Widzenie Komputerowe
Widzący ludzie czerpią wiele informacji z widzenia. Ta częķæ sztucznej inteligencji zwana "widzeniem komputerowym" (lub czasami "widzeniem maszynowym") zajmuje się nadaniem komputerom tej zdolnoķci. Większoķæ prac związanych z widzeniem komputerowym opiera się na przetwarzaniu dwuwymiarowych obrazów zebranych, z trójwymiarowych obrazów ķwiata zebranych na przykģad przez jedną lub więcej kamer telewizyjnych. Poniewaŋ obrazy są dwuwymiarowymi projekcjami trójwymiarowej sceny, proces obrazowania traci informacje. Oznacza to, ŋe róŋne trójwymiarowe sceny mogą wytwarzaæ ten sam dwuwymiarowy obraz. Zatem problem wiernego odtworzenia sceny z obrazu jest w zasadzie niemoŋliwy. Jednak ludzie i inne zwierzęta radzą sobie bardzo dobrze w trójwymiarowym ķwiecie. Wydaje się, ŋe potrafią zinterpretowaæ dwuwymiarowe obrazy powstaģe na ich siatkówkach w sposób, który zapewnia im doķæ dokģadne i uŋyteczne informacje o ich otoczeniu. Wzrok stereo przy uŋyciu dwojga oczu pomaga uzyskaæ informacje o gģębi. Widzenie komputerowe równieŋ moŋe korzystaæ ze 'stereopsis ", wykorzystując dwie lub więcej kamer o róŋnych lokalizacjach, patrząc na tę samą scenę. (Ten sam efekt moŋna uzyskaæ, przesuwając jedną kamerę w róŋne pozycje.) Gdy uŋywane są dwie kamery, na przykģad utworzone przez nie obrazy są nieznacznie przesunięte względem siebie, a to przesunięcie moŋna wykorzystaæ do obliczenia odlegģoķci do róŋnych częķci sceny. Obliczenia obejmują porównanie względnych lokalizacji na obrazach, które odpowiadają obiektom w scenie, dla których gģębokoķæ pomiary są poŋądane. Ten "problem korespondencji" zostaģ rozwiązany na róŋne sposoby, z których jednym jest poszukiwanie wysokich korelacji między maģymi obszarami na jednym obrazie z maģymi obszarami na drugim. Raz "rozbieŋnoķæ" poģoŋenia cechy obrazu w dwa obrazy są znane, odlegģoķæ do tej częķci sceny, która spowodowaģa powstanie tej cechy obrazu, moŋna obliczyæ za pomocą obliczeņ trygonometrycznych (do których nie będę tutaj wchodziģ.) Byæ moŋe zaskakujące y, wiele informacji o gģębokoķci moŋna uzyskaæ z innych sygnaģów oprócz widzenia stereo. Niektóre z tych wskazówek są nieodģączne od jednego obrazu i opiszę je w póžniejszych rozdziaģach. Co waŋniejsze, podstawowa wiedza na temat rodzajów obiektów, które moŋna zobaczyæ na kontach odpowiada za duŋą częķæ naszej zdolnoķci do interpretacji obrazów. Rozwaŋmy na przykģad obraz pokazany poniŋej
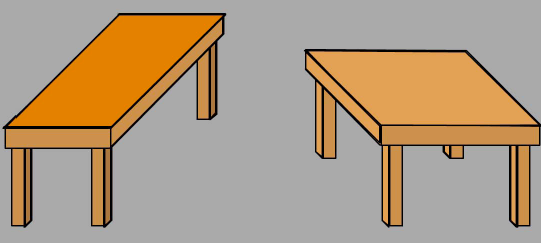
Większoķæ ludzi opisaģaby ten obraz jako skģadający się z dwóch stoģów, jednego dģugiego i wąskiego, a drugiego mniej więcej kwadratowego. Jeķli jednak zmierzysz rzeczywiste blaty na samym obrazie, moŋesz byæ zaskoczony, gdy zobaczysz, ŋe mają dokģadnie taki sam rozmiar i ksztaģt! (Ilustracja opiera się na iluzji zwanej "przewracaniem stoģu" przez psychologa Rogera Shepherda i jest adaptacją wersji Michaela Bacha ze schematu Shepherda. Jak zobaczymy, ta dodatkowa informacja skģada się z dwóch rzeczy: wiedzy o procesie tworzenia obrazu w róŋnych warunkach oķwietleniowych oraz wiedzy o rodzajach rzeczy i ich powierzchniach, które występują w naszym trójwymiarowym ķwiecie. Gdybyķmy mogli wyposaŋyæ komputery w tego rodzaju wiedzę, byæ moŋe i oni byliby w stanie to zobaczyæ.
