Zrozumienie zapytaņ i sygnaģów
Ustawienie
Aŋ do okoģo poģowy lat 70. XX wieku menedŋerowie DARPA byli w stanie zģagodziæ wpģyw poprawki Mansfielda (która wymagaģa, aby badania Departamentu Obrony byģy dostosowane do potrzeb wojskowych), opisując komputerowe programy badawcze w sposób, który podkreķlaģ zastosowania. Larry Roberts, dyrektor IPTO DARPA na przeģomie lat 60-tych i 70-tych, napisaģ, ŋe poprawka Mansfielda stworzyģa szczególny problem podczas mojego pobytu w DARPA. Zmusiģo nas to do wygenerowania znacznej dokumentacji i do obrony róŋnych rzeczy. Sprawiģo to, ŋe mamy więcej prac rozwojowych w porównaniu z pracami badawczymi, aby uzyskaæ taką mieszankę, abyķmy mogli ją obroniæ. Jednak nie sądzę, ŋe musiaģem porzuciæ projekt w naszej grupie z powodu poprawki Mansfielda. Zawsze moŋemy znaležæ sposób na obronę informatyki.. Formalne wnioski do Kongresu dotyczące AI zostaģy napisane, aby podkreķliæ moŋliwy wpģyw, a nie względy teoretyczne. Cordell Green, pracujący pod kierunkiem Robertsa w IPTO, napisaģ :
"Ogólnie rzecz biorąc, wszystko, co pojawiģo się w AI, myķleliķmy, ŋe wyglądaģo dobrze, wspierano… Jednym z moich zadaņ byģa obrona budŋetu AI, ale to nie byģo strasznie trudne … wszelkiego rodzaju informatyka jest istotna, poniewaŋ będzie miaģa duŋy wpģyw na kaŋdą duŋą organizację przetwarzającą informacje, a Departament Obrony jest z pewnoķcią taką organizacją … wszystkie te badania powinny pozostaæ przy ŋyciu, poniewaŋ miaģy potencjalne znaczenie wojskowe."
Jednak w poģowie lat siedemdziesiątych presja na produkcję wojskową byģa uŋyteczna ,systemy staģy się znacznie bardziej intensywne. DARPA, która hojnie wspieraģa raczej nieukierowane podstawowe badania nad sztuczną inteligencją, zamiast tego zaczęģa koncentrowaæ się na rozwiązywaniu "pilnych problemów DoD". Chociaŋ ówczesny dyrektor IPTO DARPA, J. C. R. Licklider, byģ jak zawsze ŋyczliwy dla podstawowych badaņ nad AI, najwyŋsze kierownictwo DARPA miaģo zupeģnie inne podejķcie. Licklider miaģ trudnoķci z wytģumaczeniem swojego programu sztucznej inteligencji "front office" DARPA. Dyrektor DARPA na początku lat 70. Stephen Lukasik byģ (zgodnie z Lickliderem)
"ani za, ani przeciw AI. Byģ za dobrym zarządzaniem i wpadģ na pomysģ, ŋe byæ moŋe niektóre rzeczy związane z AI nie byģy zbyt dobrze zarządzane. . . . [Miaģ] przekonany, ŋe propozycja nie jest propozycją, chyba ŋe ma kamienie milowe. Myķlę, ŋe wierzyģ, ŋe im więcej kamieni milowych, tym lepsza propozycja. . . . Myķlę, ŋe nie byģo niechęci do rozwijania AI, ale przekonanie, ŋe to taki waŋne pole, ŋe naukowcy muszą nauczyæ się ŋyæ w większa, bardziej sztywna, ustrukturyzowana biurokracja"
Poglądy Lukasika na temat sposobu zarządzania projektami miaģy bezpoķredni wpģyw na podstawowe badania wspierane przez DARPA w AI. Na przykģad" Kwartalne sprawozdanie z zarządzania ", które przedģoŋono w lutym 1975 r., opisujące postępy w Komputerowym Konsultancie SRI spowodowaģ, ŋe Licklider zapytaģ, w jaki sposób moŋna przeksztaģciæ raport, aby podkreķliæ postępy na okreķlonych ķcieŋkach w "Tabeli PERT". "Co chciaģbym mieæ" - napisaģ w liķcie z 3 marca 1975 r. - "to Tabela PERT , dzięki czemu mogę zaznaczyæ osiągnięcia na czerwono i zobaczyæ, gdzie stoisz w odniesieniu do ogólnego wzorca. . . . Czy masz taki wykres? Jeķli tak, przeķlij mi kopię. Jeķli nie, to jak by to zrobiæ? Naprawdę nam w ARPA bardzo to pomaga"
