I.Historia
Wprowadzimy tu dziedzinê sztucznej inteligencji (AI) poprzez przeglḟd jej gġównych tematów, historii, gġównych obszarów badawczych i aktualnych trendów. Celem jest dostarczenie czytelnikowi wystarczajḟcego kontekstu tġa, aby zrozumieæ i doceniæ kolejne czê¶ci.
Przeglḟd gġównych tematów
Historiê sztucznej inteligencji moṡna najlepiej zrozumieæ w kontek¶cie jej podstawowych zagadnieñ i kontrowersji. Poniṡej znajduje siê krótki wykaz takich róṡnic, zagadnieñ, tematów i kontrowersji AI. Byġoby dobrze o tym pamiêtaæ podczas lektura reszty materiaġów. Kaṡdy z tematów zostanie rozwiniêty i wyja¶niony w miarê rozwoju. Wiele z nich wynika z tego, ṡe do dnia dzisiejszego nie ma uzgodnionej definicji inteligencji w spoġeczno¶ci badaczy AI.
Inteligentne oprogramowanie a modelowanie kognitywne. Sztuczna inteligencja zawsze byġa czê¶ciḟ informatyki, dyscypliny inṡynierskiej majḟcej na celu tworzenie inteligentnych programów komputerowych - to znaczy inteligentnych produktów programowych zaspokajajḟcych ludzkie potrzeby. Zobaczymy kilka przykġadów takiego inteligentnego oprogramowania. AI ma równieṡ swojḟ stronê naukowḟ, która ma pomóc nam zrozumieæ ludzkḟ inteligencjê. To przedsiêwziêcie obejmuje budowanie systemów oprogramowania, które "my¶lḟ" w sposób podobny do czġowieka, a takṡe produkujḟ modele obliczeniowe aspektów ludzkiego poznania. Te modele obliczeniowe dostarczajḟ hipotezy dla kognitywistów.
Symboliczne AI w porównaniu do sieci neuronowych. Od samego poczḟtku sztuczna inteligencja zostaġa podzielona na dwa odrêbne strumienie badawcze: symbolicznḟ sztucznḟ inteligencjê i sieci neuronowe. Symboliczna AI przyjêġa poglḟd, ṡe inteligencjê moṡna osiḟgnḟæ poprzez manipulowanie symbolami w komputerze zgodnie z zasadami. Sieci neuronowe, czyli poġḟczenie, jak to nazywali naukowcy kognitywni, zamiast tego próbowali tworzyæ inteligentne systemy jako sieci wêzġów, z których kaṡdy zawiera uproszczony model neuronu. Zasadniczo róṡnica byġa miêdzy analogiḟ komputerowḟ a analogiḟ mózgu, miêdzy wdraṡaniem systemów sztucznej inteligencji jako tradycyjnych programów komputerowych i modelowaniem ich po systemach nerwowych.
Rozumowanie a percepcja. W tym przypadku rozróṡnienie miêdzy inteligencjḟ a rozumowaniem o wysokim poziomie podejmowania decyzji, np. w maszynie szachowej lub diagnostyce medycznej, a przetwarzaniem percepcyjnym na niṡszym poziomie, zwiḟzanym np.z wizjḟ maszynowḟ - rozumieniem obrazów poprzez identyfikacjê obiektów i ich zwiḟzków.
Rozumowanie a wiedza. Wcze¶ni badacze symbolicznej sztucznej inteligencji skupili siê na zrozumienie mechanizmów (algorytmów) uṡywanych do wnioskowania w procesie podejmowania decyzji. Zaġoṡono, ṡe zrozumienie, w jaki sposób takie rozumowanie moṡna osiḟgnḟæ w komputerze, byġoby wystarczajḟce do zbudowania uṡytecznego inteligentnego oprogramowania. Póỳniej naukowcy zdali sobie sprawê, ṡe aby zwiêkszyæ skalê problemów zwiḟzanych ze ¶wiatem rzeczywistym, musieli zbudowaæ znacznḟ ilo¶æ wiedzy w swoich systemach. System diagnozy medycznej musiaġ wiedzieæ wiele na temat medycyny, aby móc to zrobiæ wyciḟgnḟæ cenne wnioski.
Reprezentowania lub nie. Ta wiedza musiaġa byæ w jaki¶ sposób reprezentowana w systemie; to znaczy, system musiaġ jako¶ modelowaæ swój ¶wiat. Taka reprezentacja moṡe przybieraæ róṡne formy, w tym zasady. Póỳniej pojawiġy siê kontrowersje co do tego, jak wiele z takich modelowañ faktycznie trzeba wykonaæ. Niektórzy twierdzili, ṡe wiele moṡna osiḟgnḟæ bez rozlegġego modelowania wewnêtrznego.
Mózg w kadzi kontra uciele¶niona sztuczna inteligencja. Wczesne systemy AI wprowadzaġy ludzi wprowadzenie do systemów i dziaġanie na wyj¶ciu systemów. Podobnie jak "mózg w kadzi", systemy te nie wyczuwaġy ¶wiata ani nie dziaġaġy na nim. Póỳniej badacze AI stworzyli wcielone lub usytuowane systemy AI, które bezpo¶rednio wyczuwaġy ich ¶wiaty i dziaġaġy bezpo¶rednio na nich. Roboty w ¶wiecie rzeczywistym sḟ przykġadami wcielone systemy AI.
Wḟska sztuczna inteligencja w porównaniu z inteligencjḟ na poziomie czġowieka. W poczḟtkowej fazie badañ nad sztucznḟ inteligencjḟ wielu badaczy miaġo na celu stworzenie inteligencji na poziomie ludzkim w swoich maszynach, tak zwanya "silna sztuczna inteligencja". Póỳniej, gdy niezwykġa trudno¶æ takiego przedsiêwziêcia staġa siê bardziej oczywista, prawie wszyscy badacze AI zbudowali systemy, które dziaġaġy inteligentnie w pewnej stosunkowo wḟskiej dziedzinie, takiej jak szachy czy medycyna. Dopiero od niedawna nastḟpiġ powrót w kierunku systemów zdolnych do tego bardziej ogólna inteligencja na poziomie ludzkim, która moṡe byæ szeroko stosowana w róṡnych dziedzinach.
Niektóre kluczowe momenty w sztucznej inteligencji
McCulloch i Pitt
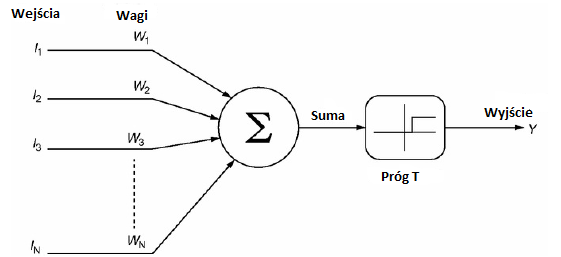
Sieæ neuronowa AI rozpoczêġa siê bardzo wczesnym opracowaniem Warrena McCullocha i Waltera Pittsa (1943). McCulloch, profesor na Uniwersytecie w Chicago i Pitts, student studiów licencjackich, opracowali znacznie uproszczony model funkcjonujḟcego neuronu, jednostki McCullocha-Pittsa. Pokazali, ṡe sieci takich jednostek mogḟ wykonywaæ dowolne operacje logiczne (i, lub, nie), a zatem wszelkie moṡliwe obliczenia. Kaṡda z tych jednostek porównywaġa waṡonḟ sumê swoich wej¶æ do warto¶ci progowej, aby wytworzyæ wyj¶cie binarne. W ten sposób narodziġa siê sieæ neuronowa AI, a takṡe neuronauka obliczeniowa.
