
2. Analizuj zdania za pomocą tego PCFG, obliczając prawdopodobieņstwo dla kaŋdej niejednoznacznej analizy.
3. Policz reguģy w kaŋdym parsowaniu dla kaŋdego zdania i zwaŋ liczbę wedģug prawdopodobieņstwa tego parsowania.
4. Uŋyj tych waŋonych liczb do obliczenia nowych prawdopodobieņstw dla reguģ, a tym samym nowego PCFG.
5. Powtarzaj ten proces, aŋ prawdopodobieņstwo reguģy przestanie się zmieniaæ (co ostatecznie nastąpi).
Ta procedura jest wersją algorytmu często uŋywanego w uczeniu maszynowym, zwanym algorytmem Expectation Maximization (EM). Aby uwzględniæ bezkontekstowe aspekty struktury zdania i dla szczegóģowej informacji o konkretnych sģowach, praktyczne aplikacje zwykle wykorzystują PCFG, które zostaģy rozszerzone na róŋne sposoby. Opracowano kilka parserów dla wersji PCFG. Nie mogę się oprzeæ wspominaniu o jednym opartym na algorytmie wyszukiwania A*. Przedstawiając to, Dan Klein i Christopher D. Manning napisali :
"Ķrednio dģugie wyroki banku drzew Penn, nasze najbardziej szczegóģowe oszacowanie [do zastosowania jako funkcja heurystyczna] zmniejsza sumę liczb przetworzonych krawędzi [przy uŋyciu wyszukiwania A] do mniej niŋ 3% wymagane przez wyczerpujące parsowanie i prostsze oszacowanie, które wymaga mniej niŋ minutę wstępnego obliczenia, zmniejsza pracę do mniej niŋ 5%."
Opracowano kilka innych statystycznych metod analizy zdaņ. Wymienię tylko kilka z nich. Rens Bod i wspóģpracownicy z Uniwersytetu w Amsterdamie opracowali technikę, którą nazywają "analizą danych zorientowaną na dane" (DOP), która opiera się na idei, ŋe "percepcja i produkcja języka ludzkiego dziaģa raczej w oparciu o konkretne doķwiadczenia językowe niŋ abstrakcyjne reguģy gramatyczne ". Metody statystyczne poprawiģy takŋe gramatyczne funkcje leksykalne (LFG), zarówno przy uŋyciu pomysģów DOP, jak i dzięki pracy Josefa van Genabitha i jego grupy z Dublin City University nad nauką gramatyki LFG na podstawie adnotowanych danych banku drzew. Wreszcie Ron Kaplan i jego grupa w komercyjnej firmie zajmującej się wyszukiwaniem języków naturalnych, Powerset (obecnie częķæ firmy Microsoft), próbują nauczyæ się przypisywaæ porządki prawdopodobieņstwa do wielu drzew parsowania zdania, które są tworzone przez analizator skģadni ręcznie ( zamiast wyuczonej) gramatyki. Inne zastosowania statystyk w przetwarzaniu języka naturalnego obejmują wykorzystywanie danych o tym, jak często pewne kombinacje sģów występują w róŋnych žródģach tekstu. Takie kombinacje nazywane są "n-gramami". Na przykģad sekwencja dwóch sģów, na przykģad "wģaķnie teraz", to 2-gram, a sekwencja pięciu sģów, na przykģad "odģóŋ na póģkę", to 5-gram. Uŋywając hasģa "nie ma danych takich jak więcej danych" ,Google przeanalizowaģ na przykģad zbiór bilionów sģów z publicznych stron internetowych, aby opublikowaæ "liczby dla wszystkich 1 176 470 663 pięcioznakowych sekwencji, które pojawiają się co najmniej 40 razy".
Podsumowując wpģyw zastosowania metod statystycznych w NLP Manning i Schutze napisali: "Istotnie, większoķæ entuzjazmu w zakresie metod statystycznych w przetwarzaniu języka naturalnego wynika z tego, ŋe ludzie widzą perspektywę metod statystycznych zapewniających praktyczne rozwiązania rzeczywistych problemów, które wymykaģy się przy uŋyciu tradycyjne metody NLP ". Wspominają nawet o niektórych moŋliwych nowych nazwach dla eld, takich jak "Technologia językowa" lub "Inŋynieria językowa" zamiast NLP
Widzenie komputerowe
Omówim kilka reprezentatywnych próbek najnowszych prac w dziedzinie widzenia komputerowego, z których większoķæ opiera się na podstawowych technikach przetwarzania obrazu opisanych wczeķniej. W rzeczywistoķci ten dģug z poprzedniej pracy jest uznawany przez większoķæ badaczy, tak jak w następującym fragmencie ostatniego artykuģu: Warto zauwaŋyæ, ŋe wiele z tych, które są uwaŋane za nowoczesne pomysģy w widzeniu komputerowym - deskryptory regionu i granic, superpiksele, ģącząc dóģ-górę i odgórne przetwarzanie, formuģowanie bayesowskie, wybór funkcji itp. -byģy znane czteryy dekady temu! … Wydaje się jednak, ŋe pierwsi pionierzy po prostu wyprzedzili swój czas. Nie mieli wyboru, musieli polegaæ na heurystyce, poniewaŋ brakowaģo im duŋych iloķci danych i zasobów obliczeniowych, aby poznaæ relacje rządzące strukturą naszego ķwiata wizualnego. Postęp metod uczenia się w ostatnim dziesięcioleciu daje nową nadzieję na peģne zrozumienie scen. Teraz mamy potrzebne dane i zasoby obliczeniowe. Poza tym wizja komputerowa skorzystaģa na wkģadach kilku innych osób, w tym optyki, matematyki, grafiki komputerowej, elektrotechniki, fizyki, neuronauki i statystyki. Wszystkie te dyscypliny nadal dostarczają pomysģów i technik, ale jedna z nich zaczęģa dominowaæ, a mianowicie uczenie maszynowe. Niektóre osoby rozróŋniają "widzenie komputerowe" i "widzenie maszynowe" - ģącząc widzenie komputerowe gģównie z robotyką i wykorzystując widzenie maszynowe do wyģącznie tej aplikacji i wielu innych. Poniewaŋ ostatecznie chcemy, aby roboty byģy zaangaŋowane w większoķæ tych aplikacji, nie sądzę, aby to rozróŋnienie byģo bardzo przydatne, dlatego