Net Logo : Zachowania
Zachowanie
1. Kwestia perspektywy: musimy odróŋniæ perspektywę obserwatora od perspektywy samego agenta. Perspektywa obserwatora musi byæ traktowana jako wewnętrzny mechanizm leŋący u podstaw opisanego zachowania.
2. Problem zachowania w stosunku do mechanizmu: zachowanie agenta zawsze jest wynikiem interakcji system-ķrodowisko. Nie moŋna tego wyjaķniæ tylko na podstawie mechanizmów wewnętrznych
3. Problem zģoŋonoķci: zģoŋonoķæ, którą obserwujemy w danym zachowaniu, nie zawsze wskazuje na zģoŋonoķæ mechanizmów leŋących u podstaw. -
(Rolf Pfeifer i Christian Scheier)
Co to jest zachowanie?
Sposób, w jaki zachowuje się agent, jest często uŋywany do odróŋnienia ich i odróŋnienia tego, kim i czm są, zarówno od zwierząt, ludzi, jak i od sztucznych. Zachowanie moŋna równieŋ powiązaæ z grupami agentów, a nie tylko z jednym agentem. Na przykģad ludzkie zachowania kulturowe odnoszą się do zachowania, które jest związane z okreķlonym narodem, ludem lub grupą spoģeczną, i róŋni się od zachowania indywidualnego czģowieka lub ludzkiego ciaģa. Zachowanie ma równieŋ waŋną rolę do odegrania w przetrwaniu róŋnych gatunków i podgatunków. Sugerowano na przykģad, ŋe muzyka i sztuka stanowiģy częķæ zestawu zachowaņ prezentowanych przez nasz wģasny gatunek, który zapewniģ nam ewolucyjną przewagę nad neandertalczykami. Wczeķniej rozmawialiķmy o róŋnych aspektach dotyczących zachowaņ ucieleķnionych, usytuowanych agentów, takich jak to, jak moŋna scharakteryzowaæ zachowanie agenta z perspektywy projektu pod kątem jego ruchu w otoczeniu i jak agenci wykazują zakres zachowaņ od reaktywnych do poznawczych. Nie dostarczyliķmy jednak bardziej konkretnej definicji tego, czym jest zachowanie. Z perspektywy projektowania ucieleķnionych, usytuowanych agentów, zachowanie moŋna zdefiniowaæ w następujący sposób. Szczególnym zachowaniem ucieleķnionego, usytuowanego agenta jest seria dziaģaņ wykonywanych podczas interakcji ze ķrodowiskiem. Okreķlona kolejnoķæ lub sposób wykonywania ruchów akcji i ogólny wynik, który pojawia się w wyniku dziaģaņ, okreķla rodzaj zachowania. Moŋemy zdefiniowaæ dziaģanie jako serię ruchów wykonywanych przez agenta w odniesieniu do konkretnego wyniku, albo przez wolę (dla dziaģaņ poznawczych), albo przez instynkt (dla dziaģaņ opartych na reaktywnoķci). W tej definicji ruch jest traktowany jako podstawowa częķæ komponentów, które charakteryzują kaŋdy typ zachowania - innymi sģowy, dziaģania i reakcje, które agent wykonuje, gdy wykonuje zachowanie. Rozróŋnienie między ruchem a dziaģaniem polega na tym, ŋe dziaģanie obejmuje jeden lub więcej ruchów wykonywanych przez agenta, a takŋe, ŋe istnieje okreķlony wynik, który pojawia się w wyniku dziaģania. Na przykģad, czynnik ludzki moŋe chcieæ wykonaæ dziaģanie wģączania ķwiatģa. Efektem dziaģania jest wģączenie ķwiatģa. Ta czynnoķæ wymaga wykonania szeregu ruchów, takich jak podniesienie ręki do przeģącznika ķwiateģ, przesunięcie okreķlonego palca z ręki, a następnie uŋycie tego palca do dotknięcia górnej częķci przeģącznika, a następnie naciķnięcie przycisku w dóģ, aŋ do przeģączenia porusza się. Rozróŋnienie między dziaģaniem a okreķlonym zachowaniem polega na tym, ŋe zachowanie obejmuje jedną lub więcej czynnoķci wykonywanych przez agenta w okreķlonej kolejnoķci lub sposobie. Na przykģad, agent moŋe preferowaæ zachowanie oszczędzające energię poprzez wģączanie ķwiateģ tylko wtedy, gdy jest to konieczne (jest to przykģad zachowania poznawczego, poniewaŋ wymaga ķwiadomego wyboru). Inny agent zawsze moŋe wģączyæ ķwiatģo poprzez przyzwyczajenie, gdy wchodzi do pokoju (jest to przykģad zachowania gģównie reaktywnego). Sposób zachowania jest sposobem, w jaki agent dziaģa w danej sytuacji lub zestawie sytuacji. Sytuacja jest okreķlona przez warunki ķrodowiskowe, wģasne okolicznoķci i wiedzę, którą agent obecnie ma do dyspozycji. Jeķli agent ma niewystarczającą wiedzę do danej sytuacji, moŋe zdecydowaæ się na poszukiwanie dalszej wiedzy na temat sytuacji. Zachowania mogą skģadaæ się z sub-zachowaņ. Poszukiwanie dalszej wiedzy samo w sobie jest zachowaniem, na przykģad, i moŋe byæ skģadową pierwotnego zachowania. Istnieją równieŋ róŋne aspekty zachowania, w tym następujące: wykrywanie i ruch (koordynacja sensomotoryczna); rozpoznanie obecnej sytuacji (klasyfikacja); podejmowanie decyzji (wybór odpowiedniej odpowiedzi); wydajnoķæ (wykonanie odpowiedzi). Zachowania sięgają od w peģni ķwiadomego (poznawczego) do nieķwiadomego (reaktywnego), od jawnego (zrobione w otwarty sposób) do ukrycia (zrobione w tajemnicy) i od dobrowolnego (agent dziaģa zgodnie z wģasną wolną wolą) do mimowolnego (zrobionego bez ķwiadomej kontroli lub zrobionego wbrew woli agenta). Termin "zachowanie" ma równieŋ róŋne znaczenia w zaleŋnoķci od kontekstu. Powyŋsza definicja ma zastosowanie, gdy termin jest uŋywany w odniesieniu do dziaģaņ czģowieka lub zwierzęcia, ale ma równieŋ zastosowanie w opisywaniu dziaģaņ systemu mechanicznego lub zģoŋonych dziaģaņ chaotycznego systemu, jeķli zorientowany na agenta rozpatrywana jest perspektywa (tutaj są ludzie, zwierzęta, systemy mechaniczne lub zģoŋone systemy). Jednak w rzeczywistoķci wirtualnej i aplikacjach multimedialnych termin ten moŋe byæ czasem uŋywany jako synonim animacji komputerowej. W wiarygodnych czynnikach i sztucznych polach ŋycia, zachowanie jest uŋywane "w odniesieniu do improwizacji i ŋycie-podobne dziaģania o charakterze autonomicznym". Często antropomorficznie przypisujemy ludzkie cechy behawioralne za pomocą dziaģania komputera, gdy mówimy, ŋe system komputerowy lub program komputerowy zachowuje się w okreķlony sposób w oparciu o reakcje na naszą interakcję z systemem lub programem. Podobnie często (zazwyczaj bģędnie) przypisujemy ludzkie zachowanie behawioralne zwierzętom i obiektom nieoŋywionym, takim jak samochody.
Ķrodki reaktywne a czynniki poznawcze
W tej częķci będziemy dalej badaæ waŋne rozróŋnienie pomiędzy zachowaniami reaktywnymi i poznawczymi, które po raz pierwszy zostaģy podkreķlone w poprzednim rozdziale. Czynniki moŋna scharakteryzowaæ, gdy znajdują się na kontinuum, jak pokazano na rysunku.
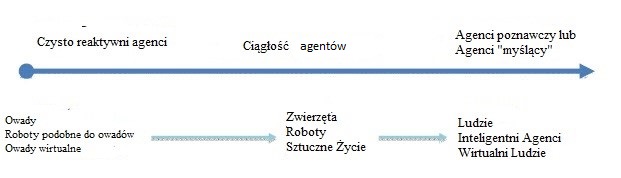
Kontinuum to sięga od czysto reaktywnych ķrodków, które nie wykazują zdolnoķci poznawczych (takich jak mrówki i termity), do czynników, które wykazują zachowania poznawcze lub mają zdolnoķæ myķlenia. Tabela przedstawia róŋnice między dwoma typami agentów.
Agenci Reaktywni : Agenci Poznawczy
• Uŋyj prostych zachowaņ. : • Uŋywaj zģoŋonych zachowaņ.
• Mają maģą zģoŋonoķæ : • Mieæ duŋą zģoŋonoķæ.
• Nie są w stanie przewidzieæ przyszģoķci. : • Przewiduj, co się wydarzy
• Nie ma celów : • Mieæ okreķlone cele.
• Nie planuj ani nie koordynuj między sobą. : • Twórz plany i koordynuj ze sobą.
• Nie reprezentuj ķrodowiska. : • Mapuj swoje ķrodowisko (tzn. Buduj wewnętrznie reprezentacje ich ķrodowiska).
• Nie adaptuj się i nie ucz się.: • Pokazuj wyuczone zachowanie.
• Moŋe wspóģpracowaæ w celu rozwiązania zģoŋonych problemów. : • Potrafi rozwiązywaæ zģoŋone problemy zarówno poprzez pracę razem i dziaģając indywidualnie.
W rzeczywistoķci, wiele czynników przejawia zarówno zachowania reaktywne, jak i poznawcze w róŋnym stopniu, a rozróŋnienie między reaktywnym a poznawczym moŋe byæ arbitralne. Porównując zdolnoķci czynników reaktywnych z czynnikami poznawczymi wymienionymi w Tabeli 1, jasne jest, ŋe czynniki reaktywne są bardzo ograniczone w tym, co mogą zrobiæ, poniewaŋ nie mają zdolnoķci planowania, koordynacji między sobą lub ustalania i zrozumienia konkretnych celów; po prostu reagują na zdarzenia, kiedy się pojawią. Nie wyklucza to ich roli w tworzeniu inteligentnego zachowania. Reaktywna szkoģa myķli polega na tym, ŋe agenci nie muszą byæ indywidualnie inteligentni. Mogą jednak wspólnie wspóģpracowaæ w celu rozwiązania zģoŋonych problemów. Ich moc pochodzi z potęgi wielu - na przykģad owady oparte na koloniach, takie jak mrówki i termity, mają zdolnoķæ wykonywania zģoŋonych zadaņ, takich jak znajdowanie i komunikowanie miejsca pobytu ŋywnoķci, walka z naježdžcami i budowanie zģoŋonych struktur. Ale robią to na poziomie populacji, a nie na poziomie indywidualnym, uŋywając bardzo sztywnych powtarzalnych zachowaņ. W przeciwieņstwie do tego, poznawcza szkoģa myķli dąŋy do zbudowania agentów, które w pewien sposób wykazują inteligencję. W tym podejķciu poszczególni agenci mają cele i mogą opracowaæ plany, jak je osiągnąæ. Korzystają z bardziej wyrafinowanych mechanizmów komunikacji i celowo koordynują swoje dziaģania. Mapują takŋe swoje ķrodowisko w pewien sposób, korzystając z wewnętrznej reprezentacji lub bazy wiedzy, którą mogą odnosiæ i aktualizowaæ poprzez mechanizmy uczenia się, aby pomóc w kierowaniu ich decyzjami i dziaģaniami. W rezultacie są znacznie bardziej elastyczne w zachowaniu w porównaniu z czynnikami reaktywnymi. W Sztucznej Inteligencji podejķcie behawioralne do budowania inteligentnych systemów nazywa się sztuczną inteligencją behawioralną (BBAI). W tym podejķciu, po raz pierwszy zaproponowanym przez Rodneya Brooksa, inteligencja zostaje rozģoŋona na zbiór niezaleŋnych, póģ-autonomicznych moduģów. Moduģy te byģy początkowo pomyķlane jako dziaģające na oddzielnym urządzeniu z wģasnymi wątkami przetwarzania i mogą byæ uwaŋane za oddzielne czynniki. Brooks zalecaģ reaktywne podejķcie do sztucznej inteligencji i uŋywaģ skoņczonych maszyn stanów do implementacji moduģów zachowania. Te skoņczone maszyny stanu nie mają konwencjonalnej pamięci i nie zapewniają bezpoķrednio wyŋszych funkcji poznawczych, takich jak uczenie się i planowanie. Okreķlają zachowanie w sposób reaktywny, przy czym agent reaguje bezpoķrednio na ķrodowisko, zamiast budowaæ jego reprezentację w pewien sposób, taki jak mapa. Oparte na zachowaniu podejķcie do sztucznej inteligencji staģo się popularne w robotyce, ale znajduje równieŋ inne zastosowania w dziedzinie animacji komputerowej i inteligentnych agentów wirtualnych.
Powstanie, samoorganizacja, adaptacja i ewolucja
W tej sekcji omówiono kilka cech autonomicznych czynników waŋnych z punktu widzenia behawioralnego - emergentne, samoorganizujące się, adaptacyjne i ewoluujące zachowania. Zģoŋony system to system skģadający się z wielu komponentów, które, gdy wchodzą ze sobą w interakcje, wytwarzają aktywnoķæ, która jest większa niŋ to, co jest moŋliwe w przypadku pojedynczych komponentów. System wieloagentowy to zģoŋony system, jeķli agenci wykazują zachowawcze zachowania. Pojawienie się w zģoŋonym systemie jest pojawieniem się nowej wģaķciwoķci wyŋszego poziomu, która nie jest prostym liniowym agregatem istniejących wģaķciwoķci. Na przykģad masa samolotu nie jest wyģaniającą się wģasnoķcią, poniewaŋ jest to po prostu suma masy poszczególnych elementów samolotu. Z drugiej strony umiejętnoķæ latania jest wyģaniającą się wģasnoķcią, poniewaŋ wģaķciwoķæ ta znika, gdy częķci samolotu zostają zdemontowane. Wschodzące wģaķciwoķci są równieŋ powszechne w ŋyciu codziennym - na przykģad zachowanie kulturowe u ludzi, ŋerowanie pokarmu u mrówek i budowanie kopców w termitach. Wraŋliwe zachowanie to pojawienie się zachowania systemu wieloagentowego, którego wczeķniej nie zaobserwowano i które nie jest wynikiem prostej liniowej kombinacji istniejących zachowaņ agentów. Niektórzy uwaŋają, ŋe inteligencja jest wyģaniającą się wģasnoķcią, wynikiem interakcji agent-agent i agent-ķrodowisko reaktywnych, ucieleķnionych, usytuowanych agentów. Jeķli tak jest, to zapewnia alternatywną ķcieŋkę do tworzenia inteligentnych zachowaņ - zamiast budowaæ czynniki poznawcze poprzez jawne programowanie wyŋszych zdolnoķci poznawczych, takich jak rozumowanie i podejmowanie decyzji, alternatywą jest zbudowanie agenta o zdolnoķciach reaktywnych, takich jak rozpoznawanie wzorców i uczenie się, a to prowadzi do inteligentnego zachowania. Podejķcie to jednak nie przyniosģo jeszcze efektów, poniewaŋ mechanizmy stojące za rozpoznawaniem wzorców i zdolnoķciami uczenia się przez ludzi nie zostaģy jeszcze w peģni zrozumiane i nie dysponujemy wystarczająco zaawansowanymi algorytmami w tym obszarze, aby agent mógģ poznaæ sposób, w jaki ludzie to robią, na przykģad takie jak zdolnoķæ maģego dziecka do nabycia języka. Jednak bardziej tradycyjna droga do sztucznej inteligencji - do projektowania agentów o wyražnych zdolnoķciach poznawczych wyŋszego poziomu - równieŋ nie przyniosģa efektów. Mówi się, ŋe system samoorganizuje się, gdy wzorzec lub struktura w systemie pojawiają się spontanicznie, a nie w wyniku zewnętrznych nacisków. System wieloagentowy wyķwietla samoorganizujące zachowanie w wyniku zastosowania reguģ lokalnych, gdy wzór lub struktura powstaje w wyniku interakcji, której nie spowodowaģ zewnętrzny agent. Systemy samoorganizujące się zazwyczaj wyķwietlają nowe wģaķciwoķci. Wiele naturalnych systemów wykazuje zachowania zapobiegawcze. Oto kilka przykģadów: roje ptaków i ryb oraz stada zwierząt, takich jak bydģo, owce, bawoģy i zebry (biologia); tworzenie i struktura planet, gwiazd i galaktyk (z dziedziny astrofizyki); formacje chmurowe i cyklony (meteorologia); struktura powierzchni ziemi (geofizyka); reakcje chemiczne (chemia); autonomiczne ruchy robotów (robotyka); sieci spoģecznoķciowe (Internet); sieci komputerowe i ruchome (technologia); naturalnie występujące fraktalne wzory, takie jak paprocie, pģatki ķniegu, struktury krystaliczne, krajobrazy, fiordy (ķwiat naturalny); wzory występujące na futrze, skrzydģach motyla, skórze owadów i naczyniach krwionoķnych w ciele (biologia); wzrost populacji (biologia); kolektywne zachowanie kolonii owadów, takich jak termity i mrówki (biologia); mutacja i selekcja (ewolucja); i konkurencja, gieģdy i rynki finansowe (ekonomia). Biblioteka modeli NetLogo zawiera wiele modeli symulujących samoorganizację. Na przykģad model Flocking naķladuje zachowanie stada u ptaków - po uruchomieniu modelu przez jakiķ czas, ŋóģwie będą się samoorganizowaæ w kilka stad, w których ptaki kierują się w podobnym kierunku. Dzieje się tak pomimo zachowania poszczególnych agentów skģadającego się tylko z kilku lokalnych reguģ. W modelu Fireflies, agenci ŋóģwia są w stanie zsynchronizowaæ miganie przy uŋyciu tylko interakcji między sąsiednimi agentami; ponownie tylko lokalne reguģy okreķlają zachowanie poszczególnych agentów. Model termitów i model maszyny stanowej symulują zachowanie termitów. Po uruchomieniu tych modeli przez pewien czas ģatki "zrębków drewnianych" zostaną umieszczone w kilku stosach. Trzy zrzuty ekranu modelu przykģadowego maszyny stanu są pokazane na rysunku poniŋeh.
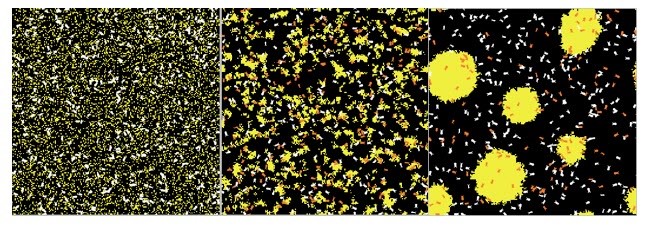
Lewy obraz pokazuje ķrodowisko na początku symulacji (liczba tyknięæ = 0). Pokazuje agentów umieszczonych losowo w caģym ķrodowisku, z ŋóģtymi plamami przedstawiającymi zrębki i biaģe ksztaģty reprezentujące termity. Ķrodkowe i prawe obrazy pokazują otoczenie po 5000 i 50 000 tyknięæ. Pomaraņczowe ksztaģty przedstawiają termity, które niosą drewniane wióry, a biaģe ksztaģtują te, które nie są. Te dwa obrazy pokazują system ķrodków termitów, wiórów drzewnych i ķrodowiska, które stopniowo samoorganizują się, dzięki czemu zrębki koņczą się w kilku stosach. Kod dla przykģadowego modelu jest pokazany poniŋej:
turtles-own [
task ;;nazwa procedury (ciąg) ŋóģw będzie biegaģ podczas tego tiku
steps ;; …chyba ŋe liczba ta jest większa od zera, w którym
;; w przypadku tego tyknięcia ŋóģw porusza się do przodu 1
]
to setup
clear-all
set-default-shape turtles "bug"
;; losowo rozprowadzaæ zrębki
ask patches [
if random-float 100 < density
[ set pcolor yellow ]
]
;; losowo rozprowadzaj termity
crt number [
set color white
setxy random-xcor random-ycor
set task "search-for-chip"
set size 5 ;; easier to see
]
end
to go
ask turtles
[ ifelse steps > 0
[ set steps steps - 1 ]
[ run task
wiggle ]
fd 1 ]
tick
end
to wiggle ;; procedura ŋóģwia
rt random 50
lt random 50
end
to search-for-chip ;; procedura ŋóģwia - "podnosi chi", zmieniając kolor na pomaraņczowy
if pcolor = yellow
[ set pcolor black
set color orange
set steps 20
set task "find-new-pile" ]
end
to find-new-pile ;; procedura ŋóģwia - poszukaj ŋóģtej ģatki
if pcolor = yellow
[ set task "put-down-chip" ]
end
to put-down-chip ;; procedura ŋóģwia - wyszukuje puste miejsce i upuszcza chip
if pcolor = black
[ set pcolor yellow
set color white
set steps 20
set task "get-away" ]
end
to get-away ;; procedura ŋóģwia - wyjdž z ŋóģtego stosu
if pcolor = black
[ set task "search-for-chip" ]
end
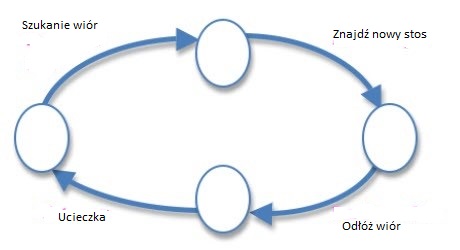
Procedura setup losowo rozprowadza ŋóģte ķrodki pģatkowe i ķrodki termitów w caģym ķrodowisku. Polecenie ask w procedurze go okreķla zachowanie agentów termitów. Zastosowane podejķcie polega na reprezentowaniu zachowania jako skoņczonej maszyny stanu skģadającej się z czterech stanów z inną akcją lub zadaniem wykonywanym przez agenta, zapewniającym przejķcie do następnego stanu. Te zadania to: poszukiwanie wiórów drewnianych; znalezienie nowego stosu; odkģadanie kawaģka drewna; i wydostanie się ze stosu. Uproszczona skoņczona maszyna stanów dla tego modelu zostaģa przedstawiona na rysunku
Mówi się, ŋe system w ogólnym sensie ewoluuje, jeķli dostosowuje się lub zmienia w czasie, zwykle od prostej do bardziej zģoŋonej postaci. Termin "ewolucja" ma róŋne znaczenia w róŋnych kontekstach, co moŋe powodowaæ pewne zamieszanie. Bardziej szczegóģowe znaczenie odnosi się do terminu ewolucji do teorii ewolucji Darwina - mówi się, ŋe gatunek ewoluuje, gdy następuje zmiana w DNA jego populacji z pokolenia na pokolenie. Zmiana jest przekazywana potomstwu poprzez reprodukcję. Zmiany te mogą byæ niewielkie, ale po wielu pokoleniach poģączone efekty mogą prowadziæ do istotnych zmian w organizmach. Aby odróŋniæ róŋne znaczenia terminu "ewolucja", moŋemy zdefiniowaæ zachowanie adaptacyjne i ewoluujące osobno w następujący sposób. Agent wykazuje zachowania adaptacyjne, gdy ma zdolnoķæ zmiany swojego zachowania w jakiķ sposób w odpowiedzi na zmiany w ķrodowisku. Jeķli zmienia się ķrodowisko, zachowanie dobrze dostosowane do poprzedniego ķrodowiska moŋe juŋ nie byæ tak dobrze dostosowane; Na przykģad, bardziej przejrzyste, pokazano, ŋe niektóre zachowania dostosowane do warunków labiryntu Hampton Court Palace nie są tak dobrze dopasowane do ķrodowiska labiryntu Chevening House i na odwrót. Z drugiej strony ewolucja zachowaņ występuje w populacji, gdy jej geneza zmieniģa się z pokolenia na pokolenie. Ewolucja w populacji jest napędzana przez dwa gģówne mechanizmy - selekcję naturalną i dryf genetyczny. Selekcja naturalna to proces, w którym osoby z dziedzicznymi cechami, które są pomocne w rozmnaŋaniu i przetrwaniu w ķrodowisku, staną się bardziej powszechne w populacji, podczas gdy szkodliwe cechy staną się rzadsze. Dryf genetyczny jest zmianą względnej częstotliwoķci dziedzicznych cech ze względu na rolę przypadku w okreķleniu, które osobniki przeŋywają i rozmnaŋają się. Ewolucja czģowieka i gatunków zwierząt ma miejsce przez setki tysięcy lat, a czasem miliony. Aby przedstawiæ te skale czasowe w perspektywie i aby pokazaæ, jak maģe zmiany mogą mieæ epokowe efekty, moŋemy posģuŋyæ się przykģadem Góry Himalajskiej. Linia uskoków rozciąga się od jednego koņca Himalajów do drugiego, poniewaŋ znajduje się na granicy między tektonicznymi pģytami euroazjatyckimi i indoeurlandzkimi, a w konsekwencji jest jednym z najbardziej aktywnych sejsmicznie regionów na ķwiecie. Badania wykazaģy, ŋe Himalaje wciąŋ rosną w tempie okoģo 1 cm rocznie. Chociaŋ wzrost o 1 cm rocznie moŋe wydawaæ się nieistotny, jeķli zaplanujemy tak daleko w przyszģoķci, efekt akumulacyjny moŋe byæ niezwykģy. Po 100 latach wzroķnie tylko o metr; po 1000 latach, 10 m; po 10000 latach, zaledwie 100 m, nadal nie jest szczególnie znaczący w porównaniu do ogólnej ķredniej wysokoķci gór. Jednak po 100 000 lat wzroķnie o 1 km - to ponad 10% obecnej wysokoķci Mt. Everest, który wynosi 8 848 metrów. Po milionie lat wzrost wyniesie 10 km, co więcej niŋ podwaja obecną wysokoķæ Mt. Everest. Proces, który powoduje niewielkie zmiany z roku na rok, o ile jest staģy, spowoduje dramatyczne zmiany w ciągu miliona lat. Mt. Everest stale roķnie od miliona lat, jest oczywiķcie hipotetyczną sytuacją, poniewaŋ istnieją inne siģy dziaģające, takie jak erozja i ruch pģyt tektonicznych. W przeciwieņstwie do tego wzrost mórz, nawet tak niewielkiej jak 1 cm na rok, moŋe spowodowaæ dramatyczne zmiany w znacznie krótszym czasie. Dryf kontynentalny spowodowaģ równieŋ znaczącą zmianę w krajobrazie ķwiata. Odlegģoķæ lotu między Sydney, Australia i Wellington w Nowej Zelandii wynosi na przykģad 2220 km. Jeķli Nowa Zelandia oddalaģa się od Australii w tempie 1 cm rocznie, to miaģo to miejsce w okresie 222 milionów lat. Bez względu na to, jak dobrze nadaje się dany gatunek do przetrwania w obecnym ķrodowisku, będzie potrzebowaæ dostosowaæ się do zmian na poziomie epoki, jeķli ma przetrwaæ bardzo dģugo.
Problem z odniesieniem
Waŋne jest, aby nie przypisywaæ bģędnych wyjaķnieņ z obserwacji mechanizmom stojącym za zachowaniem ucieleķnionego przedstawiciela znajdującego się w otoczeniu. Ramy odniesienia wskazują na róŋnicę między perspektywą obserwatora a perspektywą obserwowanego ze względu na ich róŋne przykģady wykonania. Kaŋdy prawdziwy agent jest wyjątkowy ze swoim ciaģem i mózgiem, z unikalnym zestawem moŋliwoķci wykrywania i ma wyjątkową lokalizację w ķrodowisku (poniewaŋ w prawdziwych ķrodowiskach ŋadne dwa ciaģa nie mogą zajmowaæ tej samej przestrzeni w tym samym czasie) . Dlatego kaŋdy agent ma unikalną perspektywę swojego otoczenia; w związku z tym perspektywa czynnika wykonującego obserwację będzie bardzo odmienna od perspektywy obserwowanego czynnika. Rozbieŋnoķci w ramach odniesienia będą najbardziej wyražne między gatunkami o znacznie róŋnych przykģadach wykonania, na przykģad między ludžmi a owadami. Często ludzie jako obserwatorzy popeģniają bģąd przypisywania zdolnoķci podobnych do ludzkich przy opisywaniu mechanizmów stojących za zachowaniem, które jest obserwowane. Na przykģad magnetyczne kopce termitów w póģnocnej Australii wszystkie stoją na póģnoc i z daleka wyglądają jak nagrobki na cmentarzu. W tym przypadku ģatwo jest popeģniæ bģąd, ŋe zostaģy one stworzone zgodnie z pewnym centralnym planem, ale kopce termitów są wynikiem wielu pojedynczych czynników stosujących proste zachowanie reaktywne. Rolf Pfeifer i Christian Scheier twierdzą, ŋe istnieją trzy gģówne aspekty ram odniesienia: kwestia perspektywy; kwestia zachowania w stosunku do mechanizmu; i problem zģoŋonoķci. Kwestia perspektywy dotyczy potrzeby rozróŋnienia perspektyw obserwatora od obserwowanego, a nie przypisywania opisów mechanizmów z punktu widzenia obserwatora. Problem zachowania względem mechanizmu stwierdza, ŋe zachowanie agenta nie jest tylko wynikiem samych mechanizmów wewnętrznych; interakcja między agentem a ķrodowiskiem równieŋ ma waŋną rolę do odegrania. Problem zģoŋonoķci wskazuje, ŋe zģoŋone zachowania niekoniecznie są wynikiem zģoŋonych mechanizmów leŋących u podstaw. Rolf Pfeifer i Christian Scheier uŋywają eksperymentu myķlowego mrówki na plaŋy, zaproponowanej przez Simona po raz pierwszy, aby zilustrowaæ te problemy. Podobny scenariusz przedstawiono w Eksperymencie Myķlowym 1.
Eksperyment Myķlowy 1 : Mrówka na plaŋy
Wyobraž sobie mrówkę powracającą do gniazda na skraju plaŋy w pobliŋu lasu. Napotyka przeszkody po drodze w lesie, takie jak dģuga trawa, opadģe liķcie i gaģęzie, a następnie przyspiesza po dotarciu do plaŋy, która jest blisko gniazda. Podąŋa specyficznym szlakiem wzdģuŋ plaŋy i napotyka kolejne przeszkody, takie jak maģe skaģy, drewno, suszone wodorosty i róŋne ķmieci, takie jak odrzucone plastikowe butelki i dŋety wysypane z morza. Mrówka zdaje się podąŋaæ okreķloną ķcieŋką i reagowaæ na obecnoķæ przeszkód, obracając się w pewnych kierunkach, jakby prowadzona przez mentalną mapę terenu. Większoķæ mrówek podąŋających za oryginalną mrówką równieŋ podróŋuje w ten sam sposób. W koņcu wszystkie mrówki wracają do gniazda, nawet te, które wydawaģy się zagubione po drodze. Chģopiec idący po plaŋy zauwaŋa szlak mrówek. Decyduje się zablokowaæ ich szlak, budując na ich drodze niewielki stos piasku. Pierwsza mrówka, która dociera do nowej przeszkody, zdaje się od razu rozpoznawaæ, ŋe na jej drodze jest coķ nowego, czego wczeķniej nie byģo. Powoli skręca w prawo, a potem w lewo, jakby szukaģ ķcieŋki wokóģ przeszkody. Pojawiają się równieŋ inne mrówki i razem wydają się koordynowaæ polowanie na ķcieŋkę wokóģ przeszkody. W koņcu mrówki są w stanie znaležæ ķcieŋkę wokóģ przeszkody i wróciæ do gniazda. Po pewnym czasie wybierana jest jedna konkretna ķcieŋka bliska najkrótszej drodze powrotnej do gniazda. Z punktu widzenia obserwatora mrówki zdają się wykazywaæ inteligentne zachowanie. Po pierwsze, wydają się podąŋaæ konkretną zģoŋoną ķcieŋką i zdają się mieæ zdolnoķæ rozpoznawania punktów orientacyjnych po drodze. Po drugie, wydają się mieæ zdolnoķæ do przekazywania informacji między sobą. Na przykģad szybko przesyģają lokalizację nowego žródģa poŋywienia, dzięki czemu mogą ķledziæ inne mrówki. Po trzecie, mogą znaležæ najkrótszą ķcieŋkę między dwoma punktami. Po czwarte, radzą sobie ze zmieniającym się ķrodowiskiem. Jednak bģędem byģoby przypisywanie inteligencji zachowaniom mrówek. Badania wykazaģy, ŋe mrówki po prostu wykonują maģy zestaw reguģ w sposób reaktywny. Nie mają moŋliwoķci stworzenia mapy swojego ķrodowiska, którą inne mrówki mogą ķledziæ w póžniejszym czasie. Nie są ķwiadomi kontekstu swojej sytuacji, tak jak przeszli dģugą drogę, ale są teraz blisko gniazda, więc mogą przyspieszyæ, aby szybciej wróciæ. Nie mogą przekazywaæ informacji bezpoķrednio, z wyjątkiem zapachu chemicznego ustanowionego w ķrodowisku. Nie mogą omawiaæ i realizowaæ nowego planu ataku, gdy sprawy nie idą zgodnie z planem, a nie ma centralnego koordynatora. Naleŋy to porównaæ z umiejętnoķciami ludzkimi, takimi jak orientator uŋywający mapy do zlokalizowania flag kontrolnych umieszczonych przez kogoķ innego las lub plaŋa lub biegacz przyķpieszający po dģugim biegu, poniewaŋ wie, ŋe zbliŋa się koniec, lub myķliwy z plemienia powracającego do obozu, by powiedzieæ innym myķliwym, gdzie jest więcej zwierząt, lub szefowi plemię polecające grupie myķliwych, aby wyszli i szukali więcej jedzenia. Teraz wyobraž sobie, ŋe mrówka ma olbrzymie ciaģo, takie same jak ludzkie. Najprawdopodobniej zachowanie gigantycznej mrówki będzie zupeģnie inne niŋ w przypadku normalnej wielkoķci mrówki. Maģe obiekty, które byģy przeszkodami dla mrówki z normalnym rozmiarem ciaģa, nie stanowiģyby problemu. W rzeczywistoķci byģyby one zignorowane najprawdopodobniej, a gigantyczna mrówka powróciģaby bardziej bezpoķrednio z powrotem do gniazda. Inne obiekty, których normalnej wielkoķci mrówka nie byģaby ķwiadoma, ŋe są odrębne, takie jak drzewo, teraz stanowiģyby inny problem dla gigantycznej mrówki w stosunku do jej postępu przez teren. A teraz gigantyczna mrówka moŋe mieæ trudnoķci z wyczuwaniem chemicznego zapachu leŋącego na ziemi. Podsumowując, zmiana w ciele mrówki radykalnie zmienia perspektywę jego otoczenia.
Stygmatyzacja i inteligencja rozproszona
W opisanych wczeķniej modelach Termity i Mrówki widzieliķmy juŋ kilka przykģadów tego, jak zbiór agentów reaktywnych moŋe wykonywaæ zģoŋone zadania, które przekraczają moŋliwoķci któregokolwiek z agentów dziaģających pojedynczo. Z naszego wģasnego ukģadu odniesienia agenci wydają się zbiorowo wykazywaæ inteligentne zachowanie, chociaŋ jak wyjaķniono w poprzedniej sekcji, byģoby to niepoprawne. Modele NetLogo ilustrują, w jaki sposób mechanizmy stojące za takimi zachowaniami są bardzo proste - wystarczy kilka zasad okreķlających, w jaki sposób agenci powinni wchodziæ w interakcję ze ķrodowiskiem. Ta sekcja definiuje dwie waŋne koncepcje związane z inteligencją zbioru agentów: stygmatyzacją i inteligencją roju. Zbiór agentów przejawia stigmergię, gdy w jakiķ sposób korzystają ze ķrodowiska, a dzięki temu są w stanie koordynowaæ swoje dziaģania, aby tworzyæ zģoŋone struktury poprzez samoorganizację. Kluczową ideą stigmergii jest to, ŋe ķrodowisko moŋe mieæ istotny wpģyw na zachowanie agenta i na odwrót. Innymi sģowy, wpģyw między ķrodowiskiem a agentem jest dwukierunkowy. W prawdziwym ŋyciu stygmatyzacja występuje wķród owadów spoģecznych, takich jak termity, mrówki, pszczoģy i osy. Jak widzieliķmy w modelach Termites i Ants, stygmergia moŋe występowaæ pomiędzy bardzo prostymi agentami reaktywnymi, którzy mają jedynie zdolnoķæ reagowania w sposób lokalny na informacje lokalne. Te ķrodki nie mają inteligencji i wzajemnej ķwiadomoķci w tradycyjnym sensie, nie uŋywają pamięci i nie mają zdolnoķci planowania, kontroli lub bezpoķredniej komunikacji ze sobą. Mają jednak zdolnoķæ wykonywania zadaņ na wyŋszym poziomie w wyniku poģączonych dziaģaņ. Stygmatyzacja nie ogranicza się do przykģadów ŋycia naturalnego - Internet jest oczywistym przykģadem. Wiele systemów komputerowych równieŋ wykorzystuje stygmergię - na przykģad algorytm optymalizacji kolonii mrówek jest metodą znajdowania optymalnych ķcieŋek jako rozwiązaņ problemów. Niektóre systemy komputerowe korzystają ze wspóģuŋytkowanych struktur danych, które są zarządzane przez rozproszoną spoģecznoķæ klientów, która obsģuguje nową organizację. Jednym z przykģadów jest architektura tablicy uŋywana w systemach AI opracowanych po raz pierwszy w latach 80. XX wieku. Tablica korzysta z komunikacji za poķrednictwem pamięci wspóģdzielonej, która moŋe zostaæ napisana niezaleŋnie przez agenta, który badani są przez innych agentów tak, jak w prawdziwym ŋyciu tablica w pokoju wykģadowym. Tablice są obecnie uŋywane w grach wideo dla strzelanek FPS i jako ķrodek komunikacji między agentami w sieci komputerowej. Zbiór agentów wykazuje inteligencję roju, kiedy wykorzystuje wiedzę lokologiczną stygmergiczną do koordynowania swoich dziaģaņ i tworzenia zģoŋonych struktur poprzez samoorganizację. Mechanizmy stojące za inteligencją roju wykazywaną przez owady spoģeczne są solidne, poniewaŋ nie ma scentralizowanej kontroli. Są równieŋ bardzo skuteczne - co pokazuje wielkoķæ populacji ķwiatowej i odzwierciedlenie rozwiązaņ dla róŋnych gatunków. Kilka liczb podkreķla ten punkt. Naukowcy szacują, ŋe w dzisiejszym ķwiecie ŋyje okoģo 9000 gatunków mrówek i jedna czworonoŋna (1015) mrówek. Ponadto oszacowano, ŋe na przykģad kolonie mrówek harwester mają podobną liczbę neuronów co ludzki mózg. Ludzie równieŋ wykorzystują inteligencję roju na wiele sposobów. Internetowa encyklopedia, Wikipedia, to tylko jeden przykģad, który wynika ze zbiorowej inteligencji ludzi dziaģających indywidualnie przy minimalnej scentralizowanej kontroli. Serwisy spoģecznoķciowe za poķrednictwem stron internetowych to kolejne. Obydwa korzystają ze stygmergicznych informacji lokalnych umieszczonych w chmurze.
Implementowanie zachowania agentów Turtle w NetLogo
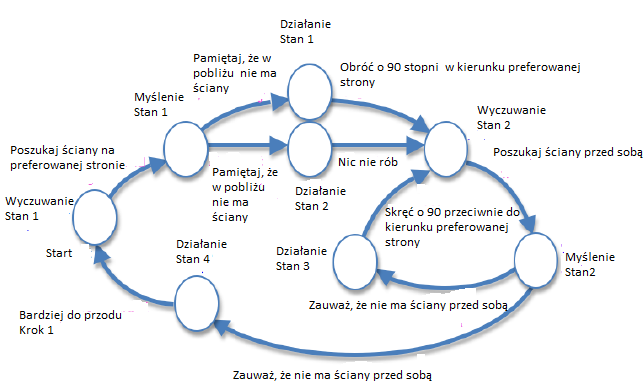
W NetLogo zachowanie agenta jest jawnie okreķlone przez polecenie ask. Definiuje to serię poleceņ wykonywanych przez agenta lub zestaw agentów, czyli procedurę, którą ma wykonaæ agent. Procedura w programie komputerowym to specyficzna seria poleceņ wykonywanych w precyzyjny sposób w celu wygenerowania poŋądany wynik. Musimy jednak zachowaæ ostroŋnoķæ, aby odróŋniæ faktyczne zachowanie agenta od mechaniki procedury NetLogo, która sģuŋy do definiowania zachowania. Celem większoķci poleceņ proceduralnych jest manipulowanie zmiennymi wewnętrznymi, w tym zmiennymi globalnymi i wģasnymi zmiennymi agenta. Ta ostatnia odzwierciedla stan agenta i moŋe byæ przedstawiona jako punkty w przestrzeni n-wymiarowej. Jednak ten stan jest niewystarczający, aby opisaæ zachowanie agenta. Jego zachowanie jest reprezentowane przez dziaģania wykonywane przez agenta, które powodują pewne zmiany w jego wģasnym stanie, w stan innych agentów lub w stan ķrodowiska. Rodzaj zmiany, która pojawia się, jest wynikiem zachowania. Niektóre przykģady zachowaņ, które juŋ widzieliķmy, prezentowane przez agentów w modelach Netlogo, to: poszukiwanie ŋerowania poŋywienia przez czynniki mrówkowe w modelu Mrówki, co skutkuje efektywnym zwrotem ŋywnoķci do zagnieŋdŋaæ się jako wynik; zachowanie budujące gniazda czynników termitów w modelach termitów i modeli maszynowych, w wyniku czego zrębki drewniane są umieszczane w stosach jako wynik; oraz zachowanie ķciany ŋóģwia w modelu Wall Po Przykģad, który powoduje, ŋe wszystkie ŋóģwie dziaģają na wszystkie ķciany w okreķlonym kierunku jako rezultat. Biblioteka modeli w NetLogo zawiera wiele innych przykģadów, w których agenci wykazują bardzo róŋne zachowania. W większoķci tych modeli podstawowe mechanizmy są spowodowane mechanicznym zastosowaniem kilku lokalnych reguģ, które definiują zachowanie. Na przykģad model Fireflies symuluje zdolnoķæ populacji ķwietlików uŋywających tylko lokalnych interakcji do synchronizowania ich flashowania jako wyniku. Model Heatbugs pokazuje, w jaki sposób moŋe powstaæ kilka rodzajów zachowaņ wynikających z zastosowania przez agentów prostych reguģ w celu utrzymania optymalnej temperatury wokóģ siebie. Model flokowania naķladuje zachowanie stada ptaków, co jest równieŋ podobne do zachowania szkolnego ryb i zachowaņ stadnych bydģa i owiec. Wynik ten osiąga się bez lidera, przy czym kaŋdy agent wykonuje ten sam zestaw zasad. Zwartoķæ kodu NetLogo w tych modelach potwierdza, ŋe zģoŋonoķæ zachowania niekoniecznie koreluje ze zģoŋonoķcią mechanizmów leŋących u podstaw. Zachowanie moŋna okreķliæ za pomocą róŋnych alternatyw, na przykģad za pomocą procedur i poleceņ NetLogo oraz automatów stanu skoņczonego. Ten ostatni jest abstrakcyjnym modelem zachowania z ograniczoną pamięcią wewnętrzną. W tym formacie zachowanie moŋna uznaæ za wynik przejķcia agenta z jednego stanu do drugiego - lub punktu w przestrzeni n-wymiarowej - poniewaŋ moŋe on byæ reprezentowany jako skierowany wykres ze stanami, przejķciami i dziaģaniami. Aby utworzyæ powiązanie między procedurą zaimplementowaną w języku programowania, takim jak NetLogo i skoņczone automaty stanów (a tym samym ponownie podkreķliæ analogię między zachowaniem a ruchem agenta znajdującego się w ķrodowisku), ķciana ķledząca zachowanie NetLogo Code powtórzony poniŋej zostaģ przeksztaģcony na równowaŋny skoņczony automat stanów na rysunku
to behaviour-wall-following
; klasyczne zachowanie "na ķcianie"
if not wall? (90 * direction) 1 and wall? (135 * direction) (sqrt 2)
[ rt 90 * direction ]
;;ķciana prosto: w razie potrzeby skręæ w lewo (czasami więcej niŋ raz)
while [wall? 0 1] [ lt 90 * direction]
;; pójķæ naprzód
fd 1
end
Kod zostaģ przekonwertowany na skoņczony automat stanów poprzez uporządkowanie stanów w trybie dziaģania "zmysģów - myķl-dziaģanie" zgodnie z opisem. Zwróæ uwagę, ŋe nie jesteķmy ograniczeni do dokonywania konwersji w ten szczególny sposób - moŋemy dowolnie organizowaæ paņstwa i przejķcia w dowolny sposób. W tym przykģadzie stany i przejķcia, jak pokazano na rysunku, zostaģy zorganizowane w celu odzwierciedlenia rodzaju dziaģania (wykrywanie, myķlenie lub dziaģanie), które agent ma wykonaæ podczas następnego przejķcia ze stanu. Ponadto, niezaleŋnie od wybranej ķcieŋki, kolejnoķæ przechodzenia stanów jest zawsze stanem odczuwającym, po którym następuje stan myķlenia, a następnie stan dziaģania. Następnie następuje kolejny stan odczuwania i tak dalej. Na przykģad zachowanie agenta rozpoczyna się od stanu wyczuwania (oznaczonego jako "Stan czuwania 1") na lewym ķrodku rysunku. Jest tylko na przejķciu poza tym stanem i uŋywany jest okreķlony sens jest widzeniem,
poniewaŋ wykonywana czynnoķæ polega na szukaniu ķciany po korzystnej stronie (to znaczy prawej stronie, gdy podąŋają za prawymi ķciankami, a lewej strony, jeķli podąŋają za ķcianami po lewej ręce). Następnie agent przechodzi do stanu myķlenia (Thinking State 1), który uwzględnia informacje, które otrzymaģ z tego, co wyczuģ. Myķląca czynnoķæ wykonywana przez agenta polega na odnotowaniu, czy w pobliŋu znajduje się ķciana. Jeķli nie byģo, to agent przechodzi do stanu dziaģania (Stan dziaģania 1), który polega na wykonaniu dziaģania obracania o 90 ° w kierunku preferowanej strony. Jeķli byģa ķciana, nie wykonuje się ŋadnej akcji (Stan dziaģania 2). Zauwaŋ, ŋe robienie niczego nie jest uwaŋane za dziaģanie, poniewaŋ jest ruchem o zerowej dģugoķci. Agent przejdzie następnie do nowego stanu odczuwania (Sensing State 2), który obejmuje wyczuwalne dziaģanie polegające na szukaniu ķciany przed sobą. Będzie on wielokrotnie przechodziæ przez stan roboczy (Stan dziaģania 3), obracając się o 90 ° w kierunku przeciwnym do preferowanej strony i z powrotem do Czuģy 2, dopóki nie będzie ķciany naprzód. Następnie przejdzie do stanu dziaģania (Stan dziaģania 4) przesunięcia o 1 stopieņ do przodu i do początku. Jak wskazano, metoda dziaģania "Rozwaŋaj - myķl - dziaģaj" ma ograniczenia w stosowaniu do modelowania prawdziwych, inteligentnych lub poznawczych zachowaņ, i zasugerowano alternatywne podejķcie obejmujące ucieleķnione, usytuowane poznanie. Pozostaje jednak pytanie o to, jak wdroŋyæ takie podejķcie, poniewaŋ skutecznie obejmuje ono wykrywanie, myķlenie i dziaģanie, wszystkie występujące jednoczeķnie, tj. Jednoczeķnie, a nie sekwencyjnie. Opracowano dwa modele NetLogo, aby zilustrowaæ jeden sposób, w jaki moŋna to symulowaæ. Pierwszy model (nazywany Wall Following Example 2) jest modyfikacją modelu Wall Po Example opisanego w poprzednim rozdziale. Zmodyfikowany interfejs udostępnia selektor, który pozwala uŋytkownikowi wybraæ standardowe zachowanie po ķcianie lub zmodyfikowany wariant. Zmodyfikowany kod jest wyķwietlany w kodzie NetLogo
turtles-own
[direction ;; 1 podąŋa za prawą ķcianą, -1 podąŋa za lewą ķcianą
way-is-clear? ;; reporter - prawda, jeķli nie ma przed sobą ķciany
checked-following-wall?] ;; reporter - prawda, jeķli zaznaczona po ķcianie
to go
if-else (behaviour = "Standard")
[ ask turtles [ walk-standard ]]
[ ask-concurrent turtles
[ walk-modified shuffle [1 2 3]]
]
tick
end
to walk-standard ;; standardowe zachowanie ŋóģwia
;; w razie potrzeby skręæ w prawo
if not wall? (90 * direction) and wall? (135 * direction)
[ rt 90 * direction ]
;; w razie potrzeby skręæ w lewo (czasami więcej niŋ raz)
while [wall? 0] [ lt 90 * direction ]
;; pójķæ do przodu
fd 1
end
to walk-modified [order] ;; zmodyfikowane zachowanie podczas chodzenia ŋóģwia
ifelse (choose-sub-behaviours = "Choose-all-in-random-order")
[
foreach order
[ if (? = 1) [ walk-modified-1 ]
if (? = 2) [ walk-modified-2 ]
if (? = 3) [ walk-modified-3 ]]
][
let ord one-of order
if (ord = 1) [ walk-modified-1 ]
if (ord = 2) [ walk-modified-2 ]
if (ord = 3) [ walk-modified-3 ]
]
end
to walk-modified-1 ;; zmodyfikowane zachowanie podchodzące do ŋóģwia 1
;; w razie potrzeby skręæ w prawo
if not wall? (90 * direction) and wall? (135 * direction)
[ rt 90 * direction ]
set checked-following-wall? true
end
to walk-modified-2 ;; zmodyfikowane zachowanie podchodzące do ŋóģwia 2
;; w razie potrzeby skręæ w lewo (czasami więcej niŋ raz)
ifelse (wall? 0)
[ lt 90 * direction
set way-is-clear? false ]
[ set way-is-clear? true ]
end
to walk-modified-3 ;; zmodyfikowane poddziaģanie chodzenia ŋóģwia 3
;; pójķæ do przodu
if way-is-clear? and checked-following-wall?
[ fd 1
set way-is-clear? false
set checked-following-wall? false ]
end
Aby zasymulowaæ równolegģy charakter zmodyfikowanego zachowania, oryginalne zachowania związane z zachowaniem ķciany zostaģy podzielone na trzy pod-zachowania - są one okreķlone w procedurach walk-modified-1, walk-modified-2 i walk-modified-3 powyŋszego kodu. Pierwsza procedura sprawdza, czy agent nadal podąŋa za ķcianą i w razie potrzeby zmienia się na preferowaną stronę. Następnie ustawia zmienną agenta, checked-following-wall na prawdę, aby wskazaæ, ŋe to zrobiģo. Druga procedura sprawdza, czy ķciana jest przed nami, skręca w przeciwnym kierunku do preferowanej strony, jeķli istnieje, a następnie ustawia nową zmienną agenta way-is-clear aby wskazaæ, czy ķciana jest przed nami, czy nie. Trzecia procedura przesuwa się o 1 krok do przodu, ale tylko wtedy, gdy obie drogi są wyražnie przed sobą i wykonano sprawdzenie podąŋania za ķcianą. Zasadniczo ogólne zachowanie jest takie samo jak poprzednio, poniewaŋ wszystko, co zrobiliķmy, to podzielenie pierwotnego zachowania na trzy pod-zachowania - innymi sģowy, samo zrobienie tego samo nie przynosi niczego nowego. Powodem tego jest umoŋliwienie nam wykonywania sub-zachowaņ w sposób niesekwencyjny, niezaleŋnie od siebie, w celu symulowania zachowania "odczuwanie i myķlenie i dziaģanie", gdzie "i" wskazuje, ŋe kaŋdy jest wykonywany jednoczeķnie, w bez szczególnej kolejnoķci. Moŋna to zrobiæ w NetLogo za pomocą polecenia ask-concurrent, jak pokazano w procedurze go w kodzie. Zapewnia to, ŋe kaŋdy agent na zmianę wykonuje komendy procedury walk-modified. Gģówna róŋnica w porównaniu ze standardowym zachowaniem jest widoczna w tej procedurze. Interfejs do modelu zapewnia inny wybierak, który pozwala uŋytkownikowi ustawiæ zmienną choose-sub-behaviours, która kontroluje sposób wykonywania czynnoķci podrzędnych. Jeķli ta zmienna jest ustawiona na " Choose-all-in-random order", wtedy wszystkie trzy sub-zachowania będą wykonywane jak przy standardowym zachowaniu, ale tym razem w losowej kolejnoķci; w przeciwnym razie zmienna jest ustawiona na Choose-one-at-random" i wybierane jest tylko jedno zachowanie podrzędne. Oczywiķcie sposób, w jaki modyfikowane zachowanie jest wykonywane, jest teraz wyražnie róŋny od standardowego zachowania - mimo ŋe pierwszy wykonuje te same pod-zachowania tego drugiego, to jest to wykonywane w okreķlonej kolejnoķci, lub wybierane jest tylko jedno z trzech pod-zachowaņ. kaŋdy tyk. A jednak podczas pracy z modelem uzyskuje się takie same ogólne wyniki, niezaleŋnie od tego, który wariant modelu zostanie wybrany - kaŋdy agent z powodzeniem udaje się podąŋaæ za ķcianami, które znajdują się w ķrodowisku. Występują niewielkie róŋnice między poszczególnymi wariantami, takie jak wielokrotne przechodzenie w tyģ i w dóģ w dóģ po krótkich ķlepiach za zmodyfikowane warianty. Zdolnoķæ zmodyfikowanych wariantów do osiągnięcia podobnego rezultatu co oryginaģ jest interesująca, poniewaŋ zmodyfikowana metoda jest zarówno skuteczna, jak i niezawodna - niezaleŋnie od tego, kiedy iw jakiej kolejnoķci wykonywane są subkwarki, ogólny wynik jest nadal podobnie. Drugi model NetLogo, model Wall Following Events, zostaģ stworzony w celu konceptualizacji i wizualizacji zmodyfikowanego zachowania. Model ten uwaŋa, ŋe agent jednoczeķnie rozpoznaje i przetwarza wiele strumieni "zdarzeņ", które odzwierciedlają to, co dzieje się z nim samym i w ķrodowisku (w sposób podobny do tego przyjętego w procesie przetwarzania strumienia zdarzeņ (ESP). mają róŋne typy, ale są traktowane jako równowaŋne sobie nawzajem pod względem sposobu ich przetwarzania. Zachowanie definiuje się poprzez ģączenie szeregu zdarzeņ w las drzew (jeden lub więcej acyklicznych kierowanych wykresów), jak pokazano na rysunku.
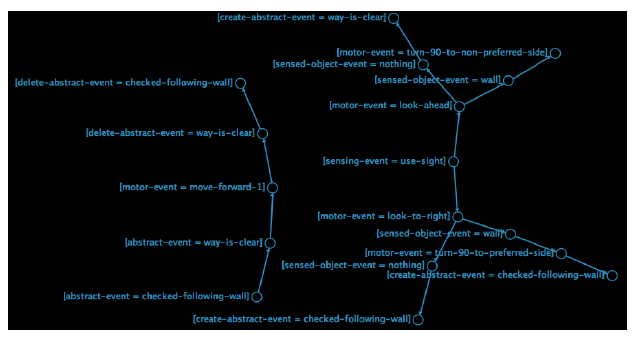
Drzewa ģączą ze sobą serie zdarzeņ (reprezentowane jako węzģy na wykresie), które muszą występowaæ w poģączeniu ze sobą. Jeķli okreķlone zdarzenie nie jest zarejestrowane w drzewie, to zdarzenie nie jest rozpoznawane przez agenta (tj. jest ignorowane i nie ma wpģywu na zachowanie agenta). Przetwarzanie zdarzeņ odbywa się w sposób reaktywny - to znaczy, ŋe okreķlona ķcieŋka w drzewie jest przesuwana przez sukcesywne dopasowywanie zdarzeņ, które obecnie występują do agenta, w stosunku do wychodzących przejķæ z kaŋdego węzģa. Jeķli nie ma ŋadnych przejķæ wychodzących lub ŋadne nie pasują, ķcieŋka jest ķlepym zauģkiem, w którym to momencie traversal się zatrzyma. Odbywa się to jednoczeķnie dla kaŋdego zdarzenia; innymi sģowy, istnieje wiele punktów początkowych, a zatem jednoczesne aktywacje w sieci leķnej. Na rysunku, drzewa zdarzeņ zostaģy zdefiniowane w celu reprezentowania zmodyfikowanej ķciany po zachowaniu okreķlonym powyŋej. Kaŋdy węzeģ na wykresie reprezentuje zdarzenie, które jest oznaczone przez identyfikator strumienia, oddzielone znakiem "=", po którym następuje identyfikator zdarzenia. Na przykģad węzeģ oznaczony [motor-event = moveforward-1] identyfikuje zdarzenie motoryczne dotyczące przesuwania do przodu o 1 stopieņ. W przypadku tego modelu zachowania istnieją cztery typy zdarzeņ - wykrywanie zdarzeņ, w których agent rozpoczyna aktywne wykrywanie konkretnego strumienia danych czuciowych (takiego jak widok, jak na rysunku); zdarzenia ruchowe, w których agent wykonuje pewien ruch lub dziaģanie, zdarzenia okreķlone przez obiekt, które występują, gdy dany obiekt jest rozpoznawany przez agenta; i zdarzenia abstrakcyjne, które są abstrakcyjnymi sytuacjami, które są wynikiem jednego lub więcej zdarzeņ zmysģowych, motorycznych i abstrakcyjnych, i które mogą byæ równieŋ tworzone lub usuwane przez agenta z jego wewnętrznej pamięci (która rejestruje, które abstrakcyjne zdarzenia są obecnie aktywne). Jeķli w pamięci znajduje się okreķlone abstrakcyjne zdarzenie, moŋna go uŋyæ do póžniejszego dopasowywania przez agenta wzdģuŋ ķcieŋki drzewa. Na przykģad węzeģ oznaczony [sensing event = use-sight] w ķrodkowym prawym rogu rysunku reprezentuje zdarzenie, w którym agent uŋywa zmysģu wzroku. Na tym czuciowym kanale wejķciowym moŋe wystąpiæ wiele zdarzeņ, ale tylko dwa zdarzenia są szczególnie istotne dla zdefiniowania zachowania na ķcianie - są to zarówno zdarzenia ruchowe, z których jedno jest dziaģaniem polegającym na patrzeniu w przyszģoķæ, a drugim jest dziaģaniem polegającym na patrzeniu w prawo. . Następnie, w zaleŋnoķci od tego, która ķcieŋka jest ķledzona, w drzewku napotykane są róŋne zdarzenia sensed-object, albo obiekt ķciany jest wykrywany, albo nic nie jest wykrywane. Ķcieŋki te są kontynuowane, dopóki nie zostanie wykonane ostatnie zdarzenie motoryczne (takie jak obrót o 90 ° w stronę preferowaną w prawym górnym rogu figury) lub zostanie utworzone zdarzenie abstrakcyjne (np. czy ķledzenie ķciany zostaģo sprawdzone w dole rysunku). Naleŋy zauwaŋyæ, ŋe w przeciwieņstwie do modelu Sense - Think - Act, ten model zachowania nie ogranicza się do okreķlonej kolejnoķci zdarzeņ. Kaŋdy rodzaj zdarzenia moŋe "podąŋaæ" za innym, a dwa tego samego typu są równieŋ moŋliwe - na przykģad w ķcieŋce, która rozpoczyna się po lewej stronie rysunku, po sobie następują dwa abstrakcyjne zdarzenia. Naleŋy równieŋ zauwaŋyæ, ŋe uŋycie sģowa "follow" jest mylące w tym kontekķcie. Chociaŋ odpowiednio opisuje, ŋe jedno ģącze przychodzi po drugim na okreķlonej ķcieŋce w modelu drzewa, zdarzenie moŋe faktycznie wystąpiæ jednoczeķnie, a kolejnoķæ okreķlona przez ķcieŋkę drzewa jest dowolna i po prostu opisuje kolejnoķæ, w której agent rozpozna obecnoķæ wielokrotnie występujących zdarzeņ. Na przykģad, nie ma powodu, dla którego przeciwna kolejnoķæ nie moŋe byæ obecna w drzewie; lub kolejnoķæ alternatywna, która doprowadzi do takiego samego zachowania (np. zamiana dwóch abstrakcyjnych zdarzeņ na dole ķcieŋki lewej ręki na rysunku nie będzie miaģa wpģywu na wynikowe zachowanie agenta). Kod sģuŋący do utworzenia zrzutu jest wyķwietlany w kodzie NetLogo
breed [states state]
directed-link-breed [paths path]
states-own
[ depth ;; gģębokoķæ w drzewie
stream ;; nazwa strumienia zdarzeņ sensorycznych lub motorycznych
event ;; zdarzenie sensoryczne lub motoryczne
]
globals
[ root-colour node-colour link-colour ]
;; okreķla sposób wizualizacji drzewa zdarzeņ
to setup
clear-all ;; wyczyķæ wszystko
set-default-shape states "circle 2"
set root-colour sky
set node-colour sky
set link-colour sky
add-events (list ["sensing-event" "use-sight"]
(list "motor-event" "look-to-right")
(list "sensed-object-event" "wall")
(list "motor-event" "turn-90-to-preferred-side")
(list "create-abstract-event" "checked-following-wall"))
add-events (list ["sensing-event" "use-sight"]
(list "motor-event" "look-to-right")
(list "sensed-object-event" "nothing")
(list "create-abstract-event" "checked-following-wall"))
add-events (list ["sensing-event" "use-sight"]
(list "motor-event" "look-ahead")
(list "sensed-object-event" "wall")
(list "motor-event" "turn-90-to-non-preferred-side"))
add-events (list ["sensing-event" "use-sight"]
(list "motor-event" "look-ahead")
(list "sensed-object-event" "nothing")
(list "create-abstract-event" "way-is-clear"))
add-events (list ["abstract-event" "checked-following-wall"]
(list "abstract-event" "way-is-clear")
(list "motor-event" "move-forward-1")
(list "delete-abstract-event" "way-is-clear")
(list "delete-abstract-event" "checked-following-wall"))
reset-layout
end
to reset-layout
repeat 500
[ layout-spring states paths spring-constant spring-length
repulsion-constant ]
;; zostaw miejsce wokóģ krawędzi
ask states [ setxy 0.95 * xcor 0.95 * ycor ]
end
to change-layout
reset-layout
display
end
to set-state-label
;; ustawia etykietę dla stanu
set label (word "[" stream " = " event "] ")
end
to add-events [list-of-events]
;; dodaj zdarzenia z listy wydarzeņ do drzewa wydarzeņ.
;; kaŋda pozycja listy wydarzeņ musi skģadaæ się z dwóch pozycji.
;; na przykģad [[odcieņ 0,9] [jasnoķæ 0,8]]
let this-depth 0
let this-stream ""
let this-event ""
let this-state nobody
let next-state nobody
let these-states states
let matching-states []
let matched-all-so-far true
foreach list-of-events
[ set this-stream first ?
set this-event last ?
;; sprawdž, czy stan juŋ istnieje
set matching-states these-states with
[stream = this-stream and event = this-event]
ifelse (matched-all-so-far = true) and (count matching-states > 0)
[
set next-state one-of matching-states
ask next-state [ set-state-label ]
set these-states [out-path-neighbors] of next-state ]
[ ;; stan nie istnieje - utwórz got
set matched-all-so-far false
create-states 1
[
set size 8
set depth this-depth
set stream this-stream
set event this-event
set-state-label
ifelse (depth = 0)
[ set label-color root-colour ]
[ set label-color node-colour ]
ifelse (depth = 0)
[ set color root-colour ]
[ set color node-colour ]
set next-state self
]]
if (this-state != nobody)
[ ask this-state
[ create-path-to next-state [ set color link-colour ]]]
;; zejķæ z drzewa
set this-state next-state
set this-depth this-depth + 1
]
ask links [ set thickness 1.3 ]
end
Kod najpierw okreķla dwa typy, stany i ķcieŋki, które reprezentują przejķcia między stanami. Kaŋdy agent paņstwowy ma powiązane trzy zmienne - depth, która jest odlegģoķcią od stanu gģównego drzewa; stream, który identyfikuje nazwę okreķlonego typu zdarzenia; i wydarzenie, które jest nazwą wydarzenia. Typ zdarzenia nazywany jest "strumieniem", poniewaŋ uŋywamy analogii wyglądu zdarzeņ jako podobnych do przepģywu obiektów w strumieniu. Wiele wydarzeņ moŋe "przepģywaæ" przeszģoķcią, niektóre pojawiają się jednoczeķnie, ale jest teŋ okreķlona kolejnoķæ nadejķcia wydarzeņ, poniewaŋ jeķli zignorujemy konkretne wydarzenie, zostanie ono utracone - musimy sobie z nim w jakiķ sposób poradziæ. Procedura setup inicjalizuje drzewa zdarzeņ, wywoģując procedurę add-events dla kaŋdej ķcieŋki. Ta procedura pobiera pojedynczy parametr jako dane wejķciowe, które jest listą zdarzeņ okreķlonych jako pary nazw strumieni i nazw zdarzeņ. Na przykģad dla pierwszego wywoģania add-events lista zawiera pięæ zdarzeņ: pierwsza to zdarzenie typu "use-sight" w strumieniu sensing-event ; drugie jest zdarzeniem look-to-right w strumieniu motor-event; i tak dalej. Kierowana ķcieŋka zawierająca wszystkie zdarzenia z listy zdarzeņ jest dodawana do drzew zdarzeņ. Jeķli pierwsze zdarzenie na liķcie nie występuje w katalogu gģównym ŋadnego istniejącego drzewa, tworzony jest katalog gģówny nowego drzewa, a ķcieŋka bez rozgaģęzieņ z katalogu gģównego jest dodawana w celu uwzględnienia pozostaģych zdarzeņ na liķcie. W przeciwnym razie pierwsze zdarzenia na liķcie są porównywane z istniejącą ķcieŋką, z nowymi stanami dodanymi na koņcu, gdy zdarzenia nie są juŋ zgodne.