Alan Turing
Alan Turing, matematyk z Cambridge z pierwszej poġowy XX wieku, moṡna go uznaæ za ojca komputerów (jego dziadkiem byġ Charles Babbage z poġowy XIX wieku) i dziadka AI. Podczas II wojny ¶wiatowej w latach 1939-1944 Turing kierowaġ opracowaniem brytyjskiego Bombe, wczesnej maszyny obliczeniowej, która byġa wielokrotnie uṡywana do dekodowania wiadomo¶ci zakodowanych za pomocḟ Enigmy. Na poczḟtku XX wieku Turing i inni interesowali siê kwestiami obliczalno¶ci. Chcieli sformalizowaæ odpowiedỳ na pytanie, które problemy moṡna rozwiḟzaæ obliczeniowo, a kilka osób wypracowaġo w rezultacie róṡne formalizmy. Turing zaoferowaġ maszynê Turinga (1936), Alonzo Church the Lambda Calculus (1936) a Emil Post the Production System (1943). Te trzy pozornie zupeġnie róṡne systemy formalne wkrótce okazaġy siê byæ logicznie równowaṡnymi w definiowaniu obliczalno¶ci, to znaczy okre¶lania tych problemów, które mogḟ byæ rozwiḟzane przez program dziaġajḟcy na komputerze. Maszyna Turinga okazaġa siê byæ najbardziej uṡytecznḟ
formalizacjḟ i jest to najczê¶ciej stosowana w teoretycznej informatyce. W 1950 r. Turing opublikowaġ pierwszy artykuġ sugerujḟcy moṡliwo¶æ sztucznej inteligencji (1950 r.). W pierwszej kolejno¶ci opisaġ to, co teraz nazywamy testem Turinga, i zaproponowaġ go jako wystarczajḟcy warunek istnienia sztucznej inteligencji. W te¶cie Turinga testerzy rozmawiajḟ w jêzyku naturalnym bez ograniczeñ przez terminale z ludzkim lub sztucznym jêzykowym programem sztucznej inteligencji, ukrytym przed wzrokiem. Je¶li testerzy nie sḟ w stanie w sposób niezawodny odróṡniæ czġowieka od programu, inteligencja jest przypisana do programu. W roku 1991 Hugh Loebner ustanowiġ Nagrodê Loebnera, która przyznawaġa 100 000 $ na pierwszy program AI, który zaliczyġ test Turinga.
Warsztaty w Dartmouth
Warsztaty w Dartmouth posġuṡyġy naukowcom w nowo powstajḟcym polu do wspóġpracy i wymiany pomysġów. Odbywajḟce siê w sierpniu 1956 roku warsztaty oznaczajḟ narodziny sztucznej inteligencji. AI wydaje siê byæ sama w¶ród dyscyplin, je¶li chodzi o urodziny. Jej rodzicami byli John McCarthy, Marvin Minsky, Herbert Simon i Allen Newell. Innymi znanymi uczestnikami byli Claude Shannon z teorii informacji, Oliver Selfridge, twórca teorii Pandemonium i Nathaniel Rochester, gġówny projektant bardzo wczesnego komputera IBM 701. John McCarthy, jest uznany za twórcê nazwy Sztuczna inteligencja. Byġ takṡe wynalazcḟ LISP-a, dominujḟcego jêzyka programowania AI przez póġ wieku. McCarthy nastêpnie doġḟczyġ do wydziaġu MIT, a nastêpnie przeniósġ siê do Stanford, gdzie zaġoṡyġ swoje AI Lab. Pozostaġ aktywnym badaczem AI aṡ do swojej ¶mierci w 2011 roku. Marvin Minsky pomógġ zaġoṡyæ MIT AI Lab, gdzie pozostaġ aktywnym i wpġywowym badaczem sztucznej inteligencji. Herbert Simon i Allen Newell wprowadzili jedyny dziaġajḟcy program AI, teoretykê logiki, do Warsztatu Dartmouth. Operacja ta odbywaġa siê za pomocḟ analizy ¶rodków, algorytmu planowania AI. Na kaṡdym etapie próbowaġ wybraæ operacjê (¶rodki), która przesunêġa system bliṡej celu (koñca). Simon i Newell zaġoṡyli laboratorium badawcze AI na Uniwersytecie Carnegie Mellon. Newell zmarġ w 1992 r., A Simon w 2001 r
Warcaby Samuela
Kaṡdy informatyk komputerowy wie, ṡe komputer wykonuje tylko algorytm zaprogramowany do dziaġania. Dlatego moṡna by pomy¶leæ, ṡe moṡe robiæ tylko to, co poleciġ jej programista. Nie wie nic o tym, czego jej programista nie zrobiġ, ani nic, czego jego programista nie mógġby. Ten pozornie logiczny wniosek jest po prostu bġêdny, poniewaṡ ignoruje moṡliwo¶æ zaprogramowania komputera do nauki. Takie uczenie maszynowe, które póỳniej staġo siê gġównym poddziedzinḟ sztucznej inteligencji, zaczêġo siê od programu wacabów Arthura Samuela (1959). Chociaṡ Samuel poczḟtkowo mógġ pokonaæ swój program, po kilku miesiḟcach nauki mówi siê, ṡe nigdy nie wygraġ z nim kolejnej gry. Narodziġo siê uczenie maszynowe
Rozprawa Minsky′ego
W 1951 roku Marvin Minsky i Dean Edmonds zbudowali SNARC, pierwszḟ sztucznḟ sieæ neuronowḟ, która symulowaġa szczura z labiryntem. Praca ta byġa podstawḟ rozprawy Minsky′ego z Princeton (1954). Tak wiêc jeden z zaġoṡycieli i gġównych graczy w symbolicznej sztucznej inteligencji byġ poczḟtkowo bardziej zainteresowany sieciami neuronowymi i przygotowaġ scenê do ich implementacji obliczeniowej
Perceptrony i sieæ neuronowa
Perceptron Franka Rosenblatta (1958) naleṡaġ do najwcze¶niejszych sztucznych sieci neuronowych. Dwuwarstwowa sieæ neuronowa najlepiej postrzegana jako binarny system klasyfikacyjny, perceptron odwzorowuje swój wektor wej¶ciowy na sumê waṡonḟ podlegajḟcḟ progowi, dajḟc odpowiedỳ tak lub nie. Atrakcyjno¶æ perceptronu wynikaġa z nadzorowanego algorytmu uczenia, za pomocḟ którego moṡna nauczyæ perceptron poprawnie klasyfikowaæ. W ten sposób sieci neuronowe przyczyniġy siê do uczenia maszynowego. Badania nad perceptronami zakoñczyġy siê niesġawnym zakoñczeniem publikacji ksiḟṡki Minsky i Papert Perceptrons (1969), w której pokazali, ṡe perceptron nie jest w stanie nauczyæ siê klasyfikowaæ jako prawdziwych lub faġszywych danych wej¶ciowych do tak prostych systemów, jak wyġḟczne "lub" (XOR - albo A albo B, ale nie oba) .Minsky i Papert równieṡ przypuszczali, ṡe nawet wielowarstwowe perceptrony majḟ podobne ograniczenia. Choæ to przypuszczenie okazaġo siê w wiêkszo¶ci faġszywe, agencje rzḟdowe finansujḟce badania nad sztucznḟ inteligencjḟ potraktowaġy to powaṡnie. Finansowanie badañ sieci neuronowej wyschġo, co doprowadziġo do powstania sieci neuronowej, która nie zmniejszyġa siê do czasu opublikowania równolegġego przetwarzania w poġowie lat 80.