nadal będę odnosiæ się do caģego pola jako do widzenia komputerowego. Kolejne rozróŋnienie polega na tym, co z jednej strony nazywa się "wizją analizy sceny" i "wizją celową (lub aktywną)". Podejķcie oparte na analizie sceny kierowaģo wieloma badaniami dotyczącymi widzenia od najwczeķniejszych dni. Ten pogląd utrzymywaģ, ŋe celem widzenia komputerowego byģo przeksztaģcenie dwuwymiarowego obrazu w opis trójwymiarowej sceny. Na przykģad system wizyjny dla MIT "Copy Demo" skonstruowaģ trójwymiarowy model ukģadu klocków zabawek. Natomiast niektórzy badacze zwrócili uwagę, ŋe celem widzenia byģo dostarczenie tylko i wyģącznie tych konkretnych informacji potrzebnych do sterowania silnikiem. Widzimy to podejķcie zastosowane na przykģad w róŋnych procedurach widzenia uŋywanych przez Shakeya. Zamiast skonstruowaæ kompletny model swojego ķwiata wizualnego, Shakey uŋyģ widzenia, aby przekazaæ mu informacje potrzebne do prowadzenia dziaģaņ motorycznych i planowania. Ten rodzaj widzenia celowego "jest zwykle mniej wymagający od obliczeniowych wyników obliczeniowych, niŋ byģaby peģna analiza sceny. Ludzie, którzy badają wizualne procesy zwierząt (w tym ludzi), równieŋ spierali się o te dwa podejķcia. David Marr, który byģ zainteresowany modelowaniem czģowieka procesy wizualne opowiadaģy się za podejķciem do analizy sceny. Jednak ludzie, którzy analizowali percepcję wzrokową u ŋaby, zauwaŋyli, ŋe jej system wizualny zostaģ zorganizowany bardziej celowo, na przykģad w celu ģapania owadów. Neurobiolog komputerowy Terrence Sejnowski (ten sam Sejnowski, który pracowaģ nad NETtalk) i koledzy opisują dowody biologiczne i psychologiczne, ŋe wizja czģowieka jest celowa, a nie rekonstrukcyjna, a którą nazywają "czystym widzeniem". Do czego sģuŋy widzenie? Czy naprawdę konieczna jest idealna wewnętrzna rekreacja trójwymiarowego ķwiata? Biologiczne i obliczeniowe odpowiedzi na te pytania prowadzą do koncepcji widzenie zupeģnie inna niŋ czyste widzenie. Interaktywne widzenie, jak nakreķlono [w tym artykule], obejmuje widzenie z innymi ukģadami sensorycznymi jako partnerami pomagającymi w kierowaniu dziaģaniami. Kiedy patrzę na wiele komputerowych systemów wizyjnych wyprodukowanych w ciągu ostatnich dwudziestu lat, widzę oba rodzaje. Istnieją systemy, które są skuteczne w prowadzeniu pojazdów autonomicznych po drogach (zwracając uwagę tylko na jezdnię i inne pojazdy na drodze, nie analizując ani nawet nie wiedząc o domach po drodze, które - choæ mogą znajdowaæ się na miejscu - są nieistotne do zadania prowadzenia pojazdu. Istnieją równieŋ systemy analizujące zdjęcia lub konstruujące trójwymiarowe modele budynków i innych obiektów w nich zawartych. Ponadto istnieją systemy, które mają aspekty obu podejķæ
Odzyskiwanie informacji o powierzchni i gģębokoķci
Derek Hoiem, Alexei Efros i Martial Hebert z Robotics Institute na Carnegie Mellon University opracowali program, który byģ w stanie sklasyfikowaæ segmenty jednego obrazu jako naleŋące do powierzchni róŋnego typu i orientacji. Chociaŋ te klasyfikacje nie stanowią trójwymiarowego modelu sceny, która daģa początek obrazowi, dają one informacje o waŋnych wģaķciwoķciach fizycznych sceny, podobnie jak robi to szkic Davida Marra 2 1/2-D. Na przykģad takie informacje, które mogą byæ przydatne dla robota, który musi nawigowaæ i rozpoznawaæ obiekty w scenie. W ich pracy wykorzystano zdjęcia obiektów na wolnym powietrzu, takich jak "lasy, miasta, drogi, plaŋe, jeziora itp." wykonano w róŋnych warunkach "(ķnieŋny, sģoneczny, pochmurny, zmierzch)". Ich program podzieliģ regiony obrazu na jedną z trzech gģównych kategorii powierzchni: "wsparcie", "pionowe" lub "niebo". Jak autorzy okreķlają te kategorie: "Powierzchnie podparcia są w przybliŋeniu równolegģe do podģoŋa i mogą potencjalnie podpieraæ solidny obiekt. Przykģady obejmują nawierzchnie dróg, trawniki, ķcieŋki gruntu, jeziora i blaty stoģu. Powierzchnie pionowe są zbyt twardymi powierzchniami do wspierania obiektu, takiego jak ķciany, skaģy, krawęŋniki, ludzie, drzewa lub krowy. Niebo to po prostu obszar obrazu odpowiadający otwartemu powietrzu i chmurom." Aby uzasadniæ tę klasyfikację, autorzy podkreķlają, ŋe w 300 obrazach zebranych za pomocą wyszukiwania obrazów Google "ponad 97% pikseli naleŋy do poziomych (pomocniczych), prawie pionowych powierzchni lub nieba" (ustalonych przez czģowieka) obrazów). Program dodatkowo zaklasyfikowaģ kaŋdą pionową powierzchnię do jednej z następujących podklas: "pģaskie powierzchnie zwrócone w stronę" lewej "," ķrodkowej "lub" prawej " przeglądarki oraz powierzchnie niepģaskie, które są albo" porowate ", albo" staģe ". " Pģaskie powierzchnie obejmują ķciany budynków, ķciany klifu i inne powierzchnie pionowe, które są w przybliŋeniu pģaskie. Porowate powierzchnie to te, które nie mają staģej ciągģej powierzchni. Liķcie drzew, krzewy, przewody telefoniczne i ogrodzenia ogniw są przykģadami porowatych powierzchni. Powierzchnie peģne to niepģaskie powierzchnie pionowe, które mają staģą ciągģą powierzchnię, w tym samochody, ludzi, piģki plaŋowe i pnie drzew ".
