Machine Learning
Zautomatyzowane techniki gromadzenia danych wraz z niedrogim urządzeniem pamięci masowej umoŋliwiģy gromadzenie i przechowywanie olbrzymich iloķci danych. Zakupy w punktach sprzedaŋy, odczyty temperatury i ciķnienia (wraz z innymi danymi pogodowymi), wiadomoķci, transakcje finansowe wszelkiego rodzaju, strony internetowe i zapisy interakcji w sieci to tylko kilka z wielu przykģadów. Ale ogromna iloķæ surowych danych wymaga skutecznych technik "eksploracji danych" w celu klasyfikacji, kwantyfikacji i wyodrębniania przydatnych informacji. Metody uczenia maszynowego odgrywają coraz większą rolę w analizie danych, poniewaŋ mogą radziæ sobie z ogromnymi iloķciami danych. W rzeczywistoķci im więcej danych, tym lepiej. Większoķæ metod uczenia maszynowego konstruuje hipotezy na podstawie danych. Tak więc (na przykģad klasyczny przykģad), jeķli duŋy zestaw danych zawiera kilka wystąpieņ ģabędzi będących biaģymi i ŋadnych wystąpieņ ģabędzi innych kolorów, wówczas algorytm uczenia maszynowego moŋe wywnioskowaæ, ŋe "wszystkie ģabędzie są biaģe". Wnioskowanie jest "indukcyjne", a nie "dedukcyjne". Wnioski dedukcyjne wynikają koniecznie i logicznie z ich przesģanek, podczas gdy indukcyjne są hipotezami, które zawsze podlegają sfaģszowaniu przez dodatkowe dane. (Byæ moŋe nadal istnieje nieodkryta wyspa czarnych ģabędzi .) Mimo to wnioskowania indukcyjne, oparte na duŋej iloķci danych, są niezwykle przydatne. Rzeczywiķcie sama nauka opiera się na wnioskach indukcyjnych. Podczas gdy przed okoģo 1980 r. Uczenie maszynowe (reprezentowane gģównie przez metody sieci neuronowej) byģo przez niektórych uwaŋane za margines sztucznej inteligencji, uczenie maszynowe staģo się ostatnio znacznie waŋniejsze we wspóģczesnej sztucznej inteligencji. Opisaģem juŋ jeden przykģad, a mianowicie wykorzystanie sieci bayesowskich, które są automatycznie konstruowane z danych. Rozwój r, począwszy od lat 80. XX wieku, uczyniģ uczenie maszynowe jedną z najwaŋniejszych gaģęzi sztucznej inteligencji.
Uczenie się oparte na pamięci
Zwykģym podejķciem sztucznej inteligencji do radzenia sobie z duŋymi iloķciami danych jest w pewien sposób zmniejszenie ich iloķci. Na przykģad sieæ neuronowa jest w stanie reprezentowaæ to, co jest waŋne w duŋej iloķci danych treningowych, wedģug struktury sieci i wartoķci masy. Podobnie, uczenie się sieci bayesowskiej na podstawie danych powoduje kondensację tych danych w strukturze węzģa sieci i jej tabelach prawdopodobieņstwa warunkowego. Jednak nasze rosnące moŋliwoķci przechowywania duŋych iloķci danych w pamięci komputera o szybkim dostępie i obliczania tych danych umoŋliwiģy techniki, które przechowują i wykorzystują wszystkie dane w razie potrzeby - bez wczeķniejszej kondensacji. Oznacza to, ŋe te techniki nie próbują zmniejszyæ iloķci danych, zanim zostaną one faktycznie wykorzystane do jakiegoķ zadania. Wszystkie niezbędne redukcje, na przykģad decyzji, są wykonywane w momencie podjęcia decyzji. W dalszej częķci opiszę niektóre z tych metod uczenia się opartych na pamięci. Wspomniaģem juŋ o metodach "najbliŋszego sąsiada" do klasyfikacji punktu w przestrzeni wielowymiarowej. Na przykģad "reguģa k-najbliŋszego sąsiada" przypisuje punkt danych do tej samej kategorii, co większoķæ k przechowywane punkty danych, które są najbliŋej. Podobną technikę moŋna zastosowaæ do powiązania wartoķci liczbowej (lub zestawu wartoķci) z punktem danych. Na przykģad moŋna przypisaæ ķrednią z przechowywanych wartoķci powiązanych z najbliŋszymi sąsiadami nowy punkt. Ta wersja reguģy moŋe byæ uŋywana w aplikacjach kontrolnych lub szacunkowych. Reguģa k-najbliŋszego sąsiada jest prototypowym przykģadem uczenia się opartego na pamięci i wywoģuje kilka pytaņ na temat moŋliwych rozszerzeņ. Po pierwsze, zastosowaæ najbliŋsze- reguģa sąsiada (jak to juŋ przedstawiģem), kaŋdy punkt odniesienia musi byæ listą liczb {punkt lub wektor w przestrzeni wielowymiarowej. o, jedno pytanie brzmi: "Jak przedstawiæ dane tak, aby coķ w rodzaju metody najbliŋszego sąsiada moŋna zastosowaæ? "Po drugie, co to jest "odlegģoķæ" do zmierzenia między punktami danych? Gdy dane są reprezentowane przez punkty w przestrzeni wielowymiarowej, naturalnym wyborem jest zwykģa odlegģoķæ euklidesowa. Jednak nawet w takim przypadku zwykle "przeskalowuje się" wymiary, aby nie przypisywaæ nadmiernej wagi tym wymiarom, dla których dane są bardziej "rozģoŋone". Jeķli dane nie są reprezentowane jako punkty w przestrzeni, naleŋy zastosowaæ inny sposób pomiaru "bliskoķci" danych. W zaleŋnoķci od formy danych zaproponowano kilka metod. Po trzecie, czy wķród najbliŋszych punktów danych bliŋsze wyniki powinny byæ lepsze niŋ odlegģe? Podstawową metodę k-najbliŋszego sąsiada moŋna rozszerzyæ, waŋąc waŋnoķæ punktów danych w sposób zaleŋny od ich bliskoķci. Zwykle uŋywa się czegoķ zwanego "jądrem", które stopniowo zmniejsza wagę punktów danych, które są coraz dalej. Po czwarte, jaka powinna byæ wartoķæ k? Ilu pobliskich sąsiadów wykorzystamy, podejmując decyzję w sprawie nowej częķci danych? Cóŋ, przy odpowiednim rodzaju jądra moŋna wziąæ pod uwagę wszystkie punkty danych. Te, które są najdalej, po prostu miaģyby zerowy lub nieistotny wpģyw na decyzję. Pytanie o to, jaką wartoķæ k do uŋycia zastępuje się teraz pytaniem o to, jak daleko powinien rozciągaæ się wpģyw jądra. Wreszcie, po uwzględnieniu wszystkich waŋonych sąsiadów, w jaki sposób podejmujemy decyzję lub przypisujemy wartoķæ liczbową lub wartoķci? Powinno to byæ w taki sam jak ten związany z większoķcią gģosów sąsiadów, a moŋe z jakąķ "ķrednią" waŋonych sąsiadów? W zaleŋnoķci od tego wyboru moŋna zaimplementowaæ róŋne wersje tak zwanych metod regresji statystycznej. Andrew W. Moore i Christopher G. Atkeson (są jednymi z pionierów w opracowywaniu rozszerzeņ zasad k-najbliŋszych sąsiadów i zastosowaniu tych rozszerzeņ do kilku waŋnych problemów w eksploracji danych i kontroli robota. Eksperymenty w stosowaniu tych pomysģów do kontrolowania problemów opisano w kilku artykuģach. Jeden artykuģ2 wspomina o sterowaniu robotycznym urządzeniem do gry w ŋonglerkę zwaną "trzymaniem diabģa". Opracowano system oparty na pamięci, aby nauczyæ się, jak trzymaæ kij w grze. Rysunek poniŋej pokazuje schemat ŋonglowania czģowiekia
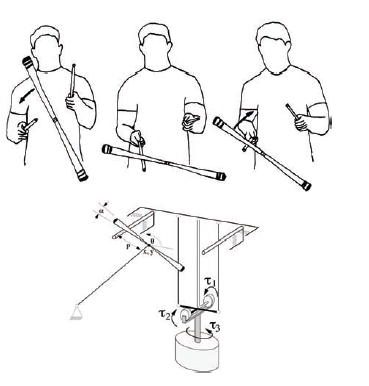
Przedstawiono równieŋ konfigurację robotów z niektórymi parametrami sensorycznymi i kontrolnymi.