Geneza gġównych obszarów badawczych
Na poczḟtku swojej historii nacisk na badania nad sztucznḟ inteligencjḟ polegaġ w duṡej mierze na tworzeniu systemów, które mogġyby prowadziæ do wysokich, stosunkowo abstrakcyjnych, ale sztucznych problemów - problemów, które wymagaġyby inteligencji, gdyby byġy podejmowane przez czġowieka. Jednym z pierwszych takich systemów byġ ogólny problem Simona i Newella, który podobnie jak jego poprzednik, teoretyk logiki, uṡyġ analizy ¶rodków do rozwiḟzania róṡnych zagadek. Jeszcze innym wczesnym systemem rozumowania byġo twierdzenie Gelerntera o geometrii. Innym waṡnym poddziedztwem sztucznej inteligencji jest przetwarzanie jêzyka naturalnego, zwiḟzane z systemami, które rozumiejḟ jêzyk. Jednym z pierwszych takich byġ SHRDLU (Winograd 1972), nazwany na podstawie kolejno¶ci kluczy na maszynie linotypowej. SHRDLU moṡe zrozumieæ i wykonaæ polecenia w jêzyku angielskim, nakazujḟc mu manipulowanie drewnianymi klockami, stoṡkami, kulami itp. Za pomocḟ ramienia robota w ¶wiecie znanym jako "¶wiat bloków". SHRDLU byġ wystarczajḟco wyrafinowany, aby móc korzystaæ z zapamiêtanych kontekstów rozmowy w celu ujednoznacznienia odniesieñ. Nie trwaġo to jednak dġugo, zanim naukowcy z AI zdali sobie sprawê, ṡe rozumowanie nie byġo wszystkim w inteligencji. Próbujḟc skalowaæ swoje systemy, aby poradziæ sobie z problemami ¶wiata rzeczywistego, popadli prosto w ¶cianê braku wiedzy. Prawdziwe problemy wymagaġy, aby solver co¶ wiedziaġ. Tak narodziġy siê systemy oparte na wiedzy (czêsto nazywane systemami eksperckimi). Nazwa pochodzi od procesu inṡynierii wiedzy: inṡynierowie wiedzy pracowicie wyciḟgajḟ informacje od ludzkich ekspertów, a nastêpnie kodujḟ tê wiedzê w swoich systemach ekspertowych. Prowadzony przez chemika Joshua Lederberga i badaczy AI Edwarda Feigenbauma i Bruce'a Buchanana, pierwszy taki system ekspercki, zwany DENDRAL, byġ ekspertem w dziedzinie chemii organicznej. Projekt DENDRAL pomógġ zidentyfikowaæ strukturê molekularnḟ czḟsteczek organicznych, analizujḟc dane ze spektrometru mas i wykorzystujḟc jego znajomo¶æ chemii . Projektanci DENDRAL dodali wiedzê do mechanizmu leṡḟcego u podstaw mechanizmu wnioskowania, aby stworzyæ system ekspercki zdolny poradziæ sobie ze zġoṡonym, realnym problemem. Drugi taki system ekspercki, zwany Mycin, pomógġ lekarzom zdiagnozowaæ i leczyæ zakaỳne choroby krwi i zapalenie opon mózgowych. Podobnie jak DENDRAL, Mycin opieraġ siê zarówno na rêcznej wiedzy eksperckiej, jak i opartym na reguġach mechanizmie wnioskowania. System odniósġ sukces, poniewaṡ mógġ diagnozowaæ trudne przypadki, jak równieṡ najbardziej do¶wiadczonych lekarzy, ale nie powiodġo siê, poniewaṡ nigdy nie byġo obsadzone. Wprowadzanie informacji do Mycina wymagaġo okoġo dwudziestu minut. Lekarz spêdziġby co najwyṡej piêæ minut na postawienie diagnozy.
Badanie podczas zimy dla sieci neuronowej
Jak juṡ zauwaṡono, Perceptrons Minsky'ego i Paperta (1969) bġêdnie przekonali rzḟdowe agencje finansujḟce, ṡe podej¶cie sieci neuronowej byġo maġo obiecujḟce, prowadzḟc do zimy dla sieci neuronowej, która trwaġa prawie dwadzie¶cia lat. Pomimo tego zatrwaṡajḟcego braku funduszy nadal prowadzono znaczḟce badania na caġym ¶wiecie. Nieustraszeni badacze, którzy w jaki¶ sposób zdoġali utrzymaæ te waṡne badania, doġḟczyli Shun-ichi Amari i Satoru Fukushima w Japonii, Stephen Grossberg i John Hopfield w Stanach Zjednoczonych, Teuvo Kohonen w Finlandii i Christoph von der Malsburg w Niemczech. Znaczna czê¶æ tej pracy dotyczyġo samoorganizacji sieci neuronowych i uczenia siê w nich. Wiele motywowaġo równieṡ pochodzenie tych badaczy z neuronauki.
Powstanie zwiḟzku
Koniec zimy dla sieci neuronowej zostaġ przerwany przez opublikowanie dwóch tomów Równolegġe Przetwarzanie Rozproszone. Byġy to dwa masowo zmontowane tomy z rozdziaġami autorstwa czġonków grupy badawczej PDP, a nastêpnie na Uniwersytecie Kalifornijskim w San Diego. Tomy te daġy poczḟtek stosowaniu sztucznych neuronowych sieci, które wkrótce zostanḟ nazwane poġḟczeniami, w kognitywistyce. Czy poġḟczenie byġo do wykonania w wyja¶nieniu umysġu szybko staġo siê gorḟcym tematem debaty w¶ród filozofów, psychologów i badaczy AI. Debata wygasġa bez deklarowanego zwyciêzcy, ale ze sztucznymi sieciami neuronowymi staje siê ugruntowanym graczem w obecnej SI. Oprócz ich sukcesu (pod postaciḟ poġḟczenia) do modelowania kognitywnego sztuczne sieci neuronowe znalazġy wiele praktycznych zastosowañ. Wiêkszo¶æ z nich obejmuje rozpoznawanie wzorców. Obejmujḟ one inwestowanie w fundusze inwestycyjne, wykrywanie oszustw, punktacjê kredytowḟ, wycenê nieruchomo¶ci i wiele innych. Ta szeroka moṡliwo¶æ zastosowania byġa przede wszystkim wynikiem szeroko stosowanego algorytmu szkoleniowego o nazwie backpropagation. Choæ póỳniej prze¶ledzono wiele wcze¶niejszych prac, backpropagacja zostaġa ponownie odkryta przez grupê badawczḟ PDP i stanowiġa gġówne narzêdzie do badañ zgġoszonych w dwóch tomach PDP
Zima A.I.
