Postęp w NLP
Jak wspomniano wczeķniej, problemy ze zrozumieniem, generowaniem i tģumaczeniem materiaģów w zwykģych językach ludzkich (a nie komputerowych) naleŋą do kategorii przetwarzania języka naturalnego. Podczas fazy "wczesnych eksploracji" badaņ nad sztuczną inteligencją poczyniono pewne dobre początki dotyczące problemów NLP. W kolejnej fazie, od koņca lat szeķædziesiątych do wczesnych lat siedemdziesiątych, na tych fundamentach opracowano nowe prace, co opiszę w tej częķci ksiąŋki.
Tģumaczenie maszynowe
W. John Hutchins, który napisaģ obszernie o historii tģumaczenia maszynowego (MT), nazwaģ lata 1967-1976 "spokojną dekadą". Brak aktywnoķci w tym okresie wynika częķciowo z raportu ALPAC, co, jak juŋ powiedziaģem, byģo pesymistyczne co do perspektyw tģumaczenia maszynowego. Hutchins stwierdziģ:
"Raport ALPAC byģ gģęboki. Przez ponad dekadę wirtualnie zakoņczyģ badania MT w USA, a MT przez wiele lat postrzegano jako caģkowitą poraŋkę. . . . Dziaģalnoķæ MT przeniosģa się ze Stanów Zjednoczonych na Kanadę i Europę. "
Jednym z wyjątków od tego trwającego dekadę zastoju w Stanach Zjednoczonych byģo opracowanie programu tģumaczeņ Systran (System Translator) autorstwa Petr Toma, komputerowca urodzonego na Węgrzech naukowca i językoznawcę, który pracowaģ nad systemem tģumaczeņ rosyjsko-angielskiego w Georgetown W 1968 r. Toma zaģoŋyģ firmę o nazwie Latsec, Inc. w La Jolla w Kalifornii, aby kontynuowaæ prace rozwojowe Systran, które rozpocząģ wczeķniej w Niemczech Siģy powietrzne Stanów Zjednoczonych zawarģy umowę na opracowanie systemu tģumaczeņ z języka rosyjskiego na angielski. Przetestowano go na początku 1969 r. W bazie siģ powietrznych Wright-Patterson w Dayton w stanie Ohio, gdzie nadal zapewnia rosyjskie {angielskie tģumaczenia dla Departamentu Technologii Zagranicznych USAF do dziķ. "Systran ewoluowaģ jako jeden z gģównych automatycznych systemów tģumaczeņ. Jest sprzedawany przez Imageforce Corporation w Tampie na Florydzie. Jak dobrze Systran tģumaczy? Wszystko zaleŋy jak chce się mierzyæ wydajnoķæ. Margaret Boden wymienia dwie miary, a mianowicie "zrozumiaģoķæ" i "poprawnoķæ". Oba te ķrodki zaleŋą od ludzkiego osądu. Po pierwsze, pytamy: "Czy tģumaczenie moŋna ogólnie zrozumieæ?" Po drugie, pytamy: "Czy ludzcy" redaktorzy "muszą zmodyfikowaæ tģumaczenie?" Boden twierdzi, ŋe "w dwuletnim okresie od 1976 do 1978 r. zrozumiaģoķæ tģumaczeņ generowanych przez Systran wzrosģa z 45 do 78 procent dla [wprowadzania tekstu surowego]." Zauwaŋa równieŋ, ŋe tģumaczenia ludzkie mają tylko 98 do 99 procent , nie 100 procent. Jeķli chodzi o poprawnoķæ, Boden twierdzi, ŋe w 1978 r. "Tylko 64 procent sģów pozostaģo nietkniętych przez post-redaktorów. Mimo to, ludzka post-edycja strony wyników Systran zajęģa tylko dwadzieķcia minut w poģowie lat osiemdziesiątych, podczas gdy normalne ( tģumaczenie w peģni ludzkie) zajęģoby godzinę.
