Przedstawienia Semantyczne
Programy komputerowe, które do tej pory opisywano, przeprowadzaģy transformacje na stosunkowo prostych strukturach symboli, które byģy wszystkie potrzebne do rozwiązywania problemów matematycznych, zagadek i gier, z którymi te programy się uporaģy. Gģówny wysiģek polegaģ na opracowaniu i wykorzystaniu heurystyk specyficznych dla problemu (takich jak na przykģad funkcje do obliczenia wartoķci pozycji kontrolera), aby ograniczyæ liczbę przeksztaģceņ tych struktur w poszukiwaniu rozwiązaņ. Jak ująģ to Minsky: "Najbardziej centralna idea to okres przed 1962 r., to okres poszukiwania urządzeņ heurystycznych do kontrolowania zakresu poszukiwaņ metodą prób i bģędów. ". Na początku lat 60. XX wieku w kilku projektach badawczych doktoranckich, niektóre prowadzone pod kierunkiem Minsky′ego w MIT, zaczęto stosowaæ zģoŋone struktury symboli w programach do wykonywania róŋnych zadaņ intelektualnych. Ze względu na bogatą, artykuģowaną treķæ informacji na temat ich problematyki struktury te nazwano reprezentacjami semantycznymi. Jak napisaģ Minsky: " W maģej domenie, w której dziaģa kaŋdy program, wydajnoķæ [ z tych programów] nie jest tak zģa w porównaniu z niektórymi ludzkimi dziaģaniami … Ale znacznie waŋniejsze niŋ to, co osiągają te konkretne eksperymenty, są metody, których uŋywają do osiągnięcia tego, co robią, poniewaŋ kaŋdy jest pierwszą próbą wczeķniej niesprawdzonych pomysģów". Opiszemy kilka przykģadów tego rodzaju projektów i nowych metod, które zastosowali.
Rozwiązywanie problemów z analogią geometryczną
Thomas G. Evans zaprogramowaģ system, który byģ w stanie dobrze wykonywaæ niektóre standardowe testy analogii geometrycznych. Byģ to najwyražniej największy program napisany do tego czasu w nowym języku programowania Johna McCarthy′ego, LISP. Zastanowimy się nad rozwiązaniem maszynowym tak zwanych pytaņ testu inteligencji "analogii geometrycznej". Kaŋdy czģonek tej klasy problemów skģada się z zestawu rysowanych linii. Zadanie do wykonania moŋna opisaæ pytaniem: "Rysunek A dotyczy rysunku B, podobnie jak rysunek C do którego z poniŋszych wskažników?" Na przykģad wydaje się bezpiecznie powiedzieæ, ŋe większoķæ ludzi zgodziģaby się z programem, który zamierzamy opisaæ, wybierając [numer 4] jako poŋądaną odpowiedž.
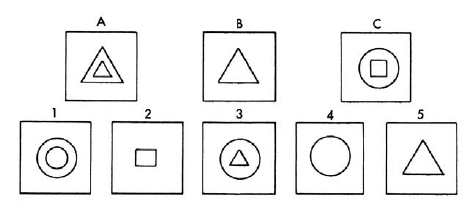
Zauwaŋyģ takŋe, ŋe problemy tego typu są powszechnie uwaŋane za wymagające wysokiego stopnia inteligencji do ich rozwiązania i faktycznie są wykorzystywane jako kamieņ węgielny inteligencji w niektórych ogólnych testach inteligencji wykorzystywanych do przyjmowania na studia i innych celów. "Zatem ponownie, badania AI skupiģy się na mechanizowaniu zadaņ wymagających ludzkiej inteligencji. Program Evansa pierwszy przeksztaģciģ przedstawione na niej diagramy, aby ujawniæ, w jaki sposób zostaģy one zģoŋone z częķci. Nazwaģ te reprezentacje "stawowe". Spoķród moŋliwych kilku dekompozycji wybór wybrany przez program zaleŋaģ od jego "kontekstu". jeden przykģad heurystyki zastosowanej przez program.) Na przykģad schemat