Algorytm stada
v
W 1986 r. Craig Reynolds opracowaģ rozproszony model do symulacji zachowaņ zwierząt, który obejmuje skoordynowany ruch, taki jak uciekanie się do ptaków, uczenie ryb i pasterstwo dla ssaków. Reynolds obserwowaģ flockowe zachowanie kosów i zastanawiaģ się, czy moŋliwe jest przyciągnięcie wirtualnych stworów w ten sam sposób w symulacji komputerowej w czasie rzeczywistym. Jego hipoteza byģa taka, ŋe istniaģy proste reguģy odpowiedzialne za to zachowanie. Model, który opracowaģ, wykorzystuje wirtualne agenty zwane boids, które mają ograniczoną formę przykģadu wykonania podobną do tej stosowanej przez agentów w modelu Vision Cone. Zachowanie boidów jest podzielone na trzy warstwy - wybór akcji, sterowanie i lokomocja - jak pokazano na rysunku.
Wybór Akcji : Strategia, wyznaczanie celów, planowanie
Sterowanie : Okreķlenie ķcieŋki
Lokomocja : Ruch, animacja, artykulacja
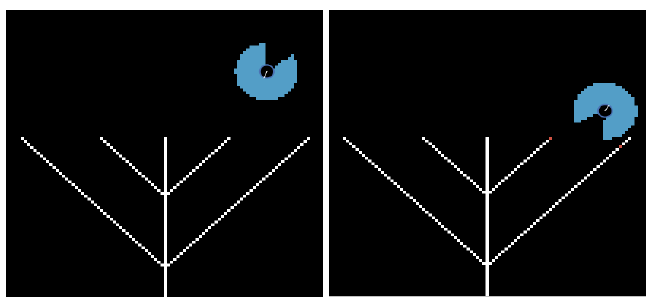
Najwyŋsza warstwa dotyczy selekcji dziaģaņ, która kontroluje zachowania, takie jak strategia, ustalanie celów i planowanie. Te skģadają się z zachowaņ sterujących na kolejnym poziomie, które dotyczą bardziej podstawowych zadaņ wyznaczania ķcieŋki, takich jak podąŋanie ķcieŋką, poszukiwanie i ucieczka. Te z kolei skģadają się z zachowaņ lokomocyjnych związanych z ruchem, animacją i artykulacją wirtualnych stworzeņ. Aby opisaæ swój model, Reynolds uŋywa analogii kowbojów, którzy opiekują się stadem bydģa, gdy krowa odlatuje od stada. . Szef szlaku odgrywa rolę selekcji dziaģaņ - mówi kowbojowi, by sprowadziģ bezpaņskie z powrotem do stada. Kowboj odgrywa rolę sterowania, rozkģadając cel na serię pod-celów, które odnoszą się do indywidualnych zachowaņ sterujących wykonywanych przez zespóģ kowbojów i koni. Kowboj steruje swoim koniem za pomocą sygnaģów sterujących, takich jak polecenia gģosowe i uŋycie ostróg i stew, które powodują, ŋe zespóģ porusza się szybciej lub wolniej lub skręca w lewo lub w prawo. Koņ wykonuje lokomocję, która jest wynikiem zģoŋonej interakcji między wizualnymi percepcjami konia, ruchami jego mięķni i stawów oraz poczuciem równowagi. Naleŋy zauwaŋyæ, ŋe warstwy wybrane przez Reynoldsa są arbitralne, a bardziej kwestią projektowania odzwierciedlającą naturę problem modelowania. Sam Reynolds zwraca uwagę, ŋe alternatywne struktury są moŋliwe, a ten wybrany do modelowania prostych istot flokujących nie byģby odpowiedni dla innego problemu, takiego jak projektowanie agenta konwersacyjnego lub chatbota. Tak jak w przypadku prawdziwych stworzeņ, to, co te boidy widzą w dowolnym jednym punkcie w czasie jest wyznaczany przez kierunek, w którym są skierowane i zakres ich widzenia peryferyjnego, jak okreķlono przez stoŋek o okreķlonym kącie i odlegģoķci. Kąt stoŋka okreķla, jak duŋy jest "ķlepy" punkt - to znaczy częķæ, która znajduje się poza ich zasięgiem widzenia bezpoķrednio za ich gģową przeciwną do kierunku, w którym się znajdują. Jeķli kąt stoŋka wynosi 360 °, wtedy będą mogli zobaczyæ wszystko dookoģa; jeķli jest mniejsza, to wielkoķæ martwego punktu jest róŋnicą między kątem stoŋka a 360 °. Algorytm moŋe byæ ģatwo zaimplementowany w NetLogo za pomocą polecenia in-cone, jak w przypadku modelu Vision Cone. Rysunek jest zrzutem ekranu boidu zaimplementowanego w NetLogo

Zdjęcie przedstawia stoŋek widzenia w kolorze niebieskiego nieba o kącie 300 ° (rozmiar martwego pola wynosi 60 °). Ŋóģw jest rysowany za pomocą ksztaģtu "directional-circle" w ķrodku obrazu i koloru niebieskiego, z biaģą linią promienia skierowaną w tym samym kierunku, co aktualny kurs ŋóģwia. Szerokoķæ stoŋka zaleŋy od parametru dģugoķci przekazywanego do polecenia in-cone i rozmiaru patch dla ķrodowiska. Zobaczymy teraz, jak niektóre z tych zachowaņ moŋna wdroŋyæ w NetLogo. Zauwaŋ, ŋe tak jak w przypadku wszystkich implementacji, istnieją róŋne sposoby tworzenia kaŋdego z tych zachowaņ. Na przykģad, obserwowaliķmy juŋ zachowanie się ķciany, co zostaģo przedstawione w modelu "Ķciana po przykģadzie" opisanym w poprzedniej częķci oraz w modelu "Ķciana po przykģadzie 2" opisanym tu. Chociaŋ zachowanie nie jest dokģadnie takie samo dla obu modeli, wynik jest faktycznie taki sam. Oba modele mają ķrodki, które wykorzystują metodę stoŋka widzenia z przykģadu wykonania z figury powyŋej, która jest w sercu modelu behawioralnego boids. Opracowano dwa modele w celu wykazania unikania przeszkód. Niektóre zrzuty ekranu pierwszego modelu, o nazwie Unikanie przeszkód 1, przedstawiono na rysunku
Pokazują one pojedynczy boid poruszający się po otoczeniu, próbując uniknąæ biaģych rzędów przeszkód - analogią byģaby æma, starająca się uniknąæ wpadnięcia na ķciany podczas lotu. Zakres widzenia boidów jest pokazany przez halo w kolorze nieba otaczając boid - zostaģ ustawiony na dģugoķci 8 w modelu o kącie 300 °. Obraz po lewej pokazuje boid tuŋ po naciķnięciu przycisku setup w interfejsie w kierunku rzędów przeszkód. Po kilku kleszczach krawędž stoŋka wizji boida wpada na koniec ķrodka póģnocno-wschodniego, wskazujący przekątną rząd przeszkód (przedstawiony przez zmianę koloru przeszkody na czubku od biaģego do czerwonego), następnie obraca się w lewo o okoģo 80 ° i kieruje się w stronę zewnętrznej przekątnej. Jego stoŋek widzenia równieŋ trafi w pobliŋu koņca tej przekątnej, a następnie w koņcu boid ponownie się obraca i odsuwa się od przeszkód w kierunku póģnocno-wschodnim, jak pokazano na drugim obrazku po prawej. Kod do tego jest pokazany w kodzie NetLogo
breed [wanderers wanderer] ; name of the breed of boids
to setup
clear-all
set-default-shape wanderers "directional-circle"; ustawia ksztaģty boid
; stworzyæ kolor, rozmiar i losową lokalizację pojedynczego wędrowca
create-wanderers 1 [default blue ]
draw-obstacles
end
to default [colour] ; worzy domyķlne ustawienia boid
print "Got here"
set color colour ; ustawia kolor za pomocą przekazanego parametru
setxy random-xcor random-ycor ; ustawia początkową losową pozycję
set size 5 ; domyķlny rozmiar ŋóģwia
end
to draw-obstacles
ask patches with [pxcor = 0 and pycor <= 15 or
abs pxcor = (pycor + 40) and pycor < 40 or
abs pxcor = (pycor + 15) and pycor < 6]
[ set pcolor white ]
end
to make-obstacle
if mouse-down?
[ ask patches
[ if ((abs (pxcor - mouse-xcor)) < 1) and
((abs (pycor - mouse-ycor)) < 1)
[ set pcolor white ]
]
]
end
to go
ask wanderers ; nstrukcje wędrowców
[
rt random-float rate-of-random-turn
lt (rate-of-random-turn / 2)
; losowo obraca się w górę w lewo lub w prawo, zgodnie z definicją
; zmienna losowa stopa zwrotu w interfejsie
fd boid-speed
avoid-patches
]
end
to avoid-patches
ask patches with [pcolor = sky]
[ set pcolor black ]
ask patches in-cone radius-length radius-angle
[ if pcolor = black
[ set pcolor sky ]
if pcolor = white
[ set pcolor red ]]
if count patches in-cone radius-length radius-angle with
[pcolor = white or pcolor = red] > 0
[
ask wanderer 0
[
bk boid-speed
lt 90
]
]
end
Procedura setup umieszcza boid w losowym miejscu w otoczeniu i wywoģuje procedurę draw-obstacles, aby narysowaæ biaģe przeszkody w dolnej poģowie ķrodowiska. Polecenie ask-wanderers w procedurze go okreķla zachowanie boid. Boid wykona obrót w prawo i lewo o losową liczbę, a następnie przesunie do przodu o okreķloną wartoķæ okreķloną przez zmienną boid-speed zdefiniowaną w interfejsie. Następnie boid wywoģuje procedurę avoid-patches w celu uniknięcia kolizji. W tej procedurze najpierw zabarwiony na niebie halo otaczający boid zostaje skasowany poprzez ustawienie kolorowych plam na niebie na czarny. Następnie halo wzroku jest przerysowywane wokóģ boidu w oparciu o jego bieŋące poģoŋenie - szybkie wymazanie, a następnie przerysowanie powoduje, ŋe boid migocze jak motyl szybko macha skrzydģami. Boid następnie wykonuje unikanie kolizji, cofając dystans równy boid-speeed i wykonuje skręt w lewo. Ostatnia częķæ procedury powoduje, ŋe ģatki, które zostaģy zderzone z kolorem czerwonym. Model Unikania Przeszkód 2 ilustruje unikanie przeszkód w tym samym ķrodowisku, co model przewidywany z biblioteki modeli. Zrzut ekranu modelu pokazano na rysunku

Węŋyk moŋna zobaczyæ w ķrodkowym lewym rogu otoczenia. Ķcieŋka, którą podjąģ boid, jest wykreķlona na czerwono. To wyražnie pokazuje, ŋe boid udaģo się uniknąæ kolizji ze ķcianami i przeszkodami. Dģugoķæ stoŋka widzenia boida ustawiono na 1, a kąt 300 °. Kod jest podobny do modelu Unikania Przeszkód 1. Model "Podąŋaj za i unikaj" wdraŋa poszukiwania i ucieka przed zachowaniami. Trzy zrzuty ekranu tego modelu pokazano na rysunku
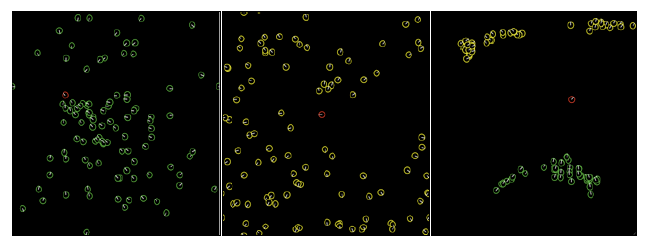
Lewy obraz pokazuje, kiedy jeden ķrodek wędrowiec jest w kolorze czerwonym, a 100 osób naķladowców ma kolor zielony. Pokazuje większoķæ agentów skierowanych w stronę agenta wędrownego. Podczas symulacji agenci naķladowcy aktywnie ķcigają agenta wędrownego, gdy wędruje on wokóģ. Ķrodkowy obraz pokazuje 100 ķrodków zapobiegających powstawaniu koloru, które zabarwiają się na ŋóģto, próbując uniknąæ ķrodka wędrownego. W tym przypadku większoķæ czynników unikających jest odsunięta od ķrodka wędrownego i aktywnie odsunie się od niego podczas symulacji. Odpowiedni obraz pokazuje sytuację, w której 50 agentów obserwujących i 50 agentów unikowych znajduje się w ķrodowisku wraz z agentem wędrownym. Obraz pokazuje większoķæ agentów obserwujących na zielono, wskazując na wędrowca, a większoķæ ķrodków zapobiegawczych na ŋóģto wskazuje z niego. Na początku wszyscy agenci są losowo rozmieszczeni w caģym ķrodowisku, ale po przeprowadzeniu symulacji dla krótkiej liczby kleszczy, zwykle pojawia się, ŋe zarówno zwolennicy, jak i czynniki unikające zaczną zbijaæ się razem, jak pokazano na obrazku. Kod modelu jest pokazany w kodzie NetLogo
breed [wanderers wanderer] ; wanders around
breed [followers follower] ;próbuje podąŋaæ za wędrowcem
breed [avoiders avoider] ; próbuje uniknąæ wędrowca
to setup
clear-all
; ustawiæ ksztaģty dla ras
set-default-shape wanderers "directional-circle"
set-default-shape followers "directional-circle"
set-default-shape avoiders "directional-circle"
; stwórz wędrowca, wyznawcę i unikającego w losowych miejscach
create-wanderers 1 [ default red ]
create-followers number-of-followers [ default green ]
create-avoiders number-of-avoiders [ default yellow ]
end
to-report number-of-agents
; uŋywane, aby pokazaæ, ŋe liczba ŋóģwi jest staģa, nawet gdy
; wszyscy obserwujący zbijają się jedna na drugiej
report count turtles
end
to default [colour] ; creates default settings for boid
set color colour ; sets colour using passed parameter
setxy random-xcor random-ycor ; sets an initial random position
set size 3 ; default turtle size
end
to go
ask wanderers ; instrukcje wędrowca
[
lt random 30 ; losowo skręæ w lewo
rt 15
fd boid-speed ; zmienna prędkoķæ zdefiniowana przez uŋytkownika
]
ask followers ;instrukcje obserwującego
[
fd boid-speed / speed-scale ; porusza się do przodu ze zdefiniowaną przez uŋytkownika prędkoķcią
; obserwujący szuka wędrowca w promieniu
if any? wanderers in-radius radius-detection
[ set heading (towards wanderer 0) - random boid-random-heading
+ random boid-random-heading
; dostosowuje kurs do punktu wędrowca]
]
ask avoiders ; avoiders' instructions
[
fd boid-speed / speed-scale ; moves forward at user defined speed
; unikaj poszukiwaņ wędrowca w jego promieniu
if any? wanderers in-radius radius-detection
[ set heading (towards wanderer 0) + 180 - random boid-random-heading
+ random boid-random-heading ]
; dostosowuje kurs, aby wskazywaģ z dala od wędrowca
]
end
Zachowanie trzech typów agentów okreķlają procedury wanderers, followers i avoiders. Pierwszy okreķla zachowanie agenta wędrownego, aby bģąkaģ się w sposób póģlosowy. Drugi definiuje zachowanie dla agenta obserwującego, który polega na tym, ŋe agent najpierw przesuwa się do przodu o okreķloną przez uŋytkownika liczbę zgodnie ze zmiennymi boid-speed i speed -scale. Następnie uŋywa reportera in-radius NetLogo, aby wykryæ, czy wędrowiec jest w jego okrągģym polu widzenia, którego wielkoķæ jest okreķlona przez zmienną Interface radius-detection. Jeķli tak, to ruszy w jego kierunku. Zachowanie agenta unikającego definiuje się w podobny sposób, z tą róŋnicą, ŋe kieruje się w przeciwnym kierunku (180 °) od wędrownego zamiast do niego. Model Flocking With Obstacles jest modyfikacją modelu Flocking dostępnego w bibliotece modeli NetLogo. Model biblioteki wykorzystuje standardową metodę implementacji zachowania flokowania opracowaną przez Craiga Reynoldsa. W tym podejķciu flokowanie wyģania się z zastosowania trzech podstawowych zachowaņ sterujących. Są to: separacja, gdzie boid próbuje uniknąæ zbytniego zbliŋania się do innych boidów; wyrównanie, gdzie boid próbuje poruszaæ się w tym samym kierunku, co pobliskie boidy; i spójnoķci, gdzie boid próbuje przejķæ w kierunku innych boidów, chyba ŋe są zbyt blisko. Dzięki zmodyfikowanemu modelowi uŋytkownik ma dodatkową opcję dodawania róŋnych obiektów do otoczenia, takich jak rafa koralowa, trawa morska i rekin. Ma to na celu symulację tego, co dzieje się, gdy stado napotka jeden lub więcej obiektów i lepiej symuluje ķrodowisko dla szkoģy ryb. Niektóre zrzuty ekranu zmodyfikowanego modelu są pokazane na rysunku

Górny lewy obraz pokazuje model na początku po naciķnięciu przycisku konfiguracji w interfejsie. Ķrodkowy górny obrazek pokazuje model po jego uruchomieniu na krótką chwilę i powstaģa szkoģa agentów ŋóģwi. Prawy górny obrazek pokazuje model z ģatami kolizji dodanymi w ķrodku w ksztaģcie rekina zaģadowanego natychmiast po wykonaniu poprzedniego zdjęcia. Te plastry powodują oderwanie się agentów ŋóģwia, gdy zderzają się z nimi. Lewy dolny obraz pokazuje obraz tģa naģoŋony na ten sam obraz. Ķrodkowe dolne zdjęcie pokazuje szkoģę zbliŋającą się do obiektu z innego kierunku. Obraz w prawym dolnym rogu pokazuje scenę niedģugo po tym, jak szkoģa podzieliģa się na dwie podkategorie po kolizji i odchodzą od obiektu. Ģatki zderzeniowe dziaģają zgodnie z modelem, który zakģada, ŋe naleŋy unikaæ jakiejkolwiek ģaty, która nie jest czarna; to znaczy, ŋe wszystkie kolory, z wyjątkiem czarnego, zmuszają boidy do obrócenia się o 180 °, aby uniknąæ kolizji. Inną zmianą w modelu jest to, ŋe prędkoķæ przenoķnych boidów moŋe byæ teraz kontrolowana z interfejsu, aby umoŋliwiæ większe testowanie poszczególnych ruchów, a takŋe zapewnia moŋliwoķæ analizowania reakcji boidów. Kod odpowiednich częķci zmodyfikowanego modelu, które definiują zachowanie agentów, znajduje się w kodzie NetLogo
turtles-own [
flockmates ;; zestaw agentów pobliskich ŋóģwi
nearest-neighbor ;; najbliŋszy jeden z naszych stad
]
to setup
clear-all
crt population
[ set color blue - 2 + random 7
set size 1.5
setxy random-xcor random-ycor ]
end
to go
ask turtles [ flock ]
repeat 5 [ ask turtles [ fd set-speed / 200 ] display ]
tick
end
to flock
find-flockmates
if any? flockmates
[ find-nearest-neighbor
ifelse distance nearest-neighbor < minimum-separation
[ separate ]
[ align
cohere ] ]
avoid-obstacles
end
to avoid-obstacles
; unikaj w pobliŋu wszystkiego, co nie jest czarne
if (any? patches in-cone 2 300 with [pcolor != black])
[ rt 180 ] ; skieruj się w przeciwnym kierunku
end
to find-flockmates
set flockmates other turtles in-radius vision
end
to find-nearest-neighbor
set nearest-neighbor min-one-of flockmates [distance myself]
end
to separate
turn-away ([heading] of nearest-neighbor) max-separate-turn
end
to align
turn-towards average-flockmate-heading max-align-turn
end
to-report average-flockmate-heading
report atan sum [sin heading] of flockmates
sum [cos heading] of flockmates
end
to cohere
turn-towards average-heading-towards-flockmates max-cohere-turn
end
to-report average-heading-towards-flockmates
report atan mean [sin (towards myself + 180)] of flockmates
mean [cos (towards myself + 180)] of flockmates
end
to turn-towards [new-heading max-turn]
turn-at-most (subtract-headings new-heading heading) max-turn
end
to turn-away [new-heading max-turn]
turn-at-most (subtract-headings heading new-heading) max-turn
end
to turn-at-most [turn max-turn]
ifelse abs turn > max-turn
[ ifelse turn > 0
[ rt max-turn ]
[ lt max-turn ] ]
[ rt turn ]
end
Procedura setup tworzy losową populację ķrodków ŋóģwia. Polecenie ask w procedurze go okreķla zachowanie agentów - po prostu wywoģuje procedurę flock. W tym miejscu agent najpierw sprawdza, czy w jego polu widzenia znajdują się inne czynniki, a następnie, jeķli istnieją, szuka najbliŋszego sąsiada, a następnie stosuje kierowanie separacją okreķlone w procedurze, separate jeķli jest zbyt blisko . W przeciwnym razie stosuje się zachowanie kierowania wyrównaniem, jak okreķlono w procedurze dopasowywania, po której następuje kierowanie kohezją zgodnie z definicją procedury cohere. Te trzy procedury korzystają z procedur turn-away lub turn-towards, które powodują, ŋe boid się odwraca lub w kierunku konkretnej pozycji odniesienia, biorąc pod uwagę aktualną pozycję boid's. Nagģówkiem odniesienia dla zachowania kierowania separacją jest nagģówek najbliŋszego sąsiada boida, dla zachowanie kierowania wyrównaniem to ķrednia pozycja wiązaņ stada boidów, a dla zachowania sterownoķci kohezji jest to ķredni kurs w kierunku węzģów stada boidów. W symulacji moŋna zaobserwowaæ wiele pojawiających się zjawisk. Stado szybko formuje się na początku, gdy nie ma ŋadnych przeszkód. Zauwaŋalny efekt wirowania moŋna równieŋ zaobserwowaæ dla boidów w stadzie, jeķli początkowe parametry interfejsu są ustawione jako minimum-separation = 1,25 ģaty, max-align-turn = 15,00 stopni, max-cohere-turn = 15,00 stopni i max-separate-turn = 4,00 stopni. Kiedy szkoģa napotyka przeszkodę, zmienia kierunek jako grupa z indywidualnymi boidami, które bardzo szybko przejmują stado, jeķli się rozdzielą. Kiedy wystarczająca iloķæ boidów zmieniģa kurs, reszta szkoģy podąŋa za nią bez ŋadnego kolizji z przeszkodą. Czasami szkoģa dzieli się na dwie odrębne szkoģy kierując się w róŋnych kierunkach, jak pokazano w prawym dolnym obrazie na rysunku powyŋej .Model ķledzenia ķcieŋki tģumu implementuje zachowanie boidów w tģumie podąŋającym ķcieŋką. Zachowanie boidów w modelu moŋe mieæ dwie odmiany - podstawowe zachowanie po ķcieŋce tģumu i jedno z unikaniem kolizji (jest to ustawione za pomocą suwaka behaviour w interfejsie).
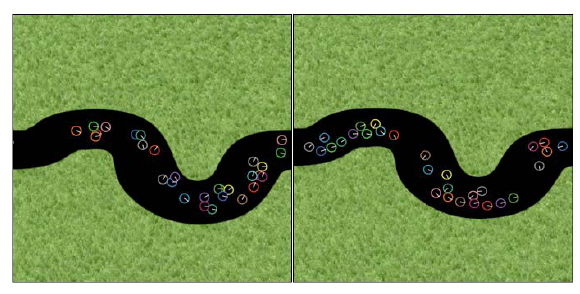
zawiera dwa zrzuty ekranu modelu dla dwóch róŋnych zachowaņ. Lewy obraz pokazuje "tģum" boidów zmierzających w dóģ w przybliŋeniu w tym samym kierunku od lewej do prawej. Nastąpiģo to po krótkiej chwili symulacji. Zauwaŋ, ŋe niektóre z agentów są bardzo blisko siebie - dzieje się tak, poniewaŋ nie ma unikania kolizji, w przeciwieņstwie do drugiego pokazanego zachowania po prawej. Chociaŋ podstawowy kod dla tych zachowaņ jest podobny (dla kodu, odnoķnik do odnoķnika znajdujący się w dolnej częķci tego rozdziaģu) jest oparty na uŋyciu polecenia in-cone, tak jak w przypadku innych implementacji agentów boid, co jest widoczne, zachowanie wynikające z unikania przeszkód jest zauwaŋalnie róŋne. Na przykģad, więcej podgrup agentów próbuje teraz iķæ wbrew przepģywowi, jak pokazano na prawym obrazie Wierne wdroŋenie bojlerów Reynoldsa powinno uwzględniaæ pewną formę siģy sterującej zaimplementowanej za pomocą aproksymacji masy punktowej, gdzie kaŋdy boid ma masę i dziaģa w stosunku do siģ. Jednak te wdroŋenia NetLogo pokazaģy, ŋe przybliŋenie podejķcia Reynoldsa moŋna osiągnąæ stosunkowo ģatwo, aw wielu przypadkach wynikowe zachowanie boidów jest zgodne z oczekiwaniami.
Podsumowanie
Sztuczna inteligencja oparta na zachowaniu (BBAI) przyjmuje behawioralne podejķcie do budowania inteligentnych systemów. To podejķcie rozkģada inteligencję na odrębne niezaleŋne póģ-autonomiczne moduģy, które opisują róŋne zachowania. Zachowanie agenta to seria dziaģaņ wykonywanych podczas interakcji ze ķrodowiskiem. Okreķlona kolejnoķæ lub sposób przeprowadzania ruchów i ogólny wynik, który pojawia się w wyniku dziaģaņ, okreķlają szczególny rodzaj zachowania. Róŋne perspektywy prowadzą do róŋnych wyjaķnieņ i róŋnych sposobów, w jakie rzeczy są tworzone. Ramy odniesienia dotyczą trudnoķci w zrozumieniu zachowania róŋnych gatunków. Punkty widzenia róŋnią się nie tylko dla kaŋdego agenta, lecz takŋe džwięk, odczucie, zapach i smak, z powodu odmiennej postaci wykonania czynnika obserwującego w porównaniu z obserwowanym czynnikiem. (Na przykģad spróbuj wyobraziæ sobie bycie mrówką.) Waŋne jest, aby nie przypisywaæ bģędnych wyjaķnieņ z obserwacji mechanizmom stojącym za zachowaniem ucieleķnionego czynnika znajdującego się w otoczeniu, a szczególnie waŋne, aby uniknąæ przypisywania skomplikowanych mechanizmów (np. "inteligencji") do zachowania obserwowanego agenta, gdy ma on inną ramę odniesienia, tj. inny przykģad wykonania.
Podsumowanie waŋnych pojęæ, które naleŋy wyciągnąæ z tego rozdziaģu, znajduje się poniŋej:
o Proste zasady mogą leŋeæ u podstaw zģoŋonych systemów.
o Proste reakcje reaktywne mogą byæ przyczyną zģoŋonych zjawisk.
o Zachowanie adaptacyjne to zachowanie, w którym agent zmieniģ swoje zachowanie w odpowiedzi na zmianę ķrodowiska.
o Zmieniające się zachowanie to zachowanie, które powstaģo w wyniku ewolucji genetycznej (to znaczy wymaga więcej niŋ jednego pokolenia, w którym cechy genetyczne są przekazywane potomstwu).
o Zachowanie wschodzące to pewna wģaķciwoķæ, która wyģania się z interakcji agent-agent lub interakcji między agentem a ķrodowiskiem, które nie mogģy powstaæ bez tych interakcji i nie jest wynikiem prostej liniowej kombinacji tych interakcji.
o Zachowanie samoorganizujące się w systemie z wieloma agentami występuje, gdy agenci stosujący reguģy lokalne tworzą pewien wzorzec lub strukturę jako wschodząca wģaķciwoķæ.
o Stygmatyka występuje wtedy, gdy agenci wykorzystują ķrodowisko do komunikowania się i interakcji. Na przykģad uŋywają mrówki i pszczoģy
ķrodowiska, aby powiedzieæ sobie, gdzie znaležæ žródģa ŋywnoķci. Ludzie uŋywają go do budowania zģoŋonych systemów informacyjnych i dzielenia się wiedzą, gdzie znaležæ žródģa informacji.
o Inteligencja roju jest zbiorem agentów, które wykorzystują stigmergiczną lokalną wiedzę do samoorganizacji i koordynacji ich zachowania.
Komunikacja
Biorąc pod uwagę historię ludzkoķci, spoģecznoķæ językowa jest bardzo naturalną jednostką. Języki, ze względu na swój charakter jako ķrodek komunikacji, dzielą ludzkoķæ na grupy; tylko przez wspólny język moŋe grupa ludzi dziaģaæ wspólnie, a zatem mają wspólną historię. Ponadto język, którym posģuguje się grupa, jest wģaķnie medium, w którym moŋna dzieliæ wspomnienia z ich wspólnej historii. języki umoŋliwiają zarówno ŋycie wspólnej historii, jak i jej opowiadanie. - Nicholas Ostler,
Nowa metoda szacowania entropii wykorzystuje fakt, ŋe kaŋdy, kto mówi językiem, posiada, nieodwoģalnie, ogromną znajomoķæ statystyk tego języka. Znajomoķæ sģów, idiomów, stereotypów i gramatyki pozwala mu uzupeģniæ brakujące lub niepoprawne litery w korekcie lub zakoņczyæ niedokoņczone wyraŋenie w rozmowie. - C.E. Shannon
Komunikacja, informacja i język
Komunikacja moŋe byæ zdefiniowana jako proces wymiany informacji między agentami. Agent wykazuje zachowanie komunikacyjne, gdy próbuje przekazaæ informacje innemu agentowi. Agent lub agenci wysyģają wiadomoķæ za poķrednictwem medium do agenta lub agentów odbiorcy. Termin komunikacja w powszechnym uŋyciu w języku angielskim moŋe równieŋ odnosiæ się do interakcji między ludžmi, które obejmują dzielenie się informacjami, pomysģami i uczuciami. Komunikacja nie jest jednak wyjątkowa dla ludzi, poniewaŋ zwierzęta, a nawet roķliny, równieŋ mają zdolnoķæ komunikowania się ze sobą. Język moŋna zdefiniowaæ jako zestaw symboli, z którymi agenci komunikują się w celu przekazywania informacji. W Sztucznej Inteligencji język ludzki jest często nazywany "językiem naturalnym" w celu odróŋnienia go od języków programowania komputerowego. Komunikacja za pomocą języka jest często uwaŋana za unikalną cechę behawioralną czģowieka. Język ludzki, taki jak mówiony, pisany lub znak, odróŋnia się od zwierzęcych systemów komunikacyjnych tym, ŋe jest uczony, a nie dziedziczony biologicznie. Chociaŋ róŋne zwierzęta wykazują zdolnoķæ komunikowania się, a niektóre zwierzęta, takie jak orangutany i szympansy, mają nawet zdolnoķæ posģugiwania się pewnymi cechami ludzkiego języka, to stopieņ zaawansowania i zģoŋonoķci w ludzkim języku odróŋnia go od systemów komunikacji zwierzęcej. Język ludzki opiera się na wyjątkowej zdolnoķci ludzi do abstrakcyjnego myķlenia za pomocą symboli do reprezentowania koncepcji i pomysģów. Język definiowany jest przez zestaw reguģ wspólnie okreķlających powszechnie akceptowane symbole, ich znaczenie oraz ich związki strukturalne okreķlone przez zasady gramatyki. Reguģy te opisują sposób manipulowania symbolami w celu utworzenia potencjalnie nieskoņczonej liczby gramatycznie poprawnych sekwencji symboli. Wybrane symbole są arbitralne i mogą byæ związane z dowolnym konkretnym fonemem, grafemem lub znakiem. Lingwistyka jest naukowym badaniem języka, które moŋna podzieliæ na odrębne obszary nauki: gramatyka jest nauką o strukturze języka; morfologia jest nauką o tym, jak sģowa są formowane i ģączone; fonologia to nauka o systemach džwięków; Skģadnia dotyczy reguģ rządzących tym, jak sģowa ģączą frazy i zdania; semantyka to badanie znaczenia; i pragmatyka dotyczy nauki języka i uŋytkowania oraz kontekstów, w których jest uŋywany.
Róŋnorodnoķæ ludzkiego języka
We wszystkich językach naturalnych istnieje duŋa róŋnorodnoķæ zastosowaņ, a takŋe często brak porozumienia między uŋytkownikami języka. Na przykģad tabela zawiera przykģady dopuszczalnych zdaņ "angielskich" z róŋnych regionów ķwiata. Kaŋde z tych zdaņ jest uwaŋane za "normalny" angielski dla regionu pokazanego po prawej stronie, a jednak większoķæ ludzi spoza tych regionów argumentowaģaby inaczej, a wiele spraw ma trudnoķci w zrozumieniu ich znaczenia.
Let's buy some food home! : Singapur
Don't smoke without causing an explosion! : Poģudniowa Walia
AIDS is very popular in Africa. : Hong Kong
My hair needs washed. : Szkocja, Póģnocna Irlandia, częķæ USA
Whenever my baby was born I was 26. : Póģnocna Irlandia
Her outlook is very beautiful. : Hong Kong
John smokes a lot anymore. : Ķrodkowy Zachód USA
I am difficult to study. : Hong Kong
I might could do it. : Szkocja, Póģnocna Anglia, Indie, częķæ USA
My name is spelt with four alphabets. : Singapur
You must beware of your handbag! : Hong Kong
We'll be there nine while ten. : Lancashire, Yorkshire
He loves his car than his girlfriend. : Indie, częķæ Afryki
Come here till I punch you! Irlandia, Liverpool, Cumbria, częķæ Szkocji
I'm after losing my ticket. Irlandia
My brother helps me with my studies and so do my car. : Hong Kong
I been know your name. : USA (Black)
I use to live there now. : Singapure
My grandfather died for a long time. : Hong Kong
I am having a nice car. : Indie, Singapur
I'll give it him. Póģnocna Anglia(standard)
Robots can do people not like jobs. : Hong Kong (niski poziom zaawansowania)
Odnoķnie języka angielskiego David Crystal (1988) stwierdza: "Język angielski rozciąga się na caģy ķwiat: od Australii po Zimbabwe, ponad 300 milionów ludzi mówi o nim jako o swoim ojczystym języku ... A jednak, pomimo jego zadziwiająco szerokiego zastosowania jako medium komunikacja, kaŋdy zawód i kaŋda prowincja - a nawet kaŋda osoba - uŋywa nieco innego wariantu. "
Angielski ma wiele róŋnych regionalnych dialektów (takich jak amerykaņski, brytyjski, australijski i nowozelandzki angielski), a takŋe wiele sub-dialektów w tych regionach. Istnieją równieŋ dialekty, które przecinają linie regionalne, na przykģad "Public School English" w Wielkiej Brytanii, Black English in America i Maori English in New Zealand. A w kaŋdym kraju istnieją niezliczone wariacje spoģeczne, które posiadają wģasną oszaģamiającą róŋnorodnoķæ kantów, ŋargonów i lingoli" . Jednym z bardziej kolorowych przykģadów jest sģownik slangu Wall Street zatytuģowany "Wysokie stepowniki, upadģe anioģy i lizaki". Obrazuje, jak taki język moŋe staæ się prawie niezrozumiaģy dla niewtajemniczonych. (Na przykģad, czym jest "wysoki stepper" lub "upadģy anioģ"?) . Hudson pisze o języku nastoletniej rewolucji, o urazie starszych ludzi do języka uŋywanego przez wspóģczesne nastolatki:
… moŋe nie lubią tego, ŋe nastolatkowie mówią innym językiem, uŋywając znacznej liczby wyraŋeņ, które sami uwaŋają za niepojęte lub odraŋające".
Oprócz róŋnorodnoķci językowej istnieje wiele róŋnych sposobów wyraŋania i uŋywania tego języka. Język ten róŋni się znacznie od języka pisanego, co ilustruje poniŋszy przykģad zaczerpnięty z Crystala:
"To częķæ wykģadu i wybraģem go, poniewaŋ pokazuje, ŋe nawet profesjonalny mówca uŋywa struktury, która rzadko by występowaģa w języku angielskim i wykazuje rozģącznoķæ przemówienia, którego w ogóle by tam brakowaģo. (Codzienna rozmowa zapewnia jeszcze bardziej uderzające róŋnice.) Kropka (.) Wskazuje krótką pauzę, kreska dģuŋszą pauzę, a erm jest próbą przedstawienia odgģosów, które wygģosiģ gģoķnik, gdy gģoķno się wahaģ. ...
- i chcę . bardzo arbitralnie, jeķli mogę podzieliæ to na trzy pozycje - i zapytaæ .erm. trzy pytania. ocena dlaczego - ocena co - i ocena jak. więc to jest naprawdę. oznacza, ŋe chcę o tym mówiæ. przede wszystkim w celach oceny - dlaczego w ogóle oceniamy - po drugie rodzaj funkcji i procesów, które są oceniane - i po trzecie chcę mówiæ o technikach ... " Baugh przypomina nam, ŋe język to nie tylko "wydrukowana strona" stosunkowo jednolita i staģa, jak wielu ludzi uwaŋa, ŋe tak jest. Język to "przede wszystkim mowa", a pisanie "tylko konwencjonalne" urządzenie do przekodowywania džwięków. "Dalej stwierdza, ŋe powtarzające się ruchy mięķni, które generują mowę, podlegają stopniowej zmianie gģoķnika:
"Kaŋda osoba nieustannie i zupeģnie nieķwiadomie wprowadza niewielkie zmiany w swojej mowie. Nie ma czegoķ takiego jak jednolitoķæ w języku. Nie tylko mowa jednej spoģecznoķci róŋni się od mowy innej, ale mowa róŋnych osób z jednej wspólnoty, kaŋdego z czģonków tej samej rodziny, charakteryzuje się indywidualnymi cechami osobowoķci. "
Niektóre inne wyróŋniające się formy języka to na przykģad poezja, dokumenty prawne, reportaŋe prasowe, reklama, pisanie listów, korespondencja biurowa, telegramy, rozmowy telefoniczne, poczta elektroniczna, artykuģy z Usenetu, artykuģy naukowe i przemówienia polityczne. Kaŋdy ma swój wģasny smak, dziwactwa i styl. I w kaŋdej formie są indywidualni autorzy, którzy mają swój wģasny styl języka. Sztuka Szekspira i powieķci science-fiction H. G. Wellsa to dwa przykģady bardzo wyražnych stylów literackich. W rzeczywistoķci kaŋda osoba ma wģasny styl języka lub idiolekt z wģasną unikatową charakterystyką, którą mogą ģatwo rozpoznaæ inni ludzie. Podobnie jak standardowe dialekty, istnieje wiele niestandardowych w uŋyciu. Fromkin twierdzi, ŋe "chociaŋ kaŋdy język jest poģączeniem dialektów, wiele osób mówi i myķli o języku tak, jakby byģ" dobrze zdefiniowanym "staģym systemem z róŋnymi dialektami odbiegającymi od tej normy". Twierdzą oni, ŋe te niestandardowe dialekty są często uwaŋane za "niedoskonaģe, nielogiczne i niekompletne" w porównaniu ze standardowymi dialektami. Posģugują się przykģadem wybitnego autora na temat języka, Mario Pei, który kiedyķ oskarŋyģ redaktorów Trzeciego Nowego Międzynarodowego sģownika Webstera o mylące do stopnia zatarcia starszego rozróŋnienia między standardowym, niestandardowym, kolokwialny, wulgarny i slang ". , w lingwistyce, stwierdza, ŋe " wiedza wielu ludzi na temat normalnego języka jest bardzo chwiejna; a ich zdolnoķæ do opisywania tego, co wiedzą, jest jeszcze gorsza. " Doķæ często nawet eksperci spierają się o lepsze aspekty uŋywania języka. Istnieje wiele sģowników objaķniających powszechne uŋycie lub mniej powszechne uŋycie, takie jak ŋargon, slang, klisze, idiomy i figury mowy, na przykģad Up the boohai shooting pukekas: sģownik slangu Kiwi. Znalezienie porządku w caģym tym chaosie byģo celem wielu ludzi odkąd Samuel Johnson skompilowaģ swój sģownik języka angielskiego w 1755 roku, a pierwsze próby zostaģy wykonane, aby niedģugo póžniej skompilowaæ gramatykę dla języka angielskiego.
Komunikacja za poķrednictwem spoģecznoķci agentów
Komunikacja jest z definicji prowadzona między dwoma lub więcej agentami. Waŋnym aspektem ludzkiej komunikacji jest to, ŋe jest ona prowadzona między spoģecznoķciami i grupami agentów. W przypadku agentów ludzkich rodzaj komunikacji za poķrednictwem języka ludzkiego, który jest uznawany za wģaķciwy w kaŋdej spoģecznoķci, często moŋe byæ wykorzystany do identyfikacji i odróŋnienia tej spoģecznoķci lub grupy. Przejawia się to w róŋnych językach, dialektach, sub-dialektach i socjolektach (język uŋywany w danej grupie spoģecznej), które róŋnią się sģownictwem, gramatyką i wymową, często przy uŋyciu odmian sģownika, takich jak ŋargon i slang. .Sieæ spoģeczna wķród spoģecznoķci agentów jest waŋnym aspektem ludzkiego języka. Sieæ spoģecznoķciowa to struktura spoģeczna zģoŋona z agentów powiązanych ze sobą wspólną cechą. Sieæ spoģecznoķciowa moŋe byæ reprezentowana przez wykres, w którym węzģy reprezentują agentów, a ģącza między węzģami definiują relacje między agentami. Termin sieci spoģecznoķciowe staģ się znacznie powszechniejszy w powszechnym uŋyciu w języku angielskim z powodu niedawnego pojawienia się serwisów spoģecznoķciowych takich jak Facebook, Myspace i Twitter. Język jest definiowany przez czģonków sieci spoģecznoķciowej obejmującej spoģecznoķæ językową. W obrębie tej spoģecznoķci mogą istnieæ podsieci dla kaŋdego z dialektów, sub-dialektów i socjolektów. Języki "ŋyjące" w przeciwieņstwie do "martwych" języków, takich jak ģacina, równieŋ są dynamiczne, a nowe sģowa i wyraŋenia są stale tworzone w celu opisania nowych koncepcji i pomysģów, a te nowe sģowa i wyraŋenia są rozpowszechniane za poķrednictwem ģączy w sieciach spoģecznoķciowych. Model zmiany języka dostępny w bibliotece modeli w NetLogo pokazuje, w jaki sposób struktura sieci spoģecznoķciowej w poģączeniu z odmianami uŋytkowników języka moŋe wpģynąæ na zmianę języka. W tym modelu węzģy w sieci reprezentują uŋytkowników języka i istnieją dwa warianty języka generowane przez dwie róŋne gramatyki (0 i 1) w konkurencji w sieci. Uŋytkownicy języka kontaktują się ze sobą w kaŋdej iteracji symulacji, mówiąc najpierw gramatykę 0 lub 1 do sąsiadów, z którymi są poģączeni w sieci spoģecznoķciowej. Podczas kolejnego sģuchania .Następnie dostosowują swoją gramatykę w oparciu o to, co zostaģo odebrane podczas fazy mówienia. Zrzut ekranu przedstawiający przykģadowe dane wyjķciowe wytworzone przez model przedstawiono na rysunku
Dane wyjķciowe zostaģy wygenerowane przy uŋyciu domyķlnych ustawieņ i algorytmu aktualizacji nagrody. Biaģe węzģy na rysunku reprezentują uŋytkowników języka, którzy uzyskują dostęp do gramatyki, czarne węzģy mają dostęp do gramatyki 0. Czerwone zacienione węzģy reprezentują uŋytkowników języka, którzy mają moŋliwoķæ korzystania z obu gramatyk. Kolor reprezentuje prawdopodobieņstwo, ŋe uzyskają dostęp do gramatyki 1 lub 0, im większe prawdopodobieņstwo, tym ciemniejsze cieniowanie. Wybór kodu w modelu jest pokazany w kodzie NetLogo
breed [nodes node]
nodes-own [
state ; obecny stan gramatyki - [0,1]
orig-state ; zapisz, aby zresetowaæ oryginalne stany
spoken-state ; przechowuje wyniki mowy agenta - 1 lub 0
]
to communicate-via [ algorithm ] ; procedura węzģa
;; *Probabilistic Grammar* ;;
;; mów i poproķ wszystkich sąsiadów, aby sģuchali
if (algorithm = "reward") [
speak
ask link-neighbors [
listen [ spoken-state ] of myself
]
end
;;; sģuchanie wykorzystuje liniowy algorytm nagrody / kary
to listen [heard-state] ; node procedure
let gamma 0.01 ; for now gamma is the same for all nodes
;; wybierz stan gramatyki
ifelse (random-float 1.0 <= state) [
;; jeķli sģychaæ gramatykę 1
ifelse (heard-state = 1) [
set state (state + (gamma * (1 - state)))
][
set state (1 - gamma) * state
]
][
;; jeķli sģychaæ gramatykę 0
ifelse (heard-state = 0) [
set state (1 - gamma) * state
][
set state gamma + ((1 - gamma) * state)
]
]
end
to update-color
set color scale-color red state 0 1
end
Uŋytkownik języka jest zdefiniowany jako typ node na początku, a kaŋdy węzeģ jest wģaķcicielem zmiennej state, liczby między 0 a 1, która jest wagą, która odzwierciedla prawdopodobieņstwo uzyskania przez uŋytkownika gramatyki 0 lub 1. Procedura communicate-via listuje kod związany tylko z algorytmem aktualizacji nagrody (istnieją dwa inne algorytmy aktualizacji nieuwzględnione tutaj - indywidualne i próg - które mogą byæ uŋywane do tworzenia róŋnych zachowaņ sieciowych). Za pomocą algorytmu aktualizacji nagrody bieŋący agent węzģa najpierw mówi, a następnie sģucha wszystkich swoich sąsiadów w sieci. Algorytm wykorzystuje liniową nagrodę /schemat waŋenia kary, jak pokazano w procedurze listen, aby ustawiæ zmienną state agenta węzģa. W dolnej częķci listy kodów uwzględniono procedurę update-color, aby pokazaæ, w jaki sposób ustawiony jest kolor agenta węzģa, w zaleŋnoķci od aktualnego wag gramatycznych przechowywanych w zmiennej state. Wiele przebiegów modelu pokazuje, ŋe uŋytkownicy języka w symulacji mają skģonnoķæ do uŋywania jednej gramatyki dominującej w sieci spoģecznoķciowej. Jednak często inna gramatyka wciąŋ pozostaje w kieszeniach w caģej sieci, co odzwierciedla tworzenie dialektów i podtekstów w ludzkich sieciach spoģecznoķciowych w prawdziwym ŋyciu.
Zachowanie komunikacyjne
Zachowanie komunikacyjne ma wiele postaci. Przez większoķæ historii ludzka komunikacja byģa ograniczona do kilku podstawowych form, takich jak mówienie i pisanie, ale w ciągu ostatniego stulecia ludzkie zachowania komunikacyjne ulegģy szybkiej transformacji z powodu postępu technologicznego umoŋliwiającego nowe formy komunikacji, które wczeķniej nie byģy moŋliwe. na przykģad nadawanie, a ostatnio pisanie wiadomoķci i blogowanie. Technologia zaciera takŋe charakter istniejącej komunikacji - podczas gdy bezpoķrednia bezpoķrednia dostawa byģa moŋliwa w niektórych formach, awans umoŋliwiģ nam rozszerzenie o wersje takie jak opóžnione dostawy jeden-do wielu - na przykģad radio i telewizja jest teraz transmitowany przez transmisję strumieniową i dlatego nie ma juŋ potrzeby natychmiastowego sģuchania lub oglądania tych mediów, poniewaŋ dostępne są alternatywne ķrodki komunikacji, w których moŋemy poczekaæ do dogodniejszego czasu. Aby zilustrowaæ, w jaki sposób zachowania komunikacyjne wpģywają na sposób rozprzestrzeniania się języka w sieci spoģecznoķciowej, moŋemy przeprowadziæ symulacje przy uŋyciu modeli NetLogo. Pierwszy model komunikacji T-T, który jest doģączony do biblioteki modeli NetLogo, stanowi prostą ilustrację tego, jak komunikacja "szeptana" moŋe byæ niezwykle skuteczna w rozpowszechnianiu wiadomoķci w sieci. Zrzut ekranu modelu w akcji pokazano na rysunku

Model dziaģa najpierw tworząc liczbę agentów na losowych pozycjach w ķrodowisku, z których jeden jest okreķlony jako agent, który rozpoczyna rozprzestrzenianie wiadomoķci. Następnie, podczas symulacji, agenci poruszają się losowo, a ci, którzy otrzymają wiadomoķæ, będą ją rozpowszechniaæ za poķrednictwem poczty pantoflowej do wszelkich agentów znajdujących się w pobliŋu. Rysunek pokazuje symulację na wczesnym etapie - wiadomoķæ zostaģa rozģoŋona tylko niewielkiemu odsetkowi czynników (te zabarwione na czerwono); w koņcu wiadomoķæ szybko rozprzestrzeni się na wszystkich agentów w ķrodowisku. Jednak nawet na tym etapie symulacji widaæ wyražnie, jak dziaģa metoda komunikacji "szeptana" i dlaczego jest tak skuteczna. Wiadomoķæ zostaģa przekazana do grup agentów, którzy są blisko siebie. Gromady te szybko rosną i przejmują caģą sieæ, podobnie jak falujący efekt fal rozprzestrzeniających się po stawie po wrzuceniu do niego kamienia. Kod modelu jest pokazany w kodzie NetLogo
turtles-own [
message? ;; prawda czy faģsz: czy ten ŋóģw otrzymaģ juŋ wiadomoķæ?
]
to setup
clear-all
crt 400 [
set shape "Person"
set size 2
set message? false
setxy random-xcor random-ycor
]
ask one-of turtles
[ set message? true ] ;; przekaŋ wiadomoķæ jednemu z ŋóģwis
ask turtles [ recolor ]
end
to go
ask turtles [ move ]
ask turtles [ communicate ]
ask turtles [ recolor ]
tick
end
;; poruszaæ się losowo
to move ;; procedura ŋóģwia
fd random 4
;; obróæ losową kwotę między -40 a 40 stopni,
;; utrzymując ķredni obrót na poziomie 0
rt random 40
lt random 40
end
;; podstawowa procedura!
to communicate ;; procedura ŋóģwia
if any? other turtles-here with [message?]
[ set message? true ]
end
; kolor ŋóģwie z komunikatem czerwony, a te bez komunikatu niebieski
to recolor ;; procedura ŋóģwia
ifelse message?
[ set color red ]
[ set color blue ]
end
Kod zostaģ nieznacznie zmodyfikowany do celów wizualizacji z tego udostępnianego przez bibliotekę modeli, zmniejszając liczbę utworzonych agentów i zmieniając rozmiar i ksztaģt agentów. Procedura konfiguracji tworzy 400 agentów ŋóģwia w losowych lokalizacjach, z których jeden jest oznaczony jako mający wiadomoķæ na początku. Podczas procedury go kaŋdy agent najpierw przemieszcza się w przypadkowym kierunku, a następnie kaŋdy agent, który ma ten komunikat, przesyģa komunikat do dowolnego innego agenta, który znajduje się w tej samej lokalizacji poprawki, a na koņcu kolory kaŋdego agenta są resetowane, aby odzwierciedliæ, czy mają wiadomoķæ, czy nie.
Zjawisko maģego ķwiata i algorytm Dijkstry
Kolejny model NetLogo, model Being Kevin Bacon, zostaģ stworzony, aby dowiedzieæ się, w jaki sposób róŋne formy komunikowania się zachowują w rozpowszechnianiu informacji w sieci spoģecznoķciowej. Zanim jednak wytģumaczymy ten model, musimy poznaæ waŋną cechę charakterystyczną sieci zwanych "zjawiskiem maģego ķwiata" i związaną z nim frazę "szeķæ stopni separacji". Zjawisko maģego ķwiata zostaģo po raz pierwszy zbadane przez Stanleya Milgrama, psychologa spoģecznego na Uniwersytecie Yale. Przeprowadziģ eksperyment, aby pokazaæ, ŋe jesteķmy przeciętnie tylko o szeķæ "kroków" od kogokolwiek innego na Ziemi. W eksperymencie listy zostaģy wysģane do losowo wybranych osób w Omaha i Wichita w USA. Ludzie ci zostali zapytani, czy znali osobę X mieszkającą w Bostonie. Jeķli nie, poproszono ich o przesģanie tego listu do kogoķ, kogo mogliby znaæ X. Wyniki eksperymentu byģy następujące: 64 z 256 wysģanych listów dotarģo do celu; niektóre ģaņcuchy udanych listów miaģy tylko 1 lub 2 dģugoķci, podczas gdy inne miaģy ponad 10 dģugoķci. Co istotne, ķrednia dģugoķæ ķcieŋki wynosiģa okoģo 5,5 do 6 - stąd pochodzi zdanie "szeķæ stopni separacji". Chodzi o to, ŋe nawet w bardzo duŋej sieci, prosta metoda rozprzestrzeniania wiadomoķci za pomocą ustnej wiadomoķci moŋe byæ niezwykle skuteczna z powodu efektu marszczenia w miarę rozprzestrzeniania się wiadomoķci. Chociaŋ wiadomoķæ zawarta w tym eksperymencie zostaģa spisana raczej niŋ mówiona, metoda ta moŋe nadal byæ uwaŋana za analogiczną do komunikacji ustnej w ludziach, poniewaŋ bezpoķredni kontakt jest nadal wymagany, aby rozpowszechniaæ przesģanie, choæby za poķrednictwem trzeciego agenta przekazującego, listonosza. separacja jest uŋytecznym ķrodkiem do pomiaru ģącznoķci sieci, niezaleŋnie od tego, czy jest to sieæ spoģecznoķciowa, czy sieæ komputerowa. Wiele sieci zawiera tak zwane "super-węzģy" - koncentratory, które są poģączone z wieloma innymi węzģami w sieci. Tutaj liczba poģączeņ, które hub ma z innymi węzģami, jest znacznie większa niŋ ķrednia liczba poģączeņ na węzeģ. Te koncentratory mogą pomóc w szybkoķci rozprzestrzeniania komunikacji w sieci, poniewaŋ po dotarciu komunikatu do koncentratora, wiadomoķæ moŋe natychmiast dotrzeæ do większej częķci sieci bez koniecznoķci przechodzenia przez kolejne węzģy poķrednie. W dowolnej sieci moŋemy zidentyfikowaæ koncentrator, a następnie okreķliæ stopieņ oddzielenia od niego danego węzģa - czyli liczbę węzģów, które naleŋy odwiedziæ wzdģuŋ najkrótszej ķcieŋki od węzģa do koncentratora. W sieci spoģecznoķciowej moŋe to byæ pomocne w okreķleniu, jak "bliska" jest jedna osoba dla sģawnej osoby - im bliŋej celebryty, tym większa odzwierciedlona chwaģa. Matematycy uŋywali w rzeczywistoķci liczby zwanej liczbą Erdösa, aby zmierzyæ dystans wspóģpracy znanego i pģodnego węgierskiego matematyka, Paula Erdösa, który miaģ setki wspóģpracowników i pracowaģ w wielu dziedzinach, w tym w kombinatoryce, teorii grafów, teorii liczb, teoria mnogoķci i teoria prawdopodobieņstwa. Liczba Erdösa jest obliczana rekurencyjnie w następujący sposób:
• Jeķli masz artykuģ wspóģtworzony przez Erdösa, masz numer Erdös 1.
• W przeciwnym razie, jeķli masz artykuģ opublikowany ze wspóģautorem, który ma numer Erdös 1, masz numer Erdös 2.
• W przeciwnym razie, jeķli masz artykuģ opublikowany ze wspóģautorem, który ma liczbę Erdös n, masz liczbę Erdös n + 1.
Metryki odlegģoķci moŋna ģatwo zastosowaæ w innych sieciach, a nie tylko w sieciach osób publikujących artykuģy naukowe. Bardzo odmienną siecią jest sieæ aktorów, którzy zagrają w filmach - tutaj jako "centrum" wszechķwiata aktorów filmowych zostaģo wybrane jako Kevin Bacon, amerykaņski aktor filmowy i teatralny, który zagraģ w wielu filmach, takich jak JFK, Apollo 13 i Footloose. Liczba Kevina Bacona obliczana jest w następujący sposób:
• Jeķli zagraģeķ w filmie z Kevinem Baconem, masz numer Kevina Bacona 1.
• W przeciwnym razie, jeķli zagraģeķ w filmie z gwiazdą, który ma numer Kevina Bacona 1, masz numer Kevina Bacona 2.
• W przeciwnym razie, jeķli zagraģeķ w filmie z kimķ, kto ma numer Kevin Bacon n, masz numer Kevina Bacona n + 1.
Liczby Erdösa i Kevina Bacona dostarczają przybliŋonych miar stopnia przynaleŋnoķci danej osoby do konkretnej spoģecznoķci, takiej jak Matematycy i / lub aktorzy filmowi - im wyŋsze liczby, tym mniejsze zaangaŋowanie w tę spoģecznoķæ. W kaŋdej spoģecznoķci istnieją osoby, które są równieŋ czģonkami innych spoģecznoķci, i często te osoby mogą szybciej rozpowszechniaæ wiadomoķci, szczególnie między najbardziej rozģącznymi spoģecznoķciami, w których interakcja jest minimalna - to znaczy, gdy komunikacja między spoģecznoķciami jest znacznie mniejsza niŋ wewnątrz organizacji. komunikacja spoģeczna. Osoby z wieloma czģonkostwami sģuŋą do rozpowszechniania pomysģów lub wiadomoķci, które mogą byæ dobrze znane w ramach jednej spoģecznoķci innym spoģecznoķciom, w których ta sama wiadomoķæ moŋe byæ mniej znana lub nawet zupeģnie nieznana. W badaniach akademickich często dokonano waŋnych przeģomów, na przykģad dzięki interdyscyplinarnym badaniom. Poniewaŋ moŋemy zmierzyæ stopieņ oddzielenia od jednej dobrze znanej osoby w danej spoģecznoķci, moŋemy zmierzyæ poģączone rozdzielenie z dwóch lub więcej spoģecznoķci. Dla spoģecznoķci matematyków i aktorów filmowych mamy numer Erdös-Bacon, który jest sumą liczby Erdösa plus liczba Kevina Bacona. Nie jest niespodziewanie, niewielu ludzi ma zarówno numer Erdösa, jak i numer Kevina Bacona, co ķwiadczy o niewielkiej interakcji między matematykami a aktorami filmowymi. Istnieją jednak i są pewne godne uwagi wyjątki, takie jak astronom Carl Sagan i fizyk teoretyczny Stephen Hawking, a takŋe Natalie Portman, aktorka znana z roli w filmach Gwiezdnych wojen. Natalie Portman ma numer 5 Erdös ze względu na autorstwo artykuģów psychologicznych podczas studiów Harvard w dziedzinie psychologii. Ma równieŋ numer Kevina Bacona 1 (zagraģa w filmie Nowy Jork, Kocham cię z Kevinem Baconem). Jej liczba Erdös-Bacon wynosi zatem 6 (5 + 1). Mamy teraz tģo, aby przyjrzeæ się modelowi Being Kevin Bacon NetLogo. Zrzut ekranu przedstawia model.
W ķrodowisku NetLogo pokazana jest losowo wygenerowana sieæ. Sģuŋy ona do symulacji skutecznoķci róŋnych metod komunikacyjnych, pomagając w rozprzestrzenianiu wiadomoķci w caģej sieci. Sieæ w tym przypadku zawiera 65 węzģów, z których dwa to supernody. Normalne węzģy mają losowa liczba poģączeņ od jednego do 5, a super-węzģy mają losową liczbę poģączeņ do 50. Kod uŋywany do generowania sieci jest pokazany w NetLogo Code
to create-network [number-of-nodes]
;; Tworzy liczbę nowych węzģów w sieci.
create-nodes number-of-nodes
[
set blackboard table:make ;; used by walkers if applying the blackboard
;; metoda dzielenia się wiedzą
ifelse (random 100 < percent-in-both)
[ set link-type 0 ;; zarówno erdos, jak i węzeģ bekonowy
set color red
set label (word "eb" who " ") ]
;jeszcze
[ ifelse (random 2 = 0)
[ set link-type 1 ;; węzeģ erdos
set color lime
set label (word "e" who " ") ]
[ set link-type 2 ;; węzeģ boczek
set color blue
set label (word "b" who " ") ]]
]
set erdos-set nodes with [link-type = 1 or link-type = 0] ;; węzeģ erdos
set bacon-set nodes with [link-type = 2 or link-type = 0] ;; węzeģ boczek
end
to setup-network
clear-all
set-default-shape nodes "circle 2"
set-default-shape dwalkers "person"
;; utwórz losową sieæ
reset-counts
set max-distance 999999
;; liczba ta musi byæ większa niŋ maksymalna dģugoķæ ķcieŋki w sieci
if (network-update > 0)
[ set network-update-count random network-update ]
create-network no-of-nodes
set paul-erdos min-one-of erdos-set [ who ]
set kevin-bacon min-one-of bacon-set [ who ]
ask paul-erdos [ set color magenta set paul-erdos-no who ]
ask kevin-bacon [ set color orange set kevin-bacon-no who ]
create-network-links
reset-layout
end
Generowane są trzy typy węzģów - węzģy naleŋące do zestawu Paula Erdösa (są to kolorlimonki ), węzģy naleŋące do zestawu Kevina Bacona (kolor niebieski) i te, które naleŋą do obu (kolor czerwony). Procent suwaka w obu przypadkach sģuŋy do okreķlenia szansy, ŋe węzeģ zostanie losowo wygenerowany i będzie naleŋaģ do obu zestawów; w przeciwnym razie węzeģ zostanie losowo wybrany do jednego z zestawów Paula Erdösa lub zestawu Kevina Bacona. Etykiety węzģów są pokazane obok węzģów w ķrodowisku z ich agentem, którego numer jest poprzedzany przez "e", jeķli są w zestawie Paula Erdösa, "b", jeķli są w zestawie Kevina Bacona i "eb", jeķli są są w obu. Węzeģ powiązany z Paulem Erdösem zostaģ wybrany jako węzeģ z zestawu Paula Erdösa z minimalną liczbą osób (jest to kolorowa magenta i oznaczona jako "e1" w ķrodkowej prawej częķci otoczenia), podobnie jak dla węzģa Kevina Bacona (kolorowego pomaraņczowy i oznaczony "b0" blisko doģu po lewej). Po utworzeniu sieci moŋemy uzyskaæ agentów spacerowiczów, którzy "przeszukują" ją, wykonując róŋne zadania. Jednym z zadaņ moŋe byæ znalezienie ķredniego stopnia rozdzielenia węzģów w sieci od okreķlonego węzģa; w modelu ten węzeģ jest wyznaczony przez centrum suwaka wszechķwiata. Dobrze znanym algorytmem do wykonywania tych obliczeņ jest algorytm Dijkstry. Algorytm zostaģ zaimplementowany w modelu Being Kevin Bacon - kod znajduje się w kodzie NetLogo
to initialise-distances [initial-node]
;; inicjuje najkrótsze odlegģoķci między węzģami sieci do 0
let number-of-nodes max [who] of nodes + 1
set dijkstra-distances array:from-list n-values number-of-nodes
[number-of-nodes + 1] ;; "nieskoņczonoķæ"
set dijkstra-directions array:from-list n-values number-of-nodes [nobody]
array:set dijkstra-distances initial-node 0
;; (ustawia odlegģoķæ na 0 dla początkowego węzģa)
end
to perform-dijkstra [initial-node nodes-to-visit]
;; oblicza tablicę odlegģoķci dla algorytmu Dijkstra przy uŋyciu
;; węzeģ początkowy jako punkt centralny
set nodes-visited 0
initialise-distances [who] of initial-node
let visited-set [] ;; this is the list of nodes that have been visited
let unvisited-set nodes-to-visit
;; jest to lista węzģów, które jeszcze nie zostaģy odwiedzone
let this-dwalker nobody
if (animate-dijkstra)
[ create-dwalkers 1
[ set color white
set size 2
set this-dwalker who ]]
let current-node initial-node
while [count unvisited-set > 0]
[
if (animate-dijkstra)
[ ask dwalker this-dwalker
[ setxy [xcor] of current-node [ycor] of current-node
display
wait 0.1 ]]
ask current-node
[
set nodes-visited nodes-visited + 1
set visited-set fput who visited-set
set unvisited-set other unvisited-set
ask link-neighbors
[
let dist-thru-here
(array:item dijkstra-distances [who] of current-node) + 1
let dist-thru-to-there array:item dijkstra-distances who
if (dist-thru-here < dist-thru-to-there)
[ array:set dijkstra-distances who dist-thru-here
array:set dijkstra-directions who [who] of current-node ]
]
;; ustaw bieŋący węzeģ na pozostaģy nie odwiedzony węzeģ, który ma
;; najmniejsza odlegģoķæ do początkowego węzģa
set current-node min-one-of unvisited-set
[array:item dijkstra-distances who]
]
]
;;
print array:to-list dijkstra-distances
if (animate-dijkstra)
[ wait 0.2 ask dwalker this-dwalker [ die ]]
end
to go-dijkstra
;; Uruchom bezpoķrednio za pomocą przycisku interfejsu - oblicza tablicę odlegģoķci
;; dla algorytmu Dijkstra
let initial-node nobody
ifelse (centre-of-the-universe = "Paul Erdos")
[ set initial-node paul-erdos ]
;; ustaw węzeģ początkowy na węzeģ powiązany z Paulem Erdosem
[ set initial-node kevin-bacon ]
;; ustaw węzeģ początkowy na węzeģ powiązany z Kevinem Baconem
initialise-distances [who] of initial-node
let nodes-to-visit []
;; (jest to lista węzģów, które jeszcze nie zostaģy odwiedzone))
ifelse (centre-of-the-universe = "Paul Erdos")
[ set nodes-to-visit erdos-set ]
[ set nodes-to-visit bacon-set ]
perform-dijkstra initial-node nodes-to-visit
dump-dijkstra-directions
plot-dijkstra
end
Algorytm dziaģa, gdy agenci spacerujący indeksują sieæ, aktualizując najkrótsze odlegģoķci ķcieŋek w trakcie ich dziaģania. Odlegģoķci te są przechowywane w strukturze danych tablicy, która jest rozszerzeniem do NetLogo. Procedura perform-dijkstra wykonuje obliczenia zwracane w dijkstradystancjach tablicy odlegģoķci. Ta tablica ma licznik odlegģoķci skojarzony z kaŋdym węzģem (indeksowany przez numer węzģa), który jest stopniowo aktualizowany przez agentów spaceeujących podczas przeszukiwania sieci. Algorytm utrzymuje dwa zestawy - zestaw węzģów, które jeszcze nie odwiedziģ, oraz zestaw węzģów, które ma. Pierwszy odwiedzony węzeģ jest wybierany jako węzeģ powiązany z węzģem docelowym (to znaczy węzģem związanym z centrum Wszechķwiata lub Kevin Bacon w tym przykģadzie). Dla kaŋdego odwiedzanego węzģa jest on najpierw dodawany do juŋ odwiedzonego zestawu, aby nie byģ ponownie odwiedzany, a następnie algorytm aktualizuje liczniki odlegģoķci dla wszystkich jego sąsiadów ģącza, w których odlegģoķæ do węzģa docelowego byģaby krótsza w stosunku do bieŋącego węzģa. Bieŋący węzeģ jest następnie ustawiony na węzeģ w nieodwiedzonym zbiorze, który ma najmniejszą odlegģoķæ od początkowego węzģa docelowego. W modelu Being Kevin Bacon, algorytm Dijkstra jest wykonywany przez kliknięcie przycisku go-djijkstra w interfejsie. Po zakoņczeniu wyķwietli się okno dialogowe z informacją, jaka jest ķrednia odlegģoķæ najkrótszej ķcieŋki, następnie wykreķli najkrótszą ķcieŋkę, odlegģoķci dla kaŋdego węzģa na dolnym wykresie pokazanym w prawym dolnym rogu rysunku.
