Systemy rozpoznawania mowy i rozumienie
Przetwarzanie mowy
Opisane juŋ systemy NLP wymagaģy, aby ich angielski byģ wprowadzany w formacie tekstowym. Istnieje jednak kilka przypadków, w których rozmowa z komputerem byģaby lepsza niŋ pisanie na raz. Ludzie zazwyczaj mówią szybciej niŋ potrafią pisaæ (okoģo trzech sģów na sekundę w porównaniu z jednym sģowem na sekundę) i mogą mówiæ podczas ruchu. Ponadto mówienie nie wiąŋe rąk ani oczu. Przy omawianiu problemu komputerowego przetwarzania mowy waŋne jest, aby wprowadziæ pewne rozróŋnienia. Jedna dotyczy róŋnicy między rozpoznaniem izolowanego sģowa mówionego a przetwarzaniem ciągģego strumienia mowy. Większoķæ badaņ nad AI koncentruje się na drugim i trudniejszym z tych problemów. Kolejnym rozróŋnieniem jest rozpoznawanie mowy i rozumienie mowy. Przez rozpoznawanie mowy rozumie się proces przeksztaģcania strumienia akustycznego mowy wprowadzonej przez mikrofon i powiązany sprzęt elektroniczny w tekstową reprezentację sģów skģadowych. Proces ten jest trudny, poniewaŋ wiele strumieni akustycznych brzmi podobnie, ale skģada się z zupeģnie innych sģów. (Rozwaŋmy na przykģad wypowiadane wersje "Istnieje wiele sposobów rozpoznawania mowy" i "Istnieje wiele sposobów na zniszczenie ģadnej plaŋy"). Z kolei rozumienie mowy wymaga zrozumienia tego, co się mówi. Moŋna powiedzieæ, ŋe wypowiedž naleŋy rozumieæ, jeķli wywoģuje ona odpowiednie dziaģanie lub odpowiedž, a moŋe to byæ nawet moŋliwe bez rozpoznania wszystkich jej sģów. Zrozumienie mowy jest trudniejsze niŋ zrozumienie tekstu, poniewaŋ istnieje dodatkowy problem przetwarzania ksztaģtu fali mowy w celu wyodrębnienia wypowiadanych sģów. Mowa uchwycona przez mikrofon jest przeksztaģcana na sygnaģ elektroniczny lub przebieg, który moŋna wyķwietliæ na oscyloskopie. Na poniŋszym rysunku pokazano przebieg wygenerowany przez osobę mówiącą: "To jest test".
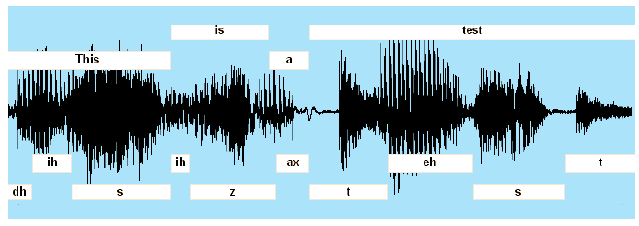
Ten schemat pokazuje amplitudę (napięcie) wykreķlonego sygnaģu mowy w funkcji czasu. Sekcje ksztaģtu fali odpowiadające sģowom są oznaczone ramkami u góry diagramu. Pola u doģu pokazują akustyczne elementy tych sģów, które nazywane są "telefonami". Zasadniczo telefony to džwięki odpowiadające samogģosek i spóģgģosek. Uwaŋa się, ŋe angielska mowa skģada się z okoģo czterdziestu róŋnych telefonów. Opracowano specjalne alfabety do reprezentowania telefonów. Jednym z nich jest Międzynarodowy Alfabet Fonetyczny (IPA), który zawiera telefony wszystkich znanych języków. IPA uŋywa kilku znaków specjalnych, które nie mają standardowych kodów komputerowych (ASCII). Kolejnym, zawierającym tylko telefony uŋywane w amerykaņskim języku angielskim i uŋywającymi tylko standardowych znaków, jest ARPAbet, który zostaģ opracowany podczas badaņ przetwarzania mowy sponsorowanych przez DARPA. Telefony pokazane na ryc. 17.1 uŋywają notacji ARPAbet. Tabela pokazuje telefony ARPAbet i przykģadowe sģowa je zawierające.

Wczesne systemy rozpoznawania mowy próbowaģy najpierw podzieliæ segment fali mowy na telefony skģadowe, a następnie zģoŋyæ telefony w porządki. Aby to zrobiæ, sygnaģ mowy zostaģ najpierw zdigitalizowany i wyodrębniono róŋne parametry, takie jak częstotliwoķæ lub wysokoķæ tonu. Sposoby zmiany wartoķci tych parametrów w czasie wykorzystano do podzielenia ksztaģtu fali na jednostki zawierające telefony. Uŋywając sģowników, które ģączą wartoķci parametrów ksztaģtu fali z telefonami i telefonami ze sģowami, ksztaģt fali zostaģ ostatecznie przeksztaģcony w tekst. Proces ten wydaje się prosty, ale w rzeczywistoķci jest doķæ zģoŋony, poniewaŋ między innymi początki i zakoņczenia wypowiadanych sģów oraz ich skģadowe telefony nakģadają się na siebie w zģoŋone wzory, a ludzie często wymawiają te same sģowa na róŋne sposoby. Na przykģad sģowo "ty" moŋna wymawiaæ inaczej w "czy jesteķ" [aa r y uw] i "did you" [d ih d jh uh]. Próby rozpoznania mowy rozpoczęģy się w Bell Laboratories juŋ w latach 30. XX wieku. W 1952 r. Inŋynierowie z Bell Labs zbudowali system rozpoznawania liczb od "zero" do "dziewięæ" wypowiadanych przez jeden gģoķnik. Inne prace wykonano w latach 50. i 60. w RCA Laboratories, w MIT, w Japonii, w Anglii i w Związku Radzieckim Praca przyspieszyģa w latach 70. XX wieku, a niektóre z nich opiszę póžniej.
