VIII.Percepcja i widzenie komputerowe
Chêæ budowy sztucznych i inteligentnych systemów prowadzi do oczekiwania, ṡe bêdḟ dziaġaæ w naszych typowych ¶rodowiskach. Dlatego oczekiwania dotyczḟce ich zdolno¶ci percepcyjnych sḟ wysokie. Percepcja odnosi siê do procesu u¶wiadamiania sobie elementów ¶rodowiska poprzez doznania fizyczne, które mogḟ obejmowaæ wkġad sensoryczny z oczu, uszu, nosa, jêzyka lub skóry. Skupimy siê na percepcji wzrokowej, która jest dominujḟcym zmysġem u ludzi i byġa uṡywana od pierwszych dni budowy sztucznych maszyn. Dwa wczesne przykġady to Shakey, robot mobilny z dalmierzem i kamerḟ umoṡliwiajḟcḟ mu rozumowanie swoich dziaġañ w pomieszczeniu z kilkoma obiektami, oraz FREDDY, robot staġy z lornetkowym systemem wizyjnym kontrolujḟcym dwa palce rêki. Celem komputerowej wizji jest zrozumienie sceny lub funkcji w obrazach realnego ¶wiata. Waṡnymi ¶rodkami do osiḟgniêcia tego celu sḟ techniki przetwarzania obrazu i rozpoznawania wzorów. Analizê obrazów komplikuje fakt, ṡe jeden i ten sam obiekt moṡe przedstawiaæ aparatowi wiele róṡnych wyglḟdów w zaleṡno¶ci od o¶wietlenia rzucanego na obiekt, kḟta, z którego jest oglḟdany, rzucanych cieni, uṡywanej kamery, czy czê¶ci obiektu sḟ zatkane i tak dalej. Niemniej jednak dzisiejsza wizja komputerowa jest wystarczajḟco zaawansowana, aby wykrywaæ okre¶lone obiekty i kategorie obiektów w róṡnych warunkach, aby umoṡliwiæ pojazdowi autonomicznemu jazdê z umiarkowanymi prêdko¶ciami na otwartych drogach, kierowaæ robotem mobilnym przez zestaw biur i obserwowaæ i zrozumieæ ludzkie dziaġania. Celem tej sekcji jest podkre¶lenie najnowocze¶niejszych metod wizyjnych, które okazaġy siê skuteczne i które doprowadziġy do rozwoju wspomnianych wyṡej moṡliwo¶ci. Po krótkiej dyskusji na temat bardziej ogólnych zagadnieñ podsumowujemy pracê podzielonḟ na cztery kluczowe tematy: rozpoznawanie i kategoryzacjê obiektów, ¶ledzenie i serwomechanizm wizualny, rozumienie ludzkich zachowañ i rozumienie scen kontekstowych. Koñczymy krytycznḟ ocenḟ tego, co osiḟgnêġo widzenie komputerowe i jakie wyzwania pozostajḟ
Paradygmaty i zasady widzenia komputerowego
Widzenie komputerowe to niejednorodna dziedzina obejmujḟca szerokie spektrum metod oraz perspektyw naukowych. Zaczyna siê to od fizycznego zrozumienia, jak powstaje obraz lub co moṡna zasadniczo zobaczyæ. Zanim ¶wiatġo zostanie zebrane w gêsty dwuwymiarowy ukġad na czujniku, zaġamuje siê, odbija, rozprasza lub absorbuje w odniesieniu do sceny. Obraz powstaje przez pomiar natêṡenia promieni ¶wietlnych przez kaṡdy element matrycy - zwany pikselem. Gdyby kto¶ znaġ o¶wietlenie dla kaṡdego moṡliwego promienia ¶wiatġa w scenie, kaṡdy moṡliwy obraz z kamery mógġby zostaæ obliczony przed pomiarem. To odwzorowanie miêdzy punktem widzenia a jego o¶wietleniem jest formalnie opisane przez tak zwanḟ funkcjê plenoptycznḟ. Grafika komputerowa ma na celu przybliṡenie tej funkcji poprzez rendering znanej sceny z danymi ỳródġami ¶wiatġa. W pierwszej perspektywie widzenie komputerowe ma na celu obliczenie odwrotnej funkcji grafiki komputerowej, to znaczy odtworzenie punktu widzenia i leṡḟcej u jego podstaw sceny z danego obrazu, pary obrazów lub sekwencji obrazów. Widzenie komputerowe jest tutaj rozumiane jako problem pomiarowy, który jest szeroko leczony za pomocḟ fotogrametrii, kalibracji fotometrycznej, a takṡe technik rekonstrukcji i rejestracji. to dla kaṡdego moṡliwego punktu widzenia i kḟta widzenia. Drugḟ perspektywḟ wizji komputerowej jest na¶ladowanie wizji biologicznej aby uzyskaæ gġêbsze zrozumienie procesów, reprezentacji i architektur. Tutaj staje siê coraz bardziej oczywiste, ṡe podstawowe pytania i otwarte problemy w widzeniu komputerowym znajdujḟ siê w czoġówce badañ poznawczych. Nie moṡna ich rozwiḟzaæ w oderwaniu, lecz dotyczḟ one fundamentalnych podstaw samego poznania. Trzecia perspektywa postrzega wizjê komputerowḟ jako dyscyplinê inṡynierskḟ, której celem jest rozwiḟzanie praktycznych zadañ zwiḟzanych z widzeniem. Z jednej strony ta perspektywa wymaga wydajnych rozwiḟzañ algorytmicznych, ale z drugiej strony zadaje dalsze pytanie, jak budowaæ komputerowe systemy wizyjne. W tej dziedzinie dominuje heurystyka i wiedza z do¶wiadczenia. Systematyczne podej¶cia metodologiczne sḟ rzadkie, gġównie specyficzne dla aplikacji i obecnie brakuje gġêbokiego zrozumienia problemu widzenia jako takiego. Tak wiêc wszystkie trzy perspektywy nie mogḟ byæ rozdzielone i gġêboko na siebie wpġywajḟ, co - wraz z ogromnym postêpem technicznym - sprawiġo, ṡe wizja komputerowa staġa siê bardzo dynamicznym polem w ciḟgu ostatnich piêædziesiêciu lat. W celu rozwiḟzania okre¶lonych zadañ zwiḟzanych z wizjḟ komputerowḟ naleṡy podjḟæ róṡne decyzje projektowe. Niektóre z nich zostaġy wskazane poniṡej. Jaka wiedza jest potrzebna? Aby zrozumieæ tre¶æ obrazu, odpowiednie czê¶ci naleṡy powiḟzaæ z pojêciami znaczḟcymi semantycznie. W przypadku sceny pokoju konferencyjnego baza wiedzy moṡe obejmowaæ to, ṡe skġada siê z duṡego stoġu i kilku ustawionych wokóġ niego krzeseġ, ṡe stóġ ma blat i tak dalej. Baza wiedzy rozkġada kompleks sceny pokoju konferencyjnego w prostsze elementy, takie jak blat stoġu, które odpowiadajḟ pġaskiej powierzchni lub jednorodnemu obszarowi, który moṡna bezpo¶rednio wyodrêbniæ z obrazu. Dlatego algorytm moṡe rozpoczḟæ siê od wyszukiwania obrazu w poszukiwaniu jednorodnych regionów, co jest koncepcjḟ niskiego poziomu w odniesieniu do sygnaġu. Nastêpnie sḟ one sukcesywnie