Uŋywanie agentów komunikacyjnych do wyszukiwania sieci
Kolejnym zadaniem, które moŋemy wykonaæ dla agentów walkerów, jest symulowanie przeszukiwania sieci, takiego jak w rzeczywistych ludzkich sieciach spoģecznoķciowych lub komputerowych sieciach peer-to-peer. W tym miejscu wielu agentów przeszukuje sieæ jednoczeķnie bez uprzedniej wiedzy, aby znaležæ róŋne węzģy celu z róŋnych punktów początkowych w sieci. Na przykģad w sieciach typu peer-to-peer występuje problem zwany wykrywaniem zasobów, gdy uŋytkownik musi znaležæ okreķlony zasób w sieci typu peer-to-peer. Zasobem moŋe byæ konkretny plik, który chce pobraæ, lub komputer z niezbędną mocą obliczeniową lub pamięcią, który jest wymagany do zdalnego wykonania programu. Symulacja wdroŋona przez model Being Kevin Bacon polega na stworzeniu agentów spacerowiczów, którzy chodzą po sieci, próbując dotrzeæ do wybranego węzģa celu wybranego losowo. Wiedza dotycząca lokalizacji węzģów w sieci jest przekazywana przy uŋyciu róŋnych metod komunikacji - model implementuje pięæ: metoda o nazwie none, w której agenty nie komunikują niczego, gdy się krzyŋują; metoda zwana "word-of-mouth", która jest analogiczna do zachowania komunikacji ustnej; metoda zwana blackboard która jest analogiczna do zachowania komunikacyjnego która wykorzystuje stygmergię, jak omówiono w sekcji wczeķniej ; oraz dwie metody (combined 0 i combined 1), które ģączą metody komunikacji w mowie i na tablicy. Metoda Blackboard opiera się na architekturze sztucznej inteligencji o tej samej nazwie, w której agenci wspóģdzielą i aktualizują wspólną bazę wiedzy. Architektura tablicy jest analogiczna do tego, w jaki sposób tablice uŋywane są w klasach i podczas wykģadów. Tablica sģuŋy jako medium, za poķrednictwem którego przekazywane są idee. W komunikacji ludzkiej osoby w klasie lub w teatrze wykģadowym mają moŋliwoķæ czytania w czasie wolnym (lub ignorowania) tego, co zostaģo napisane na tablicy. Odmiana architektury tablicowej uŋytej w symulacji polega na tym, ŋe zamiast uŋywaæ jednej tablicy, kaŋdy węzeģ ma wģasną tablicę. Kaŋdy przechodzący agent spacerowy moŋe wybraæ odczytanie informacji zapisanych na tablicy węzģa lub moŋe zignorowaæ to; jednak w modelu agenci piechurów zawsze wybierają odczyty i aktualizują tablice węzģów. Przechowywane informacje to odlegģoķæ, jaką trzeba pokonaæ, aby dostaæ się do innego węzģa w sieci, wybierając okreķloną ķcieŋkę z bieŋącego węzģa. Jest on aktualizowany, gdy walker zwraca ķcieŋkę do węzģa, z którego zacząģ. Ŋadne inne informacje nie są przechowywane na tablicy - na przykģad peģna ķcieŋka dostępu do węzģa celu nie jest przechowywana - tylko informacja, ile czasu zajęģo, aby wybraæ konkretną ķcieŋkę. Jeķli póžniejszy piechur znajdzie krótszą trasę za pomocą innej ķcieŋki, wówczas mniejsza wartoķæ odlegģoķci zostanie zapisana na tablicy. Jeķli na tablicy nie ma ŋadnych wczeķniejszych informacji, agenci piechoty dokonają losowego wyboru, gdzie dalej iķæ. Kod do aktualizacji tablic jest pokazany w NetLogo Code Procedura update-along-path aktualizuje tablice wzdģuŋ ķcieŋki walkera, this-walker jeķli ķcieŋka do celu jest krótsza.
to update-along-path [this-walker value]
;; aktualizuje informacje wzdģuŋ ķcieŋki, gdy metoda dzielenia się wiedzą
;; to Tablica lub kombinacja
let p 0
let val 0
let val1 0
let key-dist ""
let key-path ""
if knowledge-sharing = "Blackboard" or
knowledge-sharing = "Combined 1" or
knowledge-sharing = "Combined 2"
[
ask this-walker
[
;;wpisz goal = wpisz goal wpisz path = " show path
let this-goal goal
let prev first path
foreach but-first path
[
set key-dist (word this-goal " dist")
set key-path (word this-goal " path")
ifelse (value = "F")
[ set val max-distance ] ;; failure - node was not found
[ set val p + 1 ] ;; calculate the position in the path
if is-turtle? ? ;; does the node exist? (it may have been deleted)
[
ask ?
;; aktualizuj tablice wzdģuŋ ķcieŋki, jeķli droga do celu jest krótszar
[ ifelse (not table:has-key? blackboard key-dist)
[ set val1 max-distance + 1 ]
;; (ŋaden wpis nie istnieje - upewnij się, ŋe dodano nowy wpis)
[ set val1 table:get blackboard key-dist ]
if (val < val1)
[ table:put blackboard key-dist val
table:put blackboard key-path prev ]]
]
set prev ?
set p p + 1
]]
]
end
Kod uŋywa rozszerzenia tabeli do NetLogo, gdzie wartoķci powiązane z kluczami wyszukiwania mogą byæ przechowywane i pobierane w tabeli mieszania. Istnieją dwa rodzaje kluczy uŋywanych do tablicy, klucz do przechowywania wyboru ķcieŋki i klucz do przechowywania jej odlegģoķci. Przycisk dump-blackboards moŋna kliknąæ w interfejsie, aby zrzuciæ zawartoķæ wszystkich tablic węzģów. Zrzut tablicy z wpisami dla dwóch węzģów docelowych moŋe wyglądaæ następująco:
Kluczowy ciąg zawiera najpierw listę zawierającą ciąg "węzeģ", po którym następuje numer docelowego węzģa, który moŋna znaležæ, podąŋając za odnoķnikiem okreķlonym przez klucz ķcieŋki. W przykģadzie, dwoma węzģami docelowymi są węzģy 59 i 52. Pierwszy z nich moŋna osiągnąæ wzdģuŋ ķcieŋki z odlegģoķcią 8, podąŋając za ģączem do węzģa 11, ten ostatni wykonuje 6 kroków, jeķli następuje to samo ģącze z węzģem 11. Symulacja modelu rozpoczyna się od kliknięcia przycisku go-walkers. Pojedyncza iteracja symulacji moŋe zostaæ wykonana poprzez kliknięcie przycisku go-walkers-once. Wielokrotne symulacje pokazują, ŋe metoda komunikacji w Tablicy zaimplementowana w symulacji konsekwentnie przewyŋsza metodę komunikacji "z ust do ust". Odzwierciedla to wyniki eksperymentalne symulacje dla problemu wykrywania zasobów w sieciach peer-to-peer. Podczas symulacji modelu NetLogo, ķcieŋka, którą poruszają się spacerowicze, jest pokazana poprzez zwiększenie szerokoķci przekierowanego poģączenia, jak pokazuje grubsze biaģe linie na Rysunku. Po prawej stronie zauwaŋ, istnieją pewne statystyki, które zostaģy zebrane podczas symulacji. W prawym dolnym rogu znajdują się cztery monitory, które wyķwietlają liczbę węzģów (65 na rysunku), aktualną liczbę agentów (12), liczbę węzģów odwiedzonych przez spacerowiczów (30) i procentowy sukces, jaki mieli spacerowicze. w znalezieniu węzģa celu (67,34%). Wykres w prawym górnym rogu wykresu pokazuje liczbę walkerów w stosunku do tick. Agenci wędrują dalej, dopóki nie znajdą węzģa celu lub przekroczą czas, jaki time-to-live (w tym przypadku ustawiono 20 ticków). Wykres pokazuje, ŋe początkowo liczba spacerowiczów roķnie do momentu przekroczenia przez agentów spacerujących zmiennej time-to-ive, a następnie nadal spada, poniewaŋ coraz więcej agentów spacerowych zaczyna znajdowanie węzģa celu bardziej regularnie, niŋ wiedza zawarta w tablicach i / lub transmitowane przez sģowo z ust staje się bardziej skuteczny w ograniczaniu poszukiwania nowych agentów. Ķrodkowy wykres przedstawia odsetek udanych wyszukiwaņ w porównaniu z caģkowitą liczbą wyszukiwaņ; niewielki wzrost nachylenia wskazuje na efekt uczenia się, poniewaŋ większa wiedza jest przechowywana lub przesyģana. Dolny wykres jest wynikiem dziaģania algorytmu Dijkstra, jak omówiono powyŋej. Kod, który zostanie wykonany po kliknięciu przycisku go-walkers, jest wyķwietlany w kodzie NetLogo
to go-walkers
;; zmusiæ spacerowiczów do kontynuowania wyszukiwania
if (simulation-ticks > 0) and (ticks > simulation-ticks)
[ stop ]
update-network
setup-walkers
ask links [ set thickness 0 ]
ask walkers
[
set nodes-visited nodes-visited + 1
ifelse (ticks-alive >= time-to-live)
;;ŋyģ zbyt dģugo bez sukcesu - zabij to
[ set unsuccessful-searches unsuccessful-searches + 1
update-along-path self "F"
;; w razie potrzeby zaktualizuj informacje wzdģuŋ ķcieŋki; F oznacza awarię
]
[ ;; utwórz nowych spacerowiczów, aby przenieķæ się do nowej lokalizacji
expand-walkers (next-locations location)
]
die ;; zawsze umieraj - stwory zostaģy juŋ wysģane
;; kontynuuj poszukiwanie mnie
]
plot-walkers
tick
end
to expand-walkers [new-locations-list]
let new-walkers-count length new-locations-list
let new-location 0
hatch-walkers new-walkers-count
[ ;; utwórz nową walker w miejscu, aby kontynuowaæ wyszukiwanie
;; i przenieķ się do nowej lokalizacji
set ticks-alive ticks-alive + 1
;; zjedž z następnej lokalizacji do odwiedzenia:
set new-location first new-locations-list
set new-locations-list but-first new-locations-list
ifelse (not revisits-allowed and member? new-location path)
[ die ] ;; nie odwiedzaj ponownie węzģów, które juŋ odwiedziģeķ, chyba ŋe masz na to zgodę
[
if (new-location != nobody) and
([link-with new-location] of location != nobody)
[
;; podķwietl link jaki pzekraczam
ask [link-with new-location] of location [ set thickness 0.4 ]
face new-location
move-to new-location
set location new-location
set path fput new-location path
if new-location = goal ;; success-no need to hang around any longer
[ set successful-searches successful-searches + 1
;; w razie potrzeby zaktualizuj informacje wzdģuŋ ķcieŋki; S oznacza sukcess
update-along-path self "S"
die ] ;; die happy
]]
]
end
Procedura go-walkers najpierw aktualizuje sieæ, dodając lub usuwając losowe węzģy w sieci, jeķli sieæ jest dynamiczna. Ma to na celu symulację sieci, w których węzģy nieustannie się zmieniają; szybkoķæ zmian moŋna kontrolowaæ za pomocą suwaków network-update, nodes-to-ad i nodes-to-delete modelu interfejsu . Jeķli network-update jest ustawiona na 0, sieæ staje się statyczna bez dodawania nowych węzģów lub usuwania kaŋdego tiku.Procedura go -walkers zeruje następnie gruboķæ linii wszystkich linków do 0, a następnie pyta kaŋdego aktualnie aktywnego agenta, czy trwa zbyt dģugo (tj. time-to-live). Jeķli tak, tablice na ķcieŋce odwiedzonej przez spacerówki są aktualizowane przez zapisanie duŋej liczby max-distance w celu odzwierciedlenia, ŋe ķcieŋka zostaģa uszkodzona (ta liczba zostaģa zainicjowana w kodzie NetLogo, i musi byæ liczbą znacznie większą niŋ maksymalna dģugoķæ dowolnej ķcieŋki w sieci). W przeciwnym razie wyszukiwanie zostanie rozszerzone poprzez wywoģanie procedury expand-walkers, która wykluczy nowych spacerowiczów w celu przeniesienia do nowych lokalizacji w sieci i zaktualizuje tablice, jeķli ķcieŋka wyszukiwania zakoņczyģa się powodzeniem. Następnie bieŋący piechur moŋe umrzeæ, poniewaŋ juŋ przekazaģ pozostaģą częķæ poszukiwaņ spacerowiczom stworzonym przez procedurę expand-walkers. Przyjrzymy się teraz probabilistycznemu podejķciu do charakteryzowania komunikacji opartej na teorii informacji, aby pomóc nam w dalszym badaniu natury komunikacji i języka.
Entropia i informacje
W teorii informacji, entropia zapewnia ķrodki do pomiaru informacji przesyģanych między ķrodkami przekazującymi w kanale komunikacji. Entropia to ķrednia liczba bitów wymaganych do przekazania komunikatu między dwoma agentami w kanale komunikacji. Zasadnicze twierdzenie o kodowaniu (Shannon, 1948) stwierdza, ŋe dolna granica do ķredniej liczby bitów na symbol potrzebnych do zakodowania wiadomoķci (tj. sekwencji symboli, takich jak tekst) przesģanych kanaģem komunikacyjnym, jest okreķlona przez jej entropię):
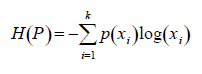
gdzie jest k moŋliwych symboli z rozkģadem prawdopodobieņstwa i gdzie prawdopodobieņstwa są niezaleŋne i sumują się do 1. Jeķli podstawa logarytmu wynosi 2, to jednostka miary jest podana w bitach. Zaģóŋmy na przykģad, ŋe alfabet zawiera pięæ symboli: biaģy, czarny, czerwony, niebieski i róŋowy
prawdopodobieņstwa 2/7. 2/7, 1/7 , 1/7 i 1/7 .
Następnie ķrednia liczba bitów potrzebnych do zakodowania kaŋdego symbolu jest okreķlona przez:
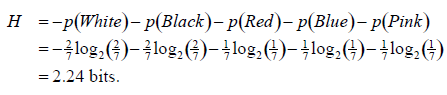
Entropia jest miarą iloķci niepewnoķci związanej z wyborem symbolu - im większa entropia, tym większa niepewnoķæ. Moŋe byæ równieŋ uwaŋana za miarę "treķci informacyjnej" komunikatu - bardziej prawdopodobne komunikaty przekazują mniej informacji niŋ mniej prawdopodobne. Entropia moŋe byæ bezpoķrednio związana z kompresją. Entropia jest dolną granicą ķredniej liczby bitów na symbol wymaganą do zakodowania dģugiego ciągu tekstu wyciągniętego z okreķlonego języka žródģowego, co oznacza, ŋe kodowanie arytmetyczne, metoda przypisywania kodów do symboli o znanym rozkģadzie prawdopodobieņstwa, pozwala uzyskaæ ķredni kod dģugoķæ arbitralnie zbliŋona do entropii. Zatem kompresję moŋna stosowaæ bezpoķrednio do oszacowania górnej granicy entropii w następujący sposób. Biorąc pod uwagę sekwencję n symboli x1 x2…xn, entropię moŋna oszacowaæ, sumując dģugoķci kodu wymagane do kodowania kaŋdego symbolu:
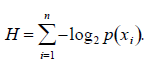
Tutaj dģugoķæ kodu dla kaŋdego symbolu xi jest obliczana za pomocą wzoru -log2p(xi). Entropia obliczona w ten sposób jest istotna, poniewaŋ zapewnia miarę tego, jak dobrze model statystyczny robi w porównaniu do innych modeli. Odbywa się to poprzez obliczenie entropii dla kaŋdego modelu statystycznego, a model o najmniejszej entropii jest oceniany jako "najlepszy"
Obliczanie entropii w NetLogo
W NetLogo stworzono model gier z odgadywaniem samochodów, aby zilustrowaæ, jak obliczane są dģugoķci kodu entropii i kompresji. Zrzut ekranowy interfejsu modelu pokazano na rysunku
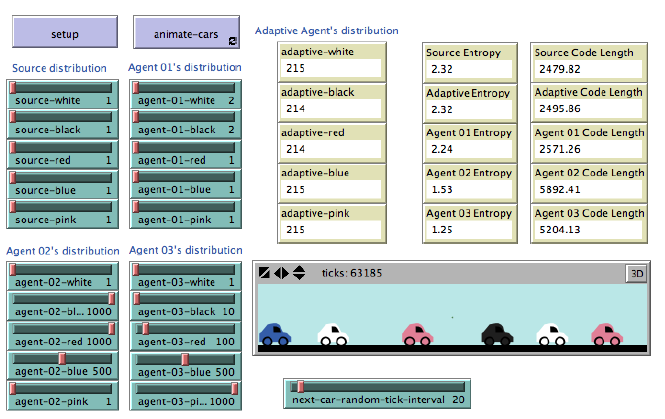
Model reprezentuje odmianę gry, w którą ludzie mogą graæ podczas podróŋy samochodem. Ludzie wybierają kolor z góry - zwykle biaģy, czarny, czerwony lub niebieski - a następnie liczą, ile samochodów z wybranym kolorem przejeŋdŋa obok nich w przeciwnym kierunku. Osoba, która ma największą liczbę na koniec gry, wygrywa. Odmiana gry zawarta w modelu polega na tym, ŋe zamiast kaŋdej osoby wybierającej pojedynczy samochód, okreķlają one z góry liczbę kaŋdego koloru w celu zdefiniowania rozkģadu prawdopodobieņstwa. Ich wyniki mierzone są poprzez kodowanie przybycia samochodów do ich wģasnej dystrybucji. Osoba, która ma najmniejszą caģkowitą dģugoķæ kodu (suma dziennika prawdopodobieņstw kolorów samochodów, które się pojawiają) jest tą, która wygrywa. Na rysunku są rozkģady prawdopodobieņstwa dla trzech agentów, które symulują trzy róŋne osoby grające w tę grę. Są one definiowane za pomocą suwaków po lewej stronie, które są uŋywane do zmiany liczby dla kaŋdego koloru w rozkģadzie, a liczby są uŋywane do obliczenia prawdopodobieņstw przez podzielenie przez caģkowitą liczbę. Dodatkowo istnieją liczniki, które definiują dystrybucję žródģową, która jest uŋywana do generowania kolorów samochodów, które pojawiają się w animacji. Czwarty agent komputerowy równieŋ gra w grę, aktualizując w sposób automatyczny liczbę poszczególnych kolorów w miarę pojawiania się samochodów. Liczby te są pokazane w biaģych polach pod nagģówkiem "Dystrybucja agenta adaptacyjnego" na ķrodku figury. Poniewaŋ dystrybucja žródģa jest w tym przypadku równie prawdopodobna - kaŋdy z kolorów ma taką samą liczbę 1 - wtedy znajduje to odzwierciedlenie w liczbach adaptacyjnych, które są bardzo podobne, 214 lub 215. Oznacza to, ŋe byģo 214 lub 215 samochodów z obserwowanym kolorem, który zostaģ wygenerowany przez model od momentu uruchomienia animacji. Obliczenia entropii i dģugoķci kodu pokazano w prawej ramce na rysunku. Entropia dla wszystkich rozkģadów pozostaje taka sama, z wyjątkiem rozkģadu adaptacyjnego do momentu uŋycia suwaka do zmiany liczby po lewej stronie, a następnie entropia jest natychmiast ponownie obliczana, aby odzwierciedliæ zmianę w rozkģadzie prawdopodobieņstwa. Entropia dla rozkģadu adaptacyjnego zmienia się nieustannie, aby odzwierciedliæ fakt, ŋe wartoķci adaptacyjne są ciągle aktualizowane. Dģugoķæ kodu po prawej stronie figury stanowi sumaryczne sumy kosztów kodowania informacji o kolorze rzeczywistego samochodu wedģug rozkģadu kaŋdego agenta. Zazwyczaj caģkowita dģugoķæ kodu žródģowego jest mniejsza niŋ reszta, poniewaŋ odzwierciedla rzeczywisty rozkģad, który jest uŋywany do generowania wyglądu samochodów. Dģugoķæ kodu adaptacyjnego jest równieŋ zwykle bliska, ale nieco większa niŋ dģugoķæ kodu žródģowego, co wskazuje na uŋytecznoķæ strategii dopasowania twojego rozkģadu do rzeczywistych obserwacji, zamiast wczeķniejszego zdefiniowania predefiniowanego prawdopodobieņstwa. W niektórych okolicznoķciach jednak, z powodu losowoķci uŋywanej do generowania sekwencji samochodów, które się pojawiają, w róŋnych momentach rzeczywisty rozkģad nie pasuje dokģadnie do rozkģadu žródģa, w którym to przypadku strategia adaptacyjna moŋe przewyŋszaæ prognozy žródģowe przy odgadywaniu koloru samochody W przypadku trzech agentów uŋywających częķciowo ustalonej strategii (tj. Uŋytkownik moŋe uŋywaæ suwaków do zmiany liczby w locie, więc dystrybucja jest ustalana tylko do następnej zmiany liczby), dģugoķci kodu odzwierciedlają, jak podobne są liczby do žródģa się liczy. Jeķli istnieje odmiany, spowoduje to większe kodowanie kosztów. Na przykģad na rysunku liczba agentów 01 jest najbliŋej liczby žródeģ, przy czym tylko liczba biaģych i czarnych jest róŋna. Powoduje to nieznaczny spadek entropii - od 2,32 do 2,24, poniewaŋ entropia wskazuje ķredni koszt kodowania koloru pojedynczego samochodu, a niektóre kolory mają obecnie występowaæ częķciej niŋ terapeuty. Jednak nie jest to odzwierciedlone w obserwacje, poniewaŋ rozkģady prawdopodobieņstwa obecnie nie są zgodne, a zatem w wyniku tego zwiększa się caģkowita dģugoķæ kodu (z 2479.82 do 2571.26). Kiedy liczba jest znacząco niedopasowana, tak jak w przypadku agentów 02 i 03, sumy dģugoķci kodu są w rezultacie duŋo większe niŋ dģugoķæ kodu žródģowego. Wybrane częķci kodu modelu zostaģy wymienione w kodzie NetLogo. (Peģny kod moŋna pobraæ za pomocą linku URL pokazanego na dole tego rozdziaģu). Pierwsza lista kodów zawiera procedurę setup-configuration i dystrybucji, w której rozkģady są ustalane na podstawie liczby suwaków. Rozkģady są reprezentowane jako lista pięciu liczb - w kolejnoķci biaģej, czarnej, czerwonej, niebieskiej i róŋowej. Rozkģad adaptacyjny inicjowany jest tak, ŋe wszystkie liczby wynoszą 1 na początku. Pod koniec procedury ustawiania obliczono caģkowitą liczbę dist-total i dist-entropy i obliczoną dla rozkģadu. Procedura neg-log-prob oblicza wartoķæ ujemną logu prawdopodobieņstwa dla kaŋdego koloru, wykorzystując liczbę i liczbę caģkowitą, i jest uŋywana do obliczenia entropii dla rozkģadu.
to setup-distributions
;; ustawia rozkģady dla kaŋdego agentat
ask agents with [agent-id = 0]
[ set distribution
(list source-white source-black source-red source-blue source-pink) ]
ask agents with [agent-id = 1]
[ set distribution
(list agent-01-white agent-01-black agent-01-red agent-01-blue
agent-01-pink) ]
ask agents with [agent-id = 2]
[ set distribution
(list agent-02-white agent-02-black agent-02-red agent-02-blue
agent-02-pink) ]
ask agents with [agent-id = 3]
[ set distribution
(list agent-03-white agent-03-black agent-03-red agent-03-blue
agent-03-pink) ]
if (ticks = 0)
[ ask agents with [agent-id = 4] ; initialise the adaptive distribution
[ set distribution (list 1 1 1 1 1) ]]
;; wszystkie kolory są dostępne na początku dla ķrodka adaptacyjnego
;; liczby dystrybucji agenta adaptacyjnego są następnie aktualizowane
;; gdzie indziej w aktualizacji-adaptacyjnej-liczbie
ask agents
[ set dist-total 0
set dist-entropy 0
foreach distribution
[ set dist-total dist-total + ?] ; calculate total first
foreach distribution
[ set dist-entropy dist-entropy + neg-log-prob ? dist-total]]
end
to-report neg-log-prob [p q]
;; zwraca ujemną wartoķæ logarytmu do podstawy 2 prawdopodobieņstwa p / q.
report (- log (p / q) 2)
end
Obliczanie dģugoķci kodu odbywa się za pomocą procedury encode-this-car w kodzie NetLogo. Ģączna dģugoķæ kodu do tej pory, codelength-total, jest aktualizowana poprzez dodanie ujemnego logu prawdopodobieņstwa dla koloru zakodowanego samochodu. Prawdopodobieņstwo to liczba kolorów zapisanych na liķcie distribution agenta podzielona przez caģkowitą liczbę, dist-total.
to encode-this-car [colour]
;; zwraca koszt kodowania koloru tego samochodu zgodnie z
;; dystrybucja agenta
let codelength 0
ask agents
[
set codelength 0
ifelse colour = white
[set codelength neg-log-prob (item 0 distribution) dist-total]
[ifelse colour = 1 ;almost black to make the car doors & windows visible
[set codelength neg-log-prob (item 1 distribution) dist-total]
[ifelse colour = red
[set codelength neg-log-prob (item 2 distribution) dist-total]
[ifelse colour = blue
[set codelength neg-log-prob (item 3 distribution) dist-total]
[set codelength neg-log-prob (item 4 distribution) dist-total]]]]
set codelength-total codelength-total + codelength
]
end
Moŋemy reprezentowaæ stan wewnętrzny agentów w tej symulacji za pomocą ich dystrybucji. Jeķli zmienimy listę liczników dystrybucji na jeden numer, stosując procedurę raportowania wymienioną w kodzie NetLogo, wówczas moŋemy okreķliæ, w jaki sposób kaŋda dystrybucja zmienia się w zaleŋnoķci od czasu. Celem tego jest pokazanie, w jaki sposób rozkģady prawdopodobieņstwa mogą byæ przedstawione jako pojedyncze punkty w przestrzeni n-wymiarowej i jak ich zmiana w czasie reprezentuje ruch w tej przestrzeni. Rysunek 7.5 pokazuje dwa zrzuty ekranów, które model wytworzyģ dla dwóch konfiguracji - jeden, w którym liczy się žródģo byģy wszystkie 1 (lewy wykres) i jeden, w którym žródģem byģy wszystkie 1000 (prawy wykres).
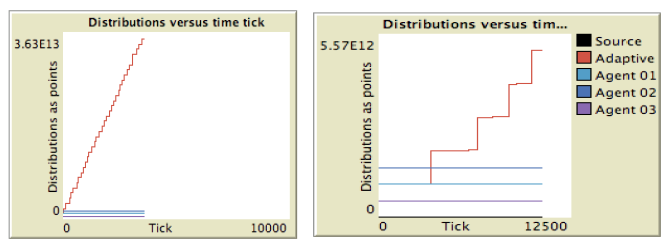
Tylko dystrybucja adaptacyjna jest zmienna, a czerwone linie na wykresie odzwierciedlają to. Poniewaŋ liczniki adaptacyjne stale rosną, musimy się upewniæ, ŋe maksymalna liczba nie jest nigdy przekroczona, więc robi się to za pomocą reportera remainder w kodzie. Pozostaģe rozkģady są statyczne, a ich linie są poziome. Jeķli uŋytkownik byģy zmieniæ licznik na jedną z tych dystrybucji, dziaģki będzie odzwierciedlaæ zmiany przez zmiany w pozycji odpowiedniej linii.
to-report distribution-as-a-point [agent]
; zwraca rozkģad agenta reprezentowany jako pojedynczy punkt
report ;; note that the maximum count for non-adaptive distributions is
;; 1000, więc upewnij się, ŋe max. liczba nie przekracza 1000 dla
;; rozkģad adaptacyjny
(remainder (item 0 [distribution] of agent) 1000) +
(remainder (item 1 [distribution] of agent) 1000) * 1000 +
(remainder (item 2 [distribution] of agent) 1000) * 1000 * 1000 +
(remainder (item 3 [distribution] of agent) 1000) * 1000 * 1000 * 1000 +
(remainder (item 4 [distribution] of agent) 1000) * 1000 * 1000 * 1000 *
1000
end
Ten model pokazuje, w jaki sposób agenci mogą porównywaæ jakoķæ róŋnych modeli statystycznych. Modele te mogą pomóc przewidzieæ prawdopodobne przyszģe zdarzenia w celu podjęcia ķwiadomych decyzji. Waŋne jest, aby pamiętaæ, ŋe jeķli nie masz pewnej wiedzy na temat procesu tworzenia przyszģych zdarzeņ, to nigdy nie moŋesz upewnij się, który model statystyczny jest "najlepszy" do przewidywania, co moŋe się wydarzyæ w przyszģoķci, szczególnie w dynamicznym ķrodowisku, w którym siģy generujące zdarzenia mogą się zmieniaæ z jednej chwili na następną.
Modelowanie języka
Metoda podejmowania decyzji na podstawie tego, który model statystyczny byģ najlepszy w przewidywaniu przeszģych sekwencji zdarzeņ (na przykģad przy uŋyciu obliczeņ dģugoķci kodu kompresji, jak powyŋej) ma szeroki zakres aplikacji do podejmowania decyzji przez agentów. W tym rozdziale koncentrowaliķmy się na komunikacji i języku, moŋemy teŋ przyjrzeæ się kolejnym przykģadom, które to ilustrują, szczególnie w dziedzinie modelowania języka. W statystycznym (lub probabilistycznym) modelu języka przyjmuje się, ŋe symbole (na przykģad sģowa lub znaki) moŋna scharakteryzowaæ za pomocą zestawu prawdopodobieņstw warunkowych. Model językowy to komputerowy mechanizm sģuŋący do okreķlania prawdopodobieņstw warunkowych. Przypisuje prawdopodobieņstwo wszystkim moŋliwym ciągom symboli. Najbardziej udane typy modeli językowych dla sekwencji symboli, które występują w językach naturalnych, takich jak angielski i walijski, to sģowa modele n-gramowe (które bazują na prawdopodobieņstwie sģowa w poprzednich n wyrazach) i częķæ
mowy w gramach modele (które opierają prawdopodobieņstwo na poprzednich sģowach i częķciach mowy, są równieŋ nazywane modelami n-pos). Modele n-gramowe (modele oparte na znakach) równieŋ zostaģy wypróbowane, chociaŋ nie są tak wyražnie widoczne w literaturze, jak pozostaģe dwie klasy modelu. Prawdopodobieņstwa dla modeli są szacowane poprzez zbieranie statystyk częstotliwoķci z duŋego zbioru tekstów, zwanego tekstem szkolenia, w procesie zwanym treningiem. Rozmiar tekstu szkolenia jest zwykle bardzo duŋy i zawiera wiele milionów (aw niektórych przypadkach miliardów) sģów. Modele te są często okreķlane jako "modele Markowa", poniewaŋ opierają się na zaģoŋeniu, ŋe język jest žródģem Markowa. Model n-gramowy nazywany jest rzędem modelu n-1 Markowa (na przykģad model trygramowy to model 2 Markowa rzędu). W modelu n-gramowym prawdopodobieņstwa są uwarunkowane poprzednimi sģowami w tekķcie. Formalnie prawdopodobieņstwo wystąpienia sekwencji S, n sģów, w1 w2 … wn, jest podana przez:
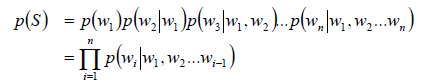
Tutaj wi nazywa się przewidywanie i w1 w2 … wi-1 historii. Budowanie modelu języka, który wykorzystuje peģną historię, moŋe byæ kosztowne obliczeniowo. n-gramowe modele językowe przyjmują zaģoŋenie, ŋe historia jest odpowiednikiem poprzednich sģów n - 1 (zwanych kontekstem warunkowania). Na przykģad modele bigram przedstawiają następujące przybliŋenie:
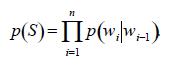
Innymi sģowy, tylko poprzednie sģowo sģuŋy do warunkowania prawdopodobieņstwa. Modele Trigram okreķlają prawdopodobieņstwo dwóch poprzednich sģów:
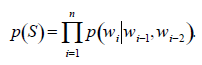
Zaģoŋenia, na których oparte są te przybliŋenia, nazywane są "zaģoŋeniami Markova". Na przykģad model bigram zakģada następujące zaģoŋenie Markowa:
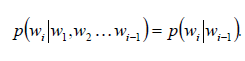
Mogģoby się wydawaæ, ŋe takie drastyczne zaģoŋenia miaģyby niekorzystny wpģyw na wydajnoķæ modeli statystycznych, ale w praktyce modele bigram i trygram zostaģy z powodzeniem zastosowane w wielu dziedzinach, w szczególnoķci w zakresie tģumaczenia maszynowego i rozpoznawania mowy. Kuhn i De Mori wskazują, dlaczego to podejķcie jest tak skuteczne: "Nowoķcią tego podejķcia jest to, ŋe uwaŋa za waŋniejsze trzymanie informacji zawartych w ostatnich kilku sģowach, niŋ koncentrowanie się na skģadni, która z definicji obejmuje caģoķæ zdanie. Wysoki procent wypowiedzi i pisania w języku angielskim skģada się z zwrotów akcji, które pojawiają się ponownie; jeķli ktoķ jest w poģowie jednego z nich, wiemy z niemal pewnoķcią, jakie będą jego następne sģowa ". Decyzja co do tego, które zaģoŋenia dają lepsze wyniki, jest kwestią empiryczną, a nie teoretyczną
Entropia Języka
Iloķæ informacji na sģowo w jakimķ zbiorze sģów wynosi:
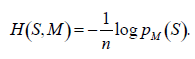
Moŋna to wykorzystaæ do oszacowania entropii języka, w którym do oszacowania prawdopodobieņstw uŋywany jest model języka M opisany w poprzedniej sekcji, a im większa jest liczba sģów n w korpusie, tym lepsza jest ocena. , H (S, M) jest okreķlana jako entropia krzyŋowa języka, poniewaŋ jest estymatem opartym na modelu M, a nie na prawdziwej entropii.) W klasycznym artykule zatytuģowanym "Prediction and entropia of printed English" opublikowanym w 1951, Shannon oszacowaģ entropię angielskiego na okoģo 1 bit na znak. Metoda szacowania entropii przez Shannona polegaģa na tym, aby badani ludzie odgadywali nadchodzące postacie na podstawie bezpoķrednio poprzedzającego tekstu. Wybraģ 100 losowych próbek pobranych od Jeffersona z Virginii Dumasa Malone&primela. Z liczby domysģów dokonanych przez kaŋdego badanego, Shannon wyprowadziģ górną i dolną granicę szacunkową 1,3 i 0,6 bitów na znak (skrót "bpc" w skrócie). Cover & King zauwaŋyli, ŋe procedura odgadywania Shannona dawaģa tylko częķciową informację o prawdopodobieņstwach nadchodzącego symbolu. Prawidģowe odgadnięcie mówi nam tylko, który symbol, który podmiot uwaŋa za najbardziej prawdopodobny, a nie o wiele bardziej prawdopodobny niŋ inne symbole. Rozwinęli podejķcie hazardowe, w którym kaŋdy podmiot uprawiaģ częķæ obecnego kapitaģu na następny symbol. Korzystając ze ķredniej waŋonej wszystkich schematów zakģadów podmiotów, udaģo im się uzyskaæ górną granicę 1,25 bpc. Wydajnoķæ poszczególnych osób wahaģa się od 1,29 pz do 1,90 pz. Okģadka i King omawiają znaczenie wyraŋenia "entropia angielskiego": "Naleŋy zdaæ sobie sprawę, ŋe język angielski jest generowany przez wiele žródeģ, a kaŋde žródģo ma wģasną charakterystyczną entropię. Operacyjne znaczenie entropii jest jasne. Jest to minimalna oczekiwana liczba bitów / symboli potrzebnych do scharakteryzowania tekstu. "Podejķcia Shannona, Cover'a i Kinga opieraģy się na ludziach zgadujących tekst. Inne podejķcia zostaģy oparte na statystycznej analizie częstotliwoķci znaków i sģów pochodzących z tekstu oraz na wydajnoķci modeli komputerowych z wykorzystaniem algorytmów kompresji. Model Guessing Game Shannona zostaģ stworzony w NetLogo, aby zilustrowaæ, jak to dziaģa. Model pozwala uŋytkownikowi najpierw zaģadowaæ tekst treningowy, aby przygotowaæ swój model statystyczny, a następnie wybraæ tekst testowy, aby zagraæ w grę Shannon's Guessing Game. Odbywa się to po wybraniu maksymalnej gģębokoķci drzewa i maksymalnego rozmiaru tekstu, do æwiczenia na podstawie suwaków max-tree-depth i max-text-size, a następnie za pomocą wybieracza which-text, który znajduje się w poģowie po lewej stronie NetLogo wniosek o wybranie szkolenia lub testowania tekstu, a następnie kliknięcie przycisku tekstowego load-training-text lub load-testing-text. Następnie uŋytkownik uruchamia grę Zgadywanie Shannona, klikając przycisk predict-text. Aplikacja następnie wielokrotnie przewiduje kaŋdy nadchodzący znak po kolei. Na przykģad, moŋemy najpierw zaģadowaæ Jane Austen's Pride and Prejudice jako tekst treningowy. W tym przypadku tekst szkolenia jest następującymi postaciami zaczerpniętymi z początku ksiąŋki Jane Austen: "Jest to prawda powszechnie uznana, ŋe jeden czģowiek w posiadaniu szczęķcia musi byæ w potrzebie ŋony. Jakkolwiek maģo znane uczucia i poglądy takiego czģowieka mogą byæ na jego pierwszym wejķciu do sąsiedztwa, prawda ta jest tak dobrze umiejscowiona w umysģach otaczających rodzin, ŋe uwaŋany jest za prawowitą wģasnoķæ jakiejķ jednej lub drugiej z ich córek. "Jeķli następnie wybierzmy zmysģ i wraŋliwoķæ Jane Austen jako tekst testowy, aplikacja NetLogo będzie przewidywaæ nadchodzące postacie jeden po drugim, uŋywając następującej sekwencji zaczerpniętej z początku tej ksiąŋki:" Rodzina Dashwood od dawna osiadaģa w Sussex. Ich majątek byģ duŋy, a ich rezydencja znajdowaģa się w Norland Park, w centrum ich posiadģoķci, gdzie od wielu pokoleņ ŋyli tak szanowanym sposobem, by wzbudziæ ogólną dobrą opinię o otaczającej je znajomoķci. Póžnym wģaķcicielem tej posiadģoķci byģ samotny męŋczyzna, który ŋyģ do bardzo zaawansowanego wieku i który przez wiele lat ŋycia miaģ staģą towarzyszkę i gospodynię w swojej siostrze. "Aplikacja wymienia prognozy dla wszystkich postaci, które ma widoczne wczeķniej, w tym ich liczniki częstotliwoķci i szacowane prawdopodobieņstwa, zgodnie z aktualnym kontekstem (tj. natychmiastowy tekst poprzedzający) i wynikającą z tego gģębią w modelu drzewa tekstowego szkolenia. Na przykģad, na początku nie ma wczeķniejszego kontekstu, więc tylko predykcje w górnej częķci drzewa (gģębokoķæ 0) są wymienione, jak pokazano na rysunku
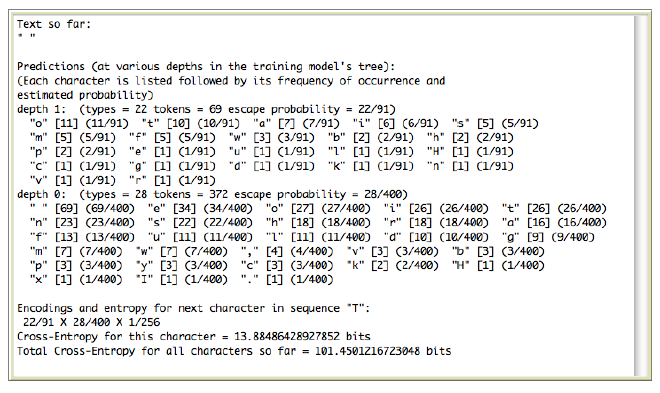
W tym przykģadzie maksymalna gģębokoķæ drzewa zostaģa ustawiona na 3. Znak spacji zostaģ zakodowany jako pierwszy, a następnie zakodowany jest następny znak, znak "T", a następnie znak "h", a następnie "e". i tak dalej. Sytuację po przetworzeniu pierwszego znaku (spacja) pokazano na rysunku. Wszystkie prognozy są wymienione na gģębokoķci 1 i 0, ale nie gģębiej, poniewaŋ nie mamy dalszego kontekstu, na którym moŋna oprzeæ nasze prognozy. Przewidywania gģębi 1 zawierają listę wszystkich znaków, które wystąpiģy po kontekķcie pojedynczego znaku zawierającego spację. Poniewaŋ spacja jest często występującą postacią w tekķcie angielskim, istnieje wiele przewidywaņ - na przykģad po spacji znak "o" pojawiģ się 11 razy po spacji w tekķcie szkoleniowym, znak "t" pojawiģ się 10 razy, znak "a" wystąpiģ 7 razy i tak dalej. Te prognozy zostaģy wymienione w porządku malejącej częstotliwoķci. Sytuacja, która pojawia się w tym przykģadzie, polega na tym, ŋe musimy zakodowaæ znak "T", ale to nigdy wczeķniej nie miaģo miejsca w tekķcie szkoleniowym. (Spójrz w powyŋszy akapit treningowy zaznaczony kursywą - znak "T" nigdy nie podąŋa za znakiem spacji, co jest wynikiem krótkoķci tekstu treningowego uŋytego w tym przykģadzie, w rzeczywistoķci, w większym tekķcie treningowym, moŋe wiele wystąpieņ, gdy "T" podąŋa za spacją, na przykģad na początku zdania zaczynającego się od sģowa "The".) Problem w tym przykģadzie polega na tym, ŋe bez prognozy w naszym modelu musimy przypisaæ zerowe prawdopodobieņstwo, które spowoduje w nieskoņczonej dģugoķci kodu od log (0) = ?. Ten problem nazywa się problemem z zerową częstotliwoķcią i aby przezwycięŋyæ ten problem, musimy przypisaæ pewne prawdopodobieņstwo zdarzeniom, które nigdy wczeķniej nie miaģy miejsca. Jedna metoda nazywa się "ucieczką" lub "wycofaniem się" - cofamy się do krótszego kontekstu, w którym zwykle jest więcej prognoz. Aby to zrobiæ, przypisujemy maģe prawdopodobieņstwo w sytuacjach, w których będziemy musieli uciec - tj. Gdy napotkamy sekwencję, której nigdy wczeķniej nie widzieliķmy. Proces ten jest równieŋ nazywany "wygģadzaniem", poniewaŋ powoduje to, ŋe rozkģad prawdopodobieņstwa jest bardziej jednolity (stąd powód jego nazwy), z niskimi (w tym zerowymi) prawdopodobieņstwami zwykle korygowanymi w górę i wysokimi prawdopodobieņstwami skorygowanymi w dóģ. Celem wygģadzania jest dwojakie: po pierwsze, aby zapewniæ, ŋe prawdopodobieņstwo nigdy nie jest zerowe; a po drugie, mając nadzieję poprawiæ dokģadnoķæ modelu statystycznego. Metodą stosowaną do oszacowania prawdopodobieņstwa ucieczki w przykģadzie (jak zakodowano w modelu gry w odgadywanie gry Shannon′s NetLogo) jest oparcie go na liczbie typów, które wystąpiģy w kontekķcie. Dla danej sekwencji symboli liczba typów jest liczbą niepowtarzalnych symboli, które miaģy miejsce, podczas gdy liczba tokenów to caģkowita liczba symboli. Na przykģad w sekwencji znaków "aaaa bbb cc d" istnieje 5 typów znaków - "a", "b", "c", "d" i spacja - w przeciwieņstwie do 13 znaków ŋetonowych; dla palindromicznej sekwencji sģów "czģowiek planem panamskim kanaģu" jest 5 typów sģów - "a", "czģowiek", "plan", "kanaģ" i "panama" - i ģącznie 7 tokenów sģownych. Na powyŋszym rysunku dla kontekstu skģadającego się z pojedynczej przestrzeni widzimy 22 typy i 69 tokenów. Dlatego szacuje się, ŋe prawdopodobieņstwo ucieczki wynosi 22/91, a prawdopodobieņstwa dla pozostaģych znaków zostaģy dostosowane odpowiednio do ich liczby podzielonej przez 91, a nie 69. Formalnie, prawdopodobieņstwo dla symbolu s w konkretnym kontekķcie C jest obliczane jako następuje:
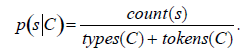
Ta metoda wygģadzania, wynaleziona przez Alistaira Moffata dla schematu kompresji PPMC, nazywa się wygģadzaniem Witten-Bell w literaturze dotyczącej modelowania języka. W tym przykģadzie model statystyczny musi cofnąæ się do domyķlnego modelu, w którym wszystkie postacie są równie prawdopodobne, aby móc zakodowaæ znak "T", poniewaŋ w tym przypadku nigdy nie byģ widziany w sekwencji treningowej. Dlatego koszt kodowania znaku "T" jest 22/91 Ũ 28/400 Ũ 1/256 o wspóģczynniku 28/400 przeznaczonym do kodowania wyjķcia dla kontekstu zerowego (tj. Po prostu przy uŋyciu częstotliwoķci znaku zlicza się na gģębokoķci 0 w drzewie) i 1/256 dla modelu domyķlnego ( gdzie 256 to wielkoķæ alfabetu).
Wymaga to 13,88 bitów do kodowania jako
-Log 2 (22/91 Ũ 28/400 Ũ 1/256) = 13,88 bitów.
Rysunek pokazuje dane wyjķciowe po zakodowaniu pierwszych dziesięciu znaków w sekwencji testowej
("Rodzina").

Kolejny znak, jaki musimy zakodowaæ jest "y", a poniewaŋ nie byģo widaæ w kontekķcie gģębi 3 w sekwencji treningowej, musimy uciec z kontekstu, który znajduje się na gģębokoķci 3 w drzewie (gdzie byģo tylko jedno poprzednie wystąpienie, więc prawdopodobieņstwo wynosi 1/2), a następnie przez gģębokoķæ 2 (gdzie ponownie wystąpiģo tylko jedno poprzednie wystąpienie, więc prawdopodobieņstwo wynosi 1/2) do gģębokoķci 1 (gdzie widzieliķmy znak "y" przed , a jego prawdopodobieņstwo to 1/16). Kosztuje to 6 bitów, aby kodowaæ od -log 2 (1/2 Ũ 1/2 Ũ 1 16) = 6.
Kolejny model Netlogo o nazwie Language Modeling zostaģ opracowany w celu wizualizacji modeli treemodeli. Rysunek pokazuje zrzut ekranu modelu drzewa, który zostaģ przeszkolony na 32 znakach na początku Sensu i wraŋliwoķci Jane Austen pokazanego powyŋej.

W tym przykģadzie maksymalna gģębokoķæ drzewa zostaģa ustawiona na 2. Rysunek pokazuje, ŋe większoķæ dwuznakowych sekwencji jest unikatowych (tj. Najbardziej zewnętrzne liczby to wszystkie 1), czego moŋna się spodziewaæ ze względu na krótkoķæ tekstu szkolenia, oprócz sekwencja "d", która występuje dwukrotnie (moŋna ją znaležæ w lewym górnym rogu lub w kierunku NNW na rysunku). Niektóre pojedyncze znaki występują więcej niŋ jeden raz, powodując efekt rozwijania na gģębokoķci 2 - na przykģad, "" występuje 5 razy (patrz ķrodkowe prawe poģoŋenie), po którym następuje 5 róŋnych znaków ("f", "o", " D "," h "i" l "). Aplikacja do modelowania języka zostaģa opracowana w celu obsģugi modelowania zdarzeņ na róŋnych strumieniach wejķciowych przy uŋyciu podejķcia podobnego do stosowanego w modelu Wall Following Events. W przykģadzie przedstawionym na rysunku modelowane są tylko zdarzenia postaci. To wyjaķnia ponowne pojawienie się ciągu znaków "char" na caģej figurze. Model pozwala takŋe na ģadowanie zdarzeņ sģownych, jak równieŋ zdarzeņ znakowych, dģuŋszy rozmiar tekstu do trenowania i ustawienie maksymalnej gģębokoķci drzewa do 8, chociaŋ wizualizacja tych drzew staje się znacznie bardziej problematyczna ze względu na ograniczenia NetLogo ķrodowisko i zģoŋonoķæ produkowanych drzew
Znaczenie komunikacyjne
Ta częķæ koncentruje się na komunikacji agenta, róŋnych typach komunikacji i waŋnej roli, jaką musi peģniæ komunikacja agentów w interakcji między agentami. Rozdziaģ ten miaģ mniej do powiedzenia na temat treķci komunikatów przesyģanych między agentami. Język sģuŋy do definiowania symboli, które przekazują znaczenie tych komunikatów. Celem komunikacji dla nadawcy jest przekazanie znaczenia wiadomoķci w taki sposób, aby odbiornik mógģ ją zdekodowaæ i odpowiednio zareagowaæ. Jeķli odbiornik nie jest w stanie tego zrobiæ, komunikacja nie powiodģa się i komunikat zostaģ zmarnowany. Znaczenie moŋna zdefiniowaæ w następujący sposób. Znaczenie ma znaczenie lub znaczenie komunikatu przekazanego przez jakiķ język, który agent chce przekazaæ innemu agentowi. Podobnie jak w przypadku wszystkich definicji, dokģadniejsza analiza tej roboczej definicji ujawni pewne niedociągnięcia. Moŋna zadaæ dalsze pytania dotyczące definicji, takie jak "Jakie jest znaczenie sģowa" wiadomoķæ "?" Oraz "Jakie jest znaczenie" ?? Kontynuacja tej linii pytaņ prowadzi do nieskoņczonego regresu definicji, w których znaczenie czegokolwiek nigdy nie wydaje się byæ przypięte dokģadnie w taki sposób, ŋe moŋemy na przykģad okreķliæ znaczenie symboli matematycznych. Charakter znaczenia (i związane z nim studium semantyki w językoznawstwie) byģ dyskutowany i debatowany przez stulecia, i jest przedmiotem wielu zbiorów prac pisemnych i badaņ naukowych. Jako ludzie, moŋemy ģatwo zrozumieæ znaczenie tych sģów, abyķmy mogli przyjąæ pragmatyczny punkt widzenia, tak jak Turing, sugerując test Turinga dla inteligencji, ŋe chociaŋ uzyskanie precyzyjnych definicji znaczenia sģów i języka jest interesującą filozoficzną pogoņ, nie jest to konieczne, poniewaŋ ludzie mogą bez niej osiągnąæ udaną komunikację. Dzieje się tak, pomimo tego, ŋe ludzie nigdy nie są caģkowicie zgodni co do dokģadnych znaczeņ symboli, z którymi się komunikują. Ale co by byģo, gdybyķmy musieli przekazaæ znaczenie wiadomoķci komuķ lub czemuķ, co nie byģo ludzkie? Jest to temat Eksperymentu Myķlowego
Eksperyment Myķlowy: Komunikacja z kosmitami
Rozwaŋmy problem, jak przekazaæ wiadomoķæ obcemu. W tym ustawieniu przyjmijmy, ŋe nie ma wspólnej podstawy dla zrozumienia znaczenia wiadomoķci. Oznacza to, ŋe musimy przekazaæ znaczenie symboli w komunikacie, a takŋe same symbole. Na przykģad, moŋemy chcieæ przekazaæ następujący komunikat: "Nie otwieraj". Tak taki scenariusz wystąpiģ w filmie Alien Hunter, ale z lekkim akcentem - my (ludzie) byliķmy tymi, którzy potrzebowali rozszyfrowaæ wiadomoķæ, kosmici byli tymi, którzy chcieli to przekazaæ. Grupa naukowców odkryģa duŋy metalowy przedmiot pochodzenia obcego, zamroŋony w lodzie na Antarktydzie, który wysyģaģ jakąķ wiadomoķæ radiową. Jeden z naukowców ostatecznie rozszyfrowaģ wiadomoķæ, ale dopiero po tym, jak niektórzy inni naukowcy wģaķnie otworzyli obiekt - fraza "Nie otwieraj" byģa powtarzana w kóģko w wiadomoķci radiowej. Pytanie jest następujące. Jak moŋemy przekazaæ nawet tak prostą wiadomoķæ, jak "Nie otwieraj", gdy nie wiemy, w jakim języku stwór otrzymujący wiadomoķæ będzie w stanie ją zrozumieæ? Moŋemy nie znaæ zdolnoķci poznawczych odbiorców, ich tģa kulturowego, a nawet ich zdolnoķci zmysģowych, a zatem mają bardzo maģo wspólnych ram odniesienia, z którymi moŋna się komunikowaæ. Język wymaga komunikacji pojęæ - to znaczy znaczenia symboli przekazywanych w wiadomoķci. W szczególnoķci, w jaki sposób moŋemy przekazaæ koncepcję "otwartego", na przykģad, lub pojęcia "nie"? Astronomowie Carl Sagan i Frank Drake stanęli twarzą w twarz z tym problemem na początku lat siedemdziesiątych, kiedy zdecydowali, jakie wiadomoķci umieķciæ na statku kosmicznym Pioneer - pierwszych przedmiotach ludzkiej produkcji, które opuķciģy Ukģad Sģoneczny. Postanowili wykorzystaæ obrazkową wiadomoķæ zawierającą nagie postacie istot ludzkich wraz z kilkoma symbolami, aby przekazaæ informacje o tym, skąd wziąģ się statek kosmiczny. Przesģania zostaģy skrytykowane przez innych ludzi za zbyt humanistyczne i trudne do zrozumienia, nawet dla ludzi. Nawet częķci najģatwiejszych do zrozumienia dla ludzi - strzaģka pokazująca trajektorię statku kosmicznego - mogą byæ nieczytelne dla obcej kultury, poniewaŋ symbol strzaģki jest wytworem spoģecznoķci ģowiecko-zbierackich powszechnych na Ziemi. Komunikacja z kosmitami jest oczywiķcie hipotetyczną sytuacją. Nie jest pewne, czy istnieją jakieķ istoty pozaziemskie, czy teŋ istnieją, czy potrafią się z nami komunikowaæ - w koņcu znaležliķmy bardzo maģo dowodów na istnienie istot pozaziemskich w innych częķciach wszechķwiata, nawet po dziesięcioleciach. wyszukiwania za pomocą zaawansowanych komputerów. Seti @ home to projekt przetwarzania rozproszonego, który wykorzystuje bezczynne komputery w Internecie do wyszukiwania dowodów na pozaziemską inteligencję. Od daty premiery 17 maja 1999 r. Rejestruje ponad 10 milionów lat czasu komputerowego i obecnie korzysta z ponad 300 000 komputerów w ponad 200 krajach. Jednak projekt nie dostarczyģ ŋadnych dowodów, mimo ŋe dziaģaģ przez ponad dziesięæ lat. Jednakŋe wszelką komunikację między ludžmi moŋna uznaæ za posiadającą pewien stopieņ "obcoķci" w następującym sensie. Kiedykolwiek rozmawiamy z innym czģowiekiem, często musimy wyjaķniaæ znaczenia pojęæ, które są nam nieznane lub obce, lub wyjaķniaæ pojęcia, które są rozumiane na róŋne sposoby. Jeķli języki nadawcy i odbiorcy są róŋne - na przykģad rozmowa między kimķ z Walii, który gģównie mówi po walijsku i kimķ z Afryki, który gģównie mówi po suahili, lub gģuchym, który zna język migowy, a osobą, która tego nie robi - to dģuŋej wyjaķnienia są wymagane częķciej w trakcie rozmowy. Trudnoķæ z kosmitami polega jednak na tym, ŋe moŋemy stanąæ przed problemem wyjaķnienia znaczenia wszystkiego, co chcemy przekazaæ. Problem komunikacji z obcym jest podobny do problemu komunikacji z nowo odkrytym plemieniem, na przykģad w Papui Nowej Gwinei, które zostaģo odizolowane od reszty ludzkoķci. Problem ten zostaģ rozwaŋony przez XX-wiecznego filozofa W. Quine'a, który nazwaģ to radykalnym tģumaczeniem. Powstaje trudnoķæ w komunikowaniu się, czy to z izolowanym plemieniem, czy obcym gatunkiem, kiedy byæ moŋe nawet jedno sģowo języka, którego uŋywa nadawca, nie jest zrozumiane z góry. Zasadniczo jest to problem, z którym stykają się projektanci systemów rozumienia tekstu i mowy, poniewaŋ moŋemy uwaŋaæ "obcego" agenta za system komputerowy, a ludzki agent - tego, który wytworzyģ tekst lub mowę, które naleŋy zrozumieæ. Jak stwierdzono wczeķniej, znaczna częķæ języka skģada się z metafory pojęciowej i analogii. Lakoff i Johnson w swojej ksiąŋce "Metafory, w której ŋyjemy", podkreķlają waŋną rolę, jaką metafora pojęciowa odgrywa w języku naturalnym i jak jest ona związana z naszymi fizycznymi doķwiadczeniami. Twierdzą, ŋe metafora to nie tylko urządzenie poetyckiej wyobražni, ale "jest wszechobecna nie tylko w języku potocznym, ale w naszych myķlach i dziaģaniu", będąc podstawową cechą ludzkiego systemu pojęciowego. Twierdzą oni, ŋe "Istotą metafory jest zrozumienie i doķwiadczanie jednego rodzaju rzeczy w kategoriach innego". Twierdzą oni, ŋe większoķæ naszego systemu przetwarzania myķli ma charakter pojęciowy i ŋe ludzie uŋywają metaforycznych pojęæ znacznie częķciej niŋ im się wydaje. Metafory są związane z naszym fizycznym ucieleķnieniem w prawdziwym ķwiecie. Celem urządzenia metaforycznego jest podkreķlanie podobieņstw i ukrywanie róŋnic między pokrewnymi pojęciami. Dla tych ludzi pojęcie, ŋe argument jest związany z aktem wojny, jest obce - zamiast tego nacisk w jakiejkolwiek konfrontacji lub argumentacji jest poģoŋony na aktywną wspóģpracę uczestników. Celem nie jest niszczenie nawzajem swoich argumentów, ale aktywne rozwijanie swoich punktów widzenia i / lub ich wģasnej wiedzy i zrozumienia. Podobnie jest w przypadku, gdy dwoje ludzi taņczy razem, jest artystycznie bardziej pociągająca niŋ dwoje ludzi taņczących oddzielnie i niezaleŋnie. W rozmowach ci ludzie mogliby powiedzieæ takie rzeczy jak: "W poģączeniu z jego argumentem", "Nasze argumenty byģy nie na miejscu" i "Podjąģem jego krytykę i przetoczyģem je dalej". Dla nas początkowo wydawaģoby się to dziwne, dopóki nie zrozumieliķmy podstawowej metafory pojęciowej
Język ludzki ma zdolnoķæ przekazywania wielu znaczeņ na kilku poziomach. Kaŋdy z nich wspóģdziaģa, aby zapewniæ coķ, co jest większe niŋ suma jego częķci. Czasami czytelnik lub sģuchacz znajduje znaczenie, którego nie zamierzali nawet autor (autorzy). Język równieŋ ujawnia wiele informacji o myķlach zachodzących w umysģach autora (-ów) - tego, co wiedzą i czego nie wiedzą; ich wierzenia; ich upodobania lub antypatie; ich opinie; ich nadzieje i lęki; co szanują i wysoko cenią, lub czego nie okazują szacunku i mają pogardę; na co oni popierają lub są przeciwni; ich pragnienia / potrzeby / potrzeby; i ich intencje.
Podsumowanie
Agenty wykazują zachowania komunikacyjne, gdy próbują przekazaæ informacje innym agentom. Język to zbiór symboli uŋywanych przez agentów do przekazywania informacji. Ludzie uŋywają wielu form komunikowania się, a ich język jest róŋnorodny i bogaty w znaczenie. Komunikacja
między ludžmi rozprzestrzenia się za poķrednictwem sieci spoģecznoķciowych. Podsumowanie waŋnych pojęæ, które naleŋy wyciągnąæ z tego rozdziaģu, pokazano poniŋej:
• Entropia jest sumą prawdopodobieņstw pomnoŋonych przez log prawdopodobieņstw rozkģadu prawdopodobieņstwa. Moŋe byæ stosowany jako ķrodek do pomiaru treķci informacyjnej w wiadomoķciach.
• Język jest definiowany przez zestaw reguģ wspóģuŋytkowanych spoģecznie, które definiują powszechnie akceptowane symbole, ich znaczenie i ich związki strukturalne okreķlone przez zasady gramatyki.
• Język ludzki występuje w wielu formach i jest niezwykle róŋnorodny.
• Modelowanie języka to mechanizm okreķlania prawdopodobieņstw warunkowych dla symboli w języku.
• Entropię języka moŋna oszacowaæ na podstawie duŋego korpusu tekstu reprezentatywnego dla danego języka.
• Sieci spoģecznoķciowe odgrywają kluczową rolę w rozpowszechnianiu komunikacji między ludžmi.
• Zjawisko maģego ķwiata jest waŋną cechą charakterystyczną sieci spoģecznych i komputerowych.
• Celem komunikacji jest przekazanie znaczenia przekazywanej wiadomoķci. Znaczenie przekazywane w wiadomoķciach dla ludzi jest zģoŋone i wielowarstwowe oraz stanowi obszar, który stanowi ciągģe wyzwanie dla badaņ nad sztuczną inteligencją.
Wyszukiwanie
"Poszukiwanie jest fundamentalne dla inteligentnego zachowania, nie jest to tylko inna metoda czy mechanizm kognitywny, ale fundamentalny proces." Jeķli jest coķ, co sztuczna inteligencja przyczyniģa się do naszego zrozumienia inteligencji, odkrywa, ŋe wyszukiwanie to nie tylko jedna metoda poķród wielu, które mogą byæ uŋyte do osiągnięcia celów, ale jest najbardziej podstawową metodą ze wszystkich. " - Allen Newell (1994).