Oczywiķcie w badaniach podstawowych, chociaŋ moŋna ogólnie opisaæ problemy, które próbuje się rozwiązaæ, nie moŋna (z wyprzedzeniem) opisaæ, jakie będą rozwiązania. wraz z postępem badaņ eksploracyjnych pojawiają się nowe problemy, więc nie moŋna nawet opisaæ wszystkich problemów z wyprzedzeniem. Nie moŋna sporządziæ takiego szczegóģowego planu badaņ podstawowych, jaki moŋna zastosowaæ w celu zastosowania juŋ opracowanej technologii do okreķlonych zastosowaņ Niestety zarządzanie DARPA zmieniģo się z ludzi, którzy rozumieli, jak inicjowaæ i zarządzaæ podstawowymi badaniami, na ludzi, którzy wiedzieli, jak zarządzaæ aplikacjami technologicznymi. Przejķcie w kierunku krótkoterminowych, intensywnie zarządzanych badaņ staģo się bardziej wyražne, gdy George Heilmeier zastąpiģ Stephena Lukasika jako Dyrektor DARPA w 1975 r. Heilmeier pochodziģ z RCA, gdzie kierowaģ grupą badawczą, która wynalazģa pierwszy wyķwietlacz ciekģokrystaliczny. Licklider napisaģ póžniej, ŋe Heilmeier "chciaģ zrozumieæ sztuczną inteligencję w sposób, w jaki rozumiaģ wyķwietlacze ciekģokrystaliczne. . . " . Jednym z zadaņ, które powierzyģ Heilmeier IPTO, byģo opracowanie "mapy drogowej" (czyli szczegóģowego planu) dla jej programu badawczego AI (i innych programów informatycznych). Ta mapa drogowa powinna podsumowaæ dotychczasowe osiągnięcia, wskazaæ obszary, w których istniejącą technologię moŋna zastosowaæ do problemów wojskowych, oraz wskazaæ kamienie milowe po drodze. Te "wskazówki" kierownictwa ARPA spowodowaģy ogromne trudnoķci dla Licklidera, niektóre z nich zostaģy wyjaķnione w e-mailu wysģanym do niektórych liderów badaņ nad AI w kwietniu 1975 r. Oto kilka fragmentów:
nie ma wojskowego "nabywcy" gotowego przejąæ go, gdy tylko koncepcja zostaģa dobrze sformuģowana…
[są] silne naciski nowego dyrektora, George Heilmeiera, ŋe IPTO "przekierowuje'' wysiģki AI uniwersytetu na pracę nad problemami, które mają prawdziwą waŋnoķæ DoD…
…sytuację komplikuje fakt, ŋe ARPA byģa za wspieraniem badaņ podstawowych na doķæ wysokim poziomie przez ponad dziesięæ lat (wydaģo na to ponad 50 milionów dolarów) i jest to naturalne pytanie nowego dyrektora, a nawet starego, z pytaniem: "Co otrzymaliķmy poza tym pod względem poprawy obrony narodowej?"
Zgodnie z notatką wielkanocną Licklidera, niektóre z rzeczy, które zdaniem Heilmeiera dla IPTO dla Departamentu Obrony byģy następujące:
• poproķ komputery, aby odczytaģy kod Morse'a w obecnoķci innego kodu i szumu,
• poproķ komputery, aby zidentyfikowaģy / wykryģy sģowa kluczowe w strumieniu mowy,
• rozwiązaæ "problem oprogramowania" DoD
• wnoszą rzeczywisty wkģad w dowodzenie i kontrolę, oraz
• zrób dobrą rzecz w sonarze.