Wskazówki z biologii
Nastąpiģ staģy przepģyw informacji tam i z powrotem między naukowcami próbującymi zrozumieæ, w jaki sposób dziaģa widzenie u zwierząt, a inŋynierami pracującymi nad widzeniem komputerowym. Wczesny przykģad pracy na skrzyŋowaniu tych dwóch zainteresowaņ zostaģ opisany w artykule zatytuģowanym "Co oko ŋaby mówi mózgowi ŋaby" autorstwa czterech naukowców z MIT. Kierując się poprzednimi pracami biologicznymi, Jerome Lettvin, HR Maturana, Warren McCulloch i Walter Pitts zbadali częķci mózgu ŋaby, które przetwarzają obrazy. Stwierdzili, ŋe system wizualny ŋaby skģadaģ się z "detektorów", które reagowaģy tylko na pewne rodzaje elementów w jej polu widzenia. Miaģ detektory maģych, ruchomych wypukģych obiekty (takie jak muchy) i nagģe przyciemnienie oķwietlenia (które moŋe byæ spowodowane przez zbliŋającego się drapieŋnika), które wraz z kilkoma innymi prostymi wykrywaczami dostarczyģy ŋabie informacji o jedzeniu i niebezpieczeņstwie. W szczególnoķci system wizualny ŋaby najwyražniej nie skonstruowaģ kompletnego trójwymiarowego modelu sceny wizualnej. Jak napisali autorzy:
"Ŋaba wydaje się nie widzieæ, a w kaŋdym razie nie przejmuje się szczegóģami stacjonarnych częķci ķwiata wokóģ niej. Będzie gģodowaģ ,na ķmieræ ,otoczona jedzeniem, jeķli się nie porusza. Wybór jedzenia zaleŋy od wielkoķci i ruchu. Skoczy, aby schwytaæ dowolny obiekt wielkoķci owada lub robaka, pod warunkiem, ŋe porusza się jak on. Moŋna ją ģatwo oszukaæ nie tylko przez zwisające mięso, ale takŋe przez kaŋdy poruszający się maģy przedmiot. Jej ŋycie seksualne prowadzone jest za pomocą džwięku i dotyku. Jej wybór ķcieŋek ucieczki odwrogów nie wydaje się byæ rządzony przez nic bardziej przebiegģego niŋ skakanie tam, gdzie jest ciemniej. Skoro jest ona równie dobra w domu na wodzie i na lądzie, dlaczego miaģoby to mieæ znaczenie, gdzie zapala się po skoku lub jaki konkretny kierunek obiera?"
Inne eksperymenty przyniosģy dalsze informacje o tym, jak mózg przetwarza obrazy wizualne. Neurofizjolodzy David Hubel i Torsten Wiesel przeprowadzili serię eksperymentów, począwszy od okoģo 1958 r., które wykazaģy, ŋe niektóre neurony w korze wzrokowej ssaków reagowaģy wybiórczo na obrazy i częķci obrazów o okreķlonych ksztaģtach. W 1959 roku wszczepili mikroelektrody do pierwotnej kory wzrokowej znieczulonego kota. Odkryli, ŋe niektóre neurony szybko czerwienieją, gdy kotowi pokazano obrazy maģych linii pod jednym kątem, a inne neurony szybko czerwienią w odpowiedzi na maģe linie pod innym kątem. W rzeczywistoķci mogliby stworzyæ "mapę" tego obszaru mózgu kota, odnosząc lokalizację neuronu do kąta linii. Nazwali te neurony "prostymi komórkami" -w celu odróŋnienia od innych komórek, zwanymi "komórkami zģoŋonymi", które reagowaģy selektywnie na linie poruszające się w okreķlonym kierunku. Póžniejsze prace ujawniģy, ŋe inne neurony specjalizowaģy się w reagowaniu na obrazy zawierające bardziej zģoŋone ksztaģty, takie jak rogi, dģuŋsze linie i duŋe krawędzie. Stwierdzono, ŋe podobne wyspecjalizowane neurony istniaģy równieŋ w mózgach maģp. Hubel i Wiesel otrzymali Nagrodę Nobla w dziedzinie fizjologii lub medycyny w 1981 r. (Wspólnie z Rogerem Sperry′m za inne prace). Prace Hubela i Wiesela pomogģy potwierdziæ ich pogląd, ŋe znajdowanie linii na obrazach jest waŋną częķcią procesu wizualnego. Jednak proste linie rzadko występują w naturalnych ķrodowiskach, w których ewoluowaģy koty (i ludzie), więc dlaczego one (i my) mają neurony wyspecjalizowane w ich wykrywaniu? W rzeczywistoķci w 1992 r. neuronaukowcy Horacy B. Barlow i David J. Tolhurst napisali artykuģ zatytuģowany "Dlaczego masz detektory krawędzi?". Jako moŋliwą odpowiedž na to pytanie Anthony J. Bell i Terrence J. Sejnowski wykazali póžniej matematycznie, ŋe sceny naturalne moŋna analizowaæ jako waŋone podsumowanie maģych krawędzi, nawet jeķli same sceny nie mają wyražnych krawędzi
Rozpoznawanie twarzy
Na początku lat szeķædziesiątych w swojej firmie w Palo Alto, Panoramic Research, Woodrow (Woody) W. Bledsoe (który póžniej pracowaģ nad automatycznym dowodzeniem twierdzeņ na University of Texas), wraz z Charlesem Bisson i Helen Chan (póžniej Helen Chan Wolf), opracowaģ techniki rozpoznawania twarzy wspierane przez projekty CIA. Oto opis ich podejķcia zaczerpnięty z pamiątkowego artykuģu:
