Przetwarzanie Języka Naturalnego
Poza rozpoznawaniem wzorów pojedynczych znaków alfanumerycznych, niezaleŋnie od tego, czy są one czcionką staģą czy odręcznie, leŋy problem zrozumienia ciągów znaków tworzących sģowa, zdania lub większe zespoģy tekstu w "naturalnym" języku, takim jak angielski. Aby odróŋniæ języki takie jak angielski od języków uŋywanych przez komputery, te pierwsze są zwykle nazywane "językami naturalnymi". W sztucznej inteligencji "rozumienie" danych wejķciowych w języku naturalnym zwykle oznacza albo konwersję do pewnego rodzaju modelu pamięci (takiego jak ten uŋywany przez Rafaela w jego systemie SIR lub sieæ semantyczna wykorzystywana przez Quilliana) lub wywoģanie pewnych dziaģaņ odpowiednich dla wejķcie. Języki naturalne są mówione i pisane. A poniewaŋ džwięki mowy nie są tak dobrze podzielone na segmenty, jak znaki drukowane na stronie, rozumienie mowy przedstawia dodatkowe trudnoķci. Odwrotnoķcią rozumienia języka naturalnego jest generowanie języka naturalnego - zarówno w mowie, jak i piķmie. Tģumaczenie z jednego języka na inny dotyczy zarówno zrozumienia, jak i generacji. Podobnie jest z kontynuowaniem rozmowy. Wszystkie te problemy (rozumienie, generowanie, tģumaczenie i konwersacja) naleŋą do ogólnej nazwy "przetwarzanie języka naturalnego" (czasami w skrócie NLP).
Poziomy językowe
Lingwiķci i inni uczący się języka rozpoznają kilka poziomów, na których moŋna analizowaæ język. Poziomy te moŋna uģoŋyæ w pewnego rodzaju hierarchię, zaczynając od tych, które dotyczą najbardziej podstawowych skģadników języka (džwięków i częķci sģów) i przechodząc w górę do poziomów zajmujących się sekwencjami zdaņ. Jeķli mowa jest o mowie, istnieją poziomy fonetyki (džwięki językowe) i fonologii (organizacja džwięków w sģowa). Zarówno w mowie, jak i tekķcie, morfologia zajmuje się sposobem ģączenia caģych sģów z mniejszych częķci. Na przykģad "chodzenie" skģada się z "chodzenia" plus "-ing". Następnie skģadnia dotyczy struktury zdaņ i gramatyki. Próbuje opisaæ zasady, wedģug których ciąg sģów w okreķlonym języku moŋe byæ oznaczony gramatycznie lub nie. Na przykģad ciąg "John uderzyģ piģkę" jest gramatyczny, ale ciąg "piģka uderzyģ Jana" nie. Wraz ze sģownikowymi definicjami sģów najwaŋniejsza jest skģadnia dla zrozumienia znaczenia zdania. Na przykģad zdanie "Jan widziaģ czģowieka z teleskopem" ma dwa róŋne znaczenia w zaleŋnoķci od struktury skģadniowej (to znaczy, w zaleŋnoķci od tego, czy "za pomocą teleskopu" odnosi się do "czģowieka", który miaģ teleskop, czy do "zobaczyģ "). Jednak sama gramatyka nie wystarcza do okreķlenia znaczenia. Na przykģad zdanie "Bezbarwne zielone pomysģy ķpią wķciekle" moŋe byæ uwaŋane za gramatyczne, ale jest to nonsensowny. Poziom semantyki pomaga okreķliæ znaczenie (lub bezsensownoķæ) zdania poprzez zastosowanie analiz logicznych. Na przykģad poprzez analizę semantyczną "idea" nie moŋe byæ jednoczeķnie "bezbarwny" i "zielony". Następnie pojawia się poziom pragmatyki, który uwzględnia kontekst zdania, aby okreķliæ znaczenie. Na przykģad "John poszedģ do banku" miaģby inne znaczenie w zdaniu o shing streamie niŋ w zdaniu o handlu. Pragmatyka zajmuje się znaczeniami w kontekķcie konkretnych sytuacji. Jeden z tych poziomów, a mianowicie skģadnia, byģ przedmiotem wielu wczesnych badaņ i nadal jest waŋnym aspektem NLP. W 1957 r. Lingwista amerykaņski Noam Chomsky opublikowaģ przeģomową ksiąŋkę zatytuģowaną "Struktury syntaktyczne", w której