Zrozumienie
Chociaŋ przeģom lat szeķædziesiątych i siedemdziesiątych mógģ byæ "cichą dekadą" w tģumaczeniu maszynowym, byģ to bardzo aktywny okres dla innych prac NLP. W tych latach badacze zastosowali znacznie silniejsze zdolnoķci syntaktyczne, semantyczne i wnioskowania do problemu zrozumienia języka naturalnego. Typową dla nowego podejķcia byģa obserwacja doktora Terry′ego Winograda, doktora MIT pod koniec lat 60. XX wieku: Jeķli naprawdę chcemy, aby komputery nas rozumiaģy, musimy daæ im moŋliwoķæ korzystania z większej wiedzy. do gramatyki języka, muszą mieæ wszelkiego rodzaju wiedzę na temat, który omawiają, i muszą uŋyæ rozumowania, aby poģączyæ fakty we wģaķciwy sposób, aby zrozumieæ zdanie i odpowiedzieæ na nie. Proces rozumienia zdania musi ģączyæ gramatykę, semantykę i rozumowanie w bardzo intymny sposób, wzywając kaŋdą stronę do pomocy innym.
13.2.1 SHRDLU
Byæ moŋe osiągnięciem NLP, które wywoģaģo największe podekscytowanie, byģ system dialogowy języka naturalnego SHRDLU zaprogramowany przez Terry′ego Winograda dla jego doktoratu. Rozprawa (podu Seymoura Paperta) w MIT SHRDLU byģa w stanie prowadziæ dialog na temat tego, co Winograd nazwaģ "mikroķwiatem", ķwiatem skģadającym się z bloków zabawek i "chwytaka" do ich przemieszczania. W przeciwieņstwie do ķwiata prawdziwych bloków uŋywanych w poprzednich badaniach MIT i Stanforda, ķwiat bloków Winograda byģ symulowany na komputerze DEC PDP-10 i oglądany na czarno-biaģym ekranie graficznym DEC 340, takim jak pokazany poniŋej
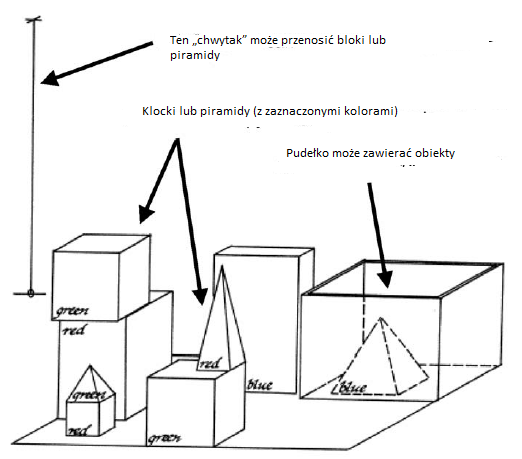
SHRDLU moŋe otrzymaæ polecenia wpisane zwykģym angielskim, aby manipulowaæ blokami za pomocą jego chwytaka. Moŋna by równieŋ zadawaæ pytania o stan jego ķwiata. Mógģ "zrozumieæ" te polecenia i pytania, wykonaæ ŋądane manipulacje i zadaæ uŋytkownikowi wyjaķnienie pytaņ w języku angielskim na temat pytaņ lub poleceņ, których nie rozumiaģ. Przed opisaniem czegoķ na temat projektu SHRDLU, spójrzmy na przykģad częķci okna dialogowego. Poniŋej dane wejķciowe uŋytkownika są ponumerowane i pokazane maģymi literami, a odpowiedž SHRDLU jest pisana wielkimi literami, komentarz Winograda następuje tym samym krojem pisma, a mój w nawiasach normalnym typem:
1. podnieķ duŋy czerwony blok.
Aby podnieķæ czerwony blok, musisz go usunąæ aby odszukaæ miejsce na zielony i przesuņ zielony z dala.
OK
System odpowiada "OK", gdy wykonuje polecenie.
(Nie zawracam sobie gģowy pokazaniem, jak wygląda konfiguracja bloku w trakcie dialogu, zakģadając, ŋe moŋesz uŋyæ wģasnego modelu umysģu "do ķledzenia rzeczy". Chwytak trzyma teraz czerwony blok.)
2. chwyæ piramidę.
Na scenie są trzy piramidy, więc program nic nie robi.
NIE ZROZUMIEM, CO OZNACZA. PIRAMIDA
3. znajdž blok, który jest wyŋszy niŋ ten, który trzymasz i umieķæ go w pudeģku. (Uŋytkownik najwyražniej teraz zmieniģ zdanie na temat chwytania piramid). System musi ustaliæ, co naleŋy rozumieæ przez "jeden" i "to", a takŋe za pomocą dedukcji, aby zdecydowaæ, który blok trzyma.