Ich program nauczyģ się tworzyæ te klasyfikacje (i podklasy) za pomocą zestawu szkoleniowego zawierającego 300 obrazów Google. Grupy sąsiadujących pikseli na kaŋdym obrazie szkoleniowym w tym zestawie zostaģy zģoŋone w prawie jednolite regiony, zwane "superpikselami", na podstawie podobieņstwa kolorów i intensywnoķci. Następnie kaŋdemu superpikselowi (nuŋąco!) Ręcznie przypisywano klasyfikację i podklasę. Suprpiksele zostaģy następnie pogrupowane w większe regiony zwane segmentami, które odziedziczyģy po nich klasyfikacje skģadowe superpikseli. Odtąd matematyka staje się bardziej zģoŋona, ale w gruncie rzeczy proces uczenia się skonstruowaģ drzewo decyzyjne, które moŋe odpowiednio pasowaæ do ręcznie sklasyfikowanych regionów na obrazach zestawu treningowego. Wyuczone drzewo decyzyjne moŋna następnie wykorzystaæ do klasyfikacji regionów dowolnych obrazów. Węzģy drzewa decyzyjnego byģy oparte na cechach pikseli i segmentów obejmujących lokalizację, kolor, teksturę i perspektywę, z których wszystkie moŋna byģo obliczyæ przy uŋyciu wczeķniej wynalezionych technik. Chociaŋ nie są w peģni reprezentatywne dla ogólnych wyników, obrazy na ryc. 30.3 wskazują, jak dobrze ich program przetrwaģ. Na zdjęciach poniŋej, zielony oznacza powierzchnię podparcia, czerwony oznacza powierzchnię pionową, a niebieski oznacza niebo. Podklasy powierzchni pionowych są oznaczone strzaģkami w lewo dla pģaszczyzn skierowanych w lewo, strzaģkami w górę dla pģaszczyzn skierowanych do ķrodka i strzaģkami w prawo dla pģaszczyzn skierowanych w prawo, "O" dla powierzchni porowatych i "X" dla powierzchni staģych.

Profesor ze Stanford Andrew Ng i jego uczniowie poszli dalej w wyodrębnianiue rzeczywistych informacji o gģębokoķci i informacji o strukturze sceny z obrazów monokularowych. Informacje o gģębokoķci "prawdy gruntu" dla zestawu obrazów treningowych są najpierw gromadzone przez trójwymiarowy skaner laserowy. Algorytm uczenia się próbuje dopasowaæ swoje szacunki gģębokoķci do gģębokoķci rzeczywistej przy uŋyciu kilku funkcji obrazu, takich jak zmiany tekstury, gradienty tekstury, kolor i informacje o okluzji. Poniewaŋ informacje o gģębokoķci bliskich obiektów są rejestrowane w większych skalach niŋ w przypadku odlegģych obiektów, operacje są wyodrębniane w wielu skalach obrazu. Proces uczenia trenuje hierarchiczną, wieloskalową losową sieæ Markowa do reprezentowania zaleŋnoķci między gģębią ģatki obrazu a gģębią sąsiednich ģat. Rysunek poniŋej jest skróconą ilustracją dwóch z trzech poziomów takiej sieci.
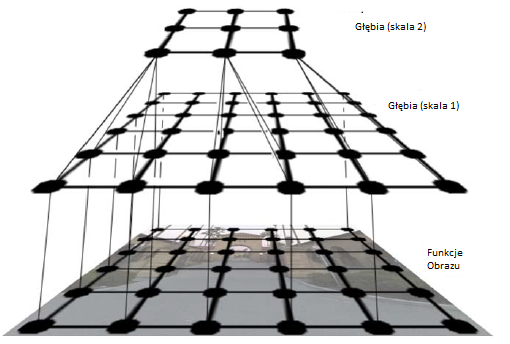
Rysunek poniŋej pokazuje niektóre obrazy pobrane z Internetu wraz z powiązanymi "mapami gģębi" (o róŋnych gģębokoķciach wskazanymi przez róŋne kolory) przewidywanymi przez ich system. Ashutosh Saxena i Andrew Ng nadal doskonalą te techniki.