zaproponowaģ zestawy reguģ gramatycznych, które moŋna by wykorzystaæ do generowania "legalnych" zdaņ w języku. Te same zasady moŋna równieŋ zastosowaæ do analizy ciągu sģów w celu ustalenia, czy utworzyģy one prawny wyrok w danym języku. Zilustruję sposób przeprowadzania tej analizy przy uŋyciu tego, co Chomsky nazwaģ gramatyką struktury fraz (PSG). Proces ten jest bardzo podobny do tego, w jaki sposób wszyscy powtarzaliķmy zdania w szkole podstawowej. Gramatyki definiuje się, okreķlając zasady zastępowania sģów w ģaņcuchu symbolami odpowiadającymi kategoriom skģadniowym, takim jak rzeczownik, czasownik lub przymiotnik. Gramatyki mają równieŋ zasady zastępowania ciągów tych symboli skģadniowych dodatkowymi symbolami. Aby zilustrowaæ te idee, uŋyję bardzo prostej gramatyki, dostosowanej do jednego z przykģadów Chomsky'ego. Ta gramatyka ma tylko trzy kategorie skģadniowe: okreķlnik, rzeczownik i czasownik. Te trzy elementy są wystarczające do analizy ciągów, takich jak "czģowiek uderzyģ piģkę". Jedna z zasad w tej ilustracyjnej gramatyce mówi, ŋe moŋemy zastąpiæ jedno ze sģów "the" lub "a" symbolem "DET" (dla okreķlenia Lingwiķci piszą tę zasadę w następujący sposób:
the | a → DET
(Symbol | sģuŋy do wskazania, ŋe którekolwiek z otaczających go sģów moŋna zastąpiæ skģadniowym symbolem po prawej stronie strzaģki.) Oto kilka innych zasad, napisanych w tym samym formacie:
man | ball | John → N.
(Sģowa "man", "ball" i "John" moŋna zastąpiæ symbolem "N "dla rzeczownika.)
hit | took | throw → V.
(Sģowa "hit, "took" i "throw "moŋna zastąpiæ symbolem "V "dla czasownika.)
DET N → NP
(Ciąg symboli "DET "i " N" moŋna zastąpiæ symbolem "NP "dla frazy rzeczownik.)
V NP. → VP
(Ciąg symboli "V "i "NP" moŋna zastąpiæ symbolem "VP "dla frazy czasownika).
NP VP → S.
(Ciąg symboli "NP "i "VP" moŋna zastąpiæ symbolem "S "za zdanie.)
Symbole takie jak "S, "DET," "NP, i tak dalej nazywane są "nieterminalnymi" symbolami języka okreķlonego przez gramatykę, podczas gdy sģowa sģownictwa takie jak "ball, "john" i "throw "są symbolami "terminala" języka. Moŋemy zastosowaæ te reguģy do ģaņcucha "czģowiek uderzyģ piģkę", aby przeksztaģciæ go w "S." Mówi się, ŋe kaŋdy ģaņcuch, który moŋna zmieniæ w "S "w ten sposób bądž gramatyczny {prawny wyrok w języku okreķlonym przez tę bardzo prostą gramatykę. Jednym ze sposobów zilustrowania aplikacji reguģ, zwanych drzewem analizy, jest pokazane na poniŋej
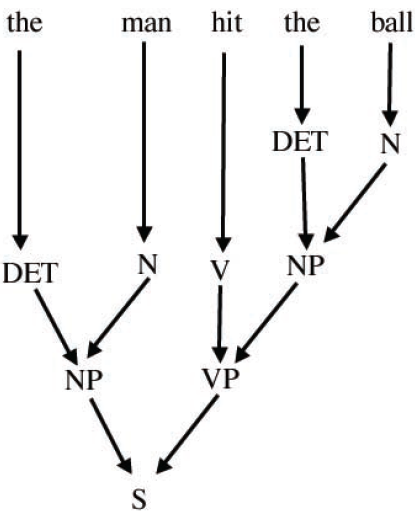
Ten przykģad zostaģ oparty na maģym zestawie kategorii skģadniowych i zasady zastępowania, aby zilustrowaæ gģówne pomysģy dotyczące analizy skģadniowej. Aby gramatyka byģa nieco bardziej realistyczna, musielibyķmy uwzględniæ symbole i reguģy zastępcze dla przymiotników, przysģówków, przyimków i tak dalej. I oczywiķcie musielibyķmy uwzględniæ o wiele więcej sģów sģownych. Gramatyki nazywane są gramatykami bezkontekstowymi (CFG), jeķli wszystkie ich reguģy mają tylko jeden nieterminalny symbol po prawej stronie strzaģki. Nazywa się to tak, poniewaŋ gdy reguģy są uŋywane w odwrotnej kolejnoķci (zamiast generowaæ, a nie analizowaæ zdania gramatyczne), sposób, w jaki symbol nieterminalny jest zastąpiony nie zaleŋy od obecnoķci jakichkolwiek innych symboli. PSG są pozbawione kontekstu. Schemat poniŋszy pokazuje, jak reguģy naszej prostej gramatyki moŋna wykorzystaæ do generowania zdaņ. W tym przypadku zaczyna się od symbolu zdania, a mianowicie "S" i generuje zdanie "John rzuciģ piģkę."