"Ten projekt [rozpoznawania twarzy] zostaģ nazwany czģowiek-maszyna, poniewaŋ czģowiek wyodrębniģ ze zdjęæ wspóģrzędne zestawu funkcji, które następnie zostaģy uŋyte przez komputer do rozpoznania. Za pomocą GRAFACON lub RAND TABLET operator wyodrębni wspóģrzędne takich elementów, jak ķrodek žrenic, wewnętrzny kącik oczu, zewnętrzny kącik oczu, punkt wierzchoģka wdów i tak dalej. Na podstawie tych wspóģrzędnych obliczono listę 20 odlegģoķci, takich jak szerokoķæ ust i szerokoķæ oczu, od žrenicy do žrenicy. Operatorzy ci mogą przetwarzaæ okoģo 40 zdjęæ na godzinę. Podczas budowania bazy danych nazwisko osoby na zdjęciu byģo powiązane z listą obliczonych odlegģoķci i przechowywane na komputerze. W fazie rozpoznawania zestaw odlegģoķci porównano z odpowiednią odlegģoķcią dla kaŋdego zdjęcia, uzyskując odlegģoķæ między zdjęciem a zapisem bazy danych. Zwracane są najbliŋsze rekordy."
Bledsoe kontynuowaģ tę pracę z Peterem Hartem w SRI po odejķciu z Panoramic w 1966 r. Następnie w 1970 r. na Stanfor ,student, Michael D. Kelly, napisaģ program komputerowy, który byģ w stanie automatycznie wykrywaæ rysy twarzy na zdjęciach i wykorzystywaæ je do identyfikowania ludzi. Zadaniem jego programu byģo, jak sam to okreķliģ,
"wybór z kolekcji zdjęæ osoby wykonane kamerą telewizyjną, te zdjęcia przedstawiające tę samą osobę. . . . W skrócie, program dziaģa poprzez wyszukiwanie lokalizacji takich elementów, jak oczy, nos lub ramiona na zdjęciach. . . . Interesującą i trudną częķcią pracy opisanej w tej pracy jest wykrycie tych cech na zdjęciach cyfrowych. Metodę najbliŋszego sąsiada stosuje się do identyfikacji osobników po uzyskaniu zestawu pomiarów. "
Inną pionierską pracą w rozpoznawaniu twarzy byģ badacz wzroku Takeo Kanade, obecnie profesor na Uniwersytecie Carnegie Mellon. W przemówieniu z 2007 r. podczas jedenastej międzynarodowej konferencji IEEE na temat widzenia komputerowego zastanowiģ się nad swoją wczesną pracą w tej dziedzinie: "Napisaģem mój program rozpoznawania twarzy w języku asemblera i uruchomiģem go na maszynie o czasie cyklu 10 mikrosekund i 20 kB pamięci gģównej. Z dumą przetestowaģem program z 1000 obrazów twarzy, co jest rzadkim przypadkiem w czasie, gdy testowanie przy uŋyciu 10 obrazów byģo nazywane eksperymentem na duŋą skalę. " Programy do rozpoznawania twarzy z lat 60. i 70. miaģy kilka ograniczeņ. Zazwyczaj wymagaģy, aby obrazy miaģy twarze o standardowej skali, pozie, wyrazie i iluminacji.
Komputerowa wizja trójwymiarowych obiektów staģych
System wczesnego widzenia
Lawrence G. Roberts , doktorant MIT ,student pracujący w Lincoln Laboratory byģ prawdopodobnie pierwszą osobą, która napisaģa program, który mógģby identyfikowaæ obiekty na czarno-biaģych (w skali szaroķci) fotografiach oraz okreķlaæ ich orientację i pozycję w przestrzeni. (Jego program byģ równieŋ pierwszym zastosowaniem algorytmu "ukrytej linii, tak waŋnego w póžniejszych pracach nad grafiką komputerową. Jako gģówny naukowiec, a póžniej dyrektor biura ARPA ds. technik przetwarzania informacji, Roberts póžniej odegraģ waŋną rolę w stworzenie ARPANETu, prekursora Internetu.) We wstępie do swojej rozprawy doktorskiej MIT z 1963 roku Roberts napisaģ:
"Problem maszynowego rozpoznawania danych obrazowych od dawna jest trudnym celem, ale rzadko podejmowano próby uŋycia czegoķ bardziej zģoŋonego niŋ znaki alfabetyczne. Wiele osób uwaŋa, ŋe badania nad rozpoznawaniem postaci byģyby pierwszym krokiem, prowadzącym do bardziej ogólnego systemu rozpoznawania wzorców. Jednak wiele prób rozpoznania postaci, w tym mojej wģasne, nie doprowadziģy bardzo daleko. Wydaje mi się, ŋe powodem tego jest to, ŋe badanie abstrakcyjnych, dwuwymiarowych form prowadzi nas od technik, a nie w kierunku technik niezbędnych do rozpoznawania trójwymiarowych obiektów. Postrzeganie ciaģ staģych jest procesem, który moŋe opieraæ się na wģaķciwoķciach trójwymiarowych transformacji i prawach przyrody. Ostroŋnie wykorzystując te wģaķciwoķci opracowano procedurę, która nie tylko identyfikuje obiekty, ale takŋe okreķla ich orientację i poģoŋenie w przestrzeni."