Z powodu tego, co okazaġo siê przesadḟ potencjaġu i czasu sztucznej inteligencji, symboliczna SI doznaġa wġasnej zimy. Dla przykġadu, w 1965 roku Herbert Simon przewidziaġ, ṡe "maszyny bêdḟ zdolne, w ciḟgu dwudziestu lat, wykonywaæ jakḟkolwiek pracê, którḟ czġowiek moṡe wykonaæ." Ta i inne tego typu przewidywania nie speġniġy siê. W rezultacie do poġowy lat osiemdziesiḟtych fundusze rzḟdowe na AI zaczêġy wysychaæ, a inwestycje komercyjne prawie nie istniaġy. Sztuczna inteligencja staġa siê sġowem tabu w branṡy komputerowej przez dekadê lub dġuṡej, pomimo ogromnego sukcesu systemów eksperckich. Wiosna AI nie dotarġa aṡ do nadej¶cia nastêpnej aplikacji "killer", gier wideo.
Przetwarzanie miêkkie
Termin "soft computing" odnosi siê do pstrokatego zestawu technik obliczeniowych zaprojektowanych do radzenia sobie z niedokġadno¶ciḟ, niepewno¶ciḟ, aproksymacjḟ, czê¶ciowymi prawdami itd. Metody te majḟ raczej charakter indukcyjny niṡ dedukcyjny. Oprócz sieci neuronowych, o których juṡ mówili¶my, soft computing obejmuje obliczenia ewolucyjne, logikê rozmytḟ i sieci bayesowskie. Rozpatrzymy kaṡdy z nich po kolei.
Obliczenia ewolucyjne rozpoczêġy siê od komputerowego odwzorowania naturalnej selekcjizwana algorytmem genetycznym. Algorytm wyszukiwania populacji, proces ten zazwyczaj rozpoczyna siê od populacji sztucznych genotypów reprezentujḟcych moṡliwe rozwiḟzania danego problemu. Czġonkowie tej populacji sḟ poddawani mutacjom (zmiany losowe) i krzyṡowaniu (ang. crossover, mieszanie dwóch genotypów). Powstaġe nowe genotypy sḟ wprowadzane do funkcji fitness, która mierzy jako¶æ genotypu. Najbardziej udane z tych genotypów stanowiḟ nastêpnḟ populacjê, a proces powtarza siê. Je¶li sḟ dobrze zaprojektowane, genotypy w populacji z biegiem czasu stajḟ siê podobne, zbliṡajḟc siê do poṡḟdanego rozwiḟzania i uzupeġniajḟc algorytm genetyczny. Ponadto obliczenia ewolucyjne obejmujḟ równieṡ systemy klasyfikacyjne, które ġḟczḟ koncepcje oparte na reguġach i wzmocnieniu z algorytmami genetycznymi. Obliczenia ewolucyjne obejmujḟ równieṡ programowanie genetyczne, metodê wykorzystywania algorytmów genetycznych do wyszukiwania programów komputerowych, zazwyczaj w LISP-ie, które rozwiḟṡḟ dany problem. Opierajḟc siê na teorii zbiorów rozmytych Zadeha, w której przypisywane sḟ stopnie przydziaġu od 0 do 1 (1965), logika rozmyta staġa siê ostojḟ miêkkiego przetwarzania. Uṡywajḟc reguġ if-then ze zmiennymi rozmytymi, logika rozmyta zostaġa zastosowana w wielu aplikacjach kontrolnych, w tym w sprzêcie gospodarstwa domowego, windach, oknach samochodowych, kamerach i grach wideo. (Referencje nie sḟ podawane, poniewaṡ te komercyjne aplikacje sḟ prawie zawsze zastrzeṡone).
Sieæ bayesowska, z wêzġami reprezentujḟcymi sytuacje, uṡywa twierdzenia Bayesa o prawdopodobieñstwie warunkowym do powiḟzania prawdopodobieñstwa z kaṡdym z jego ġḟczy. Sieci bayesowskie byġy szeroko stosowane w modelowaniu kognitywnym, sieciach regulacji genów, systemach wspomagania decyzji i tak dalej. Stanowiḟ integralnḟ czê¶æ soft computingu.
Ostatnie gġówne osiḟgniêcia
Zakoñczymy naszḟ krótkḟ historiê sztucznej inteligencji, przedstawiajḟc niektóre z jej stosunkowo niedawnych gġównych osiḟgniêæ. Naleṡḟ do nich systemy eksperckie, szachi¶ci, dowcipy twierdzeñ, przetwarzanie jêzyka naturalnego i nowa aplikacja zabójcy. Kaṡda z nich zostanie opisana po kolei
Systemy eksperckie oparte na wiedzy
Choæ systemy eksperckie oparte na wiedzy pojawiġy siê stosunkowo wcze¶nie w historii sztucznej inteligencji, staġy siê waṡnḟ, ekonomicznie istotnḟ aplikacjḟ AI nieco póỳniej. Byæ moṡe najwcze¶niejszym takim komercyjnie skutecznym systemem eksperckim byġ R1, póỳniej przemianowany na XCON (McDermott 1980). XCON zaoszczêdziġ miliony DEC (Digitial Equipment Corporation), efektywnie konfigurujḟc swoje komputery VAX przed dostawḟ, a nie po tym, jak inṡynierowie DEC rozwiḟzali problemy po ich dostarczeniu. Inne podobne aplikacje, w tym systemy diagnostyczne i konserwacyjne dla kuchenek Campbell Soups i lokomotyw GE. Reklama Ford Motor Company dotyczḟca czê¶ci maszyn produkcyjnych przewidywaġa, ṡe taki system ekspercki w zakresie diagnostyki i konserwacji bêdzie czê¶ciḟ kaṡdej propozycji. Jedna ksiḟṡka wyszczególniġa 2500 systemów eksperckich. Systemy eksperckie stanowiġa pierwszḟ aplikacjê zabójcy AI. To nie miaġo byæ ostatnie.
Deep Blue pokonujḟca Kasparova
Wczesne badania nad sztucznḟ inteligencjḟ zwykle pracowaġy nad problemami, które wymagaġyby inteligencji, gdyby byġy podejmowane przez czġowieka. Jednym z takich problemów byġo granie w szachy. Gracze w szachy AI pojawili siê niedġugo po warcabach Samuela. Jednym z najbardziej udanych systemów szachowych byġ Deep Blue firmy IBM, który w 1997 roku pokonaġ mistrza ¶wiata, Gary&primle;ego Kasparowa, w sze¶ciu meczach, spóỳniajḟc siê z wcze¶niejszymi przewidywaniami Herberta Simona. Choæ dziaġa na specjalnie zbudowanym komputerze i ma duṡo wiedzy o szachach, Deep Blue zaleṡaġo ostatecznie od tradycyjnych algorytmów gier AI. Mecz z Kasparowem byġ triumfem AI.