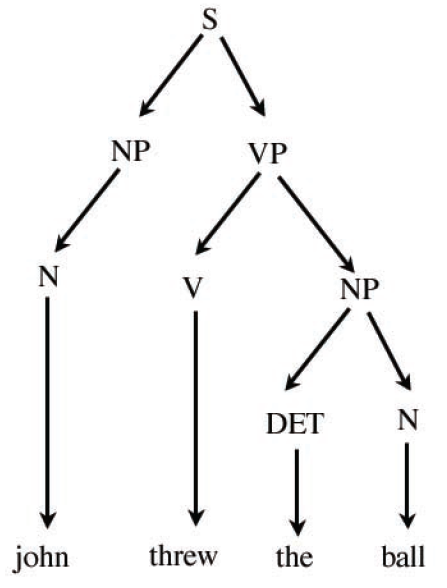
Ta prosta gramatyka z pewnoķcią nie moŋe wygenerowaæ wszystkich zdaņ, które, jak twierdzimy, ŋe jest legalny lub akceptowalny. Generuje takŋe zdania, których normalnie nie chcielibyķmy zaakceptowaæ, na przykģad: "John rzuciģ piģkę". Ksiąŋka Chomsky′ego prezentuje znacznie bardziej zģoŋone gramatyki, a póžniej powstaģy doķæ skomplikowane gramatyki. Na początku lat 60. XX wieku zakodowano kilka gramatyk w programach komputerowych, które potrafią parsowaæ próbki tekstu w języku angielskim. Niemniej jednak nawet najbardziej zģoŋone gramatyki nie mogą czysto rozróŋniaæ zdania, które uznalibyķmy za poprawne gramatycznie, od tych, których byķmy nie zaakceptowali. Sposób, w jaki zdanie jest analizowane przez gramatykę, moŋe determinowaæ jego znaczenie, dlatego waŋną częķcią przetwarzania języka naturalnego jest uŋycie reguģ gramatyki w celu znalezienia akceptowalnych drzew parsowania zdaņ. Znalezienie drzewa analizy wymaga wyszukiwania - na kilka róŋnych sposobów, w jakie nieterminalne symbole, zaczynające się na "S", moŋna zastąpiæ za pomocą reguģ gramatycznych, próbując dopasowaæ zdanie docelowe lub na kilka róŋnych sposobów sģowa w zdaniu docelowym moŋna zastąpiæ nieterminalnymi symbolami w celu uzyskania symbolu "S." Pierwsze z tych wyszukiwaņ nosi nazwę "z góry na dóģ" (od "S" do zdania); drugie nazywa się "z doģu do góry" (od zdania do "S"). Często (jeķli nie zwykle) zdarza się, ŋe z uwagi na gramatykę zdania mogą mieæ więcej niŋ jedno drzewo analizy, kaŋde o innym znaczeniu. Na przykģad "męŋczyzna uderzyģ piģkę w parku" moŋe mieæ drzewo parsowania, w którym "w parku" jest częķcią frazy czasownika wraz z "uderzeniem" lub parsowanie drzewa, w którym "w parku" jest częķcią fraza rzeczownikowa wraz z "piģką". Co więcej, jak juŋ wspomniaģem, niektóre fragmenty zdaņ mogą byæ bez znaczenia. Na przykģad, zgodnie z moją prostą gramatyką, "piģka rzuciģa czģowieka" to zdanie legalne, ale prawdopodobnie bez znaczenia. Decyzja o tym, które drzewo analizy jest odpowiednie, jest częķcią procesu decydowania o znaczeniu i jest zadaniem dla semantyki (a byæ moŋe nawet poziom pragmatyki). Pod koniec lat pięædziesiątych i przez większoķæ lat szeķædziesiątych i póžniej analiza syntaktyczna byģa bardziej rozwinięta niŋ semantyka. Analiza semantyczna zwykle polega na uŋyciu drzewa parsowania do kierowania transformacją zdania wejķciowego w wyraŋenie w jakiejķ studni -de ned "język reprezentujący znaczenie" lub program, który odpowiednio reaguje na zdanie wejķciowe. Na przykģad "męŋczyzna rzuciģ piģkę" moŋe zostaæ przeksztaģcony w wyraŋenie logiczne, takie jak
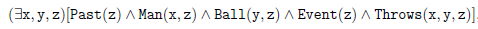
które moŋna zinterpretowaæ jako "istnieją x, y i z , tak ŋe z jest zdarzeniem, które miaģo miejsce w przeszģoķci, x jest męŋczyzną w tym zdarzeniu, y jest piģką w tym zdarzeniu, a x rzuca y w tym zdarzeniu .Analiza semantyczna moŋe równieŋ przeksztaģciæ zdanie "męŋczyzna rzuciģ piģkę" w program, który w pewien sposób symuluje rzucanie piģką w przeszģoķci.