Rozumowanie na podstawie przypadków
Dziedzinę sztucznej inteligencji, zwaną "rozumowaniem opartym na analizie przypadków" (CBR), moŋna postrzegaæ jako uogólniony rodzaj uczenia się opartego na pamięci. W CBR przechowywana biblioteka "spraw" sģuŋy do analizy, interpretacji i rozwiązywania nowych spraw. Na przykģad w medycynie zapisy diagnostyczne i terapeutyczne dla pacjentów stanowią bibliotekę przypadków; po przedstawieniu nowego przypadku podobne przypadki moŋna pobraæ z biblioteki, aby pomóc w diagnozowaniu i leczeniu. W prawie wczeķniejsze precedensy prawne są stosowane w interpretacjach i decyzjach dotyczących nowych spraw (zgodnie z praktyką prawną stare decisis, która nakazuje rozstrzyganie spraw w oparciu o precedensy okreķlone w poprzednich sprawach). Przypadki podobne do nowego przypadku moŋna traktowaæ jako "sąsiadów" w uogólnionej "przestrzeni" przypadków. Aby odzyskaæ bliskich sąsiadów, idea bliskoķci w tej przestrzeni musi opieraæ się na pewnej mierze podobieņstwa. Jedna z pionierów wnioskowania na podstawie przypadków, Janet Kolodner, profesor informatyki i kognitywistyki w Georgia Institute of Technology opisuje proces w następujący sposób: Dobrymi przypadkami [do pobrania] są te, które mogą potencjalnie poczyniæ odpowiednie prognozy dotyczące nowego przypadku. Pobieranie odbywa się za pomocą funkcji nowej sprawy jako indeksów w bibliotece spraw. Przypadki oznaczone przez podzbiory tych funkcji lub przez funkcje, które moŋna uzyskaæ z tych funkcji, są przywoģywane. [Następnie wybieramy spoķród tych] najbardziej obiecującą sprawę lub sprawy do uzasadnienia…Czasami wģaķciwe jest wybranie jednego najlepszego przypadku; czasami potrzebny jest maģy zestaw. Gdy odzyskana sprawa (lub sprawy) jest przystosowana do zastosowania do nowej sprawy, moŋe następnie (jeķli się powiedzie) zostaæ zmieniona, tak aby częķci, które mogą byæ przydatne do rozwiązywania problemów w przyszģoķci, mogģy zostaæ zachowane w stale rosnącej bibliotece spraw. Rozumowanie na podstawie przypadków ma swoje korzenie w modelu pamięci dynamicznej Rogera Schanka. Wczesna praca zostaģa wykonana przez dwóch doktorantów Schanka, Janet Kolodner i Michaela Lebowitza. Innym waŋnym žródģem pomysģów na CBR są pomysģy Minsky′ego na temat ram. Edwina Rissland, profesor na University of Massachusetts w Amherst i inny pionier CBR, pisze, ŋe jej praca CBR jest bezpoķrednim rozwinięciem jej "pracy nad" ograniczonym generowaniem przykģadów " … która modelowaģa budowę nowych (kontr) przykģadów poprzez modyfikację istniejących wczeķniejszych "bliskich" przykģadów (przedstawionych jako ramek) pobranych z sieci przykģadów. "Rissland i jej uczniowie wnieķli istotny wkģad w stosowanie CBR w prawie. Napisaģa, ŋe proces CBR jest czasami podsumowywany przez cztery" R ", Retrieve, Reuse, Revise, i Retain. Wedģug strony internetowej prowadzonej przez Artficial Intelligence Applications Institute na University of Edinburgh, "Case-based Reasoning jest jedną z najbardziej udanych stosowanych technologii sztucznej inteligencji w ostatnich latach. Aplikacje komercyjne i przemysģowe moŋna szybko opracowywaæ, a istniejące bazy danych korporacyjnych mogą byæ wykorzystywane jako žródģa wiedzy. Najpopularniejsze aplikacje to centra informacyjne i systemy diagnostyczne. "
Drzewa decyzyjne
Następny na liķcie nowych osiągnięæ w uczeniu maszynowym jest automatyczna konstrukcja struktur zwanych "drzewami decyzyjnymi" z duŋych baz danych. Drzewa decyzyjne skģadają się z sekwencji testów sģuŋących do okreķlenia kategorii lub wartoķci liczbowej do przypisania do rekordu danych. Drzewa decyzyjne są szczególnie odpowiednie do uŋycia z danymi nienumerycznymi i numerycznymi. Na przykģad baza danych personelu moŋe zawieraæ informacje na temat dziaģu pracownika, na przykģad marketingu, produkcji lub księgowoķci. W języku bazy danych takie elementy danych nazywane są "kategorialnymi" (w celu odróŋnienia ich od danych liczbowych). W tej sekcji opiszę te struktury, ucząc się metody ich automatycznego konstruowania oraz niektóre z ich aplikacji.
Wyszukiwanie danych i drzewa decyzyjne
Eksploracja danych to proces uzyskiwania przydatnych informacji z duŋych baz danych. Rozwaŋmy na przykģad bazę danych na temat zachowania kart kredytowych przez ludzi. Moŋe to obejmowaæ zapisy pģatnoķci, ķrednie kwoty zakupu, opģaty za opóžnienie, ķrednie salda i tak dalej. Odpowiednie metody eksploracji danych mogą ujawniæ, między innymi, ŋe ludzie z wysokimi opģatami za póžne opģaty, wysokimi ķrednimi zakupami i innymi zidentyfikowanymi cechami zwykle wykazywali wysokie ķrednie salda. Jedna waŋna metoda eksploracji danych wykorzystuje dane do konstruowania drzew decyzyjnych. Rozwaŋmy bardzo prostą bazę danych, aby zilustrowaæ dziaģanie drzew decyzyjnych. Zaģóŋmy, ŋe firma, powiedzmy Wal-Mart, utrzymuje bazę danych, w której przechowuje informacje o gospodarstwach domowych, do których wczeķniej wysģaģ kupony rabatowe na niektóre swoje produkty. Zaģóŋmy, ŋe baza danych zawiera informacje o lokalizacji gospodarstwa domowego (miejskiego, podmiejskiego lub wiejskiego), rodzaju domu (ranczo lub wielopiętrowy), niezaleŋnie od tego, czy gospodarstwo domowe jest poprzednim klientem Wal-Mart, oraz czy gospodarstwo domowe jest, czy nie odpowiedziaģ na którykolwiek z poprzednich mailingów z kuponami. (Oczywiķcie jest to tylko zmyķlony przykģad; wģaķciwie nie wiem nic o prawdziwych bazach Wal-Mart.) Tabelaryczna reprezentacja takiej bazy danych wyglądaģaby tak:

Kaŋdy wiersz w tabeli nazywany jest "rekordem". Przedmioty na górze kaŋdej kolumny nazywa się "atrybuty ", a elementy w kolumnie nazywane są" wartoķciami "odpowiedniego atrybutu. Analiza tej bazy danych, metodami, które wyjaķnię póžniej, moŋe ujawniæ, ŋe drzewo decyzyjne pokazane poniŋej przechwytuje informacje o tym, które gospodarstwa domowe odpowiedziaģy na wysyģkę kuponu, a które nie.
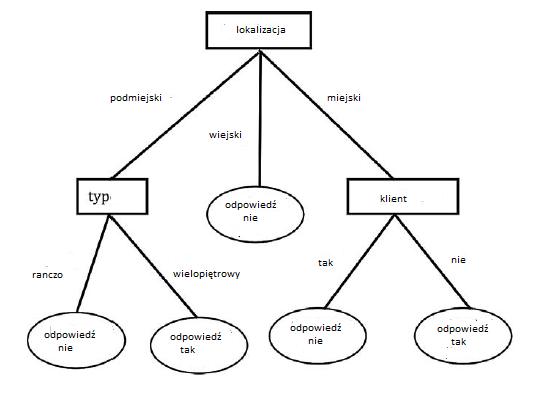
Testy wartoķci atrybutów przeprowadzane są w wewnętrznych węzģach drzewa (w polach), a wyniki (niezaleŋnie od tego, czy pojawiģa się odpowiedž) znajdują się na koņcach (lub liķciach) drzewa (w owalach). Takie drzewo moŋe byæ przydatne do prognozowania oczekiwanych odpowiedzi przed wysģaniem kolejnej wiadomoķci. Opracowano metody automatycznego konstruowania (czyli uczenia się) drzew decyzyjnych takich jak ten (i znacznie większe) automatycznie z duŋych baz danych.
Konstruowanie drzew decyzyjnych
A. EPAM
Prawdopodobnie najwczeķniejszy system do konstruowania drzew decyzyjnych zostaģ opracowany pod koniec lat 50. XX wieku przez Edwarda Feigenbauma w ramach jego pracy doktorskiej. Rozprawa pod kierunkiem Herberta Simona z Carnegie Mellon University (wówczas Carnegie Institute of Technology). Jego system nazywaģ się EPAM, skrót od Elementary Perceiver and Memorizer. Celem badaņ byģo "wyjaķnienie i przewidzenie zjawiska [ludzkiego] uczenia się werbalnego". Standardowy eksperyment psychologiczny do testowania tej umiejętnoķci polegaģ na pokazaniu ludziom par nonsensownych sylab, takich jak DAX-JIR i PIB-JUX. Pierwszy czģonek pary byģ nazywany "bodžcem", a drugi "odpowiedzią". Po kilkakrotnym zobaczeniu wielu takich par, pacjentowi następnie pokazuje się losowy bodziec i testuje jego zdolnoķæ do generowania prawidģowej odpowiedzi. Pary takie pokazano EPAM podczas "fazy uczenia się". Uczenie się polegaģo na rozwijaniu czegoķ, co Feigenbaum nazwaģ "siecią dyskryminacyjną" do przechowywania związków między bodžcami i
reakcjami. Sieæ byģa tym, co teraz nazwalibyķmy drzewem decyzyjnym z testami cech liter w wewnętrznych węzģach i odpowiedziami przechowywanymi na koņcach lub liķciach drzewa. W "fazie testowania" programu EPAM sylaba bodžca bezsensownego zostaģa przefiltrowana przez testy w dóģ drzewa, aŋ do liķcia, w którym (ma się nadzieję) zachowano prawidģową odpowiedž. Przykģadową sieæ dyskryminacyjną EPAM pokazano poniŋej
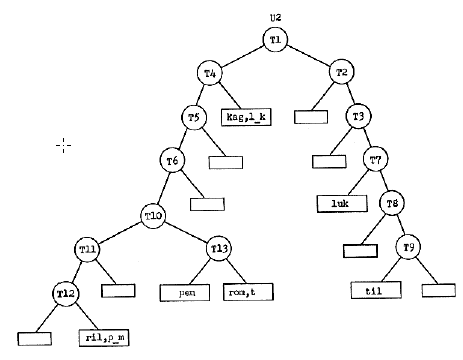
Okrągģe węzģy to testy, a węzģy w ramkach to odpowiedzi. EPAM nie tylko skutecznie modelowaģ w tym zakresie wydajnoķæ ludzi w zadaniu uczenia się "w parze z partnerem", modelowaģo równieŋ zapominanie. Feigenbaum stwierdziģ, ŋe "o ile wiemy, [EPAM] jest pierwszą konkretną demonstracją tego rodzaju zapominania w maszynie uczącej się". EPAM zostaģ napisany w języku przetwarzania list Carnegie, IPL-V. W rzeczywistoķci funkcje przetwarzania list języków, takich jak IPL-V, byģy wymagane do pisania programów, które mogģyby rozwijaæ drzewa decyzyjne. Nic więc dziwnego, ŋe EPAM byģ pierwszym takim programem. Program Feigenbauma jest nadal uwaŋany za istotny wkģad zarówno w teorie ludzkiej inteligencji, jak i badania AI. Simon, Feigenbaum i inni kontynuowali prace nad programami EPAM, których zwieņczeniem byģ EPAM-VI, kodowany w IPL-V i dziaģający na PC.
B. CLS
Kolejną znaczącą pracę nad drzewami decyzyjnymi wykonano na Uniwersytecie Yale okoģo 1960 roku. Tam psycholog Carl I. Hovland i jego doktorat. uczeņ Earl B. (Buz) Hunt opracowaģ komputerowy model uczenia się koncepcji czģowieka. Po tym, jak Hovland zapadģ na raka w 1961 roku, Hunt kontynuowaģ pracę nad koncepcją uczenia się i wspóģpracowaģ z Janet Marin i Philipem Stone′em przy opracowywaniu serii programów edukacyjnych opartych na drzewie decyzyjnym o nazwie CLS, akronim od Concept Learning System. Hunt i jego koledzy potwierdzili powiązaną wczeķniejszą pracę nad EPAM. Przynajmniej dla celów AI systemy CLS wkrótce zostaģy przyæmione przez inne systemy uczenia się na drzewach decyzyjnych, a mianowicie ID3, CART i powiązane programy.