ġḟczone (kierujḟc siê bazḟ wiedzy), aby tworzyæ koncepcje wyṡszego poziomu. Podej¶cie to jest zwykle okre¶lane jako "oddolne". Inny algorytm moṡe zaczḟæ siê od koncepcji tabeli i szukaæ konkretnie konfiguracji czê¶ci (przewidywanych przez bazê wiedzy), które speġniajḟ wymagania tej koncepcji. Te czê¶ci z kolei mogḟ aktywowaæ detektor stoġowy zastosowany do obrazu. Takie podej¶cie jest zwykle okre¶lane jako "z góry na dóġ". Oba podej¶cia do bazy wiedzy pomogġy w przeprowadzeniu znacznej liczby badañ nad wizjḟ komputerowḟ w latach 70. i 80. XX wieku . Jak przedstawiæ geometriê sceny? Waṡna jest geometria sceny ,po¶rednia reprezentacja w procesie interpretacji obrazu. Moṡna sobie z tym poradziæ w 2D lub 3D. Scena jest przedstawiona jako zwykġy obraz 2D) i obraz gġêboko¶ci. Te ostatnie moṡna obliczyæ na podstawie par obrazów stereo lub bezpo¶rednio zmierzyæ, na przykġad za pomocḟ czujników czasu lotu, które mierzḟ odlegġo¶æ na kaṡdym pikselu poprzez modulowanie i odbieranie wiḟzki ¶wiatġa podczerwonego. Poniewaṡ reprezentacja we wspóġrzêdnych pikseli jest nadal zaleṡna od widoku, jest równieṡ nazywana Szkicem 2 ?D. W nastêpnym kroku prymitywy geometryczne 3D sḟ dopasowywane do sceny, a kaṡde dopasowanie definiuje transformacjê geometrycznḟ. Poniewaṡ obecnie znana jest wzglêdna pozycja 3D i orientacja 3D miêdzy tymi prymitywami, uzyskano reprezentacjê niezaleṡnḟ od widoku i skoncentrowanḟ na obiekcie. Takie podej¶cie zostaġo pierwotnie zasugerowane przez Davida Marra, który równieṡ przyjrzaġ siê koncepcjom ludzkiej wizji znanym w swoim czasie. Jednak w wielu przypadkach ekstrakcja geometrii 3D jest zbyt delikatna. Rzeczywiste ksztaġty obiektów 3D sḟ czêsto zġoṡone, niesztywne i pasujḟ do procedury ,czêsto koñczḟ siê lokalnymi minimami i bġêdnym poġoṡeniem i orientacjḟ obiektu ("pozḟ"). W rezultacie bardziej stabilne reprezentacje geometryczne moṡna równieṡ wyodrêbniæ z obrazów 2D. W takim przypadku obrazy sḟ analizowane pod kḟtem nieciḟgġo¶ci przestrzennych na poziomie szaro¶ci lub powierzchni koloru. Reprezentacje skupiajḟ siê na jednorodnych ġatach obrazu (regiony) lub na krawêdziach (linie graniczne). Oba stanowiḟ podstawê do dalszych procesów interpretacyjnych. Wydobycie takich prymitywów geometrycznych jest problemem cyfrowego przetwarzania obrazu. Jakie sḟ odpowiednie funkcje? Aby dopasowaæ reprezentacjê geometrycznḟ lub obrazowḟ do koncepcji semantycznej, takiej jak "stóġ", "krzesġo" lub "sala konferencyjna", naleṡy okre¶liæ funkcjê decyzyjnḟ, która decyduje o czġonkostwie w klasie lub przeciw niej. Jest to problem klasyfikacji, który jest intensywnie rozwiḟzywany w dziedzinie rozpoznawania wzorów.. Wzór jest reprezentowany przez wektor cech definiujḟcy punkt w przestrzeni o duṡych wymiarach. Biorḟc pod uwagê, ṡe klasy niektórych punktów w tej przestrzeni sḟ znane (np. Zestaw obrazów szkoleniowych opatrzonych adnotacjami rêcznie), moṡna nauczyæ siê funkcji decyzyjnej dzielḟcej przestrzeñ na te klasy. Na rysunku 8.5 podano prosty przykġad. Obraz jest podzielony na sze¶æ czê¶ci i dla kaṡdego podobrazu obliczany jest histogram kolorów. Poġḟczone histogramy zapewniajḟ wektor cech, który moṡna wykorzystaæ na przykġad do klasyfikacji okre¶lonych sal konferencyjnych .Pytanie o dobre cechy jest od dawna tematem dyskusji. Przez lata pojawiġo siê kilka wynalazków, które wywarġy gġêboki wpġyw na tê dziedzinê. W latach 90. XX wieku Swain i Ballard zaproponowali wykorzystanie lokalnych statystyk obiektów (takich jak histogramy kolorów), Turk i Pentland zastosowali technikê opartḟ na wektorach wġasnych do zestawów obrazów ludzkich twarzy (zwanych wtedy twarzami wġasnymi). Póỳniej, w 2000 roku, Viola i Jones zrewolucjonizowali wykrywanie twarzy, wynajdujḟc automatyczny proces wyboru cech oparty na ogromnej liczbie bardzo prostych cech zwiḟzanych z falkami Haara (cechy oparte na binarnym wyborze wġḟczania / wyġḟczania sḟsiadujḟcych czê¶ci obrazu). Kolejnym przeġomem byġa Scale Invariant Feature Transform (SIFT) Davida Lowe'a, która przesunêġa rozpoznawanie obiektów na nowy poziom. Tutaj idee lokalnych statystyk gradientu sḟ ġḟczone z niezwykle stabilnym wykrywaniem staġych punktów na obiekcie - tzw. punkty procentowe. Jak kontrolowaæ proces akwizycji? Wizja biologiczna nie jest pasywnym procesem interpretacyjnym, podobnie jak autonomiczne sztuczne systemy. Ruch agenta w ¶wiecie rzeczywistym w zasadzie determinuje problem percepcji, który musi rozwiḟzaæ. Wizja jest rozumiana jako aktywny proces, który obejmuje kontrolê nad czujnikiem i jest ¶ci¶le powiḟzany z pomy¶lnym wykonaniem decyzji lub dziaġania. Ma to pewne konsekwencje dla projektowania komputerowych systemów wizyjnych, które odnotowano juṡ na poczḟtku lat 90.. Po pierwsze, zamiast modelowaæ izolowany proces interpretacji obrazu, system musi zawsze dziaġaæ i musi kontrolowaæ swoje zachowanie za pomocḟ strumienia obrazów. Po drugie, ogólnym celem przetwarzania wizualnego nie jest zrozumienie obrazu. Zamiast tego system wizyjny musi dziaġaæ jako filtr, który wyodrêbnia informacje istotne dla jego zadania. Po trzecie, system musi zareagowaæ w ustalonym czasie, aby byġ przydatny w bieṡḟcym zadaniu, takim jak nawigacja i omijanie przeszkód w robocie. Po czwarte, zamiast przetwarzaæ peġny obraz, system musi skupiæ siê na regionie zainteresowania (ROI), aby osiḟgnḟæ cele w zakresie wydajno¶ci. Pierwszy ma na celu peġnḟ interpretacjê obrazu, drugi wyciḟga istotne informacje do wyboru akcji i przewidywania stanu.