"IT", PRZYJMUJĘ, ŊE OZNACZASZ BLOK, KTÓRY JEST WYŊSZY NIŊ TEN KTÓRY TRZYMAM.
Wydrukowano, aby nas informowaæ. Ręka musi odģoŋyæ czerwony blok, aby podnieķæ wyŋszy niebieski.
OK.
4. co zawiera pudeģko?
NIEBIESKI PIRAMIDA I NIEBIESKI BLOK.
5. na czym opiera się piramida?
Wczeķniej system odpowiedziaģ "piramidą", mówiąc
"Nie rozumiem, którą piramidę masz na myķli". teraz wie, ŋe musimy mieæ na myķli ten, o którym wģaķnie wspomniano.
PUDEĢKO
To okno dialogowe ilustrujące moŋliwoķci SHRDLU jest kontynuowane dla czterdziestu dwóch dodatkowych danych wejķciowych i odpowiedzi systemowych. Aby zaangaŋowaæ się w takie dialogi, SHRDLU potrzebowaģa "wiedzy. "Musiaģa wiedzieæ o skģadni uŋywanej częķci języka angielskiego i musiaģa wiedzieæ, co oznaczają róŋne sģowa i kombinacje sģów w kontekķcie ich uŋycia. wiedzieæ o ķwiecie bloków {jak manipulowaæ blokami i co to znaczy, ŋe obiekt znajduje się w "pudeģku". Musiaģ ķledziæ okno dialogowe, aby mógģ zdecydowaæ, do którego obiektu wspomniano wczeķniej sģowo takie jak "to", o którym mowa. Caģa ta potrzebna wiedza byģa reprezentowana w programach LISP lub "procedurach", jak je nazywaģ Winograd. Wiedza na temat skģadni byģa reprezentowana jako zbiór procedur opartych na zasadach "gramatyki systemowej". Wiedza o znaczeniu sģów w kontekķcie byģa reprezentowana w procedurach, które mogģyby odnosiæ się do sģownika znaczeņ sģów, do innych częķci zdania, w którym uŋyto tego sģowa, oraz do dyskursu. Wiedza na temat ķwiata bloków byģa reprezentowana na dwa sposoby: istniaģ model, który podawaģ lokalizacje wszystkich obiektów oraz istniaģy procedury, które mogą wnioskowaæ o przewidywanych efektach (w modelu) manipulacji przez chwytak na róŋnych obiektach. Procedury przemieszczania obiektów zawieraģy informacje zarówno o warunkach wstępnych, jak i o skutkach tych manipulacji. Procedury te zostaģy zakodowane w wersji języka PLANNER firmy Hewitt, która, jak wspomniano wczeķniej, byģa w pewnym stopniu podobna do operatorów STRIPS. Zastosowano dodatkowe procedury w języku PLANNER dla innych rodzajów wnioskowania potrzebnych przez system. Reguģy logiczne zostaģy wyraŋone jako programy, które byģy w stanie dokonywaæ zarówno dedukcji do przodu, jak i do tyģu. Procesy SHRDLU do rozumienia języka moŋna podzieliæ na trzy częķci, a mianowicie skģadnię, semantykę i wnioskowanie, ale jest to nieco wprowadzające w bģąd, poniewaŋ wzajemne oddziaģywanie tych częķci byģo kluczową cechą systemu. Jak stwierdziģ Winograd:
"Poniewaŋ kaŋdy kawaģek wiedzy moŋe byæ procedurą, moŋe on przywoģaæ dowolną inną wiedzę dowolnego rodzaju". Na przykģad Winograd napisaģ: "Gdy wyszukuje kaŋdy kawaģek struktury syntaktycznej, sprawdza jego semantyczny interpretacji, najpierw, aby sprawdziæ, czy jest to prawdopodobne, a następnie (jeķli to moŋliwe), aby sprawdziæ, czy jest to zgodne ze znajomoķcią systemu przez ķwiat, zarówno konkretną, jak i ogólną."