C. ID3
J. Ross Quinlan opracowaģ ID3, akronim dla iteracyjnego dychotomizera, pod koniec lat siedemdziesiątych, kiedy byģ na urlopie naukowym (z University of Sydney) w Stanford. (Nazwa pochodzi od faktu, ŋe program konstruowaģ drzewa decyzyjne przez iteracyjne dzielenie zestawów rekordów danych, aŋ moŋna je byģo sklasyfikowaæ w jednej z dwóch odrębnych kategorii. Póžniejsze wersje pozwoliģy na klasyfikację w więcej niŋ dwóch kategoriach, ale "D" utrzymywaģo się w nazwie.) Quinlan byģ wczeķniej doktorem (pierwszym wģaķciwie) na Wydziale Informatyki Uniwersytetu Waszyngtoņskiego, pracujący w Earl Hunt. Quinlan wyjaķniģ genezę ID3 w e-mailu:
"Usiadģem na kursie podanym przez Donalda Michie [odwiedzającego wówczas Stanforda] i zaintrygowaģo mnie zaproponowane przez niego zadanie, a mianowicie poznanie zasady decydowania o wyniku prostej gry w szachy. ID3 zaczęģo się od przekodowania CLS Buz [czyli Earla B. Hunta], ale zmieniģem niektóre wewnętrzne elementy (takie jak kryterium podziaģu zestawu przypadków) i wģączyģem iteracyjne podejķcie, które pozwoliģo ID3 na obsģugę wtedy - ogromny zestaw 29 000 skrzynek treningowych."
Oto, w skrócie, jak ID3 przystąpiģoby do budowy drzewa decyzyjnego do przewidywania wartoķci atrybutu odpowiedzi przy uŋyciu mojej rozbudowanej bazy danych Wal-Mart. Po pierwsze, ID3 szukaģby tego pojedynczego atrybutu, który mógģby byæ uŋyty jako "najlepszy" test przy rozróŋnianiu tych rekordów danych o wartoķci "tak" dla atrybutu odpowiedzi od tych o wartoķci "nie". (Będę miaģ więcej do powiedzenia na temat tego, jak na chwilę okreķla się "najlepsze"). Ŋaden pojedynczy test nie dzieli danych idealnie, ale zaģóŋmy, ŋe lokalizacja dziaģa lepiej niŋ inne. W koņcu w tym przykģadzie wszystkie rekordy danych o wartoķci wiejskiej dla atrybutu lokalizacji ma wartoķæ "tak" dla atrybutu odpowiedzi, a ŋaden z nich nie ma wartoķci "nie". Zaģóŋmy, ŋe przewaga (ale nie wszystkie) rekordów danych o wartoķci podmiejskiej ma wartoķæ tak dla atrybutu odpowiedzi i ŋe przewaga (ale znowu nie wszystkie) rekordów danych o wartoķci miejski ma wartoķæ nie dla atrybut odpowiedzi. Tak więc atrybut poģoŋenia ma caģkiem dobre (ale niedoskonaģe) zadanie polegające na rozdzielaniu rekordów danych w odniesieniu do atrybutu odpowiedzi. Test wartoķci atrybutu lokalizacji zostaģby zatem uŋyty jako pierwszy test w drzewie decyzyjnym . Do tej pory podzielilibyķmy bazę danych na trzy podzbiory, z których dwa mają rekordy danych o mieszanych wartoķciach atrybutu odpowiedzi. Następnie ID3 zastosowaģby tę samą technikę podziaģu do kaŋdego z tych dwóch podzbiorów o mieszanej wartoķci, szukając dla kaŋdego z nich najlepszej następnej funkcji do uŋycia jako testu. W tym prostym i raczej nierealistycznym przykģadzie dwa testy, które zostaģyby zastosowane, a mianowicie typ i klient, zapewniģyby "czyste" podziaģy (to znaczy te, które nie mają mieszanych wartoķci), a skoņczylibyķmy juŋ drzewem decyzyjnym pokazanym powyŋej. Gdyby podziaģy nie byģy czyste lub w inny sposób nie do zaakceptowania, ID3 kontynuowaģby wybieranie testów na wynikowych podzbiorach baz danych, dopóki podziaģy nie dadzą czystych lub akceptowalnych wyników. Wybór atrybutu do przetestowania jest kluczowy w tworzeniu uŋytecznych drzew decyzyjnych. W swoim oryginalnym programie ID3 Quinlan zastosowaģ miarę związaną z "dokģadnoķcią" wynikającego z tego podziaģu przy okreķlaniu, którego atrybutu uŋyæ do testowania. W póžniejszych pracach uŋyģ miary zwanej "zdobywaniem informacji", której dokģadnej definicji nie będę tu wchodziģ, poza stwierdzeniem, ŋe jest to ten atrybut, którego wartoķci przekazują najwięcej 'informacji"o poszukiwanej kategoryzacji. Quinlan uŋyģ definicji Claude′a Shannona do mierzenia iloķci informacji. Jeszcze póžniej uŋyģ znormalizowanej miary zdobywania informacji, aby nie odchylaæ się na korzyķæ testów z wieloma wynikami. Zainteresowanie maszyną symboliczną Quinlana i innych byģa ukierunkowana gģównie na uczenie się tego rodzaju reguģ na podstawie danych. Z drzewa decyzyjnego ģatwo jest konstruowaæ reguģy, ķledząc testy w celu wygenerowania częķci "IF" i wykorzystując wskazówki zawarte w częķci "THEN". Na przykģad w przykģadzie bazy danych Wal-Mart moŋemy wywnioskowaæ następujące reguģy z drzewa decyzyjnego:
IF (location = suburban) and (type = ranch), THEN (response = no)
IF (location = suburban) and (type = multi-story), THEN (response = yes)
IF (location = rural), THEN (response = yes)
IF (location = urban) and (customer = yes), THEN (response = no)
IF (location = urban) and (customer = no), THEN (response = yes)
W pracy Quinlana w Stanford, ID3 byģ w stanie wygenerowaæ doķæ duŋe drzewa decyzyjne, a tym samym zestawy reguģ, do przewidywania, czy pewne pozycje w szachach koņcowych zakoņczą się stratą dla czarnych. W przypadku problemu tego typu zasugerowanego przez Donalda Michie, ID3 uŋyģ dwudziestu atrybutów (obejmujących cechy pozycji kawaģków na planszy) i bazy danych 29 236 róŋnych uģoŋenia kawaģków, aby zbudowaæ drzewo z 393 węzģami, których przewidywania byģy prawidģowe 99,74% . Jednym z problemów, którego naleŋy unikaæ przy konstruowaniu drzew decyzyjnych, jest "przesadzanie", to znaczy wybieranie testów na podstawie tak maģej iloķci danych, ŋe wyniki testów nie wychwytują znaczących relacji w danych jako caģoķci. Bez względu na to, jak duŋa jest oryginalna baza danych, jeķli seria testów ostatecznie wytworzy podzbiór, który nadal nie jest czysty, ale zostaģ zredukowany do zbyt maģej liczby rekordów danych, kaŋda próba podzielenia tego podzbioru przekroczyģaby te dane, a zatem nie byģaby przydatna. Z tego powodu techniki uczenia się drzewa decyzyjnego zazwyczaj zatrzymują budowę drzewa tuŋ przed podzbiorami danych, które miaģyby zbyt maģo rekordów, ale nadal dawaģyby akceptowalne wyniki.
D. C4.5, CART i następcy
Quinlan kontynuowaģ pracę nad systemami do konstruowania drzew decyzyjnych, poprawiając ich moc i moŋliwoķci zastosowania. Powiedziaģ, ŋe "ID3 jest doķæ prosty - okoģo 600 linii PASCAL".Jego system C4.5 (który miaģ okoģo 9 000 linii C) mógģ pracowaæ z bazami danych, których atrybuty miaģy ciągģe wartoķci liczbowe oprócz tych kategorycznych. Mógģ nawet radzą sobie z bazami danych, w których niektórych rekordach brakowaģo wartoķci niektórych atrybutów. Na koniec dysponowano metodami poprawy ogólnej wydajnoķci poprzez przycinanie niektórych częķci drzewa i dla uproszczenia reguģy IF-THEN wywodzące się z drzew. Firma komercyjna Quinlana, zaģoŋona w 1983 roku, sprzedaje ulepszoną wersję C4.5 o nazwie C5.0 (wraz z wersją Windows o nazwie See5) . Donald Michie zaģoŋyģ równieŋ firmę, która niezaleŋnie opracowaģa komercyjną wersję ID3 o nazwie ACLS. Jednym ze znaczących postępów w uczeniu maszynowym w tym okresie byģa owocna wspóģpraca między ludžmi sztucznej inteligencji a statystykami, którzy prowadzili fundamentalne, a takŋe badania stosowane w zakresie klasyfikacji, szacowania i prognozowania. Kaŋda grupa uczyģa się od drugiej, a uczenie maszynowe jest dla niej znacznie bogatsze. Chociaŋ w tę wspóģpracę zaangaŋowanych byģo kilka osób, mógģbym wspomnieæ w szczególnoķci statystyka Stanforda, Jerome′a Friedmana, który rozpocząģ wspóģpracę z niektórymi doktoratami AI ze Stanford. Po swojej wczeķniejszej pracy nad konstrukcją drzewa decyzyjnego Friedman, we wspóģpracy z Leo Breimanem, Richardem Olshenem i Charlesem Stoneem, pomógģ opracowaæ system o nazwie CART, akronim dla drzew klasyfikacyjnych i drzew regresji. CART ma wiele funkcji z C4. 5 (i w rzeczywistoķci C4.5 zastosowaģ techniki CART do radzenia sobie z atrybutami liczbowymi). Systemy uczenia drzew decyzyjnych zostaģy zastosowane do szerokiej gamy problemów eksploracji danych
E. Programowanie logiki indukcyjnej
Wyraŋone w języku logiki zdaņ, JEŊELI {NASTĘPNIE reguģy utworzone z drzew decyzyjnych mają postaæ P1 ∧ P2∧… PN → P. P i Q to zdania bez wewnętrznej struktury. Wczeķniej mówiģem o rachunku predykatów, w którym zdania, zwane predykatami, miaģy wewnętrzne argumenty. W tym języku moŋna mieæ znacznie bardziej wyraziste reguģy, takie jak ∀ (x , y, z) [Ojciec (x; y) ∧ Rodzeņstwo (z , y) → Ojciec (x; z)], na przykģad. Opracowano kilka technik uczenia się tego rodzaju reguģ "relacyjnych" z baz danych i innych "wiedzy podstawowej". (Wspomniaģem wczeķniej pokrewny temat, mianowicie uczenie się "probabilistycznych modeli relacyjnych", które są wersjami sieci bayesowskich, które dopuszczaģy predykaty ze zmiennymi.) Jeden ze wczesnych systemów uczenia się reguģ relacyjnych zostaģ opracowany przez Quinlan i nazywaģ się FOIL. Poniewaŋ wyuczone reguģy mają tę samą formę, co instrukcje w języku komputerowym PROLOG (język oparty na logice), dziedzina poķwięcona nauce tych reguģ nazywa się " Indukcyjnym programowaniem logicznym"(ILP). Chociaŋ metody ILP wykorzystują aparat logiczny zbyt skomplikowany, bym mógģ tu wyjaķniæ, niektóre z nich mają ķcisģy związek z konstrukcją drzewa decyzyjnego. Istnieje kilka zastosowaņ ILP, w tym nauka zasad relacyjnych dla aktywnoķæ leku, w przypadku struktury drugorzędowej biaģka i projektowania siatki elementarnej. Są to wszystkie przykģady tego, co moŋna nazwaæ "eksploracją danych relacyjnych"
Sieci neuronowe
W latach 60. XX wieku badacze sieci neuronowych stosowali róŋne metody zmiany regulowanych wag sieci, dzięki czemu caģa sieæ reagowaģa odpowiednio na zestaw danych wejķciowych "szkoleniowych". Na przykģad Frank Rosenblatt w Cornell skorygowaģ wartoķci masy w warstwie koņcowej tego, co nazwaģ trójwarstwowym perceptronem alfa. Bill Ridgway (jeden ze studentów Bernarda Widrowa ze Stanford) dostosowaģ wagi w pierwszej warstwie, którą nazwaģ MADALINE. Mieliķmy podobny schemat dostosowywania cięŋarów w pierwszej warstwie maszyn sieci neuronowych MINOS II i MINOS III w SRI. Inni stosowali róŋne techniki statystyczne do ustalania wartoķci masy. Ale wszystkim nam przeszkodziģo to, jak zmieniæ wagi w więcej niŋ jednej warstwie sieci wielowarstwowych.