Tģumaczenie maszynowe
Niektóre z pierwszych prób wykorzystania komputerów do wykonywania więcej niŋ zwykģych obliczeņ numerycznych polegaģy na automatycznym tģumaczeniu zdaņ z jednego języka na zdania z drugiego. Sģowniki sģowne mogą byæ przechowywane w pamięci komputera (na taķmach lub na perforowanych kartach) i mogą byæ uŋyte do znalezienia angielskich odpowiedników dla obcych sģów. Uwaŋano, ŋe wybranie odpowiedniego odpowiednika dla kaŋdego obcego sģowa w zdaniu, wraz z niewielką iloķcią analizy skģadniowej, moŋe zostaæ wykorzystane do przetģumaczenia zdania na obcy język (na przykģad z rosyjskiego) na angielski. Raportując o nowym komputerze opracowywanym przez zespóģ prowadzony przez Harry′ego D. Huskeya w National Bureau of Standards (obecnie nazywanym National Institute of Standards and Technology), New York Times poinformowaģ 31 maja 1949 r :
"rodzaj maszyny obliczeniowej "elektryczny mózg", zdolnej nie tylko do wykonywania skomplikowanych problemów matematycznych, ale nawet do tģumaczenia języków obcych, jest w trakcie budowy w Bureau of Standards Laboratory w University of California's Institute of Numerical Analysis. Maszyna nie będzie w polu tģumaczenia ,nie zostaģa podjęta, naukowcy pracujący nad nią twierdzą, ŋe byģoby caģkiem moŋliwe, aby obejmowaģa ona 60 000 sģów z Webster Collegiate Dictionary z odpowiednikami dla kaŋdego sģowa w aŋ trzech językach obcych. urządzenie moŋe wykonaæ tģumaczenie, napisaģ reporter "Timesa", gdy obce sģowo do tģumaczenia jest wprowadzane do maszyny w formie elektro symbol matematyczny na taķmie lub karcie, urządzenie przejdzie przez swoją "pamięæ ", a jeķli uzna ten symbol za rekord, automatycznie wyemituje z góry okreķlony odpowiednik -angielskie sģowo.…"
Wprawdzie będzie to prymitywne tģumaczenie sģowo w sģowo, pozbawione skģadni, ale mimo to będzie niezwykle cenne, projektanci twierdzą, ŋe do takich celów, jak tģumaczenia zagranicznych prac technicznych przez naukowców, w których sģownictwo jest znacznie większym problemem niŋ skģadnia. Maszyna w rzeczywistoķci nie wykonaģa ŋadnych tģumaczeņ - pomysģ zrobienia tego byģ nadal tylko moŋliwoķcią przewidzianą przez Huskey′a. Ale nawet nienaukowcy mogliby sobie wyobraziæ trudnoķci. Artykuģ wstępny w "New York Times" następnego dnia dobrze przedstawiģ problem:
"mamy wątpliwoķci co do dokģadnoķci kaŋdego tģumaczenia. Jak maszyna decyduje, czy francuskie sģowo "pont" ma byæ tģumaczone jako "most" lub "pokģad", czy wiedzieæ, ŋe "operacja" w języku niemieckim oznacza operację chirurgiczną? Wszystko, co maszyna moŋe zrobiæ, to uproķciæ zadanie wyszukiwania sģów w sģowniku i ustawiania ich angielskich odpowiedników na taķmie, tak aby tģumacz wciąŋ musiaģ oprawiæ odpowiednie zdania i nadaæ sģowom znaczenie kontekstowe."