Grupa analityczna rozumiejąca mowę
Larry Roberts, który pod koniec 1966 r. Wyjechaģ do DARPA jako "gģówny naukowiec" w biurze technik przetwarzania informacji (IPTO), a póžniej zostaģ jego dyrektorem, zaintrygowaģ pomysģ budowy systemów, które mogģyby rozumieæ mowę. Cordell Green, peģniąc wówczas funkcję porucznika w armii amerykaņskiej, zostaģ przydzielony do IPTO pod rządami Robertsa na początku 1970 r. I powierzono mu finansowanie i monitorowanie projektów badawczych dotyczących AI. Wedģug Greena Roberts powiedziaģ mu: "Wykonaj studium wykonalnoķci systemu rozpoznającego mowę". A pod koniec marca 1970 roku Green zorganizowaģ spotkanie na Carnegie Mellon University z kilkoma kontrahentami DARPA i innymi zainteresowanymi przetwarzaniem mowy, aby omówiæ wykonalnoķæ rozumienia mowy przez komputer. Uczestnikami spotkania byli badacze z SDC, Lincoln Laboratory, MIT, CMU, SRI i BBN. Na spotkaniu zdecydowano o utworzeniu "grupy analitycznej" w celu oceny stanu techniki i sformuģowaniu zaleceņ dotyczących uruchomienia duŋego projektu wspieranego przez DARPA w zakresie rozumienia mowy. Grupie miaģ przewodniczyæ Allen Newell z CMU. Podczas marcowego spotkania przekonano Robertsa do rozmowy o rodzaju systemu rozumienia mowy, który miaģ na myķli. Zgodnie z interpretacją uwag przedstawionych w raporcie, Roberts myķlaģ o systemie, który mógģby zaakceptowaæ ciągģą mowę od wielu wspóģpracujących uŋytkowników, przez telefon, przy uŋyciu sģownictwa 10 000 sģów, z mniej niŋ 10% bģędem semantycznym, w kilku przypadkach realnego czasu. Grupa analityczna odbyģa swoje pierwsze spotkanie w BBN w dniach 26 i 27 maja 1970 r. Podczas tego spotkania grupa rozwaŋyģa niektóre szczególne zadania, w które mógģby się zaangaŋowaæ system rozumienia. Odpowiadanie na pytania dotyczące zarządzania danymi, odpowiadanie na pytania dotyczące stanu operacyjnego komputera i konsultowanie systemu operacyjnego komputera. Ostatnie spotkanie grupy odbyģo się w SDC w Santa Monica w dniu 28 lipca 1970 r. Zaleceniem grupy (w skrócie) byģo dąŋenie do systemu, który byģby w stanie zaakceptowaæ nieprzerwaną mowę od wielu wspóģpracujących mówców "ogólnego dialektu amerykaņskiego" przez mikrofon dobrej jakoķci (nie przez telefon), przy uŋyciu wybranego sģownictwa zģoŋonego z 1000 sģów (a nie 10 000 sģów), z "wysoce sztuczną skģadnią", obejmującą zadania takie jak zarządzanie danymi lub status komputera (ale bez konsultacji), z mniejszym niŋ 10% bģędem, kilka razy w czasie rzeczywistym, i byæ moŋliwe do wykazania w 1976 (nie 1973) z umiarkowanym szansa na sukces. Raport koņcowy grupy zostaģ sporządzony po spotkaniu, dostarczony do DARPA i ostatecznie opublikowany w 1973 roku. Chociaŋ wczeķniej wiele badaņ dotyczących przetwarzania mowy przez komputer (ģadnie podsumowane w raporcie grupy analitycznej), nie wszyscy byli optymistami co do sukcesu . Jednym z niewiadomych byģ John R. Pierce, badacz z Bell Laboratories, gdzie juŋ wiele pracy nad rozpoznawaniem mowy miaģo miejsce. W 1969 r. Pierce napisaģ list do Journal of Acoustical Society of America, w którym stwierdziģ, ŋe większoķæ ludzi pracujących nad mową
"zachowywaģo się jak szaleni naukowcy i niewiarygodni inŋynierowie. Typowy rozpoznawca wpada mu do gģowy, ŋe moŋe rozwiązaæ problem".
W tym samym liķcie napisaģ równieŋ, ŋe
"… wydajnoķæ byģaby nadal bardzo ograniczona, chyba ŋe urządzenie do rozpoznawania będzie rozumieæ, co mówi się w jakimķ sensie o rodzimym języku mówionym (to znaczy lepiej niŋ obcokrajowiec, który zna język). Jeķli tak, to czy ludzie powinni kontynuowaæ prace nad rozpoznawaniem mowy? Byæ moŋe to decyzja naleŋy do ludzi w tej dziedzinie."