Rozpoznawanie i kategoryzacja obiektów
Rozpoznawanie obiektów moṡe byæ postrzegane jako wyzwanie dla okre¶lenia "gdzie" i "co" obiektów na scenie. Zaproponowano wiele róṡnych technik, a wszystkie majḟ swoje zalety i wady. Biorḟc pod uwagê scenariusz aplikacji, naleṡy starannie wybraæ odpowiedniḟ technikê rozpoznawania obiektów, która speġnia przewidywany zestaw ograniczeñ. Techniki róṡniḟ siê takṡe dokġadnym problemem, który rozwiḟzujḟ. Wiele technik rozpoznawania to detektory obiektów, które zadajḟ pytanie tak / nie dotyczḟce obecno¶ci klasy obiektów. Obraz jest zwykle skanowany przez model szablonu; oznacza to, ṡe okno jest przesuwane nad obrazem i dla kaṡdej pozycji obliczana jest tak zwana odpowiedỳ filtru poprzez dopasowanie szablonu do podobrazu zdefiniowanego przez okno. Kaṡda inna parametryzacja obiektu (skala obiektu, obrót itp.) Wymaga osobnego skanu. Bardziej wyrafinowane podej¶cia skutecznie wykonujḟ wiele przej¶æ w róṡnych skalach i stosujḟ filtry wyuczone z duṡych zestawów oznaczonych obrazów. Dobrym przykġadem jest wykrywacz twarzy Violi i Jonesa wspomniany w poprzedniej sekcji. W tym przypadku filtr skġada siê z zestawu dodatnich i ujemnych caġek na prostokḟtnych obszarach obrazu wyuczonych wcze¶niej. Techniki oparte na segmentacji najpierw wyodrêbniajḟ geometryczny opis obiektu, grupujḟc razem piksele, które definiujḟ rozszerzenie obiektu na obrazie. Jest to typowy proces oddolny, jak omówiono wcze¶niej. W drugim etapie techniki te obliczajḟ niezmienny zestaw funkcji. Wġa¶ciwo¶æ niezmienniczo¶ci oznacza, ṡe funkcje zachowujḟ te same lub podobne warto¶ci przy róṡnych przeksztaġceniach obrazu, takich jak skalowanie, obracanie lub zmiana o¶wietlenia. Nastêpnie funkcje sḟ uṡywane do rozpoznania klasy obiektu lub wyodrêbnienia zestawu podstawowych operacji podstawowych, z których obiekty sḟ zbudowane. Nowoczesne techniki przeplatajḟ lub ġḟczḟ oba etapy, aby poradziæ sobie z problemami przeszacowania (w których czê¶ci sḟ podzielone na maġe kawaġki) i niedosegmentacji (w których czê¶ci sḟ zgrupowane razem z obszarami tġa). Metody wyrównywania wykorzystujḟ "parametryczne" modele obiektów, które sḟ dopasowane do danych obrazu. Algorytm musi wyszukiwaæ parametry, takie jak skalowanie, obrót lub translacja, które optymalnie dopasujḟ model do odpowiednich funkcji obrazu. Przybliṡone rozwiḟzanie moṡna równieṡ znaleỳæ w procesie odwrotny, tj. cechy obrazu (np. naroṡniki, kontury lub inne charakterystyczne punkty obrazu) gġosujḟ na rozwiḟzania parametrów, które sḟ kompatybilne z wykrytḟ cechḟ (proces wymaga uṡycia schematu gġosowania lub algorytmu, który uzyskuje jedno wyj¶cie z wielu ỳródġa danych). W tym przypadku przestrzeñ parametrów jest dyskretnie dyskretna. Technikê tê czêsto okre¶la siê jako uogólnionḟ transformatê Hougha, a wariant rozpoznawania obiektów zostaġ zastosowany przez Davida Lowe'a wspomnianego w ostatniej czê¶ci. Wszystkie trzy podej¶cia dostarczajḟ róṡnych informacji o obiektach na obrazach i zakġadajḟ, ṡe dostêpne sḟ róṡne rodzaje wiedzy wstêpnej.
Modelowanie 2D
Wiêkszo¶æ obiektów w prawdziwym ¶wiecie jest z natury trójwymiarowa. Niemniej jednak wiele technik rozpoznawania obiektów odnosi siê do reprezentacji 2D ze znacznym sukcesem. Jest tego kilka przyczyn. (1) £atwa dostêpno¶æ: informacje o obrazie 2D otrzymujemy prawie za darmo przy uṡyciu standardowego sprzêtu kamery. (2) Szybkie obliczenia: operacje moṡna obliczyæ bezpo¶rednio z danych pikseli obrazu i nie wymagajḟ one wyszukiwania skomplikowanych prymitywów geometrycznych. (3) Prosta akwizycja modeli wykrywania: Modele uṡywane do automatycznego wykrywania obiektów sḟ zwykle uczone z przykġadowych obrazów. (4) Odporno¶æ na zakġócenia: Funkcje sḟ obliczane bezpo¶rednio na podstawie warto¶ci pikseli. Kontrastuje to z wydobywaniem bardziej abstrakcyjnych prymitywów (obszary, kontury, prymitywy ksztaġtu 3D), które zazwyczaj wiḟṡḟ siê z problemami z segmentacjḟ, a zatem sḟ bardziej podatne na bġêdy w odniesieniu do baġaganu i szumu. (5) Ponadto wiele interesujḟcych obiektów ma do¶æ charakterystyczne widoki 2D - na przykġad strony tytuġowe, znaki drogowe, widoki z boku motocykli lub samochodów, widoki z przodu twarzy. Cena, jakḟ naleṡy zapġaciæ za ignorowanie wġa¶ciwo¶ci 3D obiektów, to zazwyczaj modele o zbyt duṡym lub zbyt ograniczonym dostêpie, poniewaṡ istnieje wiele wariantów perspektyw , z którymi nie moṡna systematycznie sobie radziæ. Typowym przypadkiem niewystarczajḟcego podej¶cia sḟ modele work-of-feature. Podobnie jak modele histogramów wspomniane wcze¶niej, te obliczane statystyki funkcji dotyczḟ regionu obrazu lub caġego obrazu. W ten sposób poġoṡenie elementów jest caġkowicie utracone, a obrotu obiektu i dokġadnej pozycji nie moṡna rozróṡniæ. Zatem na przykġad, je¶li oczy, nos i usta twarzy byġy do góry nogami lub caġkowicie zmieszane, urzḟdzenie rozpoznajḟce nadal nieprawidġowo wykrywa twarz. Z drugiej strony modele z ograniczeniami wymagajḟ wielu reprezentacji, aby poradziæ sobie z róṡnymi konfiguracjami czê¶ci lub obrotami obiektów. (Dobrymi przykġadami sḟ wspomniane wcze¶niej metody oparte na szablonie.) Dlatego je¶li na przykġad twarz zostanie obrócona o 90 stopni, urzḟdzenie rozpoznajḟce nigdy jej nie wykryje. Jako dodatkowḟ cenê do zapġaty musimy poradziæ sobie z trudniejszym problemem segmentacji - czyli z wydobyciem obiektu z jego tġa. Zazwyczaj tġo jest dalej, wiêc informacje 3D zapewniajḟ znacznie silniejszḟ wskazówkê niṡ warto¶ci luminancji obrazów 2D. Dominujḟcḟ klasḟ technik rozpoznawania obiektów 2D sḟ podej¶cia oparte na wyglḟdzie. Zamiast uṡywaæ niezmiennej reprezentacji zorientowanej obiektowo reprezentacji, reprezentujḟ one róṡne aspekty obiektu. Kompaktowe reprezentacje sḟ dostarczane przez wykresy aspektowe, które ġḟczḟ róṡne wyglḟdy 2D w wydajnej strukturze danych. Po drugie, podej¶cia oparte na wyglḟdzie upuszczajḟ po¶redni poziom reprezentacji geometrycznej, obliczajḟc cechy bezpo¶rednio z warto¶ci pikseli. Ma to pewne konsekwencje dla rodzaju klas obiektów, które moṡna rozróṡniæ, oraz wariantów wewnḟtrz klasy, które moṡna uwzglêdniæ. Jak dotḟd omawiane metody dotyczḟ zmian obrotu, o¶wietlenia, haġasu i niewielkich znieksztaġceñ ksztaġtu obiektu. Zakġadajḟ gġównie, ṡe obiekty sḟ staġe, w przybliṡeniu sztywne, majḟ podobne tekstury lub kolory i sḟ w niewielkim stopniu zasġoniête. Dalsze warianty sḟ uwzglêdniane w lokalnych podej¶ciach deskryptorów. Tutaj gġównḟ ideḟ jest wykrycie istotnych punktów na obrazie, które zapewniajḟ czê¶ciowe opis funkcji zamiast peġnego modelu wyglḟdu. Podej¶cia te zwróciġy uwagê w pierwszej dekadzie XXI wieku i osiḟgnêġy niespotykany wcze¶niej wystêp. Opierajḟc siê na lokalnych deskryptorach (typowe przykġady to funkcje SIFT lub SURF, które analizujḟ rozkġad gradientów obrazu wokóġ punktu obrazu), metody te sḟ w stanie poradziæ sobie z okluzjḟ i lokalnymi wariacjami wystêpujḟcymi w rzeczywistych warunkach