Chociaŋ jeden z elementów na liķcie Heilmeiera dotyczyģ przetwarzania mowy , jedną z ofiar jego kadencji jako dyrektora DARPA byģ program SUR. Ŋaden z systemów opracowanych w ramach programu nie byģ w stanie reagowaæ w czasie rzeczywistym, ani nie mógģ poradziæ sobie z wystarczająco duŋymi sģownikami. Heilmeier uwaŋaģ (prawdopodobnie z sģusznego powodu), ŋe rozumienie mowy jest nadal podstawową dziaģalnoķcią badawczą. Pomyķlaģ więc, ŋe powinna je wspieraæ, powiedzmy, National Science Foundation (NSF), i odrzuciģ propozycje DARPA, aby go kontynuowaæ. Niestety większoķæ obszarów badawczych, które znajdowaģy się na wģasnej liķcie Licklidera (o czym równieŋ wspomniano w jego notatce wielkanocnej), nie byģa wyražnie wymieniona na liķcie Heilmeiera. (Nie mogę się oprzeæ wspominaniu o jednym z przedmiotów na liķcie Licklider:
"Opracuj system, który poprowadzi niedostatecznie przeszkolonych pracowników utrzymania ruchu przez konserwację skomplikowanego sprzętu." Jeden z przedmiotów Heilmeiera byģ jednak wystarczająco niejasny, aby uzasadniæ pracę zarówno w NLP, jak i przy widzeniu komputerowym. Byģo to "dowodzenie i kontrola", dziaģanie polegające na pozyskiwaniu i przedstawianiu odpowiednich informacji dowódcom, aby mogli skutecznie kontrolowaæ siģy zbrojne. Oficerowie programu DARPA, Floyd Hollister i puģkownik David Russell, byli w stanie przekonaæ kierownictwo DARPA, ŋe tekstowy dostęp w języku naturalnym do duŋych, rozproszonych baz danych będzie waŋnym elementem systemów dowodzenia i kontroli. Argumentowali, ŋe technologia takiego dostępu jest wystarczająco daleko, aby moŋna ją byģo zastosowaæ w tak zwanych "systemach testowych dowodzenia i kontroli". W koņcu Bill Woods i koledzy z BBN zademonstrowali juŋ LUNAR, naturalny język "front end" dla baz danych o skaģach księŋycowych. Kilku innych badaczy równieŋ rozpoczęģo prace nad problemem komunikowania się z komputerami przy uŋyciu języka angielskiego lub innego języka naturalnego. (Na przykģad ponad pięædziesiąt artykuģów na temat NLP zostaģo zaprezentowanych na piątym IJCAI w 1977 r. Na MIT, a wydanie biuletynu SIGART ACM z lutego 1977 r. Opublikowaģo podsumowanie trwających badaņ nad interfejsami języka naturalnego.) W kolejnej częķci opiszę niektóre osiągnięcia w tym okresie w zakresie komunikacji z komputerami przy uŋyciu języka naturalnego. Drugim obszarem o duŋym znaczeniu dla dowodzenia i kontroli byģa automatyzacja analizy zdjęæ lotniczych. Wykrywanie celów o znaczeniu wojskowym na tych zdjęciach, takich jak drogi, mosty i sprzęt wojskowy, zwykle wymagaģo godzin pracy analityków wywiadu. Poniewaŋ techniki opracowywane przez badaczy w dziedzinie widzenia komputerowego mogą dostarczyæ narzędzi pomagających ludzkim analitykom, DARPA miaģ dobre powody, by kontynuowaæ finansowanie badaņ nad widzeniem komputerowym. W 1976 r. rozpocząģ program "Image Understanding" (IU) w celu opracowania technologii wymaganej do automatycznej i póģautomatycznej interpretacji i analizy zdjęæ wojskowych i powiązanych obrazów. Chociaŋ początkowo byģ pomyķlany jako program pięcioletni, trwaģ (z szerszymi celami) przez ponad dwadzieķcia lat. Robienie czegoķ z sonarem byģo jednym z elementów na liķcie Heilmeiera. W swojej notatce wielkanocnej Licklider napisaģ: "Jednym z gģównych obszarów srebrnej kuli [Heilmeiera] jest podwodny džwięk i sonar, a IPTO wģaķnie "kupuje" projekt HASP (podejķcie AI Eda Feigenbauma)."