Rozwiḟzanie przypuszczenia Robbinsa
Kolejny, jeszcze wiêkszy, triumf AI miaġ wkrótce nadej¶æ. W artykule z 1933 roku E. V. Huntington przedstawiġ nowy zestaw trzech aksjomatów charakteryzujḟcych algebrê Boole′a, formalny system matematyczny waṡny dla teoretycznej informatyki. Trzeci z tych aksjomatów byġ tak zġoṡony, ṡe zasadniczo nie nadawaġ siê do uṡytku. Dlatego motywowany Herbert Robbins wkrótce zastḟpiġ ten trzeci aksjomat prostszym i domy¶laġ siê, ṡe ten nowy zestaw trzech aksjomatów charakteryzuje równieṡ algebrê Boole′a. Ten domysġ Robbinsa pozostaġ jednym z wielu takich w literaturze matematycznej, dopóki znaczḟcy logik i matematyk Alfred Tarski nie zwróciġ na to uwagi, zmieniajḟc go w sġynny nierozwiḟzany problem. Po ponad stuleciu sprzeciwu wobec wysiġków ludzkich matematyków, domysġy Robbinsa ostatecznie poddaġy siê twierdzeniu ogólnego przeznaczenia o automatycznym twierdzeniu AI o nazwie EQP (EQuational Prover ). Tam, gdzie ludzie zawiedli, EQP udowodniġo, ṡe hipoteza Robbinsa jest prawdziwa
Watson pokonuje ludzkich czempionów w grze Jeopardy
Jeopardy jest popularnym i dġugo dziaġajḟcym teleturniejem telewizyjnym, w którym uczestnicy otrzymujḟ wskazówki w postaci odpowiedzi na rozlegġe pytania dotyczḟce ciekawostek i muszḟ odpowiedzieæ na odpowiednie pytania tak szybko, jak to moṡliwe. Dwudziesty szósty sezon rozpoczḟġ siê w 2011 roku. W tym samym roku wyemitowano trzy wyjḟtkowe odcinki Jeopardy, w których dwaj najbardziej utytuġowani mistrzowie i rekordzi¶ci zostali pokonani przeciwko sobie i przeciwko systemowi AI o nazwie Watson. (na cze¶æ zaġoṡyciela IBM). Korzystajḟc z algorytmów przetwarzania jêzyka naturalnego AI do zapytania okoġo 200 milionów stron tre¶ci i odpowiadajḟc w konwersacyjnym jêzyku angielskim, Watson konsekwentnie osiḟgaġ lepsze wyniki niṡ jego dwaj przeciwnic
Gry - zabójcy aplikacji
Zatrudniajḟc wiêcej praktyków sztucznej inteligencji niṡ jakakolwiek inna, przemysġ gier komputerowych i wideo cieszy siê peġnḟ sukcesów sġawḟ. Wedġug jednego wiarygodnego ỳródġa, Entertainment Software Association, caġkowite wydatki USA na przemysġ gier w 2012 r. przekroczyġa 20 miliardów dolarów, a 188 milionów sprzedanych gier2. Rola AI w tym zdumiewajḟcym sukcesie jest krytyczna; jego uṡycie jest niezbêdne do wytworzenia potrzebnego inteligentnego zachowania ze strony wirtualnych postaci, które zapeġniajḟ gry. Wikipedia posiada wpis zatytuġowany "sztuczna inteligencja gry", który zawiera historiê coraz bardziej zaawansowanych technik sztucznej inteligencji wykorzystywanych w takich grach, a takṡe odniesienia do kilkunastu ksiḟṡek na temat stosowania sztucznej inteligencji w grach. W tym pi¶mie wydaje siê, ṡe istnieje nieograniczone zapotrzebowanie na pracowników sztucznej inteligencji w branṡy gier. Ta bardzo popularna komercyjna aplikacja jest kolejnym triumfem dla sztucznej inteligencj
Gġówne obszary badawcze A.I.
Istnieje prawie tuzin róṡnych poddziedzin badañ nad sztucznḟ inteligencjḟ, z których kaṡda ma wġasne specjalistyczne czasopisma, konferencje, warsztaty i tak dalej. Ta sekcja zawiera zwiêzġe sprawozdanie z zainteresowañ badawczych w kaṡdym z tych subpól.
Reprezentacja wiedzy
Kaṡdy system sztucznej inteligencji, czy to klasyczny system sztucznej inteligencji z ludỳmi dostarczajḟcy dane wej¶ciowe i wykorzystujḟcy dane wyj¶ciowe, czy teṡ autonomiczny agent, musi w jaki¶ sposób przetġumaczyæ wej¶cie (bodỳce) na informacjê lub wiedzê, które zostanḟ uṡyte do wyboru wyj¶cia (dziaġania). Te informacje lub wiedza muszḟ byæ w jaki¶ sposób reprezentowane w systemie, aby moṡna je byġo przetworzyæ w celu ustalenia wyj¶cie lub dziaġanie. Problemy wywoġane przez takie reprezentacje stanowiḟ przedmiot badañ w subdyscyplinie sztucznej inteligencji, zwanej powszechnie reprezentacjḟ wiedzy. W systemach sztucznej inteligencji napotykamy wiedzê reprezentowanḟ za pomocḟ formalizmów logicznych, takich jak logika zdaniowa i rachunek predykatów pierwszego rzêdu. Moṡna równieṡ znaleỳæ reprezentacje sieci, takie jak sieci semantyczne, których wêzġy i ġḟcza majḟ etykiety dostarczajḟce tre¶æ semantycznḟ. Podstawowḟ ideḟ jest to, ṡe pojêcie reprezentowane przez wêzeġ zyskuje znaczenie poprzez swoje relacje (ġḟcza) z innymi pojêciami. Stosowane sḟ równieṡ bardziej zġoṡone struktury danych, takie jak reguġy produkcji, ramki i zbiory rozmyte. Kaṡda z tych struktur danych ma wġasny typ rozumowania lub aparatu decyzyjnego, jego mechanizm wnioskowania. Wydaje siê, ṡe kwestia, czy reprezentowaæ, czy nie, zostaġa domy¶lnie rozstrzygniêta, poniewaṡ argumenty ustaġy. Wydaje siê, ṡe Rodney Brooks z MIT AI Lab zdaġ sobie sprawê, ṡe wiêcej znosili ten dzieñ, w którym reprezentacje sḟ nadal szeroko stosowane. Wydaje siê, ṡe reprezentacje majḟ kluczowe znaczenie dla procesu decydowania, jakie dziaġania podjḟæ, a tym bardziej dla procesu realizacji dziaġania. To wydaje siê byæ istotḟ problemu.
Wyszukiwanie heurystyczne
Problemy z wyszukiwaniem byġy badane w informatyce prawie od samego poczḟtku. Na przykġad w problemie komiwojaṡera zadanie polega na znalezieniu najskuteczniejszej trasy, jakḟ powinien przej¶æ sprzedawca, aby odwiedziæ kaṡde z N miast dokġadnie jeden raz. Wszystkie znane algorytmy znalezienia optymalnych rozwiḟzañ takiego problemu wzrastajḟ wykġadniczo z N, co oznacza, ṡe w przypadku duṡej liczby miast nie moṡna znaleỳæ optymalnego rozwiḟzania. Jednak wystarczajḟco dobre rozwiḟzania moṡna znaleỳæ za pomocḟ heurystycznych algorytmów wyszukiwania z AI. Takie algorytmy wykorzystujḟ znajomo¶æ jêzyka konkretna domena w postaci heurystyki, reguġy, które nie gwarantujḟ znalezienia najlepszego rozwiḟzania, ale które najczê¶ciej znajdujḟ wystarczajḟco dobre rozwiḟzanie. Takie heurystyczne algorytmy wyszukiwania sḟ szeroko stosowane do planowania, eksploracji danych (odnajdywania wzorców w danych), problemów z ograniczeniem wiêzów, gier, wyszukiwania w Internecie i wielu innych podobnych aplikacji.