Modelowanie 3D
Obrazy kolorowe lub intensywne 2D nie kodujḟ bezpo¶rednio informacji o gġêboko¶ci ani ksztaġcie. W zwiḟzku z tym rozpoznawanie i lokalizacja obiektów jest trudnym problemem i ogólnie ỳle przedstawionym. Aby rozwiḟzaæ te problemy, ksztaġt 3D obiektów moṡna odzyskaæ bezpo¶rednio z gġêbi lub zakresu obrazów. Gġêboko¶æ obrazów moṡna uzyskaæ róṡnymi metodami, od skanowania za pomocḟ czujnika laserowego, podej¶cie do ¶wiatġa strukturalnego, do systemów stereo wykorzystujḟcych dwie kamery, co jest metodḟ stosowanḟ przez ludzkie widzenie. Tanim przykġadem strukturyzowanego aparatu ¶wietlnego jest kolorowa i gġêboka kamera Kinect. Gġównym pytaniem w widzeniu komputerowym jest sposób modelowania lub reprezentowania obiektu w taki sposób, aby moṡna go byġo wykryæ na podstawie gġêbokich danych. Jednym ze sposobów jest parsowanie ksztaġtów na czê¶ci skġadowe i zdefiniowanie ich relacji przestrzennych. W widzeniu komputerowym czê¶ci sḟ przydatne z dwóch powodów. Po pierwsze, wiele obiektów jest przegubowych, a oparty na czê¶ciach opis pozwala nam oddzieliæ ksztaġty czê¶ci od ich relacji przestrzennych. Po drugie, nie wszystkie czê¶ci obiektów sḟ widoczne, ale czê¶ci sḟ czêsto wystarczajḟce do rozpoznania obiektu; na przykġad kubek moṡna rozpoznaæ po korpusie lub uchwycie. Kluczowym aspektem reprezentacji opartych na czê¶ciach jest ich liczba parametrów. W ostatnim dziesiêcioleciu dokonano wielu prac opisujḟcych dane dotyczḟce gġêboko¶ci za pomocḟ rotacyjnych symetrycznych prymitywów (kula, walec, stoṡek, torus). Uogólnione cylindry moṡna utworzyæ, przesuwajḟc kontur 2D wzdġuṡ dowolnej krzywej przestrzennej. Poniewaṡ kontur moṡe siê zmieniaæ wzdġuṡ krzywej (osi), definicje osi i krzywej zamiatania sḟ potrzebne do zdefiniowania uogólnionego walca, który wymaga duṡej liczby parametrów. Czêsto cytowanym systemem wczesnego widzenia, w którym zastosowano cylindry uogólnione, jest system ACRONYM do wykrywania samolotów. Jednak dopasowanie wielu parametrów jest skomplikowane i ograniczyġo stosowanie tej metody. Jedna z najlepiej zbadanych metod modelowania 3D polega na odzyskiwaniu nadkwadratów - ksztaġtów geometrycznych okre¶lonych przez wzory, w tym arbitralnych mocy do tworzenia ksztaġtów przypominajḟcych sze¶ciany, cylindry i stoṡki, o zaokrḟglonych lub ostrych naroṡach. Staġy siê one popularne, poniewaṡ maġy zestaw parametrów moṡe opisywaæ duṡḟ róṡnorodno¶æ róṡnych podstawowych ksztaġtów. Solina i in. byġ pionierem prac nad odzyskiwaniem pojedynczych nadkwadrat i wykazaġ, ṡe odzyskiwanie nadkwadratów z obrazów zasiêgu jest wraṡliwe na szum i warto¶ci odstajḟce, w szczególno¶ci z pojedynczych widoków podanych w aplikacjach takich jak robotyka. Jaklic i wspóġpracownicy podsumowujḟ paradygmat odzyskiwania i wyboru do segmentowania sceny z prostymi obiektami geometrycznymi bez okluzji. Ta metoda peġnego wyszukiwania z otwartym czasem przetwarzania nieodpowiednim dla wiêkszo¶ci aplikacji, takich jak robotyka. Ostatnio obrazy z czujników gġêboko¶ci, takich jak Kinect lub z systemów stereo, sḟ czê¶ciej wykorzystywane do uzyskiwania danych 3D. Poniewaṡ dane na ogóġ nie sḟ tak dobre jak ze skanów laserowych, stosuje siê metody statystyczne, a nie bezpo¶rednie metody ksztaġtowania. Przykġadem jest wykrycie krzeseġ. Otwartymi problemami w tym obszarze sḟ sposoby radzenia sobie z rzadkimi danymi wynikajḟcymi ze skanów sceny w jednym widoku, radzenia sobie z typowym laserem i kamerowania cieni i okluzji w zagraconych scenach oraz radzenia sobie z niepewno¶ciḟ obrazów stereo.
Ḋledzenie i wizualny serwomechanizm
Innym typowym zadaniem wykonywanym przez ludzi jest wykrywanie i ¶ledzenie ruchu obiektów. Podczas chwytania obiektu obserwuje siê ruch wzglêdny. Podczas chodzenia monitorowany jest ruch otoczenia. Technika wizualnego ¶ledzenia obiektu i okre¶lania jego poġoṡenia jest stosowana szczególnie w zadaniach nadzoru i robotyki. W tym pierwszym szacuje siê, ṡe ¶cieṡki samochodów lub osób odzyskujḟ bieṡḟce dziaġania i odpowiednio reagujḟ. W robotyce celem jest ¶ledzenie wzglêdnej pozycji robota mobilnego i jego otoczenia lub skierowanie robota do obiektu. Ciḟgġe sterowanie zwrotne poġoṡenia robota jest nazywane wizualnym serwomechanizmem. Pierwsze sukcesy w zakresie autonomicznej jazdy samochodem i prowadzenia pojazdu powietrznego wskazujḟ na zastosowanie wizualnego serwomechanizmu. Jednak nadal istniejḟ dwie gġówne przeszkody w dalszym korzystaniu ze scenariuszy w ¶wiecie rzeczywistym. Po pierwsze, wymagany jest wydajny cykl ¶ledzenia. Wizja i kontrola muszḟ byæ poġḟczone, aby zapewniæ dobrḟ dynamikê. Potrzebne sḟ szybkie ruchy, aby uzasadniæ uṡycie serwomechanizmu wizualnego w rzeczywistych aplikacjach robotycznych. Po drugie, musi istnieæ niezawodne wykrywanie obiektów docelowych. Wizja musi byæ solidna i niezawodna. Percepcja musi byæ w stanie oceniæ stan obiektów i robota, umoṡliwiajḟc robotowi reagowanie na zmiany i upewnienie siê, ṡe porusza siê bezpiecznie w swoim otoczeniu. Problem z cyklem ¶ledzenia spotkaġ siê z duṡym zainteresowaniem w literaturze , ale niezawodne wizualne wykrywanie celów jest równie waṡne, a ostatnio zaczêġo otrzymywaæ coraz wiêcej uwagi. W poniṡszych sekcjach podsumowano stan techniki w odniesieniu do tych dwóch kryteriów.