Ķledzenie ruchomych obiektów
Jeķli systemy wizyjne mają dziaģaæ na naturalnych scenach w prawdziwym ķwiecie, jedną z rzeczy, z którymi będą musieli sobie poradziæ, są ruchome obiekty. Kilku badaczy pracowaģo nad problemem wizualnego ķledzenia obiektów, a niektóre z najwczeķniejszych prac pochodzą z koņca lat siedemdziesiątych. Jednym z przykģadów, które wykorzystam do wyjaķnienia niektórych zastosowanych metod, są prace Michaela Isarda i Andrew Blake′a na uniwersytecie w Oxfordzie. Opracowali algorytm o nazwie CONDENSATION (do propagacji gęstoķci warunkowej) do ķledzenia poruszających się obiektów. Algorytm jest w stanie "ķledziæ kontury i cechy obiektów pierwszego planu, zamodelowanych jako krzywe, gdy poruszają się w znacznym baģaganie, i wykonywaæ to z prędkoķcią klatek wideo lub w ich pobliŋu. Oto, w skrócie, jak ich system dziaģa na jednym z ich kilku przykģadów - filmie liķcia na krzaku wiejącym na wietrze na tle podobnych liķci. Rozpoczyna się od początkowej klatki filmu, w której dany liķæ interesujący jest rysowany ręcznie krzywa jak w lewej częķci rysunku

Ķledzenie konturu liķcia podczas ruchu wymaga wiedzy o dynamice liķcia. To znaczy, biorąc pod uwagę jego pozycję i ksztaģt na obrazie w jednym momencie, jaką pozycję i ksztaģt moŋe mieæ w następnym momencie? A w kolejnych chwilach? My nie jesteķmy pewni, ale moŋemy uŋyæ dynamicznych sieci bayesowskich (DBN), odpowiednio zmodyfikowanych w celu uŋycia ciągģych rozkģadów prawdopodobieņstwa zamiast rozkģadów prawdopodobieņstwa względem zmiennych dyskretnych, aby dokonaæ oszacowaņ. Wymagane prawdopodobieņstwa są szacowane na podstawie procesu uczenia się i są one stopniowo okreķlane przez obserwację liķcia podczas jego ruchu. Jednak, aby to zaobserwowaæ, musimy to wyķledziæ, a to wymaga znajomoķci prawdopodobieņstwa - problemu "jaja kurzego i jaja", z którym Isard i Blake byli w stanie sobie poradziæ. W miarę upģywu czasu prawdopodobieņstwo poģoŋenia i ksztaģtu liķcia na obrazie rozprasza się, powodując coraz większą niepewnoķæ co do konturu liķcia. Ale robimy obserwacje {przyjmując nowy obraz za kaŋdym razem. Obserwacje te, jako ŋe same w sobie są nieprecyzyjne, dostarczają równieŋ prawdopodobieņstwa (przy uŋyciu reguģy Bayesa) dotyczące poģoŋenia i ksztaģtu liķcia. Te ostatnie prawdopodobieņstwa pomagają wyostrzyæ di przy uŋyciu tych o dynamice liķcia {do tego stopnia, ŋe moŋna dokonaæ doķæ dokģadnych oszacowaņ. Na przykģad, w dwudziestu krokach póžniej (0: 5 s), system zgaduje na zarysie pokazanym po prawej stronie rysunku powyŋej. Isard i Blake uŋywają szeregu skomplikowanych technologii, aby to wszystko osiągnąæ. Jednym z problemów jest to, jak reprezentowaæ funkcje prawdopodobieņstwa dla dynamiki liķcia i jak przenosiæ tę reprezentację z jednego kroku czasowego na drugi. Przyjęli technikę zwaną "filtrowaniem cząstek", która reprezentuje prawdopodobieņstwo krzywej zarysu przez duŋy zestaw waŋonych próbek, zwanych cząsteczkami, konturów. Na kaŋdym etapie grupa cząstek jest przenoszona do następnego etapu, a caģa partia jest reprezentowana jako funkcja prawdopodobieņstwa. Filtrowanie cząstek jest intensywnie wykorzystywane do przetwarzania obrazu i innych problemów z percepcją. Uŋyģem pracy Isarda {Blake'a do zilustrowania ķledzenia obiektów, ale jest wiele innych projektów. Dieter Fox i wspóģpracownicy z University of Washington Robotics i State Estimation Lab uŋywali filtrowania cząstek w wielu zastosowaniach. Imponującą prezentacją jest film pokazujący jednoczesne ķledzenie zmieniającej się liczby osób za pomocą dalmierzy laserowych z ruchomym robotem. Typowy zrzut ekranu pokazano poniŋej

Zdjęcie po lewej stronie (nieuŋywane przez robota; jest tylko dla nas) pokazuje rzeczywiste poģoŋenie ludzi i robota. Zdjęcie po prawej pokazuje obliczone lokalizacje ludzi i robota, reprezentowane przez obiekty graficzne. Ta aplikacja wykorzystuje rozszerzenie do filtrowania cząstek, które autorzy nazywają "opartymi na próbach wspólnymi probabilistycznymi powiązaniami danych. Grupa kierowana przez Ernsta D. Dickmannsa w Institut fur Systemdynamik und Flugmechanik na Universit at der Bundeswehr w Monachium w Niemczech pracuje nad systemami wizyjnymi i sterującymi dla samochodów bez kierowców od póžnych lat siedemdziesiątych. Ich dynamiczne systemy wizyjne są w stanie wykrywaæ i ķledziæ sąsiednie pojazdy za pomocą przestrzenno-czasowych modeli ruchu wyrzutowego, co nazywają podejķciem "4-D". Byæ moŋe są pierwszą grupą, która korzysta z filtrowania Kalmana do ķledzenia obiektów wizualnych. ich praca zostaģa nazwana pierwszym znaczącym zastosowaniem wizji komputerowej w ķwiecie rzeczywistym ". Zainstalowane w róŋnych pojazdach Mercedes-Benz, ich systemy wizji i kontroli byģy w stanie jechaæ autonomicznie na duŋe odlegģoķci, zmieniając biegi i wyprzedzając wolniejsze pojazdy. W 1995 roku ich pojazd VaMP (Mercedes-Benz 500 SEL) przejechaģ 1758 km z Monachium do Odense w Danii i z powrotem z prędkoķcią przekraczającą 175 km / h. Okoģo 95% przejazdu odbyģo się w peģni autonomicznie, w sumie 400 manewrów zmiany pasa. Niektóre dodatkowe szczegóģy na temat ich autonomicznych pojazdów i projektów wizyjnych moŋna znaležæ w ksiąŋce Dickmanna na temat "Dynamic Vision". Kosmos nie pozwala na opisanie kilku innych projektów ķledzenia obiektów, ale wspomnę jeszcze o dwóch. Jitendra Malik kieruje grupą wizji na Uniwersytecie Kalifornijskim w Berkeley, gdzie przeprowadzono badania nad ķledzeniem obiektów (wraz z innymi pracami nad wizją) W grupie wizji na Uniwersytecie w Leeds w Wielkiej Brytanii prace nad ķledzeniem piģkarzy i samochodów. Innym celem w Leeds jest poprawa dokģadnoķci ķledzenia obiektów poprzez rozumowanie o "podstawowych ograniczeniach przestrzenno-czasowej ciągģoķci obiektów
Modele hierarchiczne
Jeden z potencjalnie najbardziej obiecujących rozwiązaņ w dziedzinie widzenia komputerowego (a moŋe nawet caģej sztucznej inteligencji) dotyczy modeli hierarchicznych. Istnieją róŋne wersje tych modeli i róŋne sposoby ich budowy, ale jeķli odstąpimy wystarczająco od szczegóģów, mają one podobne struktury i funkcje. Po pierwsze, nieprzetworzone piksele są agregowane przestrzennie (a w niektórych systemach czasowo), aby utworzyæ grupy wyŋszego poziomu. Te grupy mogą tworzyæ maģe krawędzie lub naroŋniki lub inne prymitywne komponenty odpowiednie dla rodzajów przetwarzanych obrazów. Na kolejnym poziomie hierarchii grupy pierwszego poziomu są ponownie agregowane do nieco wyŋszego poziomu i tak dalej, dopóki, powiedzmy, rozpoznawalne obiekty na obrazie nie będą reprezentowane na najwyŋszym poziomie. Wiele pomysģów uŋywanych w tych systemach nawiązuje do niektórych cech wczeķniejszych systemów (takich jak Pandemonium, Neocognitron, architektury tablic, systemy rozpoznawania mowy i sieci rekurencyjne PDP), ale wiele nowszych systemów ģączy i rozszerza te funkcje na róŋne sposoby to nie indywidualny wczeķniejszy system. W szczególnoķci pozwól mi wspomnieæ o następujących kwestiach:
1. Agregacje na róŋnych poziomach są poznawane przy uŋyciu ogromnych zestawów danych - nieprzeznaczonych ręcznie. W niektórych systemach uczenie się jest "bez nadzoru" {polegające na ciągģoķci wyglądu obiektu w czasowym strumieniu obrazów w celu dostarczenia informacji o toŋsamoķciach obiektów.