Planowanie
Planista AI to system, który automatycznie okre¶la kolejno¶æ dziaġañ prowadzḟcych od poczḟtkowego stanu rzeczywistego do poṡḟdanego stanu celu. Plani¶ci mogḟ byæ wykorzystywani na przykġad do planowania pracy w hali produkcyjnej, aby znaleỳæ trasy do pakietu dostarczenie lub przypisaæ uṡycie teleskopu Hubble'a. Badania nad takimi programami planowania to gġówne poddziedzinie sztucznej inteligencji. Aplikacje polowe sḟ zaangaṡowane w eksploracjê kosmosu, logistykê wojskowḟ oraz operacje i sterowanie zakġad
Systemy eksperckie
Oparte na wiedzy systemy eksperckie omówiono w poprzednich sekcjach. Jako poddziedzina sztucznej inteligencji, badacze systemów eksperckich zajmujḟ siê rozumowaniem (ulepszaniem mechanizmów wnioskowania dla ich systemów), reprezentacjḟ wiedzy (jak przedstawiaæ potrzebne fakty w swoich systemach) i inṡynieriḟ wiedzy (jak pozyskiwaæ wiedzê od ekspertów, która czasami jest niejawna) . Jak widzieli¶my, ich aplikacje sḟ legionem
Widzenie maszynowe
Widzenie maszynowe lub komputera jest subpolem sztucznej inteligencji, po¶wiêconym automatycznemu zrozumieniu obrazów wizualnych, zwykle fotografii cyfrowych. W¶ród wielu jego zastosowañ sḟ inspekcja produktów, nadzór ruchu i wywiad wojskowy. Przy obrazach mnoṡḟcych siê co kilka sekund od satelitów, wysokolatajḟcych samolotów szpiegowskich i autonomicznych dronów, nie ma wystarczajḟcej liczby ludzi, aby interpretowaæ i indeksowaæ obiekty na obrazach, aby moṡna je byġo zrozumieæ i zlokalizowaæ. Badania nad automatyzacjḟ tego procesu dopiero siê rozpoczynajḟ. Badania nad sztucznḟ inteligencjḟ w zakresie widzenia maszynowego równieṡ zaczynajḟ byæ stosowane w kamerach bezpieczeñstwa, aby zrozumieæ sceny i ostrzegaæ ludzi w razie potrzeby.
Uczenie maszynowe
Poddziedzina sztucznej inteligencji ,uczenie maszynowe zajmujḟ siê algorytmy, które umoṡliwiajḟ uczenie siê systemów A. Chociaṡ uczenie maszynowe jest tak stare, jak sama sztuczna inteligencja, jego znaczenie wzrosġo, poniewaṡ coraz wiêcej systemów sztucznej inteligencji, szczególnie autonomiczne, dziaġa w coraz bardziej zġoṡonych i dynamicznie zmieniajḟcych siê domenach. Znaczna czê¶æ uczenia maszynowego to nadzorowane uczenie siê, w którym system jest instruowany za pomocḟ danych treningowych. Systemy nieobsġugiwane lub samoorganizujḟce siê, jak wspomniano powyṡej, stajḟ siê powszechne. Uczenie siê wzmacniania, osiḟgane dziêki sztucznym nagrodom, jest typowe dla uczenia siê nowych zadañ. Istnieje nawet nowe poddziedzinie uczenia maszynowego po¶wiêcone rozwojowej robotyki, robotom, które przechodzḟ szybkḟ fazê wczesnego uczenia siê, podobnie jak ludzkie dzieci.
Przetwarzanie jêzyka naturalnego
Poddziedzina sztucznej inteligencji jêzyka naturalnego obejmuje zarówno generowanie, jak i rozumienie jêzyka naturalnego, zazwyczaj tekstu. Jego historia siêga wcze¶niej omówionego Testu Turinga. Dzi¶ jest kwitnḟcḟ dziedzinḟ badañ nad tġumaczeniem maszynowym, udzielaniem odpowiedzi na pytania, automatycznym podsumowaniem, rozpoznawaniem mowy i innymi obszarami. Tġumaczenia maszynowe, choæ zwykle tylko okoġo 90 procent dokġadne, mogḟ czterokrotnie zwiêkszyæ produktywno¶æ tġumaczy. Opracowywane sḟ systemy rozpoznawania tekstu do automatycznego wprowadzania historii medycznych. Rozpoznawanie gġosu umoṡliwia wypowiadanie poleceñ gġosowych na komputerze, a nawet dyktowanie.
Agenci oprogramowania
Czynnik autonomiczny definiuje siê jako system umiejscowiony w ¶rodowisku, które wyczuwa otoczenie i dziaġa zgodnie z wġasnym planem, w taki sposób, ṡe jego dziaġania mogḟ wpġywaæ na to, co póỳniej wyczuwa. Sztuczne ¶rodki autonomiczne obejmujḟ oprogramowanie i niektóre roboty. Autonomicznie agenci oprogramowania wystêpujḟ w kilku odmianach. Niektórzy lubiḟ autorskḟ IDA "na ṡywo" w ¶rodowisku, w tym w bazach danych i Internecie, i autonomicznie wykonujḟ okre¶lone zadanie, takie jak przydzielanie marynarzom nowych miejsc pracy po zakoñczeniu obowiḟzków sġuṡbowych. Inne, czasami nazywane awatarami, majḟ wirtualne twarze lub ciaġa wy¶wietlane na monitorach, które umoṡliwiajḟ im bardziej naturalnḟ interakcjê z ludỳmi, czêsto dostarczajḟc informacji. Jeszcze inni, zwani konwersacyjnymi wirtualnymi agentami, symulujḟ ludzi i wchodzḟ w interakcjê z nimi na czatach, niektórzy tak realistycznie, ṡe sḟ myleni z ludỳmi. Wreszcie istniejḟ wirtualni agenci jako postacie w grach komputerowych i wideo
Inteligentne systemy nauczania
Inteligentne systemy nauczania to systemy sztucznej inteligencji, zazwyczaj agenci oprogramowania, których zadaniem jest interaktywne nauczanie uczniów, tak samo jak ludzki nauczyciel. Wyniki wczesnych starañ w tym kierunku byġy rozczarowujḟce. Póỳniejsze systemy odniosġy wiêkszy sukces w dziedzinach takich jak matematyka, które nadajḟ siê do krótkich odpowiedzi od ucznia. Ostatnio opracowano inteligentne systemy nauczania, takie jak AutoTutor, które mogḟ odpowiednio radziæ sobie z peġnymi akapitami napisanymi przez ucznia. Dzi¶ gġówne wḟskie gardġo w tym badania doprowadzajḟ wiedzê dziedzinowḟ do systemów nauczania. W rezultacie rozkwitġy badania w róṡnych narzêdziach do authoringu.