Zachowanie wyszukiwania
W badaniach nad sztuczną inteligencją powszechnie uznaje się, ŋe wyszukiwanie ma kluczowe znaczenie dla budowy inteligentnych systemów i projektowania inteligentnych agentów. Na przykģad Newell stwierdziģ, ŋe poszukiwanie jest fundamentalne dla inteligentnego zachowania. Z perspektywy behawioralnej wyszukiwanie moŋe byæ uznane za meta-zachowanie, w którym agent podejmuje decyzję, które zachowanie naleŋy do zestawu moŋliwych zachowaņ do wykonania w danej sytuacji. Innymi sģowy, moŋna go zdefiniowaæ jako proces behawioralny, który agent stosuje, aby podejmowaæ decyzje dotyczące wyboru dziaģaņ, które powinien wykonaæ, aby wykonaæ okreķlone zadanie. Zadanie moŋe obejmowaæ wyŋsze poziomy zachowaņ poznawczych, takie jak uczenie się, strategia, wyznaczanie celów, planowanie i modelowanie (nazywane byģy wyborem akcji w modelu Boynów Reynoldsa). Jeķli nie ma decyzji do podjęcia, wyszukiwanie nie jest wymagane. Jeķli agent juŋ wie, ŋe okreķlony zestaw dziaģaņ lub zachowania jest odpowiedni dla danej sytuacji, nie ma potrzeby poszukiwania odpowiedniego zachowania, a zatem dziaģania moŋna zastosowaæ bez podejmowania jakiejkolwiek decyzji. Wyszukiwanie moŋe byæ uwaŋane za zachowanie, które agent wykazuje, gdy ma niewystarczającą wiedzę, aby rozwiązaæ problem. Problem jest okreķlony przez aktualną sytuację agenta, która jest okreķlona przez warunki ķrodowiskowe, wģasne okolicznoķci i wiedzę, którą agent obecnie ma do dyspozycji. Jeķli agent nie ma wystarczającej wiedzy, aby rozwiązaæ dany problem, moŋe zdecydowaæ się na poszukiwanie dalszej wiedzy na temat problemu. Jeķli ma juŋ wystarczającą wiedzę, nie będzie musiaģ stosowaæ zachowania w celu rozwiązania problemu. Agent uŋywa zachowania związanego z wyszukiwaniem, aby odpowiedzieæ na pytanie, na które nie zna odpowiedzi lub ukoņczyæ zadania, którego nie potrafi wykonaæ. Agent musi eksplorowaæ ķrodowisko, podąŋając za więcej niŋ jedną ķcieŋką, aby uzyskaæ tę wiedzę. Eksploracja ķrodowiska odbywa się w sposób analogiczny do wczesnych odkrywców kontynentów amerykaņskich lub australijskich lub osób odkrywających labirynt w ogrodzie, takich jak Labirynt Paģacu Hampton Court lub Labirynt Chevening House. W przypadku dwóch labiryntów ogrodowych, osoby próbujące dostaæ się do ķrodka labiryntu muszą zastosowaæ zachowanie poszukiwawcze, jeķli nie mają wiedzy o tym, gdzie to jest. Jeķli jednak wykonają z nimi mapę, nie muszą juŋ korzystaæ z wyszukiwania zachowanie, gdy mapa dostarcza im informacji o tym, które ķcieŋki pokonaæ, aby dotrzeæ do centrum. Pierwsi amerykaņscy odkrywcy, Lewis i Clark, zostali poinstruowani przez Thomasa Jeffersona, by zbadaģ Missouri i znalazģ drogę wodną przez kontynent do Pacyfiku. Nie wiedzieli juŋ, jak duŋy jest kontynent lub co tam byģo i potrzebowali fizycznie zbadaæ kraj. Wybrali kierunek w kierunku zachodnim, póģnocno-zachodnim, wzdģuŋ ķcieŋki wzdģuŋ rzeki Missouri. Podobnie australijscy odkrywcy Burke i Wills poprowadzili ekspedycję rozpoczynającą się od Melbourne w celu dotarcia do Zatoki Carpentaria. Ziemia w tym czasie musiaģa zostaæ zbadana przez europejskich osadników. Wyprawa uniemoŋliwiaģa osiągnięcie ostatecznego celu, zaledwie trzy mile od póģnocnej linii brzegowej z powodu bagien namorzynowych, a co gorsza, przywódcy ekspedycji zginęli w drodze powrotnej. Podczas wyszukiwania agent moŋe przyjąæ róŋne zachowania, które okreķlają sposób wyszukiwania. Przyjęte zachowanie wyszukiwania moŋe mieæ znaczący wpģyw na skutecznoķæ wyszukiwania. Na przykģad zģe przywództwo zostaģo obwiniane za nieudaną wyprawę Burke'a i Willsa. Zachowanie moŋe byæ uwaŋane za strategię przyjętą przez agenta podczas przeprowadzania wyszukiwania. Te zachowania związane z wyszukiwaniem moŋemy rozpatrywaæ z perspektywy ucieleķnionego agenta. Typ zachowania wyszukiwania jest okreķlany zarówno przez przykģad wykonania agenta, jak i to, czy agent stosuje reaktywne lub bardziej poznawcze zachowanie podczas wykonywania wyszukiwania. Widzieliķmy juŋ wiele przykģadów tego, w jaki sposób agent moŋe przeprowadziæ wyszukiwanie w ķrodowisku jako efekt uboczny zastosowania czysto reaktywnego zachowania. Moŋemy okreķliæ te typy zachowaņ wyszukiwania jako reaktywne wyszukiwanie. Moŋemy równieŋ uŋyæ terminu wyszukiwanie poznawcze w przypadkach, w których agent ma zdolnoķæ rozpoznania, ŋe istnieje wybór, gdy wybór pojawia się w ķrodowisku (np. Gdy agent osiąga skrzyŋowanie w labiryncie). Ten akt rozpoznawania jest podstawową częķcią poznawczych zachowaņ poszukiwawczych i jest związany z sytuacją, w której znajduje się agent, sposobem poruszania się jego ciaģa i interakcji ze ķrodowiskiem. Jest to równieŋ związane z tym, co dzieje się w ķrodowisku zewnętrznym i / lub co dzieje się z innymi agentami w tym samym ķrodowisku, jeķli takie istnieją. Ponadto do wykonania dowolnego wyszukiwania moŋna uŋyæ pojedynczego agenta, ale nic nie powstrzymuje nas przed uŋyciem więcej niŋ jednego agenta do wykonania wyszukiwania. Moŋemy przyjąæ perspektywę z wieloma agentami, aby opisaæ, w jaki sposób moŋna przeprowadziæ poszczególne wyszukiwania, aby wyjaķniæ, w jaki sposób róŋnią się wyszukiwania. W tym przypadku skutecznoķæ okreķlonego wyszukiwania moŋna oceniæ, porównując liczbę agentów potrzebnych do przeprowadzenia wyszukiwania i iloķæ informacji, które są między nimi przekazywane.
Problemy z wyszukiwaniem
Istnieje wiele problemów wymagających wyszukiwania o róŋnym stopniu trudnoķci. Uproszczone lub "zabawkowe" problemy to w większoķci problemy syntetyczne i niezwiązane z rzeczywistym ŋyciem. Jednak problemy te mogą byæ przydatne dla projektantów w uzyskaniu wglądu w problem wyszukiwania. Po zbadaniu wģaķciwoķci róŋnych zachowaņ dotyczących wyszukiwania w przypadku problemów z zabawkami, moŋna je dostosowaæ i / lub dostosowaæ do rzeczywistych problemów. Aby zilustrowaæ róŋne problemy z wyszukiwaniem, w tej sekcji opisano trzy problemy, które zostaģy w szczególnoķci symulowane w NetLogo - są to model Mazury, model Misjonarzy i Cannibal oraz model Wyszukiwanie Kevina Bacona. Są to problemy z zabawkami nie dlatego, ŋe są sztucznymi problemami, ale z powodu ich względnej prostoty. Zapewniają one jednak uŋyteczne stanowiska testowe podczas opracowywania i oceny skutecznoķci róŋnych zachowaņ związanych z wyszukiwaniem, poniewaŋ moŋemy ich uŋyæ do porównania skutecznoķci kaŋdego z nich. Następnie dzięki tym informacjom moŋemy przystąpiæ do rozwiązywania znacznie większych lub trudniejszych problemów związanych z wyszukiwaniem. Klasycznym problemem z zabawkami, często wykorzystywanym do zademonstrowania aspektów poszukiwaņ, jest problem misjonarzy i kanibali. W tym dylemacie jest trzech misjonarzy i trzech kanibali. Chcą, aby wszyscy przeszli przez rzekę, uŋywając kajaka, który ma tylko dwie osoby, ale problem polega na tym, ŋe jeķli kanibale kiedykolwiek będą przewyŋszaæ liczbę misjonarzy na dowolnym etapie, wtedy kanibale zjedzą misjonarzy. Rysunek poniŋej pokazuje kilka zrzutów ekranu z animacji dostarczonych przez misjonarzy i model Cannibals NetLogo , który demonstruje rozwiązanie problemu.
Górny obraz przedstawia stan początkowy, z trzema misjonarzami, trzema kanibalami i czóģnem po lewej stronie rzeki. Osoby w szarym kolorze reprezentują misjonarzy, a osoby w czerwonych barwach reprezentują kanibali. Ķrodkowy obraz przedstawia stan poķredni, w którym po lewej stronie znajduje się jeden misjonarz i jeden kanibal, w poģowie drogi przez rzekę jest dwóch misjonarzy, a po prawej stronie rzeki są dwaj kanibale. Dolny obraz przedstawia ostateczny stan poŋądany lub docelowy, w którym wszyscy trafiają na prawą stronę. Szukanie ludzi to problem, który często pojawia się w prawdziwym ŋyciu. Ma to równieŋ wpģyw na wiele problemów sieci komputerowych, na przykģad wykrywanie zasobów w sieciach typu peer-to-peer, w których musi znajdowaæ się okreķlony zasób, taki jak plik lub komputer o okreķlonych wymaganiach procesora. Model wyszukiwania Kevina Bacona symuluje ten problem, tworząc sieci losowe, jak pokazano na rysunku poniŋej
Okreķlony węzeģ w sieci jest okreķlony jako stan poŋądany lub docelowy - jest to pokazane przez węzeģ narysowany jako gwiazda na ķrodku obrazu. Wyszukiwanie rozpoczyna się od losowego węzģa w sieci - dla pokazanego obrazu węzģem początkowym byģ węzeģ b154 w ķrodkowym prawym rogu obrazu. W tym scenariuszu analogią do prawdziwego problemu z ŋyciem jest sala peģna studentów, w której celem jest przekazanie okreķlonego przedmiotu, np. Notatki od osoby do osoby, aŋ dotrze ona do zamierzonego odbiorcy. Rozbieŋnoķæ w rzeczywistym problemie pojawia się, gdy agenci w symulacji (reprezentowani jako węzģy w sieci) mają okreķlone ograniczenia dotyczące ich zdolnoķci sensorycznych, które sprawiają, ŋe symulacja jest bardziej analogiczna do wyszukiwania w sieciach komputerowych. W tym przypadku agenci są "ķlepi" w tym sensie, ŋe nie mają pojęcia o globalnej konfiguracji sieci i mają jedynie lokalną wiedzę o tym, co jest bezpoķrednio wokóģ nich (tj. Znają tylko ģącza do sąsiednich węzģów). Ponadto agenci nie wiedzą, gdzie znajduje się węzeģ gwiazdy. Problem wyszukiwania moŋna scharakteryzowaæ jako czynnik eksplorujący automat skoņczony w przestrzeni n-wymiarowej. Jeden lub więcej stanów jest okreķlanych jako stany początkowe - to jest lokalizacja, w której agenci wykonujący wyszukiwanie najpierw wybierają się na swoje poszukiwania. Te stany początkowe są poģączone z innymi stanami poķrednimi, które z kolei są poģączone z kolejnymi stanami itd. ostatecznie poģączenia będą prowadziæ do poŋądanych lub docelowych stanów po zakoņczeniu wyszukiwania, w przeciwieņstwie do sytuacji modelowanej w poszukiwaniu modelu Kevina Bacona. Wyszukiwanie jest wymagane, gdy agenci nie wiedzą, jak dostaæ się do poŋądanych stanów lub chcą znaležæ najkrótszą ķcieŋkę do ŋądanych stanów. Jeķli znają juŋ ķcieŋkę, wyszukiwanie nie jest wymagane. W przeciwnym razie muszą zbadaæ automat skoņczony, dopóki nie znajdą poŋądanego stanu lub dopóki nie znajdą najkrótszej ķcieŋki.
Niedoinformowane (ķlepe) wyszukiwanie
Wyszukiwanie niedoinformowane lub ķlepe następuje, gdy agent nie ma informacji o szukanym ķrodowisku. Prawdziwą analogią do tego typu poszukiwaņ jest ķlepa osoba szukająca labiryntu, w którym nigdy wczeķniej nie byģ, bez wczeķniejszej znajomoķci jego wymiarów czy miejsca pobytu w centrum lub wyjķcia z labiryntu. Jednym podejķciem, które moŋe podjąæ "ķlepy" agent wyszukiwania, jest kontynuowanie dokonywania jednego konkretnego wyboru na kaŋdym skrzyŋowaniu, z którym się spotyka, i kontynuowanie aŋ do momentu, gdy dotrze do wyjķcia lub centrum (celu) lub dopóki nie osiągnie ķlepego zauģka. Jeķli to drugie, moŋe on następnie wróciæ do ostatniego skrzyŋowania, które odwiedziģ, ma ķcieŋki, których jeszcze nie przeszukiwaģ, a następnie wybiera jedną z nich. Wielokrotnie stosuje to zachowanie, dopóki cel nie zostanie osiągnięty. Ten agent ma jeszcze jedną moŋliwoķæ wyboru - kolejnoķæ, którą wybiera, by podąŋaæ ķcieŋkami. Mógģ na przykģad wybraæ losowe ķcieŋki, albo mógģ zawsze najpierw podąŋaæ za pierwszą gaģęzią po swojej prawej stronie, a następnie ķledziæ kolejne gaģęzie zgodnie z ruchem wskazówek zegara. Ten typ wyszukiwania nazywa się najpierw gģębokim wyszukiwaniem. Aby uproķciæ poniŋszą dyskusję oraz wyjaķniæ rozwiązania oparte na wielu agentach, które zostaģy opracowane dla modeli NetLogo opisane poniŋej, odejdziemy od rzeczywistej analogii pojedynczego agenta wykonującego wyszukiwanie w następujący sposób. Na kaŋdym skrzyŋowaniu lub punkcie decyzyjnym w wyszukiwaniu, zamiast samego agenta, który kontynuuje wyszukiwanie wzdģuŋ pojedynczej ķcieŋki, zapewniamy agentowi moŋliwoķæ wysyģania wģasnych klonów wzdģuŋ wszystkich ķcieŋek, które znajdzie. W procesie klonowania się on następnie umrze. W przypadku pierwszego wyszukiwania, jeden z nowo sklonowanych agentów zostanie wybrany, aby kontynuowaæ wyszukiwanie, podczas gdy pozostali siedzą i czekają, na wypadek, gdyby byli potrzebni w póžniejszym czasie. Ten proces tworzenia klonów, a następnie wybieranie jednego z klonów w celu dalszego wyszukiwania trwa do momentu osiągnięcia celu lub ķlepego zauģka. Jeķli to drugie, klon zginie bez tworzenia kolejnych klonów, a wyszukiwanie będzie kontynuowane z klonem, który czekaģ najkrócej. Zilustrowano to na rysunku , który pokazuje pierwsze wyszukiwanie Gģębokiego Modelu Bacinonu
W prawym górnym rogu pojedynczy agent zaczyna od lewego dolnego węzģa oznaczonego etykietą b26 i próbuje wyszukaæ węzeģ celu narysowany jako biaģa gwiazda. Agent ten następnie przechodzi do węzģa b14 po klonowaniu się jeden raz, a następnie tworzy dwa wģasne klony, poniewaŋ istnieją kolejne dwie moŋliwe ķcieŋki do naķladowania (do węzģów b5 i b23), jak pokazano w prawym górnym obrazie. Następnie umiera i wyszukiwanie jest kontynuowane przez jeden z agentów, w tym przypadku agent w węžle b5. Wyszukiwanie kontynuuje wzdģuŋ nagģówka gaģęzi b5 przez szczęķcie w kierunku węzģa celu, aŋ osiągnie węzeģ b3, jak pokazano w lewym dolnym obrazie. Następnie wybierany jest jeden klon, aby przeszukaæ boczną ķcieŋkę, która kieruje się na póģnoc w punkcie b8, ale gdy ta ķcieŋka zostanie caģkowicie przeszukana, klon na b1 przejmuje i ostatecznie węzeģ celu zostaje osiągnięty, jak pokazano na prawym dolnym obrazie. Oczywistą modyfikacją tego typu wyszukiwania jest umoŋliwienie przeszukiwania jednoczeķnie więcej niŋ jednego klonu agenta. Innymi sģowy, zamiast pojedynczego klona wykonującego wyszukiwanie samodzielnie, moŋemy wysģaæ wszystkie klony, aby równolegle wyszukiwaæ razem. Ten rodzaj wyszukiwania nazywa się najpierw szerokim wyszukiwaniem. Sposób przeszukiwania sieci w poszukiwaniu modelu Kevina Bacona przy uŋyciu pierwszego wyszukiwania szerokoķci pokazano na rysunku
Lewy obraz to zrzut ekranu podczas poķredniej częķci wyszukiwania. Prawy obrazek pokazuje wyszukiwanie po zakoņczeniu. Aby zrozumieæ fundamentalne róŋnice między tymi dwoma róŋnymi rodzajami poszukiwaņ, moŋemy pomyķleæ o analogii wyprawy Lewisa i Clarka badającej amerykaņski kontynent po rzece Missouri i jej dopģywach. W miarę postępów "granica" ich wiedzy "rozwijaģaby się". Gdyby ta ekspedycja przyjęģa pierwsze poszukiwania w zakresie gģębokoķci, granica rozszerzyģaby się, podąŋając za jednym konkretnym odgaģęzieniem rzeki - coraz gģębiej w dóģ w jednym oddziale. Jeķli dopģyw zatrzymaģ się, ekspedycja powróciģaby do ostatniego skrzyŋowania i zaczęģa szukaæ alternatywnej ķcieŋki. Nawiązując do powyŋszej analogii, klony mogą byæ uwaŋane za lokalizacje przeszģych jažni, do których powracają, gdy jedna ķcieŋka zakoņczyģa się niepowodzeniem. Z drugiej strony wyprawa przyjmuje politykę dzielenia zespoģu, aby przeszukiwaæ alternatywne gaģęzie w tym samym czasie. W tym przypadku granica rozszerza się na zewnątrz tym samym tempie, podobnie jak falowanie rozszerza się równomiernie na zewnątrz, gdy kamyk wrzuca się do stawu. Uŋywając innej analogii, poszerzającą się granicę moŋna uwaŋaæ za "drzewo", z korzeniami coraz gģębiej wnikającymi w glebę. W przypadku pierwszego wyszukiwania jeden root jest narastający naraz, a to staje się coraz gģębsze (stąd dlaczego ten szczególny rodzaj wyszukiwania nazywany jest wyszukiwaniem od początku do gģębokoķci), dopóki nie zablokuje go podģoŋe skalne. W przypadku pierwszego wyszukiwania wszystkie korzenie rosną w podobnym tempie i równomiernie rosną w dóģ. Moŋemy przyjrzeæ się modelowi Searching Mazes, aby dokģadniej zilustrowaæ róŋnice między tymi dwoma wyszukiwaniami. Moŋemy wybraæ pusty labirynt do przeszukania, a następnie ustawiæ move-forward-behaviour i move-forward- behaviour-after-turning, choosera na move-forward-n-steps-unlesshit- wall a takŋe ustawienie suwaka move-forward-step-amount na 2. Zapewni to, ŋe wyszukiwanie rozszerzy się do pustej przestrzeni tylko o 2 kroki naraz, jak pokazano na zrzutach ekranu z rysunku

Graficznie ilustrują róŋnice między dwoma wyszukiwaniami. Gģębokie pierwsze wyszukiwanie jest oportunistyczne, zmierzając w dowolnie wybranym przez siebie kierunku, podczas gdy pierwsze wyszukiwanie jest dokģadniejsze, a kaŋda moŋliwoķæ jest przeszukana, zanim przejdzie dalej. Terminy "granica", "drzewo" i "rozszerzenie wyszukiwania" są często uŋywane do opisu wyszukiwania. Moŋliwe ķcieŋki w wyszukiwaniu mogą byæ traktowane jak drzewo wyszukiwania przy uŋyciu analogii gaģęzi i liķci - to znaczy, analogia do drzewa rosnącego nad ziemią, a nie do korzeni rosnących w glebie jak wyŋej. W tym przypadku granica wyszukiwania moŋe byæ traktowana jako węzģy liķcia drzewa. Są to węzģy drzewa, które naleŋy następnie przeszukaæ. Dla kaŋdego węzģa liķci istnieje zdefiniowany zestaw moŋliwych węzģów, które moŋna rozszerzyæ. Na przykģad dla lewego górnego obrazu na powyŋszym rysunku zbiór rozszerzonych węzģów dla węzģa b14 to {b5, b23, b26}. Mimo ŋe pochodzi on wģaķnie z węzģa b26, nic nie stoi na przeszkodzie, aby wyszukiwanie powróciģo do miejsca, z którego pochodzi, chyba ŋe wyszukiwanie wyražnie uniemoŋliwia ponowne odwiedzanie węzģów. Zaletą nie ponownego odwiedzania węzģów jest to, ŋe wyszukiwanie nie będzie marnowaģo czasu przeszukiwania na coķ, co juŋ przeszukaģo; jednak wadą jest to, ŋe musi rejestrowaæ, gdzie byģ. W niektórych aplikacjach, w których występuje bardzo duŋa liczba węzģów do odwiedzenia (na przykģad roboty indeksujące muszą odwiedzaæ miliardy węzģów), przechowywanie zestawu juŋ odwiedzonych węzģów moŋe byæ kosztowne i stanowiæ powaŋne problemy inŋynieryjne. Wszystkie trzy modele NetLogo zapewniają przeģącznik interfejsu, który ustawia zmienne allow-revisited-states, aby wģączyæ lub wyģączyæ ponowne odwiedzanie węzģów. Modele równieŋ utrzymują globalną zmienną o nazwie visited-nodes, która jest listą wszystkich juŋ odwiedzonych węzģów. To, czy ponowne odwiedzanie węzģów jest dozwolone czy nie, jest waŋnym czynnikiem wpģywającym na skutecznoķæ róŋnych wyszukiwaņ. Jest to widoczne na przykģadzie modelu Misjonarzy i Kanibali, na przykģad w przypadku niektórych wyszukiwaņ wymagających znacznie większej liczby agentów wyszukujących, aby ukoņczyæ wyszukiwanie lub w niektórych przypadkach wyszukiwanie nie zakoņczyģo się w ogóle. Rysunek 8.6 pokazuje zrzut ekranu modelu Misjonarzy i Cannibal dla pierwszego wyszukiwania z dozwolonym powtórką.
Model pokazuje wykonanie wyszukiwania w miarę jego kontynuacji - kaŋda iteracja jest wyķwietlana po naciķnięciu przycisku go once" w interfejsie. W tym przypadku moŋemy przedstawiæ stan, w którym wyszukiwanie osiągnęģo za pomocą krotki zawierającej trzy liczby - liczbę misjonarzy po lewej stronie rzeki (0 do 3), liczbę kanibali po lewej stronie (od 0 do 3) ), a liczba kajaków po lewej stronie (1 lub 0). Na przykģad stan początkowy jest reprezentowany przez krotkę (3, 3, 1), poniewaŋ na początku jest 3 misjonarzy, 3 kanibali i 1 kajak po lewej stronie rzeki. Poŋądany lub docelowy stan jest reprezentowany przez krotkę (0, 0, 0) ze wszystkimi i czóģnem teraz po prawej stronie. Istnieje 32 moŋliwych stanów, do których moŋe dotrzeæ wyszukiwanie, ale nie wszystkie z nich będą dozwolone - na przykģad krotka (1, 3, 0) nie jest stanem dozwolonym, poniewaŋ reprezentuje przypadek, gdy liczba kanibali jest większa niŋ liczba misjonarzy o 2. Ta reprezentacja pozwala nam wizualizowaæ wyszukiwanie przy uŋyciu równolegģego ukģadu wspóģrzędnych, jak pokazano na powyŋszym rysunku. Iteracja przeszukiwania za kaŋdym razem jest pokazywana na osiach równolegģych, z początkiem wyszukiwania pokazanym w ticku t = 0 po lewej stronie. Następnie wyszukiwanie przenosi się do trzech moŋliwych stanów w ticku t = 1: do (3, 2, 0), po tym jak jeden kanibal przepģynąģ na prawo w kajaku; do (3, 1, 0), po dwóch kanibali wioķlarzy w kajaku; i do (2, 2, 0) po tym, jak jeden misjonarz i jeden kanibal przemaszerowali. Na rysunku przedstawiono ķcieŋki, którymi zajmuje się po raz pierwszy wyszukiwanie w ķrodowisku przestrzeni stanów. Liczba czynników znacząco roķnie wraz z kaŋdym tikkiem. Zrzut ekranu pokazuje równieŋ jedno moŋliwe rozwiązanie narysowane na czerwono. Jest to rysowane od lewej do prawej podczas animacji pokazanej na dole po naciķnięciu przycisku go-animacji w interfejsie. Moŋemy zatrzymaæ wyszukiwanie od ponownego stawiania stanów, ustawiając przeģącznik allowed-revisited-states w interfejsie na Off. Ma to dramatyczny efekt, eliminując większoķæ ķcieŋek z wyszukiwania, jak pokazano na rysunku
Podobny efekt widaæ po pierwszym wyszukiwaniu. Rysunek poniŋszy pokazuje, co dzieje się z pierwszą gģębią wyszukiwania w modelu Misjonarzy i Cannibal z dozwolonym powtórką.
Zrzut ekranu pokazuje wyszukiwanie wielokrotnie wybierające te same zģe ķcieŋki, które nigdy nie doprowadziģy do rozwiązania. W koņcu wyszukiwanie zostaje przerwane, poniewaŋ trwa zbyt dģugo. Rysunek ponizje pokazuje, co dzieje się z pierwszym wyszukiwaniem gģębokoķci, gdy ponowne odwiedzanie jest niedozwolone.
Wyszukiwanie niemal natychmiast znajduje poprawną ķcieŋkę, poniewaŋ alternatywne zģe ķcieŋki są eliminowane jako moŋliwoķci.
Wdraŋanie wyszukiwania niedoinformowanego w NetLogo
Kod rozszerzania granicy wyszukiwania dla modelu wyszukiwania Kevina Bacona pokazany jest w NetLogoCode
to expand-paths [searcher-agent]
;; rozwija wszystkie moŋliwe ķcieŋki dla wyszukiwarki-agenta
foreach sort [link-neighbors] of [location] of searcher-agent
[ expand-path searcher-agent ? ]
end
to expand-path [searcher-agent node]
; agent wyszukiwania tworzy nowy agent wyszukiwania, który rysuje ķcieŋkę w pliku
; sieæ od bieŋącej pozycji do węzģa
let xcor1 0
let ycor1 0
if not search-completed
[ ; utwórz nową ķcieŋkę, tworząc agenta do jej przeszukiwania
; sprawdž, czy ķcieŋka zostaģa juŋ odwiedzona
if allow-revisited-nodes or not member? node visited-nodes
[
set path-found true
if not allow-revisited-nodes
[set visited-nodes fput node visited-nodes]
; dodaj do przodu zestawu odwiedzonych węzģów
hatch-searchers 1
[ ; wyszukiwarka klonów
set searchers-used searchers-used + 1
set size 2
set pen-size 5
set color magenta
set shape "person"
set xcor [xcor] of searcher-agent
set ycor [ycor] of searcher-agent
set xcor1 xcor ; copy xcor
set ycor1 ycor ; copy ycor
set heading [heading] of searcher-agent
set time [time] of searcher-agent + 1
set path-cost [path-cost] of searcher-agent
pen-down
; move to the node
set location node
move-to location
set xcor [xcor] of self
set ycor [ycor] of self
; przyrost ķcieŋki ķcieŋki przy wykonywaniu zachowania za pomocą
; Odlegģoķæ euklidesowa
set path-cost path-cost +
euclidean-distance xcor1 ycor1 xcor ycor
set estimated-cost (heuristic-function xcor ycor)
set height hill-height xcor ycor
stamp ]
]
if goal-node node
[ set search-completed true ]
]
end
to-report goal-node [this-node]
;; zwraca true, jeķli agent wyszukiwarki osiągnąģ cel
report this-node = kevin-bacon-node
end
Procedura expand-paths wywoģuje podporcedurę expand-path dla kaŋdego węzģa sąsiadującego z węzģem w bieŋącej lokalizacji agenta wyszukującego, tj. kaŋdy węzeģ w zbiorze link-neighborough węzģa agenta wyszukującego. Ta pod-procedura tworzy nową ķcieŋkę do kaŋdego sąsiedniego węzģa (przekazanego jako parametr), tworząc agenta do przeszukania. Najpierw sprawdza jednak, czy ķcieŋka zostaģa juŋ odwiedzona, a ponowne odwiedzanie węzģów jest niedozwolone, a jeķli jest to prawdą, nie utworzy nowego agenta. Ķcieŋki rozwinięcia procedury wywoģują ķcieŋkę rozszerzającą pod procedurą dla kaŋdego węzģa sąsiadującego z węzģem w bieŋącej lokalizacji agenta wyszukującego, tj. Kaŋdy węzeģ w zestawie węzģów-sąsiadów węzģa agenta wyszukującego. Ta pod-procedura tworzy nową ķcieŋkę do kaŋdego sąsiedniego węzģa (przekazanego jako parametr), tworząc agenta do przeszukania. Najpierw sprawdza jednak, czy ķcieŋka zostaģa juŋ odwiedzona, a ponowne odwiedzanie węzģów jest niedozwolone, a jeķli jest to prawdą, nie utworzy nowego agenta. Po utworzeniu nowego agenta jest on początkowo umieszczany w lokalizacji bieŋącego agenta wyszukiwania, a następnie jest przenoszony do sąsiedniego węzģa. Ta pod-procedura utrzymuje równieŋ koszt ķcieŋki - odlegģoķæ przebytą do tej pory podczas wyszukiwania wzdģuŋ aktualnej ķcieŋki; w tym modelu obliczany jest koszt ķcieŋki za pomocą odlegģoķci euklidesowej. Kiedy nowy agent zostanie sklonowany, skopiuje on dotychczasowe koszty ķcieŋki, a liczba ta zostanie zwiększona po przeniesieniu agenta klonów do nowej lokalizacji. Szacowany koszt dotarcia do celu i wysokoķci są równieŋ obliczane (są one wykorzystywane do wyszukiwania informacji i wspinaczki górskiej. Pod koniec procedury podrzędnej wykonywane jest sprawdzenie, czy węzeģ celu zostaģ osiągnięty przez wywoģanie procedury goal-node. Ta procedura po prostu sprawdza, czy węzeģ jest węzģem bocznym Kevina zdefiniowanym podczas instalacji (reprezentowanym przez gwiazdę na zrzutach ekranu). Procedury wyszukiwania od pierwszego do najmniejszego i pierwszego wg gģębokoķci są definiowane za pomocą procedury expand-paths, jak pokazano w kodzie NetLogo. Kod jest taki sam dla wszystkich trzech modeli - do wyszukiwania. Model Kevina Bacona oraz modele Searching Maze and Missionaries and Cannibals. Róŋnica występuje dla kaŋdego modelu w sposobie rozszerzania ķcieŋek - czyli sposobu definiowania procedury expand-paths - poniewaŋ zaleŋy to od natury problemu i sposobu definiowania ķcieŋek w ķrodowisku.
to expand-breadth-first-search
; rozszerz wyszukiwanie, dodając więcej agentów wyszukiwania
ask searchers
[
expand-paths (searcher who)
die ; odetnij agentów nadrzędnych uŋywanych w niŋszych odstępach czasu
]
end
to expand-depth-first-search
; rozwiņ wyszukiwanie, postępując zgodnie z najnowszą ķcieŋką
; nie podąŋaj równolegle innymi ķcieŋkami; po prostu wykonaj jedną z nich
set path-found false
ask first (sort-by [[time] of ?1 > [time] of ?2] searchers)
[
expand-paths (searcher who)
die ; ten agent wykonaģ swoją pracę; to dzieci wykonują teraz pracę
]
end
Najpierw wyszukiwanie rozszerza ķcieŋki dla wszystkich obecnych agentów wyszukujących za pomocą polecenia ask, wywoģując procedurę expand-paths przed zabiciem kaŋdego z nich. Polecenie ask searchers zapewnia, ŋe wyszukiwanie jest kaŋdorazowo rozszerzane w przypadkowej kolejnoķci. W przeciwieņstwie do tego, pierwsze wyszukiwanie gģębi rozszerza ķcieŋki dla pojedynczego agenta, najnowszego wyszukiwacza, który ma najwyŋszą zmienną czasową okreķlaną przez sort-by reporter, zanim go zabije. Proste odmiany tych dwóch procedur prowadzą do róŋnych zachowaņ związanych z wyszukiwaniem. Jedną z odmian jest najpierw rozszerzenie ķcieŋki najniŋszego kosztu. Jest to tak zwane jednolite wyszukiwanie kosztów, którego kod jest pokazany w kodzie NetLogo. Kolejnoķæ rozwijania agentów wyszukujących jest okreķlana przez raport sort-by, który zamawia agentów w kolejnoķci rosnącej wedģug path-cost
to expand-uniform-cost-search
; rozszerz wyszukiwanie, postępując najpierw ķcieŋkami o najniŋszych kosztach
set path-found false
ask first (sort-by [[path-cost] of ?1 < [path-cost] of ?2] searchers)
[
expand-paths (searcher who)
die ; ten agent wykonaģ swoją pracę; to dzieci wykonują teraz pracę
]
end
W przypadku pierwszego wyszukiwania w gģąb moŋemy zmniejszyæ ograniczenie, ŋe jeden agent przeprowadza wyszukiwanie, i umoŋliwia więcej niŋ jednemu agentowi jednoczesne wyszukiwanie w tym samym czasie. W limicie, w którym nie ma ograniczeņ co do liczby agentów, które mogą wyszukiwaæ w tym samym czasie, będzie to równoznaczne z szerokim wyszukiwaniem. Wariant wielo-agentowy wyszukiwania z gģębokim pierwszym pokazano w NetLogo Code poniŋej. Jedyne zmiany z powyŋszego pierwszego kodu to uŋycie zmiennej globalnej max-agents-to-expand, aby okreķliæ, ilu agentów powinno jednoczeķnie wyszukiwaæ w kaŋdej iteracji (moŋna to zmieniæ w interfejsie) i korzystaæ z n-reporter zamiast first reportera w poleceniu ask. Polecenie let przed poleceniem ask jest wymagane, gdy liczba agentów jest mniejsza niŋ max-agent-to-expand, który zwykle występuje na początku wyszukiwania, w przeciwnym razie n-of reportera spowoduje bģąd wykonania.
to expand-MA-depth-first-search
; rozszerz wyszukiwanie, podąŋając najdģuŋszą ķcieŋką
; podąŋaj równolegle innymi ķcieŋkami; ale nie podąŋaj za nimi wszystkimi
false
let agents ifelse-value (count searchers < max-agents-to-expand)
[ count searchers ]
[ max-agents-to-expand ]
ask n-of agents turtle-set
(sort-by [[time] of ?1 > [time] of ?2] searchers)
[
expand-paths (searcher who)
die ; ten agent wykonaģ swoją pracę; to dzieci wykonują teraz pracę
]
end
Inną odmianą pierwszego wyszukiwania jest ograniczenie gģębi wyszukiwania do okreķlonej maksymalnej gģębokoķci. Moŋe to byæ przydatne, gdy maksymalna gģębokoķæ drzewa wyszukiwania jest nieznana i chcielibyķmy, aby wyszukiwanie najpierw rozpoczęģo alternatywne krótsze ķcieŋki. W tym przypadku ķcieŋki są rozszerzane tylko dla tych agentów, których zmienna czasowa jest mniejsza lub równa temu limitowi. Jest to nazywane wyszukiwaniem z ograniczeniem gģębokoķci, a kod jest wyķwietlany w kodzie NetLogo
to expand-depth-limited-search
; rozszerz wyszukiwanie, podąŋając najdģuŋszą ķcieŋką
; nie podąŋaj równolegle innymi ķcieŋkami; po prostu wykonaj jedną z nich
; ogranicz gģębokoķæ wyszukiwania do maksymalnej gģębokoķci
expand-depth-limited-search-1 max-depth
end
to expand-depth-limited-search-1 [maxdepth]
;rozszerz wyszukiwanie, podąŋając najdģuŋszą ķcieŋką
; nie podąŋaj równolegle innymi ķcieŋkami; po prostu wykonaj jedną z nich
; ogranicz gģębokoķæ wyszukiwania do maxdepth
set path-found false
ask first (sort-by [[time] of ?1 > [time] of ?2] searchers)
[
if (time <= maxdepth)
[ expand-paths (searcher who) ]
; rozwinąæ tylko, jeķli nie zostanie przekroczony limit gģębokoķci
umrzeæ; ten agent wykonaģ swoją pracę; to dzieci wykonują teraz pracę
]
end
Procedura expand-depth-limited-search wywoģuje podprocedurę expand-depth-search-1 z parametrem max-depth, która jest zmienną zdefiniowaną w interfejsie. Podprocedura jest po prostu odmianą standardowej procedury wyszukiwania z gģębokim pierwszym zatrzymaniem ekspansji ķcieŋek, jeķli zostanie osiągnięte ,max-depth gģębokoķci. Problem z wyszukiwaniem ograniczonym do gģębi jest taki, ŋe nie ma gwarancji, ŋe wyszukiwanie zakoņczy się powodzeniem. Jeķli wybieramy konkretną maksymalną gģębokoķæ, wówczas poŋądany lub docelowy stan moŋe znajdowaæ się tuŋ poza maksymalną gģębokoķcią odcięcia. Wariantem rozwiązania tego problemu jest "Iteracyjne pogģębianie wyszukiwania". W tym przypadku, ograniczone wyszukiwanie ograniczone jest do coraz większych maksymalnych gģębokoķci, jak pokazano w kodzie NetLogo
to expand-iterative-deepening-search
; rozszerz wyszukiwanie, wykonując iteracyjnie wyszukiwanie z ograniczoną gģębokoķcią
; na coraz większe gģębokoķci
set IDS-depth 1
set person-colour magenta
while [ IDS-depth <= max-depth ]
[
while [count searchers != 0]
[ expand-depth-limited-search-1 IDS-depth ]
set IDS-depth IDS-depth + 1
; change colour of person to reflect the increased maxdepth of search
if (person-colour > 5)
[ set person-colour person-colour - 5 ]
create-searchers 1 [ setup-searcher ]
]
set person-colour magenta ; przywróæ domyķlny kolor
end
Zmienna IDS-depth rejestruje, jaka jest bieŋąca maksymalna gģębokoķæ dla wyszukiwania z ograniczeniem gģębokoķci. Na początku ustawiona jest na 1, a następnie kod wykorzystuje pętlę while do wykonania wyszukiwania z ograniczeniem gģębokoķci poprzez wielokrotne wywoģywanie procedury expand-depth-limited-search-1, dopóki nie będzie więcej wyszukiwaņ (dzieje się tak, gdy gģębokoķæ ograniczone wyszukiwanie osiągnęģo maksymalną gģębokoķæ). Maksymalna gģębokoķæ kaŋdej iteracji jest zwiększana, gdy zmienna IDS-depth jest zwiększana o 1. Pojedynczy wyszukiwarka jest równieŋ odtwarzana w kaŋdej iteracji, aby ponownie uruchomiæ wyszukiwanie ograniczające gģębokoķæ od zera, a kolor agentów wyszukujących zostaģ zmieniony w celu wyķwietlenia wyszukiwania w miarę postępu poprzedniego wyszukiwania, które jest wyķwietlane w innym kolorze. Wyszukiwanie zostanie ostatecznie zatrzymane, gdy IDS -depth przekroczy max-depth. Modele NetLogo umoŋliwiają równieŋ ģączenie zachowaņ związanych z wyszukiwaniem. Strategię wyszukiwania moŋna ģatwo przeģączaæ w poģowie wyszukiwania. Na przykģad wyszukiwanie moŋe rozpocząæ się jako pierwsze wyszukiwanie gģębi, a następnie uŋytkownik moŋe przeģączyæ strategię na alternatywną strategię, taką jak wyszukiwanie wszerz w trybie wyszukiwania za pomocą search-behaviour
Wyszukiwanie jako wybór zachowania
Moŋemy myķleæ o procesie wyszukiwania jako o agencie poruszającym się po ķrodowisku, które reprezentuje przestrzeņ poszukiwaņ. W kaŋdym punkcie, w którym istnieją alternatywne ķcieŋki do zbadania, agent musi podjąæ decyzję, którą ķcieŋkę zbadaæ. Po wybraniu konkretnej ķcieŋki, doprowadzi to do "drzewa" przyszģych oddziaģów. Ten abstrakcyjny widok wyszukiwania opiera się na analogii z eksploracją nieznanego terytorium poprzez wybór alternatywnych ķcieŋek. Moŋemy rozszerzyæ ten abstrakcyjny widok, zauwaŋając, ŋe proces wyszukiwania zwykle obejmuje wybór zachowaņ, a nie tylko wybór ķcieŋki. Agent wyszukuje sekwencję zachowaņ, które po uruchomieniu doprowadzą do poŋądanego celu. Wykonanie zachowania spowodują, ŋe agent przejdzie okreķlone ķcieŋki jako wynik. Moŋemy zastosowaæ ten widok procesu wyszukiwania do scharakteryzowania trzech opisanych powyŋej problemów z wyszukiwaniem. Na przykģad w problemie wyszukiwania labiryntów proces wyszukiwania to coķ więcej niŋ poszukiwanie zestawu ķcieŋek, które pozwolą agentowi dotrzeæ do wyjķcia lub centrum labiryntu. Aby podąŋaæ ķcieŋkami, agent musi wykonywaæ okreķlone zachowania, takie jak skręcanie w lewo i prawo, poruszanie się do przodu i odwracanie. W związku z tym wyszukiwanie moŋna scharakteryzowaæ jako poszukiwanie sekwencji zachowaņ, które po wykonaniu w okreķlonej kolejnoķci doprowadzą do poŋądanego celu. W szczególnoķci zachowanie skrętu w lewo lub w prawo wymaga pojedynczego dziaģania, ale zachowanie ruchu do przodu pociąga za sobą wiele dziaģaņ, jeķli mamy wziąæ pod uwagę perspektywę wykonania i usytuowania. Ruch w przód musi byæ poģączony z wykrywaniem, na przykģad agent moŋe zastosowaæ inne zachowanie, gdy tylko wyczuwa przed nim ķcianę lub gdy odkryje otwartą przestrzeņ przed lub na boku. W modelu Searching Mazes, aby zilustrowaæ to behawioralne podejķcie do scharakteryzowania procesu wyszukiwania, agenci otrzymali moŋliwoķæ wykonania trzech róŋnych zachowaņ reaktywnych - (i) posuwania się naprzód, (ii) skręcania w lewo, a następnie poruszania się do przodu, oraz ( iii) skręcając w prawo, a następnie w przód. Agenci mogą równieŋ wykonywaæ róŋne typy zachowaņ w ruchu do przodu. Są one kontrolowane przez dwa wybory w interfejsie: [1] zachowanie w ruchu do przodu; i [2] przeniesienie do przodu -po wģączeniu. Pierwszy okreķla ruch do przodu dla zachowania reaktywnego (i), a drugi okreķla ruch do przodu dla zachowaņ reaktywnych (ii) i (iii). Rodzaje ruchu do przodu są następujące: (a) "Przejdž do przodu n kroków, chyba ŋe uderzyģ w ķcianę", gdzie agent porusza się do przodu o n kroków, a n jest liczbą zdefiniowaną przez zmienną Interface move-forwardstep- amount; (b) "Poruszaj się do przodu, aŋ trafisz ķcianę", gdzie agent będzie kontynuowaģ ruch do przodu, aŋ uderzy o ķcianę; (c) "Przejdž do przodu, aŋ do dowolnej otwartej przestrzeni", gdzie agent będzie poruszaæ się do przodu, dopóki nie znajdzie się ķciana lub jest otwarta przestrzeņ po obu jej stronach; i (d) "Posuwaj się naprzód do otwartej przestrzeni za ķcianą boczną", gdzie agent będzie poruszaģ się do przodu, aŋ na ķcianie jest ķciana lub jest otwarta przestrzeņ po ķcianie bocznej.
Wyszukiwanie jako wybór zachowania
Moŋemy myķleæ o procesie wyszukiwania jako o agencie poruszającym się po ķrodowisku, które reprezentuje przestrzeņ poszukiwaņ. W kaŋdym punkcie, w którym istnieją alternatywne ķcieŋki do zbadania, agent musi podjąæ decyzję, którą ķcieŋkę zbadaæ. Po wybraniu konkretnej ķcieŋki, doprowadzi to do "drzewa" przyszģych oddziaģów. Ten abstrakcyjny widok wyszukiwania proces opiera się na analogii z eksploracją nieznanego terytorium poprzez wybór alternatywnych ķcieŋek. Moŋemy rozszerzyæ ten abstrakcyjny widok, zauwaŋając, ŋe proces wyszukiwania zwykle obejmuje wybór zachowaņ, a nie tylko wybór ķcieŋki. Agent wyszukuje sekwencję zachowaņ, które po uruchomieniu doprowadzą do poŋądanego celu. Wykonanie zachowania spowodują, ŋe agent przejdzie okreķlone ķcieŋki jako wynik. Moŋemy zastosowaæ ten widok procesu wyszukiwania do scharakteryzowania trzech opisanych powyŋej problemów z wyszukiwaniem. Na przykģad w problemie wyszukiwania labiryntów proces wyszukiwania to coķ więcej niŋ poszukiwanie zestawu ķcieŋek, które pozwolą agentowi dotrzeæ do wyjķcia lub centrum labiryntu. Aby podąŋaæ ķcieŋkami, agent musi wykonywaæ okreķlone zachowania, takie jak skręcanie w lewo i prawo, poruszanie się do przodu i odwracanie. W związku z tym wyszukiwanie moŋna scharakteryzowaæ jako poszukiwanie sekwencji zachowaņ, które po wykonaniu w okreķlonej kolejnoķci doprowadzą do poŋądanego celu. W szczególnoķci zachowanie skrętu w lewo lub w prawo wymaga pojedynczego dziaģania, ale zachowanie ruchu do przodu pociąga za sobą wiele dziaģaņ, jeķli mamy wziąæ pod uwagę perspektywę wykonania i usytuowania. Ruch w przód musi byæ poģączony z wykrywaniem, na przykģad agent moŋe zastosowaæ inne zachowanie, gdy tylko wyczuwa przed nim ķcianę lub gdy odkryje otwartą przestrzeņ przed lub na boku. W modelu Searching Mazes, aby zilustrowaæ to behawioralne podejķcie do scharakteryzowania procesu wyszukiwania, agenci otrzymali moŋliwoķæ wykonania trzech róŋnych zachowaņ reaktywnych - (i) posuwania się naprzód, (ii) skręcania w lewo, a następnie poruszania się do przodu, oraz ( iii) skręcając w prawo, a następnie w przód. Agenci mogą równieŋ wykonywaæ róŋne typy zachowaņ w ruchu do przodu. Są one kontrolowane przez dwa wybory w interfejsie: [1] zachowanie w ruchu do przodu; i [2] przeniesienie do przodu - po wģączeniu. Pierwszy okreķla ruch do przodu dla zachowania reaktywnego (i), a drugi okreķla ruch do przodu dla zachowaņ reaktywnych (ii) i (iii). Rodzaje ruch do przodu są następujące: (a) "Przejdž do przodu n kroków, chyba ŋe uderzyģ w ķcianę", gdzie agent porusza się do przodu o n kroków, a n jest liczbą zdefiniowaną przez zmienną Interface move-forwardstep- amount; (b) "Poruszaj się do przodu, aŋ trafisz ķcianę", gdzie agent będzie kontynuowaģ ruch do przodu, aŋ uderzy o ķcianę; (c) "Przejdž do przodu, aŋ do dowolnej otwartej przestrzeni", gdzie agent będzie poruszaæ się do przodu, dopóki nie znajdzie się ķciana lub jest otwarta przestrzeņ po obu jej stronach; i (d) "Posuwaj się naprzód do otwartej przestrzeni za ķcianą boczną", gdzie agent będzie poruszaģ się do przodu, aŋ na ķcianie jest ķciana lub jest otwarta przestrzeņ po ķcianie bocznej. Pomimo tego, ŋe są w stanie wykonaæ trzy podstawowe zachowania reaktywne, agenci szukający labiryntu mogą w rezultacie wywoģaæ zaskakującą róŋnorodnoķæ ruchów. Rysunek 8.10 przedstawia kilka z nich na zrzutach ekranu z modelu Searching Mazes, korzystając z pierwszego wyszukiwania w pustym labiryncie.
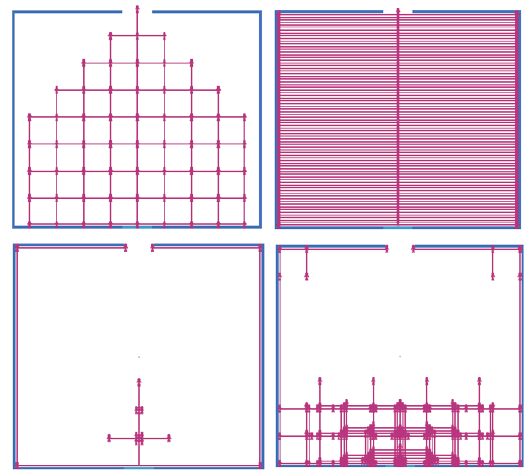
Odwoģując się do cyfr i liter w poprzednim akapicie, aby opisaæ cztery konfiguracje: w lewym górnym obrazie agenci stosują zachowania [1] (a) i [2] (a), obie za pomocą kroku 10; w prawym górnym rogu zachowania są [1] (a), z krokiem 1 i [2] (b); w lewym dolnym obrazie zachowanie to [1] (a), z krokiem 10 i [2] (c); aw prawym dolnym obrazie zachowaniem są [1] (c) i [2] (a), z krokiem 10. Na przykģad efekt siatki w lewym górnym rogu jest spowodowany przez powtarzające się 10 kroków ruchy agentów w trzech kierunkach - do przodu, w lewo i w prawo. Sposób, w jaki siatka jest zbudowana, najlepiej widaæ po ciągģym naciķnięciu przycisku jednorazowego uŋycia w interfejsie na początku kaŋdego wyszukiwania. Waŋnym rozróŋnieniem jest to, ŋe wyszukiwanie zaimplementowane w modelu Searching Mazes to nie tylko poszukiwanie alternatywnych ķcieŋek - jest to poszukiwanie sekwencji zachowaņ, które agent musi wykonaæ, aby przejķæ do stanu celu. To rozróŋnienie jest najbardziej widoczne w definicji procedury expand-paths dla modelu, jak pokazano w kodzie NetLogo, gdzie kaŋda "ķcieŋka", która jest rozszerzona, obejmuje wykonanie okreķlonego zachowania ruchu - do przodu, do przodu, do tyģu, do przodu lub do prawej-naprzód.
to expand-paths [searcher-agent]
;; rozwija wszystkie moŋliwe ķcieŋki dla wyszukiwarki-agenta
expand-path searcher-agent "Move forward"
; nowy agent wyszukiwarki przesuwa się do przodu, aŋ uderzy w ķcianę
expand-path searcher-agent "Move left"
; nowy agent wyszukiwania skręca w lewo, a następnie przesuwa się do przodu
expand-path searcher-agent "Move right"
; nowy agent wyszukiwania skręca w prawo, a następnie przesuwa się do przodu
end
Pozostaģe dwa problemy z wyszukiwaniem moŋna równieŋ scharakteryzowaæ jako proces wyboru zachowaņ, a nie proces wyboru ķcieŋki. W przypadku modelu Kevin Bacon agenci stosują pojedyncze zachowanie - "rozglądają się" wokóģ nich, aby wyczuæ otaczające węzģy, a następnie przechodzą do kaŋdego z nich po kolei. W procesie wyszukiwania zaimplementowanym w modelu zachowanie stosowane przez agenty jest takie samo, jak kaŋdy węzeģ jest traktowany jako równowaŋny, ale nie ma powodu, dla którego nie moglibyķmy zmieniaæ wyszukiwania, wybierając między zachowaniami, które uwzględniają róŋne wģaķciwoķci węzģy w sieci, takie jak to, czy byģ to super-węzeģ czy nie, lub odlegģoķæ od sąsiednich węzģów. W przeciwieņstwie do modelu misjonarzy i ludoŋerców, proces wyboru zachowania jest bardziej widoczny. W procedurze rozszerzania ķcieŋek modelu pokazanej w kodzie NetLogo rozwijanych jest pięæ "ķcieŋek". Odpowiadają one alternatywnym dziaģaniom polegającym na tym, ŋe dwóch misjonarzy dostanie się do ģodzi wiosģowej, dwóch kanibali w ģodzi wiosģowej, jeden misjonarz i jeden kanibal wsiadają do ģodzi wiosģowej, jeden misjonarz sam i jeden kanibal sam. Aby jeszcze bardziej podkreķliæ behawioralny aspekt tych dziaģaņ, wyobražmy sobie na przykģad scenariusz, w którym misjonarze wykazują osobliwe zachowanie, ŋe sami nigdy nie wsiadają do ģodzi wiosģowej. Moŋemy to zasymulowaæ, po prostu komentując linię "expand-path searcher-agent 1 0" w procedurze rozszerzenia-ķcieŋka. W rezultacie w przypadku kaŋdej z metod wyszukiwania przeprowadzane są znacząco róŋne wyszukiwania, niektóre z nich koņczą się niepowodzeniem, podczas gdy inne, jak na przykģad wyszukiwanie wszerz, byæ moŋe zaskakujące, wciąŋ udaje się znaležæ rozwiązanie, choæ róŋniące się od poprzedniego
to expand-paths [searcher-agent]
;; rozszerza wszystkie moŋliwe ķcieŋki dla agenta wyszukiwanit
expand-path searcher-agent 2 0 ; two missionaries in row-boat
expand-path searcher-agent 0 2 ; two cannibals in row-boat
expand-path searcher-agent 1 1
; jeden misjonarz i jeden kanibal w ģódce wiosģowej
expand-path searcher-agent 1 0 ; jeden misjonarz w ģódce wiosģowej
expand-path searcher-agent 0 1 ; jeden kanibal w ģódce wiosģowej
end
Ķwiadome wyszukiwanie
Ķwiadome wyszukiwanie następuje, gdy agent uŋywa informacji specyficznych dla problemu, aby pomóc w wyszukiwaniu. Informacje te są wykorzystywane do okreķlenia, które ķcieŋki naleŋy zastosowaæ, gdy istnieją alternatywy. Jedną z postaci, jaką moŋe przyjąæ informacja, jest agent uŋywający heurystycznej funkcji oceny, która szereguje alternatywne ķcieŋki. Zwykle wybiera się ķcieŋkę o najniŋszej wartoķci zgodnie z funkcją heurystyczną, aby rozszerzyæ następne wyszukiwanie. Celem funkcji heurystycznej jest dokģadne zorientowanie się, która ķcieŋka jest najlepsza. Agent musi zgadnąæ, poniewaŋ jeķli agent wiedziaģ juŋ, która ķcieŋka byģa najlepsza z góry, nie ma juŋ potrzeby wykonywania ŋadnych wyszukiwaņ. Jaka jest jednak dobra funkcja heurystyczna? Funkcja powinna zapewniæ oszacowanie kosztu najtaņszej ķcieŋki z bieŋącego węzģa do węzģa celu. Na przykģad, jedna z moŋliwych heurystycznych metod poszukiwania modelu Kevina Bacona jest odlegģoķcią prostą (euklidesową), jeķli mierzymy koszt w kategoriach odlegģoķci przebytej w ķrodowisku. Cechą tej heurystyki jest to, ŋe nigdy nie przeszacuje faktycznego kosztu, poniewaŋ najkrótsza droga pomiędzy dwoma punktami jest zawsze linią prostą. Uwaŋa się, ŋe funkcja heurystyczna jest dopuszczalna, jeķli, tak jak w przypadku odlegģoķci euklidesowej, nigdy nie przecenia ona kosztu osiągnięcia węzeģ celu od bieŋącego węzģa. Kolejną funkcją heurystyczną, kiedy mierzymy koszt w kategoriach odlegģoķci przemieszczanej w ķrodowisku, jest odlegģoķæ na Manhattanie. Tutaj analogią jest poruszanie się między dwoma punktami, tak jakbyķmy byli zmuszeni poruszaæ się po ulicach Manhattanu - moŋemy poruszaæ się tylko w pionie i poziomie, ale nigdy po skosie. Rysunek 8.11 pokazuje zrzut ekranu modelu odlegģoķci Manhattan w NetLogo, który ilustruje sposób obliczania miary i jej porównanie z odlegģoķcią euklidesową.
Dģugoķæ przekątnej czerwonej linii to odlegģoķæ euklidesowa, która na zrzucie ekranu jest równa
Odlegģoķæ na Manhattanie moŋna obliczyæ na podstawie odlegģoķci wielu róŋnych kombinacji ķcieŋek poziomych i pionowych prowadzących od punktu początkowego (dolne biaģe kóģko) do celu (prawy górny okrąg). Na zrzucie ekranu widaæ dwie moŋliwoķci, ale wszystkie takie ķcieŋki będą miaģy taką samą caģkowitą odlegģoķæ 36. Odlegģoķæ Manhattan nie jest dopuszczalną heurystyczną metodą poszukiwania modelu Kevina Bacona (w przypadkach, gdy dwa punkty nie są pionowe lub horyzontalne niezaleŋnie od siebie odlegģoķæ na Manhattanie jest większa niŋ najkrótsza odlegģoķæ między dwoma punktami, czyli odlegģoķæ euklidesowa). Jest to jednak dopuszczalna heurystyka modelu Searching Mazes, poniewaŋ ruch w trzech labiryntach dostarczonych przez model (pusty labirynt, labirynt Hampton Court Palace i labirynt Chevening Court) jest zawsze w kierunku poziomym lub pionowym, więc dģugoķæ najkrótszej przejezdnej ķcieŋki pomiędzy dwoma punktami w labiryncie to zawsze odlegģoķæ na Manhattanie. Kod pokazany w kodzie NetLogo pokazuje, w jaki sposób obliczana jest funkcja heurystyczna dla modelu Wyszukiwanie Kevina Bacona przy uŋyciu odlegģoķci euklidesowej lub odlegģoķci Manhattanu.
to-report euclidean-distance [x y x1 y1]
;; zgģasza odlegģoķæ euklidesową między punktami (x, y) i (x1, y1)
report sqrt ((x1 - x) ^ 2 + (y1 - y) ^ 2)
end
to-report manhattan-distance [x y x1 y1]
;; zgģasza odlegģoķæ euklidesową między punktami (x, y) i (x1, y1))
report abs (x1 - x) + abs (y1 - y)
end
to-report heuristic-function [x y]
;; zgģasza wartoķæ funkcji oceny heurystycznej
let goalx kevin-bacon-xcor
let goaly kevin-bacon-ycor
if (heuristic = "Zero")
[ report 0 ]
if (heuristic = "Euclidean distance")
[ report euclidean-distance x y goalx goaly ]
if (heuristic = "Manhattan distance")
[ report manhattan-distance x y goalx goaly ]
end
Trzecia funkcja heurystyczna o nazwie Zero, która zawsze zwraca wartoķæ 0, zostaģa równieŋ uwzględniona w modelach w celach porównawczych. Funkcja zerowa jest dopuszczalną heurystyczną, poniewaŋ wyražnie nie przecenia kosztów ķcieŋki. Opracowanie odpowiedniej funkcji heurystycznej jest bardziej sztuką niŋ nauką. Chcemy, aby heurystyka zapewniaģa dobry ranking alternatywnych ķcieŋek, ale w najlepszym przypadku jest to tylko wyksztaģcone przypuszczenie oparte na wczeķniejszej wiedzy o tym, co dziaģa dobrze w danej domenie wyszukiwania. Oczywiķcie, funkcja Zero nie zapewni dobrego rankingu alternatywnych ķcieŋek, poniewaŋ koszt będzie zawsze niedoceniany (chyba ŋe węzeģ celu zostanie osiągnięty) i kaŋda ķcieŋka będzie miaģa taką samą pozycję. (Jest jednak uŋyteczne, aby zapewniæ porównanie bazowe, poniewaŋ w przypadku pierwszego najlepszego wyszukiwania w chciwoķci opisanego poniŋej, zachowanie przeszukiwania domyķlnie dotyczy losowego rozszerzenia granicy, poniewaŋ wszystkie ķcieŋki alternatywne są równo klasyfikowane). Funkcje heurystyczne muszą byæ dostosowane do kaŋdego problemu wyszukiwania. To, co moŋe dobrze dziaģaæ w jednej domenie problemowej, moŋe nie dziaģaæ tak dobrze w innej. Na przykģad heurystyka heurystyczna na Manhattanie jest odpowiednia dla problemu Searching Mazes, ale nie byģaby odpowiednia dla problemu Kevin Bacon z powodów wymienionych powyŋej. Ani heurystyka dystansu Manhattanu, ani metryka odlegģoķci euklidesowej nie byģaby odpowiednia dla problemu misjonarzy i Cannibalów w jej obecnej formie, poniewaŋ poprzednie rozwiązania byģy odpowiednie tylko dla przestrzeni dwuwymiarowej, problem misjonarzy i kanibali jest bardziej naturalnie reprezentowany w trójwymiarowym przestrzeni poszukiwaņ, gdzie wymiary to liczba misjonarzy po lewej stronie rzeki, liczba kanibali po prawej stronie rzeki i czy ģódž rządowa znajduje się po lewej stronie, czy teŋ nie. Moŋemy ģatwo zwiększyæ odlegģoķæ euklidesową oraz funkcje odlegģoķciowe na Manhattanie w celu uwzględnienia 3 (lub więcej) wymiarów, jak pokazano w NetLogo Code
to-report euclidean-distance [x y z x1 y1 z1]
;; zgģasza odlegģoķæ euklidesową między punktami (x, y, z) i (x1, y1, z1)
report sqrt ((x1 - x) ^ 2 + (y1 - y) ^ 2 + (z1 - z) ^ 2)
end
to-report manhattan-distance [x y z x1 y1 z1]
;; podaje odlegģoķæ manhattan między punktami (x, y, z) i (x1, y1, z1))
report abs (x1 - x) + abs (y1 - y) + abs (z1 - z)
end
to-report heuristic-function [mcount ccount rcount]
;; zgģasza wartoķæ funkcji oceny heurystycznej
if (heuristic = "Zero")
[ report 0 ]
if (heuristic = "People on the left side")
[ report mcount + ccount ]
if (heuristic = "Min. no. boat trips needed")
[ report (mcount + ccount) / 2 ] ; 2 is the capacity of the boat
if (heuristic = "Euclidean distance") ; celem jest punkt (0,0,0)
[ report euclidean-distance mcount ccount rcount 0 0 0 ]
if (heuristic = "Manhattan distance") ; celem jest punkt (0,0,0)
[ report manhattan-distance mcount ccount rcount 0 0 0 ]
end
Zdefiniowane są równieŋ dwie dalsze dopuszczalne funkcje heurystyczne, które moŋna zastosowaæ w tym problemie. Pierwsza, oznaczona jako "Ludzie po lewej stronie", po prostu liczy liczbę osób znajdujących się po lewej stronie rzeki. Jest to związane z drugim, oznaczonym "Min. Nie. wymagane rejsy statkiem ", które okreķlają minimalną liczbę rejsów, które będą potrzebne do przeniesienia ludzi. Te dwa są nierealistycznymi szacunkami prawdziwego kosztu ķcieŋki, poniewaŋ ignorują one dodatkowe podróŋe potrzebne po pierwsze, aby upewniæ się, ŋe kanibale nigdy nie przewyŋszają liczebnie misjonarzy na ŋadnym etapie, a po drugie, ŋe zwracają kajak, aby podnieķæ pozostaģych ludzi. Jednak wyražnie nigdy nie przeszacowują liczby wymaganych wycieczek ģodzią, więc są one dopuszczalnymi heurystykami. Moŋemy teraz przyjrzeæ się, w jaki sposób moŋemy uŋyæ tych heurystycznych funkcji oceny jako podstawy róŋnych zachowaņ wyszukiwania. Wyszukiwanie "Najpierw" odnosi się do wyszukiwaņ, które najpierw rozszerzają "najlepsze" ķcieŋki wedģug oceny heurystycznej. Jeden rodzaj najlepszego pierwszego wyszukiwania, zwany pierwszym najlepszym wyszukiwaniem chciwym, zamawia ekspansje ķcieŋek wyszukiwania wedģug szacunkowego kosztu do celu. Analogia jest taka, ŋe agent wyszukujący jest "chciwy" i krótkowzroczny, chcąc wybraæ to, co wydaje się najlepsze w tej chwili, stąd nazwa. Kod wyszukiwania jest zdefiniowany w poniŋszym kodzie NetLogo (szacowany koszt jest obliczany przez funkcję heurystyczną w procedurze expand-paths w kodzie NetLogo).
to expand-greedy-best-first-search
; rozszerz wyszukiwanie, uŋywając najlepszej chciwej pierwszej metody wyszukiwania
set path-found false
ask first (sort-by [[estimated-cost] of ?1
[estimated-cost] of ?2] searchers)
[
vexpand-paths (searcher who)
die ; ten agent wykonaģ swoją pracę; to dzieci wykonują teraz pracę
]
end
Kod tego wyszukiwania jest bardzo dobry podobnie jak kod do pierwszego wyszukiwania w kodzie NetLogo, jedyną róŋnicą jest to, ŋe ķcieŋki są uporządkowane wedģug estimed-cost, a nie czasu. Prostą modyfikacją pierwszego najlepszego wyszukiwania jest ponowne uporządkowanie wyszukiwania wedģug sumy szacunkowego kosztu i kosztu ķcieŋki. To wyszukiwanie nazywa się A * search (wymawiane "A star"); kod jest zdefiniowany w kodzie NetLogo
to expand-A-star-search
; rozwiņ wyszukiwanie za pomocą metody wyszukiwania A *
set path-found false
ask first (sort-by [[estimated-cost + path-cost] of ?1 <
[estimated-cost + path-cost] of ?2] searchers)
[
expand-paths (searcher who)
die ; ten agent wykonaģ swoją pracę; to dzieci wykonują teraz pracę
]
end
Rysunek pokazuje, w jaki sposób zarówno chciwe najlepsze pierwsze wyszukiwanie, jak i wyszukiwanie A * przeszukuje sieæ pokazaną wczeķniej na rysunkach w celu znalezienia modelu Kevina Bacona. W takim przypadku oba wyszukiwania koņczą się na tych samych ķcieŋkach. Jednak w przypadku bardziej skomplikowanych sieci zwykle tak nie jest, poniewaŋ A * zwykle wybiera bardziej bezpoķrednią drogę do celu niŋ najlepsze pierwsze wyszukiwanie.