Program badawczy dotyczący rozumienia mowy DARPA
Praca w BBN
SPEECHLIS byģ pierwszym systemem rozumienia mowy opracowanym w BBN. Zostaģ zaprojektowany, aby odpowiadaæ na pytania mówione na temat bazy danych skaģ księŋycowych (tej uŋywanej we wczeķniejszym systemie LUNAR BBN). Byģ raczej powolny i nie byģ systematycznie testowany. HWIM zostaģ zaprojektowany jako automatyczny asystent menedŋera budŋetu podróŋy i byģ w stanie odpowiedzieæ na pytania mówione, takie jak "Ile pozostaģo w budŋecie na rozumienie mowy?" W swojej ostatecznej wersji HWIM zostaģ przetestowany na dwóch wersjach, z których kaŋda ma szeķædziesiąt cztery róŋne wypowiedzi przez trzy męskie gģoķniki. Trzydzieķci jeden z tych zdaņ byģo wczeķniej uŋywanych przez system w trakcie jego projektowania, więc mogģa istnieæ jakaķ domyķlna (choæ niezamierzona) wbudowana dodatkowa moŋliwoķæ radzenia sobie z tymi zdaniami. Zdania miaģy dģugoķæ od trzech do trzynastu sģów. HWIM byģ w stanie poprawnie odpowiedzieæ na 41% zdaņ i "zamknąæ" poprawnie na 23% więcej zdaņ. System w ogóle nie zareagowaģ na 20% zdaņ. Chociaŋ zarówno SPEECHLIS, jak i HWIM byģy pionierami nowych i waŋnych metod rozumienia mowy, wydajnoķæ HWIM byģa ogólnie uwaŋana za niespeģniającą pierwotnych celów DARPA. (Ich projektanci twierdzili, ŋe test nie wskazywaģ na potencjaģ HWIM i ŋe mogliby zrobiæ to lepiej, mając więcej czasu.)
Praca w CMU
W 1969 r. Raj Reddy opuķciģ Stanford, aby zostaæ czģonkiem wydziaģu Carnegie Mellon University. Jeden z pierwszych systemów mowy, nad którymi pracowaģ wraz z kolegami w CMU, nazywaģ się HEARSAY (póžniej przemianowany na HEARSAY-I) .1Uŋywaģ wielu niezaleŋnych procesów obliczeniowych do rozpoznawania mówionych ruchów w szachach z danej pozycji na planszy, takich jak " pionek króla przenosi się do goņca czwartego. "Na wczesnych etapach tej pracy DARPA utworzyģa Grupę Badającą Zrozumienie Mowy i rozpoczęģa pracę nad rozumieniem mowy. W czerwcu 1972 r. odbyģa się publiczna demonstracja HEARSAY-I rozpoznawania powiązanej mowy. Trzy róŋne systemy rozpoznawania i rozumienia mowy zostaģy opracowane w CMU pod patronatem wysiģków badawczych DARPA w zakresie rozumienia mowy. Byģy to DRAGON, HARPY i HEARSAY-II i wszystkie one wniosģy waŋne pomysģy na sztuczną inteligencję. Prace nad tymi systemami prowadzili Allen Newell, Raj Reddy, James Baker, Bruce Lowerre, Lee Erman, Victor Lesser i Rick Hayes-Roth.
DRAGON
We wczesnych dniach badaņ nad zrozumieniem mowy CMU, doktorat. James K. Baker, rozpocząģ pracę nad systemem rozumienia mowy, który nazwaģ "DRAGON". (Wedģug Allena Newella nazwa DRAGON miaģa na celu "wskazaæ, ŋe byģa to zupeģnie inna bestia niŋ systemy AI rozwaŋane w pozostaģej częķci mowy". Podobnie jak HEARSAY-I, DRAGON zostaģ zaprojektowany tak, aby zrozumieæ zdania o ruchy szachowe DRAGON wprowadziģ nowe, potęŋne techniki przetwarzania mowy - których opracowania są stosowane w większoķci nowoczesnych systemów rozpoznawania mowy. Wykorzystaģ techniki statystyczne do zgadywania najbardziej prawdopodobnych ciągów sģów, które mogģy wytworzyæ obserwowany sygnaģ mowy. wczesny przykģad importu reprezentacji probabilistycznych i powiązanych metod obliczeniowych do AI. Spróbuję wyjaķniæ gģówne idee bez uŋycia duŋej matematyki. Zaģóŋmy, ŋe pozwalamy x staæ na ciąg sģów i y oznacza falę mowy, która powstaje, gdy wypowiadane jest x. (W rzeczywistoķci pozwolimy y byæ pewną zachowującą informację reprezentacją fali pod względem jej ģatwo mierzalne wģaķciwoķci, takie jak iloķæ energii zawartej w ksztaģcie fali w róŋnych pasmach częstotliwoķci. Dla uproszczenia będę nadal nazywaģ przebieg falowy, chociaŋ mam na myķli jego reprezentację, która moŋe byæ róŋna dla róŋnych systemów rozumienia mowy.) Poniewaŋ ten sam mówca moŋe wypowiadaæ te same sģowa nieco inaczej przy róŋnych okazjach, a róŋni mówcy z pewnoķcią będą powiedzmy inaczej, ciąg sģowa x nie okreķla caģkowicie, jaki będzie przebieg fali mowy y. To znaczy, biorąc pod uwagę dowolny x, moŋemy jedynie powiedzieæ, jakie są prawdopodobieņstwa róŋnych y. Te prawdopodobieņstwa zapisano w formie funkcjonalnej jako p(y | x) (odczytywane jako "prawdopodobieņstwo y podane x"). Zasadniczo rzeczywiste wartoķci p(y|x) dla niektórych szczególnych x, powiedzmy x = X, moŋna oszacowaæ, na przykģad, przez liczbę gģoķników wypowiadających ciąg sģów X wiele razy i zestawienie, jak często róŋne przebiegi mowy y pojawiæ się. Ten proces musiaģby zostaæ powtórzony dla wielu róŋnych ciągów sģów. SMOK uniknąģ tego ŋmudnego zestawienia w sposób, który zostanie wkrótce wyjaķniony. Jednak do rozpoznawania mowy chcemy poznaæ prawdopodobieņstwo ciągu sģów x, biorąc pod uwagę sygnaģ mowy y, abyķmy mogli wybraæ najbardziej prawdopodobne x. Oznacza to, ŋe chcemy p (x | y) zamiast p (y | x). Moŋemy uŋyæ reguģy Bayesa jak wczeķniej, aby uzyskaæ poŋądane prawdopodobieņstwo w następujący sposób:
p (x | y) = p (y | x) p (x) = p (y):
Po zaobserwowaniu okreķlonego ksztaģtu fali, powiedzmy y = Y, oto, w jaki sposób uŋyjemy wielkoķci w tej formule, aby zdecydowaæ, który ciąg sģowa x najprawdopodobniej zostaģ wypowiedziany:
1. Wyszukaj wszystkie wartoķci p (Y | x) dla wszystkich rozwaŋanych wartoķci x. (Nie musimy tego robiæ dla wszystkich moŋliwych ciągów sģów, ale tylko dla tych dozwolonych przez sģownictwo i skģadnię specjalistycznego obszaru odpowiedniego do zadania rozumienia mowy - szachy porusza się w przypadku DRAGON).