Dostęp języka naturalnego do systemów komputerowych
LIFER
W SRI Gary Hendrix opracowaģ system o nazwie LIFER (skrót od Language Interface Facility with Elliptical and Recursive Features), zaprogramowany w INTERLISP, do szybkiego rozwoju "frontonów" języka naturalnego do baz danych i innego oprogramowania . LIFER pozwoliģ nietechnicznemu uŋytkownikowi okreķliæ podzbiór języka naturalnego (na przykģad angielski) do interakcji z systemem baz danych lub innym oprogramowaniem. Analizator skģadni zawarty w LIFER mógģby następnie przetģumaczyæ zdania i zapytania w tym języku na odpowiednie interakcje z oprogramowaniem. LIFER miaģ mechanizmy do obsģugi danych eliptycznych (tzn. niekompletnych), do korygowania bģędów ortograficznych oraz do umoŋliwienia nowicjuszom rozszerzania języka za pomocą parafraz. Interesującą cechą LIFER byģo to, ŋe język, którym mógģ się posģugiwaæ, zostaģ zdefiniowany w kategoriach "wzorców", które wykorzystywaģy pojęcia semantyczne w dziedzinie aplikacji. Jednym z takich wzorców moŋe byæ na przykģad CO TO JEST < ATRYBUT > OD < OSOBY >, gdzie sģowa WHAT, IS, THE i OF to rzeczywiste sģowa, które mogą wystąpiæ w zapytaniu w języku angielskim, a < ATRYBUT > i < OSOBA > to "symbole wieloznaczne ", które mogą pasowaæ do dowolnego sģowa w predefiniowanych zestawach. < ATTRIBUTE > moŋe zostaæ zdefiniowane tak, aby pasowaģo do sģów takich jak WIEK, WAGA, WYSOKOĶÆ itp., A

CHAT-80
W latach 1979-1982 Fernando Pereirai David H. D. Warren opracowali system o nazwie CHAT-80 na University of Edinburgh. CHAT-80 byģ w stanie odpowiedzieæ na doķæ zģoŋone pytania w języku angielskim dotyczące bazy danych faktów geograficznych. Wedģug rozprawy Pereiry praca nad CHAT-80 rozpoczęģo się jako "próba wyjaķnienia i ulepszenia niektórych wczeķniejszych prac Alaina Colmerauera". CHAT-80 zostaģ napisany w PROLOGU, logicznym języku programowania opracowanym pierwotnie przez Alaina Colmerauera. W rzeczywistoķci gramatyka uŋywana przez CHAT-80 skģadaģa się z logicznych wzorów podanych w języku PROLOG. Na przykģad,
zdanie (s (NP, VP), S0, S): - fraza rzeczownikowa (NP, N, S0, S1),
fraza czasownika (VP, N, S1, S)
jest sposobem CHAT-80 stwierdzenia, ŋe "istnieje zdanie między punktami S0 i S w ciągu (sģów), jeķli istnieje fraza rzeczownikowa o numerze N (to znaczy liczba pojedyncza lub mnoga) między punktami S0 i S1, a fraza czasownika z liczbą N między punktami S1 i S" .Gramatyki zdefiniowane przez tego rodzaju klauzule PROLOG nazywane są gramatykami Definite Clause Grammars (DCG). Kilka takich klauzul byģo uŋywanych przez CHAT-80 do analizowania zdaņ angielskich. Rzeczywiste parsowanie zostaģo wykonane przez program PROLOG skģadający się z tych klauzul. W CHAT-80 obliczenie znaczenia (czyli semantyki) zapytania w języku angielskim byģo kierowane przez strukturę skģadniową zapytania (obliczoną przez program PROLOG) i byģo wyraŋony jako logiczna formuģa. Ta formuģa zostaģa następnie przeksztaģcony w indywidualne zapytania bazy danych potrzebne do udzielenia odpowiedzi na pierwotne pytanie. Oto kilka przykģadów (z rozdziaģu 5 rozprawy Pereiry) zapytania, na które CHAT-80 byģ w stanie odpowiedzieæ:
P: Jaka jest stolica Górnej Volty?
Odp .: Wagadugu
P: Stolicą którego kraju jest Londyn?