Cykl ¶ledzenia
Celem serwomechanizmu wizualnego jest uwzglêdnienie caġego systemu i jego interfejsów. Podstawowa pêtla sterowania jest przedstawiona na rysunku
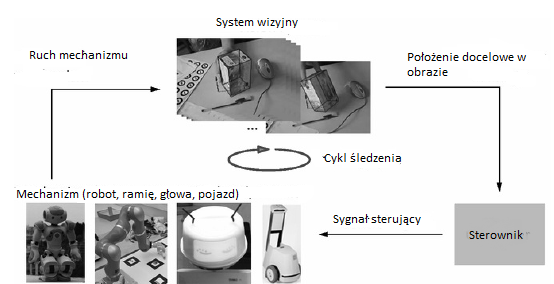
Zawiera trzy gġówne bloki: system wizyjny, sterownik i mechanizm (robot lub pojazd). System wizyjny okre¶la bieṡḟcḟ lokalizacjê celu (obiektu bêdḟcego przedmiotem zainteresowania) na obrazie. Kontroler przeksztaġca lokalizacjê na obrazie na pozycjê w przestrzeni lub bezpo¶rednio w warto¶ci poleceñ. System powtarza to z czêstotliwo¶ciḟ cyklu. W kaṡdym cyklu okre¶lana jest nowa lokalizacja, a takṡe moṡna uṡyæ róṡnicy lokalizacji w celu uzyskania polecenia sterujḟcego. Robot lub pojazd zwykle uṡywa osobnego kontrolera do sterowania silnikami na poziomie osi i kóġ. Celem jest zbudowanie systemu ¶ledzenia, aby cel nie zostaġ utracony. Jeden limit ¶ledzenia jest okre¶lony przez pole widzenia kamery. Stḟd tak jest przydatne do badania ¶ledzenia najwyṡszej moṡliwej prêdko¶ci docelowej (lub przyspieszenia). Wġa¶ciwḟ wġa¶ciwo¶ciḟ jest opóỳnienie (lub opóỳnienie) sprzêṡenia zwrotnego generowanego przez system wizyjny. Dwa gġówne czynniki, którymi naleṡy siê zajḟæ, to (1) opóỳnienie lub opóỳnienia w jednym cyklu oraz (2) czê¶æ lub okno obrazu, który jest faktycznie przetwarzany. Opóỳnienia gromadzḟ siê w kamerze. Obecnie aparaty wytwarzajḟ obrazy z czêstotliwo¶ciḟ 25 lub 30 Hz lub obrazów na sekundê. Dodatkowe opóỳnienia wynikajḟ z czasu przesġania danych obrazu do kontrolera. Najwiêkszym opóỳnieniem jest czas potrzebny do przetworzenia obrazu. Choæ wydaje siê intuicyjne, ṡe opóỳnienia opóỳniajḟ ¶ledzenie, drugi czynnik, przetwarzanie obrazu, czêsto nie jest przestrzegany. Je¶li zostanie obliczony peġny obraz, moṡe to potrwaæ znacznie dġuṡej niṡ czas kadru w aparacie, co w konsekwencji spowoduje utratê zdjêæ. Je¶li zostanie uṡyte maġe okno, na przykġad wokóġ miejsca, w którym cel byġ widziany na ostatnim obrazie, moṡliwe jest wykorzystanie kaṡdego obrazu. Optymalne osiḟga siê, gdy rozmiar okna jest tak dobrany, ṡe przetwarzanie jest tak szybkie, jak pozyskiwanie obrazów, a przetwarzanie obrazu dziaġa z tḟ samḟ czêstotliwo¶ciḟ 25 lub 30 Hz. Oznacza to, ṡe optymalne jest dziaġanie systemu ¶ledzenia z opóỳnieniem dwóch cykli liczby klatek na sekundê dla kamer: jeden do przesyġania obrazu z aparatu do komputera, a drugi do przetwarzania obrazu. Aby zrekompensowaæ to opóỳnienie, filtry (takie jak filtr Kalmana) przewidujḟ, gdzie bêdzie cel (Chaumette i Hutchinson). Warto zauwaṡyæ, ṡe ludzkie oko bardzo róṡni siê od aparatu. Aparaty majḟ jednolity ukġad pikseli w jednej rozdzielczo¶ci lub odstêpie miêdzy pikselami. Ludzka siatkówka wykazuje teselacjê w wariancie kosmicznym z foveḟ o wysokiej rozdzielczo¶ci po¶rodku i szerokim polem widzenia (okoġo 180 stopni) przy logarytmicznie malejḟcej rozdzielczo¶ci. W efekcie czġowiek caġy czas przetwarza caġy obraz (Vincze 2005). Ludzie mogḟ reagowaæ na ruch na peryferiach, podczas gdy rozpoznawanie dziaġa tylko w fovei, która jest obrócona do celu i ¶ledzi go.
Solidne wykrywanie celu
Niezawodno¶æ ¶ledzenia ma zasadnicze znaczenie dla zapewnienia ciḟgġo¶ci dziaġania w aplikacjach. Stwierdzenie, ṡe metoda ¶ledzenia jest niezawodna, oznacza, ṡe zmniejsza siê ona pġynnie, gdy dane wej¶ciowe sḟ haġa¶liwe i zawierajḟ warto¶ci odstajḟce. Powszechnym mianownikiem technik poprawy niezawodno¶ci jest wykorzystanie nadmiarowo¶ci za pomocḟ wielu kamer, wielu rozdzielczo¶ci, ograniczeñ czasowych nieodġḟcznie zwiḟzanych ze ¶ledzeniem, modelami oraz integracji kilku wskazówek lub funkcji. Minimalna forma redundancji jest nieodġḟczna w systemie wizyjnym stereo wykorzystujḟcym dwie nieruchome kamery i szukajḟcym celu na obu obrazach. Obecnie systemy obliczajḟce gġêbiê obrazu z dwóch obrazów stereo sḟ dostêpne w handlu (np. Videre Design). Niemniej jednak problem korespondencji (znalezienie tego samego punktu sceny na obu obrazach) pozostaje, a udane zastosowania stereo sḟ rzadkie. Problem korespondencji widzenia wizyjnego jest redukowany przez uṡycie trzech lub wiêcej kamer, jak w TRICLOPS (Point-Gray Research). Systemy wspomagajḟce do kierowania samochodami przy duṡych prêdko¶ciach wykorzystujḟ dwie lub trzy kamery o róṡnych polach widzenia. Pomysġ ġḟczenia informacji z róṡnych poziomów rozdzielczo¶ci zostaġ wykorzystany w podej¶ciu do przestrzeni skali lub piramidy obrazowej, w której oryginalny obraz jest kilkakrotnie zmniejszany. Spójno¶æ jest agregowana na mniejszych obrazach, aby uzyskaæ miarê niezawodno¶ci, na przykġad wykrywania krawêdzi. Ostatnio funkcje punktów procentowych (obiekty, które majḟ maksymalne gradienty) wykorzystujḟ to do wybrania najsolidniejszej lokalnej skali punktu gradientu, na przykġad SIFT. Jednak uṡycie piramid obrazowych nie zostaġo wystarczajḟco wykorzystane. Nadmiarowo¶æ serii obrazów moṡna wykorzystaæ, biorḟc pod uwagê spójno¶æ czasowḟ wykrytych funkcji, zwanḟ takṡe powiḟzaniem danych czasowych. Aby poradziæ sobie z niepewno¶ciḟ lokalizowania obiektu docelowego na obrazie, powszechnie stosowane sḟ standardowe metody teorii sterowania, takie jak filtrowanie i przewidywanie (patrz wyṡej) w celu poprawy niezawodno¶ci. Obecnie najczêstszym podej¶ciem do radzenia sobie z tḟ niepewno¶ciḟ jest Kalman lub filtrowanie czḟstek, gdzie kilka hipotez pomaga w adaptacji do niepewno¶ci ruchu mechanizmu i pomiar. Podej¶cie dynamicznej wizji) wykorzystaġo czasowḟ ewolucjê cech geometrycznych, takich jak linie, do zbudowania modelu postrzeganego ¶wiata. Fizyczne wġa¶ciwo¶ci obiektów, takie jak pewna bezwġadno¶æ, sḟ wykorzystywane do przewidywania przyszġych pozycji obiektu na nastêpnych