2. Pomnóŋ kaŋdą z tych wartoķci przez p(x). (Decyzja powinna byæ stronnicza w stosunku do prawdopodobnych ciągów sģów).
3. Wybierz x, powiedzmy X, dla którego produkt jest największy. [Moŋemy zignorowaæ dzielenie przez p (y), poniewaŋ jego wartoķæ nie wpģywa na to, które p (x | Y) jest największe.]
Chociaŋ proces ten dziaģaģby w zasadzie, jest jednak niepraktyczny obliczeniowo. Zamiast tego DRAGON i inne nowoczesne systemy rozpoznawania mowy wykorzystują hierarchiczną strukturę zaangaŋowaną w sposób, w jaki zakģada się sposób generowania fali mowy. W tej hierarchii istnieją róŋne poziomy, które moŋna zidentyfikowaæ. Aby nieco uproķciæ, na szczycie hierarchii dana idea semantyczna jest wyraŋana przez ciąg sģów przestrzegających reguģ skģadniowych języka. Z kolei ciąg sģów powoduje powstanie szeregu telefonów (jednostek fonetycznych). Wreszcie, ciąg telefonu jest wyraŋany przez przebieg mowy na dole hierarchii. Na kaŋdym poziomie mamy sekwencję bytów, powiedzmy x1; x2; … xn, wytwarzając sekwencję innych bytów, powiedzmy y1; y2;… yn. Moŋemy przedstawiæ schemat procesu, jak pokazano poniŋej
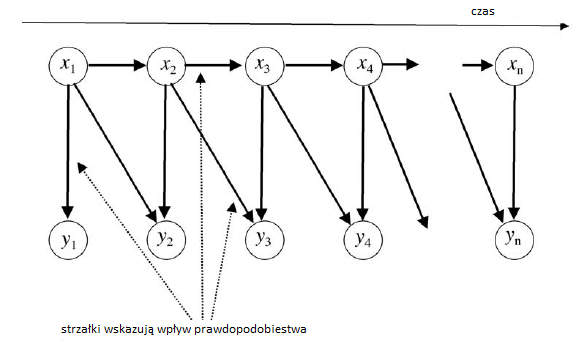
System DRAGON przyjąģ pewne uproszczenia. Zakģadano, ŋe na kaŋdy xi w sekwencji x wpģyw ma tylko jego bezpoķredni precedens, xi-1, a nie ŋaden inny z xi. To zaģoŋenie nazywa się zaģoŋeniem Markowa. [Andrey Andreyevich Markov byģ rosyjskim matematykiem. Uŋyģ (jak się póžniej nazwano) modelu Markowa do analizy statystyki sekwencji 20 000 rosyjskich listów zaczerpniętych z powieķci Puszkina Eugeniusza Oniegina. Modele Markowa są szeroko stosowane w fizyce i Inŋynierii. Google wykorzystuje na przykģad zaģoŋenie Markowa obliczenie rangi strony.] Oczywiķcie wiemy, ŋe kaŋde sģowo w sekwencji zaleŋy od czegoķ więcej niŋ tylko sģowa bezpoķrednio poprzedzającego. Mimo to zaģoŋenie Markowa upraszcza obliczenia i zapewnia dobrą wydajnoķæ. Ponadto zaģoŋono, ŋe na kaŋdy yi wpģywają tylko xi i xi-1. Wszystkie te "wpģywy" są probabilistyczne. To znaczy, biorąc pod uwagę wielkoķci takie jak na przykģad x3 i x4, wartoķæ y4 nie jest caģkowicie okreķlona. Moŋna jedynie powiedzieæ, jakie mogą byæ prawdopodobieņstwa wartoķci yi; są one podane przez wyraŋenie funkcjonalne p (y4 | x3; x4). Wartoķci prawdopodobieņstwa dla y są zatem podawane przez tak zwaną "funkcję probabilistyczną procesu Markowa". Aby uzyskaæ oszacowania tych prawdopodobieņstw, statystyki mogą byæ gromadzone podczas "procesu uczenia się" (w którym mówca wypowiada zestaw zdaņ szkoleniowych). DRAGON poģączyģ te oddzielne poziomy w sieæ skģadającą się z hierarchii probabilistycznych funkcji procesów Markowa. Elementy reprezentujące segmenty fali mowy znajdowaģy się na dole, podmioty reprezentujące telefony znajdowaģy się na ķrodku, a podmioty reprezentujące sģowa na górze. Na kaŋdym poziomie zastosowano zasadę Bayesa do obliczenia prawdopodobieņstwa x dla danych y. Poniewaŋ faktycznie obserwowano tylko przebieg mowy na najniŋszym poziomie, telefony i sģowa byģy "ukryte". Z tego powodu w caģej sieci zastosowano ukryte modele Markowa (HMM). DRAGON byģ pierwszym przykģadem uŋycia HMM w AI. Zostaģy one wczeķniej opracowane do innych celów. Korzystając z tej sieci, rozpoznanie wypowiedzi zostaģo następnie osiągnięte przez znalezienie ķcieŋki o najwyŋszym prawdopodobieņstwie w sieci. Obliczanie zdolnoķci do syntaktycznie prawidģowych sekwencji sģów, biorąc pod uwagę sekwencję segmentów obserwowanego ksztaģtu fali mowy, jest problemem podobnym do tego, który opisaģem wczeķniej, a mianowicie obliczaniem konsekwencji ciągów znaków na arkuszach kodujących FORTRAN Znów metoda wykorzystano programowanie dynamiczne. Jak napisaģ Baker: "Optymalną ķcieŋkę znajduje algorytm, który w efekcie bada równolegle wszystkie moŋliwe ķcieŋki". Pod koniec procesu