Odp .: Zjednoczone Królestwo
P: Jaki jest ocean, który graniczy z krajami afrykaņskimi i który graniczy z krajami azjatyckimi?
Odp .: Ocean Indyjski
P: Jakie są stolice krajów graniczących z Baģtykiem?
Odp .: Dania: Kopenhaga; wschodnie Niemcy: wschodni Berlin; Finlandia: Helsinki; Polska: Warszawa; Związek Radziecki: Moskwa; Szwecja: Sztokholm; zachodnie Niemcy: Bonn
P: Jaka jest ģączna powierzchnia krajów na poģudnie od równika, a nie w Australii?
Odp .: 10228 ksqmiles
P: W jakich kontynentach nie ma kraju, w którym znajdują się więcej niŋ dwa miasta, których populacja przekracza 1 milion?
Odp .: Afryka, Antarktyda, Australia
P: Który kraj graniczący z Morzem Ķródziemnym graniczy z krajem graniczącym z krajem, którego populacja przekracza populację Indii?
Odp.: Turcja
Chociaŋ przykģady te wskazują raczej imponującą wydajnoķæ, moŋliwoķci CHAT-80 byģy ograniczone ograniczonym sģownictwem i gramatyką. Ograniczenia te zostaģy szczegóģowo opisane w rozprawie Pereiry.
Przenoķne systemy zapytaņ w języku naturalnym
CHAT-80 zostaģ zaimplementowany jako system zapytaņ do bazy danych faktów geograficznych. Poniewaŋ jednak znaczna częķæ jego projektu nie byģa dostosowana do geografii, moŋna go ģatwo zmodyfikowaæ, aby obsģugiwaģ inne bazy danych. CHAT-80 byģ tylko jednym z kilku systemów zapytaņ, które moŋna byģo "przenosiæ" w tym sensie, ŋe moŋna je byģo dostosowaæ jako interfejsy języka naturalnego do róŋnych baz danych. Inne takie systemy zostaģy opracowane w ASK w Caltech, EUFID w SDC, IRUS w BBN, LDC-1 opracowany na Uniwersytecie Duke′a, NLP-DBAP opracowany w Bell Laboratories, a TEAM opracowany w SRI. Poniewaŋ wiem więcej o TEAM niŋ o innych, powiem kilka rzeczy na ten temat jako reprezentatywny dla jego klasy. TEAM (skrót od Transportable English Database Access Medium) byģ obsģugiwany przez DARPA i zostaģ zaprojektowany do pozyskiwania informacji o bazie danych z bazy danych przez administrator oraz interpretowaæ i odpowiadaæ na pytania bazy danych, które są zawarte w podzbiorze języka angielskiego odpowiednim dla tej bazy danych. TEAM, podobnie jak wiele innych przenoķnych systemów, zostaģ zbudowany w taki sposób, ŋe informacje potrzebne do dostosowania go do nowej bazy danych i odpowiadających jej tematów moŋna byģo uzyskaæ od eksperta w tej bazie danych, nawet jeķli on lub ona moŋe nic nie wiedzieæ o interfejsach języka naturalnego. Aby zilustrowaæ dziaģanie TEAM, jego projektanci wykorzystali bazę danych skģadającą się z czterech "plików" (lub "relacji") danych geograficznych. Przeķledzę niektóre kroki, które zespóģ TEAM uŋyģ do udzielenia odpowiedzi na pytanie "Pokaŋ najwyŋszy szczyt kaŋdego kontynentu". Zespóģ TEAM wykorzystaģ podsystem DIALOGIC do konwersji zapytania w języku angielskim na wyraŋenie logiczne. W ramach DIALOGIC podsystem oparty na DIAMOND przeprowadziģ analizę skģadniową z wykorzystaniem gramatyki DIAGRAM. Drzewo parsujące o najwyŋszym wyniku pokazano na rysunku
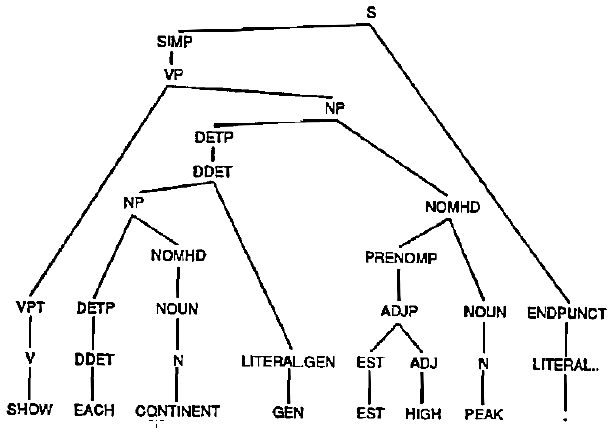
W oparciu o to drzewo analizy i wiedzę na temat pojęæ uŋywanych w bazie danych system analizy semantycznej przeksztaģciģ zapytanie w następujące wyraŋenie logiczne (tutaj przeksztaģcone w formie angielskiej dla lepszego zrozumienia):
FOR EVERY CONTINENT
WHAT IS EACH PEAK
SUCH THAT THE PEAK IS THE HIGHEST PEAK SUCH THAT
THE CONTINENT IS CONTINENT OF THE PEAK?