System Roberta najpierw przetworzyģ zdjęcie sceny, aby stworzyæ przedstawienie rysunku linii. Następnie przeksztaģciģ rysunek linii w trójwymiarową reprezentację. Dopasowanie tej reprezentacji do zapisanej listy reprezentacji obiektów bryģowych pozwoliģo jej sklasyfikowaæ oglądany obiekt. Moŋe równieŋ wytworzyæ obraz komputerowo-graficzny obiektu, który moŋna zobaczyæ z dowolnego punktu widzenia. Naszym gģównym zainteresowaniem jest sposób, w jaki Roberts przetworzyģ obraz fotograficzny. Po zeskanowaniu fotografii i przedstawieniu jej jako tablicy liczb (pikseli) reprezentujących wartoķci intensywnoķci Roberts zastosowaģ specjalne obliczenie, zwane póžniej "Krzyŋem Robertsa", w celu ustalenia, czy kaŋdy maģy kwadrat 2 x 2 w tablicy odpowiada częķæ obrazu z nagģą zmianą intensywnoķci obrazu. (Krzyŋ Robertsa byģ pierwszym przykģadem czegoķ, co póžniej nazwano "operatorami gradientu"). Następnie reprezentowaģ obraz "oķwietlając" tylko te częķci obrazu, w których intensywnoķæ zmieniģa się nagle i pozostawiając "ciemne" te częķci obrazu o mniej więcej jednolitej intensywnoķci. Duŋe zmiany intensywnoķci obrazu są zwykle związane z krawędziami obiektów. Tak więc operatory gradientu, takie jak krzyŋ Robertsa, są często nazywane "detektorami krawędzi". Program Robertsa byģ w stanie przeanalizowaæ wiele róŋnych zdjęæ ciaģ staģych. Skomentowaģ, ŋe "Caģy proces rysowania obrazu do linii nie jest optymalny, ale dziaģa na proste zdjęcia". Sukces Robertsa pobudziģ dalsze prace nad programami do ndingowania linii w obrazach i do ģączenia tych linii w reprezentacje obiektów. Byæ moŋe zagruntowane przez wybór staģych obiektów przez Robertsa, wiele póžniejszych prac dotyczyģo klocków zabawek (lub "cegieģ", jak się je nazywa w Wielkiej Brytanii).
"Projekt Summer Vision"
Co ciekawe, Larry Roberts byģ studentem teorii informacji MIT, u profesora Peter Elias, nie Marvin Minsky. Ale grupa Minsky′ego wkrótce zaczęģa równieŋ pracowaæ nad widzeniem komputerowym. Latem 1966 roku matematyk i psycholog Seymour Papert, niedawno przybyģy do MIT's Artifiial Intelligence Group, uruchomiģ "projekt letniej wizji". Jego celem byģo opracowanie zestawu programów, które analizowaģyby obraz z "videsector" (rodzaj skanera), aby "faktycznie nazwaæ obiekty [takie jak kule, cylindry i bloki] poprzez dopasowanie ich do sģownictwa znanych obiektów. " Jedną z motywacji tego projektu byģo "efektywne wykorzystanie naszych letnich pracowników do budowy znacznej częķci systemu wizualnego". Oczywiķcie problem budowy "znaczącej częķci ukģadu wzrokowego" byģ znacznie trudniejszy niŋ się spodziewaģ Papert. Niemniej jednak projekt odniósģ sukces, poniewaŋ rozpocząģ ciągģy wysiģek w badaniach komputerowych w MIT, który trwa do dziķ. Po tych wczesnych próbach na MIT (i podobnych, w Stanford i SRI), badania widzenia komputerowego skupiģy się na dwóch obszarach. Pierwszym byģo to, co moŋna nazwaæ wizją "niskiego poziomu" {te pierwsze etapy przetwarzania obrazu które miaģy na celu zbudowanie reprezentacji obrazu jako rysunku linii, biorąc pod uwagę obraz, który byģ sceną zawierającą raczej proste obiekty. Drugi obszar dotyczyģ sposobu analizy rysunku linii jako zestawu oddzielnych obiektów, które moŋna zlokalizowaæ i zidentyfikowano. Waŋną częķcią widzenia na niskim poziomie byģo "przefiltrowanie obrazu", które zostanie opisane poniŋej.