W liķcie do Norberta Wienera z 1947 r. Warren Weaver, matematyk i administrator nauki, wspomniaģ o moŋliwoķci wykorzystania komputerów cyfrowych do tģumaczenia dokumentów między naturalnymi ludzkimi językami. Wiener wątpiģ w tę moŋliwoķæ. W odpowiedzi dla Weavera Wiener napisaģ:
"Szczerze mówiąc, obawiam się, ŋe granice sģów w róŋnych językach są zbyt niejasne, a konotacje emocjonalne i międzynarodowe są zbyt rozlegģe, aby jakikolwiek quasi-mechaniczny schemat tģumaczenia byģ bardzo obiecujący".
Niemniej jednak do lipca 1949 r. Weaver opracowaģ swoje pomysģy w memorandum zatytuģowanym "Tģumaczenie", które przesģaģ kilku kolegom. Weaver rozpocząģ swoją notatkę od stwierdzenia, co następuje:
"Nie trzeba nic więcej robiæ niŋ wspomnieæ o oczywistym fakcie, ŋe róŋnorodnoķæ języków utrudnia kulturową wymianę między ludami ziemi i stanowi powaŋny czynnik odstraszający od międzynarodowego zrozumienia. Niniejsze memorandum, zakģadające waŋnoķæ i znaczenie tego faktu, zawiera kilka uwag i sugestii dotyczących moŋliwoķci wniesienia przynajmniej częķciowego rozwiązania problemu tģumaczenia na caģym ķwiecie za pomocą komputerów elektronicznych o duŋej pojemnoķci, elastycznoķci i prędkoķæ."
Wedģug redaktorów opublikowanego tomu, w którym memorandum zostaģo przedrukowane,
"kiedy wysģaģ go do okoģo 200 swoich znajomych w róŋnych krajach, byģa to dosģownie pierwsza sugestia, ŋe większoķæ kiedykolwiek widziaģa, ŋe tģumaczenie języka za pomocą technik komputerowych jest moŋliwe. "
Dokumentowi Weavera często przypisuje się zainicjowanie pola tģumaczenia maszynowego (często w skrócie MT). W czerwcu 1952 r. W MIT Yehoshua Bar-Hillel, izraelski logik, który byģ wówczas w Laboratorium Badawczym ds. Elektroniki MIT, zorganizowaģ pierwszą konferencję poķwięconą tģumaczeniu maszynowemu. Początkowo optymistycznie nastawiony do moŋliwoķci, Bar-Hillel doszedģ do wniosku, ŋe peģne automatyczne tģumaczenie jest niemoŋliwe. W styczniu 1954 r. W gģównej siedzibie IBM World przy 57th Street i Madison Avenue w Nowym Jorku zademonstrowano automatyczne tģumaczenie próbek rosyjskiego tekstu na angielski. Demonstracja, przy uŋyciu maģego sģownictwa i ograniczonej gramatyki, byģa wynikiem wspóģpracy między IBM a Georgetown University. Projektem kierowali Cuthbert Hurd, dyrektor Departamentu Nauk Stosowanych w IBM i Lonon Dostert z Georgetown. Wedģug komunikatu prasowego IBM 10 z 8 stycznia 1954 r. rosyjski zostaģ po raz pierwszy przetģumaczony na angielski przez "mózg". Krótkie wypowiedzi na temat polityki, prawa, matematyki, chemii, metalurgii, komunikacji i spraw wojskowych zostaģy przekazane w języku rosyjskim przez lingwistów z Georgetown University Institute of Languages and Linguistics do sģynnego komputera 701 International Business Machines Corporation. A gigantyczny komputer w ciągu kilku sekund przeksztaģciģ zdania w czytelny angielski. Dziewczyna, która nie rozumiaģa ani sģowa języka Sowietów, wyrzuciģa rosyjskie wiadomoķci na kartach IBM. "Mózg" wysģaģ swoje angielskie tģumaczenia na automatycznej drukarce z zawrotną prędkoķcią dwóch i póģ linii na sekundę.