Następnie zespóģ TEAM wykorzystaģ swoją wiedzę na temat struktury bazy danych i tego, w jaki sposób komponenty tego logicznego wyraŋenia są powiązane z relacjami w bazie danych, w celu wygenerowania rzeczywistego zapytania do bazy danych i skonstruowania odpowiedzi.
HASP / SIAP
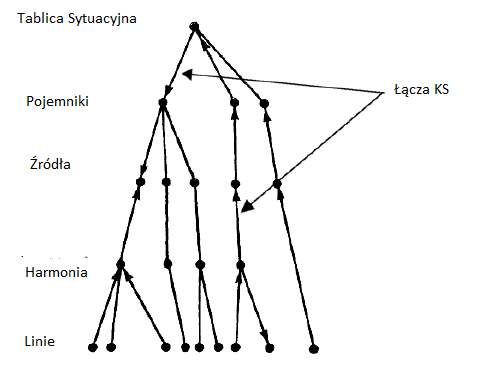
W 1972 r., gdy Larry Roberts byģ nadal dyrektorem IPTO, poprosiģ Eda Feigenbauma ze Stanford o zastanowienie się nad zastosowaniem pomysģów sztucznej inteligencji tak skutecznie wykorzystywanych w DENDRAL do problemu identyfikacji i ķledzenia statków i ģodzi podwodnych na oceanie przy uŋyciu danych akustycznych z ukrytego hydrofonu. Niektóre dane akustyczne zebrane przez ukģady hydrofonów pochodzą z obracających się waģów i ķmigieģ oraz maszyn tģokowych na pokģadzie statków. Róŋne statki emitują džwięki o wģasnych cechach identyfikujących podstawowe częstotliwoķci i harmoniczne. Ludzcy specjaliķci, którzy analizują tego rodzaju dane z monitoringu, patrzą na sonogramy džwięków oceanicznych i, dopasowując widma džwiękowe do przechowywanych referencji, próbują zidentyfikowaæ i zlokalizowaæ statki, które mogą byæ obecne (jeķli występują). Podejmowanie tych decyzji często wymaga wykorzystania informacji nieobecnych w samych sygnaģach, takich jak raporty z innych matryc czujników, raporty wywiadowcze oraz ogólna wiedza na temat cech statków i wspólnych szlaków morskich. Problem z analizą komplikuje kilka czynników: haģas tģa z odlegģych statków miesza się z haģasem burzowym i biologicznym. Ķcieŋki džwiękowe do tablic róŋnią się w zaleŋnoķci od cykli dobowych i sezonowych. Nadejķcie energii džwiękowej kilkoma ķcieŋkami moŋe nagle zmieniæ się na brak przybycia lub przybycie tylko częķci promieniowania statku. Džwięk z jednego žródģa moŋe wydawaæ się docieraæ z wielu kierunków jednoczeķnie. Charakterystyka odbiorników moŋe równieŋ powodowaæ mieszanie džwięku z róŋnych ģoŋysk, które wydają się pochodziæ z jednego miejsca. Wreszcie najbardziej interesujące cele okrętów podwodnych są bardzo ciche i skryte. Wspierane przez DARPA prace nad tym problemem rozpoczęģy się w 1973 roku w firmie Systems Control Technology, Inc. (SCI), firmy z Palo Alto z doķwiadczeniem w tej dziedzinie, która mogģaby pracowaæ nad klasyfikowanymi projektami wojskowymi. (SCI zostaģ póžniej przejęty przez British Petroleum). Feigenbaum i jego koledzy z SCI wkrótce zdali sobie sprawę, ŋe strategia "generowania i testowania" DENDRAL nie zadziaģa w przypadku problemu nadzoru oceanicznego, poniewaŋ nie istniaģ "generator legalnego ruchu" które mogģyby wygenerowaæ pozycje statków kandydujących i ich trasy, biorąc pod uwagę dane z nadzoru. Jednak zauwaŋając, ŋe ogólny problem analizy moŋna podzieliæ na poziomy podobne do tych uŋywanych w architekturze tablicy HEARSAY-II (okazaģo się, ŋe system dobrze radzi sobie z sygnaģami w haģasie), zespóģ pomyķlaģ, ŋe coķ podobnego zadziaģaģoby na ich problem. Zespóģ opracowaģ system o nazwie HASP (akronim Heuristic Adaptive Surveillance Program) oparty na modelu Blackboard. Dalsze prace, które przetworzą rzeczywiste dane oceaniczne, rozpoczęģy się w SCI od SIAP (akronim programu Surveillance Integration Automation Program) w 1976 r. Najwyŋszym poziomem Blackboard byģa "tablica sytuacji" {symboliczny model rozwijającej się sytuacji oceanicznej, zbudowany i utrzymywany przez program. Opisano hipotezę, ŋe wszystkie statki znajdują się tam z poziomem konwencyjnym związanym z kaŋdym z nich. Tuŋ pod pokģadem sytuacji znajdowaģ się poziom zawierający poszczególne hipotetyczne jednostki. Kaŋdy element statku miaģ informacje o swojej klasie, poģoŋeniu, aktualnej prędkoķci, kursie i miejscu docelowym, kaŋdy z waŋeniem konsystencji. Poniŋej poziomu statku znajdowaģ się poziom zawierający hipotetyczne žródģa džwięku: silniki, waģy, ķmigģa itp. wraz z ich poģoŋeniem i wagami zaleŋnoķci. Funkcje spektralne wyodrębnione z danych akustycznych byģy na najniŋszym poziomie. Poziomy byģy poģączone žródģami wiedzy (KS), które byģy w stanie wnioskowaæ, ŋe jeķli podejrzewa się obecnoķæ pewnych elementów na jednym poziomie, wówczas inne elementy moŋna by wywnioskowaæ, ŋe są obecne na innym poziomie (lub jeķli byģy juŋ obecne na tym poziomie, ich suma moŋe byæ dostosowana). Podobnie jak w HEARSAY-II, linki mogą obejmowaæ wiele poziomów i wyciągaæ wnioski w górę, w dóģ lub w obrębie poziomu. Wnioskowanie spowodowane przez jedną KS moŋe pozwoliæ drugiej KS na wyciągnięcie dodatkowego wniosku, i tak dalej, w kaskadzie, aŋ do wszystkich wykorzystanych odpowiednio informacji. W ten sposób moŋna przyswoiæ nowe informacje i sformuģowaæ oczekiwania dotyczące moŋliwych przyszģych wydarzeņ. Jeden typ KS skģadaģ się z reguģ IF - THEN. (Uŋyto równieŋ innych typów.) Na przykģad tutaj jest IF-THEN (przetģumaczona na angielski dla czytelnoķci), która dziaģaģa na poziomie žródģa: JEŊELI: žródģo zostaģo utracone z powodu zanikania w niedalekiej przeszģoķci, i podobne žródģo uruchomiono na innej częstotliwoķci, a lokalizacje dwóch žródeģ są stosunkowo blisko, NASTĘPNIE: są tym samym žródģem o sile 3.