Algorytm Backprop
Problem ten zostaģ rozwiązany w poģowie lat 80. XX wieku dzięki wynalezieniu techniki zwanej "propagacją wsteczną" (w skrócie backprop) wprowadzonej przez Davida Rumelharta, Geoffreya E. Hintona i Ronalda J. Williamsa. Podstawowa idea backprop jest prosta, ale matematyka (którą pominę) jest raczej skomplikowana. W odpowiedzi na bģąd na wyjķciu sieci, backprop dokonuje niewielkich korekt we wszystkich wagach, aby zmniejszyæ ten bģąd. Moŋna ją traktowaæ jako metodę wspinaczki (a raczej zejķcia w dóģ)-szukanie niskich wartoķci bģędu w krajobrazie cięŋarów. Ale zamiast wypróbowaæ wszystkie moŋliwe niewielkie zmiany masy i zdecydowaæ, który zestaw odpowiada stromemu zjazdowi, backprop uŋywa rachunku róŋniczkowego do obliczenia najlepszego zestawu zmian masy. Czytelnicy, którzy pamiętają trochę rachunku róŋniczkowego (lub byæ moŋe liceum), nie będą mieli problemów z przypomnieniem sobie, ŋe moŋna go uŋyæ do obliczenia nachylenia krzywej lub powierzchni. Bģąd na wyjķciu sieci neuronowej moŋna traktowaæ jako funkcję cięŋaru sieci, to znaczy powierzchni w "przestrzeni wagowej". Tę funkcję moŋna zapisaæ i "zróŋnicowaæ" (operację w rachunku róŋniczkowym) w odniesieniu do cięŋarów, aby uzyskaæ zestaw zmian cięŋaru, które poprowadzą nas w dóģ w najbardziej stromym kierunku. Problem z implementacją tego pomysģu w prosty sposób dla sieci neuronowych polega na tym, ŋe sieci te mają "progi", których efektem jest wypeģnienie powierzchni bģędu nagģymi "klifami". (Wyjķcia sieci z progami mogą zmieniaæ się z 1 na 0 lub z 0 na 1 z nieskoņczenie maģymi zmianami niektórych wartoķci masy.) Operacje rachunku róŋniczkowego wymagają pģynnie zmieniających się powierzchni i są frustrowane przez klify. Rumelhart i wspóģpracownicy poradzili sobie z tym problemem, zastępując progi komponentami, których dane wyjķciowe mogą zmieniaæ się tylko pģynnie, mimo ŋe zmieniają się doķæ gwaģtownie, aby sieæ mogģa wykonaæ mniej więcej to samo co sieæ z progami. Dzięki tym zamianom moŋna zastosowaæ rachunek róŋniczkowy i caģkowy do propagacji funkcji bģędu (od wyjķcia do wejķcia) w sieci, aby obliczyæ najlepszy zestaw zmian wartoķci wagi we wszystkich warstwach sieci. Chociaŋ ten proces zerowania dopuszczalnych wartoķci masy jest powolny, zostaģ zastosowany z imponującymi wynikami w przypadku wielu problemów związanych z uczeniem się sieci neuronowej. Dlaczego o tym nie pomyķleliķmy? W rzeczywistoķci niektórzy ludzie najwyražniej wymyķlili podobny pomysģ, zanim Rumelhart i jego koledzy to zrobili. Prawdopodobnie najwczeķniej Arthur E. Bryson Jr. i Y. C. Ho zastosowali iteracyjne metody gradientu do rozwiązania równaņ Eulera -Lagrange′a. Paul Werbos, zaproponowaģ równieŋ bģędy propagacji wstecznej w celu trenowania wielowarstwowych sieci neuronowych. Podobnie jak w przypadku wszystkich lokalnych technik wyszukiwania, backprop moŋe utknąæ na jednym z lokalnych minimów powierzchni bģędu. Oczywiķcie proces uczenia się moŋna powtarzaæ, zaczynając od róŋnych wartoķci początkowych wag, aby spróbowaæ znaležæ niŋszą (lub byæ moŋe najniŋszą) wartoķæ bģędu. W kaŋdym razie metoda backprop jest nadal, jak napisaģ Laveen Kanal w 1993 roku, prawdopodobnie najbardziej rozpowszechniona ogólna procedura szkolenia sieci neuronowych w zakresie klasyfikacji wzorców. "Metody uczenia sieci neuronowej zostaģy zastosowane w róŋnych obszarach, w tym w kontroli samolotów, wykrywaniu oszustw związanych z kartami kredytowymi, rozpoznawaniu waluty w automatach i eksploracji danych.
NETtalk
Jednym z bardzo interesujących zastosowaņ metody uczenia się z wykorzystaniem metody backprop byģo opracowane przez Terrence'a J. Sejnowskiego i Charlesa Rosenberga . Nauczyli sieci neuronowej mówiæ! W jednym ze swoich eksperymentów ich system, zwany NETtalk, nauczyģ się czytaæ tekst, który zostaģ przepisany z nieformalnej, ciągģej mowy szeķcioletniego dziecka i wytwarzaģ džwięk (brzmiaģ wyjątkowo jak u dziecka). Sieæ miaģa 203 jednostek wejķciowych zaprojektowanych do kodowania ciągu siedmiu list. Tekst byģ przesyģany strumieniowo przez te siedem jednostek litera po literze. Byģo 80 "ukrytych jednostek", które byģy podģączone do wejķæ za pomocą regulowanych obciąŋników. Spodziewano się, ŋe ukryte jednostki będą tworzyæ wewnętrzne reprezentacje odpowiednie do rozwiązania problemu odwzorowania liter na fonemy. "Byģy jednostki wyjķciowe, które miaģy wytwarzaæ zakodowane wersje fonemów, podstawowe jednostki džwięków mowy. Jednostki wyjķciowe zostaģy poģączone z ukrytymi jednostkami za pomocą dodatkowych regulowanych cięŋarów. (Ģącznie byģo 18 629 regulowanych cięŋarów). W koņcu kody fonemiczne zostaģy przekazane do komercyjnego syntezatora mowy w celu uzyskania sģyszalnego sygnaģu wyjķciowego. Sieæ byģa szkolona przez porównywanie, za kaŋdym razem, fonemiczny kod w jednostkach wyjķciowych w stosunku do tego, jaki powinien byæ kod dla wprowadzania tekstu w tym kroku czasu. Backprop zostaģ uŋyty do zmodyfikowania wag w taki sposób, aby zmniejszyæ ten bģąd. Autorzy twierdzą, ŋe "w ciągu kilku dni moŋna byģo wytrenowaæ sieæ z siedmioliterowym oknem." (Pamiętaj, ŋe komputery byģy znacznie wolniejsze w 1987 r.) Doszli do wniosku, ŋe "ogólnie zrozumiaģoķæ mowy byģa caģkiem dobra" i ŋe "im więcej sģów uczy się sieæ, tym lepiej jest uogólniaæ i poprawnie wymawiaæ nowe sģowa." Po treningu na korpusie 1024 sģów sieæ zostaģa przetestowana [bez dalszego szkolenia] na kontynuacji 439 sģów od tego samego mówcy . Wydajnoķæ wyniosģa 78%, co wskazuje, ŋe duŋa częķæ nauki zostaģa przeniesiona na nowe sģowa nawet po maģej próbce angielskich sģów. "Oprócz okreķlonej sieci przeprowadzono równieŋ eksperymenty w sieciach z bardziej ukrytymi z dwiema warstwami jednostek ukrytych. Ogólnie rzecz biorąc, większe sieci dziaģaģy lepiej.
ALVINN
Kolejna aplikacja sieci neuronowej, ta do sterowania furgonetką, zostaģa opracowana przez doktora Deana Pomerleau, student Carnegie Mellon University. System, który obejmowaģ furgonetkę, kamerę telewizyjną do patrzenia na drogę przed sobą oraz aparat interfejsu, nazywaģ się ALVINN, skrót od Autonomous Land Vehicle in a Neural Network. ALVINN wykorzystaģ pojazd CMU Navlab, który zostaģ zbudowany na podwoziu samochodu dostawczego z napędem hydraulicznym i elektrycznym ukģadem kierowniczym. Wedģug artykuģu CMU: "Komputery mogą sterowaæ i prowadziæ furgonetkę za pomocą serwomechanizmów elektrycznych i hydraulicznych lub kierowca moŋe przejąæ kontrolę nad jazdą do miejsca testowego lub pominąæ komputer". Dane wejķciowe do sieci neuronowej ALVINN stanowiģa tablica wartoķci natęŋenia obrazu w skali szaroķci 30x32 o niskiej rozdzielczoķci 30x32 wytwarzana przez kamerę wideo zamontowaną na dachu furgonetki. Kaŋde z tych 960 wejķæ byģo podģączone do kaŋdego z czterech ukrytych jednostek dzięki regulowanym cięŋarkom. Z kolei jednostki ukryte zostaģy poģączone z linią 30 jednostek wyjķciowych od lewej do prawej za pomocą regulowanych wag. Jednostki wyjķciowe sterowaģy mechanizmem sterującym furgonetki w następujący sposób: Ķrodkowa jednostka wyjķciowa reprezentuje warunek "jazdy na wprost", podczas gdy jednostki na lewo i prawo od ķrodka reprezentują kolejno ostrzejsze skręty w lewo i prawo. Jednostki po skrajnej lewej i prawej stronie wektora wyjķciowego reprezentują zwoje o promieniu 20 m odpowiednio w lewo i w prawo, a jednostki pomiędzy reprezentują zwoje, które zmniejszają się liniowo w swojej krzywižnie do jednostki ķrodkowej "na wprost".…Kierunek sterowania podyktowany przez sieæ jest uwaŋany za ķrodek masy "wzgórza" aktywacji otaczającej jednostkę wyjķciową o najwyŋszym poziomie aktywacji. Uŋywając ķrodka masy aktywacji zamiast najbardziej aktywnej jednostki wyjķciowej podczas okreķlania w ten sposób kierunku kierowania pozwala na korekty kierownicy dla poprawy dokģadnoķci jazdy ALVINN. Istnieją róŋne wersje ALVINN. W jednym szkolenie sieci byģo "w locie", co oznacza, ŋe sieæ byģa szkolona w czasie rzeczywistym, gdy van kierowany byģ przez ludzkiego kierowcę róŋnymi drogami i ķcieŋkami. Poŋądany kąt skrętu zostaģ wybrany przez kierowcę, a cięŋary sieci zostaģy skorygowane za pomocą korekcji tylnej, aby spróbowaæ naķladowaæ wydajnoķæ kierowcy. Jednym z problemów związanych z tą metodą byģo to, ŋe sieæ nigdy nie byģa naraŋona na moŋliwe obrazy "zejķcia z drogi". Do zestawu treningowego dodano symulacje tego, jak wyglądaģyby takie obrazy (oznaczone w tych przypadkach kątem skrętu). Podsumowując typowy test wydajnoķci ALVINN, Pomerleau napisaģ:" Ponad trzy przebiegi, sieæ jedzie z prędkoķcią 5 mil na godzinę wzdģuŋ 100-metrowego odcinka testowego ķrednia pozycja pojazdu wynosiģa 1,6 cm na prawo od ķrodka, przy standardowym odchyleniu 7,2 cm. Pod kontrolą czģowieka ķrednia pozycja pojazdu wynosiģa 4,0 cm na prawo od ķrodka, ze standardowym odchyleniem 5,47 cm."
Carnegie Mellon's Robotics Institute kontynuowaģ (i nadal kontynuuje) prace nad pojazdami autonomicznymi, chociaŋ podejķcie sieci neuronowej do sterowania za pomocą obrazu zostaģo zastąpione przez bardziej niezawodne algorytmy widzenia komputerowego. Ich system postrzegania wizualnego RALPH z 1995 r. (Akronim oznaczający funkcję szybkiego dostosowywania pozycji bocznej) wykorzystywaģ specjalne procedury przetwarzania obrazu w celu okreķlenia krzywizny granicy drogi. Wedģug Pomerleau: "RALPH byģ w stanie zlokalizowaæ drogę i samodzielnie kierowaæ na róŋnych rodzajach dróg w wielu róŋnych warunkach. RALPH przejechaģ naszym pojazdem testowym Navlab 5 ponad 3000 mil po drogach od ķcieŋek rowerowych jednopasmowych, po wiejskie autostrady, do autostrad międzystanowych ". Latem 1995 r. Jeden z ich specjalnie wyprofilowanych pojazdów, Pontiac Trans Sport z 1990 r. (Navlab 5) przekazany przez Delco Electronics, kierowaģ autonomicznie (za pomocą RALPH) na 2779 z 2849 mil z Pittsburgha do San Diego w Kalifornii. (Tylko kierowanie byģo autonomiczne {doktorant z Pomerleau i doktor Todd Jochem obsģugiwaģ przepustnicę i hamulec.) Ķrednia prędkoķæ wynosiģa ponad 60 mil na godzinę
Uczenie się bez nadzoru
Drzewo decyzyjne i metody uczenia sieci neuronowej opisane do tej pory są przykģadami "uczenia nadzorowanego", "rodzaju uczenia się, w którym próbuje się nauczyæ klasyfikowaæ dane z duŋej próbki danych szkoleniowych, których klasyfikacje są znane." nadzór ", który kieruje uczeniem się w tych systemach, polega na informowaniu systemu o klasyfikacji kaŋdej bazy danych w zestawie szkoleniowym. Jednak czasami moŋliwe jest zbudowanie uŋytecznych klasyfikacji danych na podstawie samych danych. Techniki do tego celu podlegają nagģówek "nauka bez nadzoru". Zaģóŋmy , ŋe mamy zestaw nieznakowanych punktów próbnych, takich jak te pokazane na rysunku
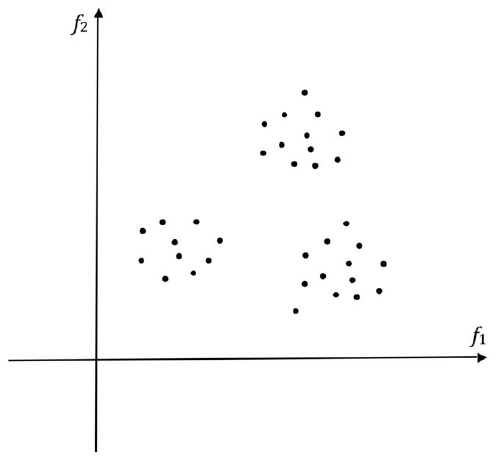
Czy moŋna się czegoķ nauczyæ z takich danych? Po oględzinach widzimy, ŋe punkty wydają się byæ rozmieszczone w trzech grupach. Byæ moŋe kaŋdy klaster zawiera punkty, które moŋna uznaæ za naleŋące do tej samej kategorii. Tak więc, gdybyķmy mogli automatycznie przetwarzaæ próbki danych w celu identyfikacji klastrów i granic między nimi, mielibyķmy metodę uczenia się bez nadzoru. Badacze AI zastosowali kilka metod identyfikacji klastrów próbek treningowych. Popularnym i ģatwym do wyjaķnienia jest tak zwana metoda k-ķrednich. Dziaģa poprzez powtarzanie następujących kroków:
1. Zainstaluj, byæ moŋe w przypadkowych lokalizacjach, pewną liczbę, powiedzmy k, "poszukiwaczy klastrów" w przestrzeni próbek.
2. Dla kaŋdego z tych osób poszukujących klastra zgrupuj próbki szkoleniowe, które są do niego bliŋsze niŋ dla innych osób poszukujących klastra.
3. Oblicz centroid ("ķrodek cięŋkoķci") kaŋdej z tych grup próbek.
4. Przenieķ kaŋdego z poszukiwaczy gromad do ķrodka cięŋkoķci odpowiedniej grupy.
5. Powtarzaj te kroki, aŋ ŋadna osoba poszukująca klastra nie będzie musiaģa zostaæ ponownie przeniesiona.
Pod koniec tego procesu osoby poszukujące klastra będą znajdowaæ się w ķrodkach grup prób szkoleniowych, które moŋna uznaæ za klastry lub oddzielne kategorie danych. Teraz, aby sklasyfikowaæ jakiķ nowy punkt danych, którego nie ma w zestawie szkoleniowym, po prostu obliczamy, do którego poszukiwacza klastra jest najbliŋej. Proces zaleŋy oczywiķcie od moŋliwoķci odgadnięcia liczby klastrów, k. Metody tego polegają na ogóģ na dostosowaniu ich liczby, tak aby punkty w klastrach byģy bliŋej siebie niŋ odlegģoķci między klastrami. Statystycy i inni opracowali kilka metod grupowania danych, w tym wariacje związane z metodą k-ķrednich. Jedna wybitna technika AutoClass zostaģa opracowana przez Petera Cheesemana i wspóģpracowników z NASA. Wedģug strony internetowej o AutoClass, AutoClass pobiera bazę danych przypadków opisaną przez kombinację rzeczywistych i dyskretnych atrybutów i automatycznie wyszukuje naturalne klasy w tych danych. Nie trzeba mówiæ, ile klas jest obecnych ani jak wyglądają - wyciąga te informacje z samych danych. Klasy są opisane probabilistycznie, dzięki czemu obiekt moŋe mieæ częķciowe czģonkostwo w róŋnych klasach, a definicje klas mogą się nakģadaæ. AutoClass sģynie z odkrycia nowej klasy gwiazd w podczerwieni. Odkryģ takŋe nowe klasy biaģek, intronów i innych wzorów w danych sekwencji DNA / biaģek. Istnieją nawet techniki, które moŋna zastosowaæ do danych nienumerycznych. Statystycy grupują wszystkie te metody (numeryczne i nienumeryczne) pod ogólnym nagģówkiem "analiza skupieņ". Podręcznik Dudy, Harta i Bociana zawiera obszerną dyskusję na temat uczenia się bez nadzoru (a takŋe innych tematów w klasyfikacji danych).