Filtrowanie obrazu
Pomysģ filtrowania obrazu w celu uproszczenia go, korekty szumu i poprawy niektórych funkcji obrazu trwaģ juŋ od dekady lub dģuŋej. W 1955 roku Gerald P. Dinneen przetwarzaģ obrazy w celu usunięcia szumu i poprawienia krawędzi. Russell Kirsch i koledzy eksperymentowali równieŋ z przetwarzaniem obrazu. (Czytelnicy, którzy zmanipulowali swoje zdjęcia cyfrowe na komputerze, skorzystali z niektórych z tych filtrów obrazu). Filtrowanie obrazów dwuwymiarowych nie róŋni się tak bardzo od filtrowania jednowymiarowych sygnaģów elektronicznych {operacja powszechna. Byæ moŋe najprostszą operacją, którą moŋna opisaæ, jest "uķrednianie ", które rozmywa drobne szczegóģy i usuwa przypadkowe plamki szumu. Podobnie jak we wszystkich operacjach uķredniania, uķrednianie obrazu uwzględnia sąsiednie wartoķci i ģączy je. Wežmy na przykģad tablicę obrazów pokazanych wartoķci natęŋenia na rysunku poniŋej, zawierającym "okno uķredniające" 3 x 3 przedstawione pogrubioną czcionką.

Te wartoķci intensywnoķci odpowiadają obrazowi, którego prawa strona jest jasna, a lewa strona jest ciemna, z ostrą krawędzią pomiędzy. (Przyjmuję konwencję, ŋe duŋe liczby, takie jak 10 odpowiadają jasno oķwietlonym częķciom obrazu, a liczba 0 odpowiada czerni.) Operacja uķredniania przesuwa okno uķredniania na caģy obraz, tak aby jego ķrodek leŋaģ kolejno nad kaŋdym pikselem. Dla kaŋdego umiejscowienia okna wartoķæ intensywnoķci w jego ķrodku jest zastępowana (w wersji po przefiltrowaniu) ķrednią intensywnoķcią wartoķci w oknie. (Proces przesuwania okna wokóģ obrazu i wykonywania obliczeņ na podstawie liczb w oknie nazywa się splotem.) W tym przykģadzie wartoķæ 0 w ķrodku okna zostaģaby zastąpiona wartoķcią 3,33 (byæ moŋe zaokrągloną w dóģ do 3). Widaæ, ŋe uķrednianie zaciera ostrą krawędž {z 10 zanikaniem do (zaokrąglenia) 7 zanikaniem do 3 zanikaniem do 0, gdy porusza się od prawej do lewej. Jednak intensywnoķci w obrębie równomiernie oķwietlonych regionów nie ulegają zmianie. Wspomniaģem juŋ o innej waŋnej operacji filtrowania, Krzyŋu Robertsa, sģuŋącej do wykrywania nagģych zmian jasnoķci obrazu. Kolejny zostaģ opracowany w 1968 roku przez doktora, student w Stanford, Irwina Sobela. Raj Reddy nazwaģ go "Operatorem Sobela", który opisaģ to podczas kursu komputerowego w Stanford. Operator wykorzystuje dwa okna filtrowania - jedno wraŋliwe na duŋe gradienty (zmiany intensywnoķci) w kierunku pionowym i jedno na duŋe gradienty w poziomie kierunek. Pokazano je tu
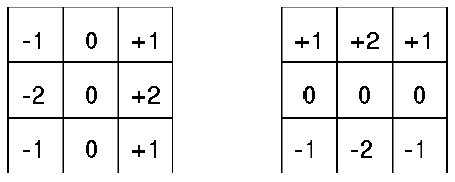
Kaŋdy z filtrów Sobela dziaģa tak samo, jak filtr uķredniający, z tym wyjątkiem, ŋe intensywnoķæ obrazu w kaŋdym punkcie jest mnoŋona przez liczbę w odpowiedniej komórce okna filtrowania przed dodaniem wszystkich liczb. Suma wynosiģaby 0 w obszarach jednolitego oķwietlenia. Jeķli pionowy filtr jest wyķrodkowany na pionowej krawędzi (prawą stroną jaķniejszą niŋ lewą), suma byģaby dodatnia. (Pozwolę ci pomyķleæ o innych moŋliwoķciach.) Wyniki z dwóch okien filtrowania są ģączone matematycznie, aby wykryæ nagģe zmiany w dowolnym kierunku. Zaproponowano wiele innych bardziej zģoŋonych i solidnych operacji przetwarzania obrazu, które wykorzystano do znajdowanai krawędzi, linii i wierzchoģków obiektów na obrazach. Szczególnie interesującą z nich dla znajdowania krawędzi zaproponowali brytyjski neurolog i psycholog David Marr i Ellen Hildreth. Detektor krawędzi Marra-Hildretha wykorzystuje okno filtrowania zwane a "Laplacian of Gaussian (LoG)." (Nazwa powstaje, poniewaŋ operator matematyczny o nazwie "Laplacian" jest uŋywany na krzywej w ksztaģcie dzwonu zwanej "Gaussian", upamiętniającej dwóch sģynnych matematyków, a mianowicie Pierre-Simona Laplace′a i Carla Friedricha Gaussa. Poniŋej pokazano przykģad liczb LoG w oknie filtrowania 9 x 9.