identyfikowany jest najbardziej prawdopodobny skģadniowo prawidģowy ciąg sģów. Operacje matematyczne do wykonania tych obliczeņ są zbyt skomplikowane, aby je tutaj wyjaķniæ, ale moŋna je wykonaæ wystarczająco skutecznie, aby praktyczne rozpoznawanie mowy byģo praktyczne. Chociaŋ system DRAGON nie naleŋaģ do tych, które zostaģy ostatecznie przetestowane pod kątem celów systemu rozumienia mowy DARPA, Baker stwierdziģ, ŋe jego początkowe wyniki byģy "bardzo obiecujące" i ŋe w "pierwszym teķcie z wprowadzaniem mowy na ŋywo system rozpoznaģ kaŋde sģowo we wszystkich dziewięciu zdaniach w teķcie. "DRAGON staģ się podstawą komercyjnego produktu Dragon Naturally Speaking", pierwszy opracowany i wprowadzony na rynek przez Dragon Systems, firma zaģoŋona przez Bakera i jego ŋonę Janet.
HARPY
HARPY byģ drugim systemem wyprodukowanym w CMU w ramach prac badawczych DARPA w zakresie rozumienia mowy. Bruce T. Lowerre zaprojektowaģ i wdroŋyģ system jako częķæ swojego doktoratu. Badania. HARPY poģączyģ niektóre pomysģy HEARSAY-I i DRAGON. Podobnie jak DRAGON, przeszukiwaģ ķcieŋki w sieci, aby rozpoznaæ wypowiedziane zdanie, ale nie odnotowaģ adnotacji poģączeņ między węzģami w sieci z prawdopodobieņstwem przejķcia, jak to zrobiģ DRAGON. Podobnie jak HEARSAY-I, HARPY zastosowaģ heurystyczne metody wyszukiwania. Wersje HARPY zostaģy opracowane w celu zrozumienia zdaņ wypowiadanych na temat kilku róŋnych obszarów zadaņ. Gģówną z nich byģa moŋliwoķæ udzielenia odpowiedzi na pytania i odzyskania dokumentów z bazy danych zawierającej streszczenia (zwane "streszczeniami") dokumentów AI. Oto kilka przykģadów:
"Które streszczenia odnoszą się do teorii obliczeņ?"
"Wymieņ te artykuģy".
"Czy są jakieķ Feigenbaum i Feldman?"
"Co napisaģ McCarthy od dziewiętnastu siedemdziesięciu czterech?"
HARPY moŋe obsģuŋyæ zasób 1011 sģów. Zamiast uŋywaæ gramatyki z konwencjonalnymi kategoriami skģadniowymi, takimi jak rzeczownik, przymiotnik itp., HARPY uŋyģ tak zwanej "gramatyki semantycznej", która rozszerzyģa kategorie takie jak temat, autor, rok i wydawca, które byģy semantycznie powiązane do jego obszaru tematycznego, a mianowicie danych o papierach AI. Gramatyka HARPY byģa ograniczona do obsģugi zestawu zdaņ o autorach i artykuģach, które HARPY miaģ byæ w stanie rozpoznaæ. Sieæ zostaģa zbudowana z tak zwanych "žródeģ wiedzy" (KS), które skģadaģy się z informacji potrzebnych do procesu rozpoznawania. Pierwsza z tych zakodowanej wiedzy skģadniowej o gramatyce. Drugie žródģo wiedzy uŋywane przez HARPY opisywaģo, w jaki sposób kaŋde sģowo. Sģownictwo HARPY moŋe byæ wymawiane. A poniewaŋ granice sģów w języku mówionym pokrywają się w sposób zaleŋny od uŋytych sģów, pomyķlne rozpoznanie wymaga trzeciego žródģa wiedzy zajmującego się takimi zjawiskami. Czwarte žródģo wiedzy wyszczególniģo telefony zaangaŋowane w wymowę sģów i przejķcia między nimi. HARPY poģączyģ caģą tę wiedzę w gigantyczną sieæ telefonów reprezentujących wszystkie moŋliwe sposoby wypowiadania legalnych skģadniowo. Kaŋdy "węzeģ telefoniczny" w sieci zostaģ sparowany z reprezentacją odcinka fali mowy, zwanej "szablonem widmowym", który ma byæ powiązany z tym konkretnym telefonem. Szablony te uzyskano na początku, czytając okoģo 700 zdaņ przez mówcę. Moŋna by je "dostroiæ" dla nowego mówcy, czytając okoģo 20 wybranych zdaņ podczas sesji "uczenia się". Częķciową sieæ telefonów pokazano poniŋej, aby zilustrowaæ ogólną ideę. Rzeczywista sieæ HARPY miaģa 15 000 węzģów. Sieæ obejmuje te fragmenty zdaņ, które zaczynają się od "Powiedz mi …" i "Daj mi …" Symbole wewnątrz węzģów reprezentują telefony, uŋywając dla nich notacji DRAGON. Strzaģki oznaczają moŋliwe przejķcia z jednego telefonu do drugiego. Pamiętaj, ŋe istnieje wiele ķcieŋek odpowiadających róŋnym sposobom wymawiania sģów.