2. Występowania agregacji na kaŋdym poziomie są równowaŋone prawdopodobieņstwami za pomocą probabilistycznych modeli graficznych (takich jak pola losowe Markowa) zapewniających gģówne mechanizmy reprezentacyjne i obliczeniowe.
3. Prawdopodobieņstwa agregacji na jednym poziomie mogą wpģywaæ nie tylko na prawdopodobieņstwa agregacji na wyŋszych poziomach, ale takŋe na prawdopodobieņstwa agregacji na tym samym i na niŋszych poziomach. To znaczy, w przeciwieņstwie do Pandemonium i sieci neuronowych ze sprzęŋeniem zwrotnym, w tych nowszych systemach istnieją poģączenia "wsteczne" od wyŋszych poziomów do niŋszych poziomów. Te zacofane poģączenia pozwalają systemom przewidywaæ, co prawdopodobnie byģo na scenie, nawet jeķli mogģo byæ zasģonięte lub nieobecne na obrazie.
Kilku naukowców byģo zaangaŋowanych w rozwój modeli hierarchicznych. Niektóre motywowane są gģównie próbami modelowania mechanizmów przechowywania i wnioskowania w korze wzrokowej ludzi i naczelnych. Mimo to ich modele są jednak doķæ interesujące dla ludzi AI, ģącząc w tym czasie spostrzeŋenia i dowody z neuronauki z doķæ skomplikowanym aparatem obliczeniowym - w tym hierarchicznymi modelami graficznymi i technikami statystycznego próbkowania. Inni uŋywają modeli hierarchicznych i zaawansowanych metod obliczeniowych, nie zwracając szczególnej uwagi na ich biologię i wiarygodnoķæ budowy silniejszych systemów wizyjnych. Tai Sing Lee i Davida Mumford , proponuja hierarchię przetwarzania warstw kory wzrokowej , które moŋna modelowaæ jak poniŋej
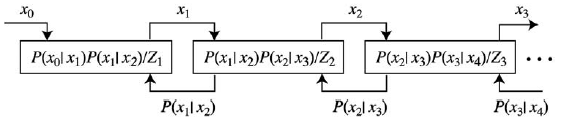
W modelu Lee-Mumforda (opartym częķciowo na teorii wzoru , pracy Ulfa Grenander), obserwacje "od doģu do góry" przychodzące z lewej strony są zintegrowane z hipotezami "z góry na dóģ" sformuģowanymi po prawej stronie. Na diagramie pomyķl o x0 jako reprezentującym reprezentację obrazu jako tablicę pikseli. Pomyķl o x1 jako bardziej abstrakcyjnej reprezentacji obrazu, powiedzmy w kategoriach funkcji takich jak krótkie segmenty linii. Gdy przechodzimy o jeden krok w prawo, obliczenia dają jeszcze bardziej abstrakcyjną reprezentację, x 2, która następnie sģuŋy jako hipoteza o x1. Wzory w ramkach (których nie będę tutaj próbowaģ wyjaķniæ) i ģączące je strzaģki mają na celu pokazanie, ŋe na kaŋdym poziomie prawdopodobieņstwo reprezentacji, x i, zaleŋy zarówno od na x i-1 (uwaŋany za wejķcie) oraz na x i + 1 (uwaŋany za hipotezę na temat xi). Lee i Mumford opisują ten proces sprzęŋenia zwrotnego {sprzęŋenie zwrotne w
następujący sposób: Wejķcie sprzęŋenia zwrotnego napędza generowanie hipotez, a sprzęŋenie zwrotne z wyŋszych obszarów wnioskowania zapewnia priorytetom ksztaģtowanie wnioskowania na wczeķniejszych poziomach. Ani komunikaty przekazujące, ani komunikaty zwrotne nie są statyczne: jak trwa interpretacja obrazu, nowe interpretacje wysokiego poziomu pojawiają się, które informują o nowych priorytetach, a gdy pojawi się interpretacja niskiego poziomu, komunikat przekazywania jest modyfikowany. Takie hierarchiczne wnioskowanie bayesowskie moŋe przebiegaæ równolegle w wielu obszarach … [z] kolejnymi obszarami korowymi w wizualnej hierarchii [ograniczającymi] wzajemne wnioskowanie w maģych pętlach szybko i stale w miarę ewolucji interpretacji. Moŋna mieæ nadzieję, ŋe taki system jako caģoķæ szybko zbiegnie się w spójną interpretację sceny wizualnej obejmującej wszystkie žródģa informacji niskiego i wysokiego poziomu; ale są problemy…Jednym z "problemów" jest to, ŋe poniewaŋ ŋaden z poziomów nie moŋe byæ
caģkowicie pewien swojej interpretacji, moŋe istnieæ wiele interpretacji globalnych o wysokim prawdopodobieņstwie. Lee i Mumford sugerują rozwiązanie oparte na innych trwających prac AI, a mianowicie "nie przeskakiwanie do wniosku" na ŋadnym poziomie, ale umoŋliwienie kilku interpretacjom o wysokim prawdopodobieņstwie "pozostania przy ŋyciu", dopóki jedna ogólna interpretacja dla caģego ģaņcucha nie okaŋe się najbardziej prawdopodobna. (Moŋesz sobie przypomnieæ, ŋe dwa systemy Barrowa i Tenenbauma, a mianowicie MSYS i tego, który korzystaģ z wewnętrznych obrazów, próbowaģ to zrobiæ juŋ w latach 70.). Aby zrealizowaæ swój pomysģ, Lee i Mumford sugerują zastosowanie filtrowania cząstek, które, jak juŋ wspomniaģem, wykorzystuje zestaw waŋonych próbek reprezentujących rozkģad prawdopodobieņstwa w odniesieniu do interpretacji na kaŋdym poziomie tego rozkģadu, których naleŋy nauczyæ się z doķwiadczenia, oraz wzory ģączące poziomy, system moŋe ustaliæ najbardziej prawdopodobną interpretację na kaŋdym poziomie.