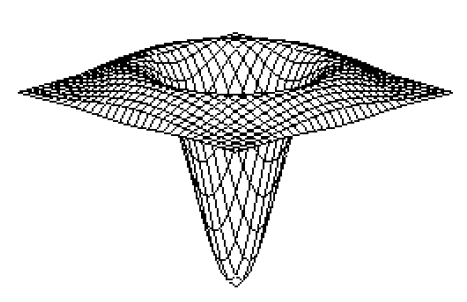
To okno jest przesuwane wokóģ obrazu, mnoŋąc numery obrazów i dodając je, w taki sam sposób, jak inne okna filtrowania, o których juŋ wspomniaģem. Jeķli liczby LoG są wykreķlane jako "wysokoķci " powyŋej (i poniŋej) pģaszczyzny, ciekawie wyglądające wyniki na powierzchni. Przykģad pokazano poniŋej. Ta funkcja LoG jest często nazywana, co nie jest zaskoczeniem, meksykaņską czapką lub funkcją sombrero.
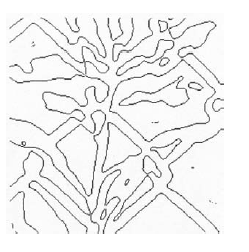
Marr i Hildreth uŋyli okna filtrowania LoG na kilku przykģadowych zdjęciach. Jeden przykģad wzięty z ich pracy. Zauwaŋ, ŋe obraz po prawej stronie ma biaģawe pasy otaczające ciemniejsze częķci obrazu. Detektor krawędzi Marra-Hildretha wykorzystuje drugą operację przetwarzania obrazu, która szuka przejķcia od jasnego do ciemnego (i odwrotnie) na obrazie przetworzonym LoG, aby uzyskaæ ostateczny "rysunek linii", jak pokazano na rysunku
Poczyniono dalsze postępy w wykrywaniu krawędzi od czasu pracy Marra i Hildretha. Wķród obecnie najlepszych detektorów są detektory związane z jednym zaproponowanym przez Johna Canny′ego, zwanym detektorem krawędzi Canny. Jako neurofizjolog Marr byģ szczególnie zainteresowany tym, jak ludzki mózg przetwarza obrazy. W artykule z 1976 r. zasugerowaģ, ŋe pierwszy etap przetwarzania daje tak zwany "pierwotny szkic". Jak ujmuje to w podsumowaniu tego artykuģu, argumentuje się, ŋe pierwszym krokiem konsekwencji jest obliczenie prymitywnego, ale bogatego opisu zmian poziomu szaroķci obecnych na obrazie. Opis wyraŋony jest w sģowniku rodzajów zmian intensywnoķci (KRAWĘDŽ, KRAWĘDZIE CIENIA, KRAWĘDZIE PRZEDĢUŊONE, LINIA, BLOB itp.)… Opis ten uzyskano z tablicy intensywnoķci za pomocą technik staģych i nazywa się to szkicem pierwotnym. Marr i Hildreth przedstawili swój detektor krawędzi jako jedną z operacji, których mózg uŋywa do wykonania pierwotnego szkicu. Stwierdzili, ŋe ich teoria "wyjaķnia kilka podstawowych psychofizycznych odkryæ i stanowi podstawę fizjologicznego modelu prostych komórek [nerwowych]". Obiecująca kariera Marra w badaniach nad wzrokiem zakoņczyģa się, gdy w 1980 r. zapadģ na raka. W ostatnich latach ŋycia ukoņczyģ waŋną ksiąŋkę opisującą swoje teorie ludzkiego widzenia.