"Mi pyeryedayem mislyi posryedstvom ryechyi", w[pisaģa dziewczyna.
A 701 odpowiedziaģ:
" Przekazujemy myķli za pomocą Mowa."
Chociaŋ demonstracja wywoģaģa wiele emocji i doprowadziģa do zwiększenia funduszy na badania nad tģumaczeniem, póžniejsze prace w terenie byģy rozczarowujące. Po ocenie pracy MT w opublikowanym raporcie z 1959 r. wķród badaczy, Bar-Hillel przekonaģ się, ŋe w peģni automatyczne tģumaczenie wysokiej jakoķci (które nazwaģ FAHQT) nie byģo moŋliwe "nie tylko w niedalekiej przyszģoķci, ale w ogóle". Jego rozszerzony raport ukazaģ się w artykule z 1960 r., który cieszyģ się szerokim rozpowszechnieniem. Jednym z czynników prowadzących Bar-Hillela do jego negatywnych wniosków byģa widoczna trudnoķæ w zapewnieniu komputerom "wiedzy o ķwiecie" potrzebnej do tģumaczenia wysokiej jakoķci. Zilustrowaģ problem następującą historią:
Maģy John szukaģ swojego pudeģka z zabawkami. W koņcu go znalazģ. Pudeģko byģo w piórze. John byģ bardzo szczęķliwy. Jak tģumaczyæ "Pudeģko byģo we piórze"? Bar-Hillel argumentowaģ, ŋe nawet gdyby istniaģy tylko dwie definicje "pióra" (przybory do pisania i obudowa, w której bawią się maģe dzieci), komputer znający tylko te definicje nie byģby w stanie zdecydowaæ, które znaczenie jest zamierzone. Oprócz znajomoķci sģownictwa i skģadni komputer tģumaczący musiaģby znaæ "względne rozmiary piór w sensie pisania narzędzia, pudeģka z zabawkami i dģugopisy, w sensie kojców" .Tą wiedzę, jak twierdziģ Bar-Hillel, nie dysponowaģ komputer elektroniczny. Powiedziaģ, ŋe przekazanie komputerowi takiej encyklopedycznej wiedzy jest" caģkowicie chimeryczne i prawie na nic nie zasģuguje dalsza dyskusja".
Jak póžniej przyznali póžniej naukowcy, Bar-Hillel miaģ rację co do tego, ŋe wysoce kompetentne systemy przetwarzania języka naturalnego (a wģaķciwie ogólnie rzecz biorąc, ogólnie wszechstronne systemy sztucznej inteligencji) będą musiaģy posiadaæ wiedzę encyklopedyczną. Jednak większoķæ badaczy AI nie zgadza się z nim co do bezcelowoķci próby przekazania komputerom wymaganej wiedzy encyklopedycznej. Bar-Hillel byģ znany z tego, ŋe byģ trochę niemiģy w kwestii sztucznej inteligencji. (Komentując artykuģ Johna McCarthy′ego "Programy ze zdrowym rozsądkiem" na konferencji w Teddington w 1958 r., Bar-Hillel powiedziaģ: "Artykuģ dr McCarthy′ego naleŋy do Journal of Half-Baked Ideas, którego stworzenie niedawno zaproponowaģ dr IJ Good. ")
W kwietniu 1964 r. Narodowa Akademia Nauk utworzyģa Komitet Doradczy ds. Automatycznego Przetwarzania Języków (ALPAC), którego przewodniczącym byģ John R. Pierce z Bell Laboratories, aby "doradzaæ Departamentowi Obrony, Centralnej Agencji Wywiadowczej oraz National Science Foundation o badaniach i rozwoju w dziedzinie mechanicznego tģumaczenia języków obcych. " Komitet opublikowaģ swój raport w sierpniu 1965 r. I stwierdziģ między innymi, ŋe "nie ma bezpoķredniej ani przewidywalnej perspektywy przydatnego tģumaczenia maszynowego". Zalecili wsparcie dla podstawowej nauce o językoznawstwie i "pomoce" w tģumaczeniu, ale nie w celu dalszego wsparcia w peģni automatycznego tģumaczenia. Raport spowodowaģ radykalne ograniczenie finansowania na duŋą skalę badaņ nad tģumaczeniem maszynowym. Niemniej tģumaczenie maszynowe przetrwaģo i ostatecznie rozkwitģo, co zobaczymy póžniej. Stowarzyszenie Tģumaczeņ Maszynowych i Lingwistyki Komputerowej (AMTCL) odbyģo swoje pierwsze spotkanie w 1962 r. W 1968 r. Zmieniģo nazwę na Stowarzyszenie Lingwistyki Komputerowej (ACL) i staģo się międzynarodowym towarzystwem naukowym i zawodowym dla osób pracujących nad problemami związanymi z język naturalny i obliczenia. Wydaje kwartalnik Lingwistyka obliczeniowa oraz sponsoruje konferencje i warsztaty.