HASP / SIAP posiadaģ kilka rodzajów žródeģ wiedzy, z których kaŋde byģo reprezentowane w sposób odpowiedni do zaangaŋowanego poziomu (poziomów). Niektóre KS opieraģy się na informacjach o ķrodowisku, takich jak wspólne szlaki ŋeglugowe, lokalizacja tablic i znane obszary manewrów. Inni mieli informacje o jednostkach pģywających i ich typach, ich prędkoķciach, częķciach skģadowych, charakterystyce akustycznej, bazach domowych i tak dalej. Oprócz KS zajmujących się wiedzą odpowiednią dla róŋnych poziomów, istniaģy "meta" KS, które miaģy informacje o tym, jak korzystaæ z innych KS. Dziaģania KS w ģączeniu informacji na róŋnych poziomach moŋna przedstawiæ jako sieæ, taką jak ta pokazana schematycznie na rysunku
Pod koniec sesji analitycznej, gdy wszyscy KS mieli okazję wziąæ udziaģ i akcja umarģa, powstaģa sieæ nazywana jest "aktualnie najlepszą hipotezą" (CBH) na temat obecnej sytuacji oceanicznej. Oto częķciowa próbka (przetģumaczona na angielski), w jaki sposób moŋna opisaæ CBH dla konkretnego uruchomienia HASP / SIAPmight. Klasa Vessel-1, znajdująca się w pobliŋu szerokoķci i szerokoķci geograficznej 37,3 i dģugoķci 123,1 w czasie dnia 2, 4 godzin i 55 minut, moŋe byæ klasą Cherry, Iris, Tulipan lub Poppy. Dwa odrębne žródģa akustyczne, wspierane przez odpowiednie zestawy harmoniczne, zostaģy zidentyfikowane dla Vessel-1. Žródģo-1 moŋe byæ spowodowane waģkiem lub ķmigģem klasy statku Cherry lub Poppy. Podobne moŋliwoķci žródģa istnieją dla Source-5. Te dwa žródģa zostaģy zasymilowane w Vessel-1 ze względu na moŋliwoķæ znanego stosunku mechanicznego, który istnieje między dwoma žródģami.
Korporacja MITER przeprowadziģa kilka eksperymentów w celu porównania wydajnoķci HASP / SIAP z wydajnoķcią dwóch ekspertów analityków sonarowych. W jednym z tych eksperymentów MITER stwierdziģ, ŋe "wykazano, ŋe HASP / SIAP dobrze radzi sobie z danymi pochodzącymi z oceanów ... W przypadku tej ograniczonej sceny oceanicznej program nie jest mylony przez dane obce i daje wyniki porównywalne do eksperta analityka". W innym eksperymencie stwierdzono, ŋe "HASP / SIAP lepiej rozumiaģ scenę oceaniczną niŋ drugi analityk, a takŋe pierwszy analityk. Program moŋe dziaģaæ skutecznie z więcej niŋ jednym zestawem akustycznym. SIAP klasyfikuje scenę oceaniczną trzy godziny, co wskazuje na prawdopodobieņstwo skutecznoķci SIAP w zmieniającej się sytuacji oceanicznej. " Trzeci eksperyment doprowadziģ do wniosków, ŋe "z wyjątkiem tego, ŋe program SIAP uzyskaģ znacznie więcej kontaktów niŋ ludzcy analitycy, opisy scen oceanicznych są bardzo podobne". Co więcej, "SIAP moŋe przeprowadzaæ klasyfikację statków w coraz trudniejszych scenach oceanicznych bez znacznego wzrostu wykorzystania zasobów komputerowych". Jak wspomniano wczeķniej, model tablicy zostaģ równieŋ zastosowany w kilku innych obszarach. Przykģady obejmują analizę krystalograficzną biaģka, rozumienie obrazu i rozumienie dialogu. Co ciekawe, architektura tablicy ma wpģyw nie tylko na technologię. Donald Norman, psycholog kognitywny, powiedziaģ, ŋe HEARSAY-II jest žródģem pomysģów dla psychologii teoretycznej i ŋe speģnia on swoje "intuicje dotyczące formy ogólnej struktury przetwarzania poznawczego". Ponadto, jak wspomnę w póžniejszym rozdziale, kilka modeli kory nowej obejmuje interakcyjne warstwy przypominające zarówno formę, jak i mechanizmy systemów tablicy.