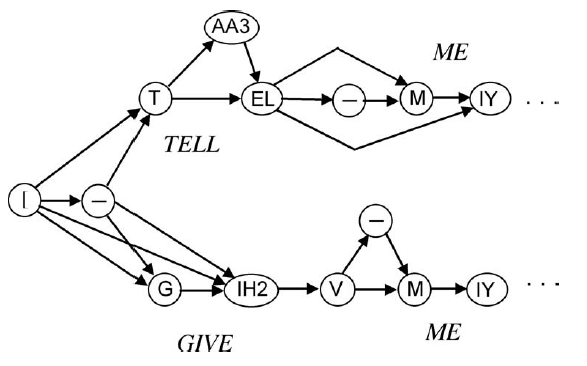
Aby rozpoznaæ sģowa w mówionym zdaniu, zaobserwowana mowa byģa najpierw podzielona na segmenty o zmiennej dģugoķci, które odgadģy, ŋe odpowiadają sekwencji telefonów w przebiegu. Dla kaŋdego z tych segmentów obliczono szablon spektralny. Proces rozpoznawania przebiegaģ następnie w następujący sposób: Szablon widmowy odpowiadający pierwszemu segmentowi widmowemu w fali mowy zostaģ porównany ze wszystkimi szablonami odpowiadającymi telefonom na początku sieci. W odniesieniu do powyŋszego rysunku będą one obejmowaæ porównania z szablonami dla - , T, G i IH2, poniewaŋ znajdowaģy się wķród węzģów w sieci, do których moŋna byģo dotrzeæ jednym krokiem od węzģa początkowego, a mianowicie [. (Oczywiķcie, uŋywając caģej sieci, a nie tylko zilustrowanego tylko częķciowego przykģadu, dokonano by kilku dalszych porównaņ z szablonami dodatkowych węzģów telefonicznych dostępnych w jednym kroku od węzģa początkowego.) Zauwaŋono kilka najlepszych dopasowaņ i ķcieŋki do tych węzģów zostaģy wyznaczone jako najlepsze jednoetapowe ķcieŋki częķciowe w sieci. W następnym etapie szablon spektralny następnego segmentu fali zostaģ porównany z szablonami wszystkich tych dostępnych węzģów telefonicznych poprzez rozszerzenie najlepszych ķcieŋek jednoetapowych o kolejny krok. Wykorzystując obliczone dotychczas wartoķci porównaņ, zidentyfikowano zestaw najlepszych dwuetapowych ķcieŋek częķciowych. Proces ten trwa do momentu osiągnięcia koņca sieci. W tym czasie najlepsza znaleziona do tej pory ķcieŋka mogģa byæ powiązana ze sģowami powiązanymi z węzģami wzdģuŋ tej ķcieŋki. Ta sekwencja sģów zostaģa następnie wygenerowana jako decyzja rozpoznająca HARPY. Metodę poszukiwania najlepszej ķcieŋki przez sieæ HARPY moŋna porównaæ z heurystycznym procesem wyszukiwania A* opisanym wczeķniej. Podczas gdy A* utrzymywaģ caģą "granicę" wyszukiwania do ewentualnego dalszego przeszukiwania, HARPY utrzymywaģ na swojej granicy tylko te węzģy na kilku najlepszych znalezionych dotychczas ķcieŋkach. (Liczba węzģów utrzymywanych na granicy byģa parametrem, który moŋna ustawiæ w razie potrzeby do kontrolowania wyszukiwania.) Projektanci HARPY nazwali tę technikę "wyszukiwaniem wiązki", poniewaŋ węzģy odwiedzane przez proces wyszukiwania byģy ograniczone do wąskiej wiązki przez sieæ. Poniewaŋ węzģy nie znajdujące się w wiązce zostaģy wyeliminowane w trakcie tego procesu, moŋliwe, ŋe najlepsza peģna ķcieŋka znaleziona przez HARPY moŋe nie byæ ogólnie najlepszą w sieci. (Jeden z wyeliminowanych węzģów moŋe znajdowaæ się na tej ogólnej najlepszej ķcieŋce.) Mimo to znaleziona ķcieŋka zwykle odpowiada poprawnej interpretacji wypowiadanego zdania. Pod koniec projektu rozumienia mowy DARPA, HARPY zostaģ przetestowany na 100 zdaniach wypowiedzianych przez trzech męŋczyzn i dwie kobiety mówiące. Byģ w stanie poprawnie zrozumieæ ponad 95% tych zdaņ, osiągając w ten sposób cel DARPA dotyczący bģędu poniŋej 10%. Ķrednio HARPY wykonaģ okoģo 30 milionów instrukcji komputerowych, aby poradziæ sobie z jedną sekundą mowy. Przy uŋyciu 0,4 miliona instrukcji na sekundę (0,4 MIPS) (DEC PDP-KA10) przetworzenie sekundy mowy zajęģoby minutę; chociaŋ jest to nieco gorsze niŋ wydajnoķæ w czasie rzeczywistym, osiągnęģo cel DARPA "kilka razy w czasie rzeczywistym" (jeķli interpretujemy "kilka" nieco ģagodnie). Aby spojrzeæ na sprawę czasu rzeczywistego z perspektywy, dzisiejsze komputery przetwarzają miliardy instrukcji na sekundę HARPY byģ jedynym systemem speģniającym cele DARPA.