obrazach. Ḋledzenie sġuṡy nastêpnie do potwierdzenia lub aktualizacji trybu ruchu. Innym podej¶ciem jest wizja modelowa . Model jest zwykle reprezentacjḟ CAD celu (komputerowego wspomagania projektowania), która jest uṡywana do przewidywania poġoṡenia obiektu (modelu) na nastêpnym obrazie. Roboty mobilne przechowujḟ (lub budujḟ) reprezentacjê obiektów, takich jak ¶ciany, filary lub skrzynki, do celów nawigacji lub chwytania obiektów. U ludzi integracja wskazówek lub cech, takich jak tekstura, kolor, cieniowanie itp. Zostaġa zidentyfikowana jako prawdopodobne ỳródġo doskonaġej zdolno¶ci radzenia sobie ze zmieniajḟcymi siê warunkami. Podsumowujḟc, istnieje wiele podej¶æ do ¶ledzenia. Wiêkszo¶æ z nich jest solidna lub szybka. Podczas gdy ¶ledzenie oparte na regionach lub punktach zainteresowania jest bardziej niezawodne w ¶rodowiskach teksturowanych, schematy ¶ledzenia oparte na krawêdziach zapewniajḟ najlepszy wkġad do wizualnego serwomechanizmu w robotyce lub w systemach rzeczywisto¶ci rozszerzonej, w których dodatkowe informacje sḟ wizualizowane na rzeczywistych obrazach. Przy staġym wzro¶cie mocy obliczeniowej prace nad integracjḟ pamiêci pójdḟ dalej. Wiele moṡna uzyskaæ dziêki wykorzystaniu wiêkszej wiedzy na temat zadania i dziedziny, modeli obiektów i funkcji obiektów, a takṡe dziêki wskazówkom, takim jak poziomy rozdzielczo¶ci, spójno¶æ czasowa i róṡne funkcje obrazu.
Zrozumienie ludzkiego zachowania
Nadzór wzrokowy
Inteligentne pokoje, interfejsy czġowiek-maszyna oraz aplikacje bezpieczeñstwa i ochrony wymagajḟ umiejêtno¶ci rozpoznawania dziaġañ ludzi. To pole jest znane jako nadzór wizualny. Zazwyczaj systemy nadzoru dziaġajḟ z kamer stacjonarnych, co pozwala na uṡycie technika odejmowania tġa w celu wykrycia zmian na obrazie. Odejmowanie tġa wykorzystuje obrazy statyczne do uzyskania modelu staġej sceny tġa, która upraszcza zadanie wydobywania ruchomych obiektów pierwszego planu (pojazdów, osób itp.) Gġównym zadaniem jest radzenie sobie ze zmiennym o¶wietleniem, które zmienia wyglḟd obrazu i moṡe ukrywaæ zmiany spowodowane poruszajḟcymi siê obiektami na pierwszym planie. Ta forma wykrywania zmian powoduje, ṡe obszary obrazu sḟ uṡywane jako wskazania obiektów. W nastêpnym kroku te plamy sḟ ¶ledzone w sekwencji obrazów, w której stosowane sḟ metody asocjacji danych, aby znaleỳæ stale poruszajḟce siê obiekty i wykryæ wygenerowane bġêdne obszary. Preferowane metody modelowania konsekwentnie poruszajḟcego siê obiektu to
Ukryte Modele Markowa i sieci bayesowskie. Systemy nadzoru czêsto dziaġajḟ w dwóch fazach: fazie uczenia siê i fazie dziaġania. W fazie uczenia system jest inicjowany na scenie, a modele sḟ dostosowywane lub uczone na podstawie obserwacji. Modele te zawierajḟ dane o normalnych czynno¶ciach, takich jak pasy samochodów, punkty wjazdu lub typowe gesty czġowieka. W fazie wykonawczej strumienie danych sḟ porównywane z danymi modelu, aby uzyskaæ interpretacje i reakcje. Obecnie systemy mogḟ wykrywaæ i rozpoznawaæ zachowanie kilku osób aṡ do wiêkszych grup ludzi. W scenach drogowych przetwarzanie odbywa siê gġównie oddolnie, podczas gdy nowsze systemy wykorzystujḟ wiedzê domenowḟ w odgórny sposób. Przykġadem jest zastosowanie modeli obiektowych i oczekiwanych modeli aktywno¶ci do monitorowania aktywno¶ci na fartuchach lotniskowych). W dziedzinie robotyki badano relacjê obiekt-czġowiek w podej¶ciach takich jak Programowanie przez Demonstracjê (PbD), gdzie zadaniem jest interpretacja poleceñ uṡytkownika w celu
nauczenia robota . W trybie PbD uṡytkownik albo fizycznie prowadzi ramiê robota przez ruch, albo system wizyjny przechwytuje ruch ludzkiego ramienia i przenosi go na ramiê robota. W ostatnich pracach czynno¶ci rêki i przedmiotów sḟ interpretowane i przechowywane przy uṡyciu wyraṡeñ jêzyka naturalnego w planie aktywno¶ci - zwiêzġe przedstawienie scenariusza okre¶lajḟcego odpowiednie obiekty i sposób ich dziaġania. Wraz ze spadkiem kosztów kamer obecny kierunek prac dotyczy sieci kamer monitorujḟcych duṡe obszary. Szczegóġowe modele ludzi i ich typowe czynno¶ci dajḟ lepszḟ interpretacjê gestów w mniej ograniczonych warunkach
Interakcja czġowiek-maszyna
Przej¶cie od technik obserwacji wzrokowej do opartego na wizji interaktywnego interfejsu czġowiek-komputer wydaje siê maġym krokiem. Otwiera peġnḟ gamê nowych aplikacji, w których komputery, monitory i urzḟdzenia wej¶ciowe, takie jak klawiatura i mysz, znikajḟ w codziennym ¶rodowisku. Na przykġad prosty gest i spojrzenie rêki moṡe przenie¶æ kolekcjê zdjêæ z aparatu na duṡy ekran telewizora w salonie, zmieniajḟc ludzkie ciaġo w kontekstowy pilot zdalnego sterowania. Jakkolwiek atrakcyjny moṡe byæ ten krok, jego realizacja napotyka kilka problemów technicznych i koncepcyjnych: (1) Reaktywno¶æ: System musi reagowaæ na aktywno¶æ uṡytkownika w odpowiednio krótkim czasie. W przeciwnym razie uṡytkownik jest rozproszony, sfrustrowany i zagubiony w odniesieniu do stanu komunikacyjnego. Opracowano odpowiednie techniki rozpoznawania twarzy, wykrywania wzroku i rozpoznawania gestów oraz okre¶lajḟ dziedzinê aktywnych badañ. (2) Wytrzymaġo¶æ: Wysokie wspóġczynniki wykrywalno¶ci faġszywie dodatnich spowodowaġyby niepoṡḟdane dziaġanie systemu przez uṡytkownika i koliduje z ich oczekiwaniami. Jest to szczególnie problematyczne, poniewaṡ nie wszystkie zachowania uṡytkowników sḟ kierowane do systemu. Waṡnḟ koncepcjḟ jest wspólna uwaga - stan, w którym obaj partnerzy komunikacyjni zwracajḟ uwagê na to samo i sḟ ¶wiadomi swojej uwagi. Na przykġad w interakcji czġowiek-robot robot musi wykryæ, kiedy uṡytkownik jest skierowany w jego stronê. W tym samym czasie