Odpowiedzi na pytania
Oprócz pracy nad tģumaczeniem maszynowym badacze zaczęli badaæ, w jaki sposób zdania w języku naturalnym, takim jak angielski, moŋna wykorzystaæ do komunikacji z komputerami. Przypomnisz sobie program ELIZA firmy Weizenbaum, który byģ w stanie zaangaŋowaæ osobę w rozmowę, mimo ŋe program "nie zrozumiaģ" niczego o tym, co zostaģo powiedziane. Wspomniaģem juŋ o systemie SIR Rafaela, który mógģby reprezentowaæ przekazane mu informacje, a następnie odpowiadaæ na pytania. Wspomnę o kilku innych projektach, które mają w tym okresie pochwaliæ się przetwarzaniem języka naturalnego. Program o nazwie BASEBALL (napisany w IPL-V, specjalnym języku programowania do przetwarzania list opracowanym przez Newella, Shawa i Simona) zostaģ opracowany w Lincoln Laboratory pod kierunkiem Berta Greena, profesora psychologii na Carnegie Institute of Technology. Potrafiģ odpowiedzieæ na proste angielskie pytania dotyczące baseballu, korzystając z bazy danych o grach baseballowych rozgrywanych w Ameryce w ciągu jednego roku. Na przykģad moŋe odpowiedzieæ na pytanie takie jak "Gdzie grali Red Sox 7 lipca?" Pytania musiaģy mieæ szczególnie prostą formę i ograniczaæ się do sģów w sģowniku programu. Wedģug autorów Pytania są ograniczone do jednej klauzuli; zakazując struktur z klauzulami zaleŋnymi, analiza skģadniowa jest znacznie uproszczona. Logiczne poģączenia, takie jak i, lub, i nie, są zabronione, podobnie jak konstrukcje sugerujące relacje jak najbardziej i najwyŋsze. Wreszcie pytania dotyczące kolejnych faktów, takie jak "Czy Red Sox wygrali kiedykolwiek szeķæ gier z rzędu?" są zakazane. Program dziaģaģ, przeksztaģcając pytanie w specjalną formę zwaną "listą specyfikacji", wykorzystując zarówno specjalne analizy skģadniowe, jak i analizy semantyczne. Ta lista byģaby następnie wykorzystana do uzyskania dostępu do bazy danych programu w celu znalezienia odpowiedzi na pytanie. Na przykģad pytanie "Gdzie grali Red Sox w dniu 7 lipca? "Zostanie najpierw przekonwertowane na listę:
Miejsce =?