C. HEARSAY-II
Wreszcie HEARSAY-II, przeprojektowana i ulepszona wersja HEARSAY-I, byģa byæ moŋe najbardziej ambitnym z projektów mowy CMU. Podobnie jak HARPY, HEARSAY-II zostaģ zaprojektowany, aby odpowiadaæ na pytania i pobieraæ dokumenty z bazy danych zawierającej streszczenia dokumentów AI. (Wczeķniej rozwaŋano zadanie polegające na wyszukiwaniu wiadomoķci z serwisów elektronicznych). Byģo ono równieŋ ograniczone do sģownika zawierającego 1011 sģów i stosowaģo gramatykę semantyczną specjalizującą się w tej dziedzinie. Pierwsze kroki w przetwarzaniu wypowiedzi przez HEARSAY obejmowaģy segmentację fali mowy i etykietowanie telefonów, które wedģug szacunków będą obecne w kaŋdym segmencie. W ramach projektu HEARSAY zastosowano nowatorską metodę stopniowego przeksztaģcania tych skģadników w sylaby, sylaby w sģowa, sģowa w sekwencje sģów, a w koņcu sekwencje sģów w frazy. Następnie frazy zostaģy przeksztaģcone w odpowiednie procedury dostępu do bazy danych dokumentów AI. Metoda przetwarzania zastosowana przez HEARSAY obejmowaģa warstwową strukturę zwaną "tablicą". Szacuje się, ŋe etykiety telefonów, a takŋe liczby związane z prawdopodobieņstwem ich wystąpienia, zostaģy "zapisane" w jednej z niŋszych warstw tablicy. Wyspecjalizowane procedury žródģa wiedzy, które wiedziaģy o "sposobie budowania sylab z telefonów", czytaģy te etykiety i obliczaģy domysģy na temat tego, jakie sylaby byģy w wypowiedzi. Te domysģy, wraz z liczbami mierzącymi ich przekonania lub prawdopodobieņstwa, zostaģy następnie zapisane w warstwa sylaby tablicy. Inne procedury žródģa wiedzy, które wiedziaģy o tym, jak sģowa zostaģy zbudowane z sylab, czytają informacje juŋ na tablicy i zapisują domysģy na temat sģów w warstwie sģów tablicy. I tak dalej. HEARSAY-II miaģ okoģo 40 te žródģa wiedzy Ogólny pogląd ilustruje rysunek
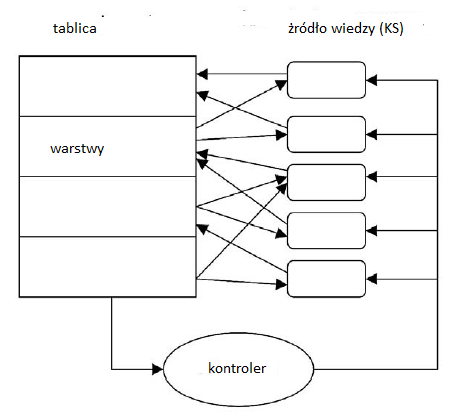
Zasadniczo žródģo wiedzy moŋe odczytywaæ lub zapisywaæ informacje na dowolnej warstwie tablicy, która byģa dla niego istotna. Co więcej, moŋe to robiæ w sposób tzw. "asynchroniczny" (niezaleŋny od tego, kiedy inne žródģa wiedzy czytaģy i pisaģy). Istnieje kilka žródeģ wiedzy, które mogą pisaæ prognozy dotyczące nowych sģów na podstawie sģów zapisanych juŋ w warstwie sģów i informacji w innych warstwach. Žródģa wiedzy mogą nawet pisaæ domysģy na temat sģów w warstwie sģów w oparciu o sekwencje sģów juŋ zapisane (z duŋą siģą) w warstwie sekwencji. Ten proces wnioskowania, co musi znajdowaæ się w dolnej warstwie (mimo ŋe pominięte przez wstępne przetwarzanie) z tego, co (z innych dowodów) jest obecne w wyŋszej warstwie, jest temat, który często powraca w póžniejszych badaniach nad AI. O ile mi wiadomo, ta niezwykle waŋna innowacja AI pojawiģa się po raz pierwszy w systemie HEARSAY-II. Wedģug Raj Reddy, jednego z wynalazców architektury tablicy (wraz z Victorem Lesserem, Lee Ermanem i Frederickiem Hayes-Rothem), Herbert Simon często uŋywaģ sģowa "tablica", aby opisaæ element "pamięci roboczej" systemu produkcyjnego architektura, z którą on i Allen Newell pracowali. System produkcyjny uŋywaģ reguģ IF {THEN (zwanych produkcjami), które byģy uruchamiane przez zawartoķæ pamięci roboczej i zapisywaģ w niej nowe dane. Reddy i zespóģ, rozpoznając róŋnorodnoķæ róŋnych žródeģ wiedzy związanych z przetwarzaniem mowy, uogólnili ideę systemu produkcyjnego, rozszerzając reguģy produkcji na większe programy, nazywając je "žródģami wiedzy" i opracowali pamięæ roboczą w warstwowej strukturze tablicy. Pod koniec projektu rozumienia mowy DARPA, HEARSAY-II zostaģ przetestowany na dwudziestu trzech wypowiedzianych zdaniach, zupeģnie nowy w systemie, mając ķrednio siedem sģów na zdanie, a 81% z nich zostaģo poprawnie rozpoznanych sģowo po sģowie , chociaŋ 91% doprowadziģo do tego samego zapytania do bazy danych, które zawieraģoby poprawne zdanie sģowo w sģowo. Projektanci HEARSAY twierdzili, ŋe ten występ jest bliski osiągnięcia ambitnych celów. . . ustanowiony dla programu DARPA w 1971 roku. "Chociaŋ HEARSAY-II zbliŋyģ się, wyniki nie byģy tak dobre jak HARPY. Chociaŋ architektura tablicy nie jest juŋ stosowana w nowoczesnych systemach rozpoznawania mowy, zostaģa przyjęta przez kilka innych programów AI. Wedģug Russella i Norviga "Systemy tablicowe są podstawą nowoczesnej architektury interfejsu uŋytkownika".