Proceduralne przedstawienie wiedzy przez Winograd (wraz z językiem Hewitta PLANNER do kodowania takich reprezentacji) moŋna skontrastowaæ z wykorzystaniem przez McCarthy′ego formuģ logicznych do deklaratywnego reprezentowania wiedzy. Sukces SHRDLU podsyciģ debatę wķród badaczy AI na temat zalet i wad tych dwóch strategii reprezentacji wiedzy - proceduralnej kontra deklaratywnej. W rzeczywistoķci uŋycie LISP do reprezentowania procedur zaciera to rozróŋnienie do pewnego stopnia, poniewaŋ, jak zauwaŋyģ Winograd, "LISP pozwala nam traktowaæ programy jako dane, a dane jako programy". Tak więc, chociaŋ wiedza SHRDLU byģa reprezentowana proceduralnie, byģa w stanie wģączyæ do swoich procedur pewną nową deklaratywną wiedzę (przedstawianą jako zdania angielskie). Wydajnoķæ HRDLU byģa naprawdę imponująca i wzbudziģa optymizm wķród niektórych badaczy języka naturalnego odnoķnie przyszģego sukcesu. Jednak Winograd wkrótce porzuciģ tę linię badaņ na rzecz pracy nad interakcją komputerów i ludzi. Byæ moŋe dlatego, ŋe miaģ doķwiadczenie z pierwszej ręki, ile wiedzy byģo potrzebne do udanego rozumienia języka w czymķ tak prostym, jak ķwiat bloków, dlatego nie chciaģ dawaæ komputerom wystarczającej wiedzy, aby powieliæ peģny zakres ludzkich umiejętnoķci werbalnych. W e-mailu z 2004 roku Winograd umieķciģ umiejętnoķci SHRDLU w kontekķcie umiejętnoķci ludzi: istnieją fundamentalne róŋnice między sposobem dziaģania SHRDLU i jego krewnych, a tym, co dzieje się w naszych mózgach. Nie sądzę, aby obecne badania poczyniģy duŋy postęp w przekraczaniu tej przepaķci, a odpowiednia nauka moŋe potrzebowaæ dziesięcioleci lub więcej, aby dojķæ do punktu, w którym początkowe ambicje stają się realistyczne. W międzyczasie AI zajęģa się znacznie bardziej wykonalnymi celami pracy w mniej ambitnych niszach lub akceptowania wyników innych niŋ ludzkie (jak w tģumaczeniu),
LUNAR
Po powrocie z pierwszego zaģogowego lądowania na Księŋycu astronauci Apollo 11 przynieķli kilka kilogramów księŋycowych skaģ do badaņ naukowych. Róŋne dane o tych skaģach byģy przechowywane w bazach danych, do których geologowie i inni naukowcy mieli dostęp. Aby uģatwiæ wyszukiwanie tych informacji geologom księŋycowym, NASA zapytaģa Williama A. Woodsa, mģodego informatyka z BBN, o moŋliwoķæ zaprojektowania pewnego rodzaju "frontonu" w języku naturalnym, aby zamiast tego moŋna byģo przeszukiwaæ bazy danych w języku angielskim w tajemnym kodzie komputerowym. Woods wģaķnie ukoņczyģ doktorat, badania na Harvardzie o systemach odpowiadania na pytania. Sponsorowany przez zaģogowe centrum kosmiczne NASA, koledzy Woodsa z BBN, Ron Kaplan i Bonnie Webber, opracowali system, który nazwali "LUNAR", odpowiadając na pytania dotyczące skaģ księŋycowych. LUNAR uŋyģ obu procesów syntaktycznych i semantycznych przeksztaģcające angielskie pytania w zapytania do bazy danych księŋycowej skaģy. Analizę syntaktyczną przeprowadzono przy uŋyciu "rozszerzonych sieci przejķciowych" (ATN), metodologii opracowanej przez Woodsa podczas jego doktoratu na Harvardzie. Skģadnik semantyczny, kierowany przez drzewa parsowania pochodzące z ATN, przeksztaģciģy zdania angielskie w coķ, co Woods nazwaģ "znaczeniem języka reprezentacji" (MRL). Ten język byģ językiem logicznym ( jak rachunek predykatów), ale rozszerzony o procedury, które moŋna wykonaæ. MRL zostaģ pierwotnie opracowany przez Woodsa z Harvardu i rozwinięty w BBN. LUNAR byģ w stanie "zrozumieæ" i odpowiedzieæ na wiele róŋnych pytaņ, w tym na przykģad: "Jakie jest ķrednie stęŋenie glinu w skaģach o wysokiej zawartoķci alkaliów?" "Ile brekcji zawiera oliwin?" "Co to jest?" (LUNAR uznaģ, ŋe "odnoszą się" do brekcji wymienionych jako odpowiedzi na ostatnie pytanie.) LUNAR byģ pierwszy system odpowiadający na pytania sģuŋący do publikowania danych dotyczących wyników. Udaģo mu się odpowiedzieæ z powodzeniem na 78% pytaņ zadanych mu przez geologów podczas drugiej dorocznej konferencji naukowej poķwięconej Księŋycowi, która odbyģa się w Houston w styczniu 1971 r. Podobno 90% byģoby odpowiedzią w stanie z "drobnymi porawkami" do systemu. W przemówieniu LUNAR z czerwca 2006 r. Woods wspomniaģ o niektórych jego ograniczeniach. Poniŋsze okno dialogowe ilustruje jedną wadę:
Uŋytkownik: Co to jest breccia?