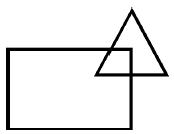
moŋna albo rozģoŋyæ na
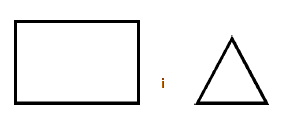
lub do
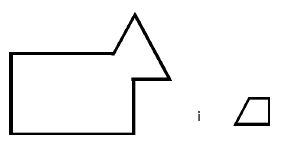
Ale jeķli problem analogii zawieraģ inny schemat (częķæ kontekstu):

wtedy wybierany byģby pierwszy rozkģad. Evans przedstawiaģ diagramy i ich częķci jako zģoŋone struktury symboli skģadające się z doķæ skomplikowanych kombinacji list i list list, których elementy wskazywaģy, które częķci byģy wewnątrz lub na zewnątrz (lub powyŋej lub poniŋej), które inne częķci, i tak dalej. Te szczegóģy nie muszą nas tutaj dotyczyæ, ale pozwoliģy Evansowi okreķliæ "reguģy" dla jego programu, które mogģyby zostaæ wykorzystane do pokazania, w jaki sposób jeden diagram moŋna przeksztaģciæ w inny. Program byģ w stanie wywnioskowaæ, które kombinacje tych reguģ przeksztaģciģy Rysunek A danego problemu na Rysunek B. Następnie mógģ zastosowaæ tę transformację na Rysunku C. Jeķli wynikģa jedna z odpowiedzi wielokrotnego wyboru, podaģaby ją jako odpowiedž . W przeciwnym razie program "osģabiģ "transformację tak, ŋe jedna z odpowiedzi zostaģa opracowana i taka byģaby odpowiedž programu. Evans podsumowaģ swoje wyniki w następujący sposób:
Pozwalając sobie tylko na [częķci faktycznie wdroŋonego programu], szacujemy, ŋe spoķród 30 problemów z analogią geometryczną podczas typowej edycji testów ACE [program] moŋe z powodzeniem rozwiązaæ co najmniej 15, a byæ moŋe nawet 20 problemy.
Zauwaŋa, ŋe ten poziom wydajnoķci wypada korzystnie w porównaniu z przeciętnym uczniem szkoģy ķredniej.
Przechowywanie informacji i udzielanie odpowiedzi na pytania
Kolejny doktor Minsky′ego z początku lat 60. Bertram Raphael skupiģ się na problemie "rozumienia maszyn". W swojej rozprawie Raphael wyjaķniģ, ŋe komputer powinien byæ uwaŋany za zdolny do "zrozumienia", jeķli moŋe rozmawiaæinteligentnie, tzn. jeķli pamięta, co zostaģo powiedziane, odpowiada na pytania i udziela odpowiedzi, które ludzki obserwator uwaŋa za rozsądne. Raphael chciaģ móc powiedzieæ coķ komputerowi, a następnie zadaæ mu pytania, których odpowiedzi moŋna by wywnioskowaæ z tego, co mu powiedziano. (Mówienie i zadawanie pytaņ powinno odbywaæ się poprzez wpisywanie zdaņ i zapytaņ.) Oto kilka przykģadów tego, co chciaģ powiedzieæ:
Kaŋdy chģopiec jest osobą.
Palec jest częķcią ręki.
Kaŋda osoba ma dwie ręce.
John jest chģopcem.
Kaŋda ręka ma kilka palców.