gġowa i oczy robota bêdḟ ¶ledziæ twarz uṡytkownika, aby wzmocniæ ustanowionḟ komunikacjê. (3) Niezawodno¶æ: dziaġania uṡytkownika czê¶ciowo pominiête przez system mogḟ uszkodziæ dane wej¶ciowe caġego uṡytkownika do systemu. Dlatego musi istnieæ sposób ustalenia, czy dane wej¶ciowe sḟ dobrze uformowane albo nie. Jest to trudny problem w nauce i rozpoznawaniu, poniewaṡ ludzie zazwyczaj wykonujḟ zadania o duṡej zmienno¶ci i nie sḟ ¶wiadomi ograniczeñ systemu. Jednym z interesujḟcych kierunków badañ jest zrozumienie, w jaki sposób ludzie komunikujḟ oczekiwania w dialogu, na przykġad zadajḟc pytanie tak / nie lub stosujḟc inne konwencje, które ograniczajḟ moṡliwe odpowiedzi. (4) Sytuacja: interpretacja wiêkszo¶ci ludzkich zachowañ zaleṡy od kontekstu. Dlatego wiele systemów zaprojektowano z my¶lḟ o bardzo specyficznym scenariuszu lub domenie aplikacji. W celum przezwyciêṡenia tych ograniczeñ waṡnym pojêciem jest ¶wiadomo¶æ kontekstu - koncepcja wprowadzona w spoġeczno¶ci komputerów mobilnych (Schilit, Adams i Want 1994). W przypadku wizji komputerowej zastosowano jḟ do pomieszczeñ spostrzegawczych, na przykġad Crowley i inni. Tam dziaġania czġowieka sḟ obserwowane przez wiele kamer i sḟ podzielone na kategorie pod wzglêdem róṡnych kontekstów i sytuacji. W wyniku wyṡej omówionych punktów badania nad opartḟ na wizji interakcjḟ czġowiek-maszyna zawsze muszḟ uwzglêdniaæ kompletne systemy wraz z ich partnerami interakcji, co czyni je wysoce interdyscyplinarnym zadaniem. Wiêkszo¶æ systemów w tym obszarze ¶ci¶le ogranicza ustawienia komunikacyjne. Wczesnḟ pracê wykonaġ Bolt i jego koledzy w swoim systemie "Put-That-There". Uṡytkownik byġ w stanie tworzyæ i przenosiæ elementy geometryczne na ekranie za pomocḟ gestów i poleceñ gġosowych. Dzisiejsze systemy obejmujḟ szeroki zakres technik i aplikacji. SafetyEYE opracowany w badaniach przemysġowych ocenia promieñ dziaġania przemysġowego robota produkcyjnego i zatrzymuje go w przypadku interferencji czġowiek-maszyna. MIT Kidsroom zapewnia interaktywnḟ przestrzeñ zabaw narracyjnych dla dzieci (Bobick i in. 1999). Opiera siê na wizualnych technikach rozpoznawania akcji poġḟczonych z kontrolḟ obrazów, wideo, ¶wiatġa, muzyki, dỳwiêku i narracji. Crowley i inni opisujḟ interaktywnḟ Magicznḟ tablicê opartḟ na ¶ledzeniu palców i oknie percepcyjnym, które przewija siê, wykrywajḟc ruchy gġowy. W ostatnich latach ¶ledzenie ciaġa staġo siê popularnym tematem komercyjnym dla konsol do gier, takich jak Sony PlayStation i Microsoft Xbox. Innḟ uwagê zwrócono na system VAMPIRE , który zapewniaġ pomoc ludziom w codziennych zadaniach, prowadzḟc ich krok po kroku przez przepis. Zostaġo to zademonstrowane w scenariuszu mieszania napojów i wykorzystano techniki rozpoznawania obiektów, ¶ledzenia, lokalizacji i rozpoznawania akcji w celu uzyskania pomocy uṡytkownika w oparciu o techniki rzeczywisto¶ci rozszerzonej. Przeprowadzono wiele prac w celu poġḟczenia mostu w komunikacji miêdzy ludỳmi a robotami usġugowymi zaprojektowanymi tak, by zachowywaæ siê jak towarzysz w domu. Przykġadami sḟ PR2 z Willow Garage, Care-O-Bot 3 z Fraunhofer IPA, Cosero z University of Bonn lub ToBI z Bielefeld. Pierwszy z nich moṡe zġoṡyæ pranie lub wypiæ napój z lodówki. Inni brali udziaġ w konkursie RoboCup @ Home, który obejmuje szereg testów porównawczych, od osób ¶ledzḟcych i wprowadzajḟcych go¶ci do sprzḟtania i pobierania napojów. W porównaniu z komunikacjḟ czġowiek-czġowiek (HHC), interakcja czġowiek-maszyna jest wciḟṡ krucha i jest w powijakach. Dzisiejsze badania koncentrujḟ siê na na¶ladowaniu niektórych aspektów HHC w celu rozwiḟzania czterech opisanych wyzwañ.
Zrozumienie kontekstu sceny
Wiêkszo¶æ podej¶æ do widzenia komputerowego nie interpretuje caġych obrazów, ale ich wybrane czê¶ci. Ich celem jest wydobycie obiektów pierwszego planu z baġaganu w tle. Nastêpnie kaṡdy obiekt jest klasyfikowany osobno. Tġo jest ignorowane i postrzegane jako nieistotne rozpraszajḟce dane lub po prostu jako szum. Kontekstowe zrozumienie sceny przyjmuje przeciwstawne zaġoṡenie, ṡe obiektów pierwszego planu nie moṡna automatycznie wyodrêbniæ lub przynajmniej nie zapewniajḟ one wystarczajḟcych informacji do klasyfikacji. Przetwarza zignorowane wcze¶niej dane - baġagan w tle i informacje relacyjne - w celu ustalenia moṡliwych interpretacji obiektów na pierwszym planie. Zatem techniki te majḟ na celu wġḟczenie kontekstu sceny do procesu klasyfikacji. Pionierskie prace zostaġy przeprowadzone przez Strata i Fischlera, którzy definiujḟ zestawy kontekstów, które regulujḟ wywoġywanie kroków przetwarzania systemu. Identyfikujḟ cztery róṡne rodzaje kryteriów, które obejmujḟ zestawy kontekstów: (1) konteksty globalne - atrybuty caġej sceny, takie jak dzieñ lub krajobraz; (2) lokalizacja - przestrzenna konfiguracja sceny, taka jak dotykanie ziemi lub zbieṡno¶æ z innymi typami obiektów; (3) wyglḟd sḟsiednich obiektów, takich jak podobieñstwo lewego i prawego oka twarzy; oraz (4) funkcjonalno¶æ - rola obiektu w scenie, taka jak obsġuga innego obiektu lub mostkowanie strumienia. Z kontrolnego punktu widzenia Strat i Fischler stosujḟ trzy rodzaje operacji kontekstowych do kierowania procesem interpretacji sceny: generowanie hipotez, walidacja hipotez i porzḟdkowanie hipotez. Podczas poszukiwania hipotez (generacji) konstruowane sḟ spójne grupy uznanych bytów, które reprezentujḟ czê¶ciowe interpretacje sceny. Gġównḟ wadḟ tego rodzaju podej¶cia jest ogromne zadanie inṡynierii wiedzy w kodowaniu wiedzy kontekstowej systemu. Jednak ogólne typy wprowadzonych kontekstów i róṡne rodzaje zaprojektowanych zasad kontroli sḟ nadal aktualne w obecnym