Podsumowanie i wpģyw programu SUR
CMU HEARSAY-II i HARPY zostaģy zademonstrowane na CMU 8 wrzeķnia 1976 r., A HWIM BBN zademonstrowano na BBN 10 wrzeķnia. W raporcie podsumowującym projekty Dennis Klatt napisaģ, ŋe "nie jest jasne, czy istnieją duŋe róŋnice w umiejętnoķæ wķród [tych] trzech systemów. Jednak tylko [HARPY] byģ w stanie osiągnąæ cele ARPA ". Twórcy HEARSAY-II przypisali najwyŋszą wydajnoķæ HARPY trzem czynnikom: dokģadniejszemu poszukiwaniu potencjalnych rozwiązaņ (dozwolonym przez wstępnie obliczoną sieæ wszystkich zdaņ, które moŋna wypowiedzieæ), bardziej szczegóģowej wbudowanej wiedzy na temat zjawisk przejķciowych między sąsiadującymi sģowami i jego dokģadniejsze testowanie, strojenie i debugowanie. Jednak niektórzy badacze i menedŋerowie programu DARPA spierali się o sposób przeprowadzenia testów i stwierdzenie, ŋe ŋaden z systemów nie speģnia celów programu SUR. W kaŋdym razie DARPA postanowiģa nie finansowaæ proponowanego programu kontynuacji. Program pokazaģ jednak, ŋe rozumienie mowy byģo rozsądnym celem technicznym i stymulowaģo postęp w technologiach przetwarzania mowy, zwģaszcza w organizacji systemu, skģadni i semantyce oraz przetwarzaniu akustycznym. Raport National Research Council stwierdziģ, ŋe finansowanie przez "DARPA badaņ nad rozumieniem mowy jest niezwykle waŋne.…" wyniki tych badaņ zostaģy wģączone do produktów uznanych firm, takich jak IBM i BBN, a takŋe start-upów, takich jak Nuance Communications (spinoff SRI) i Dragon Systems. Wiodący na rynku program do rozpoznawania mowy na rynku, oprogramowanie Dragon "NaturallySpeaking" , wywodzi się bezpoķrednio z pracy wykonanej w CMU w latach 1971-1975 w ramach SUR
Póžniejsza praca nad rozpoznawaniem mowy
Badania rozpoznawania mowy byģy równieŋ prowadzone w innych laboratoriach oprócz tych, które byģy bezpoķrednio zaangaŋowane w program SUR DARPA. Na przykģad Frederick Jelinek z Speech Processing Group w Departamencie Nauk Komputerowych IBM w Thomas J. Watson Research Center w Yorktown Heights w Nowym Jorku jest jednym z pierwszych zwolenników stosowania metod statystycznych (w tym ukrytych modeli Markowa) w rozpoznawanieu mowy. Podejķcie HMM zostaģo ostatecznie przyjęte przez wszystkie wiodące firmy rozpoznające mowę. W 1984 r. DARPA ponownie zaczęģa finansowaæ prace związane z rozpoznawaniem mowy w ramach programu "Strategic Computing". Uczestnikami byli CMU, SRI, BBN, MIT, IBM i Dragon Systems. Wķród systemów opracowanych w CMU w ciągu następnych kilku lat byģy na przykģad SPHINX autorstwa Kai-Fu Lee i innych oraz JANUS, wielojęzyczny system rozpoznawania i tģumaczenia mowy przez Alexa Waibela i innych. (Te i inne systemy są dostępne jako oprogramowanie typu open source ze strony internetowej "Speech at CMU", http://www.speech.cs.cmu.edu/. Strona zawiera równieŋ linki do wielu innych laboratoriów rozpoznających mowę.) W oparciu o swoją pracę nad DRAGON w CMU, James i Janet Baker zaģoŋyli Dragon Systems w 1982 r. W 1997 r. Dragon wprowadziģ "Dragon NaturallySpeaking", program do rozpoznawania mowy dla komputerów osobistych. Miaģ zasób 23 000 sģów. IBM wraz z ViaVoice, oraz inne firmy, w tym Microsoft, równieŋ mają oprogramowanie do rozpoznawania mowy. Transkrypcja zdaņ mówionych na ich tekstowe odpowiedniki jest obecnie w duŋej mierze rozwiązanym problemem. Na przykģad w wielu zautomatyzowanych systemach odpowiedzi telefonicznej powszechnie stosuje się dziķ wysokiej jakoķci rozpoznawanie mowy. Jednak zrozumienie mowy (lub tekstu) w języku naturalnym, aby na przykģad umoŋliwiæ ogólne dialogi z systemami komputerowymi, pozostaje dģugoterminowym problemem badawczym.