Nauka wzmocnienia
Nauka optymalnych zasad
Istnieje inny styl uczenia się, który leŋy nieco pomiędzy odmianą nadzorowaną i nienadzorowaną. Przykģadem moŋe byæ nauka, które z kilku moŋliwych dziaģaņ, na przykģad, robot powinien wykonaæ na kaŋdym etapie w ciągģej sekwencji doķwiadczeņ, biorąc pod uwagę tylko ostateczny wynik wszystkich jego dziaģaņ. Ekstremalnym przypadkiem byģaby nauka doskonaģej gry w szachy, biorąc pod uwagę tylko informacje o wygranej lub przegranej pod koniec gry. Nie zbudowano jeszcze systemu, który mógģby nauczyæ się graæ w szachy w ten sposób, ale program moŋe nauczyæ się graæ w backgammon w ten sposób i nauczyæ się wykonywania innych interesujących zadaņ, takich jak kontrolowanie walki ķmigģowców. Poŋyczając terminy z psychologicznej teorii uczenia się, moŋemy nazwaæ informacje o wygranych lub przegranych (lub ogólnie informacje o dobrych lub zģych wynikach) "nagrodą" lub "wzmocnieniem", a ten styl uczenia się nazywa się "uczeniem wzmacniającym" lub (czasami) "uczenie się metodą prób i bģędów". Nauka wzmacniana ma dģugą i zróŋnicowaną historię. Psycholog Edward L. Thorndike badaģ ten styl uczenia się na zwierzętach. W swojej ksiąŋce "Reinforcement Learning: An Introduction", Richard S. Sutton i Andrew G. Barto , dwaj pionierzy tego pola, wspominają o kilku historycznych kamieniach milowych, w tym metodzie Arthura Samuela do uczenia się funkcji oceny w warcabach, wykorzystanie dynamicznych technik programowania Richarda Bellmana w optymalnej kontroli, system uczenia się metodą prób i bģędów Johna Andreaea STeLLA, systemy uczenia Donalda Michie do gry w kóģko i krzyŋyk (MENACE) i równowaŋenia biegunów ( BOXE) oraz praca A. Harry'ego Klopfa nad neuronami hedonistycznymi. "Uczenie się przez wzmocnienie jest kolejną z tych subdyscyplin sztucznej inteligencji, która staģa się wysoce techniczna i wielorozgaģęziona. Spróbuję delikatnego i niematematycznego opisu tego, jak to dziaģa. W najprostszym ustawienie, uczenie się ze wzmocnieniem polega na nauczeniu się przechodzenia przez zbiór stanów, przechodzenia od jednego stanu do drugiego itd., aby osiągnąæ stan, w którym otrzymuje się nagrodę. Problem jest podobny do tego, z którym mierzy się szczur w nauce prowadzenia labiryntu (lub robota, z którym robot ma się zmierzyæ podczas nauki jak wykonaæ zadanie). W rzeczywistoķci wykorzystajmy przykģad labiryntu do opisania niektórych aspektów uczenia się przez wzmocnienie. Typowy labirynt pokazano tu
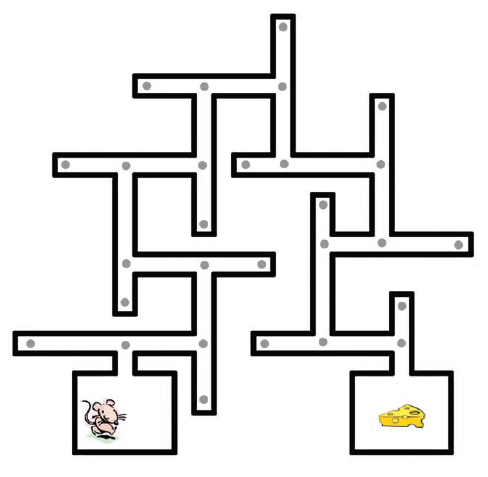
Problemem szczura jest przejķcie z pozycji początkowej do sera w pozycji bramkowej. Szare kropki mają na celu zobrazowanie sytuacji, w których szczur mógģby się znaležæ i rozpoznaæ. W terminologii uczenia wzmacniającego sytuacje te nazywane są "stanami". W kaŋdym stanie szczur moŋe wybieraæ spoķród, powiedzmy, czterech dziaģaņ, mianowicie skręæ w lewo, skręæ w prawo, idž do przodu lub do tyģu. W zaleŋnoķci od stanu moŋliwe są tylko niektóre dziaģania - na przykģad nie moŋna iķæ naprzód, gdy stoi się w ķlepym zauģku. Kaŋde moŋliwe dziaģanie przenosi szczura z jednego stanu do sąsiedniego w labiryncie. Zbiór stanów i ģączące je dziaģania moŋna traktowaæ jako wykres, podobny do tych, które omówiģem, gdy mówiģem o metodach wyszukiwania. Aby nie oddaliæ się zbytnio od tego, co wiadomo o prawdziwych szczurach biegnących w labiryncie, przejdžmy teraz do opisu, w jaki sposób funkcjonalny "robot-szczur" moŋe nauczyæ się prowadziæ ten labirynt. Gģównym problemem dla robota jest to, ŋe zaczyna się od braku mapy labiryntu i nie ma pojęcia o skutkach swoich dziaģaņ. Oznacza to, ŋe dla kaŋdego stanu, w którym się on znajduje, nie wie, które następne stany przyniosģyby dla róŋnych dziaģaņ, które mógģby podjąæ w tym stanie. Gdyby bowiem miaģ taką mapę, powiedzmy reprezentowaną przez wykres, mógģby przeszukaæ wykres (przy uŋyciu metody takiej jak A*) w celu znalezienia ķcieŋki do węzģa celu. Jednym ze sposobów jest próba nauczenia się wykresu stanów i ich poģączeņ metodami prób i bģędów, a następnie zastosowania metod wyszukiwania grafów, aby dowiedzieæ się, jak poruszaæ się po labiryncie. Alternatywą i tą stosowaną w większoķci metod uczenia się przez zbrojenie jest nazywanie wszystkich stanów napotykanych przez robota, który bģąka się losowo w poszukiwaniu celu. (Zakģadamy, ŋe ostatecznie osiągnie cel.) W terminologii uczenia się wzmacniającego "polityka" prowadzenia labiryntu ģączy pewne pojedyncze dziaģanie z kaŋdym nazwanym stanem. Najlepsza lub "optymalna polityka" kojarzyģaby z kaŋdym stanem to dziaģanie, które prowadziģoby do najkrótszej (lub w inny sposób najmniej kosztownej) ķcieŋki przez labirynt. Uczenie się przez wzmocnienie polega na uczeniu się najlepszej polityki, a przynajmniej dobrej polityki.
Jedną z metod uczenia się zasad jest powiązanie"wyceny " z kaŋdą moŋliwą akcją w kaŋdym stanie, a następnie dostosowując te liczby (w oparciu o doķwiadczenie), aŋ wskaŋą drogę do celu. Ta metoda nazywa się "Q-learning" i zostaģa pierwotnie zasugerowana przez Christophera Watkinsa w jego doktoracie na Uniwersytecie Cambridge. Teza,ŋe Robot rozpoczyna proces uczenia się, przypisując nazwę do stanu, w którym się rozpoczyna, i przypisując losowo wybrane numery wyceny do kaŋdej akcji, jaką moŋe podjąæ w tym stanie. Proces uczenia się rozszerzy tę tabelę, przypisując nazwy i numery wyceny wszystkich dziaģaņ, które moŋe podjąæ w kaŋdym napotkanym nowym stanie. (Zakģadamy, ŋe robot pamięta w swojej tabeli nazwy wszystkich stanów, które juŋ odwiedziģ w procesie uczenia się, i odróŋnia je od nowych stanów.) Stan początkowy robota, z losowo wybranym numerem wyceny przypisanym do jego jedynego dziaģania moŋliwe, pokazano na szkicu po lewej stronie rysunku
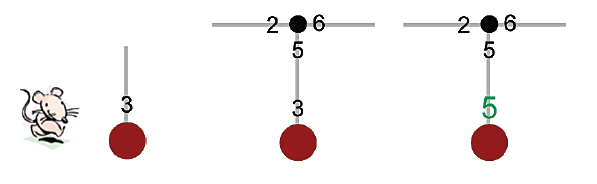
Na kaŋdym etapie procesu uczenia się robot podejmuje tę akcję, mając najwyŋszy numer wyceny. Poniewaŋ w początkowym stanie robota jest tylko jedna akcja, wykonuje ona tę czynnoķæ, wprowadza się w nowy stan i przypisuje losowe liczby wycen do moŋliwych akcji nowy stan. Ten krok pokazano na ķrodkowym szkicu z rysunku powyŋej. Teraz jest kluczowy krok w nauce. Poniewaŋ robot "teraz" wie, ŋe moŋe osiągnąæ nowy stan, mając dziaģania, których najwyŋszy numer wyceny to 6, aktualizuje numer wyceny, a mianowicie 3, akcji prowadzącej do tego stanu, dostosowując go do liczby bardziej spójnej z byciem jest w stanie podjąæ dziaģanie, które wedģug niego jest warte 6. Aby uwzględniæ "koszt" wģaķnie zakoņczonej akcji, dostosowanie 3 nie idzie aŋ do 6, ale tylko do 5, powiedzmy. Wynik pokazano na prawym szkicu z rysunku powyŋej, na którym skorygowana wycena jest nieco większa niŋ inne liczby i zacieniowana i ten proces trwa. W kaŋdym stanie podejmij dziaģanie, którego numer wyceny jest największy, a następnie dostosuj ten numer wyceny, przybliŋając jego wartoķæ do wartoķci dziaģania o najwyŋszym numerze wyceny we wģaķnie wprowadzonym stanie. I chociaŋ proces rozpoczyna się od losowo wybranych liczb wyceny, ostatecznie proces prób i bģędów potknie się do stanu docelowego, w którym zostanie uzyskana wysoka "nagroda". Na tym etapie wģaķnie podjęta akcja, która doprowadziģa do tego nagrody, ma wartoķæ wyceny podniesioną do tej samej wartoķci (lub moŋe nieco mniejszej) niŋ wartoķæ nagrody.
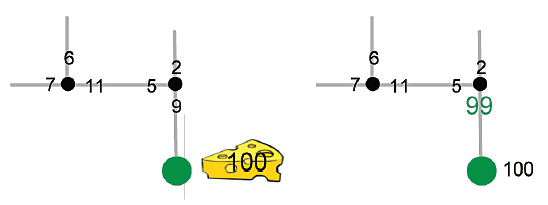
Szkic po lewej stronie przyrządu pokazuje niektóre stany i wartoķci akcji w momencie, gdy robot podejmuje akcję, która osiąga cel. Na szkicu po prawej stronie przyrządu pokazuję skorygowaną wycenę (zacieniowaną) dla tego dziaģania zmierzającego do osiągnięcia celu. Teraz po raz pierwszy , wycena akcji opiera się na zdobyciu nagrody, a nie jest ustalana losowo. Jeķli robot kiedykolwiek znajdzie się w stanie sąsiadującym ze stanem celu, z pewnoķcią podejmie tę samą akcję. Co waŋniejsze, kiedy osiągnie ten przedostatni stan w kolejnym doķwiadczeniu, propaguje tę wartoķæ opartą na nagrodach wstecz.
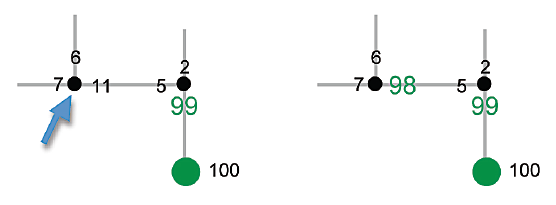
Zaģóŋmy, ŋe na szkicu po lewej robot znajduje się w stanie zaznaczonym strzaģką. Z tego stanu podejmuje tę akcję z największą wyceną, która prowadzi ją do stanu sąsiadującego z celem. Akcja o największej wycenie prowadzącej z tego stanu ma wycenę 99, więc wycena wģaķnie wykonanej akcji zmienia się z 11 na 98, jak pokazano na szkicu po prawej stronie. Zwiększenie wycen dziaģaņ w stanach zbliŋonych do celu poprzez propagację wsteczną powoduje, ŋe stany te z natury "nagradzają" tak, jakby byģy stanami docelowymi. Bystry czytelnik moŋe narzekaæ, ŋe sprytnie ustawiģem "losowe" wartoķci wyceny na wartoķci, które doprowadziģyby do celu, gdy robot osiągnie stan zbliŋony do celu. Co by byģo, gdyby wartoķci te byģy takie, jakie najprawdopodobniej byģyby, ŋe po zbliŋeniu się robot oddaliģ się od prawie osiągniętego celu? Jeķli liczby wyceny zostaną skorygowane zgodnie z zaleceniami, zawsze biorąc pod uwagę koszt ruchu, maģa myķl przekona jednego, ŋe ostatecznie liczby będą takie, aby zmusiæ robota do osiągnięcia celu, a wszystkie inne drogi ostatecznie zostaną zamknięte . Dzięki ciągģemu doķwiadczeniu wyceny dziaģaņ związanych z osiąganiem celu stopniowo propagują się wstecz od celu. Ostatecznie, po wielu doķwiadczeniach związanych z próbami i bģędami (i przy pewnych "uzasadnionych" zaģoŋeniach), wartoķci będą zbieŋne z tymi, które wdraŋają optymalną politykę, to znaczy taką, która zawsze doprowadza robota do celu w najbardziej efektywny sposób. Większoķæ wersji uczenia wzmacniającego ma następujące opracowania:
• Nagrody mogą byæ przyznawane w więcej niŋ jednym stanie. Oznacza to, ŋe niekoniecznie istnieje jeden cel, ale wiele stanów, które mogą przyczyniæ się do nagrody. Nagrody są reprezentowane przez wartoķci liczbowe, które mogą byæ dodatnie (prawdziwe "nagrody"), zero lub ujemne ("kary").
• Zamiast próbowaæ znaležæ zasadę, która odpowiada optymalnej ķieŋce do stanu jednego celu próbuje się nauczyæ zasad, które maksymalizują oczekiwaną z czasem nagrodę. Zazwyczaj przy poznawaniu zasad nagrody oczekiwane w odlegģej przyszģoķci są "dyskontowane", co oznacza, ŋe nie liczą się tak, jak nagrody oczekiwane od razu.
• Kaŋde dziaģanie podjęte w danym stanie nie zawsze moŋe prowadziæ do tego samego stanu. Moŋna próbowaæ dowiedzieæ się, jakie są prawdopodobieņstwa, ŋe niektóre dziaģania podjęte w danym stanie prowadzą do tego, co robią inne stany i niektóre metody uczenia wzmacniającego, takie jak "zamiatanie priorytetowe". Proces uczenia się Q unika potrzeby wyražnego poznania tych prawdopodobieņstw, poniewaŋ niezaleŋnie od tego, jakie one są, odpowiednio (wraz z nagrodami) odpowiednio wpģywają na wartoķci, które proces uczenia przypisuje parom stan-dziaģanie.
• Kolejną komplikacją moŋe byæ to, ŋe robot ma niedoskonaģą wiedzę o tym, w jakim jest stanie, poniewaŋ jego aparat sensoryczny nie jest wystarczająco dokģadny ani informacyjny. W takim przypadku mówi się, ŋe rzeczywisty stan, w którym znajduje się robot, jest "ukryty", co dodatkowo komplikuje problem uczenia się optymalnej polityki.
Dzięki tym opracowaniom problem staje się jednym z tzw. "Procesów decyzyjnych Markowa" (MDP). Ze względu na niedoskonaģą wiedzę o stanie nazywa się to "częķciowo obserwowalnym procesem decyzyjnym Markowa" (POMDP). MDP i POMDP zostaģy dobrze zbadane przez ludzi w teorii kontroli, a takŋe w AI. Mogę uŋyæ przykģadu labiryntu robota, aby wspomnieæ o kilku rzeczach, które są waŋne w zastosowaniu uczenia wzmacniającego w praktycznych zastosowaniach. Po pierwsze, zaģoŋyģem, ŋe losowa eksploracja robota ostatecznie wyląduje w stanie celu. W zģoŋonych problemach szansa na losowe osiągnięcie celu (lub innych nagród) moŋe byæ niewielka do zera. Podziaģ problemu na hierarchię podproblemów, w których nagrody są ģatwiejsze do zdobycia, jest czasem wykorzystywany do przyspieszenia nauki. Dodatkowo moŋna zastosowaæ strategie "ksztaģtowania", w których robot jest umieszczony w sytuacji wystarczająco blisko celu, aby losowa eksploracja znalazģa cel. Następnie, po przypisaniu niektórym dziaģaniom zbliŋonym do celu ocen związanych z celem, sytuacje początkowe moŋna stopniowo przesuwaæ coraz dalej od celu. Alternatywnie, moŋna podaæ wskazówki, byæ moŋe w postaci nagród poķrednich, aby daæ robotowi znaæ, ŋe radzi sobie dobrze. Takie strategie są wykorzystywane w nauczaniu umiejętnoķci ludzi i zwierząt. Kolejny problem dotyczy kompromisu między "wykorzystywaniem" juŋ wyuczonej polityki a "badaniem" w celu znalezienia lepszych polityk. Często zdarza się, ŋe zestaw wycen czynnoķci uzyskanych na wczesnym etapie procesu uczenia się moŋe nie byæ najlepszym moŋliwym zestawem. Aby nauczyæ się lepszego zestawu, naleŋy w jakiķ sposób zachęciæ robota do losowego odstąpienia od znanej polityki, aby przejķæ do lepszego. Wreszcie, wiele problemów moŋe mieæ tak zwane "przestrzenie stanów" tak duŋe, ŋe caģy zestaw wszystkich stanów oraz ich dziaģania i wyceny nie mogą byæ wyražnie wymienione w tabeli takiej jak ta, którą zaģoŋyģem dla problemu labiryntu robota. W takim przypadku wyceny dziaģaņ, które moŋna podjąæ w danym stanie, muszą byæ obliczone, a nie zapisane.
TD-GAMMON
Jednym z najbardziej imponujących przykģadów siģy metod uczenia maszynowego jest system TD-GAMMON opracowany przez Geralda Tesauro w IBM. Wersje TD-GAMMON nauczyģy się graæ w ķwietnego tryktraka po graniu przeciwko sobie podczas milionów gier. TD-GAMMON zastosowaģ kombinację uczenia sieci neuronowej i pewnego rodzaju uczenia wzmacniającego zwanego "uczeniem róŋnic czasowych" (co wyjaķnia pre TD ). Sieæ neuronowa TD-GAMMON skģadaģa się z trzech warstw. W jednej wersji byģo 198 jednostek wejķciowych, 40 jednostek ukrytych i 4 jednostki wyjķciowe. Kaŋda z jednostek wyjķciowych moŋe mieæ wartoķæ wyjķciową od 0 do 1. Kaŋde z wyjķæ miaģo za zadanie oszacowanie prawdopodobieņstwa okreķlonego wyniku gry. Cztery moŋliwe rozwaŋane wyniki to biaģe wygrane, biaģe gammony, czarne wygrane lub czarne gammony. Jednostki wejķciowe zostaģy zakodowane, aby reprezentowaæ konfigurację elementów na pģycie. Wartoķci czterech wyjķæ poģączono, aby uzyskaæ liczbę dającą oszacowaną "wartoķæ" pozycji pģytki z punktu widzenia bieli. Po pierwsze, oto jak sieæ zostaģa wykorzystana do wyboru ruch (zakģadam tutaj, ŋe czytelnik ma pewną znajomoķæ trik-traka, ale mój opis powinien mieæ sens nawet dla tych, którzy tego nie robią). Na kaŋdym etapie gry rzuca się kostkami, a program bierze pod uwagę wszystkie moŋliwych ruchów, które mógģby wykonaæ, biorąc pod uwagę rzut kostką. Sieæ oblicza wartoķæ kaŋdej moŋliwej wynikowej planszy, a program wybiera ruch produkujący planszę o najlepszej wartoķci (która jest najwyŋszą wartoķcią, gdy jest to ruch biaģych i najniŋsza wartoķæ, gdy jest ruch czarnego). Oto, jak sieæ się uczy: Dla kaŋdej pozycji planszy napotkanej podczas rzeczywistej gry wagi sieci są korygowane za pomocą backprop, dzięki czemu wartoķæ obliczona dla tej pozycji planszy jest bliŋsza obliczonej wartoķci dla tymczasowej następnej pozycji na planszy (i dlatego widzimy, dlaczego pojawia się termin "róŋnica czasowa"). Sieæ rozpoczyna się od losowo wybranych wartoķci masy, więc ruchy na początku procesu uczenia się, a takŋe korekty wagi, są losowe. Ale ostatecznie nawet losowo wybrane ruchy powodują zwycięstwo jednego z graczy. Po wygranej znane są cztery wartoķci prawdopodobieņstwa - jedna z nich to "1", a reszta to "0". Następnie moŋna dopasowaæ wagi sieci, aby wartoķæ przedostatniej planszy byģa zbliŋona do wartoķci tej ostatecznej, zwycięskiej pozycji na planszy. Podobnie jak we wszystkich procedurach uczenia się przy wzmocnieniu, wartoķci są stopniowo propagowane do tyģu od koņca gry do pozycji wyjķciowej. Po milionach gier wagi sieciowe przyjmują wartoķci, które prowadzą do eksperckiej gry. Komentując wersję TD-GAMMON, która oprócz uczenia się wykorzystuje równieŋ wyszukiwanie, Sutton i Barto napisali TD-GAMMON 3.0, który wydaje się byæ na poziomie lub bardzo blisko siģy gry najlepszych ludzkich graczy na ķwiecie. Moŋe juŋ byæ mistrzem ķwiata. Programy te zmieniģy juŋ takŋe sposób, w jaki grają najlepsi gracze. Na przykģad TD-GAMMON nauczyģ się graæ na niektórych pozycjach otwarcia inaczej niŋ byģo to w konwencji najlepszych graczy ludzkich. W oparciu o sukces TD-GAMMON i dalszą analizę, najlepsi ludzcy gracze zajmują teraz te pozycje, podobnie jak TD-GAMMON.