Chociaŋ Lee i Mumford sugerują pomysģy wdroŋeniowe dla swoich obliczeņ prawdopodobieņstwa, takie jak uŋycie losowoķci Markowa starsi, nie wdroŋyli swojego modelu. Jak wyjaķniają, nie zaproponowaliķmy symulacji towarzyszącej naszej propozycji, częķciowo dlatego, ŋe naleŋy jeszcze opracowaæ wiele szczegóģów, a częķciowo dlatego, ŋe wybór modelu jest wciąŋ nieograniczony, a kaŋda konkretna symulacja zapewnia jedynie sģabe wsparcie dla wysokiego poziomu hipoteza taka jak nasza. Przytaczają jednak dowody neurofizjologiczne i psychofizyczne potwierdzające ich model. Korzystają z ilustracji na, aby wyjaķniæ, w jaki sposób modele podobne do nich mogą dziaģaæ w celu poprawy przetwarzania obrazów wizualnych.
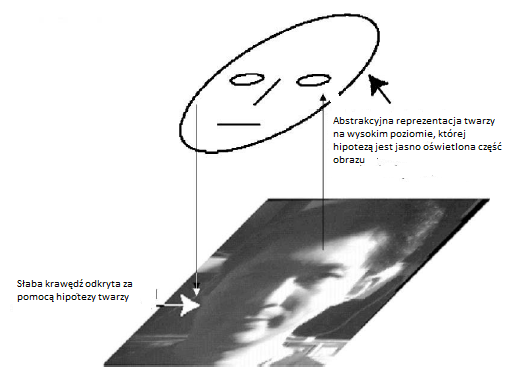
Jasno oķwietlona częķæ obrazu sugeruje, ŋe moŋe to byæ twarz. Ta hipoteza z kolei powoduje, ŋe przetwarzanie obrazu na niŋszym poziomie jest bardziej wraŋliwe na występowanie sģabej krawędzi twarzy {umoŋliwiając jej wykrycie. (Ludzie mogą powiedzieæ: "O tak, teraz widzę tę krawędž.")
Geoffey E. Hinton, Simon Osindero i Yee-Whye Teh opracowali (raczej zģoŋone) strategie uczenia się bez nadzoru dla innego hierarchicznego modelu zwanego siecią gģębokiej wiary. Przeprowadzili eksperymenty z wersją pokazaną poniŋej
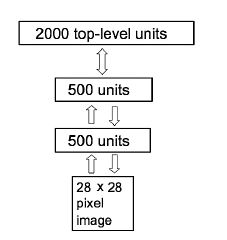
Ogólna struktura jest warstwową siecią neuronową, z najwyŋszym poziomem skģadającym się z 2000 jednostek, z dwukierunkowymi poģączeniami z jednostkami na poziomie poniŋej. Trening sieci przebiega od doģu krok po kroku, poziom po poziomie. Kiedy kaŋdy poziom jest trenowany, jego wagi są "zamroŋone", a jego wyniki są wykorzystywane jako dane wejķciowe do szkolenia następnego wyŋszego poziomu i tak dalej. Ta tak zwana chciwa metoda szkolenia skutkuje dobrym hierarchicznym modelem dystrybucji widzianych obrazów. Autorzy opisują równieŋ eksperymenty, w których dziesięæ jednostek decyzyjnych jest dodawanych na szczyt wczeķniej wyuczonej sieci hierarchicznej. Jednostki decyzyjne są następnie szkolone w zakresie rozróŋniania odręcznych cyfr, z których kaŋda ma postaæ obrazu 28 x 28 pikseli. Do szkolenia wykorzystano duŋą, standardową bazę cyfr, a drugą duŋą do testów. Wyniki przewyŋszyģy bardziej konwencjonalne techniki. Aby zobaczyæ, co "najwyŋszy poziom wyszkolonej pracy sieciowej" ma na myķli, "strzaģki skierowane w dóģ sģuŋą do generowania obrazów na dolnym poziomie na podstawie kodowania etykiet wprowadzonego na najwyŋszym poziomie. Trochę przykģadów tych wygenerowanych obrazów pokazano poniŋej
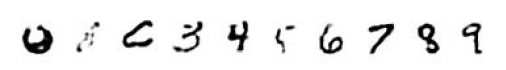
Jeff Hawkins (, projektant oryginalnego Palm Pilot, sugeruje, ŋe kora nowa jest hierarchiczną pamięcią czasową, której warstwy (od doģu do góry) przechowują coraz bardziej abstrakcyjne reprezentacje sensorycznych sekwencji wejķciowych i których funkcją (od góry do doģu) jest dokonywanie coraz bardziej szczegóģowych prognoz przyszģych doķwiadczeņ. Twierdzi, ŋe kora wzrokowa uczy się w sposób nienadzorowany, poddając się sekwencji obrazów w czasie. Poniewaŋ widzimy obrazy, które pojawiają się w sposób ciągģy w czasie, muszą istnieæ odcinki, w których kaŋdy obraz tego samego obiektu porusza się po naszym polu widzenia - choæ pojawia się w róŋnych tģumaczeniach, skalach i orientacjach. Ta identycznoķæ zapewnia ukryte oznaczenie, które jest wykorzystywane w reprezentacjach edukacyjnych na wszystkich poziomach hierarchii. Ponadto, jak twierdzi Hawkins, pamięæ hierarchiczna i jej procedury uczenia się są wykorzystywane nie tylko do wprowadzania wzrokowego, ale takŋe do innych modalnoķci sensorycznych. Na najwyŋszych poziomach hierarchii te osobne modalnoķci ģączą się, aby daæ zintegrowany model naszego ķwiata sensorycznego oparty na wzroku, dotyku i sģuchu - model, którego uŋywamy do przewidywania tego, co moŋe się dziaæ dalej. Na podstawie tych pomysģów on i Dileep George, doktorat z Stanford. opracowaģ model sieci, który nazywają "Hierarchiczną pamięcią czasową" (HTM). "W swojej rozprawie George zaimplementowaģ wersję tego modelu zilustrowaną jak tu:
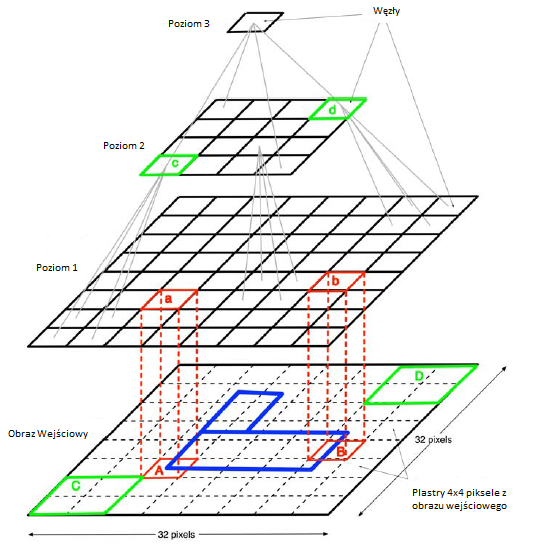
Dolny poziom to tablica pikseli 32 x 32, na której prezentowana jest sekwencja obrazów. Poziom 1 skģada się z tablicy 8 x 8 węzģów sieciowych, przy czym kaŋdy węzeģ odbiera dane wejķciowe z ģaty 4 x 4 pikseli obrazu wejķciowego. Na przykģad, węzeģ "a" odbiera dane wejķciowe ze swojego "pola odbiorczego", a mianowicie ģatka pikselowa oznaczona "A", a węzeģ "b" odbiera dane wejķciowe z pola pikselowego oznaczona "B." Poziom 2 to tablica 4 x 4 węzģów, przy czym kaŋdy węzeģ odbiera dane wejķciowe z zestawu 2 x 2 węzģów poziomu 1. Ten rodzaj konfiguracji trwa do pojedynczego węzģa na poziomie 3. Węzeģ ten ma rozpoznawaæ etykiety klas lub kategorie obrazów wejķciowych. Węzģy w kaŋdej warstwie są przeszkolone do rozpoznawania często występujących sekwencji w polu odbiorczym w warstwie poniŋej. Na przykģad węzeģ poziomu 1 oznaczony "a" na rysunku jest przeszkolony do przedstawiania prawdopodobieņstw często występujących sekwencji grup pikseli w swoim polu odbiorczym "A." Jedną z takich sekwencji o wysokim prawdopodobieņstwie mogą byæ na przykģad maģe rogi przesuwające się w prawo. Węzģy na poziomie 2 są z kolei wyszkolone do reprezentowania prawdopodobieņstwa często występujących sekwencji o wysokim prawdopodobieņstwie w ich polach odbiorczych na poziomie 1 i tak dalej. Szkolenie obejmuje prezentowanie filmów jako obrazów wejķciowych i przechodzi z poziomu na poziom wyŋej w hierarchii. Po treningu prawdopodobieņstwa sekwencji reprezentowanych na kaŋdym poziomie są uwarunkowane informacją zwrotną z góry. Na przykģad, jeķli prezentowany jest film, w którym niewielki róg przesuwa się od lewej do prawej w miejscu piksela oznaczonym "A", a jeķli taki maģy róg poruszaģ się w ten sposób często podczas treningu, to węzeģ "a"na poziomie 1 przewidziaģby, ŋe będzie kontynuowaģ swój ruch. Gdy podąŋamy w górę hierarchii poziomów, kaŋdy węzeģ odbiera dane wejķciowe, choæ poķrednio, z coraz większych segmentów obrazu. Wreszcie węzeģ na górze (poziom 3 na schemacie) reprezentuje rozkģad prawdopodobieņstwa między kategoriami obrazów, które widziaģa sieæ. Kiedy sieæ dziaģa w "trybie rozpoznawania" (po treningu) najwyŋszy węzeģ identyfikuje się najbardziej prawdopodobna kategoria obrazu na siatkówce. Sieæ byģa w stanie nauczyæ się rozpoznawaæ róŋne proste obrazy wykorzystywane przez George′a w pracy doktorskiej. George kontynuuje pracę w Numenta, firmie zaģoŋonej przez Hawkins w celu rozwoju tego rodzaju sieci. Chociaŋ modele opisane do tej pory zostaģy opracowane do zadaņ percepcyjnych, mogą, z pewnym dopracowaniem, sģuŋyæ jako podstawa ogólnych schematów architektonicznych dla inteligentnych agentów. (Patrz następny rozdziaģ.) Aby to zrobiæ, opracowania musiaģyby obejmowaæ między innymi postanowienia dotyczące planowania i wykonywania dziaģaņ zgodnie z ich istniejącymi przepisami dotyczącymi postrzegania. Oczywiķcie, jeķli te modele są w ogóle istotne dla tego, w jaki sposób kora nowa mogŋe dziaģaæ (jak twierdzą ich zwolennicy), wtedy będą musieli byæ w stanie zrobiæ więcej tego, co robi kora nowa, w tym planowaæ i wykonywaæ dziaģania. W kaŋdym razie badania modeli korowych stanowią drogę do wspóģpracy między badaczami AI i neuronaukami. Jak zauwaŋa Thomas Dean, który zbudowaģ probabilistyczne modele kory nowej: "Dostępnoķæ modeli w skali kory