Druŋyna = Red Sox
Miesiąc = lipiec
Dzieņ = 7
Autorzy twierdzili, ŋe ich "ograniczenia byģy tymczasowymi ķrodkami, które zostaną usunięte w póžniejszych wersjach programu" .O ile mi wiadomo, nie byģo póžniejszych wersji programu. (Jak zobaczymy, jak rozwinie się moja historia sztucznej inteligencji, jest kilka przypadków, w których bardzo trudno byģo usunąæ "tymczasowe "ograniczenia.). Inny program w języku naturalnym, SAD SAM, zostaģ napisany w IPL-V w 1962 -1963 r. przez Roberta Lindsaya w Carnegie Institute of Technology. Moŋe analizowaæ angielskie zdania na temat relacji rodzinnych i zakodowaæ te relacje w drzewie genealogicznym. Korzystając z drzewa, mógģby następnie odpowiedzieæ na angielskie pytania dotyczące związków. Na przykģad, jeķli SAD SAM otrzymaģo zdanie "Joe i Jane są potomstwem Toma, "stworzyģoby strukturę listy drzewa dla pewnej" jednostki rodzinnej ", w której Tom jest ojcem, a Joe i Jane są dzieæmi. otrzymaģ zdanie "Mary jest matką Jane", dodaģoby Mary do tej struktury jako ŋony Toma. Wtedy byģby w stanie odpowiedzieæ na pytanie "Kim jest matka Joe?" SAD SAM jest akronimem dla Rzeczoznawców Zdaņ, Diagrammera i Analiz Semantycznych Maszyny. Częķæ SAD przeanalizowaģa zdania wejķciowe i przekazaģa je do SAM, który wyodrębniģ informacje semantyczne potrzebne do budowy drzew genealogicznych i znalezienia odpowiedzi na pytania. Akceptuj szeroką gamę zdaņ w podstawowym języku angielskim - system gramatyki i sģownictwo okoģo 850 sģów okreķlonych przez Charlesa K. Ogdena ,Roberta F. Simmonsa, psychologa i językoznawcy w Systems Development Corporation (SDC) ) w Santa Monica w Kalifornii , miaģ większe cele dla wģasnej pracy w przetwarzaniu języka naturalnego. Wedģug strony "In Memoriam" autorstwa Gordona Novaka, jednego z jego doktorów. Marzeniem Simmonsa byģo to, ŋe moŋna byģo "rozmawiaæ z ksiąŋką", komputer czytaģ ksiąŋkę, a następnie uŋytkownik mógģ z nią porozmawiaæ, zadając pytania, na które naleŋy odpowiedzieæ, rozumiejąc ksiąŋkę . Osiągnięcie tego "marzenia" okazaģoby się równie trudne jak sama sztuczna inteligencja. W notatce z 1961 r. o swoim projekcie "Synthex" Simmons opisaģ, jak powinien zacząæ:
Celem tego projektu jest opracowanie metodologii badawczej i pojazdu do projektowania i budowy ogólnego przeznaczenia skomputeryzowany system do syntezy zģoŋonych ludzkich funkcji poznawczych. Pierwotny pojazd, proto-synthex, będzie podstawowym urządzeniem do przetwarzania języka, które odczytuje proste materiaģy drukowane i odpowiada na proste pytania sformuģowane w podstawowym języku angielskim."
W 1965 r. Simmons i Lauren Doyle przeprowadzili eksperymenty z systemem Protosynthex. Wedģug raportu Trudi Bellardo Hahna:
"W systemie zaģadowano maģą prototypową bazę peģnotekstową rozdziaģów encyklopedii dziecięcej (Golden Book). Protosynthex mógģ odpowiedzieæ na proste pytania w języku angielskim z" odpowiedzią ". […] byģ pionierem w uŋywaniu języka naturalnego do wyszukiwania tekstu ".
W międzyczasie doktor Daniel G. Bobrow , student Marvina Minsky′ego na MIT, napisaģ zestaw programów, zwanych systemem STUDENT, które mogģyby rozwiązaæ problemy z algebrą / historią podane w ograniczonym podzbiorze języka angielskiego. Oto przykģad problemu, który STUDENT mógģby rozwiązaæ:
Odlegģoķæ z Nowego Jorku do Los Angeles wynosi 3000 mil. Jeķli… ķrednia prędkoķæ samolotu odrzutowego wynosi 600 mil na godzinę oraz czas podróŋy samolotem z Nowego Jorku do Los Angeles. STUDENT rozwiązaģ problem, wykorzystując pewne znane zaleŋnoķci dotyczące prędkoķci i odlegģoķci do skonfigurowania i rozwiązania odpowiednich równaņ. Praca Bobrowa podaģa kilka innych przykģadów problemów, które STUDENT mógģ rozwiązaæ, oraz zastosowanych metod.