Biorąc pod uwagę te informacje, Raphael chciaģby, aby jego system mógģ wydedukowaæ odpowiedž na pytanie "Ile palców ma Jan?" Poniewaŋ Raphael chciaģ, aby jego system komunikowaģ się z ludžmi, chciaģ, aby jego języki wejķciowe i wyjķciowe byģy w rozsądnym stopniu zbliŋone do naturalnego angielskiego. Uznaģ, ŋe "problem językowy przeksztaģcenia języka naturalnego w uŋyteczną formę będzie musiaģ zostaæ rozwiązany, zanim będziemy uzyskaæ ogólny semantyczny system wyszukiwania informacji. "Ten" problem językowy "jest doķæ trudny i nadal nie" rozwiązany ", mimo ŋe od lat 60. dokonano znacznego postępu. Raphael uŋywaģ róŋnych" urządzeņ "(jak je nazywaģ i które nie są niemądre) do naszej obecnej dyskusji), aby "ominąæ [ogólny problem radzenia sobie z językiem naturalnym] przy jednoczesnym wykorzystaniu zrozumiaģych angielskich danych wejķciowych i wyjķciowych". Gģówny problem, który zaatakowaģ Raphael, polegaģ na tym, jak uporządkowaæ fakty w pamięci komputera, aby moŋna byģo dokonaæ odpowiednich wniosków. Jak to ująģ Raphael: "Najwaŋniejszym warunkiem umiejętnoķci rozumienia jest odpowiednia wewnętrzna reprezentacja lub model przechowywanych informacji. Model powinien byæ tak skonstruowany, aby informacje istotne dla odpowiedzi na pytania byģy ģatwo dostępne". Raphael nazwaģ swój system SIR, dla semantycznego wyszukiwania informacji (który zaprogramowaģ w LISP). Uŋyģ sģowa "semantyczny", poniewaŋ SIR modelowaģ zdania w sposób zaleŋny od ich znaczenia. Zdania, z którymi SIR mógģ sobie poradziæ, dotyczyģy "bytów" (takich jak John, chģopiec, ręka, palec itd.) Oraz relacji między tymi podmiotami (takich jak "zestaw-czģonkostwo", "częķæ {caģoķæ", "wģasnoķæ", " powyŋej, "obok" i inne relacje przestrzenne.) Model musiaģ zatem mieæ sposoby reprezentowania bytów i relacji między nimi. Podmioty takie jak John i chģopiec byģy reprezentowane przez komputer LISP jako sģowa JOHN i BOY, odpowiednio. (Oczywiķcie komputer nie mógģ wiedzieæ, ŋe sģowo komputerowe JOHN ma coķ wspólnego z osobą Johna. Raphael równie dobrze mógģ reprezentowaæ Johna na komputerze przez X13F27, o ile konsekwentnie uŋywaģ tej prezentacji dla Johna. Sģowo komputerowe JOHN byģo mnemoniczną wygodą dla programisty {nie dla komputera!) Przedstawiając fakt, ŋe John jest chģopcem, SIR "ģączy" wyraŋenie komputerowe (SUPER-SET JOHN BOY) do wyraŋenia JOHN i poģączenie wyraŋenia komputerowego (SUB-SET BOY JOHN) z wyraŋeniem BOY. Zatem jeķli SIR zostanie poproszony o nazwanie chģopca, moŋe odpowiedzieæ" JOHN "odnosząc się do BOY w swoim modelu, patrząc na link SUB-SET i wyszukując JOHN. (Uproķciģem nieco reprezentacje, aby uzyskaæ gģówne pomysģy; rzeczywiste reprezentacje SIR byģy nieco bardziej skomplikowane.) SIR mógģ poradziæ sobie z dziesiątkami róŋnych bytów i relacji między nimi. Za kaŋdym razem, gdy otrzymywaģ nowe informacje, dodawali nowe byty i linki jakie byģy potrzebne. Miaģ takŋe kilka mechanizmów dokonywania logicznych dedukcji i wykonywania prostej arytmetyki. Sama struktura modelu uģatwiģa wiele jego dedukcji, poniewaŋ, jak zauwaŋyģ Minsky w swojej dyskusji na temat tezy Rafaela, "bezpoķrednie predykaty ģączą… prawie fizycznie ģączą bezpoķrednie logiczne konsekwencje danej informacji". SIR byģ równieŋ pierwszym systemem sztucznej inteligencji stosującym "zasadę wyjątku" w rozumowaniu. Tę zasadę najlepiej wyjaķniæ, cytując bezpoķrednio z pracy Raphaela:
Uwzględniono ogólne informacje o "wszystkich elementach" zestawu aby stosowaæ do okreķlonych elementów tylko przy braku bardziej szczegóģowych informacji o tych elementach. Zatem niekoniecznie sprzeczne jest stwierdzenie, ŋe "ssaki są zwierzętami lądowymi", a jednak "wieloryb to ssak, który zawsze ŋyje w wodzie". W programie pomysģ ten wdraŋa się, zawsze odwoģując się do poŋądanych informacji do listy wģaķciwoķci [czyli linków] danej osoby przedtem patrząc na opisy zbiorów, do których naleŋy dana jednostka. Uzasadnieniem tego odstępstwa od zasad nie-wyjątkowych w logice arystotelesowskiej jest to, ŋe ten pierwszeņstwo konkretnych faktów nad wiedzą w tle wydaje się byæ sposobem dziaģania ludzi i chcę, aby komputer komunikowaģ się z ludžmi tak naturalnie, jak to moŋliwe. Obecny program nie odczuwa dyskomfortu, jaki ludzie często odczuwają, gdy muszą stawiæ czoģa faktom takim jak "wieloryb to ssak ŋyjący w wodzie, chociaŋ ssaki z reguģy ŋyją na lądzie".