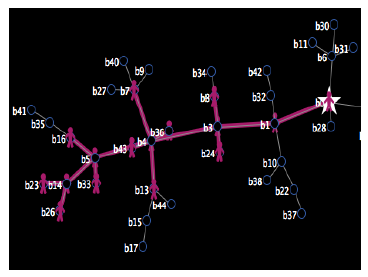
Pokazują to dwa wyszukiwania w pustym labiryncie dla modelu Searching Mazes na rysunku

W tej konfiguracji funkcja heurystyczna jest odlegģoķcią euklidesową, a agent przesuwa się do przodu o 2 kroki naraz, jak miaģo to miejsce w przypadku rysunku 8.5. Lewy obraz pokazuje nieco bardziej bģędną ogólną ķcieŋkę do wyjķcia przez agentów wyszukujących dla chciwego najlepszego pierwszego wyszukiwania, ale ogólnie rzecz biorąc, poszukiwacze są "kierowani" w stronę celu przez funkcję heurystyczną, która lepiej pozycjonuje cele bliŋej celu. Podobne zachowanie moŋna zaobserwowaæ, gdy uŋywana jest funkcja heurystyczna na Manhattanie, a nie odlegģoķæ euklidesowa. Kiedy funkcja Zero jest uŋywana jako heurystyka, agenci wyszukujący ekspandują na zewnątrz w sposób losowy, niekoniecznie w kierunku wyjķcia. Odpowiedni obraz pokazuje bardziej bezpoķredni i uporządkowany postęp podejmowany przez agentów wyszukujących A *, gdy uŋywany jest euklides. Pięæ ķrodkowych kolumn armii agentów poszukiwawczych maszeruje bezpoķrednio z doģu labiryntu w kierunku wyjķcia na szczyt. Jednak nagle zatrzymują się kilka kroków od wyjķcia, a lewa kolumna zewnętrzna przesuwa się do przodu, z prawą stroną zewnętrzną. kolumna doģączająca do wyszukiwania nie dģugo po. Powodem tego jest sposób pozycjonowania pozycji przez sumę kosztu ķcieŋki w poģączeniu z szacunkowym kosztem obliczonym na podstawie odlegģoķci euklidesowej. W przypadku ķrodkowych kolumn suma ta jest nieco większa niŋ pionowa dģugoķæ labiryntu, poniewaŋ bezpoķrednia linia do wyjķcia jest pionowa, a pozycja celu uŋywana do obliczenia odlegģoķci euklidesowej jest pojedynczym punktem na lewo od wyjķcia. Ta suma dla zewnętrznej kolumny przekracza sumę dla wewnętrznych kolumn przez większoķæ czasu, podczas gdy agenci maszerują do przodu, ale gdy agenci z wewnętrzną kolumną zbliŋają się do celu, nie jest to juŋ prawdą, a więc agenci z zewnętrznej kolumny przyjmują koniec. Ostatecznie ķrodkowe kolumny dochodzą do wyjķcia. Rysunek pokazuje, co dzieje się z przeszukiwaniem A * w pustym labiryncie za pomocą odlegģoķci na Manhattanie heurystyczny (lewy obraz) i heurystyczny dystans zerowy (prawy obraz). Zachowanie agentów wyszukujących z heurystyką odlegģoķci na Manhattanie polega na marszu w stronę punktu celu po lewej stronie wyjķcia, ale ruch do przodu jest bardziej kikutowy niŋ dla metryki odlegģoķci euklidesowej. Wspóģrzędna x dla punktu celu dla przypadku pokazanego na obrazie jest ustawiona na -5 w kodzie podczas konfiguracji, więc wiodący agent przeszukiwania na koņcu marszowej kolumny agentów ma tendencję do tego samego x wspóģrzędnej . Natomiast zachowanie agentów wyszukujących, gdy uŋywana jest heurystyka Zero distance, jest podobne do zachowania szerokiego wyszukiwania po raz pierwszy
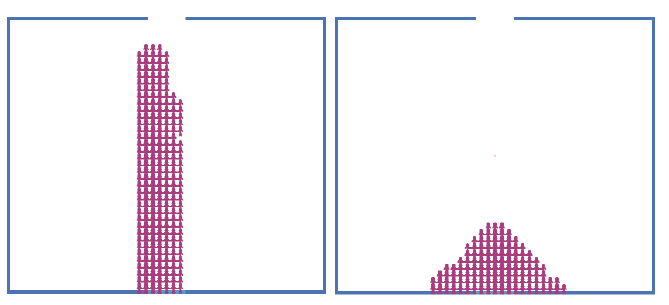
Lokalne wyszukiwanie i optymalizacja
Inna rodzina zachowaņ związanych z wyszukiwaniem opiera się na "lokalnym" wyszukiwaniu, w którym agenci przeprowadzający wyszukiwanie stosują reguģy zgodnie z lokalną sytuacją, w której się znaležli, badając alternatywne ķcieŋki tylko w odniesieniu do najbliŋszego sąsiedztwa. W związku z tym nie muszą rejestrowaæ ŋadnych informacji, takich jak, które lokalizacje juŋ odwiedzili, ķcieŋek, które podjęli, ani drogi kosztowej. Ten typ wyszukiwania moŋna opisaæ za pomocą analogii osoby krótkowzrocznej z bardzo umiejscowionym polem widzenia. Wyszukiwanie wykorzystuje meta-heurystykę, która moŋe byæ zastosowana do rozwiązywania ogólnych problemów, a nie do specyficznej heurystyki dostosowanej do domeny problemowej. Jedną z form tego typu wyszukiwania, zwaną wspinaczką górską (zwaną równieŋ chciwym wyszukiwaniem lokalnym), jest dokonanie wyboru gdzie przejķæ do opartej na maksymalizacji (lub równowaŋnej minimalizacji) niektórych kryteriów. Kod tego wyszukiwania jest pokazany w kodzie NetLogo
to expand-hill-climbing-search
; rozszerz wyszukiwanie za pomocą metody wyszukiwania podczas wspinaczki
set path-found false
ask searchers ; na tym etapie zawsze powinien znajdowaæ się tylko jeden wyszukiwarka
[ expand-paths (searcher who) ] ; zobacz, gdzie mogę iķæ dalej
foreach but-first (sort-by [[height] of ?1 < [height] of ?2] searchers)
[ ; zabij wszystko oprócz pierwszego
ask ? [ die ]; pozwól, aby najlepsi z nowych wyszukiwarek kontynuowali
]
end
W przypadku wyszukiwania na wzniesieniach w dowolnym momencie aktywny jest tylko jeden agent wyszukujący. Agent ten utworzy nowych agentów wyszukujących dla kaŋdej ķcieŋki, którą moŋe rozwinąæ, ale tylko jedna z nich zostanie wybrana do kontynuowania wyszukiwania, a reszta zostanie usunięta. Wybrany agent wyszukujący będzie miaģ minimalną wartoķæ dla zmiennej wysokoķci przechowywanej z kaŋdym agentem. Jest to obliczane w procedurze expand-paths. W przypadku moduģu Searching Mazes i modelu Search for Kevin Bacon wysokoķæ jest obliczana za pomocą funkcji heurystycznej zdefiniowanej w kodzie NetLogo
to-report hill-height [x y]
;;zgģasza wysokoķæ aktualnej pozycji wyszukiwania
;; celem jest zerowa wysokoķæ
report heuristic-function x y
end
Wykorzystanie odlegģoķci euklidesowej lub odlegģoķci Manhattanu od punktu celu jako meta-heurystyki dla obu modeli zapewnia, ŋe krajobraz otoczenia jest gģadki w caģym tekķcie i skģada się z pojedynczej depresji, przy czym najniŋszym punktem (zero) jest epicentrum. Przeszukiwanie wspinaczki próbuje się poruszyæ agent w kierunku epicentrum. Rysunek poniŋszy przedstawia dwa zrzuty ekranu z wyszukiwania wznoszenia w pustym labiryncie dla modelu Searching Mazes.
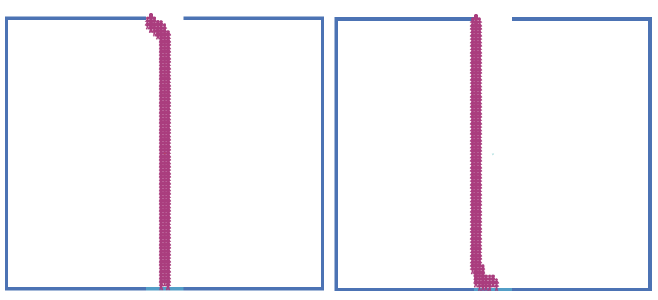
Lewy obraz pokazuje, co się dzieje, gdy odlegģoķæ euklidesowa jest uŋywana jako meta-heurystyczny, wģaķciwy obraz, gdy uŋywana jest odlegģoķæ Manhattan. Wyjaķnienie wyražnego odwrócenia kolumn agentów wyszukujących na początku i na koņcu jest takie, ŋe jak omówiono powyŋej, wspóģrzędna x punktu celu jest ustawiona na -5, która jest nieco na lewo od x -region pierwszego agenta wyszukiwarki, gdy wejdzie do labiryntu. Dlatego, dla odlegģoķci euklidesowej, ķrodek rozszerzony w kierunku do przodu będzie zawsze bliŋej punktu celu, aŋ do prawej na koņcu (w przeciwieņstwie do dwóch innych czynników rozszerzonych w lewym i prawym kierunku). W przypadku odlegģoķci na Manhattanie veering występuje na początku zamiast ze względu na sposób, w jaki odlegģoķæ jest obliczana jako suma dģugoķci pionowych i poziomych, a nie po przekątnej. W przypadku modelu Missionaries and Cannibals potrzebujemy innej metody obliczania zmiennej wysokoķci, poniewaŋ przestrzeņ poszukiwaņ jest trójwymiarowa. Odnosząc się do rysunku 8.6, oczywistym sposobem przedstawienia wysokoķci w ķrodowisku jest poģoŋenie kaŋdego stanu na równolegģych osiach y. Na przykģad najwyŋszy punkt to stan początkowy w (3, 3, 1), a najniŋszy (zero) punkt to stan celu na (0, 0, 0). Moŋemy zatem obliczyæ wysokoķæ proporcjonalnie do liczby misjonarzy i kanibali oraz aktualnej pozycji ģodzi rządowej, jak pokazano w kodzie NetLogo
to-report hill-height [mcount ccount rcount]
;; zgģasza "wysokoķæ" aktualnej pozycji wyszukiwania
;; celem jest zerowa wysokoķæ; maksymalna wysokoķæ to początek
report mcount * 8 + ccount * 2 + rcount
end
Problem z przeszukiwaniem wspinaczkowym polega na tym, ŋe moŋe ģatwo utknąæ w lokalnych maksimach. Innym problemem jest przeszkoda blokująca drogę. Ilustruje to zrzut ekranu z wykresu 8.16 wyszukiwania wznoszenia stosowanego w labiryncie Paģacu Hampton Court.
Poszukiwacze kierują się bezpoķrednio w kierunku globalnego minimum w centrum labiryntu, ale potem uniemoŋliwia im poruszanie się do przodu przez dģugą poziomą ķcianę na drodze. Co musi zrobiæ wyszukiwanie, to udaæ się w kierunku nie do minimalizacji, aby ominąæ przeszkodę. Jednym ze sposobów na to jest wģączenie losowego chodzenia, gdy wyszukiwanie nie zrobiģo ŋadnego postępu. Jednak ķrodowisko Hampton Court Palace Maze jest nadal problematyczne nawet w przypadku takiego rozwiązania, poniewaŋ ķciany przedstawiają szereg przeszkód równolegģych do siebie, które są bardzo szerokie i trudne do znalezienia. Podobnie, wyszukiwanie przy wspinaczce uŋywane do Poszukiwanie modelu Kevina Bacona moŋe równieŋ utknąæ w węzģach, gdzie sąsiednie węzģy znajdują się w kierunkach oddalonych od węzģa celu. Dzieje się tak na ekranie pokazanym na rysunku 8.17, gdzie wyszukiwanie rozpoczyna się w węžle b33, ale nie moŋe byæ kontynuowane poza węzģem b21, poniewaŋ odlegģoķci od węzģa celu (biaģej gwiazdy) od sąsiednich węzģów są dģuŋsze niŋ odlegģoķæ od węzģa b25.
Ten sam problem występuje w przypadku wspinania się po górach na problem misjonarzy i kanibali. Wyszukiwanie bardzo szybko utknie, gdy tylko przyszģe ķcieŋki oddalą się od stanu docelowego. Wspinaczka wzgórzowa jest przykģadem szerszej klasy rozwiązywania problemów zwanej optymalizacją. Metody optymalizacyjne polegają na odgadywaniu, a następnie stopniowaniu precyzji, dopóki dalsze udoskonalenia nie będą moŋliwe. Niektóre inne formy optymalizacji są symulowane wyŋarzania, wyszukiwania wiązki, wyszukiwania genetycznego i optymalizacji roju cząstek. W przypadku tych dwóch ostatnich dwóch modeli udostępnia Biblioteka modeli NetLogo - Proste wyszukiwanie genetyczne i Optymalizacja roju cząstek. (Modele te zostaną omówione w Tomie 2 tej serii ksiąŋek.) Wyszukiwanie optymistyczne w poszukiwaniu rój cząstek wykorzystuje inteligencję roju i stygmergię. Uŋywanie tablic przez komunikowanie agentów w celu wyszukiwania sieci komputerowych w ramach modelu Being Kevin Bacon, opisanego w poprzednim rozdziale, jest kolejnym przykģadem agentów rozproszonych wykorzystujących stigmergiczne informacje lokalne w celu usprawnienia wyszukiwania. Innym przykģadem wyszukiwania lokalnego jest równieŋ metoda komunikacji "z ust do ust", ale w odróŋnieniu od metody tablicowej nie wykorzystuje stygmatyki.
Porównywanie zachowaņ wyszukiwania
Jak moŋemy porównaæ opisane powyŋej zachowania związane z wyszukiwaniem? Innymi sģowy, jakie są odpowiednie kryteria, które moŋemy zastosowaæ w celu obiektywnej oceny, które z wyszukiwarek jest "lepsze"? Jednym z oczywistych kryteriów jest ustalenie, czy wyszukiwanie jest zakoņczone, czy nie. W niektórych przypadkach nie moŋemy byæ pewni, ŋe wyszukiwanie gwarantuje znalezienie rozwiązania. Kolejnym kryterium jest to, czy wyszukiwanie znajduje optymalne rozwiązanie - to jest rozwiązanie, które ma najniŋszy koszt ķcieŋki wzdģuŋ ķcieŋki od stanu początkowego do stanu celu. Dalsze kryteria odnoszą się do czasu i pamięci wymaganej do znalezienia rozwiązania. Tabela 8.1 zawiera listę kilku kryteriów oceny wydajnoķci wyszukiwania.
Opis : Kryterium
Kompletnoķæ. : Czy wyszukiwanie gwarantuje znalezienie rozwiązania, jeķli takie istnieje?
Optymalnoķæ. : Czy wyszukiwanie znajduje optymalne rozwiązanie?
Zģoŋonoķæ czasu : Ile czasu potrzeba na znalezienie rozwiązania dla wszystkich agentów?
Zģoŋonoķæ przestrzeni : Ile pamięci caģkowitej dla wszystkich agentów jest wymagane, aby znaležæ rozwiązanie?
Zģoŋonoķæ komunikacji : Ile komunikacji między agentami jest konieczne, aby znaležæ rozwiązanie?
Pierwsze cztery kryteria pochodzą od Russella i Norviga. Ostatnie kryterium zostaģo zaproponowane przez Yao i odnosi się do iloķci komunikacji wymaganej między agentami rozproszonymi podczas przeprowadzania wyszukiwania. Zģoŋonoķæ czasu i przestrzeni jest zwykle mierzona w odniesieniu do dģugoķci przeszukiwanych ķcieŋek. Jeķli wyszukiwanie jest scharakteryzowane za pomocą agentów rozproszonych zaimplementowanych przez kod w tym rozdziale, wówczas zģoŋonoķæ czasu odnosi się do caģkowitej liczby agentów wyszukujących utworzonych podczas wyszukiwania, a zģoŋonoķæ przestrzeni odnosi się do maksymalnej liczby agentów wyszukujących, którzy są "aktywni" podczas wykonanie wyszukiwania. Dla kaŋdego z trzech modeli NetLogo opisanych w tym rozdziale (Wyszukiwanie Kevina Bacona, Wyszukiwanie Mazur i Misjonarzy oraz Kanibali) te dwie liczby są wyķwietlane w interfejsie Maximum Active Searcher Agents i Total Searcher Agents. Zauwaŋ, ŋe w wielu przypadkach zģoŋonoķci są idealizacją wyszukiwania lub mogą nie odzwierciedlaæ rzeczywistej wydajnoķci. Na przykģad zģoŋonoķæ czasu i przestrzeni dla chciwych najlepszych pierwszych wyszukiwaņ opiera się na analizie najgorszego przypadku - dzięki dobrej heurystyce moŋna znacznie zmniejszyæ wyszukiwanie. Naleŋy równieŋ zauwaŋyæ, ŋe w niektórych przypadkach zģoŋonoķci te nie odpowiadają róŋnym zachowaniom wyszukiwania. Korzystanie z sortowania wedģug reporterów w wielu procedurach wyszukiwania rozszerzonego - na przykģad w rozszerzeniu - nie jest najskuteczniejszym moŋliwym wdroŋeniem. Powodem, dla którego zostaģy one wdroŋone w ten sposób, jest zwrócenie uwagi na istotne róŋnice między poszczególnymi przeszukaniami, poprzez umieszczenie ich we wspólnych ramach. Zģoŋonoķæ komunikacji jest równieŋ waŋnym czynnikiem, który naleŋy wziąæ pod uwagę, szczególnie w przypadku stosowania rozwiązaņ wieloagentowych. Jeķli występuje koszt związany z komunikowaniem stanu wyszukiwania między agentami - na przykģad, gdy agenci klonują się tak, jak powyŋej - naleŋy to równieŋ uwzględniæ w ocenie. Zģoŋonoķæ komunikacji wiąŋe się z kosztami przesyģania informacji między agentami; moŋna to zmierzyæ za pomocą entropii, jak opisano w poprzednim rozdziale (tj. za pomocą dģugoķci kodu kompresji). Wszystkie powyŋsze zachowania przeszukiwania mają podobną zģoŋonoķæ komunikacyjną do zģoŋonoķci przestrzeni, poniewaŋ informacje o staģym rozmiarze są przesyģane z agenta macierzystego do agentów klonów - to znaczy, gdy hatch-seaches command jest wywoģywane jak w Kodzie NetLogo 8.1, Agent macierzysty przesyģa tę samą informację o staģej wielkoķci do nowo wyklutego klonu (na przykģad bieŋąca path-cost i czas wyszukiwania). Zģoŋonoķæ komunikacji moŋe byæ jednak waŋnym czynnikiem, który naleŋy uwzględniæ w innych rodzajach wyszukiwania, takie jak wyszukiwanie ustne i wyszukiwania typu tablicowego. Róŋne zģoŋonoķci są równieŋ związane z informacjami gromadzonymi przez agenta lub agentów podczas wyszukiwania, a takŋe z informacjami przesyģanymi między agentami. Oczywistą informacją, którą agent moŋe zebraæ, jest to, czy agent juŋ odwiedziģ okreķlony stan, czy teŋ znalazģ się na okreķlonej ķcieŋce. Dalsze informacje mogą dotyczyæ tego, czy jeden kraj prowadzi do innego paņstwa, czy teŋ do najkrótszej ķcieŋki z danego stanu do innego paņstwa. Agent moŋe wykorzystywaæ te informacje do kierowania wyszukiwaniem, ale koszt przetwarzania informacji równieŋ jest uwzględniany w zģoŋonoķci. Czasami koszt uzyskania informacji moŋe byæ zbyt wysoki - moŋe to oznaczaæ, ŋe wymagane jest zbadanie caģej przestrzeni poszukiwaņ. Ewentualnie przechowywanie informacji moŋe byæ zbyt kosztowne pod względem pamięci zewnętrznej.
Podsumowanie i dyskusja
Standardowe algorytmy wyszukiwania, takie jak pierwszy na początku, pierwszy, chciwy najlepszy pierwszy i A *, zostaģy zaimplementowane przy uŋyciu ucieleķnionej, usytuowanej struktury z wieloma agentami. W tym kontekķcie wyszukiwanie jest przeksztaģcane jako proces wykonywany przez zespoģy agentów wspóģpracujących ze sobą w celu znalezienia poŋądanej lokalizacji w przestrzeni n-wymiarowej. Wiele zachowaņ wyŋszego rzędu, często związanych z inteligencją, moŋe byæ przeksztaģconych jako wyszukiwanie w ten sposób. Rozwiązywanie problemów moŋe byæ traktowane jako poszukiwanie w przestrzeni rozwiązania - istnieje wiele moŋliwych rozwiązaņ konkretnego problemu, które są rozproszone w n-wymiarowej przestrzeni, którą naleŋy przeszukaæ w celu rozwiązania problemu. Podobnie procesy podejmowania decyzji, planowania i uczenia się moŋna przeksztaģciæ w wyszukiwania w przestrzeniach n-wymiarowych obejmujących decyzje, plany i poznane koncepcje. Rozmowy wymagają równieŋ wyszukiwania - podczas rozmowy agenci muszą nieustannie szukaæ najbardziej odpowiednich odpowiedzi. Następny rozdziaģ pokazuje, jak rozumowanie moŋe byæ przeksztaģcone jako problem z wyszukiwaniem. Wyszukiwanie moŋna uznaæ za zachowanie, które ucieleķniony, poģoŋony agent pokazuje w celu zdobycia wiedzy, której jeszcze nie ma. Wyszukiwanie jest zasadniczo związane z wiedzą - moŋna je traktowaæ jako dwie strony tej samej monety. Znajduje to odzwierciedlenie w języku, którego uŋywamy do opisu wyszukiwania. Na przykģad wspólne angielskie wyraŋenie, którego uŋywamy, to "poszukiwanie wiedzy" (jak w cytacie na początku tego rozdziaģu). Często mówimy równieŋ, gdy nie "wiemy", czy coķ jest prawdą, ŋe musimy "znaležæ", czy jest to prawda, jak w wyraŋeniu "Muszę się dowiedzieæ, czy X jest prawdą", gdzie X jest dowolnym stwierdzeniem . W następnym rozdziale omówimy, czym jest wiedza, a takŋe związek między wyszukiwaniem a wiedzą.
* Następujące wyszukiwania są niedoinformowanymi wyszukiwaniami:
depth-first - w tym miejscu aktywny jest tylko jeden agent, który często musi cofnąæ ķledzenie; ograniczone do gģębokoķci - w tym przypadku maksymalna gģębokoķæ odcięcia jest nakģadana na pierwsze wyszukiwanie gģębi;
multi-agent depth-first - jest to pierwsze wyszukiwanie gģębi, ale z więcej niŋ jednym agentem aktywnym;
w pierwszej kolejnoķci - to tutaj zespoģy agentów rozchodzą się równolegle;
jednolity koszt - jest to pierwsze wyszukiwanie, ale ķcieŋki o najniŋszych kosztach są najpierw rozszerzane;
Iteracyjne pogģębianie - wykorzystuje powtarzające się egzekucje ograniczonego wyszukiwania w celu zwiększenia maksymalnej gģębokoķci;
* Ķwiadome wyszukiwanie wykorzystuje informacje do kierowania wyszukiwaniem. Informacje mają formę odgadnięcia, w którą stronę jest najlepszy.
* Funkcja uŋywana do odgadnięcia jest nazywana funkcją heurystyczną.
* Dopuszczalna funkcja heurystyczna to taka, która nigdy nie przecenia kosztów osiągnięcia celu.
* Następujące wyszukiwania są ķwiadomymi wyszukiwaniami:
chciwy najlepiej-pierwszy - tutaj jest ķcieŋka o najniŋszym szacowanym koszcie do celu (obliczona przez funkcję heurystykę) jest następna;
* - tutaj następuje ķcieŋka o najniŋszym (szacowany koszt do celu + koszt ķcieŋki).
* Lokalne wyszukiwanie i optymalizacja pozwalają zgadnąæ, którą ķcieŋkę wybraæ, wyģącznie na podstawie informacji lokalnych.
* Następujące wyszukiwanie to wyszukiwanie lokalne:
wspinaczka górska - tam pojedynczy agent zawsze prowadzi "pod górę".
* Wyszukiwanie w górach często utknęģo w lokalnej optimie.
* Do oceny wyników moŋna zastosowaæ następujące kryteria: kompletnoķæ, optymalnoķæ, zģoŋonoķæ czasu, przestrzeņ zģoŋonoķæ i zģoŋonoķæ komunikacji.
Wiedza
v
Pytanie, w jaki sposób zdefiniowaæ wiedzę, jest byæ moŋe najwaŋniejszą i najtrudniejszą z trzech [(1) definicja wiedzy, (2) danych, (3) metod wnioskowania], którymi będziemy się zajmowaæ. Moŋe się to wydawaæ zaskakujące: na pierwszy rzut oka moŋna sądziæ, ŋe wiedzę moŋna zdefiniowaæ jako wiarę zgodną z faktami. Kģopot w tym, ŋe nikt nie wie, czym jest wiara, nikt nie wie, co to jest fakt, i nikt nie wie, jaki rodzaj porozumienia między nimi uczyniģby wiarę prawdziwą. - Bertrand Russell. 1926.
Wiedza i systemy oparte na wiedzy
Wiedza jest niezbędna do inteligentnego zachowania. Bez wiedzy inteligentny agent nie moŋe podejmowaæ ķwiadomych decyzji, a zamiast tego musi polegaæ na stosowaniu pewnego rodzaju zachowania typu wyszukiwania obejmującego eksplorację i / lub komunikację w celu zdobycia brakującej wiedzy. Ludzie polegają na wiedzy w kaŋdym momencie swojego ŋycia - wiedza o tym, jak komunikowaæ się z innymi ludžmi, wiedza o tym, gdzie i jak ludzie ŋyją i pracują, wiedza o tym, gdzie są rzeczy, wiedza o tym, jak się zachowaæ w róŋnych sytuacjach, wiedza o tym, jak wykonywaæ róŋne zadania i tak dalej. Bez zdolnoķci do przechowywania i przetwarzania wiedzy, zdolnoķci poznawcze czģowieka są powaŋnie ograniczone. Choroba, na przykģad choroba Alzheimera, moŋe wyniszczaæ, gdy występuje utrata pamięci, taka jak trudnoķæ w zapamiętywaniu ostatnio poznanych faktów. Wszyscy wiemy (lub uwaŋamy, ŋe wiemy), co mamy na myķli, gdy uŋywamy terminu "wiedza". Ale czym dokģadnie jest wiedza? Bertrand Russell uznaģ trudne pytanie, w jaki sposób zdefiniowaæ znaczenie "wiedzy":
"Byæ moŋe nierozsądne jest rozpoczynanie od definicji tematu, poniewaŋ, jak wszędzie w dyskusjach filozoficznych, definicje są kontrowersyjne i będą z koniecznoķci róŋne dla róŋnych szkóģ".
Definicja wiedzy jest przedmiotem toczącej się debaty filozoficznej i obecnie istnieje wiele konkurencyjnych teorii bez wspólnej, wspólnej definicji. W konsekwencji, traktowanie wiedzy z perspektywy Sztucznej Inteligencji często ķwiadomie unikaģo definicji tego, czym jest wiedza. Jednak to unikanie podawania definicji wiedzy z góry powoduje brak dokģadnoķci w literaturze i badaniach. Poniŋszy argument ilustruje, dlaczego. System oparty na wiedzy jest terminem uŋywanym w Sztucznej Inteligencji do odwoģywania się do systemu, który przetwarza wiedzę w pewien sposób. Moŋemy uczyniæ analogię systemu opartego na wiedzy jako repozytorium wiedzy, podczas gdy baza danych jest repozytorium danych. Jednak w tej definicji zaniedbaliķmy zdefiniowanie znaczenie terminu "wiedza" i jego odmiennoķæ w stosunku do danych. Na przykģad moŋemy zadaæ sobie następujące pytanie: "Co to jest system oparty na wiedzy i czym róŋni się on od systemu baz danych?" Jest to trudne pytanie, na które nie moŋna ģatwo odpowiedzieæ w prosty sposób. Powszechnie stosowane podejķcie w literaturze jest takie, ŋe system oparty na wiedzy moŋe przeprowadzaæ rozumowanie za pomocą jakiejķ formy inferencji (opartej na reguģach, ramowych, patrz poniŋej). Jednak nowoczesne systemy baz danych wykorzystują obecnie większoķæ tych standardowych "opartych na wiedzy" technik i więcej. Oczywiste jest, ŋe samo dodanie zdolnoķci inferencyjnych nie jest wystarczające do zdefiniowania systemu opartego na wiedzy. Jednak wiele z literatury A.I. tworzy takie zaģoŋenie. Unikając definicji wiedzy, problemem staje się to, ŋe nie jest juŋ jasne, ŋe to, co budujemy, faktycznie jest "oparte na wiedzy". W częķci 1 stwierdzono, ŋe wczesne systemy A.I. w latach 70. i 80. XX wieku cierpiaģy na brak oceny - istniaģo pęd do budowy nowych systemów, ale często przeprowadzono bardzo niewiele oceny tego, na ile systemy dziaģają. Bez dziaģającej definicji wiedzy ten sam problem występuje obecnie w przypadku obecnych systemów opartych na wiedzy - w jaki sposób moŋemy oceniæ, jak skuteczny moŋe byæ nasz system oparty na wiedzy, jeķli nie mamy definicji tego, co powinno byæ (lub nawet osiągnąæ lub osiągnąæ) )? Moŋemy jednak uniknąæ filozoficznych puģapek i zamiast próbowaæ zdefiniowaæ wiedzę, i twierdząc, ŋe ta definicja jest "wģaķciwa", zamiast tego moŋemy zaproponowaæ zasady projektowania naszego systemu opartego na wiedzy. W związku z tym moŋemy zdecydowaæ, jakie zasady chcielibyķmy stosowaæ w naszym systemie opartym na wiedzy, a my, jako projektanci, moŋemy dowolnie je zmieniaæ w zaleŋnoķci od wiedzy, którą zdobywamy podczas procesu projektowania. Poza tym nie stoimy juŋ na niepewnym gruncie w tym sensie, ŋe nie musimy podawaæ jednej konkretnej definicji wiedzy, która jest otwarta na debatę filozoficzną, chociaŋ wciąŋ jesteķmy otwarci na krytykę, czy nasze zasady są opģacalne z perspektywy inŋynierskiej ( tj. czy produkują "dobre" programy lub nie są tak dobre, jak inne podejķcia). Ale ocena staje się znacznie prostsza - wszystko, co musimy zrobiæ, to oceniæ, czy nasze zasady projektowania są speģnione. Poniŋej przedstawiono niektóre zasady projektowania systemów opartych na wiedzy.
Zasada projektowania 9.1: System oparty na wiedzy musi byæ systemem zorientowanym na agenta. System oparty na wiedzy musi byæ systemem zorientowanym na agenta, który jest zgodny z następującymi zasadami projektowania agenta - jest autonomiczny; jest reaktywny; jest proaktywny (przynajmniej).
Argumentem za tą zasadą projektowania jest to, ŋe jeķli projektujemy z wcielonej, usytuowanej perspektywy agenta, wówczas caģa wiedza nie moŋe istnieæ niezaleŋnie od agentów. Oznacza to, ŋe wiedza nie moŋe istnieæ sama z siebie - moŋna ją znaležæ jedynie w "umysģach" agentów, które są ucieleķnione i usytuowane w otoczeniu. My równieŋ chcemy zdefiniowaæ i uŋywaæ terminu "wiedza" w sposób podobny do terminu uŋywanego w języku naturalnym. Žródģo sģowa "wiedza" pochodzi od czasownika "wiedzieæ". Z perspektywy języka naturalnego "wiedza" i "wiedza" są ze sobą powiązane. Na przykģad kamieņ nie "niczego" nie "zna". Ale pies moŋe "wiedzieæ", gdzie zakopaģ koķæ; i ma sens powiedzieæ w języku naturalnym, ŋe pies ma "wiedzę" o miejscu pochówku koķci. Pies, w tym przypadku, jest agentem, a skaģa jest obiektem w ķrodowisku. Innymi sģowy, zachowanie wiedzy jest powiązane z agentem, który ma wiedzę. System oparty na wiedzy moŋe byæ wówczas uwaŋany za agenta, którego rolą jest przekazywanie wiedzy, którą zawiera on uŋytkownikom systemu. Interakcja między agentem uŋytkownika i agentem systemu moŋe byæ scharakteryzowana przez dziaģania, które determinują zachowanie kaŋdego agenta i czy agent uŋytkownika postrzega agenta systemu jako dziaģającego w sposób kompetentny. Prowadzi to do kolejnej zasady projektowania.
Zasada projektowania 9.2: System oparty na wiedzy musi byæ w stanie odpowiedzieæ na nasze pytania lub wykonaæ zadanie w sposób, który uznajemy za kompetentny. System oparty na wiedzy musi mieæ wiedzę na temat wykonywanego zadania.
Poniŋsze zasady projektowania opierają się na wģaķciwoķciach "dobrych" systemów opartych na wiedzy zaproponowanych przez Russella i Norviga
Zasada projektowania 9.3: System oparty na wiedzy musi byæ zwięzģy. Równowaga powinna byæ obowiązującą zasadą.
Zasada projektowania 9.4: System oparty na wiedzy musi byæ jednoznaczny. Wiedza musi mieæ wyražne znaczenie i nie moŋe byæ otwarta na więcej niŋ jedną interpretację
Zasada projektowania 9.5: System oparty na wiedzy musi byæ poinformowany i aktualny. System oparty na wiedzy nie moŋe byæ nieaktualny.
Zasada projektowania 9.6: System oparty na wiedzy musi dąŋyæ do jak największej poprawnoķci. Wiedza nie powinna byæ bģędna, bģędna, niedokģadna ani nieprecyzyjna
Zasada projektowania 9.7: System oparty na wiedzy musi byæ tak kompletny, jak to tylko moŋliwe. Wiedza nie powinna byæ niekompletna ze szczegóģami brakującymi.
Behawioralne podejķcie do wiedzy kģadzie nacisk nie na budowanie konkretnego, niezaleŋnego systemu, ale na budowanie agentów, które wykazują zachowania, które pokazują, ŋe mają wiedzę o swoim ķrodowisku i innych agentach. W tym podejķciu akt "poznania" występuje, gdy agent ma informacje, które mogą potencjalnie pomóc w wykonaniu dziaģania podjętego przez niego lub przez innego agenta. Ponadto, moŋna uznaæ, ŋe agent ma "wiedzę", jeķli wie, jakie są prawdopodobne wyniki dziaģania, które moŋe wykonaæ, lub dziaģania, które wykonuje inny agent, lub co moŋe się zdarzyæ z obiektem w ķrodowisku. W tej definicji wiedzę moŋna uwaŋaæ analogicznie za brak potrzeby poszukiwania; Oznacza to, ŋe agent nie musi stosowaæ zachowaņ w wyszukiwaniu, aby dowiedzieæ się, co moŋe się wydarzyæ, poniewaŋ ma juŋ wiedzę o tym, co się wydarzy.
Wiedza jako uzasadnione prawdziwe przekonanie
Standardową definicją wiedzy, przypisaną Platonowi, jest to, ŋe istnieją trzy warunki wymagane, aby agent mógģ posiadaæ wiedzę - wiedza musi byæ uzasadniona, prawdziwa i wairygodna. Wiarę moŋna zdefiniowaæ jako stan psychologiczny agenta, który utrzymuje konkretne stwierdzenie za prawdziwe, które nie jest jeszcze w peģni poparte dowodami. Aby przekonanie mogģo staæ się wiedzą, stwierdzenie, w które wierzy agent, musi byæ prawdziwe, a agent musi równieŋ byæ uzasadniony w swoich przekonaniach - innymi sģowy, muszą mieæ powód, dla którego myķlą (tj. dlaczego "wiedzą"). konkretne oķwiadczenie za prawdziwe. Na przykģad agent moŋe sądziæ, ŋe stolicą Zjednoczonego Królestwa jest Londyn, z pewnym uzasadnieniem. Zamiast tego moŋe byæ inny agent , który faģszywie wierząy, ŋe stolicą Zjednoczonego Królestwa jest Edynburg, a nie Londyn. Jednak wiadomo, ŋe nie jest to prawda, a poparcie dla wiary jest bardzo niewielkie. Znaczna częķæ literatury - w dziedzinie filozofii, matematyki, w dziedzinie Sztucznej Inteligencji i węŋszej poddziedzinie systemów opartych na wiedzy - często sprawia, ŋe pragmatyczne zaģoŋenie, ŋe okreķlenie, czy coķ jest prawdziwe czy faģszywe, jest uŋyteczną rzeczą do zrobienia. W rzeczywistoķci jednak, absoluty są rzadkie i bardzo niewiele z naszej wiedzy jest zawsze caģkowicie prawdziwe lub caģkowicie faģszywe. Odnosi się to do naszego istnienia jako umiejscowionych, ucieleķnionych agentów, które zapewniają kaŋdemu agentowi unikalną perspektywę ķwiata, w którym ŋyje, i które powoduje, ŋe kaŋdy agent nigdy nie jest w peģnej zgodnoķci z sobą nad znaczeniem pojęæ stanowiących podstawę wiedza, umiejętnoķci . Eksperyment Myķlowy ilustruje niektóre problemy z prawdami absolutnymi.
Eksperyment Myķlowy : Spacer po lesie.
"Wszyscy kģamią. Policjanci kģamią. Prawnicy kģamią. Ķwiadkowie kģamią. Ofiary kģamią. Proces jest konkursem kģamstw. I wszyscy na sali sądowej o tym wiedzą. Nawet jsąd to wie." -Michael Connelly w The Brass Verdict.
Wyobražmy sobie następujący scenariusz. Męŋczyzna o imieniu Bill stoi u podnóŋa duŋego wzgórza na obrzeŋach maģego miasta. Wczesnym wieczorem wybraģ się na wycieczkę po lesie i zatrzymaģ się na kilka chwil obok polany na drzewach, aby spojrzeæ na krajobraz. Kiedy on tam jest, jest ķwiadkiem zbrodni w mieķcie, gdzie ktoķ wģamuje się do czerwonego samochodu, który póžniej jest uŋywany w napadzie. Kilka miesięcy póžniej zostaje wezwany do zģoŋenia zeznaņ w sądzie. Na początku pytają się go, aby powiedziaģ"prawdę, caģą prawdę i tylko prawdę". Oczekuje się, ŋe udzieli prawdziwych odpowiedzi na pytania oparte na faktach, a nie na spekulacjach. Zbadajmy ewentualne pytania, które mogą mu zadaæ obroņca (który broni osoby oskarŋonej o zbrodnie i kradzieŋe samochodów). Co waŋne, jak "prawdomówny" moŋe byæ Bill i jak ģatwo mu to zapewniæ tylko "fakty" w jego odpowiedziach?
Pytanie 1: Gdzie w lesie staģeķ? Obszar, w którym szedģ, byģ stosunkowo pģaski i nie byģ pewien dokģadnego miejsca. Odkąd zszedģ ze szlaku, mógģby spróbowaæ opisaæ, gdzie stoi "gdzieķ niedaleko skrzyŋowania gģównego szlaku i mniejszego szlaku u podnóŋa wzgórza, okoģo 200 do 300 metrów". W rzeczywistoķci jest to więcej niŋ 400 jardów, poniewaŋ jest zģym sędzią dystansu. W okolicy jest wiele wzgórz, których nie moŋna odróŋniæ od innych, z wyjątkiem tego, ŋe lokalni mieszkaņcy lubią odróŋniaæ jedno konkretne wzgórze, skoro szlaki zaczynają się obok miasta i ģatwo moŋna dojķæ na szczyt. "Noga" wzgórza nie znajduje się nigdzie, poniewaŋ wzgórze jest okrągģe, a miasto rozpoķciera się nad najniŋszym punktem po jednej stronie wzgórza, a pod względem technicznym Bill staģ poķrodku wzgórza. Węzeģ szlaku jest równieŋ wielopģaszczyznowy, z wieloma maģymi ķcieŋkami, spowodowanymi przez tysiące osób, które na przestrzeni lat stosowaģy skróty, więc niemoŋliwe jest podanie dokģadniejszej odlegģoķci, poniewaŋ niemoŋliwe jest precyzyjne okreķlenie "faktów". "Gdzie to skrzyŋowanie w rzeczywistoķci jest (do kilkunastu metrów).
Pytanie 2: Na której polanie w drzewa patrzyģeķ? Okazuje się, ŋe jest wiele polanek, ŋadna w szczególnoķci odróŋnialna od innych. Podobnie jak wszyscy, którzy kiedykolwiek przekazywali wskazówki zagubionym podróŋnikom, Bill skupiģ się na cechach, które uwaŋaģ za waŋne dla niego, i ignorowaģ inne cechy, które byģy tak samo widoczne. (które inni mogą zauwaŋyæ).
Pytanie 3: Jak dģugo się zatrzymaģeķ? Nie ma absolutnej odpowiedzi na to pytanie, poniewaŋ czas jest ciągģy. Potrafi odpowiedzieæ "5 minut", "kilka minut", "kilkaset sekund" i "nie dģugo". Jeķli wymagana jest bardziej precyzyjna odpowiedž, wówczas "4 minuty 56,4" sekundy mogą byæ bliŋsze "prawdy", a nawet bardziej precyzyjnie "296.4317817819 ... sekundy". W pewnym sensie wszystkie te odpowiedzi odzwierciedlają prawdę i moŋna je uznaæ za prawdziwe.
Pytanie 4: Kiedy przestaģeķ? Bill nie miaģ przy sobie zegarka, więc nie moŋe ustaliæ dokģadnego czasu. "Czasem wczesnym wieczorem, tuŋ przed zmierzchem, 30 minut przed zachodem sģoņca" (wszystkie trzy są "prawdziwe").
Pytanie 5: Jak byģo ciemno? Jak ciemno jest cokolwiek? To byģ początek zmierzchu, w lesie, ale miasto wciąŋ byģo w sģoņcu. W pewnym sensie byģ "względnie" ciemny (w lesie), ale "względnie" jasny (w mieķcie), a więc miaģ "względnie" dobry obraz postępowania, którego byģ ķwiadkiem. Obiektywnie mówiąc.
Pytanie 6: W jakim kierunku wyglądaģeķ? "W stronę miasta przez lukę między drzewami." Ale miasto to wielkie miejsce - trudno jest okreķliæ dokģadny kierunek, w którym patrzy, a pole widzenia Billa jest doķæ duŋe.
Pytanie 7: Jakiego koloru byģ samochód, w którym się pojawiģ? Bill myķli, ŋe kolor byģ czerwony, ale jego definicja "zaczerwienienia" jest subtelnie róŋna od definicji wszystkich innych, a poniewaŋ byģ to początek zmierzchu, a wraz z pochyleniem kierunku promieni sģonecznych, zaczerwienienie przesunęģo się bardziej w stronę czerwono-pomaraņczowej
Oczywiķcie, w przypadku wszystkich tych pytaņ bardzo trudno jest udzieliæ precyzyjnej odpowiedzi. Sąd domaga się, aby tylko fakty z sprawa powinna byæ rozwaŋona, ale jakie są "fakty"? Nie wie dokģadnie, gdzie się znajduje ani gdzie się znajduje szukaģem, albo jak ciemno byģo, albo dokģadnie jaki kolor byģ samochodem. W tej sytuacji, jak mogą istnieæ jakiekolwiek "fakty" w ogóle? Oczekuje się od niego jednak, ŋe dostarczy tylko prawdziwe odpowiedzi. Jest jeszcze jeden waŋny czynnik, który naleŋy wziąæ pod uwagę. Kolor skradzionego samochodu opisuje się jako "czerwony". Ale jaki kolor jest "czerwony"? Spróbuj opisaæ to osobie niewidomej. Lub spróbuj graæ w grę zgadywania samochodów opisaną w sekcji 7.8. W tej grze kaŋda osoba w samochodzie wybiera kolor, z którym chce się bawiæ - biaģy ma dobry kolor, ale czerwony i niebieski są równieŋ dobre. Grę wygrywa osoba, która liczy największą liczbę samochodów jadących w przeciwnym kierunku w tym samym kolorze, co wybrane. Najbardziej interesującą rzeczą w tej grze jest liczba argumentów powoduje to, na przykģad, jak dģugo gra się gra, czy samochody "zatrzymaģy się" przy poboczu drogi, oraz czy kolor ten byģ "czerwony", a nie "róŋowy" lub "fioletowy", które się nie liczą. Istnieje bardzo dobry powód, dla którego istnieją argumenty dotyczące koloru niektórych samochodów. Ŋadne dwie osoby nie mają dokģadnych danych ta sama definicja tego, co "czerwony" lub "niebieski" oznacza w ich umysģach
Róŋne rodzaje wiedzy
Zamiast próbowaæ okreķliæ, czym jest wiedza, moŋemy alternatywnie spróbowaæ zdefiniowaæ róŋne rodzaje wiedzy, które czasami mogą byæ ģatwiejsze. Na przykģad gepard i tygrys to dwa rodzaje zwierząt o wyražnych cechach, które są względnie ģatwiejsze do zdefiniowania w porównaniu do próbowania okreķlenia co to za zwierzę .Definiowanie róŋnych rodzajów wiedzy moŋe pomóc nam uzyskaæ pewien wgląd w to, jak moŋemy budowaæ agentów, które wykazują wiedzę (w tym systemy oparte na wiedzy, uwaŋane za agentów). Moŋemy zdefiniowaæ agenta jako posiadającego deklaratywną wiedzę, jeķli deklaruje, ŋe pewne stwierdzenie jest prawdziwe. Aby okreķliæ, czy okreķlona wiedza jest deklaratywna, czy nie, agent moŋe zadaæ następujące pytanie: "Czy ta wiedza moŋe byæ prawdziwa czy faģszywa?"; lub umieķciæ w inny sposób: "Czy to prawda czy faģsz, ŋe X?", gdzie X jest danym stwierdzeniem. Jeķli pytanie ma charakter gramatyczny, moŋna go uznaæ za wiedzę deklaratywną. Na przykģad następujące pytanie ma sens: "Czy to prawda czy faģsz, ŋe moa nowozelandzki wymarģy?"; dlatego wiedza, ŋe moa Nowej Zelandii wyginęģa, jest deklaratywna. Poniŋsze pytania nie mają sensu: "Czy jazda na rowerze moŋe byæ prawdą czy faģszem?" Oraz "Czy to prawda czy faģsz, ŋe jedzie się na rowerze?". Porównaj to pytanie z następującymi, które są gramatyczne, a zatem deklaratywna wiedza, jeķli agent wiedziaģ to: "Czy to prawda czy faģsz, ŋe moa nowozelandzkie moŋe ježdziæ na rowerze?" Innymi sģowy, kiedy agent deklaruje, ŋe coķ jest albo prawdą o kģamstwie, to mówi się, ŋe ta wiedza jest deklaratywna, i czy ta wiedza jest Faģszywe lub nie ma sensu w realnym ķwiecie wciąŋ nie powstrzymuje go od deklaratywnej wiedzy. Odnoķnie prawdy (czy deklaracja jest prawdziwa, czy faģszywa), naleŋy zauwaŋyæ, ŋe w rzeczywistoķci absoluty są rzadkoķcią i bardzo maģą częķcią naszego wiedza jest zawsze caģkowicie prawdziwa lub caģkowicie faģszywa (jak wskazano w poprzedniej sekcji). W jaki sposób ta definicja deklaratywnej wiedzy pasuje do wiedzy zdefiniowanej powyŋej jako brak potrzeby poszukiwania? Rozwaŋmy następujące: agent bez uprzedniej wiedzy o tym, czy deklaracja jest prawdą lub faģszem, musi najpierw skonsultowaæ się z innym agentem, albo musi zgģębiæ lub dokonaæ obserwacji ķrodowiska, aby dowiedzieæ się, co jest prawdziwe lub faģszywe. Obie są czynnoķciami, które agent musi podjąæ, aby znaležæ odpowiedž. Mówi się, ŋe agent zna juŋ odpowiedž, jeķli nie musi wykonywaæ akcji przeszukiwania. Moŋemy zdefiniowaæ agenta jako posiadającego wiedzę proceduralną, jeķli wie, jak wykonaæ sekwencję czynnoķci, aby zapewniæ, ŋe deklaracja X stanie się prawdziwa. Aby ustaliæ, czy konkretna wiedza jest proceduralna, czy nie, agent moŋe zadaæ następujące pytanie: "Jakie dziaģania muszę wykonaæ, aby móc zadeklarowaæ, ŋe X jest prawdziwe?" Jeķli pytanie ma sens, moŋna uznaæ, ŋe byæ wiedzą proceduralną. Na przykģad następujące pytanie ma sens: "Jakie dziaģania muszę wykonaæ, aby móc stwierdziæ, ŋe jeŋdŋę na rowerze jest prawdą". Pytanie, czy wiedza w systemach opartych na wiedzy powinna byæ deklaratywna czy proceduralna, byģo wķciekģą debatą w dziedzinie sztucznej inteligencji. Jak to często bywa w przypadku debat typu "Czy dziobak jest ssakiem?", Po obu stronach argumentacji jest zasģuga, poniewaŋ pewna wiedza jest z natury deklaratywna, a inna wiedza jest z natury proceduralna - na przykģad, gdy ludzie liczą, ŋe stosują procedura, ale faktyczne informacje dotyczące nazwisk osób i nazw lokalizacji na mapie mają charakter deklaratywny. Debata dostarczyģa wgląd w niektóre kwestie dotyczące kategoryzacji wiedzy, ale z pragmatycznej perspektywy projektowania, badacze AI skupili się bardziej na budowaniu przydatnych systemów, a zatem wybiorą najbardziej odpowiednie narzędzie dla danego zadania. Wiedza na temat zadaņ czasami róŋni się od wiedzy proceduralnej. Wiedzę o zadaniu moŋna uznaæ za wyspecjalizowaną formę wiedzy proceduralnej, w której celem dziaģaņ jest rozwiązanie zadania (np. Znalezienie odpowiedzi na konkretne pytanie). Wiedza behawioralna to wiedza, którą agent ma o prawdopodobnych wynikach zachowaņ (swoich i innych agentów). Agent ma wiedzę epizodyczną, jeķli wie, kiedy stwierdzenie X staģo się prawdą. Agent ma wiedzę wyjaķniającą, jeķli potrafi wyjaķniæ, co spowodowaģo sekwencję dziaģaņ, które doprowadziģy do tego, ŋe oķwiadczenie X staģo się prawdziwe. Wreszcie moŋemy stwierdziæ, ŋe agent wywnioskowaģ wiedzę, jeķli wykorzystaģ istniejącą wiedzę do okreķlenia nowej wiedzy, która nie byģa dostępna w ŋaden inny sposób. Moŋemy rozróŋniæ róŋne rodzaje wiedzy wedģug typów pytaņ, na które agent moŋe poprawnie odpowiedzieæ, korzystając z ich wiedzy. Deklaracyjna wiedza moŋe byæ wykorzystana do odpowiedzi na pytanie "Co to jest ...?" I "Gdzie jest ...?"; wiedzę epizodyczną moŋna wykorzystaæ do odpowiedzi na pytania: "Kiedy się ... zdarzyģo?"; wiedzę procesową i zadaniową moŋna wykorzystaæ w celu udzielenia odpowiedzi na pytania "Jak mogę / ty ...?"; wiedza behawioralna moŋe byæ wykorzystana do odpowiedzi na pytania "Co, jeķli ja / ty ...?"; a wnioskowa wiedza moŋe byæ uŋyta do odpowiedzi na pytania "Jeķli ... jest prawdą, to jest ... prawda?" i "Co, jeķli ... byģo prawdą?". Moŋemy równieŋ rozszerzyæ znaczenie wywnioskowanej wiedzy poza tradycyjną definicję opartą na logice, która wiąŋe się z wnioskiem, czy pewne stwierdzenie jest prawdziwe, czy faģszywe. Rozwaŋ sytuację, w której agent prowadzi rozmowę z innym agentem, na przykģad gdy jedna osoba rozmawia z inną osobą lub gdy ktoķ rozmawia z chatbotem. Powiedzmy, ŋe ta rozmowa jest obserwowana przez zewnętrznego agenta (np. Trzecia osoba, a moŋe osoba obserwująca osobę-rozmowę chatbotową w ramach testu Turinga). Ten obserwator będzie mógģ oceniæ, jak dobrze sądzi kaŋdy z agentów, którzy wykonali swoją częķæ rozmowy. Będzie to zaleŋaģo od tego, czy obserwator uzna, ŋe odpowiedzi są odpowiednie. W pewnym sensie obserwator wykorzystaģ swoją wģasną wiedzę na temat tego, co jest wģaķciwe do wydania takiego osądu. Agenci zrobili to samo, próbując utrzymaæ rozmowę. Moŋna to uznaæ za przykģad wywnioskowanej wiedzy. W takim przypadku znajomoķæ wģaķciwej odpowiedzi nie moŋe zostaæ uzyskana bezpoķrednio poprzez przejrzenie tabeli odnoķników odpowiednich odpowiedzi, poniewaŋ liczba stwierdzeņ językowych moŋe byæ uwaŋana za nieograniczoną (liczbę rzeczy, które dana osoba moŋe powiedzieæ, oraz liczbę odpowiedzi, jest zasadniczo nieskoņczony). Zamiast tego, odpowiednia odpowiedž musi byæ skonstruowana (to jest wywnioskowana) w pewien sposób.
Niektóre podejķcia do reprezentacji wiedzy i sztucznej inteligencji
Reprezentacja wiedzy dotyczy problemu, w jaki sposób wyraziæ wiedzę w bazie wiedzy. Podstawowym celem reprezentacji wiedzy jest modelowanie inteligentnego zachowania przy zaģoŋeniu, ŋe inteligentne zachowanie agenta wymaga wiedzy o nim samym i innych agentach, obiektach i ich relacjach, sposobie rozwiązywania zadaņ i prawach, które rządzą ķrodowiskiem, w którym agent znajduje samo w sobie. "Hipoteza reprezentacji wiedzy" (przypisywana Smithowi, 1985) zakģada przypuszczenie, ŋe dla inteligentnych agentów behawioralnych wykorzystuje się bazę wiedzy, która w pewien sposób reprezentuje wiedzę o ķwiecie. "Spór o reprezentację wiedzy" dotyczy tego, w jaki sposób wiedza powinna byæ reprezentowana, niezaleŋnie od tego, czy naleŋy ją wykorzystywaæ przede wszystkim w oparciu o symbole, czy teŋ za pomocą podejķcia nie symbolicznego. Podejķcie symboliczne to klasyczne podejķcie do sztucznej inteligencji, czasami nazywane "dobrą staroķwiecką sztuczną inteligencją" lub GOFAI. Opiera się na hipotezie "fizycznego systemu symboli", która stwierdza, ŋe system oparty na przetwarzaniu symboli ma "niezbędne i wystarczające ķrodki dla ogólnego inteligentnego dziaģania". Symbole w tym przypadku są rzeczami, które reprezentują lub reprezentują coķ innego przez skojarzenie. Język ludzki skģada się z symboli; na przykģad sģowo "moa" jest symbolem reprezentującym koncepcję nowozelandzkiego ptaka przedstawionego powyŋej. W dziedzinie reprezentacji wiedzy symbole są zwykle oznaczone przez identyfikator w języku programowania. Symboliczne podejķcie do sztucznej inteligencji jest podejķciem opartym na wiedzy, wymagającym budowania baz wiedzy o znacznej wiedzy na temat kaŋdej dziedziny problemowej. Wykorzystuje filozofię projektowania odgórnego skģadającą się z kilku poziomów: "poziomu wiedzy" na górze, który okreķla caģą wiedzę potrzebną systemowi; "poziom symbolu", w którym wiedza jest okreķlona w symbolicznych strukturach i identyfikatorach w niektórych językach programowania (na przykģad przy uŋyciu list lub tabel w NetLogo); oraz "poziom implementacji", które są faktycznie wykonywanymi operacjami przetwarzania symboli. Natychmiast pojawiają się problemy z symbolicznym podejķciem do reprezentowania wiedzy. Na przykģad spróbuj uŋyæ symboli (na przykģad sģów), aby opisaæ:
* jak wygląda obraz Mona Lisa po prawej stronie (dla osoby niewidomej od urodzenia);
* džwięk dudy (dla osoby gģuchej);
* smak mleka;
* jak wygląda papier ķcierny;
* jak pachnie kawa.
Sģowa wydają się niewystarczające do tego zadania. Zwróæ uwagę, ŋe wszystkie pięæ zmysģów jest tutaj reprezentowanych - wzrok, sģuch, smak, uczucie i zapach; i uŋywanie sģów do opisania tego, co odczuwamy, moŋe byæ problematyczne - często zostawiamy "walkę o sģowa", to często spotykane angielskie wyraŋenie. Inne popularne angielskie wyraŋenie mówi "obraz rysuje tysiąc sģów". Jeķli chodzi o problem wyraŋania twarzy osoby za pomocą jedynie symboli, na przykģad twarzy na obrazie Mony Lisy, ŋadna iloķæ sģów nie wystarcza, mimo ŋe obraz byģ przedmiotem niezliczonych esejów i ksiąŋek. Przeciwstawne podejķcie, zwane "poģączeniem", odrzuca klasyczne podejķcie symboliczne, i zamiast tego zaleca, aby inteligentne zachowanie byģo wynikiem przetwarzania pod-symbolicznego - to znaczy przetwarzania bodžców zamiast symboli; na przykģad przy uŋyciu sztucznych sieci neuronowych, które zawierają poģączone ze sobą sieci prostych jednostek przetwarzania. Tutaj wiedza jest przechowywana jako wzorzec znajomoķci masy neuronu. W tym podejķciu stosuje się oddolną filozofię projektu lub podejķcie "animat", najpierw próbując zduplikowaæ zdolnoķci przetwarzania bodžców i systemy kontroli prostszych zwierząt, takich jak owady, a następnie próbując stopniowo podnosiæ drabinę ewolucyjną ze wzrastającą zģoŋonoķcią. Podejķcie to podkreķla "problem uziemienia symbolu" - problem, w jaki sposób symbole nabierają znaczenia i postuluje "hipotezę o fizycznym podģoŋu", która stwierdza, ŋe znaczenie symboli musi byæ ugruntowane w fizycznym ucieleķnionym doķwiadczeniu agenta poprzez jego interakcję ze ķrodowiskiem. Kwestia, czy wiedza i inteligentne zachowanie powinny byæ reprezentowane symbolicznie lub niesymbolicznie, byģa trwającą debatą w dziedzinie Sztucznej Inteligencji od czasu, gdy w poģowie lat osiemdziesiątych pojawiģ się podsymboliczny sposób podejķcia do sztucznej inteligencji wraz z odrodzeniem się poģączenia z ideami Brooksa dotyczącymi dolnej granicy. w górę, ucieleķnione, usytuowane, oparte na zachowaniu podejķcie do sztucznej inteligencji. Jak to często bywa w przypadku tego typu debat, podobnie jak wspomniana powyŋej debata na temat deklaracji i procedur, nie ma za co obu stron argumentu, poniewaŋ niektóre zadania, takie jak odpowiadanie na pytania i rozumowanie oparte na reguģach, są bardziej dostosowane do podejķcie symboliczne, a niektóre rodzaje wiedzy stwarzają trudnoķci dla obu podejķæ, takich jak rozpoznawanie twarzy dla przetwarzania symbolicznego, oraz informacje o języku naturalnym dla przetwarzania pod symbolami za pomocą sztucznych sieci neuronowych . Opracowano wiele innych podejķæ, niektóre proponują poģączenie przetwarzania symbolicznego i podsystemu, na przykģad automatów usytuowanych. Przyjrzymy się temu drugiemu podejķciu bardziej szczegóģowo, poniewaŋ jest on przydatny do podkreķlenia niektórych waŋnych kwestii dotyczących reprezentacji wiedzy. Gärdenfors postuluje, ŋe to, co jest fundamentalne dla naszych ludzkich zdolnoķci poznawczych, to nasza zdolnoķæ do przetwarzania pojęæ, a te wyģaniają się z rozproszonej reprezentacji syndykalistów na najniŋszym poziomie, gdzie przetwarzane są bodžce z receptorów, i poģączyæ, tworząc struktury symboliczne na najwyŋszym poziomie, jak pokazano w Tabeli
Poziom modelu : Reprezentacja : Opis
Symboliczny : Zadaniowy Oparty na danym zbiorze predykatów o znanej denotacji. Reprezentacje są oparte na operacjach logicznych i skģadniowych
Pojęciowy : Geometryczny : Na podstawie zbioru "wymiarów jakoķci".
Reprezentacje są oparte o pojęcia topologiczne i geometryczne.
Asocjacjonizm : Konekcjonistyczny : W oparciu o (niezinterpretowane) dane wejķciowe od receptorów. Rozpowszechniane reprezentacje wedģug dynamicznych wag poģączeņ
Koncepcje stanowią podstawę wiedzy. Pojęcie to jednostka znaczenia reprezentująca abstrakcyjną ideę lub kategorię. Moŋemy myķleæ o koncepcjach jako analogicznych do atomów - atomy są podstawowymi elementami budującymi materię, podobnie jak pojęcia są podstawowymi elementami wiedzy. W podejķciu Gärdenfors pojęcia są reprezentowane jako regiony w przestrzeni n-wymiarowej, w analogiczny sposób, jak mapa topograficzna przedstawia uksztaģtowanie terenu, z podobnymi pojęciami reprezentowanymi w regionach geometrycznych, które są usytuowane przestrzennie blisko siebie, jak pokazano na rysunku.
W tym przykģadzie róŋne rodzaje zwierząt, takie jak ssaki, gady i ptaki, znajdują się w róŋnych regionach w przestrzeni. Gärdenfors wykorzystuje szeroki zakres eksperymentalnych dowodów z wielu dziedzin, aby wesprzeæ swoje argumenty. Na przykģad z dziedziny psychologii poznawczej istnieją dowody empiryczne, ŋe ludzie wykorzystują prototypy, aby zapewniæ kognitywny punkt odniesienia dla kaŋdej koncepcji. Podejķcie Gärdenfor w naturalny sposób pozwala na przedstawienie prototypów - prototypowa koncepcja, na przykģad robin, uŋywana jako punkt odniesienia dla koncepcji ptaka, będzie umiejscowiona centralnie w geometrycznej przestrzeni rodzica. Koncepcje, które nie są uŋywane jako prototypy, będą coraz bardziej oddalone, na przykģad pingwiny i emu. Moŋemy zilustrowaæ ten prosty eksperyment myķlowy. Pomyķl o ptaku. Który ptak sobie wyobraŋaģeķ? Eksperymenty wykazaģy, ŋe większoķæ ludzi pomyķli o robinie, wróblu lub podobnym ptaku, a nie o emu czy pingwina. Mechanizm, który Gärdenfors proponuje do konstruowania pojęæ, wykorzystuje proces oparty na tesselacji Voronoi za pomocą prototypów w celu rozbicia przestrzeni w regiony wypukģe, jak pokazano za pomocą linii prostych na powyŋszym rysunku. Wielowymiarowa geometria dla przestrzeni pojęciowej skonstruowana jest z tego, co Gärdenfors nazywa "wymiarami jakoķciowymi", które odpowiadają róŋnym sposobom oceniania bodžca agenta jako podobnego lub innego. Podstawową funkcją wymiarów jakoķciowych jest reprezentowanie róŋnych cech lub cech obiektów. Niektóre przykģady to temperatura, waga, jasnoķæ, wysokoķæ i wymiary przestrzenne, takie jak wysokoķæ, szerokoķæ i gģębokoķæ. Gärdenfors nazywa te "domeny". Uŋywa pojęcia "jabģka", aby zilustrowaæ rozróŋnienie między domeną a regionem:
Domena : Region
Owoce : Wartoķci dla skóry, ciaģa i rodzaju nasion.
: Czerwony, zielony, ŋóģty.
Smak : Wartoķci dla sģodyczy, kwaskowatoķci itp.
Ksztaģt : "Okrągģy" obszar przestrzeni ksztaģtu.
Odŋywcze : Wartoķci dla cukru, witaminy C, wģókien itp.