Przetwarzanie rysunków linii
Zakģadając, moŋe nieco przedwczeķnie, ŋe procedury wizji niskiego poziomu mogą wytworzyæ wersję obrazu do rysowania linii, wielu badaczy przeszģo do opracowania metod analizy rysunków linii do obiektów na obrazach. Adolfo Guzman-Arenas, student z AI Group Minsky′ego, skupiģ się na tym, jak podzieliæ rysunki liniowe sceny zawierającej bloki na skģadniki, które Guzman nazwaģ "body" i dziaģaģ na komputerze PDP-6 grupy MIT AI. Dane wejķciowe do SEE stanowiģy liniowe przedstawienie sceny w kategoriach jej powierzchni, linii (gdzie dwie powierzchnie poģączyģy się) i wierzchoģków (gdzie linie się poģączyģy). Analiza SEE sceny rozpoczęģa się od posortowania jej wierzchoģków na wiele róŋnych typów. Dla kaŋdego wierzchoģka, w zaleŋnoķci od jego rodzaju, ZOBACZ poģączone powierzchnie pģaskie za pomocą " links. "Poģączenia między powierzchniami dowodzą, ŋe powierzchnie te naleŋą do tego samego obiektu. Na przykģad niektóre poģączenia dla sceny analizowanej przez SEE pokazano tu
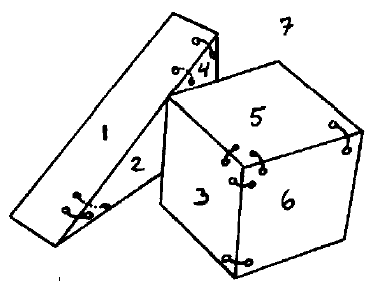
ZOBACZ caģkiem dobre wyniki na szerokiej gamie rysunków. Na przykģad poprawnie znalazģ wszystkie ciaģa w scenie pokazanej tu
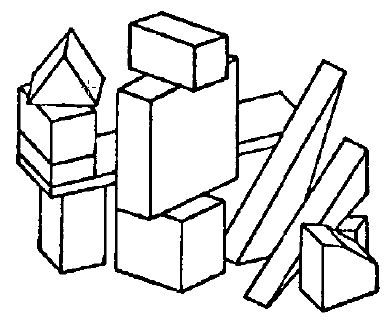
Przez większoķæ swojej pracy Guzman zakģadaģ, ŋe w jakiķ sposób inne programy wygenerują potrzebne rysunki z rzeczywistych obrazów. Jak napisaģ w artykule opisującym swoje badania. Sama scena nie jest uzyskiwana z wizualnego urządzenia wejķciowego ani z szeregu intensywnoķci jasnoķci. Zakģada się raczej, ŋe miaģo miejsce jakieķ wstępne przetwarzanie, a scena do analizy jest dostępna w formacie symbolicznym…pod względem punktów (wierzchoģków), linii (krawędzi) i powierzchni (regionów).
Ponadto Guzman nie przejmowaģ się tym, co moŋna zrobiæ po podzieleniu sceny na ciaģa:
… nie moŋe znaležæ w scenie "kostek" ani "domów", poniewaŋ nie wie, czym jest "dom". Kiedy SEE podzieli scenę na ciaģa, jakiķ inny program będzie nad nimi pracowaģ i zdecydowaģ, który z nich te ciaģa to "domy".
Póžniejsze rozszerzenia SEE, zgģoszone w ostatecznej wersji jego pracy, obejmowaģy pewne procedury przechwytywania obrazu. Ale obrazy byģy ze specjalnie przygotowanymi scenami, jakie niedawno opracowaģ: Pierwotnie ZOBACZ pracowaģ na ręcznie rysowanych scenach, "scenach idealnych" (rysunki linii). Póžniej zbudowaģ kilka drewnianych wieloķcianów (gģównie nieregularnych), pomalowanych na czarno, starannie pomalowane krawędzie na biaģo, uģoŋyģ kilka z nich razem i zrobiģ zdjęcia scen. Zdjęcia zostaģy zeskanowane, znalezione krawędzie i przekazane ZOBACZ. Dziaģaģo na nich caģkiem niežle. Chociaŋ ZOBACZYĢ raczej skomplikowane sceny, mogą takŋe popeģniaæ bģędy i nie mogą zidentyfikowaæ bloków z dziurami. Kolejną osobą, która zajęģa się problemem artykulacji sceny, byģ David Huffman, profesor inŋynierii elektrycznej w MIT. (Huffman byģ znany ze swojego wynalazku, czegoķ, co nazwano "kodowaniem Huffmana", skutecznego schematu stosowanego obecnie w wielu aplikacjach obejmujących kompresję i transmisję danych
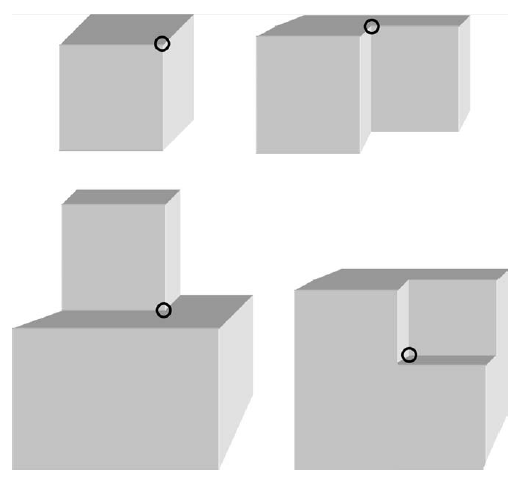
cyfrowych). Huffmanowi przeszkadzaģo to co rozwaŋono jako niepeģną analizę Guzmana dotyczącą tego, jakie obiekty mogą odpowiadaæ rodzajom rysunków. Po odejķciu z MIT w 1967 r., aby zostaæ profesorem informatyki i informatyki na Uniwersytecie Kalifornijskim w Santa Cruz, ukoņczyģ teorię przypisywania etykiet do linii na rysunkach bryģ trójķciennych - obiektów, w których dokģadnie trzy pģaskie powierzchnie ģączą się w kaŋdym wierzchoģku obiektu. Etykiety zaleŋaģy od tego, w jaki sposób pģaszczyzny mogą się ģączyæ w wierzchoģku. Huffman zwróciģ uwagę, ŋe istnieją tylko cztery sposoby, w których trzy pģaskie powierzchnie mogą poģączyæ się w jednym wierzchoģku. Pokazano je poniŋej
Oprócz tych czterech rodzajów wierzchoģków scena moŋe zawieraæ coķ, co Huffman nazwaģ "węzģami T" - typy przecięcia linii spowodowane przez jeden obiekt w scenie zasģaniającej inny. Wszystko to powoduje powstanie wielu róŋnych rodzajów etykiet dla linii na scenie; etykiety te okreķlają, czy linie odpowiadają krawędziom wypukģym, wklęsģym lub okluzującym. Huffman zauwaŋyģ, ŋe etykiety linii na rysunku mogą byæ lokalnie spójne (wokóģ niektórych wierzchoģków), ale nadal globalnie niespójne (wokóģ wszystkich wierzchoģków). Rozwaŋmy na przykģad sģynny rysunek linii "niemoŋliwego obiektu" Rogera Penrose&primela pokazany tu
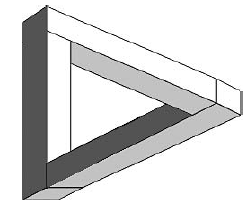
(Jest to niemoŋliwe, poniewaŋ ŋaden trójwymiarowy obiekt oglądany w "pozycji ogólnej" nie mógģby wytworzyæ tego obrazu.) Ŋadna "prawdziwa scena" nie moŋe mieæ linii z dwiema róŋnymi etykietami. Max Clowes z Sussex University w Wielkiej Brytanii opracowaģ niezaleŋnie podobne pomysģy, a schemat znakowania jest obecnie ogólnie znany jako znakowanie Huffmana-Clowesa. Następnie pojawia się David Waltz . W swojej pracy doktoranckiej na MIT z 1972 r. tezę rozszerzyģ o schemat znakowania linii Huffmana-Clowesa, aby umoŋliwiæ rysowanie linii scen z cieniami i moŋliwymi "pęknięciami" między dwoma sąsiadującymi obiektami. Waŋnym wkģadem Waltza byģo zaproponowanie i wdroŋenie skutecznej metody obliczeniowej dla speģnienia ograniczenia, które wszystkie linie muszą mieæ przypisaną jedną i tylko jedną etykietę (na przykģad krawędž nie moŋe byæ wklęsģa na jednym koņcu i wypukģa na drugim.) Poniŋej pokazano przykģad rysunku linii, który program Waltza mógģby poprawnie podzieliæ na częķci
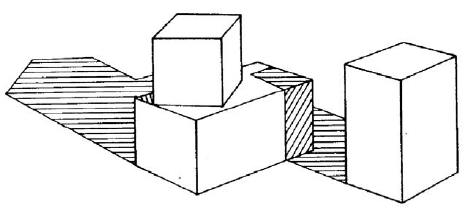
Podsumowując niektóre prace związane z przetwarzaniem rysunków linii w MIT, Patrick Winston mówi, ŋe "Guzman byģ eksperymentatorem, teoretykiem Huffmana i encyklopedystą Waltzem (poniewaŋ Waltz musiaģ skatalogowaæ tysiące skrzyŋowaņ, aby poradziæ sobie z pęknięciami i cieniami). ". W międzyczasie podobną pracę nad wyszukiwaniem, identyfikowaniem i opisywaniem obiektów w trójwymiarowych scenach wykonano w Stanford. Do 1972 r. doktor inŋynierii elektrycznej Gilbert Falk mógģ podzieliæ sceny rysunków liniowych na osobne obiekty, stosując techniki będące przedģuŋeniami Guzmana. A do 1973 r. doktor informatyki, Gunnar Grape dokonaģ segmentacji scen zawierających równolegģoķciany i kliny przy uŋyciu modeli tych obiektów. Inną pracę nad analizą scen zawierających wieloķciany wykonaģ Yoshiaki Shirai podczas wizyty w AI Lab32 MIT i Alana Mackwortha w Laboratorium Psychologii Doķwiadczalnej na Uniwersytecie w Sussex.