Robotyka
We wczesnych latach robotyka byġa poddziedzinḟ inṡynierii mechanicznej, a wiêkszo¶æ badañ po¶wiêcono rozwojowi robotów zdolnych do wykonywania okre¶lonych czynno¶ci, takich jak chwytanie, chodzenie i tak dalej. Ich systemy kontroli byġy czysto algorytmiczne, bez komponentów sztucznej inteligencji. Gdy roboty staġy siê bardziej zdolne, pojawiġa siê potrzeba stworzenia bardziej inteligentnych struktur kontrolnych i narodziġy siê badania z zakresu robotyki kognitywnej oparte na strukturach kontrolnych opartych na sztucznej inteligencji. Dzisiaj robotyka i sztuczna inteligencja badania majḟ istotne i waṡne pokrywanie siê
Najnowsze trendy i kierunki
Kiedy zaczêġa siê druga dekada XXI wieku, sztuczna inteligencja nie tylko wynurzyġa siê ze swojej zimy w sztucznḟ inteligencjê na wiosnê AI, ale ta wiosna przeksztaġciġa siê w peġnoprawne lato AI z bujnym wzrostem owoców. Najnowsze trendy obejmujḟ najnowsze technologie komputerowe, sztucznḟ inteligencjê do eksploracji danych, sztucznḟ inteligencjê opartḟ na agentach, obliczenia kognitywne (w tym robotykê rozwojowḟ i sztucznḟ inteligencjê ogólnḟ) oraz zastosowanie sztucznej inteligencji w kognitywistyce. Spójrzmy na kaṡdy z nich po kolei.
Przetwarzanie miêkkie
Poza komponentami opisanymi wcze¶niej (mianowicie sieci neuronowe, obliczenia ewolucyjne i logika rozmyta), soft computing rozszerza siê na systemy hybrydowe ġḟczḟce symbolicznḟ i ġḟczḟcḟ sztucznḟ inteligencjê. Pierwszymi przykġadami takich systemów hybrydowych sḟ ACT-R, CLARION czy LIDA. Wiêkszo¶æ takich systemów hybrydowych, w tym trzy przykġady, miaġa byæ modelami poznawczymi. Niektóre z nich leṡḟ u podstaw architektury obliczeniowej praktycznych programów sztucznej inteligencji. Technologia "soft computing" obejmuje teraz takṡe sztuczne ukġady odporno¶ciowe, które majḟ znaczḟcy wkġad w bezpieczeñstwo komputerów, a takṡe aplikacje optymalizacja i prognozowanie struktury biaġka.
AI dla eksploracji danych
Oprócz statystyk, sztuczna inteligencja zapewnia niezbêdne narzêdzia do eksploracji danych, proces wyszukiwania duṡych baz danych na uṡyteczne wzorce danych. Wiele z tych narzêdzi pochodzi z badañ nad uczeniem maszynowym. Poniewaṡ bazy danych szybko siê zwiêkszajḟ, systemy wyszukiwania danych stajḟ siê coraz bardziej uṡyteczne, co prowadzi do trendu w poszukiwaniu narzêdzi AI do eksploracji danych.
AI oparte na agentach
Umiejscowiony lub uciele¶niony ruch poznawczy, w postaci sztucznej inteligencji opartej na agentach, wyraỳnie przeszedġ ten dzieñ w badaniach nad sztucznḟ inteligencjḟ. Obecnie wiêkszo¶æ nowych systemów sztucznej inteligencji jest pewnego rodzaju autonomicznymi agentami. Dominujḟcym podrêcznikiem AI, uṡywanym na ponad 1000 uniwersytetach w ponad 100 krajach, jest tekst wiodḟcy, czê¶ciowo dlatego, ṡe jego pierwsza edycja byġa pierwszym podrêcznikiem AI opartym na agentach. Zastosowania agentów AI sḟ liczne. Niektóre z nich zostaġy wymienione w sekcji dotyczḟcej agentów oprogramowania powyṡej.
Obliczenia kognitywne
Byæ moṡe najnowszy, a na pewno jeden z najbardziej uporczywych, aktualnych trendów w badaniach nad sztucznḟ inteligencjḟ, nazwano komputerami kognitywnymi. Obliczenia kognitywne obejmujḟ robotykê kognitywnḟ, robotykê rozwojowḟ, samo¶wiadome systemy komputerowe, autonomiczne systemy komputerowe i sztucznḟ inteligencjê ogólnḟ. Opiszemy je po kolei. Jak wspomniano powyṡej, robotyka poczḟtkowo zajmowaġa siê przede wszystkim sposobem wykonywania czynno¶ci i byġa to gġównie dyscyplina inṡynierii mechanicznej. Niedawno nacisk ten przenosi siê na wybór dziaġañ, czyli decydowanie o tym, jakie dziaġania naleṡy wykonaæ. Robotyka kognitywna, udostêpnianie robotów z wiêkszymi zdolno¶ciami poznawczymi, narodziġo siê i staje siê aktywnḟ poddziedzinḟ sztucznej inteligencji. Kolejna ¶ci¶le powiḟzana nowa dziedzina badañ nad sztucznḟ inteligencjḟ, robotyka rozwojowa, ġḟczy robotykê, uczenie maszynowe i psychologiê rozwojowḟ. Pomysġ polega na umoṡliwieniu robotom ciḟgġego uczenia siê. tak jak ludzie. Takie nauczanie powinno pozwoliæ robotom kognitywnym dziaġaæ w ¶rodowiskach zbyt skomplikowanych i zbyt dynamicznych, aby wszystkie zdarzenia mogġy zostaæ rêcznie wykonane w robocie. Ta nowa dyscyplina jest wspierana przez Komitet Techniczny IEEE ds. Autonomicznego rozwoju mentalnego, a takṡe wġasny dziennik "Transakcje autonomicznego rozwoju mentalnego". Agencje rzḟdowe inwestujḟ w kognitywne przetwarzanie danych w postaci systemów samoprzylepnych systemów komputerowych. DARPA, Agencja Zaawansowanych Programów Badawczych Obrony, sponsorowaġa warsztaty na temat samo¶wiadomych systemów komputerowych. Ron Brachman, ówczesny dyrektor biura programowego DARPA IPTO, a od kiedy prezes AAAI, Stowarzyszenie Postêpu Sztucznej Inteligencji, okre¶liġ to nastêpujḟco:
System prawdziwie poznawczy byġby w stanie ... wyja¶niæ, co robi i dlaczego to robi. Byġoby wystarczajḟco refleksyjne, aby wiedzieæ, kiedy zmierzaġo w dóġ ¶lepym zauġkiem, lub kiedy trzeba byġo prosiæ o informacje, których po prostu nie moṡna byġo uzyskaæ poprzez dalsze rozumowanie. Wykorzystujḟc te moṡliwo¶ci, system kognitywny byġby solidny w obliczu niespodzianek. Byġby w stanie poradziæ sobie znacznie bardziej dojrzale z nieprzewidzianymi okoliczno¶ciami, niṡ jakikolwiek inny DARPA obecnie wspiera badania nad takimi systemami kognitywnymi inspirowanymi biologiḟ. IBM Research oferuje ukierunkowane na komercjalizacjê wsparcie obliczeñ kognitywnych poprzez tzw. Komputer autonomiczny. Gġówne zainteresowanie polega tutaj na samokonfigurujḟcych siê, samokontrolujḟcych siê i samoleczḟcych siê systemach. Bardzo aktualnym i nie w peġni rozwiniêtym trendem w badaniach nad sztucznḟ inteligencjḟ jest przej¶cie do systemów wykazujḟcych bardziej ludzkḟ inteligencjê ogólnḟ, czêsto nazywanḟ obecnie sztucznḟ inteligencjḟ ogólnḟ (AGI). Rozwój tego trendu AGI moṡna prze¶ledziæ sekwencjê specjalnych ¶cieṡek, sesji specjalnych, sympozjów i warsztatów. Aktualnie opracowywane systemy AGI to LIDA, Joshua Blue i Novamente.