Inne zastosowania
Prawdopodobnie istnieją setki waŋnych metod uczenia się przez wzmacnianie. Typowym, a zarazem dramatycznym przykģadem jest praca Andrew Ng i jego grupy w Stanford nad nauką wykonywania akrobacyjnych manewrów ķmigģowca. Inne zastosowania dotyczyģy wysyģki wind, planowania warsztatów, zarządzania zuŋyciem energii i czworonoŋnych robotów kroczących. Jako ostatni komentarz na temat uczenia się wzmacniającego, warto zauwaŋyæ, ŋe częķæ technologii uczenia maszynowego, częķæ, której nazwa zostaģa zapoŋyczona z psychologii, spģaca teraz swój dģug, zapewniając teoretyczne ramy uczenia się mózgu zwierząt na poziomie neurofizjologicznym . W artykule w Journal of Neuroscience Christopher H. Donahue i Hyojung Seo napisali: Aby podejmowaæ skuteczne decyzje podczas poruszania się w niepewnym otoczeniu, zwierzęta muszą rozwinąæ zdolnoķæ do dokģadnego przewidywania konsekwencji swoich dziaģaņ. Uczenie się przez wzmocnienie staģo się kluczowym teoretycznym paradygmatem pozwalającym zrozumieæ, w jaki sposób zwierzęta dokonują tego wyczynu… Oprócz skutecznego przewidywania zachowania zwierząt przy wyborze, z powodzeniem wykorzystano model uczenia się wzmocnienia w celu wyjaķnienia funkcji zwojów podstawy w zachowaniu ukierunkowanym na cel. Wykazano, ŋe neurony dopaminergiczne w brzusznym obszarze nakrywkowym i istocie czarnej kodują bģąd przewidywania nagrody, który jest wykorzystywany do poprawy wyników przyszģych wyborów zwierzęcia. Inne badanie na maģpach wykonujących zadanie wolnego wyboru wykazaģo, ŋe aktywnoķæ neuronów prąŋkowia jest skorelowana z wartoķciami czynnoķci, które zostaģy oszacowane poprzez zintegrowanie wczeķniejszej historii wyników związanej z kaŋdym dziaģaniem
Ulepszenia
Wiele metod uczenia maszynowego, o których wspomniano, moŋna ulepszyæ na róŋne sposoby. Niektóre z nich opierają się na pracy statystów, a inne przez ludzi pracujących nad tzw. "Obliczeniową teorią uczenia się" .Jedna technika, zwana "bagging" (akronim od agregacji bootstrapu) jest zasģugą profesora Leo Breimana z University of California, Berkeley. W przypadku problemów z klasyfikacją workowanie polega na ģączeniu wyników pewnej liczby, powiedzmy m, oddzielnych klasyfikatorów. Kaŋdy uczestnik jest szkolony przy uŋyciu innego podzbioru oryginalnego zestawu treningowego. Podzbiory te są uzyskiwane z oryginaģu przez losowe wybranie (z zastąpieniem) niektórych jego przykģadów. (Statystycy nazywają te próbki "próbkami ģadowania początkowego"). Po przeszkoleniu kaŋdego z klasyfikatorów dokonuje się ostatecznej klasyfikacji większoķcią gģosów. Technikę tę moŋna zastosowaæ niezaleŋnie od rodzaju zastosowanego indywidualnego klasyfikatora - sieci neuronowej, drzewa decyzyjnego, najbliŋszego sąsiada lub tego, co masz. Pakowanie moŋna równieŋ zastosowaæ do problemu powiązania liczby (zamiast kategorii) z przykģadem. W takim przypadku wyniki są uķredniane, a nie uczestniczą w gģosowaniu. Operacje gģosowania i uķredniania pomagają uniknąæ przesģonięcia danych, a tym samym dają lepszą wydajnoķæ, niŋ moŋna by uzyskaæ przy jednym szkoleniu wszystkich klas na wszystkich danych. [Moŋna się zastanawiaæ, jak moŋna by poprawiæ wydajnoķæ sieci neuronowej MADALINE z lat 60, gdyby kaŋda z jej jednostek progowych byģa szkolona na próbkach bootstrapu.] Podobny pomysģ, zwany "boosting, zostaģ zaproponowany przez Roberta E. Schapire. Chociaŋ istnieje wiele wersji, tutaj w skrócie opisano, jak to dziaģa. Korzystając z jednej z nadzorowanych metod uczenia maszynowego, uczący jest szkolony na oryginalnym zestawie szkoleniowym, w którym kaŋda próbka jest jednakowo waŋona. " (Masę i-tej próbki, powiedzmy wi, moŋna ustawiæ, na przykģad, wģączając tę próbkę wi razy do zestawu treningowego.) Następnie budowany jest nowy zestaw treningowy, w którym próbki, które zostaģy bģędnie sklasyfikowane, a ich "waga" zostaģa zwiększona, a dla próbek, które zostaģy prawidģowo sklasyfikowane, ich waga spadģa. Korzystając z tego nowego zestawu szkoleniowego, trenowany jest inny uczestnik. (Ten przypuszczalnie będzie pracowaģ cięŋej na wczeķniejszych bģędnie sklasyfikowanych próbach.) Proces ten powtarza się, dopóki nie znajdziemy pewnej liczby, powiedzmy m, klasyfikatorów. Teraz kaŋdy z klas gģosuje nad kategoryzacją nowych próbek. Ich gģosy waŋone są w jaki sposób dobrze spisali się na oryginalnym zestawie treningowym. Gģosy bardziej wiarygodnych klasyfikatorów liczą się bardziej niŋ gģosy mniej wiarygodnych klasyfikatorów. Nawet gdy pierwotni klasyfikatorzy są "sģabi" (to znaczy wcale niezbyt wiarygodni), ogólna dokģadnoķæ poģączonego zestawu m klasyfikatorów moŋe byæ caģkiem dobra, tym samym "poprawiając" wyniki. Zaproponowano kilka sposobów poprawy. Jeden z popularnych, z powodu Yoava Freunda i Roberta Schapire′a, nazywa się "Adaboost". Moŋliwe jest takŋe ģączenie workowania i boostingu. Na koniec wspomnę o "maszynach wektorowych wsparcia" (SVM). Peģny ich opis wymagaģby więcej matematyki, niŋ chcielibyķmy tutaj zagģębiæ, ale mogę daæ przybliŋone i gotowe wyobraŋenie o tym, jak dziaģają na podstawie przykģadu geometrycznego. Po lewej stronie ryc. 29.17 pokazuję te same punkty które ilustrowaģy granicę oddzielającą w przestrzeni cech.
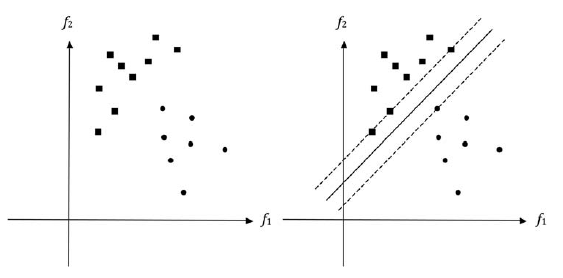
Punkty oznaczone maģymi kwadratami odpowiadają próbkom z jednej kategorii, a punkty oznaczone maģymi kóģkami odpowiadają próbkom z innej kategorii. Przypominamy, ŋe punkty na diagramach mają wspóģrzędne równe cechom, f1 i f2, obliczonym z elementów (takich jak džwięki mowy, obrazy lub inne dane), które chcemy sklasyfikowaæ. Zdarza się w tym przypadku, ŋe istnieje wiele linii prostych (to znaczy liniowych), które oddzielą punkty w dwóch kategoriach. Dlatego próba wyszkolenia elementu neuronowego w celu klasyfikacji punktów (uwaŋana za "próbki treningowe") zakoņczy się powodzeniem. Gdybyķmy uŋyli standardowej procedury korekcji bģędów do treningu, z pewnoķcią uzyskalibyķmy pewną granicę liniową, ale w przypadku maszyn SVM wymagamy więcej granicy niŋ tylko oddzielenie próbek treningowych. Chcemy, aby odlegģoķci (zwane "marginesem") od najbliŋszych punktów przeciwnych kategorii byģy jak największe. Taka liniowa granica jest pokazana po prawej stronie powyŋszego rysunku. Równolegģe linie przerywane po obu stronach przechodzą przez te najbliŋsze punkty, które są nazywane "wektorami wspierającymi". Poŋądane są granice z moŋliwie największymi marginesami, poniewaŋ lepiej klasyfikują nowe punkty, których nie ma w zestawie treningowym. Oznacza to, ŋe mają lepsze wģaķciwoķci "uogólniające". Wczesna praca nad rozpoznawaniem wzorców (nadzorowanej odmiany uczenia się) w SRI obejmowaģa pewne eksperymenty, w których próbowaliķmy znaležæ granice izolowane od próbek szkoleniowych. Jedna z metod tego polegaģa na szkoleniu próbek pochodzących z oryginalnych poprzez dodanie do nich niewielkiej iloķci "haģasu". Chodziģo o to, aby procedura szkolenia z korekcją bģędów zastosowana do tego rozszerzonego zestawu zostaģa wyparta z oryginalnych próbek. Bardziej elegancka metoda zostaģa zaproponowana przez H. Glucksmana, w której trening korekcji bģędów trwaģ do momentu osiągnięcia minimalnej dozwolonej odlegģoķci między próbkami treningowymi a granicami oddzielenia. Jednak aby zapewniæ moŋliwie duŋe marginesy, konieczne są zģoŋone procedury optymalizacji. Teraz moŋesz zapytaæ , jak uzyskaæ przestrzenie cech, które moŋna liniowo oddzieliæ? Jednym ze sposobów jest uŋycie czegoķ w rodzaju alfa-perceptronu Rosenblatta. Przypomnijmy, ŋe elementy w pierwszej warstwie elementów progowych alfa-perceptronu, powiedzmy N z nich, kaŋdy otrzymaģy swój wģasny wkģad z losowej kolekcji pomiarów danych (takich jak piksele lub wartoķci fali mowy). Wyjķcia binarne tych "jednostek asocjacyjnych" (jak nazywano te elementy pierwszej warstwy) byģy wówczas cechami podobnymi do tych, których uŋyģem w dwuwymiarowym przykģadzie. Okreķlili punkty w N-wymiarowej przestrzeni cech, którą (miaģ nadzieję Rosenblatt) moŋna byģo rozdzieliæ liniowo. Często byģy to prace Rosenblatta. Osoby pracujące z SVM uŋywają róŋnych metod definiowania funkcji. Ich metoda zapewnia, ŋe wynikowa przestrzeņ cech jest liniowo rozdzielalna (a przynajmniej prawie tak). Ich funkcje obejmują uŋycie tego, co nazywają "jądrem", a maszyny korzystające z takich funkcji nazywane są "urządzeniami jądra". Ponownie matematyka jest zbyt zģoŋona, aby ją tu opisaæ, ale zainteresowany czytelnik moŋe spojrzeæ na ksiąŋkę Nello Cristianiniego i John Shawe-Taylor: Jak wskazuje ta ksiąŋka, historia matematyki prowadzącej do maszyn jądra i maszyn SVM sięga początków XX wieku i angaŋowaģa ludzi w teorię optymalizacji, statystyki i teorię uczenia obliczeniowego. a maszyny jądra są doskonaģymi przykģadami tego, w jaki sposób praca w kilku dyscyplinach, przy uŋyciu wysoce technicznego aparatu matematycznego, przyczyniģa się do powstania nowych, zaawansowanych technik w sztucznej inteligencji. Waŋnymi miejscami opisywania nowej pracy w uczeniu maszynowym są sponsorowane przez Neural Information Processing Systems (NIPS) konferencje corocznie przez Fundację Neural Information Processing Systems Foundation, po wysģuchaniu wszystkich opisanych w nim metod uczenia maszynowego rozdziaģ, moŋesz rozsądnie zapytaæ, która metoda jest najlepsza? Naleŋy zastosowaæ metodę najbliŋszego sąsiada, drzewo decyzyjne, sieæ neuronową lub coķ takiego
jeszcze?