stanie techniki. Póỳniejsze prace dostosowaġy modele probabilistyczne do interpretacji kontekstualnej, które systematycznie ujmujḟ relacje i niepewno¶æ. Poniṡsze przykġady ilustrujḟ najnowsze trendy dotyczḟce wprowadzonych wcze¶niej ogólnych typów kontekstów. Konteksty globalne sġuṡḟ do klasyfikowania miejsc semantycznych (np. ulica, miasto, plaṡa lub kategorie pomieszczeñ wewnêtrznych, takich jak kuchnia). W ten sposób obliczana jest holistyczna reprezentacja obrazu - tzw. Istota obrazu. Kategoria semantyczna zawiera oczekiwania dotyczḟce czêsto wystêpujḟcych obiektów (takich jak te zwykle spotykane w kuchni). Lokalizacja jest modelowana przez Hoiema i wspóġpracowników, którzy odnoszḟ detekcje obiektów do ogólnego kontekstu sceny 3D i oceniajḟ skalê i lokalizacjê w odniesieniu do szacowanej geometrii sceny. Funkcjonalno¶æ wykorzystujḟ Moore, Essa i Hayes, którzy ġḟczḟ ludzkie dziaġania i przedmioty za pomocḟ modelu probabilistycznego. Wprowadzajḟ koncepcjê przestrzeni obiektowych, które ġḟczḟ oba rodzaje informacji w przestrzeni i czasie. Wreszcie konteksty jêzykowe odnoszḟ siê do dodatkowych informacji podawanych przez równolegġy tekst lub mowê. Tego rodzaju dane bimodalne czêsto pojawiajḟ siê w katalogach, gazetach, czasopismach, stronach internetowych, wiadomo¶ciach telewizyjnych, filmach lub dialogach interakcji czġowiek-maszyna. Informacje sġowne obejmujḟ przede wszystkim wszystkie trzy typy informacji kontekstowych. Podpis pod zdjêciem mówiḟcy o "ruchu ulicznym" w Nowym Jorku moṡe daæ wskazówkê, ṡe obraz przedstawia scenê miejskḟ. Inne opisy sġowne, na przykġad, ṡe dwie osoby stojḟ obok siebie, zapewniajḟ lokalne ograniczenia dla analizy obrazu. Konteksty funkcjonalne mogḟ pochodziæ z czasowników, chociaṡ ta metoda nie byġa szeroko stosowana.
Podsumowanie i wnioski
Agenci, ludzcy lub sztuczni, muszḟ postrzegaæ swoje ¶rodowisko, aby móc w nim funkcjonowaæ i przetrwaæ. Percepcja wzrokowa jest najsilniejszym ludzkim zmysġem, a praca w dziedzinie widzenia komputerowego ma na celu zapewnienie wymaganych moṡliwo¶ci. W tym rozdziale podsumowano gġówne osiḟgniêcia, zaczynajḟc od przeglḟdu trendów i perspektyw, a nastêpnie podkre¶lajḟc gġówne obszary zastosowania. Obecnie maszyny mogḟ uczyæ siê, a nastêpnie rozpoznawaæ obiekty z obrazów 2D zawierajḟcych do okoġo 1000 obiektów, a liczba ta stale ro¶nie. Jest jednak ograniczony do baz danych obrazów, w których rozmiar obiektów lub typowe sceny sḟ podobne. W otwartych ¶rodowiskach, takich jak zadania wyszukiwania w domach, róṡnice w o¶wietleniu, punkcie widzenia lub okluzji nadal stanowiḟ wyzwanie. Podczas korzystania z obrazów 3D, na przykġad ze skanerami laserowymi lub obrazami gġêbi, ksztaġt obiektów moṡna uzyskaæ i wykorzystaæ do sterowania procesami przemysġowymi, takimi jak chwytanie robotów lub malowanie natryskowe. Moṡna wykonywaæ ¶ledzenie obiektów lub punktów zainteresowania w dġuṡszych sekwencjach wideo w czasie rzeczywistym przy wystarczajḟcej teksturze. Ustanowiono zasady wykorzystania informacji o obrazie oraz skutecznego przewidywania i wyszukiwania w kolejnych obrazach, a takṡe dostêpne wizualne metody serwomechanizmu do sterowania ramionami robota. Wydajno¶æ i niezawodno¶æ w czasie rzeczywistym osiḟgniête dziêki dzisiejszym komputerowym technikom wizyjnym do ¶ledzenia rêki, ¶ledzenia ciaġa i ciaġa, rozpoznawania twarzy i tak dalej, prowadzḟ do nowej jako¶ci opartej na wizji interakcji czġowiek-maszyna. Omówili¶my kilka wyzwañ w tej nowej dziedzinie, która ġḟczy obszary wizji komputerowej (CV) i interakcji czġowiek-komputer (HCI). W ciḟgu ostatnich lat powstaġo kilka nowych serii warsztatów, takich jak CV4HCI i CV zorientowane na czġowieka. Oczekujemy, ṡe to maġṡeñstwo zapewni dalsze owocne wpġywy w terenie, biorḟc pod uwagê dwie perspektywy: jak zaprojektowaæ systemy CV dla uṡytkowników i jak skutecznie wġḟczyæ uṡytkownika w wizualnḟ pêtlê przetwarzania. Jednym z wyzwañ byġa lokalizacja: biorḟc pod uwagê jakḟkolwiek sytuacjê podczas interakcji, kiedy i jakḟ informacjḟ uṡytkownik powinien siê przejmowaæ? To samo pytanie moṡna zadaæ dla systemu wizyjnego. Nie wszystkie informacje sḟ waṡne i nie wszystkie wyniki wykrywania sḟ prawidġowe. Pojêcie kontekstu zapewnia pojêcie globalnej spójno¶ci z jednej strony, a ramy znaczenia z drugiej strony. Nawet przy do¶æ wyrafinowanych i wydajnych technikach rozpoznawania kontekst zachowa swojḟ rolê, gdy mówimy o komputerowych systemach wizyjnych, które muszḟ dziaġaæ w rzeczywistych ¶rodowiskach. Systemy wizyjne muszḟ ġḟczyæ techniki do celów aplikacji. To jest sedno CV jako dyscypliny inṡynierskiej. Jednak przez lata udowodniono, ṡe trudno jest zdefiniowaæ ogólne architektury integrujḟce wszystkie komponenty potrzebne do róṡnych aplikacji. Niektóre pproache pokazaġy swojḟ przydatno¶æ w udanych projektach europejskich obejmujḟcych wielu partnerów (np. ActIPret, VAMPIRE lub CogX). Rzeczywisty postêp jest trudny do osiḟgniêcia po stronie teoretycznej i musi byæ udowodniony praktycznḟ realizacjḟ systemów (Kragic i Vincze 2009). Chociaṡ wyniki te wskazujḟ postêp w tej dziedzinie, czeka nas kilka wyzwañ. Na przykġad praca nad rozpoznawaniem klas obiektów jest obecnie ograniczona do kilku istotnych klas, takich jak koġa lub samoloty; zdolno¶æ wykrywania punktów chwytania na dowolnych obiektach musi zostaæ rozszerzona z lokalizacji pġaskich do peġnych obiektów 3D; i nie moṡna jeszcze wydedukowaæ funkcji obiektu z obrazowania jego ksztaġtu. Niemniej jednak istnieje nadzieja, ṡe widzenie komputerowe bêdzie coraz bardziej integrowane z innymi metodami sztucznej inteligencji w celu tworzenia bardziej kompletnych systemów.