Zasada wyjątku zostaģa zbadana przez badaczy AI bardziej szczegóģowo póžniej i doprowadziģa do tak zwanego domyķlnego rozumowania i logiki niemonotonicznej, jak zobaczymy.
Sieci semantyczne
Pouczające jest przemyķlenie schematu reprezentacji SIR w kategoriach sieci. Jednostki (takie jak JOHN i BOY) są "węzģami" sieci, a ģącza relacyjne (takie jak SUB-SET) są poģączeniami między węzģami. SIR byģa wczesną wersją tego, co stanie się waŋną ideą reprezentacyjną w sztucznej inteligencji, a mianowicie sieci semantycznych. Nie byģ to jednak pierwszy. John Sowa, który pisaģ obszernie o sieciach semantycznych, twierdzi, ŋe najstarsza znana sieæ semantyczna zostaģa narysowana w III wieku n.e. przez greckiego filozofa Porphyry′ego w komentarzu do kategorii Arystotelesa. W 1961 r. Margaret Masterman, dyrektor jednostki Cambridge Language Research Unit, zastosowaģa sieæ semantyczną w systemie tģumaczeņ, w którym koncepcje byģy uporządkowane w hierarchii. M Ross Quillian, student Herba Simona w Carnegie Institute of Technology, byģ zainteresowany, wraz z Newellem i Simonem, modelami obliczeniowymi procesów umysģowych czģowieka, a konkretnie organizacją pamięci. Opracowaģ model pamięci skģadający się z semantycznej sieci węzģów reprezentujących angielskie sģowa. Węzģy zostaģy poģączone przez to, co nazwaģ "powiązaniami asocjacyjnymi". W sģowach Quilliana: "W modelu pamięci skģadniki uŋyte do zbudowania pojęcia są reprezentowane przez węzģy symboliczne nazywające inne pojęcia, a konguracyjne znaczenie pojęcie to reprezentuje szczególna struktura powiązaņ ģączących te węzģy-tokeny z kaŋdym z nich z innym". Quillian pisze dalej, ŋe" gģównym pytaniem zadanym w tych badaniach byģo: Co stanowi rozsądny pogląd na to, jak uporządkowane są informacje semantyczne w pamięci osoby? Innymi sģowy: jaki rodzaj formatu reprezentacyjnego moŋe pozwoliæ na przechowywanie "znaczeņ" sģów, aby moŋliwe byģo ich uŋycie w sposób podobny do ludzkiego?". Mogę zilustrowaæ sposób, w jaki format sieci Quillian reprezentuje znaczenie, na jednym z jego przykģadów. Rozwaŋ róŋne znaczenia sģowa "plant". Jednym z takich znaczeņ jest poģączenie węzģa PLANT z innymi węzģami, takimi jak LIVE, LIĶÆ, ŊYWNOĶÆ, POWIETRZE, WODA i ZIEMIA, poprzez poģączenia, które reprezentują, to ŋe roķlina (zgodnie z tym znaczeniem tego sģowa) ŋyje, ma liķcie i otrzymuje pokarm z powietrza, wody i ziemi. Inne znaczenie "plant "ģączy PLANT z innymi węzģami, takimi jak LUDZIE, PROCES i PRZEMYSĢ, poprzez poģączenia, które reprezentują, ŋe roķlina (zgodnie z tym innym znaczeniem tego sģowa) jest urządzeniem, które wykorzystuje ludzi do angaŋowania się w uŋywany proces w przemyķle. Wedģug Quilliana znaczenie terminu jest reprezentowane przez jego miejsce w sieci i sposób, w jaki jest on powiązany z innymi terminami. Ten sam pomysģ jest uŋywany w sģownikach, w których znaczenie sģowa jest podane przez odniesienie do tego związku sģowo do innych sģów. Znaczenia tych innych sģów są z kolei nadawane przez swoje relacje jeszcze innym sģowom. Moŋemy więc myķleæ o sģowniku jako o duŋej sieci semantycznej sģów powiązanych z innymi sģowami. Korzystając z tego widoku, peģne znaczenie pojęcia moŋe byæ doķæ obszerne. Jak to ująģ Quillian, "Zaģóŋmy, ŋe ktoķ zostaģ poproszony o przedstawienie wszystkiego, co wie na temat pojęcia "maszyna"… Informacje te zaczną się z bardziej "przekonującymi" faktami na temat maszyn, takimi jak ten są zazwyczaj wykonane przez czģowieka, zawierają ruchome częķci itd. i przejdzie "w dóģ "do coraz mniej integrujących faktów, takich jak fakt ŋe maszyny do pisania to maszyny, a potem w koņcu do nich dojdzie znacznie więcej zdalnych informacji o maszynach, takich jak fakt ŋe maszyna do pisania ma ogranicznik uniemoŋliwiający jej przewóz odlatuje za kaŋdym razem, gdy jest zwracany. Sugerujemy ,ŋe informacje mogą byæ uŋyteczne jako częķæ przedmiotu koncepcji "maszyny". W jaki sposób sieæ Quilliana jest modelem organizacji ludzkiej pamięci? Quillian zbadaģ dwie moŋliwoķci ludzkiej pamięci modelowane przez jego sieæ. Jedno porównywaģo i kontrastowaģo dwa róŋne sģowa. Quillian zaproponowaģ, aby zrobiæ to w procesie, który nazwano "aktywacją rozprzestrzeniania". Koncepcyjnie, jeden zaczyna się od węzģów reprezentujących dwa sģowa i stopniowo przemierza emanujące z nich ģącza, "aktywując" węzģy po drodze. Proces ten trwa do momentu, gdy dwie "fale" aktywacji przecinają się, tworząc w ten sposób "ķcieŋkę" między dwoma oryginalnymi węzģami. Quillian zaproponowaģ, aby caģkowitą "odlegģoķæ" na tej ķcieŋce między tymi dwoma sģowami moŋna byģo wykorzystaæ jako miarę ich podobieņstwa. Ķcieŋka moŋe zostaæ uŋyta do utworzenia konta porównującego dwa sģowa. (Program Quillian miaģ mechanizmy wyraŋania tego konta w prostym języku angielskim). Aby uŋyæ jednego z przykģadów Quilliana, zaģóŋmy, ŋe chcieliķmy porównaæ sģowa "pģacz" i "pociecha". Aktywacje rozprzestrzeniania się przecinaģyby sģowo "smutny", a angielska relacja wyraŋaģaby coķ w stylu "pģakaæ to wydawaæ smutny džwięk, a dla wygody - sprawiaæ, by coķ mniej smutnego". Quillian byģ równieŋ zainteresowany tym, w jaki sposób sieæ moŋe zostaæ wykorzystana do "ujednoznacznienia" dwóch moŋliwych zastosowaņ tego samego sģowa. Rozwaŋmy na przykģad zdanie "Po strajku prezydent go odesģaģ". Sieæ moŋe kodowaæ róŋne znaczenia sģowa "strajk". Jednym z nich moŋe byæ spór pracowniczy, innym moŋe byæ baseball, a jeszcze innym nalot samolotów wojskowych. Które z tych znaczeņ jest zamierzone w zdaniu? Przypuszczalnie aktywacja przebiegająca na zewnątrz od sģowa "prezydent" ostatecznie doprowadziģaby do koncepcji związanych ze sporami pracowniczymi, a następnie do koncepcji związanych z baseballem lub wojskiem. Dlatego "spór pracowniczy" byģby preferowany, poniewaŋ jest "bliŋszy", biorąc pod uwagę, ŋe sģowo "prezydent" znajduje się w zdaniu. W przeciwieņstwie do tego moŋna dojķæ do innego wniosku w sprawie zdania "Po strajku sędzia go odesģaģ". Model Quillian róŋni się od niektórych póžniejszych sieci semantycznych tym, ŋe nie ma z góry okreķlonej hierarchii nadklas i podklas. Jak to ująģ Quillian, "kaŋde sģowo jest patriarchą wģasnej odrębnej hierarchii, gdy zaczyna się od niego jakiķ proces wyszukiwania. Podobnie kaŋde sģowo znajduje się w róŋnych miejscach w hierarchii (tj. jest skģadnikiem) bardzo wielu innych sģów koncepcje, gdy przetwarzanie zaczyna się od nich ".