LUNAR: S10018.
Uŋytkownik: Co to jest S10018?
LUNAR: S10018.
Woods powiedziaģ:
"LUNAR po prostu odnajduje odniesienia do wyraŋeņ odsyģających i podaje ich nazwy. Nie ma modelu celu za pytaniem uŋytkownika ani róŋnego rodzaju odpowiedzi dla róŋnych celów".
Chociaŋ LUNAR mógģ rozpoznaæ kilka róŋnych sposobów sformuģowania zasadniczo tego samego pytania, Woods stwierdziģ, ŋe "istnieją inne ŋądania, które (z powodu ograniczeņ w obecnej gramatyce) muszą zostaæ okreķlone w okreķlony sposób, aby gramatyka je parsowaģa i tam są inne, które są rozumiane przez interpretatora semantycznego tylko wtedy, gdy są okreķlone w okreķlony sposób. "
Rozszerzone sieci przejķciowe
Wiele osób zdaģo sobie sprawę, ŋe gramatyki bezkontekstowe (takie jak te, które omówiģem wczeķniej) byģy zbyt sģabe do większoķci praktycznych aplikacji do przetwarzania języka naturalnego. Na przykģad, gdybyķmy rozszerzyli gramatykę ilustracyjną, tak aby obejmowaģa (oprócz "rzucania" i "uderzania" i "czģowieka") czasowniki teražniejsze "rzut", "rzuty" i "uderza" i rzeczownik w liczbie mnogiej "męŋczyžni", wówczas sznurki "męŋczyžni uderzają piģkę" i "czģowiek rzuca piģkę" byģyby niewģaķciwie przyjęte jako zdania gramatyczne. Aby rozszerzyæ gramatykę bezkontekstową, wymagając, ŋe rzeczowniki i czasowniki muszą się zgadzaæ co do liczby wymagaģoby niepraktycznie duŋego zbioru zasad. Ponadto uwzględnienie zdaņ pasywnych, takich jak "piģka zostaģa trafiona przez męŋczyzn", wymagaģoby jeszcze dalszego dopracowania. Najwyražniej tego rodzaju zdania, które geolodzy mogliby zadaæ na temat skaģ księŋycowych, wymagaģy silniejszych gramatyk -takich jak rozbudowane sieci przejķciowe, które Woods i inni opracowali. W ksiąŋce Chomsky'ego z 1957 roku zaproponowaģ hierarchię systemów gramatycznych, których gramatyki bezkontekstowe byģy tylko jednym przykģadem. Jego potęŋniejsze gramatyki miaģy "komponent transformacyjny" i byģy w stanie, na przykģad, aby przeanalizowaæ zdanie takie jak "piģka zostaģa trafiona przez męŋczyznę" i nadaæ mu taką samą "gģęboką strukturę", jak w przypadku zdania "męŋczyzna uderzyģ piģkę". Rozszerzone gramatyki sieci przejķciowej mogą równieŋ wykonywaæ tego rodzaju transformacje, ale w sposób bardziej satysfakcjonujący obliczeniowo. Rozszerzona sieæ przejķciowa jest podobną do mapy strukturą graficzną, w której węzģy reprezentują punkty postępu w procesie analizowania, a ķcieŋki ģączące dwa węzģy reprezentują kategorie skģadniowe. Moŋemy myķleæ o analizowaniu zdania jako przemierzaniu ķcieŋki przez sieæ od węzģa początkowego (brak postępów) do węzģa koņcowego (gdzie zdanie zostaģo pomyķlnie przetworzone). Przemierzanie ķcieŋki buduje strukturę skģadniową zdania w postaci drzewa parsowania. Analiza zdania polega na odrywaniu sģów od lewej do prawej i uŋyciu ich do wskazania ķcieŋki w sieci. Analiza syntaktyczna moŋe rozpocząæ się od oderwania pojedynczego sģowa i wyszukania z leksykonu, czy jest to rzeczownik, okreķlnik, pomocnik (taki jak "robi"), przymiotnik lub inna "koņcowa" kategoria skģadniowa. Lub moŋe zacząæ od oderwania grupy sģów i sprawdzenia, czy ta grupa byģa frazą rzeczownikową, frazą czasownikową, frazą przyimkową lub czymķ innym. W pierwszym przypadku, w zaleŋnoķci od kategorii pojedynczego sģowa, wybralibyķmy ķcieŋkę odpowiadającą tej kategorii prowadzącej z węzģa początkowego. Aby uwzględniæ drugi przypadek, istniaģyby moŋliwe ķcieŋki odpowiadające wyraŋeniu rzeczownikowi i innym moŋliwym kategoriom skģadniowym wyŋszego poziomu. Ale jak zdecydowalibyķmy, na przykģad, czy moŋemy podjąæ ķcieŋkę rzeczownikową? Woods i inni zaproponowali odpowiedž, ŋe będą istniaģy dodatkowe sieci przejķciowe odpowiadające tym kategoriom wyŋszego poziomu. Moglibyķmy obraæ ķcieŋkę rzeczownikową w gģównej sieci przejķciowej tylko wtedy, gdybyķmy mogli pomyķlnie przejķæ przez sieæ rzeczownikową. A poniewaŋ jedna ķcieŋka w sieci wyraŋeņ rzeczownikowych moŋe zaczynaæ się od wyraŋenia przyimkowego, musielibyķmy sprawdziæ, czy moglibyķmy podąŋaæ tą ķcieŋką (w sieci wyraŋeņ rzeczownikowych), pomyķlnie przechodząc przez sieæ wyraŋeņ przyimkowych. Proces ten byģby kontynuowany, gdy jedna sieæ "dzwoni" do innych sieci w sposób podobny do tego, w jaki program moŋe ponownie uruchomiæ (lub "wywoģaæ") inne programy, byæ moŋe rekurencyjnie. Z tego powodu takie sieci są nazywane rekurencyjnymi sieciami przejķciowymi. Pierwsze sieci tego rodzaju opracowali James Thorne, Paul Bratley i Hamish Dewar na University of Edinburgh w Szkocji. Póžniej Dan Bobrow i Bruce Fraser zaproponowali system sieci przejķciowej . Oba te systemy wykonaģy równieŋ obliczenia pomocnicze podczas przechodzenia przez swoje sieci. Te "rozszerzenia" pozwoliģy na zbudowanie "gģębokiej struktury" reprezentacji analizowanego zdania. Praca Woodsa nad "rozszerzonymi, rekurencyjnymi sieciami przejķciowymi" opieraģa się na tych ideach i wprowadzaģa do nich elegancki język definicji sieci. Jako przykģad Woods opisaģ, jak jedna z jego sieci przeanalizowaģa zdanie "Uwaŋano, ŋe John zostaģ zastrzelony". Po wykonaniu wszystkich poģączeņ do sieci pomocniczych i wszystkich obliczeņ pomocniczych uzyskano drzewo analizy przedstawione poniŋej
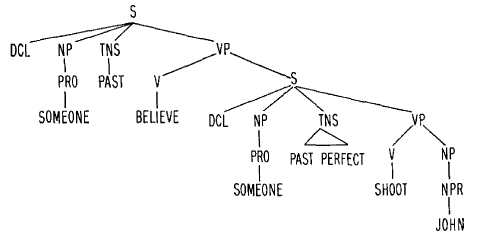
Moŋemy obserwowaæ dwie rzeczy dotyczące tego drzewa analizy. Najpierw zwróæ uwagę na występowanie "PAST" i "PAST PERFECT" jako znaczników czasu. Po drugie, zauwaŋ, ŋe forma oryginalnego zdania z pasywnym gģosem zostaģa przeksztaģcona w zdanie z aktywnym gģosem, uŋywając przypuszczalnego zaimka "Ktoķ". Jak zauwaŋa Woods, strukturę moŋna sparafrazowaæ jako "Ktoķ uwierzyģ, ŋe ktoķ zastrzeliģ Johna". Gramatyki sieciowe uzyskują "gģęboką strukturę" zdaņ, przeksztaģcając je następnie w standardową formę.