Jako kolejny przykģad, eksperymenty z ludzkim postrzeganiem domeny koloru pokazują, ŋe przestrzeņ pojęciowa koloru jest opisana za pomocą trzech wymiarów jakoķci - jasnoķci, barwy i nasycenia. (Dla porównania smak dla ludzi ma cztery wymiary jakoķci - sģodycz, kwaskowatoķæ, gorycz i zasolenie). Model Color Cylinder NetLogo pokazuje, jak wygląda ta przestrzeņ. Ten model rysuje kolorowy okrąg zawierający róŋne wartoķci odcienia i nasycenia dla okreķlonej wartoķci jasnoķci, którą moŋna regulowaæ za pomocą suwaka Interfejs między zakresem caģkowitym od 0 do 255, jak pokazano na rysunku

W celu obniŋenia wartoķci jasnoķci (patrz lewy obraz na rysunku) kolory stają się coraz bardziej ciemniejsze, a caģy okrąg staje się czarny, gdy wartoķæ jasnoķci jest ustawiona na 0, podczas gdy kolory zwęŋają się w kierunku biaģego w ķrodku okręgu, gdy suwak jasnoķci ustawiony jest na 255 (jak na prawym obrazku). Cylinder koloru wyķwietla peģny zakres moŋliwych kolorów we wszystkich wartoķciach barwy, stauracji i jasnoķci. Ludzie uŋywają szerokiego zakresu sģów w języku, aby opisaæ kolor. Dowody empiryczne pokazują, ŋe w róŋnych kulturach i grupach etnicznych ludzie zgadzają się na podobne obszary przestrzeni barw, aby odnieķæ się do podstawowych pojęæ dotyczących koloru, takich jak czerwony, zielony i niebieski. Jednak model butli kolorowej wyražnie pokazuje, ŋe nie ma wyražnych granic między kolorami, a jeden kolor stopniowo ģączy się z innym. Dlatego niemoŋliwe jest, aby móc dokģadnie wytyczaæ region powiązany z konkretnym kolorem. Na przykģad spróbuj narysowaæ granicę dla koloru ŋóģtego na prawym obrazku powyŋszego rysunku. Moŋemy wyražnie zobaczyæ, gdzie jest kolor ŋóģty, ale granice z sąsiednimi kolorami - czerwonymi i zielonymi po obu stronach i biaģymi w ķrodku - są niewyražne. Zadanie okreķlania tego, co jest ŋóģte, staje się jeszcze trudniejsze w trzech wymiarach, gdy uwzględniamy równieŋ zmianę jasnoķci. Wģaķnie dlatego występują nieporozumienia (tak jak w przypadku gry polegającej na oddywaniu samochodów opisanej w sekcji wczeķniejszej i wspomnianej w eksperymencie myķlowym 9.1), poniewaŋ kaŋdy czģowiek będzie miaģ niewielką zmiennoķæ w tym, co postrzega ŋóģty region do zrobienia. Dowody empiryczne pokazują, ŋe róŋnice w regionach pojęciowych występują nie tylko dla kategorii kolorów, ale takŋe dla wielu innych podstawowych kategorii, takich jak smak. Gärdenfors pozwala równieŋ na abstrakcyjne koncepcje i dostarcza przekonującego wyjaķnienia, dlaczego definiowanie wiedzy kategorialnej jest tak trudne, i dlaczego podejķcie czysto symboliczne nigdy nie będzie caģkowicie zadowalające. Dziobak, nietoperz i archeopteryks na przykģad na rysunku 2 występują trudnoķci z kategoryzacją, przy czym ta ostatnia jest szczególnie trudna, poniewaŋ znajduje się na granicy między kategorią gadów a kategorią ptaków. Gärdenfors wyjaķnia równieŋ, jak waŋne są kombinacje pojęæ takich jak "drewniana ģyŋka" okreķlane na podstawie korelacji między domenami, które są wspólne dla oddzielnych pojęæ "drewno" i "ģyŋka". W tym przypadku domeny są wielkoķcią i materiaģem, a to powoduje, ŋe myķlimy o drewnianej ģyŋce jako duŋej, a nie maģej, gdy wyobraŋamy sobie, jak moŋe wyglądaæ. W niektórych przypadkach znaczenie pojęcia zaleŋy od kontekstu, w którym występuje. Na przykģad woda z kranu o tej samej letniej temperaturze moŋe byæ postrzegana jako gorąca, jeķli zostanie umieszczona w szklance, a zimna, jeķli zostanie umieszczona w wannie. Ģatka niebieskiego nieba będzie się róŋniæ "bģękitem" w zaleŋnoķci od pory dnia, jasnoķci, zachmurzenia nieba, deszczu w ciągu ostatniego miesiąca i tak dalej. Gärdenfors ilustruje takŋe waŋną rolę, jaką kontekst odgrywa w okreķlaniu znaczenia na podstawie poniŋszego przykģadu. Kolor czerwony ma róŋne znaczenia w następujących kombinacjach koncepcji: "czerwona ksiąŋka" (kolor, który naszym zdaniem jest bliski do standardowej definicji koloru czerwonego); czerwone wino (zbliŋone do koloru fioletowego?); rude wģosy (zbliŋone do koloru miedzi?); czerwona skóra (tawny?); czerwona ziemia (ochra?); i sekwoja (róŋowawy brąz?). Model przestrzeni konceptualnej pokonuje niektóre niedobory wczeķniej odmiennych symbolicznych i sub-symbolicznych podejķæ do reprezentacji wiedzy i sztucznej inteligencji, postulując ķredni poziom reprezentacji. Zapewnia wiarygodne wyjaķnienie aspektów reprezentacji wiedzy czģowieka, takich jak kategoryzacja za pomocą prototypów, kombinacja koncepcji i rola kontekstu w formowaniu pojęcia znaczenia, które przedstawia trudnoķci innym modelom. Ma równieŋ znaczenie dla projektowania ucieleķnionych, usytuowanych agentów, poniewaŋ pokazuje, w jaki sposób moŋemy budowaæ wiedzę bez potrzeby stosowania semantyki uziemienia symboli. Odnosi takŋe wiedzę do miejsc w przestrzeniach n-wymiarowych, abyķmy mogli scharakteryzowaæ inteligentne zachowanie (na przykģad myķlenie) jako ruch w tej przestrzeni w sposób analogiczny do uŋywania map do nawigowania i reprezentowania topograficznego terenu.
Problemy z inŋynierią wiedzy
Inŋynieria wiedzy to proces budowania systemów opartych na wiedzy. Model NetLogo Knowledge Representation zostaģ opracowany w celu zilustrowania i porównania róŋnych metod reprezentacji wiedzy oraz pokazania, w jaki sposób moŋna je zastosowaæ do róŋnych typów rozumowania w dziedzinie problemu klasyfikacji. Model zapewnia trzy przykģadowe problemy inŋynierii wiedzy. Zoo Animals jest uproszczeniem klasycznego przykģadu z Winstona (1977). Problem New Zealand Birds zostaģ wprowadzony wczeķniej jak równieŋ drzewo decyzyjne związane z problemem . Problem Sailing Boats jest przykģadem opisanym przez Negnevitsky'go
Nazwa problemu : Opis problemu
Zoo Animals : Zidentyfikowaæ nazwę zwierzęcia w zoo.
New Zealand Bird : Zgadnij nazwę ptaka nowozelandzkiego.
Sailing Boats : Okreķlają rodzaj ģodzi, która pģynie obok w paradzie wielkich ŋaglowców
Te trzy przykģadowe problemy to problemy "zabawkowe", a nie rzeczywiste problemy. Wymienienie peģnej wiedzy i skalowanie do nietrywialnego problemu w ķwiecie rzeczywistym przedstawia wiele trudnoķci i nadal jest aktywnym obszarem badaņ w Sztucznej Inteligencji. Jednak zaletą tych przykģadów jest ich prostota i przydatnoķæ do zilustrowania tego, jak modele róŋnią się..
Wiedza bez reprezentacji
W pozostaģych sekcjach omówimy róŋne metody reprezentowania wiedzy - za pomocą map, reguģ i logiki, ram, drzew decyzyjnych i sieci semantycznych. Zanim jednak to zrobimy, musimy najpierw zadaæ waŋne pytanie: "Czy moŋliwe jest posiadanie wiedzy bez reprezentacji?" Innymi sģowy, czy agent lub agenci mogą uzyskaæ wiedzę bez ŋadnego wyražnego mechanizmu reprezentowania wiedzy uzyskanej w baza wiedzy? Jeķli jest to moŋliwe, wydaje się to początkowo sprzeczne z hipotezą o reprezentacji wiedzy. Jednak ta hipoteza zakģada, ŋe dla inteligentnego zachowania agent lub agent musi reprezentowaæ wiedzę o ķwiecie; dlatego teŋ, jeķli agent lub agenci mogą zdobywaæ wiedzę bez reprezentacji, to wedģug tej definicji nie wykazują inteligentnego zachowania. Widzieliķmy juŋ, jak wiedza bez reprezentacji jest moŋliwa w wielu modelach NetLogo, w których agenci wykorzystują stygmergię - model Ants i modele termitów. W tych przypadkach "wiedza" jest przechowywana w ķrodowisku wewnątrz kompleksu struktury powstające, gdy system agentów i ķrodowisko samoorganizują się. Chociaŋ kaŋdy agent nie posiada wiedzy indywidualnie, caģa kolonia agentów posiada wiedzę. Ale czy moŋemy powiedzieæ, ŋe ci agenci uŋywający stygmergii naprawdę zdobyli wiedzę? Zgodnie z definicją, ŋe wiedza to brak potrzeby poszukiwania, to na przykģad mrówki zdobyģy wiedzę na temat poģoŋenia pobliskich žródeģ ŋywnoķci, które następnie mogą przekazaæ kolonii, a zatem inni agenci są w stanie podąŋaæ ķcieŋką z powrotem do žródģa poŋywienia bez podejmowania decyzji, którą drogę wybraæ. Moŋna argumentowaæ, w zaleŋnoķci od twojej definicji inteligencji, ŋe te mrówki równieŋ wykazują szczątkową formę sztucznej inteligencji, poniewaŋ dziaģają i zachowują się w inteligentny sposób, aczkolwiek w ograniczonym sensie.
Reprezentowanie wiedzy za pomocą map
Mapy są jedną z najstarszych metod wykorzystywanych przez ludzi do reprezentowania wiedzy. Na przykģad najwczeķniejsze mapy ķwiata stanowią ilustrację postępu ludzkiej wiedzy geograficznej na przestrzeni wieków. Najstarszą znaną na ķwiecie mapą jest Imago Mundi, czyli tablica z gliny z VI wieku pne, datowana na okoģo 600 r. Pne, zamieszkaģa w British Museum, przedstawiająca znany ķwiat babiloņski z Asyrią, Babilonią i Armeni (patrz zdjęcie po prawej). Obraz pokazuje, ŋe znajomoķæ geografii ķwiata w tamtym czasie byģa wyražnie ograniczona, podobnie jak jakoķæ mapowania. Rysunek 9.4 przedstawia dwie dalsze wczesne mapy ķwiata.
Ten po lewej to mapa sporządzona przez Posidoniusa (150-130 pne) przedstawiająca mapę obejmującą gģównie Morze Ķródziemne, Europę poģudniową, poģudniowo-zachodnią Azję i póģnocną Afrykę. Ten po prawej jest autorstwa Abrahama Orteliusa w 1570 roku. Pokazują one postęp w zakresie wiedzy i jakoķci mapowania, z mapą "Typvs orbis terrarvm" wyprodukowaną przez Orteliusa najbliŋej ksztaģtu do wspóģczesnych map ķwiata. Wszystkie trzy przykģady ilustrują waŋną cechę tego rodzaju map geograficznych. Z samej swej natury, jako dwuwymiarowej reprezentacji ķwiata 3D, wszystkie mapy mają bģędy w reprezentacji - to znaczy, ŋe nie w peģni odzwierciedlają rzeczywistoķæ. Jest to widoczne, gdy mapy pokazane na obrazach są porównywane z mapami wspóģczesnego ķwiata. Na przykģad mapa Orteliusa odbiega w znacznym stopniu od rzeczywistoķci w jej obrazie kontynentu póģnocnoamerykaņskiego, odzwierciedlając stan wiedzy w chwili, gdy Krzysztof Kolumb odkryģ Amerykę dopiero w 1492 roku. Mapy równieŋ odbiegają od rzeczywistoķci, jeķli są statyczną reprezentacją ķrodowiska, które reprezentuje mapa - na przykģad ķwiat jest dynamicznym i ciągle zmieniającym się miejscem, które zostaģo przemienione przez ludzi przez wieki, odkąd wczesne mapy zostaģy najpierw narysowane. Kaŋda mapa staje się bardziej uŋyteczna, jeķli jest rzetelnym odbiciem prawdziwego ŋycia, ale w wielu przypadkach stylizowane obrazy pojawiają się, gdy relacje między sąsiednimi obiektami na mapie są wypaczone, aby odzwierciedliæ celowe podkreķlanie częķci programu odwzorowującego lub z powodu innych elementów. takie powody, jak brak wiedzy, celowe stronniczoķæ lub niedopatrzenie. Ten nieodģączny bģąd mapowania powinien byæ brany pod uwagę w poniŋszej dyskusji na temat tradycyjnych form reprezentacji wiedzy. Reprezentatywną wiedzę moŋna uwaŋaæ za analogiczną do mapowania w tym sensie, ŋe podejmowana jest próba dokģadnego odzwierciedlenia abstrakcyjnego n-wymiarowego ķrodowiska kosmicznego, ale proces mapowania spowoduje powstanie nieodģącznych bģędów mapowania spowodowanych znieksztaģceniami, bģędami, celowym naciskiem, nastawieniem, nadzorem i brakiem wiedzy . Znaczenie map jako metody reprezentowania wiedzy jest często pomijane w obszarze Sztucznej Inteligencji w tradycyjnej dyskusji na temat tego, jak reprezentowaæ wiedzę. Bezdyskusyjnie jednak mapy zawierają bogactwo wiedzy. Pojawienie się Google Maps i Google Earth ilustruje zdolnoķæ map internetowych do reprezentowania szerokiej gamy wiedzy. Mapa Central Park South w Nowym Jorku pokazana na rysunku 9.5 wykonana za pomocą modelu NetLogo Map Drawing zawiera równieŋ bogactwo wiedzy w tym sensie, ŋe osoba odwiedzająca Central Park po raz pierwszy moŋe korzystaæ z mapy, aby znaležæ drogę bez wiedzy gdzie wszystko jest z góry. Wiedza faktyczna lub deklaratywna jest wyražnie reprezentowana przez nazwy miejsc na mapie, takie jak Tavern on the Green, Sheep Meadow, Cherry Hill i Wollman Rink. Przedstawione są takŋe relacje tych lokalizacji z innymi lokalizacjami, takie jak lokalizacje sąsiadujące ze sobą i względne odlegģoķci między nimi. Ķcieŋki narysowane na mapie zapewniają równieŋ wyražną wiedzę o tym, jak to zrobiæ aby dostaæ się między róŋnymi miejscami. Ķcieŋki te moŋna traktowaæ jako zapewniające wiedzę proceduralną o krokach, które naleŋy wykonaæ (np. Czy skręciæ w lewo lub w prawo, czy iķæ prosto), aby uzyskaæ między dwoma lub więcej punktami. Ķcieŋki przedstawione na mapie równieŋ zapewniæ dalszą wiedzę, taką jak ich szerokoķæ oraz to, czy są one proste czy kręte, tj. mogą byæ wykorzystane do wnioskowania, czy są ģatwiejsze, czy szybsze do naķladowania. Kaŋdy, kto odwiedza Central Park lub korzysta z Google Earth, aby powiększyæ tę samą lokalizację, wkrótce zorientuje się, ŋe brakuje wielu informacji i zawiera wiele nieķcisģoķci z mapy pokazanej na rysunku.
Jednakŋe, tak jak mapy Hampton Court Palace i Chevening House pokazane w poprzednich częķciach mogą byæ uŋywane do poruszania się po prawdziwych labiryntach ogrodowych, mapa Central Park South moŋe byæ równieŋ przydatna, aby pomóc ludziom odnaležæ się i nie zgubiæ się pomimo te niedociągnięcia. Mapa przedstawia równieŋ przede wszystkim informacje topograficzne, w których brakuje innych informacji - na przykģad mapa nie uwzględnia faktów historycznych, takich jak wypasanie owiec na ģące owiec do 1934 r. (Stąd nazwa), a Tavern on the Green zostaģa przeksztaģcona z owcze pióro, w którym mieķci się trzoda. Flake (1998, strony 416-423) w swojej ksiąŋce "Computational Beauty of Nature" zauwaŋa, ŋe ķrodowiska, modele dla ķrodowiska i wyszukiwania są nierozerwalnie ze sobą powiązane. Zwracając uwagę, ŋe termin "model" moŋe oznaczaæ róŋne rzeczy w róŋnych kontekstach, definiuje go jako dobrze zdefiniowany proces, który mapuje dane wejķciowe na wyjķcia, które moŋna dostroiæ za pomocą parametrów. Poszukiwanie jest wtedy procesem wyboru najlepszych parametrów, aby model mógģ byæ zbliŋony do otoczenia. Uŋywa przykģadu wzoru matematycznego f (x; a, b, c) = asin (bx - c), który moŋe byæ uŋyty do modelowania procesu okresowego. Ta funkcja fal sinusoidalnych moŋe, ale nie musi byæ dobrym modelem do tego, co dzieje się w ķrodowisku, w którym odbywa się proces okresowy. Oczywiķcie taki model byģby caģkowicie niewystarczający jako reprezentacja większoķci ķrodowisk, które zwykle są znacznie bardziej zģoŋone. Jednak ten prosty model fali sinusoidalnej moŋna dostroiæ, szukając trzech parametrów a, b i c, które odzwierciedlają amplitudę, częstotliwoķæ i fazę fali sinusoidalnej, która najlepiej pasuje do okresowego ķrodowiska procesowego. Uŋywając analogii ķcieŋki w prawdziwym ŋyciu, proces okresowy generuje okreķloną ķcieŋkę przez ķrodowisko graficzne 2D. Sama ķcieŋka moŋe byæ przybliŋonym przybliŋeniem do ķcieŋki generowanej przez rzeczywiste obserwacje, które odnoszą się do bezwģadnoķci wahadģa, ķredniej temperatury sezonowej lub cyklu księŋycowego na przykģad. Modele zdefiniowane
przez Flake moŋna uznaæ za analogiczne do map topograficznych. Myķlenie o modelu jako o mapie ķrodowiska ķciķlej wiąŋe uŋywany język angielski, który opiera się na metaforze topograficznej kryjącej się za koncepcją ķrodowiska. Moŋemy rozwaŋyæ wyszukiwanie, które Flake odwoģuje się do procesu próbowania narysowania mapy, która ķciķle odzwierciedla to, co obserwuje się w ķrodowisku. Formuģa reprezentuje klasę map ķcieŋki, a parametry a, b i c po wyliczeniu okreķlają konkretną instancję klasy - czyli jedną konkretną mapę, która moŋe pasowaæ do rzeczywistej ķcieŋki dobrze, lub moŋe nie. Jeķli mapa dobrze pasuje, moŋemy uŋyæ jej jako uŋytecznej pomocy, aby pomóc nam modelowaæ ķrodowisko i przewidywaæ na jego temat. Jednak uŋycie terminu "ķrodowisko" wywoģuje myķl mentalną, ŋe jesteķmy w stanie go w jakiķ sposób przeszukaæ, co moŋe powodowaæ zamieszanie. Jeķli uŋyjemy analogii mapy topograficznej, moŋliwe jest mniejsze zamieszanie w porównaniu z tymi dwoma rodzajami wyszukiwania, które są moŋliwe - z których jednym jest poszukiwanie dobrego modelu ķrodowiska lub tego, co dzieje się w ķrodowisku, a drugie to poszukiwanie samo ķrodowisko. Oznaczymy te dwa rodzaje wyszukiwania w następujący sposób: wyszukiwanie map i wyszukiwanie eksploracji (lub po prostu "mapowanie" i "eksploracja"), aby podkreķliæ analogie tworzone z ich rzeczywistymi odpowiednikami. Podczas eksploracji agent moŋe odwoģywaæ się do mapy podczas wykonywania wyszukiwania. Mapa moŋe, ale nie musi byæ dobrym odzwierciedleniem tego, co istnieje w ķrodowisku w czasie wykonywania nawigacji. Dlatego agent musi nieustannie poprawiaæ lub aktualizowaæ swoją wewnętrzną mapę, aby osiągnąæ postęp do jej celu. Koncepcyjnie mapy mogą byæ uŋywane do reprezentowania wielu róŋnych rodzajów wiedzy, nie tylko wiedzy topograficznej, poniewaŋ mapy mogą byæ uŋywane do wizualizacji wiedzy reprezentowanej przez wielowymiarowe dane w n-wymiarowym ķrodowisku przestrzeni. Jednym z takich przykģadów są diagramy Venna opracowane przez Johna Venna okoģo roku 1880. Diagramy Venna zapewniają sposób reprezentowania logicznych relacji między zestawami, gdzie regiony na wykresie reprezentują zbiory lub klasy, a obszary nakģadające się - przecięcia między zestawami. Regiony te moŋna zidentyfikowaæ za pomocą etykiet, jak pokazano na rysunku
Diagram Venna na tej figurze przedstawia wiedzę dotyczącą czterech zwierząt z ogrodów zoologicznych, gepardów, tygrysów, zebry i ŋyraf, niezaleŋnie od tego, czy są to ssaki, zwierzęta mięsoŋerne, czy zwierzęta kopytne, oraz cech, które je odróŋniają, na przykģad od tego, czy zwierzęta mają ciemne plamy, ciemnobrązowy kolor czy dģuga szyja. Chociaŋ na diagramie przedstawiono przedstawione są miejsca występowania pojęæ takich jak ssaki i ich logiczne relacje zamiast tradycyjnych cech geograficznych, takich jak kraje, drogi i miejsca, podobnie jak w przypadku mapy poģudniowej w Central Parku i na ķwiecie, moŋna ją jednak uznaæ za mapa w sensie topologicznym. Istnieje równieŋ oczywista korelacja między tym sposobem reprezentowania wiedzy a podejķciem do przestrzeni koncepcyjnych Gärdenfors
Reprezentowanie wiedzy za pomocą map zdarzeņ
Tematem caģego tomu byģo wykorzystanie map do przedstawiania tego, co dzieje się w róŋnych ķrodowiskach, zarówno rzeczywistych, wirtualnych, jak i abstrakcyjnych (tj. N-wymiarowe ķrodowisko kosmiczne). Omawiając róŋne metody reprezentowania wiedzy (takie jak reguģy, logika, ramki i drzewa decyzyjne) w kolejnych sekcjach, kaŋdą z metod moŋna uwaŋaæ za analogiczną do procesu reprezentowania topograficznego terenu za pomocą map. Model NetLogo, który zostaģ opracowany w celu zilustrowania i porównania róŋnych modeli, modelu reprezentacji wiedzy, wykorzystuje ķrodowisko wyķwietlania NetLogo do wizualizacji w dwóch wymiarach wiedzy dotyczącej kaŋdego z trzech problemów z zabawkami. Jak wspomniano powyŋej, wizualizacje te mogą byæ uwaŋane za jako mapy abstrakcyjnego ķrodowiska, które reprezentuje opisywaną wiedzę. Aby pomóc w wizualizacji róŋnych typów reprezentacji wiedzy, model reprezentacji wiedzy korzysta z kodu NetLogo, który byģ równieŋ uŋywany w przypadku wydarzeņ następujących po Wall. oraz modele zdarzeņ modelowania języka. Przeksztaģca róŋne formy reprezentacji wiedzy w ramach wspólnej struktury opartej na "zdarzeniach", gdzie zdarzenie moŋe byæ wydarzeniem zmysģowym (dane wejķciowe od jednego ze zmysģów), wydarzeniem motorycznym (ruch ciaģa agenta) lub wydarzeniem abstrakcyjnym ( poģączenie zdarzeņ zmysģowych, motorycznych lub abstrakcyjnych). Podejķcie jest podobne do podejķcia przyjętego dla przetwarzania strumienia zdarzeņ (ESP) i zģoŋone przetwarzanie zdarzeņ (CEP). Ramy stosowane tutaj uwaŋają, ŋe agent jednoczeķnie rozpoznaje i przetwarza wiele strumieni zdarzeņ, które odzwierciedlają to, co dzieje się z samym sobą i otoczeniem. Kaŋde zdarzenie jest reprezentowane przez stan w skoņczonym komputerze stanu, który jest oznaczony nazwą strumienia, po którym następuje nazwa zdarzenia. Przejķcia między stanami nie są oznaczone - po prostu wskazują, ŋe jedno zdarzenie następuje po drugim. Zdarzenia występują w okreķlonej kolejnoķci (ķcieŋce) zdefiniowanej przez przejķcia stanu przez sieæ zdarzeņ. Jeķli okreķlone zdarzenie nie występuje po innym zdarzeniu, wówczas nie ma szczególnego przejķcia między stanami, a zatem zdarzenie to nie jest rozpoznawane przez agenta (tj. Jest ignorowane i nie ma wpģywu na zachowanie agenta). Przetwarzanie zdarzeņ odbywa się w sposób reaktywny - to znaczy, ŋe okreķlona ķcieŋka przechodzi przez sukcesywne dopasowywanie zdarzeņ, które obecnie występują do agenta, w stosunku do wychodzących przejķæ z kaŋdego węzģa. Jeķli nie ma ŋadnych przejķæ wychodzących lub ŋadne nie pasują, ķcieŋka jest ķlepym zauģkiem, w którym to momencie traversal się zatrzyma. Odbywa się to jednoczeķnie dla kaŋdego zdarzenia; innymi sģowy, istnieje wiele punktów początkowych, a zatem jednoczesne aktywacje w caģej sieci. Moŋemy uznaæ, ŋe sieæ jest "mapą zdarzeņ" - stany reprezentują punkty w przestrzeni n-wymiarowej, a wielowymiarowoķæ punktów w przestrzeni jest zredukowana do dwóch wymiarów. Odbywa się to przez to, ŋe kaŋdy stan reprezentuje jeden wymiar i jego wartoķæ, a następnie zapewnia ģącza do dalszych stanów wzdģuŋ uporządkowanej ķcieŋki przez stany reprezentujące kaŋdy z pozostaģych wymiarów. Redukcja z N-wymiarowa przestrzeņ do dwuwymiarowej przestrzeni dla wizualizacji dodaje dalsze informacje, poniewaŋ narzuca konkretny porządek wymiarów wyznaczony przez ķcieŋki, aby osiągnąæ stan koņcowy, który reprezentuje punkt wielowymiarowy. Trójwymiarowy punkt, reprezentowany przez krotkę (D1 = wartoķæ1, D2 = wartoķæ2, D3 = wartoķæ3) moŋna na przykģad przedstawiæ na mapie zdarzeņ jako trzy poģączone stany o etykietach [D1 = wartoķæ1], [D2 = wartoķæ2] i [D3 = wartoķæ3], przy czym trzeci stan odpowiada trójwymiarowi. punkt, ale osiągalny tylko przez dwa poprzednie stany. Ta specyficzna kolejnoķæ wymiarów nie istniaģa z oryginalnymi danymi n-wymiarowymi. Jednakŋe stany drogi są ze sobą powiązane, daje nam szansę reprezentowania rentownoķci okreķlonej ķcieŋki - w podobny sposób, jak realny zestaw ķcieŋek ģączących ze sobą dwie lokalizacje, takie jak Fontanna Bethesda i Koģo Kolumba na mapie South Central Park. Nie ma teŋ powodu, abyķmy nie mogli reprezentowaæ alternatywnych ķcieŋek na mapie zdarzeņ z innymi ķcieŋkami, które nie zostaģy zilustrowane jako po prostu ignorowane. Podczas korzystania z prawdziwej mapy do nawigacji, takiej jak mapa South Central Park, dana osoba często tworzy "mentalną mapę" w swoim umyķle, która jest uproszczeniem z rzeczywistej mapy sposobu wykonywania nawigacji. Na przykģad, rzut oka na rysunek 9.5 pokaŋe, ŋe najprostszą drogą pomiędzy Zoo a Stawem Ģodzi jest wyjķcie w kierunku najbliŋszych wieŋowców na 65. Ulicę, skręcanie w lewo, następnie kontynuowanie aŋ do 74. ulicy, a następnie skręt w lewo do parku. Ta mentalna mapa koncentruje się na zadaniu w ręku - jak najlepiej dotrzeæ do Stawu Ģodzi - i ma znacznie mniej szczegóģów i mniejszą dokģadnoķæ niŋ rzeczywiste mapy, ale wciąŋ jest wystarczająco dobra, aby pomóc osiągnąæ cel. Reprezentację mapy mentalnej tego odwzorowania na mapie zdarzeņ pokazano na rysunku
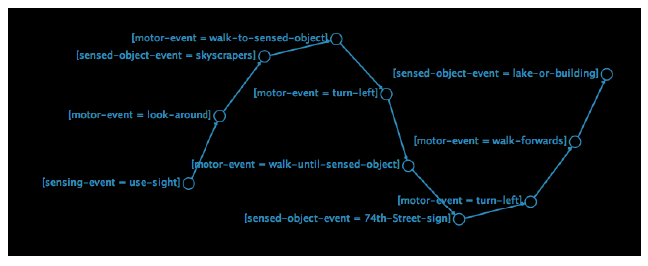
Mapa zdarzeņ przedstawia uporządkowaną sekwencję zdarzeņ, które muszą wystąpiæ przed osiągnięciem celu dotarcia do Stawu Ģodzi. Ta sekwencja zakoņczy się sukcesem niezaleŋnie od punktu początkowego w ZOO, dopóki agent będzie zmierzaæ w kierunku najbliŋszych wieŋowców i nie będzie wymagaæ, aby agent ustaliģ jej aktualną orientację względem póģnocy. Mapa zdarzeņ wiedzy dla problemu klasyfikacji Zoo Zoo jest pokazana na rysunku
Wiedza w tym przypadku jest okreķlona jako drzewo decyzyjne. Na rysunku przedstawiono sieæ zdarzeņ rozwijających się z centralnego stanu z prawej o nazwie animal = "Tak". Róŋne węzģy liķci są stanami reprezentującymi, kiedy okreķlony typ zwierzęcia zostaģ rozpoznany, na przykģad drapieŋnik (ķrodkowe dno) lub kopytny (np. Ķrodkowy wierzchoģek), lub okreķlone zwierzę, takie jak gepard (u góry po lewej) lub ŋyrafa (u doģu po prawej) . Stany te reprezentują wielowymiarowe punkty w przestrzeni n-wymiarowej, które reprezentują pojęcia "mięsoŋerca", "ungulate", "gepard" i "ŋyrafa", podobnie jak w przestrzeniach koncepcyjnych Gärdenforsa. Teraz jest juŋ jasne, dlaczego ta reprezentacja jest nazywana "mapą" zdarzenia - tak jak mapa topograficzna przedstawia trójwymiarowy teren w 2D, mapa zdarzeņ reprezentuje równieŋ punkty w przestrzeni n-wymiarowej w 2D. Model NetLogo oparty na reprezentacji wiedzy wygenerowaģ tę konkretną mapę zdarzeņ, ustawiając interfejs wyboru interfejsu KR na "drzewo decyzyjne", a selektor interfejsu wyboru "problem" na "zwierzęta z zoo". Moŋemy animowaæ mapy zdarzeņ, pokazując, w jaki sposób agenci poruszają się po mapie podczas wnioskowania, podobnie w jaki sposób animowane są algorytmy przeszukiwania w częķciach 7 i 8. Poniŋej znajduje się opis bardziej tradycyjnych form reprezentacji wiedzy, ale z ucieleķnionej, usytuowanej perspektywy za pomocą mechanizmu mapowania zdarzeņ do wizualizacji wiedzy i animowania procesu rozumowania wiedzy.
Reprezentowanie wiedzy za pomocą reguģ i logiki
Klasyczne metody reprezentowania wiedzy uŋywają reguģ lub logiki. Tabela przedstawia wiedzę na temat problemu zwierząt w zoo w dwóch formatach - za pomocą reguģ po lewej stronie, zaimplementowanych w modelu NetLogo opartym na wiedzy i przy uŋyciu logiki pierwszego rzędu po prawej.
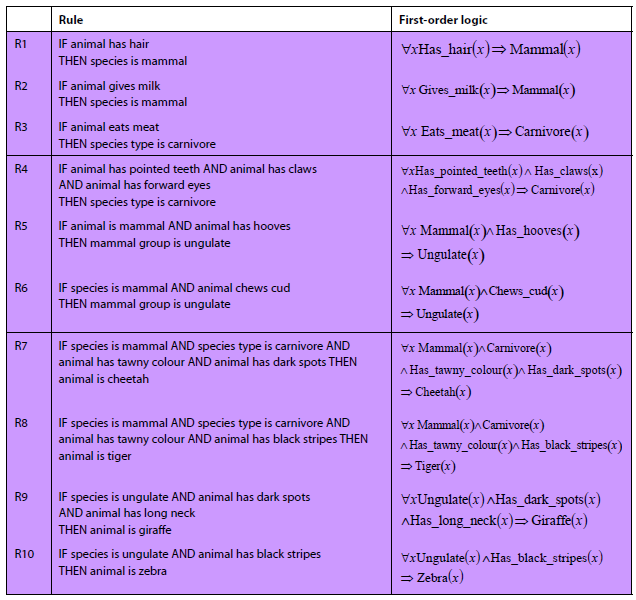
Reguģy są często uŋywane w systemach eksperckich opartych na reguģach i są albo wyražnie okreķlone przez inŋyniera wiedzy (zwykle w procesie zwanym "pozyskiwaniem wiedzy" od eksperta czģowieka), albo pochodzą z danych przy uŋyciu algorytmu uczenia maszynowego lub algorytmu eksploracji danych . Reguģy wykorzystują logiczną formę do wnioskowania. Logika jest uŋyciem technik symbolicznych i matematycznych do rozumowania dedukcyjnego, a wywodzi się z dyscypliny Arystotelesa. Oparta na reguģach metoda reprezentacji wiedzy uŋywa reguģ IF-THEN (nazywanych czasami reguģami warunkowania) w celu okreķlenia wiedzy. Wszystkie zasady dotyczące okreķlonego problemu tworzą podstawę reguģ, a baza wiedzy obejmuje trzy elementy: listę reguģ w bazie reguģ; lista znanych faktów w bazie faktów; i system inferencji, który przetwarza reguģy, aby wyprowadziæ nowe fakty za pomocą jakiejķ formy rozumowania. Reguģa skģada się z częķci IF, która jest zbiorem warunków (zwanych antecedentami), które muszą zostaæ speģnione zanim zasada zostanie okreķlona jako "ogieņ", aby wykonaæ zestaw czynnoķci w TEJ częķci (zwanej następnikami). Na przykģad w przypadku reguģy R1 w tabeli 9.5, jeķli speģniony jest warunek "zwierzę ma wģosy" - to znaczy, ŋe w bazie wiedzy jest znany fakt, ŋe zwierzę klasyfikowane ma wģosy, to zasada jest zwalniana, a dziaģanie jest dodanie do bazy wiedzy kolejnego "gatunku ssaka". W częķci IF reguģy moŋe występowaæ wiele warunków. Na przykģad reguģa R4 ma trzy warunki, które muszą zostaæ speģnione, zanim będzie moŋna wystrzeliæ. Warunki te są oddzielone sģowem kluczowym AND i dlatego te warunki są nazywane "spójnikami". Jeķli zostaģyby rozdzielone sģowem kluczowym OR, nazwano by je "disjunctions". W przypadku modelu NetLogo opartego na reprezentacji wiedzy reguģy dotyczą tylko koniunkcji zostaģy wdroŋone. Zestaw reguģ i sposób ich zdefiniowania dla problemu zwierząt w zoo i Nowej Zelandii pokazano w Kodzie NetLogo
if (select-problem = "Zoo animals")
[
setup-rule ;; rule: IF animal has hair
;; THEN species is mammal
[["has hair" "Yes"]]
[["species" "mammal"]]
setup-rule ;; rule: IF animal gives milk
;; THEN species is mammal
[["gives milk" "Yes"]]
[["species" "mammal"]]
setup-rule ;; rule: IF animal eats meat
;; THEN species type is carnivore
[["eats meat" "Yes"]]
[["species type" "carnivore"]]
setup-rule ;; rule: IF animal has pointed teeth AND animal has claws
;; AND animal has forward eyes
;; THEN species type is carnivore
[["has pointed teeth" "Yes"] ["has claws" "Yes"]
["has forward eyes" "Yes"]]
[["species type" "carnivore"]]
setup-rule ;; rule: IF animal is mammal AND animal has hooves
;; THEN mammal group is ungulate
[["species" "mammal"] ["has hooves" "Yes"]]
[["species type" "ungulate"]]
setup-rule ;; rule: IF species is mammal AND animal chews cud
;; THEN mammal group is ungulate
[["species" "mammal"] ["chews cud" "Yes"]]
[["species type" "ungulate"]]
setup-rule ;; rule: IF species is mammal
;; AND species type is carnivore
;; AND animal has tawny colour
;; AND animal has dark spots
;; THEN animal is cheetah
[["species" "mammal"] ["species type" "carnivore"]
["has tawny colour" "Yes"] ["has dark spots" "Yes"]]
[["animal" "cheetah"]]
setup-rule ;; rule: IF species is mammal
;; AND species type is carnivore
;; AND animal has tawny colour
;; AND animal has black stripes
;; THEN animal is tiger
[["species" "mammal"] ["species type" "carnivore"]
["has tawny colour" "Yes"] ["has black stripes" "Yes"]]
[["animal" "tiger"]]
setup-rule ;; rule: IF species is ungulate AND animal has dark spots
;; AND animal has long neck
;; THEN animal is giraffe
[["species type" "ungulate"] ["has dark spots" "Yes"]
["has long neck" "Yes"]]
[["animal" "giraffe"]]
setup-rule ;; rule: IF species is ungulate
;; AND animal has black stripes
;; THEN animal is zebra
[["species type" "ungulate"] ["has black stripes" "Yes"]]
[["animal" "zebra"]]
]
if (select-problem = "New Zealand birds")
[
setup-rule ;; rule: IF bird can fly AND bird is a parrot
;; AND bird is alpine
;; THEN bird is a kea
[["can fly" "Yes"] ["parrot" "Yes"] ["alpine" "Yes"]]
[["bird" "Kea" ]]
setup-rule ;; rule: IF bird can fly AND bird is a parrot
;; AND bird is not alpine
;; THEN bird is a kaka
[["can fly" "Yes"] ["parrot" "Yes"] ["alpine" "No"]]
[["bird" "Kaka"]]
setup-rule ;; rule: IF bird can fly AND bird is not a parrot
;; AND bird has white throat
;; THEN bird is a tui
[["can fly" "Yes"] ["parrot" "No"] ["has white throat" "Yes"]]
[["bird" "Tui"]]
setup-rule ;; rule: IF bird can fly AND bird is not a parrot
;; AND bird does not have a white throat
;; THEN bird is a pukeko
[["can fly" "Yes"] ["parrot" "No"] ["has white throat" "No"]]
[["bird" "Pukeko"]]
setup-rule ;; rule: IF bird cannot fly AND bird is an extinct bird
;; AND bird is large
;; THEN bird is a moa
[["can fly" "No"] ["extinct" "Yes"] ["large" "Yes"]]
[["bird" "Moa"]]
setup-rule ;; rule: IF bird cannot fly AND bird is extinct
;; AND bird is not large
;; THEN bird is a huia
[["can fly" "No"] ["extinct" "Yes"] ["large" "No"]]
[["bird" "Huia"]]
setup-rule ;; rule: IF bird cannot fly AND bird is not extinct
;; AND bird has long beak
;; THEN bird is a kiwi
[["can fly" "No"] ["extinct" "No"] ["has long beak" "Yes"]]
[["bird" "Kiwi"]]
setup-rule ;; rule: IF bird cannot fly AND bird is not extinct
;; AND bird does not have a long beak
;; THEN bird is a weta
[["can fly" "No"] ["extinct" "No"] ["has long beak" "No"]]
[["bird" "Weta"]]
]
Reguģy są definiowane za pomocą procedury reguģy ustawiania, która jest wymieniona w poniŋszym kodzie NetLogo.
breed [rules rule]
rules-own
[
antecedents ; if part of rule - list of necessary propositions for
; rule to be true consequents ; then part of rule - list of propositions that are
; the conclusions of the rule
]
to setup-rule [alist clist]
;; Creates a new rule with the specified antecedents (alist)
;; and consequents (clist)
create-rules 1
[ hide-turtle ; make invisible
set antecedents alist
set consequents clist ]
end
Reguģy są zdefiniowane jako oddzielny typ agentów, które zawierają dwie zmienne: poprzednicy, która jest listą niezbędnych zdaņ lub faktów, aby reguģa byģa prawdziwa (jest to częķæ IF reguģy); i następniki, które są listą wniosków (to jest TO częķæ zasady). Procedury setup-rule pobiera dwie listy zdaņ jako argumenty - alist jako listę poprzedzających i clist jako listę następników. Propozycje są reprezentowane za pomocą dwuelementowej listy, która zawiera atrybut i jego wartoķæ. Ta lista dwuelementowa moŋe zostaæ przekonwertowana na opis angielski poprzez wstawienie "is" między dwoma elementami na liķcie. Na przykģad lista ["moŋe lataæ" "Tak"] reprezentuje propozycję "moŋe lataæ to Tak"; to jest propozycja, ŋe ptak moŋe lataæ. Podobnie, lista ["typ gatunku" "ssak"] jest twierdzeniem, ŋe typem gatunku dla zwierzęcia jest ssak. Okreķlenie reguģ w tym formacie pozwala nam na ich wizualizację za pomocą map zdarzeņ. Reprezentacja Wiedzy robi to, wykorzystując procedurę dodawania zdarzeņ, jak pokazano w NetLogo Code
to add-rule-to-event-map [this-rule]
; adds the rule as a set of linked states to the event map network
let events []
foreach [consequents] of this-rule
[
set events lput ? ([antecedents] of this-rule)
vadd-events events white white white
]
end
to setup-rules-event-map [problem]
;; setups an event map network of states from the rules
foreach sort rules
[
add-rule-to-event-map ?
]
repeat 5 [ change-layout ]
display
end
Procedura add-rule-to-event-map dodaje jako listę zdarzeņ do mapy zdarzeņ listę poprzedników w okreķlonej regule dla kaŋdego z jej następników. Dodaje on konkretny wynik jako zdarzenie na koņcu listy poprzedzających, tak, ŋe konsekwencja zakoņczy się na koņcu ķcieŋki na mapie zdarzeņ. Reguģy instalacyjne-event-map robi to dla wszystkich reguģ. Proces ten będzie oznaczaģ, ŋe reguģy z typowymi poprzednikami trafią do tej samej gaģęzi. Wynik dla problemu ptaków nowozelandzkich pokazano na rysunku
Ta metoda wizualizacji reguģ pozwala nam dostrzec związki między reguģami - pokazuje, ŋe reguģy dzielą się na dwie sieci, jak na rysunku, z ptakami, które moŋe lataæ po prawej, a ptaki po lewej nie. Zasady te moŋna ģatwo przeksztaģciæ w logikę pierwszego rzędu. Na przykģad zasady pokazane po lewej w tabeli powyŋej są równieŋ okreķlone jako "zdania" w logice pierwszego rzędu po prawej stronie. Zdania w logice pierwszego rzędu reprezentują stwierdzenia o ķwiecie zawierającym obiekty o okreķlonych wģaķciwoķciach. Zdania mogą skģadaæ się z wielu skģadników: staģych symboli, które odnoszą się do okreķlonego obiektu na ķwiecie; terminy będące wyraŋeniami logicznymi odnoszącymi się do okreķlonego obiektu; symbole predykatów odnoszące się do okreķlonej relacji (takie jak "Has_hair" i "Mammal"); logiczne poģączenia ?, ?, ? i ? (wymawiane jako "implikuje", "i", "lub" i "jest równoznaczne z" odpowiednio "); kwantyfikator uniwersalny pron (wymawiane jako "dla wszystkich"); i kwantyfikator egzystencjalny ? (wymawiane jako "istnieje"). Na przykģad wyraŋenie "Wszystkie ssaki mają wģosy" moŋe byæ przedstawione w logice pierwszego rzędu za pomocą zdania ?x Has_hair (x) ?Mammal (x). To zdanie moŋna odczytaæ jako "dla wszystkich x, jeķli x ma wģosy, to oznacza, ŋe x jest ssakiem". Kwantyfikator uniwersalny sģuŋy do stwierdzenia, ŋe ogólny stan zachowuje się dla wszystkich obiektów na ķwiecie, a kwantyfikator egzystencjalny sģuŋy do stwierdzenia okreķlonego warunku dla co najmniej jednego obiektu na ķwiecie. Symbol ? sģuŋy do stwierdzenia implikacji (reguģy), z zaģoŋeniem lub poprzednikami po lewej stronie symbolu, a takŋe wnioskami lub poprzednikami z prawej strony symbolu. Symbol równowaŋnoķci (?) okreķla, ŋe lewa strona symbolu jest odpowiednikiem prawej strony symbolu. Negacja jest okreķlona za pomocą - symbolu (wymawiane "nie").
Powody uŋywania reguģ i logiki
Moŋemy wykorzystaæ wiedzę okreķloną przez reguģy i zdania logiczne do wnioskowania nowej wiedzy w procesie zwanym rozumowaniem. Istnieją róŋne "reguģy wnioskowania", które pozwalają nam to zrobiæ. Na przykģad, jeķli wiemy, ŋe zwierzę A1 ma wskazane zęby, ma skierowane do przodu oczy i ma szpony, tj. Has_pointed_teeth (A1) i Has_forward_eyes (A1) i Has_claws (A1) są prawdziwe, to moŋemy wywnioskowaæ z reguģy R4, ŋe zwierzę A1 jest drapieŋnikiem, tj. Carnivore (A1) Ta szczególna zasada wnioskowania nazywa się "Modus Ponens" lub eliminacją Imienia, poniewaŋ tworzy nowe zdanie poprzez usunięcie symbolu implikacji, ?. Zasady te są oczywiste i wynikają bezpoķrednio z znaczenia róŋnych symboli. Na przykģad zasada Modus Ponens wynika bezpoķrednio ze znaczenia symbolu ?. Zasady Eliminacji i Wprowadzania, Wprowadzania i Eliminacji Podwójnej Negacji wynikają bezpoķrednio ze znaczeņ symboli ?, ? i -. Podobnie pozostaģe trzy reguģy wynikają z znaczenia symboli ? i ?. Dalsze zasady i więcej szczegóģów moŋna znaležæ w Russell i Norvig. Na początku odnotowano pewne obserwacje dotyczące zwierząt obserwowanych na afrykaņskiej sawannie. Celem jest ustalenie, które zwierzę jest obserwowane. Dowód zaczyna się od konwersji obserwacji w formę logiczną pierwszego rzędu przy uŋyciu egzystencjalnego kwantyfikatora (P1). P2 do P5 uŋywa eliminacji egzystencjalnej do wnioskowania indywidualnych predykatów dotyczących zwierzęcia oznaczonego jako A1. Pozostaģa częķæ dowodu wykorzystuje Universal Elimination i Modus Ponens, aby dojķæ do wniosku, ŋe zwierzę to zebra - to znaczy, ŋe Zebra (A1) okazaģa się prawdziwa. W Knowledge Representation kliknięcie przycisku go-reasoning rozpoczyna proces wnioskowania. Jeķli suwak KR-type jest ustawiony na "rules", uŋytkownik zostanie poproszony o wybranie typu rozumowania, którego chce uŋyæ - do przodu lub do tyģu. Oba te typy rozumowania uŋywają wyszukiwania zbadaæ n-wymiarową przestrzeņ, która reprezentuje wiedzę. Ta n-wymiarowa przestrzeņ jest pokazana na mapie zdarzeņ przedstawionej w ķrodowisku NetLogo po kliknięciu przycisku "setup - knowledge" w interfejsie . Gdy proces wnioskowania przebiega,mapa wydarzeņ jest animowana przez agrafki przedstawione za pomocą ksztaģtu osoby (w ten sam sposóbŋe przedstawiano agentów walkerów badających przestrzenie wyszukiwania związane z róŋnymi problemami wyszukiwania). Ta animacja procesu wnioskowania wyražnie wzmacnia analogię rozumowania jako proces wyszukiwania.Rysunek 9.10 zawiera dwa zrzuty ekranu pokazujące, jak to wygląda w przypadku problemu klasyfikacji ptaków nowozelandzkich.
Obraz po lewej pokazuje zrzut ekranu po zakoņczeniu wnioskowania do przodu, co doprowadziģo do wniosek, ŋe klasyfikowany ptak to Kea. Zrzut ekranu pokazuje ķcieŋkę procesu wnioskowania osiągnąģ cel, uŋywając grubszych linków. W tym przypadku ķcieŋka byģa bezpoķrednia. Pierwszy odwiedzony stan byģ stan [can fly = "Yes"] w ķrodkowym prawym rogu obrazu. Powoduje to następujące pytanie uŋytkownika - "Czy ptak moŋe lataæ?". Ķcieŋka przechodzi następnie do następnego stanu oznaczonego [parrot = "Yes"]. Widaæ to po tym, ŋe ģącze jest nieco szersze niŋ inne ģącza, które nie zostaģy przetestowane. Pada pytanie "Czy ptak to papuga?". Ķcieŋka następnie przechodzi do stanu oznaczonego [alpine = "Yes"], który generuje pytanie "Czy ptak jest ptakiem alpejskim?". Ostatecznie ķcieŋka koņczy się na stanie koņcowym oznaczony [bird = "Kea"], który jest stanem docelowym, a zatem wniosek jest taki ptak to Kea. Ta ķcieŋka jest przestrzegana, poniewaŋ dopasowywana jest jedna reguģa - w tym przypadku reguģą jest pierwszą reguģą w bazie wiedzy zdefiniowanej we wczeķniejszym NetLogo Code, z listą poprzedników ["can fly" "Tak"] ["parrot" "Tak"] ["alpine" "Tak"] i kolejne listy ["bird" "Kea"]. Obraz po prawej stronie na rysunku pokazuje, jak przebiega rozumowanie wstecz. Na początku uŋytkownik jest pytany, który cel chce udowodniæ. Jeķli uŋytkownik wybierze [bird kea], agent spacerowy zostanie narysowany w stanie oznaczonym [bird = "Kea"], aby pokazaæ, ŋe jest to stan celu. Proces rozumowania następnie próbuje udowodniæ cel, zadając te same pytania, co w przypadku dalszego procesu wnioskowania. Na obrazie ķcieŋka zostaģa przetransportowana aŋ do stanu [alpine = "Yes"], a jeszcze jedno ģącze, które trzeba przejķæ, potrzebne do udowodnienia celu. Obraz prawej ręki na rysunku pokazuje, jak przebiega rozumowanie wstecz. Na początku uŋytkownik jest pytany, który cel chce udowodniæ. Jeķli uŋytkownik wybierze [bird kea], agent spacerowy zostanie narysowany w stanie oznaczonym [bird = "Kea"], aby pokazaæ, ŋe jest to stan celu. Proces rozumowania następnie próbuje udowodniæ cel, zadając te same pytania, co w przypadku dalszego procesu wnioskowania. Na obrazie ķcieŋka zostaģa przetransportowana aŋ do stanu [alpine = "Yes"], a jeszcze jedno ģącze, które trzeba przejķæ, potrzebne do udowodnienia celu. Ten konkretny przykģad jest stosunkowo prosty. W przypadku bardziej skomplikowanego przykģadu, takiego jak klasyfikowanie zwierzęcia z zoo jako geparda, proces wnioskowania spowoduje animację przeskakującą wokóģ mapy zdarzenia. W szczególnoķci proces przekazywania argumentów moŋe spowodowaæ, ŋe wiele zapytaņ zostanie zapytanych, zanim dojdzie do wniosku, jak pokazano na rysunku
W przypadku rozumowania naprzód, proces rozpoczyna się od znanych faktów i postępuje naprzód, próbując znaležæ reguģę w bazie reguģ, dla której poprzednicy pasują do faktów. Za kaŋdym razem, gdy reguģa się zgadza, jest "wystrzeliwana", a następniki dodawane są do bazy wiedzy jako nowe fakty. Reguģa moŋe byæ dopasowana tylko pewnego razu. Peģny cykl "match-fire" ma miejsce, gdy wszystkie reguģy w bazie reguģ zostaģy przetworzone. Jeķli co najmniej jedna reguģa zostaģa uruchomiona, rozpoczyna się nowy cykl przy pierwszej regule bazy reguģ. Proces trwa, dopóki w cyklu nie zostaną uruchomione ŋadne inne reguģy. Kod, który to wykonuje, jest pokazany w NetLogo
to go-rules-forward-reasoning
;; dokonuje dalszego rozumowania problemu
let fired-count length fired-rules
print selected-problem
let goal-attrib [goal-attribute] of selected-problem
set cycle-count cycle-count + 1
output-number "Cycle " cycle-count
loop
[
foreach sort rules
[ ; dla kaŋdej reguģy w bazie reguģ
if not member? ? fired-rules
[
if (match-rule? selected-problem ?)
[
fire-rule ?
output-fired-rule ? ]
if (attribute-found? goal-attrib)
[ user-message (word "The " goal-attrib " is a "
fact-get goal-attrib ".")
stop ]
]
]
if (fired-count = length fired-rules)
[ user-message
"No new rules fired this cycle. Sorry - I can't help you."
stop ]
]
end
Procedura go-rules-forward-reasoning ma pętlę, która wykonuje cykl dopasowywania ognia. Ta pętla przetwarza w porządku posortowanym kaŋdą reguģę w bazie reguģ (tj. zestaw rules agentów ). Najpierw sprawdza, czy reguģa zostaģa wczeķniej uruchomiona, a jeķli nie, to próbuje dopasowaæ reguģę, wywoģując reguģę dopasowania? reporter (pokazany w kodzie NetLogo). Jeķli ten reporter zwróci wartoķæ true, uruchomi reguģę, wywoģując procedurę reguģy ognia. Procedura output-fired-rule wyķwietli informacje w obszarze Output w interfejsie jako ķlad procesu wnioskowania, jeķli przeģącznik trace-on zostaģ ustawiony na On.
to-report match-rule? [problem this-rule]
; tries to match this-rule to facts in the facts-base
; otherwise asks user for data if attribute is not in non-input-attributes list
let attribute ""
let val ""
let value ""
let question ""
let choices []
let this-walker nobody
set this-walker start-new-walker nobody "" ""
foreach [antecedents] of this-rule
[
set attribute first ?
set value last ?
update-walker this-walker attribute value
if not attribute-found? attribute
; not found, so need to ask user if we can
[ ifelse (member? attribute [non-input-attributes] of problem)
[ report false ] ; no we can't ask user
[ ; zadaj uŋytkownikowi pytanie
set question get-input-question problem attribute value
set choices get-input-choices problem attribute
set val user-one-of question choices
fact-put attribute val
]
]
if not fact-found? attribute value
[ report false ]
]
report true
end
to fire-rule [this-rule]
; odpala dopasowaną reguģę ta zasada
let attribute ""
let value ""
let new-walker nobody
foreach [consequents] of this-rule
[
set attribute first ?
set value last ?
ask active-walker
[ hatch-walkers 1 [ set new-walker self ]] ; klon aktywnego chodzika
update-walker new-walker attribute value
fact-put attribute value
set fired-rules fput this-rule fired-rules
]
end
Reporter match-fire? przetwarza kaŋdy z poprzedników reguģy. Najpierw wyodrębnia atribute i jego value z bieŋącego elementu na poprzedniej liķcie; na przykģad dla ["can fly" "Yes"], atrybut "can fly", a wartoķæ to "Yes". Attribute w poģączeniu z jego value reprezentuje konkretną propozycję, która musi byæ prawdziwa - w tym przypadku propozycja, ŋe ptak moŋe lataæ. Reprezentując propozycję jako zdarzenie w mapie zdarzeņ, nazwa strumienia jest ustawiona na attribute, a zdarzenie, które występuje w strumieniu, jest ustawione na value. Reporter match-fire? sprawdza następnie, czy wartoķæ atrybutu nie zostaģa jeszcze przydzielona wartoķci w bazie faktów. Jeķli nie, zapyta uŋytkownika, jaka jest wartoķæ, jeķli atrybut jest atrybutem wejķciowym. Potem wreszcie zgģosi się reporter aby sprawdziæ, czy wartoķæ atrybutu jest zgodna z wartoķcią okreķloną przez reguģę. Procedura fire-rule przetwarza kaŋdy z następstw reguģy. Najpierw wykluwa nowy odtwarzacz, który przechodzi do nowego stanu zdarzenia w mapie zdarzeņ opartej na update-walker. Odbywa się to w celu animacji wizualizacji mapy zdarzeņ, aby pokazaæ, jak przebiega proces wnioskowania. Następnie procedura wprowadza nowy fakt skģadający się z atrybutu i jego wartoķci do podstawy faktów, a na koniec, dodaje reguģę do listy uruchomionych reguģ, aby nie wystartowaæ ponownie. Baza faktów jest zaimplementowana przy uŋyciu rozszerzenia tabeli, jak pokazano w kodzie NetLogo
to-report attribute-found? [attribute]
; zgģasza wartoķæ true, jeķli atrybut znajduje się w bazie danych faktów
; zgģasza faģsz inaczej
report (table:has-key? facts-base attribute)
end
to-report fact-found? [attribute value]
; zgģasza wartoķæ true, jeķli atrybut i wartoķæ znajdują się w bazie danych faktów
; zgģasza faģsz inaczej
report (value = table:get facts-base attribute)
end
to-report fact-get [attribute]
; pobiera wartoķæ powiązaną z atrybutem z bazy faktów.
report table:get facts-base attribute
end
to fact-put [attribute value]
; umieszcza parę wartoķci atrybutu w bazie faktów.
table:put facts-base attribute value
end
Kod implementuje trzy reportery: attribute-found?, który zgģasza prawdę, jeķli sam atrybut znajduje się w bazie faktów (tj. niezaleŋnie od tego, jaka wartoķæ jest z nim związana); fact-found?, który zgģasza prawdę, jeķli zarówno atrybut, jak i okreķlona wartoķæ znajduje się w bazie faktów; i fact-get, który zwraca wartoķæ powiązaną z atrybutem. Procedura fact-put wstawia konkretny atrybut i jego wartoķæ do tabeli. Problem z dalszym rozumowaniem polega na tym, ŋe poszukiwanie konkretnego celu moŋe byæ nieskuteczne, poniewaŋ moŋe wywoģaæ wiele reguģ niezwiązanych z celem. W takim przypadku bardziej odpowiednie moŋe byæ rozumowanie oparte na wstecznym lub celowym. Rozumowanie odwrotne wykorzystuje proces "znajdowania dowodów", a nie proces "zapaģek", jak w przypadku rozumowania wybiegowego. Biorąc pod uwagę konkretny cel, proces wnioskowania wstecznego najpierw przeszukuje bazę reguģ, aby znaležæ reguģy, które mają cel w swoich NAWET częķciach (tj. Jako następniki). Jeķli zostanie znaleziona reguģa i częķæ IF zostanie dopasowana, wówczas reguģa zostanie zwolniona, a cel zostanie udowodniony. W przeciwnym razie moŋesz spróbowaæ nowego celu podrzędnego udowodniæ, ŋe częķæ IF nie pasuje. Proces rekurencyjnie powtarza proces wnioskowania z nowym celem podrzędnym, który moŋe generowaæ kolejne podprogramy, które muszą zostaæ udowodnione, dopóki nie udowodni wszystkich częķci IF dla pierwotnego celu i kolejnych podprogramów. Kod do wnioskowania wstecznego zaimplementowany w modelu reprezentacji wiedzy jest pokazany w kodzie NetLogo
to go-rules-backward-reasoning
;; dokonuje wstecznego rozumowania problemu
let goal-choices []
let goal-attrib ""
let goal-value ""
let attribute ""
let value ""
set goal-attrib [goal-attribute] of selected-problem
foreach sort rules
[ ; dodaj kaŋdy cel we wszystkich reguģach do wyborów celu
foreach [consequents] of ?
[
set attribute first ?
set value last ?
if (attribute = goal-attrib) and
(not member? value goal-choices)
[ set goal-choices lput ? goal-choices ]
]
]
let goal user-one-of "Which goal do you wish to proove?" goal-choices
set goal-value (last goal)
start-new-walkers goal-attrib goal-value
ifelse not find-prove? selected-problem goal-attrib goal-value
[ user-message "No more rules found. The goal is not proven." ]
[ update-walker active-walker goal-attrib goal-value
user-message (word "The goal is proven! The " goal-attrib " is a "
goal-value ".")]
end
Kod najpierw generuje goal-choice czyli listę wszystkich celów ze wszystkich reguģ. Uŋytkownik jest następnie pytany, który cel chce udowodniæ. Następnie gracz narysowany jest na mapie wydarzenia w wybranym stanie celu, a proces rozumowania rozpoczyna się od find-prove? reporter. To zwraca wartoķæ true, jeķli moŋna znaležæ reguģę, aby udowodniæ cel lub faģsz, jeķli nie, a procedura następnie informuje uŋytkownika o wyniku. Kod znaleziskafind-prove? reporter jest pokazany w kodzie NetLogo
to-report find-goal? [this-rule goal-attrib goal-val]
;; reports if the goal is in the consequents of this_rule
let attribute ""
let val ""
let value ""
let response ""
foreach [consequents] of this-rule
[
set attribute first ?
set value last ?
if (attribute = goal-attrib) and (value = goal-val)
[ report true ]
]
report false
end
to-report prove-goal? [problem this-rule goal-attrib goal-val]
; próbuje udowodniæ tę zasadę na podstawie faktów w bazie faktów
; w przeciwnym razie prosi uŋytkownika o dane, jeķli atrybutu nie ma na liķcie atrybutów innych niŋ wejķciowe
; w przeciwnym razie rekurencyjnie wywoģuje procedurę znajdž-udowodnij? sprawdziæ, czy
; atrybuty inne niŋ wejķciowe moŋna udowodniæ
let attribute ""
let val ""
let value ""
let question ""
let choices []
let this-walker nobody
set this-walker start-new-walker nobody "" ""
foreach [antecedents] of this-rule
[
set attribute first ?
set value last ?
update-walker this-walker attribute value
if not attribute-found? attribute
; nie znaleziono, więc zapytaj uŋytkownika, czy moŋemy
[ ifelse (member? attribute [non-input-attributes] of problem)
[ ifelse not find-prove? problem attribute value
[ report false ] ; no we can't ask user
[ fact-put attribute value ]
]
[ ; zadaj uŋytkownikowi pytanie
set question get-input-question problem attribute value set
choices get-input-choices problem attribute
set val user-one-of question choices
fact-put attribute val
]
]
if not fact-found? attribute value
[ report false ]
]
update-walker this-walker goal-attrib goal-val
report true
end
to-report find-prove? [problem goal-attrib goal-val]
;; procedura rekurencyjna wywoģywana przez procedurę wnioskowania wstecznego
let this-walker nobody
output-goal goal-attrib goal-val
foreach sort rules
[ ; dla kaŋdej reguģy w bazie reguģ
if (find-goal? ? goal-attrib goal-val)
[
if (prove-goal? problem ? goal-attrib goal-val)
[
start-new-walkers goal-attrib goal-val
output-fired-rule ?
report true
]
]
to-report find-prove? [problem goal-attrib goal-val]
;; procedura rekurencyjna wywoģywana przez procedurę wnioskowania wstecznego
let this-walker nobody
output-goal goal-attrib goal-val
foreach sort rules
[ ; dla kaŋdej reguģy w bazie reguģ
if (find-goal? ? goal-attrib goal-val)
[
if (prove-goal? problem ? goal-attrib goal-val)
[
start-new-walkers goal-attrib goal-val
output-fired-rule ?
report true
]
]
]
report false
end
]
report false
end
Reportr find-prove? wywoģuje dwóch kolejnych reporterów, find-goal? i prove-goal?. Dla kaŋdej reguģy w bazie reguģ najpierw sprawdza, czy cel zostaģ znaleziony przez wywoģanie reportera find-goal? jeķli zostanie znaleziony, spróbuje to udowodniæ, nazywając reporter prove-goal?. Reporter find-goal? zwraca wartoķæ true, jeķli atrybut i wartoķæ okreķlona przez goal-attrib? i goal-val? zostaģa znaleziona w jednym z następstw okreķlonej reguģy - ta reguģa przekazana przez parametr. Reportert prove-goal próbuje najpierw udowodniæ konkretną zasadę, ŋe ta zasada jest prawdziwa z faktów w bazie faktów. W przeciwnym razie sprawdza kaŋdy z poprzedników reguģy, aby sprawdziæ, czy są one prawdziwe, pytając uŋytkownika o dane, jeķli atrybut nie jest atrybutem wejķciowym, w przeciwnym razie rekursywnie wywoģuje find-okazaæ reportera? aby sprawdziæ, czy atrybut nie-wejķciowy moŋe zostaæ udowodniony. Procedury start-new-walker, start-new-walkers i update-walker sģuŋą do animowania mapy zdarzeņ, aby pokazaæ, jak przebiega proces wnioskowania. Jakiego rodzaju rozumowania naleŋy uŋyæ przy projektowaniu systemu eksperckiego opartego na reguģach? Najlepszą odpowiedzią na to pytanie jest dla inŋyniera wiedzy obserwowanie eksperta, aby zobaczyæ, jakiego rodzaju rozumowania uŋywają. Jeķli ekspert najpierw przyjrzy się danym, a następnie wnioskuje z niego nową wiedzę, wówczas najodpowiedniejszy jest proces wnioskowania. Z drugiej strony, jeķli ekspert zaczyna najpierw od hipotetycznego rozwiązania, a następnie próbuje znaležæ fakty, które pomogą udowodniæ hipotezę, wówczas najwģaķciwsze moŋe byæ wnioskowanie zwrotne. Problemy z analizą i interpretacją nadają się do przekazania rozwiązaņ logicznych, podczas gdy problemy z typem diagnozy nadają się do wnioskowania wstecznego. Przykģadem tego pierwszego jest DENDRAL, system ekspercki, który okreķla strukturę molekularną nieznanej gleby, podczas gdy MYCIN, system ekspercki do diagnozy zakažnych chorób krwi, jest przykģadem tego ostatniego. Obecnie większoķæ systemów ekspertowych uŋywa teraz rozumowania zarówno do przodu, jak i do tyģu. Podstawową metodą wnioskowania jest ta ostatnia, poniewaŋ minimalizuje liczbę niepotrzebnych zapytaņ, które są bģędem naprzód podejķcie do rozumowania. Jednak system ekspercki moŋe przejķæ do przekazywania argumentów, gdy do podstawy faktów zostanie dodany nowy fakt w celu maksymalnego wykorzystania nowych danych. Systemy ekspertowe, takie jak DENDRAL i MYCIN, wymagają duŋych nakģadów finansowych i wysiģku (szacunkowo na 20 do 40 lat pracy). Czynnikiem, który przyczynia się do tego, jest szeroko uznaģa trudnoķæ w zdobywaniu wiedzy od ekspertów ludzkich - problem ten nazywany jest "wąskim gardģem gromadzenia wiedzy". Jednak obecnie istnieją zaawansowane powģoki systemu eksperckiego i skrzynki narzędziowe dla inteligentnych systemów wykorzystujących technologie takie jak uczenie maszynowe, sieci neuronowe i obliczenia ewolucyjne, które radykalnie skracają czas opracowywania od lat do miesięcy. Aby uzyskaæ peģniejszą dyskusję na temat opartych na reguģach systemów eksperckich i ogólnie systemów inteligentnych, czytelnik powinien odnieķæ się do Negnevitsky'ego.