AI i nauki kognitywne
Strona naukowa sztucznej inteligencji jest po¶wiêcona przede wszystkim modelowaniu ludzkiego poznania. Jej zastosowanie polega na dostarczeniu miejmy nadziejê testowalnych hipotez dla kognitywistów i neuronauk kognitywnych. Oprócz modeli kognitywnych o bardziej ograniczonych ambicjach teoretycznych opracowano zintegrowane modele duṡych czê¶ci poznania. Naleṡḟ do nich: SOAR, ACT-R, CLARION i LIDA. Niektóre z nich zostaġy zaimplementowane obliczeniowo jako agenci oprogramowania, stajḟc siê czê¶ciḟ uciele¶nionego poznania. Jeden z nich, LIDA, wdraṡa kilka róṡnych teorii psychologicznych, w tym globalnḟ teoriê przestrzeni roboczej, pamiêæ roboczḟ, percepcjê przez afordancjê i przej¶ciowḟ pamiêæ epizodycznḟ. Znaczenie tego subpopulacji modelowania poznawczego w AI zostaġo uznane przez kilka wydziaġów informatyki, które zaczêġy oferowaæ programy studiów w kognitywistyce
Gġówne tematy - gdzie teraz siê znajdujḟ?
Inteligentne oprogramowanie a modelowanie kognitywne. Tak jak w caġej historii AI, oba zajêcia nadal sḟ aktywne w badaniach nad sztucznḟ inteligencjḟ, po stronie inṡynieryjnej i naukowej. Obecnie obie strony zmierzajḟ ku bardziej ogólnemu podej¶ciu. Inteligentne oprogramowanie to zaczynajḟc od AGI. Modelowanie kognitywne zmierza w kierunku bardziej zintegrowanych modeli hybrydowych, takich jak ACT-R, CLARION i LIDA, oprócz tradycyjnego zainteresowania bardziej wyspecjalizowanymi modelami. Kolejnym waṡnym krokiem w stronê inteligentnego oprogramowania jest bardziej niezaleṡny system agentów oprogramowania.
Symboliczne AI w porównaniu do sieci neuronowych. Zarówno symboliczna sztuczna inteligencja, jak i sieci neuronowe przetrwaġy zimê i teraz kwitnḟ. Ÿadna strona kontrowersji nie wygraġa. Oba sḟ nadal bardzo przydatne. £ḟczḟ siê nawet w takich systemach hybrydowych jak ACT-R, CLARION i LIDA. ACT-R ukġada siê symbolicznie i funkcje sieci neuronowej, CLARION skġada siê z moduġu sieci neuronowej poġḟczonego z moduġem symbolicznym, a LIDA zawiera aktywacjê przechodzḟcḟ przez system, który w przeciwnym razie symboliczny, co czyni go równieṡ do¶æ neutralnym.
Rozumowanie a percepcja. Badania nad rozumowaniem sztucznej inteligencji sḟ kontynuowane w takich poddziedzinach, jak wyszukiwanie, planowanie i systemy eksperckie. Zastosowania praktyczne w terenie sḟ liczne. Percepcja weszġa w posiadanie w wizji maszynowej, komputerach opartych na agentach i robotyce kognitywnej. Naleṡy zauwaṡyæ, ṡe rozumowanie i percepcja ġḟczḟ siê w dwóch ostatnich, a takṡe w zintegrowanym modelowaniu poznawczym i AGI.
Rozumowanie a wiedza. Oprócz rozumowania, wiedza odgrywa kluczowḟ rolê w systemach eksperckich, a takṡe w komputerach opartych na agentach, komputerach ¶wiadomych i komputerach autonomicznych. Ponownie oba sḟ ṡywe i kwitnḟce, a znaczenie dodawania wiedzy do praktycznych systemów staje siê coraz bardziej oczywiste. Eksploracja danych staġa siê kolejnym sposobem zdobywania takiej wiedzy.
Do reprezentowania lub nie. Bez reprezentacji ,architektura subsumcji Brooksa dopasowuje kaṡdḟ warstwê do wġasnych zmysġów i zdolno¶ci do wybierania i wykonywania pojedynczego dziaġania. Wyṡszy poziom moṡe, w razie potrzeby, podwaṡyæ dziaġanie nastêpnego niṡszego poziom. Dziêki tej architekturze podskórnej kontrolujḟcej roboty, Brooks z powodzeniem stwierdziġ, ṡe wiele moṡna i naleṡy zrobiæ z maġḟ lub ṡadnḟ reprezentacjḟ. Mimo to reprezentacja jest niemal wszechobecna w systemach sztucznej inteligencji potrafiḟ radziæ sobie bardziej inteligentnie z coraz bardziej zġoṡonymi, dynamicznymi ¶rodowiskami. Wydawaæ by siê mogġo, ṡe reprezentacja ma kluczowe znaczenie dla procesu selekcji dziaġañ w systemach sztucznej inteligencji, a tym bardziej dla realizacji tych dziaġañ. Argument, czy reprezentowaæ, wydaje siê po prostu wygasġ.
Mózg w kadzi kontra uciele¶niona sztuczna inteligencja. Po raz pierwszy wydaje siê, ṡe mamy zwyciêzcê. Uciele¶niona lub usytuowana AI po prostu przejêġa kontrolê, poniewaṡ wiêkszo¶æ nowych badañ nad systemami sztucznej inteligencji opiera siê na agentach. Przeglḟdanie tytuġów z konferencji ogólnych AI, takich jak AAAI lub IJCAI (Miêdzynarodowa Wspólna Konferencja Sztucznej Inteligencji), wyja¶nia to doskonale.
Wḟska sztuczna inteligencja w porównaniu z inteligencjḟ na poziomie czġowieka. Wḟskie AI rozwija siê nieprzerwanie, a dḟṡenie do inteligencji na poziomie ludzkim w maszynach nabiera tempa poprzez AGI.
Z wyjḟtkiem silnego ruchu badañ nad sztucznḟ inteligencjḟ w kierunku uciele¶nienia, kaṡda strona kaṡdego problemu nadal jest silnie reprezentowana we wspóġczesnych badaniach nad sztucznḟ inteligencjḟ. Badania nad sztucznḟ inteligencjḟ rozwijajḟ siê tak, jak nigdy przedtem, i obiecujḟ staġy wkġad, zarówno praktyczny, jak i teoretyczny w naukê.