uģatwi nie tylko nasze rozumienie mózgu, ale umoŋliwi naukowcom poģączenie wniosków wyciągniętych z biologii z najnowszymi osiągnięciami techniki uczenia maszynowego do projektowania systemów hybrydowych, które ģączą najlepsze biologiczne i tradycyjne podejķcia komputerowe ". Kosmos nie pozwala mi opisaæ pracy kilku innych wybitnych badaczy wizji, którzy opracowali modele hierarchiczne, ale krótko wspomnę tylko o kilku innych. Tomaso Poggio i wspóģpracownicy z McGovern Institute for Brain Research na MIT stosują matematyczne i statystyczne mechanizmy uczenia się, aby pomóc modelowaæ, w jaki sposób mózg uczy się rozpoznawaæ obiekty wzrokowe. Jednym z obszarów ich zastosowania byģo rozpoznawanie twarzy. Yann LeCun z Computational and Biological Learning Laboratory w Courant Institute of Mathematical Sciences, New York University, bada to, co nazywa "gģębokimi architekturami", a mianowicie "zģoŋonymi z wielu warstw nadających się do szkolenia moduģów nieliniowych". Nacisk kģadziony jest na jego grupę to "modele oparte na energii" (EBM), które są modelami graficznymi, w których pojęcie związane z energią fizyczną jest powiązane ze zmiennymi (zamiast zwykģych prawdopodobieņstw)
Gramatyki obrazu
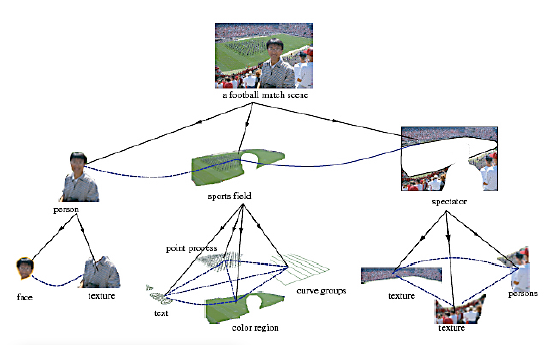
Ze względu na skuteczne wykorzystanie gramatyki i analiz skģadniowych w przetwarzaniu języka naturalnego nie jest zaskakujące, ŋe będą próby zastosowania podobnych pomysģów do przetwarzania zdjęæ i obrazów. W rzeczywistoķci, w wywiadzie cytowano Russella Kirscha, który powiedziaģ: "do 1957 roku zaintrygowaģo mnie to, co lingwiķci potrafili zrobiæ z gramatyką na komputerach… Więc zapytaģem, co wydaje mi się oczywistym pytaniem: czy mógģbyķ zrobiæ to samo ze zdjęciami? "Kirsch i jego ŋona Joan opracowali gramatykę do analizy (i tworzenia) zdjęæ. Wedģug wspomnianego wywiadu uŋywali gramatyki w programie komputerowym, który mógģ" tworzyæ linie i wzory w stylu [artysty Richarda Diebenkorna]. Kiedy go skoņczono, Kirsches pokazaģ wygenerowany obraz samemu artyķcie, który zgodziģ się, ŋe wygląda uderzająco podobnie do czegoķ, co mógģby namalowaæ. W rzeczywistoķci symulacja komputerowa byģa prawie identyczna do tego, który Diebenkorn juŋ namalowaģ. " Inne prace nad "gramatykami obrazkowymi" wykonaģ profesor Azriel Rosenfeld i jego grupa z University of Maryland". Song-Chun Zhu (1969 {), który kieruje UCLA Center for Image and Vision Science, zastosowaģ róŋnorodne techniki statystyczne i fizyki do problemów z widzeniem. On i koledzy opracowali "stochastyczną gramatykę obrazów", które moŋna wykorzystaæ do rozģoŋenia obrazów na częķci skģadowe. (Metoda dekompozycji realizuje niektóre z pomysģów opisanych w częķci 30.2.3 w pracy Lee i Mumforda). Rysunek poniŋej pokazuje przykģad dekompozycji obrazu, przedstawionego jako drzewo analizy.
Prace nad wizją komputerową poczyniģy niesamowity postęp w ciągu ostatnich kilku lat i są waŋną częķcią wielu aplikacji, w tym wykrywania zdarzeņ (takich jak wykroczenia drogowe), obrazowania medycznego, ķledzenia obiektów (takich jak twarze, piesi i pojazdy), protez wzrokowych , wyszukiwanie obiektów na fotografiach, kontrola zapasów w magazynach, nawigacja i mapowanie pojazdów robotów, rozpoznawanie znaków i pisma ręcznego, systemy ostrzegania przed niebezpieczeņstwem, kontrola procesu, kontrola pģytek drukowanych, klasyfikacja owoców i warzyw, mapowanie topograficzne, badania lasu, rozpoznawanie i identyfikacja twarzy w tģum, wyszukiwanie obrazów w Internecie, kompresja obrazów i kontrola upraw rolnych. Czytelnicy, którzy chcieliby dowiedzieæ się więcej, znajdą bogactwo materiaģów w podręcznikach, publikacjach z zakresu wizji komputerowej oraz w Internecie.