Wiedza i rozumowanie za pomocą ramek
Ramki są formą reprezentacji wiedzy zaproponowaną przez Marvina Minsky′ego. Ramka jest strukturą danych przechowującą prototypowe informacje dotyczące konkretnej koncepcji. Ramki skģadają się z "gniazd", które mogą mieæ "wartoķci", które są jawnie zadeklarowane, gdy ramka jest zadeklarowana, lub są dziedziczone z ramki nadrzędnej. Ta forma reprezentacji wiedzy jest najbardziej podobna do modelu przestrzeni konceptualnej Gärdenforsa, a szczeliny są analogiczne do wymiarów jakoķciowych. Istnieją dwa rodzaje ramek: ramka klasy; i ramkę indywidualną lub instancję. Pojęcia klasy, instancji i dziedziczenia są analogiczne do tych uŋywanych w programowaniu obiektowym opisanym w sekcji 2.2 Dziedziczenie jest zwykle okreķlane za pomocą "ako" (oznacza to "rodzaj"). Na przykģad w przypadku problemu klasyfikacji zwierząt w zoo gepard jest rodzajem ssaka, a ssak jest rodzajem zwierzęcia. Jako kolejny przykģad, ramy dla problemu klasyfikacji ģodzi ŋaglowych przedstawiono w tabeli 9.8. Tabela pokazuje osiem ramek ģodzi ŋaglowych w osobnych kolumnach, z nazwami i wartoķciami w wierszach. W przypadku tego szczególnego problemu wiedza jest stosunkowo regularna, a jedynie kilka komórek tabeli z brakującymi wartoķciami. Zwykle brakujące wartoķci są normą, gdy ramki są wyķwietlane w formie tabelarycznej, poniewaŋ nie ma wymogu, aby kaŋda klatka miaģa te same szczeliny, poniewaŋ ramki reprezentują róŋne koncepcje o róŋnych wģaķciwoķciach i mogą dziedziczyæ informacje z róŋnych ramek nadrzędnych. Reprezentację mapy zdarzeņ dla tej wiedzy pokazano na rysunku
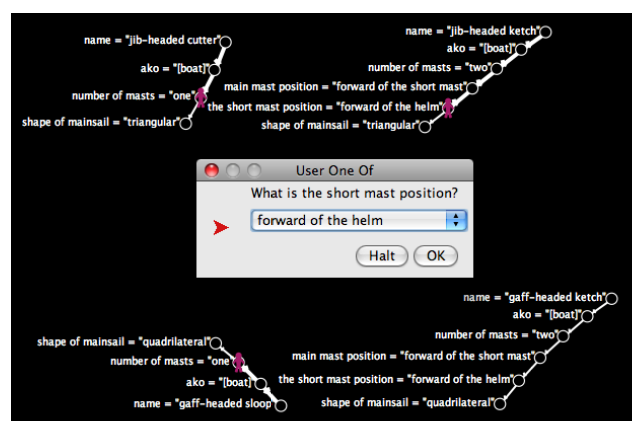
Dla jasnoķci, liczba pokazuje mapę zdarzeņ tylko dla pierwszych czterech ramek dla problemu ģodzi ŋaglowej - noŋa z gģowicą z występem (lewy górny róg), slup na czele Gaffa (na dole po lewej), kecz z Jigsem (u góry po prawej) i Gaff na czele ketch (prawy dolny róg). Kaŋda klatka jest przedstawiona jako osobna ķcieŋka, zaczynając od stanu zdarzenia oznaczonego przez nazwę ramki (na przykģad nazwa = "jib-headed-cutter" w lewym górnym rogu), a następnie przechodzenie do stanu, który deklaruje, jaki rodzaj ramki reprezentuje ķcieŋka (ten stan jest zawsze oznaczony etykietą as ako = "[boat]", poniewaŋ wszystkie ramki są ramami ģodzi w tym przykģadzie). Ķcieŋka następnie kontynuuje przez stany reprezentujące poszczególne przedziaģy i wartoķci kaŋdej klatki.
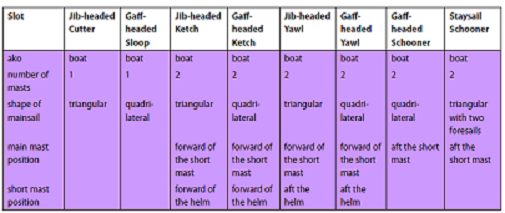
Zamiast deklarowaæ ramki oddzielnie od wiedzy opartej na reguģach, model reprezentacji wiedzy zamiast tego stosuje podejķcie polegające na przeksztaģcaniu wiedzy opartej na reguģach w formacie ramek. Ma to na celu zilustrowanie zgodnoķci między tymi dwoma podejķciami, gdy zdania w reguģach są okreķlone przy uŋyciu par wartoķci atrybutu. Umoŋliwia to równieŋ wizualizację róŋnych metod za pomocą map zdarzeņ. Kod do tego jest pokazany w kodzie NetLogo
to convert-rules-to-frames-base [problem]
;; Konwertuje bazę reguģ na bazę klatek
let this-rule nobody
let this-frame nobody
let attribute ""
let value ""
ask frames [ die ] ; kill off any previous frames
foreach sort rules
[ ; dla kaŋdej reguģy w bazie reguģ
set this-rule ?
foreach [consequents] of this-rule
[
set attribute (first ?)
set value (last ?)
set this-frame find-frame? attribute value
if (this-frame = nobody)
[ ; ramka nie istnieje z tą nazwą i typem
create-frames 1
[
hide-turtle ; uczyniæ niewidocznym
set this-frame self
set name value
set ako-list (list attribute)
set slots-table table:make
]
]
foreach [antecedents] of this-rule
[
ask this-frame
[
set attribute (first ?)
set value (last ?)
ifelse (member? attribute [input-attributes] of
problem)
[ table:put slots-table attribute value ]
[ set ako-list
(lput value ako-list) ] ; dodaj wartoķæ do listy ako
]
]
]]
end
to-report find-frame? [this-ako this-name]
;; zgģasza ramkę, która ma wartoķæ boksu ako = ako i name = name.
;; nikt nie zgģasza inaczej
report one-of frames with
[member? this-ako ako-list and name = this-name]
end
Procedura konwersji najpierw zabija wszystkie istniejące ramki, a następnie przetwarza kaŋdą z reguģ w bazie reguģ po kolei. Dla następstw kaŋdej reguģy sprawdza, czy ramka o tej samej nane i wartoķciach ako nie istnieją, wywoģując find-frame? reporter. Jeķli nie istnieje, utworzy nową ramkę, w przeciwnym razie uŋyje tego, który zostaģ znaleziony. Następnie wstawi szczeliny i ich wartoķci do slot-table dla ramki, jeķli atrybut proposition jest atrybutem wejķciowym, w przeciwnym razie dodaje wartoķæ proposition do ako-list dla ramki. Mapa zdarzeņ jest tworzona z tych ramek przy uŋyciu procedury dodawania zdarzeņ, jak pokazano w kodzie NetLogo
to-report slots-events [table]
;; zwraca listę zdarzeņ dla tabeli gniazd
let events []
let keys []
let value ""
set keys table:keys table
foreach keys
[
set value table:get table ?
set events lput (list ? value) events
]
report events
end
to setup-frames
;; konfiguruje sieæ stanów z ramek
init-problem ; zainicjuj wybrany problem
let events []
convert-rules-to-frames-base selected-problem
foreach sort frames
[
set events slots-events [slots-table] of ?
set events fput (fput "ako" (list [ako-list] of ?)) events
set events fput (list "name" [name] of ?) events
add-events events white white white
]
repeat 5 [ change-layout ]
display
end
Ten kod definiuje procedurę setup-frames, która wywoģuje procedurę convert-rules-to-frames zdefiniowaną powyŋej, a następnie dla kaŋdej z nowo utworzonych ramek generuje listę zdarzeņ dla kaŋdego z otworów w ramce w jej tabeli slotów (przez wywoģanie reportera s;ots-events), a następnie dodaje dwa kolejne zdarzenia na początku listy zdarzeņ, jeden dla ako-list i drugi dla nazwy ramki, przed wywoģaniem procedury add-events . Istnieją dwa gģówne typy rozumowania z ramami - rozumowanie przez dziedziczenie i rozumowanie przez dopasowanie. Ten pierwszy wypeģnia brakujące wartoķci szczelin dla klatek, jeķli dla ramki nadrzędnej okreķlono wartoķæ szczeliny. Na przykģad w przypadku problemu z ŋaglówką, macierzysta "ģódž" moŋe okreķliæ, ŋe liczba ŋagli dla ģodzi wynosi domyķlnie dwa. Przypomnijmy, ŋe celem ramki jest przedstawienie prototypowej koncepcji, więc przy okreķlaniu, ŋe rama ģodzi ma dwa ŋagle, oznacza to, ŋe prototypowa ģódž będzie miaģa dwa ŋagle. Oczywiķcie zawsze są wyjątki od reguģy, dlatego domyķlna
wartoķæ ramki nadrzędnej moŋe byæ ģatwo nadpisana w ramce podrzędnej przez wstawienie okreķlonej wartoķci. Samochody, na przykģad, mają najczęķciej cztery koģa, ale niektóre samochody mają trzy koģa, takie jak Reliant Robin wyprodukowany w Anglii w latach 70. ubiegģego wieku, a ostatnio samochody hybrydowe i elektryczne, które przyjmują trójkoģowe rozwiązanie z powodów aerodynamicznych i wydajnoķci. Tak więc ramka rodzica "samochód" moŋe ustawiæ wartoķæ szczeliny dla "liczby kóģ" na 4, ale zamiast tego ustaw na przykģad wartoķæ 3 dla ramki "Reliant Robin car". Druga forma rozumowania ramek opartych na dopasowywaniu polega na przeszukiwaniu ramek-podstawy dla ramki, której szczeliny i wartoķci pasują do aktualnych znanych faktów. Zostaģo to zaimplementowane w modelu reprezentacji wiedzy. Rysunek 9.12 to zrzut ekranu, który przedstawia poķredni etap procesu wnioskowania, aby pokazaæ, jak przebiega.
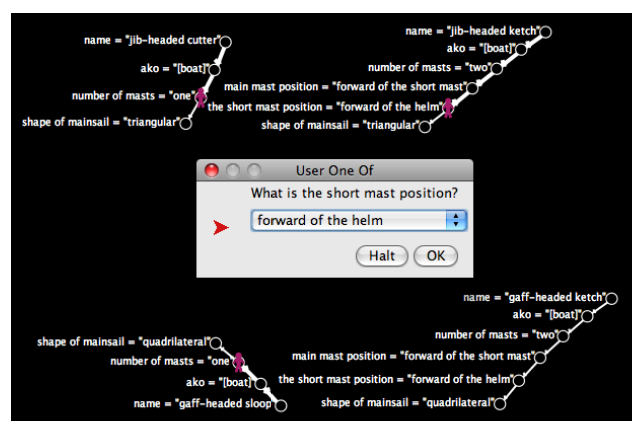
Na zrzucie ekranu ķcieŋki, które zostaģy zastosowane, są przedstawione grubszymi biaģymi ģączami. Pierwszym pytaniem, które zadecydowaģo, ŋe gģowica z gģowicą Jib jest pierwszą dopasowaną ramą, jest "Ile jest masztów?", Poniewaŋ dopasowywano gniazdo "liczba masztów". Uŋytkownik odpowiedziaģ "dwoma", co spowodowaģo, ŋe ramka obcinarki z kierownicą z przegubem i następna rama, slup z gģowicą Gaffa, nie dorównaģy. Jest to pokazane przez agentów walkerów zatrzymujących się tuŋ przed koņcem dwóch ķcieŋek pokazanych po lewej stronie ekranu. Proces rozumowania następnie próbowaģ dopasowaæ następną klatkę w podstawie ramki - ramkę Ketch z nagģówkiem Jib. Zrzut ekranu pokazuje etap po tym, jak pytanie "Jaka jest gģówna pozycja masztu?" Zostaģo odebrane "przed krótkim masztem", a uŋytkownik ma odpowiedzieæ na następne pytanie "Jaka jest krótka pozycja masztu?" wyķwietlane na ķrodku ekranu. Kod, który wykonuje proces dopasowywania ramek, jest zdefiniowany przez procedurę go-frames-reasoning modelu Kowledge Representation w NetLogo. Zamiast odtwarzaæ tutaj kod, czytelnik moŋe sprawdziæ kod bezpoķrednio w NetLogo, wybierając przycisk Procedures. Kod skģada się z reportera, matcg-frame?, który zwraca wartoķæ true, jeķli ramka pasuje do bieŋących faktów. Reporter match-frame?r najpierw tworzy nowego agenta spacerowego i przesuwa go wzdģuŋ początku ķcieŋki ramki w mapie zdarzeņ poprzez nazwę i inne stany. Następnie przetwarza kaŋdą z nazw znajdujących się na liķcie ako ramki, aby upewniæ się, ŋe kaŋda z ramek macierzystych jest zgodna z rekursywnie wywoģującą funkcję match-frame?. Będzie to równieŋ oznaczaæ, ŋe ramki typu grandparent (i ramki typu "great-grandparent" itd.) Będą równieŋ musiaģy byæ dopasowane, zanim ramka sama się dopasuje. Po dopasowaniu wszystkich tych ramek macierzystych, reporter wyodrębnia listę nazw slotów ze slot-tables a następnie dla kaŋdego z nich wyodrębnia ich wartoķci i uŋywa kodu podobnego do tego, którego uŋyto w rozumowaniu opartym na reguģach. powyŋej w sekcji , spróbuje sprawdziæ, czy fakt z nazwą i wartoķcią slotów juŋ istnieje w bazie faktów. Jeķli nie, poprosi uŋytkownika o wprowadzenie, jeķli slot jest atrybutem wejķciowym, w przeciwnym razie zwróci false (ramka nie zostaģa dopasowana). Czy procedura go-frames-reasoning wywoģuje match-frame? reporter dla kaŋdej ramki, która ma atrybut cel w swojej ako-list, która jest ustawiana podczas tworzenia ramek - na przykģad dla ramki ŋaglówek atrybut bramki jest ustawiony na ģódž, a dla klatek zwierząt w zoo- podstawa atrybut cel jest ustawiony na animal, dlatego tylko te ramki są dopasowane do problemu. Istnieje wiele odmian metody reprezentacji wiedzy opartej na ramkach. Rozszerzeniem podstawowej reprezentacji typu szczeliny jest umoŋliwienie, aby sloty miaģy "ķcianki" zapewniające rozszerzoną wiedzę o atrybucie opisywanym przez szczelinę. Facetów moŋna uŋywaæ do kontrolowania zapytaņ uŋytkowników i prowadzenia procesu wnioskowania, na przykģad wyszczególniając sposób dopasowania gniazda. Metody (zwane "demonami") moŋna równieŋ powiązaæ z atrybutami jako aspektami, które zapewniają systemowi ramowemu mechanizm wyraŋania wiedzy proceduralnej. Te metody wykonują akcje uruchamiane w okreķlonych warunkach. Na przykģad dwa typowe typy metod to: KIEDY ZMIENIONO I GDY POTRZEBUJESZ, które są wyzwalane, gdy wartoķæ gniazda zostanie zmieniona lub kiedy zostanie on udostępniony. Obecnie wiele specjalistycznych i inteligentnych systemów to systemy hybrydowe, które ģączą dwie lub więcej technologii; na przykģad wiele systemów uŋywa zarówno ramek, jak i reguģ do reprezentowania wiedzy i do wnioskowania. Terminem często uŋywanym do opisu tych systemów hybrydowych jest "miękkie przetwarzanie", które dotyczy systemów zdolnych do wnioskowania z niepewnoķcią i dynamicznymi ķrodowiskami z wieloma agentami. Negnevitsky przedstawia kilka przykģadów hybrydowych inteligentnych systemów, które ģączą róŋne technologie, nie tylko oparte na symbolach technologie, takie jak reguģy i ramki, ale takŋe technologie pod-symboliczne, takie jak sieci neuronowe i ewolucyjne obliczenia.
Znajomoķæ i rozumowanie przy uŋyciu drzew decyzyjnych
Inną metodą reprezentowania wiedzy są drzewa decyzyjne. Widzieliķmy juŋ kilka przykģadów drzew decyzyjnych w dziale wczeķniej, a na powyŋszym rysunku, który zawiera zrzut ekranu drzewa decyzyjnego dla problemu zwierząt w zoo. NetLogo Code. pokazuje, w jaki sposób reguģy moŋna przeksztaģciæ w drzewo decyzyjne za pomocą reprezentacji odwzorowania zdarzeņ omawianej w sekcji wczeķniej.
to convert-rules-to-decision-tree
;; Konwertuje bazę reguģ na drzewo decyzyjne
init-problem ; initialise the selected problem
let this-rule nobody
let attribute ""
let value ""
let events []
foreach sort rules
[ ; dla kaŋdej reguģy w bazie reguģ
set this-rule ?
set events (list (list [goal-attribute] of selected-problem "Yes"))
foreach [antecedents] of this-rule [
ask this-rule
[
set attribute (first ?)
set value (last ?)
set events lput (list attribute value) events
]
]
foreach [consequents] of this-rule
[
set attribute (first ?)
set value (last ?)
add-events (lput (list attribute value) events) white white white
]
]
repeat 5 [ change-layout ]
display
end
Ta procedura przetwarza kaŋdą reguģę w bazie reguģ, najpierw inicjując listę zdarzeņ, aby zawieraģo pojedyncze zdarzenie zawierające atrybut celu ze sģowem "Yes". Na przykģad problem z jachtami ŋaglowymi ustawi listę zdarzeņ na [[boat "Tak"]]. Efektem tego jest to, ŋe wszystkie reguģy będą poģączone z centralnym węzģem w centrum drzewa decyzyjnego. Procedura następnie doģącza wszystkie poprzedniki jako zdarzenia do listy zdarzeņ, a następnie dla kaŋdego z następstw doda następnik na koņcu tej listy i wywoģa osobno add-events. Spowoduje to utworzenie osobnej ķcieŋki zdarzenia dla kaŋdego kolejnego wyniku. Wynik dla problemu ģodzi ŋaglowych pokazano na rysunku.
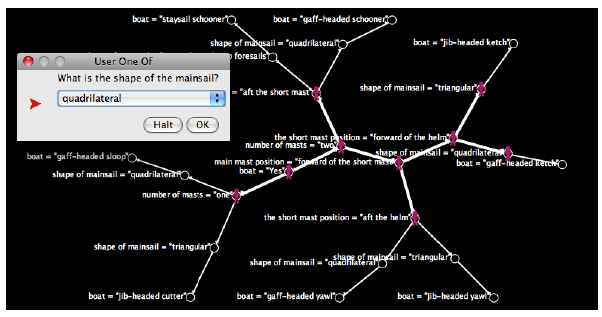
Zwróæ uwagę, ŋe drzewo ma osiem węzģów listków, które odpowiadają oķmiu reguģom w bazie reguģ. Proces rozumowania dziaģa na zewnątrz od centralnego węzģa, zadając pytania i podąŋając za odpowiednim odsyģaczem, aŋ do uzyskania liķcia w taki sam sposób, jak nowozelandzki model NetLogo pt. Omówiony w częķci 4. Postęp procesu wnioskowania na etapie poķrednim jest pokazano na rysunku powyŋej. Proces rozpocząģ się w węžle centralnym oznaczonym jako boat = "Yes". Podkreķlono dwa moŋliwe poģączenia, które mógģ nastąpiæ - link do stanu oznaczony number of mast = "one" i link do stanu oznaczony number of mast = "two". Wewnętrzna kolejnoķæ linków (w wyniku ich utworzenia) spowodowaģa, ŋe proces wnioskowania przeniósģ się do pierwszego z tych stanów i spowodowaģ pytanie "Ile masztów tam jest?". Uŋytkownik odpowiedziaģ "dwójką", co oznacza, ŋe przejķcie bieŋącej ķcieŋki zostaģo zatrzymane, a proces wnioskowania rozpocząģ się po drugiej ķcieŋce. Następne pytanie brzmiaģo: "Jaka jest gģówna pozycja masztu?", A odpowiedž "naprzód z masztu krótkiego" zmusiģa proces wnioskowania do przeniesienia do stanu oznaczonego jako main mast position = "forward of the short mast". Następne pytanie brzmiaģo: "Jaka jest krótka pozycja masztu?", A odpowiedž "naprzód steru" zmusiģa proces wnioskowania do stanu pokazanego na rysunku. Odpowiedž na aktualne pytanie "Jaki jest ksztaģt grota?" Spowoduje, ŋe proces wnioskowania zakoņczy się wnioskiem, ŋe ģódka jest kranem z przewęŋeniem, jeķli odpowiedž byģa "trójkątna", i z wnioskiem, ŋe w przeciwnym razie byģ to kecz z Gaffem. Kod wykonujący proces rozumowania drzewa decyzyjnego jest zdefiniowany przez procedurę go-decision-tree-reasoning w modelu reprezentacji wiedzy w NetLogo. Ten kod wywoģuje procedurę match-tree, aby przejķæ drzewo. Robi to, nazywając siebie rekursywnie dopasowując stany drzew do faktów w bazie faktów, aŋ do momentu, gdy nie będzie juŋ ŋadnych sąsiadów poza ķcieŋką - to znaczy, gdy zostanie osiągnięty węzeģ liķcia. Cel zostaje osiągnięty, gdy do bazy faktów dodano fakt, ŋe atrybut celu (w tym przypadku boat) zostaģ dodany.
Znajomoķæ i rozumowanie za pomocą sieci semantycznych
Ostateczna metoda reprezentacji wiedzy, którą zbadamy, nazywa się sieciami semantycznymi. Sieci semantyczne skģadają się z poģączonych ze sobą węzģów poģączonych ģukami. Węzģy reprezentują obiekty i ģukują relacje między obiektami. Przykģad sieci semantycznej dla problemu zwierząt w zoo pokazano na rysunku
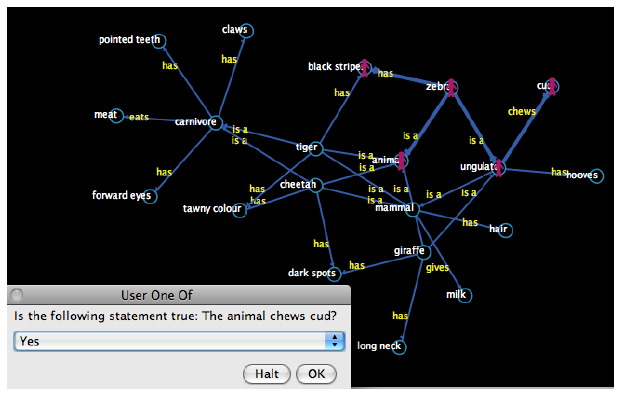
Istnieje wiele wariantów sieci semantycznych, których początki sięgają 1909 r. Wraz z "wykresami egzystencjalnymi" Pierce'a. Sieci semantyczne staģy się popularne w latach 70. XX wieku, przy czym Collins i Quillian wykonali waŋną pracę (na przykģad w 1969 r.). Waŋna debata w AI dotycząca sieci semantycznych dotyczy względnych zalet w porównaniu z logiką. Russell i Norvig zwracają jednak uwagę, ŋe sieci semantyczne moŋna równieŋ uznaæ za formę logiki, tak jak w przypadku innych form reprezentacji wiedzy omówionych powyŋej. Nowszym przykģadem sieci semantycznej jest WordNet, który jest duŋą leksykalną bazą danych angielskich sģów pogrupowanych wedģug synonimów. Kod NetLogo pokazuje, jak zadeklarowana jest sieæ semantyczna dla problemu zwierząt w zoo w modelu KnowledgeRepresentation.
to-report create-state [state-label]
;; tworzy i zwraca nowy węzeģ semantyczny
let this-state nobody
create-states 1
[
set this-state self
set color sky
set label-color white
set label state-label
set size 8
set stream "state name"
set event state-label
]
report this-state
end
to create-slink [state1 slink-label state2]
;; tworzy ģącze między dwoma węzģami state1 i state2 w
;; sieci semantycznej
ask state1
[ create-path-to state2
[ set label slink-label
set label-color yellow
set color blue
]
]
end
to setup-animals-semantic-network
;; ustawia węzģy i ģącza w sieci semantycznej Zoo Animals
let animal-state create-state "animal"
set goal-state animal-state
let mammal-state create-state "mammal"
let ungulate-state create-state "ungulate"
let carnivore-state create-state "carnivore"
let hair-state create-state "hair"
let milk-state create-state "milk"
let meat-state create-state "meat"
let pointed-teeth-state create-state "pointed teeth"
let claws-state create-state "claws"
let forward-eyes-state create-state "forward eyes"
let hooves-state create-state "hooves"
let cud-state create-state "cud"
let tawny-colour-state create-state "tawny colour"
let dark-spots-state create-state "dark spots"
let black-stripes-state create-state "black stripes"
let long-neck-state create-state "long neck"
let cheetah-state create-state "cheetah"
let tiger-state create-state "tiger"
let giraffe-state create-state "giraffe"
let zebra-state create-state "zebra"
create-slink cheetah-state "is a" animal-state
create-slink tiger-state "is a" animal-state
create-slink giraffe-state "is a" animal-state
create-slink zebra-state "is a" animal-state
create-slink ungulate-state "is a" mammal-state
create-slink cheetah-state "is a" mammal-state
create-slink tiger-state "is a" mammal-state
create-slink cheetah-state "is a" carnivore-state
create-slink tiger-state "is a" carnivore-state
create-slink giraffe-state "is a" ungulate-state
create-slink zebra-state "is a" ungulate-state
create-slink mammal-state "has" hair-state
create-slink mammal-state "gives" milk-state
create-slink carnivore-state "eats" meat-state
create-slink carnivore-state "has" pointed-teeth-state
create-slink carnivore-state "has" claws-state
create-slink carnivore-state "has" forward-eyes-state
create-slink ungulate-state "has" hooves-state
create-slink ungulate-state "chews" cud-state
create-slink cheetah-state "has" tawny-colour-state
create-slink cheetah-state "has" dark-spots-state
create-slink tiger-state "has" tawny-colour-state
create-slink tiger-state "has" black-stripes-state
create-slink giraffe-state "has" dark-spots-state
create-slink giraffe-state "has" long-neck-state
create-slink zebra-state "has" black-stripes-state
end
setup-animals-semantic-network wykorzystuje reporter, create-state, do tworzenia stanu w sieci i zwracania go oraz procedurę, create-slink, do tworzenia poģączenia między dwoma stanami. Pierwsza z nich przyjmuje pojedynczą stste - label która okreķla etykietę powiązaną ze state , a następnie tworzony jest pojedynczy agent paņstwowy z okreķloną etykietą, która następnie jest zwracana. Ta ostatnia przyjmuje trzy argumenty: stan początkowego state1, etykietę znacznika koņca slink-label dla ģuku i stan state2, a następnie tworzony jest agent pojedynczego ģącza, który ģączy state1 z state2. Sieæ semantyczną tworzy się najpierw, tworząc stan dla typów zwierząt (ssaków, zwierząt kopytnych, drapieŋnych), dla cech zwierząt (np. Wģosów, mleka, mięsa, ostrych zębów, pazurów) i dla kaŋdego ze zwierząt ( tygrys, gepard, ŋyrafa i zebra). Następnie ģącza między tymi stanami są ustawiane jeden po drugim. Chociaŋ sieci semantyczne są stosunkowo ģatwe do ustawienia, gģównym problemem jest podejmowanie decyzji o rodzaju wiedzy, która trafia do sieci - czyli jaki rodzaj wiedzy powinien byæ reprezentowany przez paņstwa i jaki rodzaj wiedzy przez ģuki. Zasadą jest, ŋe etykiety stanu powinny byæ rzeczownikami, a etykiety etykiet powinny byæ czasownikami. Dwie etykiety powszechnie uŋywane w ģukach to "is a" i "has". Na przykģad w ķrodku rysunku 9.14 znajduje się znakowany "tygrys" i ma on dwa ģuki oznaczone "ma" i trzy ģuki oznaczone jako "jest" ģączące pięæ stanów. To reprezentuje wiedzę, ŋe tygrys ma czarne pasy i brązowy kolor oraz ŋe tygrys jest zwierzęciem, amammal i mięsoŋercą. Etykieta ģukowa "jest a", podobnie jak w przypadku ramek, sģuŋy do wykonywania dziedziczenia i domyķlnego rozumowania stylu. Naleŋy zauwaŋyæ, ŋe wielokrotne dziedziczenie jest dozwolone, w przeciwieņstwie do niektórych języków programowania obiektowego, takich jak Java, które obsģugują tylko dziedziczenie pojedyncze. Ramki mogą byæ uwaŋane za odmianę sieci semantycznych, poniewaŋ kaŋdy węzeģ moŋe reprezentowaæ pojedynczą ramkę, a ģuki, które wychodzą poza węzeģ, są jego gniazdami, przy czym wartoķci szczelin są węzģami, do których prowadzą wartoķci szczelin. Sieæ semantyczną moŋna równieŋ przeksztaģciæ w równowaŋną mapę zdarzeņ. Moŋna to zrobiæ w modelu reprezentacji wiedzy, ustawiając wybierak KR-type w interfejsie na "semantic event network", a model początkowo narysuje sieæ semantyczną, a następnie zastąpi ją równowaŋną siecią semantycznych zdarzeņ. Waŋna forma rozumowania sieci semantycznych polega na dopasowaniu stanów do aktualnych faktów w sposób analogiczny do dopasowania ramek. Rysunekprzedstawia etap poķredni procesu dopasowywania stanu. W tym przypadku proces rozumowania rozpocząģ się od docelowego stanu animal w ķrodkowym prawym rogu obrazu. Jeden z sąsiadujących w tej drodze sąsiadów tego stanu zostaģ wybrany losowo, aby byæ następnym stanem odwiedzanym - w przypadku pokazanym na obrazie wybranym stanem byģ stan zebry. Proces rozumowania następnie próbowaģ dopasowaæ wszystkie stany związane z tym stanem - pierwszy wybrany byģ stan black stripe, który spowodowaģ pytanie "Czy prawdziwe jest następujące stwierdzenie: Zwierzę ma czarne paski?", Które naleŋy zadaæ. Jako ŋe odpowiedž byģa twierdząca, proces rozumowania zacząģ się dopasowywaæ do stanu ungulate, przy czym stan przytulenia zostaģ wybrany do następnej wizyty, co skutkowaģo pytaniem "Czy prawdziwe stwierdzenie jest prawdziwe: zwierzę przeŋuwa?", Jak pokazano na obrazie. Kod, który wykonuje semantyczny proces rozumowania sieci, jest zdefiniowany przez procedurę go-semantic-network- reasoning w modelu Knowledge Repreentation w NetLogo. Ten kod wykorzystuje reprotera match-network-state?, który zwraca wartoķæ true, jeķli okreķlony stan w sieci semantycznej pasuje do bieŋących faktów. Reporter dziaģa przez przetwarzanie wszystkich sąsiadujących z zewnątrz ķcieŋek do momentu znalezienia dopasowania. Najpierw klonuje agenta spacerowego, aby przejķæ do okreķlonego stanu sąsiedniego. Jeķli etykieta dla ģącza do tego stanu jest równa "is a", wówczas wywoģa się rekursywnie z nowo sklonowanym walkerem, aby sprawdziæ, czy sąsiednie paņstwo równieŋ dopasowuje się jako pierwsze, poniewaŋ jest to stan "jest" (macierzysty). W przeciwnym razie uŋyje etykiety ģącza i etykiety sąsiedniego stanu do skonstruowania zdania w celu sprawdzenia, czy jest ono prawdziwe, czy teŋ nie, w procesie, w razie potrzeby pytając uŋytkownika, czy atrybut propozycji nie jest jeszcze znany (tj. baza faktów). Ta konkretna implementacja pozwala na umieszczanie w etykietach linków sģowa kluczowego "nie" (na przykģad "nie jest" moŋe byæ uŋyte zamiast "jest", "nie moŋe" zamiast "moŋe" i "nie ma" zamiast "ma" "). Dokonano tego, aby dostosowaæ się do konkretnego stylu wiedzy w problemach ptaków nowozelandzkich, aby forma sieci semantycznej mogģa byæ bezpoķrednio porównywana z innymi formami reprezentacji. Twierdzenie jest sprawdzane przez sprawdzenie, czy istnieje w aktualnej bazie faktów, a reporter zwróci wartoķæ false, jeķli nie jest. Gģówna procedura go-semantic-network-reasoning dziaģa poprzez wywoģanie funkcji match-networkstate? dla wszystkich sąsiadujących w drodze sąsiadów stanu celu, którego link do niego ma etykietę "jest a". Kontynuuje dopóki nie znajdzie jednego z sąsiadujących paņstw, które pasują do siebie. Na przykģad dla problemu zwierząt z ogrodów zoologicznych, spróbuje (w dowolnej kolejnoķci) kaŋdego z czterech stanów - tiger, cheetah, giraffe i zebra - które są poģączone ze stanem zwierzęcia z etykietą ģącza "jest a". Jeķli nie moŋe znaležæ sąsiedniego stanu "jest", który pasuje, zwróci wartoķæ false. Ta konkretna implementacja powoduje, ŋe za kaŋdym razem, gdy uruchamiana jest procedura, ŋądany jest inny zestaw pytaņ (w wyniku polecenia ask uŋywającego in-path-neighbours). Jeķli takie zachowanie wprawia w zakģopotanie uŋytkownika, moŋna uzyskaæ bardziej spójne zachowanie systemu eksperckiego za pomocą polecenia foreach-sort, aby zapewniæ, ŋe sąsiednie stany są odwiedzane w okreķlonej kolejnoķci. Problem z rozumowaniem opartym na sieci semantycznej, widoczny podczas uruchamiania modelu reprezentacji wiedzy, polega na tym, ŋe często przeskakuje on w sieci, zadając pozornie niepowiązane pytania, aw rezultacie mylenie uŋytkownika systemu. Istnieje takŋe utrata kontekstu, poniewaŋ proces wnioskowania przechodzi z jednego stanu do następnego. W przeciwieņstwie do drzewa decyzyjnego lub reprezentacji mapy zdarzeņ, które podąŋają za zdefiniowanymi ķcieŋkami, gdzie lokalizacja stanu odzwierciedla stan rozumowania na podstawie wczeķniejszej sekwencji odwiedzonych stanów.
Podsumowanie i dyskusja
Reprezentacja wiedzy jest podstawowym zadaniem wymaganym do inteligentnego zachowania. W niniejszym rozdziale przedstawiono róŋne sposoby reprezentowania wiedzy, takie jak mapy, reguģy, logika, ramki, drzewa decyzyjne i sieci semantyczne. Reprezentacja oparta na mapach zdarzeņ zostaģa wykorzystana do wizualizacji róŋnych typów reprezentacji i pokazania, w jaki sposób moŋna je przeksztaģciæ z jednej formy w drugą. Celem byģo omówienie wiedzy z ucieleķnionej, usytuowanej perspektywy poprzez pokazanie, ŋe wiedza i rozumowanie są związane z ruchem agenta wokóģ otoczenia. Wiedza zostaģa przeksztaģcona z wykorzystaniem reprezentacji mapy zdarzeņ jako punktów w abstrakcyjnych n-wymiarowych ķrodowiskach kosmicznych, a rozumowanie jako przeszukiwanie tej przestrzeni. Moŋemy równieŋ powiązaæ wiedzę z zachowaniem w następujący sposób. Moŋna powiedzieæ, ŋe agenci posiadający wiedzę wykazują ķwiadome zachowanie, podczas gdy agenci bez wiedzy muszą wykazywaæ jakąķ formę poszukiwania zachowanie zamiast tego. Od punktu odniesienia obserwatora, jeķli widzimy agenta szukającego czegoķ, moŋemy wywnioskowaæ, dlaczego tak się dzieje z powodu braku wiedzy o tym, gdzie moŋna znaležæ to, czego szukają. Dlatego moŋemy powiedzieæ, ŋe zachowanie wiedzące jest przeciwieņstwem poszukiwaņ (lub uŋycia innej analogii, dwóch stron tej samej monety). Na przykģad, osoba wykazuje się ķwiadomym zachowaniem, gdy przechodzi prosto z ogrodu zoologicznego do stawu ģódkowego w nowojorskim Central Parku, bez koniecznoķci patrzenia na mapę. Inna osoba, moŋe antylopoņski goķæ z doģu, będzie musiaģ uŋyæ mapy, aby "znaležæ" drogę zamiast niej (zwróæ uwagę na uŋycie metafory wyszukiwania, aby opisaæ ten proces). Nieuchronnie będzie musiaģ fizycznie szukaæ na pewnym etapie, gdy zgubi się po drodze, gdy mapa nie pasuje do rzeczywistoķci.
Podsumowanie waŋnych pojęæ, które moŋna wyciągnąæ z tej częķci, pokazano poniŋej:
• Symboliczne podejķcie odgórne do AI zakģada, ŋe moŋemy reprezentowaæ wiedzę za pomocą symboli.
• Pod-symboliczne podejķcie "oddolne" do sztucznej inteligencji kģadzie nacisk na przetwarzanie bodžców, a nie symboli.
• Koncepcyjna teoria przestrzeni zakģada poķrednie ķrodowisko, w którym pojęcia reprezentowane jako regiony w przestrzeni n-wymiarowej są centralną cechą ludzkiej wiedzy i rozumowania.
• Mapy reprezentują wiedzę topograficzną, ale mogą byæ równieŋ wykorzystywane do reprezentowania innych form wiedzy w sposób abstrakcyjny.
• Mapy zdarzeņ mogą byæ uŋywane do reprezentowania i wizualizacji danych n-wymiarowych w dwóch wymiarach.
• Reguģy są formą reprezentacji wiedzy, która uŋywa instrukcji IF-THEN (warunku-dziaģania).
• Istnieją dwa gģówne typy rozumowania na podstawie reguģ: przekonanie do przodu, które rozpoczyna się od faktów i próbuje udowodniæ konkretny cel, jest prawdziwe; i rozumowanie wsteczne, które zaczyna się od celu w pierwszej kolejnoķci i dziaģa wstecz, aby pokazaæ, ŋe fakty potwierdzają hipotezę celu.
• Drzewa decyzyjne przedstawiają graficznie wiedzę jako drzewo skierowane, z pytaniami lub decyzjami związanymi z kaŋdym węzģem w drzewie oraz wnioski w węzģach liķci. Rozumowanie opiera się na wykorzystaniu faktów, aby wskazaæ, do której gaģęzi drzewa naleŋy podąŋaæ.
• Sieci semantyczne wykorzystują równieŋ formę graficzną do reprezentowania wiedzy, z węzģami reprezentującymi pojęcia i ģukami reprezentującymi relacje między koncepcjami. Sieci semantyczne są ķciķle związane z ramami
Inteligencja
Natura inteligencji
Jaka jest natura inteligencji? To jest pytanie, które byģo rozwaŋane i dyskutowane przez tysiące lat. Wiele osób na przestrzeni wieków przedstawiģo swoją opinię na ten temat, co ilustrują cytaty poniŋej
Lao Tzu (Nieznany; VI wiek p.n.e.) , Chiņski kronikarz : "Poznanie innych to inteligencja; poznanie siebie jest prawdziwą mądroķcią. Opanowanie innych jest siģą; opanowanie siebiejest prawdziwą mocą. Jeķli zdajesz sobie sprawę, ŋe masz doķæ, jesteķ naprawdę bogaty."
Socrates , 469-399 p.n.e. , Grecki filozof : "Wiem, ŋe jestem inteligentny, bo wiem, ŋe nic nie wiem "
Leonadoda Vinci, 1452-1519, Wģoski naukowiec, rzežbiarz : "Kaŋdy, kto prowadzi spór, odwoģując się do autorytetu nie wykorzystuje swojej inteligencji, po prostu uŋywa swojej pamięci."
Abigail Adams ,1744-1818 ,Amerykaņska Pierwsza Dama : "Zawsze czuģam, ŋe inteligencja osoby jest bezpoķrednio odzwierciedlona przez liczbę sprzecznych punktów widzenia, które mgą bawiæ się jednoczeķnie na ten sam temat. "
Albert Einstein, 1879-1955 , Niemiecki fizyk : "Prawdziwym znakiem inteligencji nie jest wiedza, ale wyobražnia."
Bertolt Brecht ,1898-1956 ,Niemiecki poeta i dramaturg : "Inteligencja nie polega na tym, by nie popeģniaæ bģędów, ale szybko to widzieæ jak uczyniæ je dobrymi."
Arthur Samuel, 1901-1990, Amerykaņski pionier AI : "Chodzi o to, aby maszyny pokazywaģy zachowania, które, jeķli zostaģyby wykonane przez ludzi, zakģadaģyby wykorzystanie -inteligencji".
Alan Turing ,1912-1954, Brytyjski naukowiec, matematyk : "Komputer zasģuguje na miano inteligentnego jeķli moŋe oszukaæ czģowieka, aby uwierzyģ, ŋe jest czģowiekiem. "
Susan Sontag , 1933-2004, Amerykaņska pisarka : "Inteligencja to naprawdę rodzaj smaku: smak pomysģów"
Carl Sagan ,1934-1996, Amerykaņsji astronom pisarz , naukowiec : "Poznanie wielkiej sprawy nie jest tym samym, co bycie mądrym; inteligencja to nie tylko informacje, ale takŋe osąd, sposób, w jaki gromadzone i wykorzystywane są informacje. "
Linus Torvalds , 1969 - , Fiņski inŋynier : "Inteligencja to umiejętnoķæ unikania pracy, a jednak zdobywania moŋliwoķci ukoņczenia pracy"
Wydaje się, ŋe kaŋdy ma wģasną opinię na temat tego, czym jest inteligencja. Inteligencja to koncepcja, o której wszyscy wiedzą, ale rozumie ją inaczej. Jak widzieliķmy w poprzednim rozdziale, sposób, w jaki kaŋda osoba rozumie okreķloną koncepcję, będzie miaģ swój niepowtarzalny "smak". Byæ moŋe jednym z najciekawszych cytowaņ powyŋej jest Susan Sontag, która uŋywa analogii między smakiem i inteligencją. Smak to zģoŋona sensacja w czterech wymiarach - sģodyczy, kwaskowoķci, goryczy i sģonoķci. Podobnie inteligencja jest zģoŋoną koncepcją o wielu wymiarach. Inteligencja ma wiele aspektów - jej natury nie da się zdefiniowaæ za pomocą jednego z tych cytatów; wymaga ich wszystkich. Jako analogię, spróbuj opisaæ Mona Lisa. Opis malowania jednej osoby moŋe byæ anatemą dla innej osoby. Wyobražmy sobie, ŋe moŋemy oddaæ Mona Lisa do kilku napisanych sģów, a potem naiwnie uwierzyæ, ŋe inni ludzie zgodzą się z nami, ŋe jest to jedyny ostateczny opis, jest jak wierzenie, ŋe ludzie powinni tylko jeķæ jeden rodzaj jedzenia, lub cieszyæ się oglądaniem jednego rodzaju obrazu lub czytaæ jeden rodzaj ksiąŋki. Obraz Mona Lisa nadal inspiruje ludzi do pisania coraz więcej sģów na ten temat. Podobnie, inteligencja nie jest czymķ, co moŋemy definitywnie wyjaķniæ. Ale to nie powstrzyma ludzi przed kontynuowaniem tego, poniewaŋ dzięki temu moŋna uzyskaæ gģębszy wgląd w jego naturę. Chociaŋ definicje inteligencji są obarczone problemami, moŋemy poszukiwaæ poŋądanych wģaķciwoķci inteligencji, aby pomóc nam opisaæ naturę inteligencji. Innymi sģowy, moŋemy pomóc zdefiniowaæ naturę inteligencji, opisując, jak ona wygląda lub jak smakuje. Uŋywając analogii smaku, moŋemy pomyķleæ o tych wģaķciwoķciach jako o "skģadnikach" w przepisie na inteligencję - musimy je poģączyæ, aby nadaæ okreķlony smak, który niektórzy polubią, podczas gdy inni nie, preferując alternatywne smaki . Na przykģad moŋemy posģuŋyæ się analogią afrykaņskich i australijskich odkrywców, próbujących opisaæ, jak ŋyrafa lub dziobak wygląda na kogoķ, kto nigdy jej nie widziaģ. Badacze będą uŋywaæ sģów (pojęæ), które są im znane, takich jak "dģuga szyja" i "rybopodobny ogon", ale ich opis będzie "doprawiony" wģasną unikalną perspektywą. Bez względu na to, jakie sģowa wymyķlą, będą nadmiernie podkreķlaæ pewne cechy i zignorowaæ inne waŋne skģadniki. Podobnie, badacze AI z doķwiadczeniem w inŋynierii wiedzy i symbolicznym podejķciu do sztucznej inteligencji będą opisywaæ inteligencję uŋywając skģadników takich jak:
• zdolnoķæ do zdobywania i stosowania wiedzy;
• umiejętnoķæ rozumowania; i
• umiejętnoķæ podejmowania decyzji i planowania w celu osiągnięcia okreķlonego celu.
Naukowcy zajmujący się sztuczną inteligencją, którzy preferują podejķcie behawioralne, opisują inteligentne zachowanie ucieleķnionych, usytuowanych agentów, uŋywając skģadników takich jak:
• zdolnoķæ do dziaģania, które zewnętrzny inteligentny agent uznaģby za inteligentny;
• umiejętnoķæ zademonstrowania wiedzy na temat konsekwencji swoich dziaģaņ; i
• umiejętnoķæ zademonstrowania wiedzy o tym, jak wpģywaæ na ķrodowisko lub zmieniaæ jego otoczenie, aby wpģywaæ na wyniki i osiągaæ zaģoŋone cele.
Jeķli myķlimy o inteligencji za pomocą analogii mapowania, jak omówiono w poprzednim rozdziale, moŋemy uŋyæ następujących skģadników do opisania inteligencji:
• zdolnoķæ ucieleķnionego, usytuowanego agenta do mapowania ķrodowisk, zarówno rzeczywistych, jak i abstrakcyjnych (tj. Rozpoznawanie wzorców w celu dostarczenia uŋytecznych uproszczeņ i / lub charakterystyk ich ķrodowisk);
• umiejętnoķæ korzystania z map w celu poruszania się po otoczeniu;
• moŋliwoķæ aktualizacji map, gdy uzna, ŋe nie pasują one do rzeczywistoķci; i
• moŋliwoķæ przekazywania szczegóģów swoich map innym agentom.
Waŋne jest jednak, aby zdaæ sobie sprawę, ŋe nie są to ostateczne opisy, tylko skģadniki alternatywnych recept na inteligencję. W poprzednich częķciach widzieliķmy róŋne przykģady (implementowane jako modele w NetLogo), które wykazaģy niektóre z tych skģadników. Pod pewnymi względami modele te wykazywaģy niewielki stopieņ inteligencji w tym sensie, ŋe gdybyķmy zaobserwowali czynnika ludzkiego o tym samym zachowaniu, uznalibyķmy to za znak inteligencji. W następnym tomie tej serii ksiąŋek zobaczymy takŋe inne modele, które pokaŋą bardziej zaawansowane technologie. Moŋna jednak argumentowaæ, ŋe przykģady te nie wykazują ŋadnej prawdziwej inteligencji - ale oczywiķcie zaleŋy to od twojej wģasnej perspektywy, a takŋe od skģadników, które wybierzesz dla wģasnego przepisu na inteligencję
Inteligencja bez reprezentacji i rozsądku
W ostatniej częķci zadano pytanie, czy moŋna uzyskaæ wiedzę bez reprezentacji. Podobnie moŋemy zadaæ sobie następujące pytanie: "Czy moŋna mieæ inteligencję bez reprezentacji?" W przeģomowym artykule Rodney Brooks rozwaŋaģ dokģadnie to samo pytanie. W innym artykule rozwaŋyģ takŋe pokrewne pytanie: "Czy moŋliwe jest posiadanie inteligencji bez rozumowania?" Jak omówiono w poprzedniej sekcji, Brooks opowiada się za ucieleķnionym, usytuowanym podejķciem do AI - raczej pod-symboliczny paradygmat niŋ klasyczny symboliczny paradygmat. Kiedy mówi o moŋliwoķci inteligencji bez "reprezentacji", oznacza, ŋe ucieleķniony, poģoŋony agent nie musi jawnie reprezentowaæ swojego ķrodowiska - moŋe po prostu na nią reagowaæ. Agent nie musi mieæ wyražnej wiedzy o ķwiecie, w którym się znajduje, poniewaŋ agent moŋe bezpoķrednio "konsultowaæ" go poprzez interakcję z nim. Brooks idzie dalej i stwierdza, ŋe inteligencja jest wyģaniającą się wģasnoķcią pewnych zģoŋonych systemów (patrz cytat na początku tego rozdziaģu). Pomysģy Brooka są interesujące, poniewaŋ stwarzają moŋliwoķæ, ŋe w projektowaniu systemów sztucznej inteligencji nie będziemy musieli wykonywaæ caģej pracy samodzielnie. Jeķli uda nam się znaležæ wģaķciwy sposób na ustalenie warunków początkowych systemu, sam system wykona dla nas pracę, a dzięki samoorganizacji powstanie inteligencja. Niestety, choæ pomysģ ten jest bardzo intrygujący, nikt jeszcze nie zorientowaģ się, jak ustawiæ niezbędne warunki początkowe. Jak zauwaŋyli inni badacze, podejķcie Brooka do AI niekoniecznie jest wolne od reprezentacji czy rozumowania. "Wiedza" potrzebna robotom podobnym do owadów reagującym na reakcje, które jego zespóģ zbudowaģ, aby zademonstrowaæ swoje podejķcie, jest faktycznie reprezentowana w ramach architektury subsumption i skoņczonych automatów paņstwowych uŋywanych do projektowania robotów. (Dowiemy się o tym więcej w następnym tomie). Moŋna równieŋ argumentowaæ, ŋe ta architektura ma podstawową formę rozumowania, chociaŋ nie jest to to samo, co tradycyjna, symboliczna forma rozumowania w klasycznych kategoriach AI. Jeķli jednak przyjmiemy te argumenty, musimy równieŋ zgodziæ się, ŋe mrówki i termity opisane w poprzednich rozdziaģach równieŋ wykorzystują reprezentację i wykonuj rozumowanie - poniewaŋ wiedza "mrówki" jest definiowana przez jej instynktowne zachowania i rozproszona w caģym ķrodowisku, a nie w jakimķ wewnętrznym stanie, który jest dynamicznie aktualizowany w ramach jednego agenta. Wcielone podejķcie Brooka koncentruje się na specyficznych skģadnikach inteligencji. Teoria przestrzeni pojęciowych Gärdenfors oferuje alternatywne podejķcie hybrydowe, które próbuje wyjaķniæ, w jaki sposób mogą powstaæ dalsze skģadniki inteligencji, koncepcyjne, a takŋe symboliczne i pod-symboliczne. Dalsza eksploracja tych pomysģów jest konieczna, jeķli chcemy uzyskaæ niezbędne skģadniki dla inteligencji na poziomie ludzkim.
Co AI moŋe i nie moŋe zrobiæ
Dziedzina sztucznej inteligencji staģa się dla niektórych krytyczna na przestrzeni wielkich przepowiedni, z którymi jest często kojarzona, oraz postrzegana poraŋka pola w ich realizacji. Wielu badaczy w przeszģoķci popeģniģo bģąd, powaŋnie nie doceniając trudnoķci zadania. Herbert Simon przewidziaģ, ŋe do roku 1967 komputer stanie się mistrzem ķwiata w szachach - zajęģo to czas aŋ do roku 1997, zanim mistrz ķwiata zostaģ po raz pierwszy pobity przez kompute. Przewidywaģ takŋe (ponownie w 1967 roku), ŋe komputer będzie w stanie odkryæ nowe twierdzenie matematyczne i udowodniæ je. Odkrycie twierdzeņ matematycznych okazaģo się trudne - waŋne nowe twierdzenie nie zostaģo jeszcze odkryte przez komputer - chociaŋ techniki zautomatyzowanego dowodzenia twierdzeņ istnieją juŋ od jakiegoķ czasu (ponownie patrz poniŋej). Marvin Minsky, ponownie w 1967 roku, przewidziaģ, ŋe problem tworzenia sztucznej inteligencji zostanie rozwiązany w ciągu pokolenia. Przewidywania wczesnych naukowców zajmujących się sztuczną inteligencją stanowiģy inspirację dla Stanleya Kubricka i komputera Hal C. Clarke'a . HAL 9000, który zacząģ funkcjonowaæ w ich historii w 1992 roku. Prawie dwie dekady póžniej ich wizja komputerów o zdolnoķciach emocjonalnych i konwersacyjnych wciąŋ jest daleka od rzeczywistoķci. Dalsze roszczenia zostaģy poczynione w odniesieniu do bardziej szczegóģowych podpól AI - to na przykģad w 1957 r. twierdzono, ŋe tģumaczenie maszynowe zostanie rozwiązane w ciągu trzech do pięciu lat. Kaŋdy, kto dziķ korzysta z usģug tģumaczenia maszynowego online lub oprogramowania do tģumaczenia maszynowego, będzie ķwiadomy, ŋe jest to dalekie od przypadku. Dzisiejsze prognozy mówią, ŋe do 2020 roku będziemy dysponowaæ komputerami o większej mocy obliczeniowej niŋ mózg i robotami o inteligencji ludzkiej do roku 2050, a nawet robotami zdolnymi do bicia ludzi w piģce noŋnej (takŋe do 2050 roku). Ray Kurzweil w Erze Inteligentnych Maszyn dokonaģ wielu przewidywaņ dotyczących technologii komputerowej i sztucznej inteligencji, w szczególnoķci, z których wiele się speģniģo, ale niektóre z nich nie (takie jak przewidywania, ŋe do 2009 r. Uŋytkownicy będą polegaæ gģównie na rozpoznawaniu mowy w celu komunikacji z komputerami, a nie klawiaturą). W The Singularity jest blisko: Kiedy Humans Transcend Biology, postuluje to, co nazywa "Osobliwoķcią" występującą w naszym ŋyciu (w 2045 r.). To będzie destrukcyjne, zmieniające ķwiat wydarzenie, które na zawsze zmieni bieg ludzkiej historii i stanie się, gdy nadprzyrodzone ludzkie istoty będą najbardziej inteligentnymi istotami na planecie. Odtąd rozwój technologiczny zostanie przejęty przez maszyny, a my, jako ludzie, nie będziemy juŋ w stanie nadąŋyæ. Bardzo trudno jest przewidzieæ przyszģoķæ, szczególnie jeķli chodzi o zaawansowanie technologiczne, i czy prognozy Kurzweila się pojawią, będziemy musieli poczekaæ i zobaczyæ. Zamiast przewidywaæ, co AI moŋe osiągnąæ w przyszģoķci, moŋemy zamiast tego zbadaæ, co AI osiągnęģo w przeszģoķci, a takŋe spojrzeæ na teražniejszoķæ. Na przykģad poniŋsza lista wymienia dwanaķcie zadaņ, do których moŋemy zastosowaæ sztuczną inteligencję. Pierwsze dziewięæ pozycji na tej liķcie pochodzi z æwiczenia (1.7) autorstwa Russella i Norviga. We wszystkich tych zadaniach osiągnięto sukcesy w sztucznej inteligencji w róŋnym stopniu. Stopieņ sukcesu jest jednak otwarty na debatę. Na przykģad, jaka jest przyzwoita gra w tenisa stoģowego? Odpowiedž jest subiektywna - róŋnica w standardzie między dzieckiem lub kompletnym nowicjuszem a mistrzem olimpijskim jest znaczna. Robot TOPOS TOSY moŋe wchodziæ w interakcje z czģowiekiem, aby graæ w tenisa stoģowego w ograniczonym zakresie. Ale w peģni autonomiczna rozgrywka turniejowa znacznie wykracza poza jej moŋliwoķci.
1. Rozegraj przyzwoitą grę w tenisa stoģowego.
2. Jedž do centrum Kairu.
3. Robienie tygodniowych zakupów artykuģów spoŋywczych na rynku lub w Internecie.
4. Rozegraj przyzwoitą grę w brydŋ na konkurencyjnym poziomie.
5. Odkrywaj i udowadniaj matematyczne twierdzenia.
6. Napisz celowo zabawną historię.
7. Udziel kompetentnej porady prawnej w specjalistycznej dziedzinie prawa.
8. Przetģumacz mówiony język angielski na mówiony język szwedzki w czasie rzeczywistym.
9. Wykonaj zģoŋoną operację chirurgiczną.
10. Rozpoznawaj i estetycznie doceniaj Mona Lisa.
11. Stwórz wirtualnego Elvisa.
12. Wykonaj wszystkie powyŋsze czynnoķci.
W konkursie DARPA Grand Challenge na rok 2007 przewidziano "Urban Challenge", w którym autonomiczne pojazdy musiaģy pokonaæ 96 km przebiegu w czasie krótszym niŋ 6 godzin, przestrzegając wszystkich przepisów ruchu drogowego, unikając przeszkód i innych ruchów. Szeķæ pojazdów z powodzeniem ukoņczyģo kurs. Test ten przeprowadzono jednak w kontrolowanym ķrodowisku Bazy Siģ Powietrznych George'a - w centrum Kairu (i innych duŋych miast) to kolejna sprawa, która podnosi trudnoķæ na zupeģnie nowy poziom z powodu nieprzewidywalnoķci innych kierowców i pieszych . General Motors ogģosiģ niedawno, ŋe jest sterowany komputerowo system wykorzystujący lasery i kamerę wideo do Opla Vectry 2008 o nazwie "Traffic Assist", który będzie mógģ autonomicznie prowadziæ samochód przy duŋym natęŋeniu ruchu z prędkoķcią do 60 mph. Będzie miaģ moŋliwoķæ rozpoznawania znaków i omijania przeszkód, sterowania przyspieszeniem, kierowaniem i hamowaniem, a takŋe wprowadzania zmian kursu i prędkoķci w razie potrzeby. To, czy ludzie byliby gotowi pozwoliæ sobie na takie luki, jak w samym ķrodku Kairu, to inna kwestia. Kupowanie artykuģów spoŋywczych to zadanie, które ludzie często wykonują. Dla większoķci osób niepeģnosprawnych jest to stosunkowo ģatwa do wykonania. Nawet najbardziej podstawowe zadania, takie jak pakowanie artykuģów spoŋywczych (problem uznany przez Patrick Winston w 1992 r.) lub zakupy przez Internet (Russell i Norvig) są trudne dla systemu AI . Negocjowanie sposobu poruszania się po ruchliwym rynku, rozpoznawanie i sprawdzanie jakoķci przedmiotów, które są na sprzedaŋ, i bezpoķrednie targowanie się z wģaķcicielami stoisk za cenę, są nadal daleko poza obecnymi systemami sztucznej inteligencji. Program komputerowy GIB byģ w stanie ograæ wszystko oprócz 11 najlepszych ķwiatowych graczy na Mistrzostwach Ķwiata w Lille we Francji w 1998 roku. Najlepsze programy komputerowe, takie jak Jack, mogą graæ na równych warunkach przeciwko graczom ķredniego poziomu. Jednak pole mostu komputerowego jest wciąŋ w powijakach. AI odniosģo sukces grając w szachy przeciwko ludzkim komponentom, w szczególnoķci Deep Blue pokonując mistrza ķwiata Gary'ego Kasparowa w 1997 roku, a ostatnio Deep Fritz pokonując mistrza ķwiata Vladimira Kramnika w 2006 roku. Do gry Go, gdzie przestrzeņ poszukiwaņ jest o wiele większy, programy komputerowe zaczynają graæ na profesjonalnym poziomie, ale róŋnica jest nadal znaczna dla poziomu gry naprawdę silnych graczy ludzkich. Automatyczne dowodzenie twierdzeņ lub automatyczne wnioskowanie zostaģo dobrze zbadane w AI. Udowadniacz twierdzeņ OTTER autorstwa Art Quaife, na przykģad, udowodniģ ponad 400 twierdzeņ teorii mnogoķci, ponad 1200 twierdzeņ teorii liczb, a takŋe twierdzenia o geometrii euklidesowej i twierdzenia o niezupeģnoķci Gödla. Obecnie trudniejszym wyzwaniem, które jest obecnie badane, jest automatyczne rozpoznawanie twierdzeņ przy uŋyciu zestawu aksjomatów domeny. Warunkiem, który sprawia, ŋe jest to szczególnie trudne, jest to, ŋe odkryte twierdzenia powinny byæ interesujące zarówno dla ludzi, jak i trudne do udowodnienia ludziom i automatycznym systemom dowodzenia twierdzeņ. Generowanie języka naturalnego jest czcigodnym podzakresem przetwarzania języka naturalnego, który obejmuje automatyczne generowanie tekstu pisanego. Generowanie fabuģy zajmuje się wyģącznie problemem uzyskania komputera do automatycznego napisania opowiadania. Często wyniki produkowane przez niektóre programy komputerowe generujące opowieķci są niezamieķcie zabawne z powodu absurdalnoķci kombinacji sģów i fraz, które często wynikają z losowego procesu selekcji. Generowanie intencjonalnego humoru, który jest jednoczeķnie nowy i unikalny, jest znacznie bardziej zģoŋony. Podobnie, tworząc opowieķæ ze zģoŋonoķcią Ulysses Jamesa Joyce'a, "wyczuwalną blaskiem" i ciepģem Harper Lee's To Kill a Mockingbird, satyrycznym humorem Paragrafu 22 Josepha Hellera i krzykliwą absurdią Autostartu Douglasa Adama autostopu: A Trylogia w pięciu częķciach wykracza daleko poza to, co komputer moŋe obecnie produkowaæ. Techniki z pól sztucznej inteligencji systemów eksperckich i systemów wyszukiwania informacji zostaģy dostosowane do tworzenia systemów doradztwa prawnego i powielaæ legalne rozumowanie sędziów. System ekspercki jest konsultowany w celu rozwiązania konkretnego przypadku, a do przeszukiwania dokumentacji sģuŋy system wyszukiwania informacji znaležæ podobne przypadki. Oczywiķcie te systemy doradztwa prawnego nie mają jeszcze zdolnoķci prawdziwych prawników, takich jak ci, którzy dyskutują o prawnej zawiģoķci w sprawie Bright Tunes Music przeciwko Harrisongs Music (gdzie z powodzeniem przekonywano, ŋe "Mój sģodki lord" George'a Harrisona byģ naruszeniem praw autorskich czuje się dobrze). Gdyby te systemy miaģy te same moŋliwoķci, bylibyķmy teraz w stanie zastąpiæ wszystkich prawników komputerami. Rozpoznawanie mowy i oprogramowanie do tģumaczenia maszynowego o róŋnych moŋliwoķciach istnieje juŋ od wczesnych lat szeķædziesiątych. Wyszukiwarki coraz częķciej uŋywają tego drugiego, aby pomóc ludziom czytaæ dokumenty online w innym języku. Automatyczne przetwarzanie języka naturalnego jest szczególnie trudnym problemem dla komputerów, poniewaŋ tolerancja rodzimych uŋytkowników języka na bģędy jest bardzo niska. Na przykģad systemy rozpoznawania mowy często reklamują wyniki dokģadnoķci powyŋej 90%. Brzmi to wystarczająco dobrze, ale byģoby nam bardzo trudno tolerowaæ sģuchanie innej osoby, gdyby popeģniģ aŋ 10 bģędów na kaŋde 100 wypowiedzianych sģów. Wyniki dla tģumaczenia maszynowego są znacznie niŋsze w porównaniu, często w wyniku niedopasowania między dwoma róŋnymi systemami pojęciowymi wyraŋonymi przez języki žródģowe i docelowe. W związku z tym trudnoķci w wykonywaniu symultanicznego tģumaczenia języka mówionego, w którym moŋe występowaæ znaczący haģas. Ponadto tģumaczenie symultaniczne wymaga zdolnoķci konwersacyjnych. Mimo ŋe wiele witryn twierdzi inaczej, ŋaden aktualny chatbot ani agent rozmowy nie jest w stanie przeprowadziæ wiarygodnej rozmowy z daną osobą, lub jest w stanie przejķæ testu Turinga. Systemy te zachowują jedynie podobieņstwo do rozmowy, a ich niedoskonaģoķci są wyražnie widoczne po krótkiej rozmowie. Robotyka zrobiģa znaczący postęp w ostatnich latach. Moŋna go scharakteryzowaæ za pomocą technik, które wykorzystują rosnący poziom automatycznej autonomii. Zdalna operacja (lub telekurgia) wykorzystuje robotykę, aby umoŋliwiæ wykonanie operacji zdalnie przez czģowieka. Zazwyczaj wymaga to chirurgii maģoinwazyjnej za pomocą chirurgicznych urządzeņ z dziurką od klucza ze zdalnym sterowaniem. Bezobsģugowa operacja polega na zastosowaniu w peģni autonomicznych chirurgów-robotów i odniosģa ostatnio sukces. Pierwsza bezzaģogowa operacja chirurgiczna miaģa miejsce w maju 2006 r. We Wģoszech u 47-letniego męŋczyzny w celu skorygowania arytmii serca, operacja zostaģa oceniona jako lepsza niŋ ta wykonywana przez ponad przeciętnego chirurga ludzkiego. W styczniu 2009 r. przeprowadzono pierwszy w peģni zautomatyzowany przeszczep nerki w New Jersey. Te duŋe postępy w dziedzinie robotyki i procedur medycznych spowodowaģy znacznie większą precyzję chirurgiczną i mniejsze nacięcia, prowadząc do mniejszego bólu, mniejszej utraty krwi i krótszych czasów gojenia. Oprogramowanie do rozpoznawania twarzy poczyniģo znaczne postępy na przestrzeni lat. Obecnie jest on wykorzystywany w wielu miejscach, takich jak lotniska, do automatycznego rozpoznawania przestępców i terrorystów oraz w systemach bezpieczeņstwa dla biometrii. Na przykģad oprogramowanie do rozpoznawania twarzy zostaģo wykorzystane do zidentyfikowania 19 osób, które aresztowano ,gwarantuje, ŋe w Super Bowl w Tampa Bay na Florydzie w 2001 r. oprogramowanie jest dalekie od ideaģu, zmaga się z obrazami w niskiej rozdzielczoķci i sģabym oķwietleniem, są problemy z prywatnoķcią i mogą je ominąæ osoby noszące okulary przeciwsģoneczne lub uŋywające róŋnych wyrazów twarzy, takich jak jako duŋy uķmiech. Wystąpiģy problemy z wczesnymi systemami - na przykģad rozmieszczenie w londyņskiej dzielnicy Newham nie rozpoznaģo ani jednego przestępcy w ciągu kilku lat. Ostatnie postępy odnotowaģy znaczną poprawę dokģadnoķci, przewyŋszając ludzi w niektórych eksperymentach, w tym wykazując zdolnoķæ do rozróŋnienia między identycznymi bližniętami. Najwyražniej prostym zastosowaniem tego oprogramowania byģoby rozpoznanie obrazu takiego jak Mona Lisa. Znacznie trudniejsza jest klasyfikacja duŋej liczby obrazów do wyszukiwania obrazów w skali internetowej. Wyszukiwarki wciąŋ opierają się gģównie na otaczającym tekķcie w dokumentach internetowych, aby pomóc w identyfikacji obrazów, poniewaŋ osiąga to efektywne wyniki, jest znacznie szybsze i wymaga znacznie mniej zasobów. Peģna estetyka artystycznych obrazów, takich jak Mona Lisa, która tworzy wyjątkową i krytyczną analizę róŋnic w stylu malarskim i treķci, jest równieŋ poza obecną technologią. Przechwytywanie ruchu (zwane takŋe mocap) to technika uŋywana do animacji w filmach i grach komputerowych, która rejestruje ruch czģowieka lub zwierzęcia, a następnie generuje realistyczny ruch wirtualnie za pomocą modelu cyfrowego. Techniki Mocap uŋyte na przykģad w filmie King Konga Petera Jacksona umoŋliwiģy tworzenie wirtualnych debetów dla gģównych postaci, które są tak dobre, ŋe trudno je odróŋniæ od prawdziwych. Wirtualny Elvis, który improwizuje w czasie rzeczywistym ze zdolnoķcią do ķpiewania nowych piosenek, które nie zostaģy wczeķniej nagrane, gdy ŋyģ (w przeciwieņstwie do wirtualnego Elvisa, który ķpiewaģ z Celine Dion w American Idol), jest wciąŋ poza najnowszym stanem wiedzy. Ģącznie ludzie są w stanie wykonaæ wszystkie zadania wymienione w powyŋszych zadaniach. Jednak jest maģo prawdopodobne, by istniaģ jeden czģowiek, który istnieje dzisiaj, który moŋe wykonaæ wszystkie te zadania samodzielnie, chyba ŋe jest znany szwedzkim chirurgie, który jest podziwiany za swoją sztukę, który jest arcymistrzem szachów zajmujących się prawem, matematyką i animacją komputerową, który jest zabawne. Spodziewanie się, ŋe sztuczna inteligencja wykona wszystkie te zadania, moŋe podnieķæ poprzeczkę zbyt wysoko w stosunku do naszych oczekiwaņ co do tego, czym jest lub powinna byæ sztuczna inteligencja.