GUS
Dan Bobrow i Ronald Kaplan, dwaj naukowcy wykonujący pracę NLP w BBN, przeprowadzili się do nowo utworzonego Centrum Badawczego Palo Alto (PARC) w Xerox w poģowie lat 70. XX wieku. Jednym z projektów, nad którymi pracowali tam oni i inni badacze, byģ GUS (akronim Genial Understander System), który miaģ "angaŋowaæ sympatycznego i wysoce wspóģpracującego czģowieka w angielski dialog, ukierunkowany na konkretny cel w bardzo ograniczonym zakresie dziedzina dyskursu ". Ograniczoną domeną byģa agencja turystyczna prowadząca "rozmowę z klientem, który chce odbyæ prostą podróŋ powrotną do jednego miasta w Kalifornii". Poniŋsza transkrypcja rzeczywistego okna dialogowego pokazuje niektóre z jej umiejętnoķci:
GUS: Czeķæ. Mam na imię GUS. Mogę pomóc Ci zaplanowaæ prostą podróŋ samolotem. Gdzie chcesz jechaæ?
(1) Klient: Chcę jechaæ do San Diego 28 maja.
GUS: O której chcesz wyjķæ?
(2) Klient: Muszę byæ w San Diego przed 10 rano.
GUS: Czy chciaģbyķ P.S.A. czy 102, która przyjeŋdŋa o godz. 9.15?
(3) Klient: jaki jest następny lot?
GUS: Air California 310, który odjeŋdŋa o godz. 8.30 i przyjeŋdŋa o godz. 10.00.
(4) Klient: wezmę pierwszy.
GUS: W czyim imieniu powinienem dokonaæ rezerwacji?
(5) Klient: Dan Bobrow.
GUS: Zatwierdziģem następującą walkę: P.SA. lot 102 w ķrodę 28 maja z San Jose do San Diego, który odjeŋdŋa o godz. 7.30 i przybywa o godz. 9.15. Kiedy chcesz wróciæ?
(6) Klient: w piątek wieczorem.
GUS: Czy chciaģbyķ lot, który wyjdzie o 19:45?
(7) Klient: Ķwietnie
GUS: Zatwierdziģem następujący lot: P.S.A. lot 307 w piątek 30 maja z San Diego do San Jose, który wylatuje o 19:45 i przylatuje o 21.30. Dzięki, ŋe zadzwoniģeķ. Do widzenia.
Chociaŋ moŋliwoķci systemu byģy z pewnoķcią ograniczone, GUS byģ w stanie poradziæ sobie z wieloma problemami. Jeden z nich dotyczy tego, co badacze NLP nazywają "rozwiązywaniem anafory", przez co rozumieją obiekty lub zdarzenia, do których odnoszą się róŋne sģowa lub frazy w oknie dialogowym. Kilka przykģadów, wpisanych w zdania numerowane w powyŋszym oknie dialogowym, wymieniono w artykule o GUS. Na przykģad w wierszu (3) zapytanie klienta odnosi się do kģótni wspomnianych w wypowiedzi GUS bezpoķrednio poprzedzającej. W (4) jest odniesienie do walki wspomnianej wczeķniej w rozmowie, [po linii (2)]. Zauwaŋ, ŋe "następna walka" w (3) miaģa byæ interpretowana w odniesieniu do kolejnoķci walk w przewodniku linii lotniczych, podczas gdy "pierwsza" w (4) odnosi się do kolejnoķci, w jakiej wspomniane byģy walki. Kolejne ukryte odniesienie leŋy u podstaw uŋycia "piątku" do okreķlenia daty w (6). Rozwiązanie tego odniesienia wymaga skomplikowanego uzasadnienia obejmującego zarówno treķæ, jak i kontekst rozmowy. Poniewaŋ 28 maja podano jako datę wyjazdu, klient prawdopodobnie musi byæ w następny piątek. Z drugiej strony zaģóŋmy, ŋe specyfikacje zostaģy odwrócone, a piątek podano jako datę wyjazdu w wierszu (1). Byģoby to wtedy najģatwiejsze do zinterpretowania jako odnoszące się do piątku bezpoķrednio po rozmowie. GUS byģ kombinacją kilku komunikujących się podsystemów, a analizator morfologiczny do radzenia sobie ze skģadnikami sģów, analizator skģadniowy do generowania drzew parsowanych, "uzasadnienie" pozwalające poznaæ znaczenie i intencje uŋytkownika oraz generator języka odpowiadający. Kontrolowanie tych komponentów odbywaģo się za pomocą mechanizmu "porządku obrad". Jak wyjaķniają autorzy, GUS dziaģa w cyklu, w którym analizuje ten program, wybiera następne zadanie do wykonania i robi to. Zasadniczo wykonanie wybranego zadania powoduje, ŋe wpisy dotyczące nowych zadaņ są tworzone i umieszczane w porządku obrad. Generowanie tekstu wyjķciowego moŋna w dowolnym momencie wywoģaæ za pomocą procesów wnioskowania, a dane wejķciowe od klienta są obsģugiwane za kaŋdym razem, gdy się pojawią. Są miejsca, w których informacje z póžniejszego etapu (na przykģad dotyczące semantyki) są przekazywane z powrotem do wczeķniejszego etapu ( takich jak parser). Proces nadzorczy moŋe zmieniæ porządek obrad w dowolnym momencie. Skģadniowy skģadnik GUS miaģ "dostęp do gģównego sģownika zawierającego ponad 3000 rdzeni i prostych idiomów". Analizator skģadniowy zostaģ oparty na systemie opracowanym wczeķniej przez Ronalda Kaplana, który wykorzystywaģ gramatykę sieci przejķciowej i zostaģ nazwany "Ogólnym procesorem syntaktycznym". Zdania klientów zostaģy zakodowane w "ramkach" (które są związane z ramkami Minsky′ego, ale bliŋej w formie sieci semantycznych). Niektóre ramki opisują sekwencję normalnego dialogu, podczas gdy inne przedstawiają atrybuty daty, planu podróŋy lub podróŋny. Skģadnik wnioskowania GUS wykorzystaģ zawartoķæ i strukturę ramek, aby wydedukowaæ, jak najlepiej interpretowaæ zdania klientów .Oprócz anafory w dokumencie wspomniano o kilku innych problemach, z którymi GUS byģ w stanie poradziæ sobie. Ostrzegģ jednak równieŋ, ŋe "o wiele ģatwiej jest ekstrapolowaæ z [przykģadowego okna dialogowego] bģędne przekonanie, ŋe GUS zawiera rozwiązania znacznie większej liczby problemów niŋ miaģo to miejsce". Przykģadowe dialogi zarejestrowane między ludzkimi klientami a ludžmi odgrywającymi rolę GUS ujawniģy liczne przypadki awarii komputera GUS. Autorzy doszli do wniosku, ŋe jeķli uŋytkownicy systemów takich jak GUS odstąpią "od zachowania, którego się od nich oczekują w najdrobniejszych szczegóģach, lub jeķli pozornie nieznaczne zmiany zostaną wprowadzone do struktury a systemy dziaģaģyby tak, jakby miaģy "raŋącą afazję"lub po prostu umarģy. Autorzy przyznali, ŋe" sam GUS nie jest bardzo inteligentny, ale ilustruje to, co uwaŋamy za niezbędne elementy [rozumienia języka inteligentnego ] system… [Musi mieæ wysokiej jakoķci analizator skģadni, komponent uzasadnienia i dobrze ustrukturyzowaną bazę wiedzy. "Kolejne prace nad NLP w PARC i wielu innych miejscach miaģy na celu ulepszenie wszystkich tych komponentów. Systemy opracowane przez badaczy takich jak Winograd , Woods, Bobrow i ich koledzy byli bardzo imponującymi krokami w kierunku konwersacji z komputerami w języku angielskim, ale wciąŋ byģo wiele do zrobienia, zanim systemy rozumienia języka naturalnego będą mogģy dziaģaæ w sposób przewidziany przez Winograda we wstępie do jego doktoratu. rozprawa: wyobražmy sobie nowy sposób korzystania z komputerów, aby mogli oni przyjmowaæ instrukcje w sposób odpowiadający ich pracy. Porozmawiamy z nimi tak, jak rozmawiamy z asystentem naukowym, bibliotekarzem lub sekretarką, a oni przeprowadzą nasze polecenia i przekaŋ nam informacje, o które prosimy. Jeķli nasze instrukcje nie będą wystarczająco jasne, poproszą o nie