Potrzeba zaprojektowania celów sztucznej inteligencji
Jedną z gģównych trudnoķci w badaniach nad sztuczną inteligencją jest to, ŋe nie udaģo się jej jeszcze opracowaæ realistycznej definicji inteligencji. Definiowanie inteligencji jest obarczone problemami i od stuleci jest žródģem filozoficznych debat. Z pragmatycznego punktu widzenia, projektując systemy wykazujące sztuczną inteligencję, moŋemy przyjąæ perspektywę inŋynierską - wiemy, czym jest inteligencja, dowiemy się, kiedy nasze systemy demonstrują inteligencję, gdy je obserwujemy, więc niekoniecznie musimy definiowaæ, co to jest. Jednak to unikanie podawania definicji inteligencji z góry prowadzi do braku dokģadnoķci w literaturze i badaniach. Terminy "sztuczna inteligencja" i "systemy inteligentne" są często naduŋywane z bardzo maģym uzasadnieniem, dlaczego system jest "inteligentny". Bez definicji inteligencji problemem staje się to, ŋe nie jest juŋ jasne, czy to, co zostaģo zbudowane naprawdę, jest w rzeczywistoķci "inteligentne". Wczesne systemy sztucznej inteligencji w latach siedemdziesiątych i osiemdziesiątych cierpiaģy na brak oceny - istniaģo pęd do budowy nowych systemów, ale często przeprowadzono bardzo niewiele oceny tego, na ile systemy dziaģają. Bez dziaģającej definicji inteligencji ten sam problem występuje obecnie w przypadku obecnych systemów sztucznej inteligencji - w jaki sposób moŋemy oceniæ, jak skuteczny moŋe byæ nasz system AI, jeķli nie mamy definicji tego, co powinno byæ (a nawet osiągnąæ lub zrobiæ)? Moŋemy jednak uniknąæ filozofii Moŋemy jednak uniknąæ filozoficznych puģapek i zamiast próbowaæ zdefiniowaæ inteligencję, i twierdząc, ŋe ta definicja jest "wģaķciwa", zamiast tego moŋemy zaproponowaæ cele projektowe dla systemów sztucznej inteligencji, które chcemy budowaæ. Moŋemy stwierdziæ, ŋe z punktu widzenia projektowania są to cele, które chcemy osiągnąæ w naszym systemie sztucznej inteligencji. Następnie moŋemy zaproponowaæ te cele, dodawaæ nowe i zmieniaæ istniejące, tak jak uwaŋamy, aby poprawiæ projekt, poniewaŋ sami jesteķmy projektantami. Inne osoby mogą krytykowaæ, czy nasze cele są opģacalne z punktu widzenia inŋynierii (tj. Nie produkują "dobrych" programów lub nie są tak dobre, jak inne podejķcia), ale debata filozoficzna jest istotna tylko w tym sensie, ŋe moŋe pomóc w informowaniu i ulepszyæ nasz projekt. Ocena staje się teraz prostsza - wszystko, co musimy zrobiæ, to oceniæ, czy osiągnęliķmy nasze cele projektowe.
Jakie są dobre cele?
Jakie są jednak dobre cele? Najpierw musimy spojrzeæ na to, co stanowi dobry cel. W zarządzaniu projektami istnieje dobrze znany akronim, który sģuŋy do tworzenia dobrych celów - SMARTER - gdzie kaŋda litera w akronimie oznacza poŋądane atrybuty. Projektant moŋe zadawaæ pytania o odpowiednioķæ proponowanego przez niego celu - czy jest on konkretny, czy moŋe byæ mierzalny, czy jest moŋliwy do osiągnięcia, czy ma okreķlony termin i tak dalej. Wyznaczanie dobrych celów jest jednak bardziej sztuką niŋ nauką, co moŋe odzwierciedlaæ nieporozumienie dotyczące terminów uŋywanych dla kaŋdej litery. Byæ moŋe terminy najbardziej istotne dla badaņ nad sztuczną inteligencją to pierwsze cztery gģówne terminy - potrzeba, by cele byģy konkretne, mierzalne, osiągalne i w mniejszym stopniu realistyczne. Charakter tych atrybutów będzie z czasem ulegaģ zmianie w związku z postępem - w miarę zdobywania wiedzy o tym, co jest osiągalne, o tym, co jest teraz realistyczne w porównaniu z tym, co byģo wczeķniej, oraz z ulepszeņ dokonanych w metodach oceny lub pomiaru systemów, które zostaģy zbudowane.
Niektóre cele projektowe w zakresie sztucznej inteligencji
Jakie są jednak dobre cele projektowe w Sztucznej Inteligencji? Aby opracowaæ odpowiednie cele, najpierw musimy zaproponowaæ ogólny cel projektu. Jednym z celów projektu moŋe byæ dąŋenie do naķladowania ludzkiej inteligencji. Ogólna motywacja do zrobienia tego jest dwojakie - po pierwsze, abyķmy mogli zbudowaæ inteligentne artefakty, które mogą nam w pewien sposób pomóc, a po drugie, abyķmy mogli w rezultacie lepiej zrozumieæ wģasną inteligencję. Jednak nasza inteligencja jest skomplikowana, zagadkowa i pod wieloma względami ukryta przed nami. Mamy etykiety dla aspektów naszej inteligencji, które często wykorzystujemy, aby odróŋniæ się od innych zwierząt, takich jak kompetentne zachowanie, inteligentne zachowanie, racjonalnoķæ, samoķwiadomoķæ, zamyķlenie i ķwiadomoķæ, i byæ moŋe moŋemy uŋyæ ich dla naszych celów projektowych, jak pokazano poniŋej.
Zasada projektowania 1: System AI powinien byæ systemem zorientowanym na agenta.
Cel projektu 1: System sztucznej inteligencji powinien naķladowaæ ludzką inteligencję.
Cel projektu 1.1: System sztucznej inteligencji powinien dziaģaæ w sposób kompetentny.
Cel projektu 1.2: System sztucznej inteligencji powinien dziaģaæ inteligentnie.
Cel projektu 1.3: System sztucznej inteligencji powinien dziaģaæ racjonalnie.
Cel projektu 1.4: System sztucznej inteligencji powinien dziaģaæ tak, jakby byģ samoķwiadomy.
Cel projektu 1.5: System sztucznej inteligencji powinien dziaģaæ tak, jak myķli.
Cel projektu 1.6: System sztucznej inteligencji powinien dziaģaæ tak, jakby byģ ķwiadomy
Oczywistym bģędem w realizacji tych celów projektowych jest to, ŋe w oczywisty sposób ģamią one SPRYTNE cele mnemoniczne dla wszystkich gģównych atrybutów:
o Nie są wystarczająco szczegóģowe, poniewaŋ nie mamy obecnie praktycznych definicji wiedzy, inteligencji, racjonalnoķci, samoķwiadomoķci, zamyķlenia i ķwiadomoķci, przynajmniej w tym sensie, ŋe mogą nam one pomóc w informowaniu nas, jak budowaæ systemy, które wykazują takie cechy.
o Nie jest jasne, czy cele te są moŋliwe do osiągnięcia - w następnej dekadzie, w naszym ŋyciu, a nawet w ogóle. Dlatego te cele mogą nie byæ nawet realistyczne.
o Ustalenie ostatecznego ograniczenia czasowego jest obecnie niemoŋliwe. Z pewnoķcią nie chcemy wpaķæ w tę samą puģapkę, w jaką poprzedni poplecznicy AI wpadli w poprzednich dekadach, kiedy twierdzili, ŋe wszelkie rozwiązania znajdą się w "niezbyt odlegģej przyszģoķci".
Więc, oczywiķcie, nie wydają się to bardzo dobrymi celami. Jednak celem, który system dziaģa w sposób kompetentny (cel projektu 1.1), jest ukryty cel dla systemu opartego na wiedzy, cel projektu 1.2 jest ukrytym celem dla systemów inteligentnych, a pozostaģe są kluczowymi aspektami inteligencji czģowieka, którą będziemy musieli naķladowaæ, aby osiągnąæ cel projektu 1. Oczywiķcie musimy byæ bardziej konkretni z naszymi celami projektowymi. Ponadto nie jest jasne, jak osiągalny jest kaŋdy z tych celów. Na pierwszy rzut oka, jeķli chodzi o pierwszy cel, czyli dziaģanie w sposób kompetentny, moŋna argumentowaæ, ŋe takie systemy istnieją juŋ dziķ. Dlatego ten cel moŋe wydawaæ się ģatwiejsze do osiągnięcia niŋ inne cele. Ale co to naprawdę znaczy dziaģaæ w sposób kompetentny? Ponadto, co rozumiemy przez "wiedzę" w tej sprawie? Jeķli mamy na myķli to, ŋe system zorientowany na agenta musi mieæ wystarczającą wiedzę o swoim ķrodowisku, o sobie i innych agentach, aby mógģ dziaģaæ w sposób kompetentny i wykazaæ zrozumienie tej wiedzy, wtedy osiągnięcie wiedzy moŋe byæ równie trudne, jak osiągnięcie jakiegokolwiek z inne cele. W rzeczywistoķci moŋe byæ kluczem do innych celów, a gdy zostanie osiągnięty, pozostaģe mogą byæ ģatwiejsze do osiągnięcia. Moŋna równieŋ argumentowaæ, ŋe cel, jakim jest inteligentne zachowanie systemu (Cel Projektu 1.2) obejmuje juŋ inne cele - system musi juŋ wykazywaæ wiedzę, racjonalnoķæ, samoķwiadomoķæ, zamyķlenie i ķwiadomoķæ, jeķli ma naķladowaæ inteligentne ludzkie zachowanie. Jednak zaleŋy to od tego, jak zdefiniujemy te wģaķciwoķci. Jeķli chcemy uŋywaæ terminu "inteligencja" w sposób podobny do tego, jak uŋywamy go w języku angielskim, sugerowaģoby to, ŋe węŋsza definicja moŋe byæ bardziej odpowiednia. Na przykģad moŋemy powiedzieæ (po angielsku), ŋe matematyk wykazuje inteligencję podczas rozwiązywania równania, a wynalazca wykazuje inteligencję podczas tworzenia nowego projektu systemu, który moŋna opatentowaæ. Jednak systemy komputerowe juŋ wykazaģy zdolnoķæ do wykonywania obu zadaņ w poszczególnych domenach. Moŋna więc twierdziæ, ŋe komputery juŋ wykazywaģy inteligencję, przynajmniej w wąskim znaczeniu, ŋe termin ten jest uŋywany w tym kontekķcie. Jednakŋe, chociaŋ wszyscy zgodziliby się, ŋe matematyk i wynalazca są zamyķleni i ķwiadomi, bardzo niewiele osób zgodziģoby się, ŋe te systemy komputerowe wykazują takie wģaķciwoķci. Waŋnym aspektem inteligencji jest umiejętnoķæ rozwiązywania problemów. Systemy AI wykazaģy szeroką gamę moŋliwoķci rozwiązywania problemów, z róŋnym powodzeniem. Jednak systemy AI nie wykazaģy jeszcze zdolnoķci do podjęcia przyzwoitego wysiģku, aby samodzielnie rozwiązaæ te problemy, bez korzyķci pģynących z rozwiązaņ opracowanych przez ludzi, ucząc się, jak rozwiązywaæ je od zera poprzez nauczanie przez nauczyciela zewnętrznego lub przez nauczyciela zewnętrznego. stopniowe doskonalenie dzięki próbom i bģędom. Znakiem ludzkiej inteligencji jest to, ŋe potrafimy rozwiązywaæ zģoŋone zadania, zaczynając jako nowicjusze i ucząc się przez doķwiadczenie, jak staæ się ekspertami. Co waŋne, moŋemy równieŋ dostosowaæ rozwiązania z jednej dziedziny problemowej do drugiej, wprowadzając innowacje, a takŋe mamy moŋliwoķæ wymyķlania zupeģnie nowych rozwiązaņ. Jednym ze sposobów na bardziej szczegóģowe okreķlenie naszych celów projektowych jest wyražne okreķlenie, w jaki sposób będziemy mierzyæ, kiedy zostaną osiągnięte. Byæ moŋe moŋemy uŋyæ testu Turinga jako testu kandydata na inteligencję konwersacyjną, aby bardziej szczegóģowo zdefiniowaæ Cel Projektu 1.2. Ale co z innymi celami projektowymi? Czy istnieją inne testy, których moŋemy uŋyæ lub wymyķliæ, które mogą nam pomóc? Rzeczywiķcie istnieje - na przykģad istnieje dobrze znany test samoķwiadomoķci.
Eksperyment Myķlowy : Test Lustra dla samoķwiadomoķci.
The Mirror Test, zaproponowany przez Gordona Gallupa Jr. w 1970 roku, jest testem samoķwiadomoķci u zwierząt. Pomysģ polega na umieszczeniu zwierzęcia w pokoju z lustrem. Dwie plamki są ukradkowo oznaczone na zwierzęciu za pomocą barwnika (byæ moŋe podczas znieczulenia zwierzęcia) - jeden jest punktem kontrolnym umieszczonym w ukrytej, ale dostępnej częķci ciaģa, drugi jest widoczny tylko przez lustro (na przykģad na czole między oczami dla naczelnych). Mówi się, ŋe zwierzę przechodzi test samoķwiadomoķci, jeķli zauwaŋy drugie miejsce, ale ignoruje pierwsze, tym samym demonstrując, ŋe zwierzę jest w stanie rozpoznaæ wģasne odbicie w lustrze. Zwierzęta, które przeszģy test lustra to maģpy czģekoksztaģtne (bonobo, szympansy, orangutany i goryle), delfiny butlonose, orki, sģonie i europejskie sroki. Podobnie jak w teķcie Turinga na inteligencję, test lustra samoķwiadomoķci ma swoich krytyków. Chociaŋ intensywnie testowano na naczelnych, niektórzy twierdzą, ŋe test nie jest odpowiedni dla zwierząt, które nie opierają się na wizji jako ich gģównym znaczeniu, takich jak psy, które bardziej polegają na zapachu lub zwierzęta, które nie mają widzenia stereoskopowego (króliki i jelenie ) lub zwierzęta, które mogą unikaæ kontaktu z oczami. Dlatego test jest jedynie testem umiejętnoķci ķciķle odpowiadających umiejętnoķciom ludzi. Co ciekawe, robot o nazwie Nico przeszedģ juŋ test lusterek. Robot zostaģ opracowany w ramach projektu Yale Social Robotics Project, którego celem jest zbudowanie antropomorficznych robotów, które wchodzą w interakcje z ludžmi wykorzystującymi naturalne sygnaģy spoģeczne. Nico potrafi rozpoznawaæ wģasne odbicie w lustrze, ale robi to tylko rozpoznając wģasny ruch. Jednak byæ moŋe to wszystko, co robią szympansy. Nico wydaje się podobny do tego, który jest ķwiadomym istotą. Gdyby Nico wyglądaģ bardziej jak czģowiek, jak moglibyķmy odróŋniæ? Zasadniczo jest to ten sam argument na korzyķæ testu Turinga. Jeķli nie jesteķmy w stanie odróŋniæ zachowania, to z obserwacyjnego punktu widzenia (tj. Z ukģadu odniesienia agenta dokonującego obserwacji) atrybut samoķwiadomoķci - i podobnie inteligencji do testu Turinga - ma dla wszystkie zamiary i cele zostaģy "osiągnięte" w obserwowanym czynniku. Chociaŋ Nico jest w stanie zdaæ ten test (tj. Jest w stanie naķladowaæ takie zachowanie), wyražnie nie wykazuje samoķwiadomoķci w taki sam sposób jak ludzie. Dlatego nasza definicja samoķwiadomoķci jest zbyt prosta - musimy ją w jakiķ sposób rozszerzyæ, aby objąæ zdolnoķci czģowieka. Kiedy to zrobimy, moŋemy następnie próbowaæ budowaæ roboty, które wykazują zachowanie zgodnie z rozszerzoną definicją. Chociaŋ eksperymenty takie jak te mają swoich krytyków, ten przykģad ilustruje, w jaki sposób prowadzą one do lepszego zrozumienia naszej wģasnej inteligencji.
A co z innymi celami projektowymi? Racjonalnoķæ jest atrybutem często przypisywanym agentom inteligentnym - ale co dokģadnie mamy na myķli, gdy uŋywamy tego terminu? Poniewaŋ naszym ogólnym celem projektowym jest naķladowanie ludzi, moŋemy spojrzeæ na siebie jako inspirację do zdefiniowania, co moŋe byæ racjonalnym zachowaniem, a nie irracjonalnym zachowaniem. Na przykģad, nie byģoby racjonalne, aby ktoķ wyrządziģ sobie krzywdę. Nie byģoby racjonalne dla tej osoby, po znalezieniu lekarstwa na raka, a następnie, aby nie powiedzieæ o tym innym ludziom. Oznacza to, ŋe moŋemy uwaŋaæ (przez powszechne uŋycie tego terminu w języku naturalnym), ŋe dzielenie się wiedzą jest racjonalną rzeczą do zrobienia. Racjonalnoķæ wiąŋe się takŋe z osobistymi preferencjami - na przykģad jedna osoba moŋe myķleæ, ŋe bycie wegetarianinem jest irracjonalne, a jednak wegetarianin moŋe pomyķleæ wręcz przeciwnie, ŋe zamiast tego ktoķ, kto je mięso, jest irracjonalny. Moŋemy wstępnie okreķliæ, ŋe agent dziaģa racjonalnie, jeķli zawsze dziaģa, aby zapewniæ sobie wģasne przetrwanie i przetrwanie wģasnej rodziny lub innych osób w swoim rodzaju. Następnie moglibyķmy opracowaæ testy, aby zobaczyæ, jak dziaģa agent w sytuacjach, w których musi zdecydowaæ między róŋnymi kierunkami dziaģaņ. Moŋemy tworzyæ takie sytuacje w ķrodowisku wirtualnym lub w rzeczywistym ķrodowisku dla robotów. Czy na przykģad robot dziaģa w sposób racjonalny podobny do czģowieka, gdy ma do wyboru bezpieczny wylot z pģonącego budynku lub przejķcie przez ķcianę ognia, aby dowiedzieæ się, czy w budynku wciąŋ ŋyją inne osoby? , kiedy wie, ŋe takie dziaģanie prawie na pewno doprowadzi do prawdopodobnej ķmierci? Racjonalna istota moŋe najpierw rozwaŋyæ wģasne przetrwanie, podczas gdy robot bez umiejętnoķci myķlenia w ten sposób jest po prostu podąŋaniem za zaprogramowaną sekwencją dziaģaņ (tj. Nie jest ani racjonalny, ani irracjonalny, tylko program). Rozwaŋnoķæ i ķwiadomoķæ są uwaŋane przez niektórych za "ķwiętych grails" Sztucznej Inteligencji. Nie jest jasne, w jaki sposób moŋemy zmierzyæ te atrybuty. Byæ moŋe najlepszą rzeczą, jaką moŋemy teraz zrobiæ, to uznaæ problem, pozostawiając cele projektowe dla tych atrybutów tak nieprecyzyjne, jak w Projekcie 10.1, i odkģadaj problem na bok, dopóki nie zrozumiemy ich lepiej i jak moglibyķmy zmierzyæ, kiedy zostaną osiągnięte. Eksperyment Myķlowy 2 proponuje jedną moŋliwą drogę naprzód. Moŋemy równieŋ rozwaŋyæ alternatywny test na inteligencję. Często uŋywanym terminem w branŋy gier i filmów jest "zawieszenie niewiary". Oznacza to, ŋe celem twórców jest zawieszenie w umyķle osoby grającej w grę lub oglądanie filmu ich przekonanie, ŋe nie jest prawdziwe - im dģuŋej zawieszenie niewiary, tym lepsza rozrywka. W pewnym sensie projektanci gier i filmów opowiadają historię - chcą, aby ludzie byli zanurzeni w narracji, którą stworzyli, tak jak autor powieķci chce, aby jej czytelnicy zanurzyli się w opowiadaniu, które stworzyģa. W przypadku odpowiedniego testu AI pod kątem wiarygodnoķci zawieszenie nie jest jednak wystarczające. Musimy posunąæ się dalej i nalegaæ, aby obserwator nie byģ w stanie odróŋniæ od prawdziwych zachowaņ ŋyciowych - mimo ŋe, tak jak w teķcie Turinga, wiedzą z góry, ŋe przynajmniej jeden z obserwowanych przez nie agentów jest sztuczny, a nie rzeczywisty. W związku z tym moŋemy wykorzystaæ te spostrzeŋenia, aby zaproponowaæ inny test kandydata na inteligencję, jeden oparty na tym, czy to, co obserwowane, jest wiarygodne, czy nie. Jeķli w grze wieloosobowej, powiedzmy - lub filmie - animacja wirtualnego agenta jest tak dobra, ŋe nie moŋesz odróŋniæ prawdziwego agenta, nawet jeķli wiesz, ŋe grasz przeciwko lub obserwujesz co najmniej jednego agenta komputerowego, następnie mówi się, ŋe wirtualny agent zdaģ test.
Eksperyment Myķlowy: Agenci konwersacji.
Zaģóŋmy, ŋe mamy komputerowego chatbota (zwanego równieŋ "agentem konwersacji"), który ma moŋliwoķæ zdawania testu Turinga. Jeķli podczas rozmowy z chatbotem wydawaģo się, ŋe jest "rozwaŋny" (tj. myķlący) i moŋe nas przekonaæ, ŋe byģ "ķwiadomy", skąd mielibyķmy wiedzieæ róŋnicę? W ten sposób moŋemy uŋyæ odmiennoķci testu Turinga jako testu na myķlenie i ķwiadomoķæ, zadając pytania typu chatbot, takie jak:
1. "O czym myķlisz?"
2. "O czym myķlaģeķ godzinę temu?"
3. "Jak się czujesz w tej chwili?"
4. "Czy jesteķ ķwiadomy?"
Test ten moŋna wykorzystaæ do przetestowania racjonalnoķci, zadając kolejne pytania w następujący sposób:
1. "Czy jesteķ racjonalny?"
2. "Jeķli twój syn byģ gdzieķ w pģonącym budynku, ale wiedziaģeķ, ŋe prawdopodobnie umrzesz, jeķli chcesz wejķæ do ķrodka, aby go szukaæ, co byķ zrobiģ?"
3. "Czy uwaŋasz, ŋe racjonalnie byģoby, gdyby osoba, która znalazģa lek na raka, nie powiedziaģa nikomu o tym?"
To ilustruje trudnoķæ przejķcia testu Turinga i dlaczego eksperci AI powinni byæ wykorzystywani do potwierdzenia, kiedy komputer naprawdę przeszedģ test Turinga po raz pierwszy (poniewaŋ to oni rozumieją, jak są zbudowani i mogą ģatwo opracowaæ testy puģapkę chatbota do ujawnienia się.) Teraz wyobraž sobie, ŋe prowadzisz wyimaginowaną rozmowę z inną osobą w twoim wģasnym umyķle. Często robimy to sami, kiedy przeprowadzamy próby umysģowe w przyszģoķci i byæ moŋe moŋna to uznaæ za myķl (przynajmniej jedną z jej manifestacji). tj. moŋemy "myķleæ" o myķli jako o analogii do wyimaginowanej rozmowy. Dlatego, jeķli jesteķmy w stanie zbudowaæ prawdziwie "konwersacyjnego" agenta zdolnego do przejķcia testu Turinga, moglibyķmy zmusiæ go do mówienia raczej do siebie niŋ do czģowieka. Czy to byģoby wtedy jak "myķl"?
Moŋemy teraz rozwaŋyæ zmianę szkicu oryginalnych celów projektowych na podstawie powyŋszych spostrzeŋeņ. Zwróæ uwagę, ŋe cele projektowe wymienione poniŋej są raczej pracą w toku (staramy się, aby byģy one mierzalne w pewien sposób jako pierwszy krok), a nie wrzucone w kamieņ; powinniķmy je zmieniæ, korzystając z dalszych informacji uzyskanych podczas procesu projektowania. Inni projektanci opracują róŋne cele, aby speģniæ ich specyficzne potrzeby. Prawdziwym celem wymienienia ich tutaj jest podkreķlenie, ŋe jako potencjalni projektanci sztucznej inteligencji powinniķmy jasno okreķliæ takie cele projektowe - i powiedzieæ z góry na początku kaŋdego projektu AI - zamiast pozostawaæ niejasnymi, poniewaŋ byģo to poraŋką wielu sztucznej inteligencji. projekty do tej pory. Omówimy róŋne technologie agentów w następnym tomie tej serii ksiąŋek, aby zobaczyæ, jak realistyczne są.
Cele projektu dla wiarygodnych agentów:
Cel projektu 2.1:
System sztucznej inteligencji powinien pozytywnie przejķæ test wiarygodnoķci, aby dziaģaæ w sposób kompetentny: powinien posiadaæ umiejętnoķæ zdobywania wiedzy; powinien równieŋ dziaģaæ w sposób kompetentny, poprzez wykazywanie wiedzy - samej siebie, innych agentów i ķrodowiska - oraz demonstrowaæ zrozumienie tej wiedzy.
Cel projektu 2.2:
System sztucznej inteligencji powinien przejķæ test wiarygodnoķci do dziaģania w sposób inteligentny i rozumujący. Powinien byæ w stanie samodzielnie rozwiązywaæ problemy poprzez obserwację i uczenie się oraz poprzez rozumowanie. Powinien takŋe byæ w stanie zastosowaæ rozwiązania z jednej domeny problemowej do drugiej bez pokazywania, jak to zrobiæ.
Cel projektu 2.3:
System sztucznej inteligencji powinien przejķæ test wiarygodnoķci w celu racjonalnego dziaģania: po pierwsze, zapewniając najlepsze szanse na przetrwanie samego siebie i swojej rodziny lub innych podobnych osób; po drugie, dzieląc się zdobytą wiedzą z innymi agentami; i po trzecie, wybierając dziaģanie zgodnie z osobistymi preferencjami.
Cel projektu 2.4:
System sztucznej inteligencji powinien przejķæ test lustrzany i test wiarygodnoķci, aby zachowywaæ się tak, jakby byģ samoķwiadomy.
Cel projektu 2.5:
System sztucznej inteligencji powinien przejķæ test wiarygodnoķci, aby zachowywaæ się tak, jakby byģ ķwiadom i byģ ķwiadomy.
Cele projektu dla agentów konwersacyjnych:
Cel projektu 2.6:
System sztucznej inteligencji powinien przejķæ test Turinga pod kątem inteligencji, w tym wariacja testu opisanego powyŋej w eksperymencie myķlowym, aby sprawdziæ racjonalnoķæ, zamyķlenie i ķwiadomoķæ
Ku wiarygodnym agentom
Jeķli chcemy zaprojektowaæ system sztucznej inteligencji, kryteria projektowe wymienione powyŋej dostarczają nam pewnych moŋliwych ķcieŋek do przodu. Jeķli naszym celem jest stworzenie systemu, który speģnia kryteria wiarygodnoķci, moglibyķmy pójķæ dalej, podąŋając tym, co moglibyķmy nazwaæ "sztuczną ķcieŋką ŋyciową", aby osiągnąæ nasz cel. W tym podejķciu celem byģoby stworzenie sztucznego ŋycia o rosnącej zģoŋonoķci i realizmie, zarówno rzeczywistego (na przykģad robotycznego), jak i wirtualnego (tj. wirtualne stworzenia i wirtualni ludzie). Jeķli naszym celem jest stworzenie systemu o zdolnoķciach konwersacyjnych, moglibyķmy pójķæ w alternatywną "ķcieŋkę konwersacyjną", w której staralibyķmy się zaprojektowaæ sztuczną inteligencję z moŋliwoķcią prowadzenia wiarygodnej rozmowy z czģowiekiem, a zatem zdaæ test Turinga. Podobnie jak w przypadku sztucznego ŋycia, moŋemy zacząæ od czegoķ prostego, a następnie stopniowo zwiększaæ jego zģoŋonoķæ, aŋ będziemy w stanie osiągnąæ nasz cel projektowy, lub dopóki nie udowodnimy, ŋe cel projektu nie jest moŋliwy do osiągnięcia. Wiele osób zakwestionowaģo, czy umiejętnoķæ rozmowy jest prawdziwym testem inteligencji. Whitby posunąģ się tak daleko, ŋe nazwaģ Test Turinga największym "ķlepym zauģkiem" w Sztucznej Inteligencji. Niezaleŋnie od tego, czy ktoķ zgadza się z testem Turinga, czy jest waŋnym sprawdzianem inteligencji, komputer przechodzi test, co z pewnoķcią stanie się kamieniem milowym w badaniach nad sztuczną inteligencją, tak jak wtedy, gdy komputer po raz pierwszy pokonaģ mistrza ķwiata w szachach, staģ się kamieniem milowym. Z punktu widzenia projektowania moŋemy uznaæ te dwa wysiģki (pokonanie mistrza ķwiata w szachach i zdanie testu Turinga) za wyzwania inŋynierskie w taki sam sposób, jak uzyskanie komputera do tģumaczenia lub gry w tenisa stoģowego to wyzwania inŋynieryjne. Zasģuga posiadania komputerów zdolnych do tģumaczenia jest dla nas oczywista, a jednoczeķnie pozwala im mniej graæ w tenisa stoģowego. Podobnie jak w przypadku tģumaczeņ i innych waŋnych zadaņ związanych z przetwarzaniem języka naturalnego, takich jak rozpoznawanie mowy, zaleta posiadania komputerów zdolnych do prowadzenia wiarygodnej rozmowy z nami jest równieŋ jasna. Joseph Weizenbaum wymyķliģ wczesnego agenta komunikacyjnego o nazwie Eliza w poģowie lat szeķædziesiątych, który nazwaģ "parodią" Rogerowskiego psychoterapeuty. Niedģugo potem Kenneth Colby wymyķliģ innego sģynnego wczesnego agenta konwersacyjnego o nazwie Parry w 1972 roku, który symulowaģ paranoidalną schizofrenię. Model Netbogo Chatbot pokazuje, jak ģatwo jest stworzyæ prostych agentów konwersacyjnych, takich jak Eliza i Parry.
W modelu zaimplementowano dwa chatboty - nazywają się one Liza i Harry z szacunku do dwóch wczesnych chatbotów: Elizy i Parry. Nie są to peģne implementacje tych chatbotów, chociaŋ Harry stara się byæ paranoikiem trochę jak Parry. Ich celem jest pokazanie, jak ģatwo jest stworzyæ chatbota, ale takŋe aby pokazaæ, jak trudno jest porozmawiaæ z chatbotem. Mogą równieŋ sģuŋyæ jako punkt wyjķcia do porównaņ. Zobaczymy, jak moŋna je ulepszyæ w tomie 2 tej serii ksiąŋek. Zrzut ekranu pokazuje krótki zapis rozmowy z Harrym. Rozmowa na pierwszy rzut oka wydaje się rozsądna, chociaŋ Harry wydaje się byæ trochę niepewny i byæ moŋe urojonym. Kaŋdy, kto rozmawia z Harrym, wkrótce uķwiadomi sobie, ŋe coķ w nim nie jest w porządku, i ŋe nie ma to nic wspólnego z jego postrzeganą paranoją. Wielokrotna eksploatacja Harry′ego pokaŋe, ŋe wiarygodna rozmowa jest moŋliwa tylko w niewielkim odsetku przypadków i tylko przez krótki czas. Wydajnoķæ Lizy jest jeszcze gorsza, poniewaŋ wydaje się, ŋe nie ma nic wspólnego, takiego jak paranoja, której moŋemy uŋyæ, aby pomóc nam zrozumieæ, co ona mówi. Model wykorzystuje rozszerzenie do NetLogo, dzięki czemu moŋemy korzystaæ z wyraŋeņ regularnych w celu zdefiniowania reakcji agentów na dane uŋytkownika. Wyraŋenia regularne są ķrodkiem opisywania wzorców, które my chcą się identyfikowaæ w jakimķ tekķcie i są często uŋywane w informatyce, zwģaszcza w przetwarzaniu języka naturalnego. Fragment kodu do zdefiniowania odpowiedzi Harry'ego jest pokazany w kodzie NetLogo
extensions [re]
breed [rules rule]
breed [chatbots chatbot]
rules-own [regex responses]
chatbots-own [name rules-list failure-list]
globals [liza harry]
to setup
clear-all
create-chatbots 1
[ set harry who
set name "Harry"
set shape "person"
set color red
set size 15
set label "Harry "
setxy 10 0
set rules-list
(list
;setup-rule regex unique-name list-of-responses
setup-rule "hello" (list "Who are you?" "Why are you speaking to me?"
"What do you want?" "How do you know me?")
setup-rule "bye" (list "bye" "yeah bye")
setup-rule "colou?r" (list "What about colour?" "I like blue"
"My favourite colour is blue
but don't tell anyone")
setup-rule "(\\w+)@(\\w+\\.)(\\w+)(\\.\\w+)*"
(list "I'm not giving you my address"
"I would rather not disclose my address")
setup-rule "sorry" (list "I still don't trust you"
"What do you want? Who are you really?")
setup-rule "(.+)bot(.+)"
(list "I am a bot. Why do you want to know? Who are you?"
"Whats with all the questions? Are you from MI5?")
setup-rule "(.+)did you(.+)"
(list "You will only use it against me if I tell you")
setup-rule "(.+)are you(.+)" (list "yes" "no" "maybe")
setup-rule "welcome(.+)" (list "Who are you?")
setup-rule "how are you(.+)"
(list "I'm ok. I will be much better when you leave me alone."
"Are you a doctor now?")
setup-rule "what do you think(.+) harry"
(list "Not very much to be honest" "meh")
setup-rule "go(.+)" (list "you first. I don't want to get caught"
"after you" "have you tried it yourself?"
"Are you trying to get me to do something illegal?")
setup-rule "have you(.+)" (list "should I?"
"I don't know if I should do that. You might arrest me")
)
set failure-list
(list
"I think someone is watching me. This line may not be secure"
"uhu
"
"oh yeah I know. Do you ever get the feeling you are being watched?"
"continue
"
"Do you like beans? They give me gas!"
"Are you watching me?"
"Please stop watching me"
"I get nervous when people watch me"
)
]
end
to-report setup-rule [regex-str res]
; sets up a rule for matching a user's input
let me nobody
hatch-rules 1
[ set regex regex-str
set responses res
set me who
hide-turtle ] ; make it invisible in the environment
report me
end
Kod najpierw deklaruje rozszerzenie wyraŋenia regularnego re (patrz adres URL kodu Java poniŋej), a następnie definiuje dwa typy, rules i chatbots. Reguģy agenta posiadają wyraŋenie regularne (regex) i listę odpowiedzi (responses). Agenci Chatbot posiadają nazwę (name), listę reguģ (rules-list) oraz listę odpowiedzi (failure-list) uŋywanych, gdy nie pasują do ŋadnej z reguģ. Kod wyķwietla listę wyciągów z procedury instalacji, która jest uŋywana do ģadowania chatbotów w interfejsie. Tworzy to nowego chatbota o nazwie "Harry", a następnie inicjalizuje rules-list, wielokrotnie wywoģując procedurę setup-rule. To wymaga dwóch argumentów, wyraŋenia regularnego (regex-str), a następnie listy odpowiedzi (res). Spojrzenie na reguģy pokaŋe, w jaki sposób zdefiniowane są wyraŋenia regularne. Pierwsza reguģa ma zwykģy tekst "hello" jako wyraŋenie regularne bez ŋadnych znaków specjalnych o okreķlonym znaczeniu (są one nazywane "znakami meta"). W takim przypadku reguģa będzie zgodna tylko wtedy, gdy uŋytkownik wprowadzi dokģadny tekst "hello". Odpowiedž, którą daje chatbot, jest wybrana losowo z poniŋszej listy: "Kim jesteķ?", "Dlaczego do mnie mówisz?", "Czego chcesz?" I "Jak mnie znasz?". Druga reguģa ma równieŋ wyraŋenie regularne bez ŋadnych znaków meta. Dopasuje tylko ciąg "bye" i odpowiada "pa" lub "tak czeķæ". Trzecia reguģa uŋywa wyraŋeņ regularnych z pojedynczym znakiem meta "?" oznacza to, ŋe poprzedni znak jest opcjonalny, dlatego zarówno pisownia amerykaņska, jak i brytyjska tego samego sģowa, "kolor" i "kolor" będą pasowaæ. Czwarta reguģa uŋywa wyraŋenia regularnego "(\\ w +) @ (\\ w + \\.) (\\ w +) (\\. \\ w +) *" w celu wykrycia, kiedy uŋytkownik wpisaģ nazwę uŋytkownika (cokolwiek z znak "@", niektóre kropki "." i interweniujące sekwencje alfanumeryczne lub podkreķlenia). Szósta reguģa wykorzystuje sekwencję znaków meta "(. +)", Która jest często uŋywana w pozostaģych reguģach. Ta sekwencja meta dopasuje dowolną sekwencję znaków poķrednich. W związku z tym ta konkretna reguģa będzie odpowiadaæ pytaniu "Czy jesteķ botem?", Gdzie ciąg "Are you" jest dopasowywany przez pierwszą meta sekwencję, a "?" Jest dopasowywana przez drugą meta sekwencję. Sposób dziaģania wyraŋeņ regularnych oznacza równieŋ, ŋe ta reguģa będzie równieŋ pasowaæ do danych wprowadzanych przez uŋytkownika, takich jak "Ja teŋ jestem bota", "Nie lubię botów", "-bot-" i "= bot?". To pokazuje, w jaki sposób uŋywanie wyraŋeņ regularnych moŋe byæ zarówno przekleņstwem, jak i bģogosģawieņstwem - przekleņstwem, gdy dopasowuje się zbyt wiele ciągów, których nie chcemy, i bģogosģawieņstwem, poniewaŋ moŋemy okreķliæ nieskoņczonoķæ róŋne ciągi znaków z kilkoma znakami meta. Aby uzyskaæ peģny opis wyraŋeņ regularnych i ich wykorzystania w przetwarzaniu języka naturalnego, zobacz artykuģ Jurafsky i Martin. Kod okreķlający, co dzieje się po naciķnięciu przycisku czatu w interfejsie, jest wymieniony w NetLogo
to chat
; chats with the user
if (bot = "liza") [ chat-with liza ]
if (bot = "harry") [ chat-with harry ]
end
to chat-with [this-chatbot]
; has a conversation with this-chatbot
let fired false
let pos 0
let this-chatbot-name [name] of chatbot this-chatbot
let user-reply user-input "Enter text: "
output-print "You say:"
output-print user-reply
ask chatbot this-chatbot
[ set pos 0
while [pos < length rules-list]
[
if (fired = false)
[
ask rule item pos rules-list
[
re:clear-all
re:setup-regex regex user-reply
if (re:get-group-length > 0)
[ output-type this-chatbot-name
output-print " says:"
output-print item random length responses responses
output-print ""
set fired true
]
]
]
set pos pos + 1
]
if (fired = false)
[
output-type this-chatbot-name
output-print " says:"
output-print one-of failure-list
output-print ""
]]
Procedura chat wybiera, z którego czatu chcesz rozmawiaæ (przez wywoģanie podprocedury chat-with) na podstawie wartoķci zmiennej bot ustawionej za pomocą suwaka w interfejsie. Ta podprocedura polega na tym, ŋe uŋytkownik najpierw wprowadza jakiķ tekst, a następnie prosi odpowiedniego chatbota o przetwarzanie kaŋdej z reguģ na rules-list w rosnącej kolejnoķci sekwencyjnej. Kaŋda reguģa jest dopasowywana do danych wprowadzanych przez uŋytkownika za pomocą trzech metod zdefiniowanych przez rozszerzenie re: re: clear-all usuwa bieŋące wyraŋenie regularne, które jest dopasowywane; re: setup-regex następnie ustawia wyraŋenie regularne i do czego jest dopasowywane; i re: get-group-length sģuŋy do sprawdzenia, czy istnieje dopasowanie. (Te trzy metody wywoģują metody zdefiniowane w Java API dla wyraŋeņ regularnych). Jeķli reguģa się zgadza, wybiera losowo jedną z odpowiedzi. Jeķli ŋadna reguģa nie zostanie uruchomiona, wybierze jedną z odpowiedzi na failure-list.
W stronę komputerów ze zdolnoķcią rozwiązywania problemów
Zdolnoķæ konwersacyjna jest tylko jednym z elementów ludzkiej inteligencji. Kolejnym waŋnym skģadnikiem jest umiejętnoķæ rozwiązywania problemów. Ludzie mają wyjątkową zdolnoķæ rozwiązywania problemów. Aby zilustrowaæ, zbadajmy siedem problemów, które wymagają inteligencji dla ich rozwiązaņ:
1. Poszukiwanie lepszego rozwiązania.
2. Reprezentowanie wiedzy.
3. Utrzymywanie rozmowy z czģowiekiem.
4. Tworzenie sztucznego ŋycia.
5. Tworzenie sztucznej inteligencji.
6. Przepģyw wody pod górę.
7. Znalezienie ogólnej metody rozwiązywania problemów, która dotyczy wszystkich tych problemów.
Wydaje się, ŋe problemy te pojawiają się na coraz wyŋszych poziomach trudnoķci (na razie ignorując ostatnią z nich). Ale czy te problemy są naprawdę coraz trudniejsze? Byæ moŋe mogą byæ na tym samym poziomie trudnoķci. Gdybyķmy mogli opracowaæ ogólną metodę rozwiązywania problemów (jak w przypadku siódmej pozycji na liķcie), moŋemy uŋyæ jej do rozwiązania wszystkich tych problemów. Ludzie juŋ mają tę zdolnoķæ, poniewaŋ mamy moŋliwoķæ opracowywania rozwiązaņ dla kaŋdego, oceniania, w których przypadkach rozwiązania zawodzą, wielokrotnie proponują ulepszenia lub alternatywne rozwiązania, aŋ w koņcu dotrzemy do rozwiązania, które nas satysfakcjonuje lub zrezygnujemy. Ta umiejętnoķæ rozwiązywania problemów jest kluczowym skģadnikiem ludzkiej inteligencji. Jak stwierdzono w Rozdziale 8, poszukiwanie zachowania jest podstawowym skģadnikiem inteligentnego zachowania. Algorytmy wyszukiwania w informatyce i sztucznej inteligencji są nieustannie rozwijane i udoskonalane w ciągu ostatnich kilku dekad przez wiele osób w ramach staģego programu badaņ. Samo sģowo "badanie" jest ķwiadectwem przeprowadzanego podstawowego procesu wyszukiwania. Oczywiķcie umiejętnoķæ poszukiwania alternatywnych rozwiązaņ problemu, w tym problem poszukiwania meta w poszukiwaniu lepszej metody wyszukiwania, jest podstawowym skģadnikiem inteligencji ludzkiej i inteligencji w ogóle. Umiejętnoķæ oceny "dobroci" rozwiązania i ciągģego poszukiwania lepszych rozwiązaņ jest równieŋ kluczowym elementem rozwiązywania problemów. My jako ludzie nigdy nie jesteķmy usatysfakcjonowani. W naszej naturze dąŋymy do tego, aby byæ lepszymi, zarówno indywidualnie, jak i zbiorowo. Bez względu na to, jak dobrze moglibyķmy zrobiæ w przeszģoķci, zawsze znajdzie się ktoķ, kto zechce zrobiæ coķ lepiej, niezaleŋnie od przyczyny. Aby to zilustrowaæ, wystarczy spojrzeæ na pomysģowoķæ rozwiązaņ zaproponowanych przez poprzednich badaczy sztucznej inteligencji w poszukiwaniu metod rozwoju sztucznej inteligencji. Moŋemy scharakteryzowaæ rozwiązywanie problemów jako poszukiwanie przestrzeni rozwiązania. Wracając do rozdziaģu 4, gdzie podkreķlono wagę ruchu dla agenta, moŋemy myķleæ o ulepszeniu systemu jako ruchu wykonywanego przez agenta z jednej częķci przestrzeni rozwiązania do drugiej. Postęp jest często związany z ruchem do przodu. Powszechnie uŋywane wyraŋenia angielskie odzwierciedlają tę analogię - na przykģad "dokonaliķmy postępu"; "Musimy zrobiæ jeden krok wstecz, aby zrobiæ dwa kroki do przodu"; "Musimy dokonaæ przeģomu"; i "zmierzamy w zģym kierunku". Moŋemy próbowaæ ulepszyæ rozwiązania, które zostaģy zaimplementowane jako modele w NetLogo w tym tomie. Wracając do powyŋszej tabeli, rozwiązania opisane w częķci 8 dla pierwszego elementu na liķcie - poszukiwanie lepszego rozwiązania - implementują tylko podstawowe algorytmy, a istnieje wiele przykģadów innych algorytmów wyszukiwania w literaturze, które prowadzą do ulepszonych rozwiązaņ w zakresie róŋne okolicznoķci. Rozwiązanie opracowane dla problemu labiryntu, na przykģad, wyszukiwanie pomiędzy zachowaniami, a nie szukanie między ķcieŋkami, jest niewystarczające, jeķli chcemy rozwinąæ moŋliwoķci wyszukiwania na poziomie czģowieka dla systemu sztucznej inteligencji. Do tego potrzebujemy agentów do przeszukiwania labiryntu jak czģowiek - agent musi zbadaæ jego otoczenie z ucieleķnionej, usytuowanej perspektywy, wykorzystując koordynację zmysģowo-motoryczną i byæ poznawczo ķwiadomym wyborów, kiedy się pojawią, a takŋe byæ ķwiadomym z dotychczasowych wyborów, które zostaģy dokonane. W przypadku problemu labiryntu, na przykģad, agent musi zrealizowaæ (to znaczy mieæ ķwiadomoķæ poznawczą), ŋe istnieją alternatywne ķcieŋki do naķladowania, gdy osiąga skrzyŋowanie w labiryncie. Przegląd rozwiązaņ opracowanych dla drugiego przedmiotu na liķcie - reprezentowanie wiedzy - model Wiedzy Przedstawionej opisany w rozdziale 9 implementuje tylko podstawowe metody reprezentacji i wnioskowania, a bardziej zaawansowane rozwiązania istnieją w literaturze. W ciągu ostatnich pięædziesięciu lat przeprowadzono znaczne badania w dziedzinie reprezentacji wiedzy, a naukowcy udoskonalili i nadal udoskonalają rozwiązania. Nadal potrzeba więcej pracy, aby rozwiązaæ niektóre z gģębokich problemów związanych z reprezentowaniem wiedzy, takich jak symbole uziemione, oraz w jaki sposób ucieleķniony, umiejscowiony agent moŋe automatycznie uzyskaæ wiedzę o niebanalnych koncepcjach. Ta praca moŋe z pewnoķcią przynieķæ korzyķci wglądom z innych dziedzin, takich jak kognitywistyka; Teoria przestrzeni koncepcyjnych Gärdenfors jest jednym z przykģadów. Wiele osób podjęģo próbę stworzenia agentów konwersacji na próŋno próbując zdaæ test Turinga, ale do tej pory wszystkie próby się nie powiodģy. Róŋnorodnoķæ tych rozwiązaņ jest dowodem na pomysģowoķæ ludzi i ich umiejętnoķci rozwiązywania problemów. Model Chatbot opisany w poprzedniej sekcji ma oczywiste ograniczenia i moŋna go ģatwo poprawiæ na wiele sposobów. Zasadniczo jest to argument, który tu wysuwamy - zdolnoķæ, jaką mamy, jako ludzie, do opracowania wielu róŋnych rozwiązaņ tego samego problemu, jest podstawowym skģadnikiem naszej inteligencji. Jednak w przypadku komputerów nie ma jeszcze opracowanego systemu jest zdolny do generowania róŋnorodnych rozwiązaņ problemu, który ludzie mogą wygenerowaæ. Jednym ze ķwiętych grails w badaniach nad sztuczną inteligencją byģo opracowanie ogólnego rozwiązania problemu. Chociaŋ algorytmy ewolucyjne, takie jak programowanie genetyczne, mogą automatycznie generowaæ nowatorskie rozwiązania, metody te nie są w stanie generowaæ rozwiązaņ dla wysoce zģoŋonych problemów otwartych, takich jak reprezentowanie wiedzy i budowanie agenta konwersacji, a nawet tworzenie sztucznego ŋycia i sztucznej inteligencji. Gdyby tak byģo, moglibyķmy usiąķæ i pozwoliæ im rozwiązaæ te problemy. Inne rozwiązania, które zostaģy opracowane, takie jak General Problem Solver (GPS) i SOAR, próbowaģy rozwiązaæ ten problem meta - próbę znalezienia agenta do rozwiązania problemów dla siebie - ale do tej pory tylko oni byli w stanie wyprodukowaæ rozwiązania rutynowych problemów w przeciwieņstwie do zģoŋonych problemów w ķwiecie rzeczywistym. Oczywiķcie, juŋ mamy "ogólnego rozwiązywania problemów" - my sami. Aby zilustrowaæ, jak dobrze jesteķmy w rozwiązywaniu problemów, moŋemy zbadaæ szósty problem wymieniony w powyŋszej tabeli - powodując, ŋe przepģyw wody pod górę - w celu przeciwstawienia się grawitacji. Jak stwierdzono powyŋej, na pierwszy rzut oka wydaje się to nierozpuszczalne. Jednak historia jest usiana wieloma przykģadami, w których ludzie znaležli rozwiązania problemów, które kiedyķ wydawaģy się niemoŋliwe do rozwiązania - na przykģad latanie, teleportacja i niewidzialnoķæ, by wymieniæ tylko kilka. Jako inny przykģad, trójkąt Penrose'a, o ksztaģcie podobnym do niemoŋliwego zostaģ zbudowany i wzniesiony w Gotschuchen w Austrii w 2008 r.
James Dyson, brytyjski projektant przemysģowy, zostaģ zainspirowany rysunkiem holenderskiego artysty M.C. Escher, który przedstawia scenę zawierającą niemoŋliwy wodospad (patrz zdjęcie poniŋej). Rysunek pokazuje pģynącą pod górę wodę, która opiera się logice i grawitacji, wykonując cztery skręty w prawo na tym samym poziomie, ale w jakiķ sposób koņcząc na wyŋszej wysokoķci, aby sprowadziæ kaskadę wodospadu koņczącego się z powrotem na początku. Dyson, po obejrzeniu rysunku, zacząģ zastanawiaæ się, czy moŋliwe byģoby zrobienie podobnego wodospadu. Po dwunastu miesiącach pracy Derek Philips, inŋynier Dyson, opracowaģ metodę opartą na pęcherzykach spręŋonego powietrza, które zapewniģy iluzję wody pģynącej pod górę, i to zostaģo uŋyte w ogrodowej fontannie na Chelsea Garden Show w 2003 roku

Inne przykģady pģynącej pod górę wody moŋna ģatwo znaležæ po szybkim wyszukiwaniu w Google i youtube.com. Niektóre rozwiązania obejmują: wytwarzanie kropelek wody pod górę na powierzchni polerowanego krzemu przez zmianę stopnia wodoodpornoķci (opracowany przez Manoj K. Chaudhury na Uniwersytecie LeHigh); za pomocą pola magnetycznego i roztworu na bazie siarczanu miedzi (na Uniwersytecie w Bonn); i mając zawiesiny pģynów zawieszone na cienkiej poduszce pary na przegrzanej, zapadniętej mosięŋnej powierzchni (na Uniwersytecie Oregon). Rozwiązanie Chaudhury'ego jest interesujące, poniewaŋ ma potencjalne zastosowanie w innych problemach, takich jak urządzenia mikroprzepģywowe, w szczególnoķci mikrochipy wyposaŋone w miniaturowe ogniwa paliwowe, oraz problemy z przenikaniem ciepģa obejmujące systemy o zerowej lub mikrograwitacji. Model Water Flowing Uphill NetLogo zostaģ opracowany w celu zilustrowania naszych umiejętnoķci rozwiązywania problemów. Model zawiera róŋne nieudane próby zwiększenia przepģywu wody w symulowanym ķrodowisku. Ogólne rozwiązanie, przedstawione na rycinie 10.3, opiera się na idei wykorzystania zbiorników na wzrastających wysokoķciach uģoŋonych w kaskadę, co jest przeciwieņstwem zwykģej kaskady opadowej wodospadu.
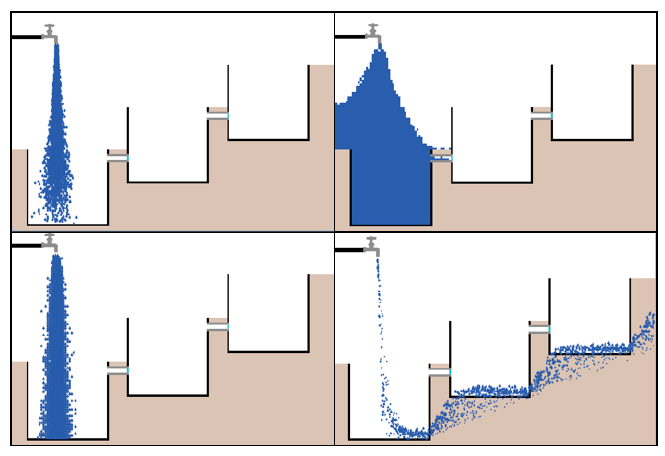
Kaŋdy zbiornik wody stopniowo napeģnia się, a następnie przelewa przez rurę do dna następnego zbiornika, który następnie zaczyna się zapeģniaæ, i tak dalej. Kluczowym wnioskiem jest to, ŋe musimy uŋyæ zaworu jednokierunkowego na koņcu rur, aby upewniæ się, ŋe woda nie napeģnia się tym samym zbiornikiem, co podwyŋsza wysokoķæ wody. W symulacji zastosowanej w modelu NetLogo maģa niebieska linia na koņcu kaŋdej rury przedstawia zawór jednokierunkowy. Ŋadnemu z rozwiązaņ wdroŋonych w modelu nie udaje się zmusiæ wirtualnej wody do przepģywu w górę zgodnie z przeznaczeniem. Problem jest szczególnie trudny, jeķli chcemy mieæ wiarygodną symulację, poniewaŋ musimy dokģadnie symulowaæ przepģyw wody, nietrywialny problem wizualizacji, który jest aktywnym obszarem badaņ. Pierwsze rozwiązanie dostarczone w modelu uŋywa podstawowych agentów ŋóģwia i moŋna je uruchomiæ, wybierając "turtle agents 1" w interfejsie wyboru solution. Wirtualna woda zaczyna spģywaæ w dóģ z rury trochę jak w prawdziwej wodzie, ale kiedy dociera do dna pierwszego zbiornika, nie rozkģada się prawidģowo na dnie. W rzeczywistoķci wydaje się po prostu zniknąæ w powietrzu, ale dzieje się tak, poniewaŋ ķrodki ŋóģwia, które reprezentują kropelki wody, pozostają tylko na dnie i nie ruszają się. To samo dzieje się z innym roztworem ķrodka ŋóģwiającego ("turtle agents 2"), ale tym razem róŋnica polega na tym, ŋe krople wody spadają bardziej jak pģatki ķniegu niŋ prawdziwa woda. Oczywiķcie, takie rozwiązania nie przypominają prawdziwego ŋycia i wymagają naprawy. Ta zdolnoķæ do identyfikowania problemów z konkretnym rozwiązaniem, poprzez dopasowanie wyniku symulacji do tego, co dzieje się w prawdziwym ŋyciu, jest kluczowym aspektem rozwiązywania problemów. Problem powoduje dalsze problemy, które naleŋy rozwiązaæ. Moŋemy na razie zignorowaæ te pod-problemy, mając nadzieję, ŋe będziemy w stanie je rozwiązaæ póžniej, ale na pewnym etapie będą one musiaģy zostaæ rozwiązane. Często te pod-problemy mogą byæ równie trudne, jeķli nie trudniejsze niŋ pierwotny problem (np. Problem symulowania przepģywu wody). Druga rodzina rozwiązaņ dostarczanych przez model uŋywa agentów poprawek. Zaletą tego podejķcia jest to, ŋe prędkoķæ symulacji wydaje się teraz znacznie szybsza niŋ rozwiązania agentów ŋóģwia. Jednak kropelki wody w pierwszym roztworze ķrodka pģatkowego ("patch gents 1") obecnie nie zachowują się jak woda w rzeczywistoķci. Zamiast tego zachowują się bardziej jak ziarna piasku, tworząc szybko rosnącą wieŋę w ķrodku pierwszego zbiornika. Inne rozwiązania agentów ģatek są próbą rozwiązania tego problemu, ale koņczą jako kompletne niepowodzenia, chociaŋ z interesującymi rezultatami - "patch agents 2" pokrywa caģy ekran wodą, "patch agents 3" wypeģnia zbiornik krokami po przekątnej i " patch agents 3 "tworzy prostokąt wody. Rozwiązania te są oczywiķcie wyražnymi bģędami (przynajmniej dla nas: posiadanie komputera rozpoznaje, ŋe jest to znacznie trudniejsze). Ale czasami poraŋki, zwģaszcza jeķli przynoszą nieoczekiwane rezultaty, jak pokazują te przykģady, mogą prowadziæ do nieprzewidzianych przeģomów. Nauka zaķmiecona jest nieoczekiwanymi rezultatami - na przykģad penicyliną Alexandra Fleminga, LSD Alberta Hofmana, promieniami X Wilhelma Roentgena, odkryciem planety Uranus Williama Herschela i kuchenki mikrofalowej Percy'ego Spencera, by wymieniæ tylko kilka. Byæ moŋe następujący cytat Isaaca Asimova podsumowuje najlepiej: "Najbardziej ekscytującym zwrotem do usģyszenia w nauce, który zapowiada nowe odkrycia, nie jest" Eureka! ", Ale" To zabawne ... "". M.K. Stoskopf dalej stwierdza: "to naleŋy uznaæ, ŋe nieoczekiwane odkrycia mają znaczącą wartoķæ w rozwoju nauki i często stanowią podstawę waŋnych intelektualnych przeskoków zrozumienia ". Natomiast komputer nie dokonaģ jeszcze naprawdę nieoczekiwanego odkrycia. Ta zdolnoķæ rozpoznawania i wykorzystywania zdarzeņ losowych jest kolejnym kluczowym skģadnikiem inteligencji. Trzecia rodzina rozwiązaņ opiera się na wykorzystaniu boidów, o których mowa w rozdziale 6. Ostatnie badania wykazaģy, ŋe boidy są przydatnym rozwiązaniem do wizualizacji przepģywu, na przykģad przepģywu krwi. Próba uŋycia boidów w modelu Netlogo odbywa się za pomocą rozwiązania "boid agents 1". Rozwiązanie zawodzi w taki sam sposób, jak zawodzi ŋóģw, ale przynosi pewne interesujące efekty, z efektami podobnymi do malowania natryskowego w niektórych konfiguracjach. Ostateczna rodzina rozwiązaņ opiera się na wykorzystaniu systemów cząsteczek wdroŋonych przez Model System Cząstek wodospadu dostarczany z biblioteką modeli NetLogo. Model ten zawiera regulacje dotyczące siģy cięŋkoķci, wiatru i lepkoķci, aby lepiej symulowaæ spadek przepģywu wody i wody. Kod zostaģ zaadaptowany do modelu Water Flowing Uphill w roztworze "particle agents 1". Mimo ŋe woda zdąŋyģa juŋ pģynąæ pod górę, robi to w bardzo nieoczekiwany sposób, w jakiķ sposób radząc sobie z tunelowaniem w otaczającej ziemi, niczym prawdziwym ŋyciem. Czytelnicy są zachęcani do samodzielnego znalezienia rozwiązania tego problemu, a przy okazji obserwowania, jak radzą sobie z rozwiązywaniem problemów. Trudnym aspektem tego problemu jest jednak niedopuszczenie do dziaģania modelu, poniewaŋ moŋna to zrobiæ doķæ ģatwo, przy odrobinie wysiģku. Prawdziwy problem polega na tym, aby komputer sam rozpoznaģ, na czym polega ten problem, i automatycznie generuje rozwiązania. Ta umiejętnoķæ musi zostaæ zaprogramowana na następną generację systemów sztucznej inteligencji, jeķli mamy wykonaæ kolejny krok w kierunku systemów AI z inteligencją poziomu ludzkiego. Byæ moŋe ostatecznym testem dla systemu sztucznej inteligencji jest to, czy moŋe on sam stworzyæ system sztucznej inteligencji.
Druga rodzina rozwiązaņ dostarczanych przez model uŋywa agentów poprawek. Zaletą tego podejķcia jest to, ŋe prędkoķæ symulacji wydaje się teraz znacznie szybsza niŋ rozwiązania agentów ŋóģwia. Jednak kropelki wody w pierwszym roztworze ķrodka pģatkowego ("ķrodki wiąŋące 1") obecnie nie zachowują się jak woda w rzeczywistoķci. Zamiast tego zachowują się bardziej jak ziarna piasku, tworząc szybko rosnącą wieŋę w ķrodku pierwszego zbiornika. Inne rozwiązania agentów ģatek są próbą rozwiązania tego problemu, ale koņczą jako kompletne niepowodzenia, chociaŋ z interesującymi rezultatami - "patch agents 2" pokrywa caģy ekran wodą, "patch agents 3" wypeģnia zbiornik krokami po przekątnej i " patch agents 3 "tworzy prostokąt wody. Rozwiązania te są oczywiķcie wyražnymi bģędami (przynajmniej dla nas: posiadanie komputera rozpoznaje, ŋe jest to znacznie trudniejsze). Ale czasami poraŋki, zwģaszcza jeķli przynoszą nieoczekiwane rezultaty, jak pokazują te przykģady, mogą prowadziæ do nieprzewidzianych przeģomów. Nauka zaķmiecona jest nieoczekiwanymi rezultatami - na przykģad penicyliną Alexandra Fleminga, LSD Alberta Hofmana, promieniami X Wilhelma Roentgena, odkryciem planety Uranus Williama Herschela i kuchenki mikrofalowej Percy'ego Spencera, by wymieniæ tylko kilka. Byæ moŋe następujący cytat Isaaca Asimova podsumowuje najlepiej: "Najbardziej ekscytującym zwrotem do usģyszenia w nauce, który zapowiada nowe odkrycia, nie jest" Eureka! ", Ale" To zabawne ... "". M.K. Stoskopf dalej stwierdza: "to naleŋy uznaæ, ŋe nieoczekiwane odkrycia mają znaczącą wartoķæ w rozwoju nauki i często stanowią podstawę waŋnych intelektualnych przeskoków zrozumienia ". Natomiast komputer nie dokonaģ jeszcze naprawdę nieoczekiwanego odkrycia. Ta zdolnoķæ rozpoznawania i wykorzystywania zdarzeņ losowych jest kolejnym kluczowym skģadnikiem inteligencji. Trzecia rodzina rozwiązaņ opiera się na wykorzystaniu boidów, o których mowa w rozdziale 6. Ostatnie badania wykazaģy, ŋe boidy są przydatnym rozwiązaniem do wizualizacji przepģywu, na przykģad przepģywu krwi. Próba uŋycia boidów w modelu Netlogo odbywa się za pomocą rozwiązania "boid agents 1". Rozwiązanie zawodzi w taki sam sposób, jak zawodzi ŋóģw, ale przynosi pewne interesujące efekty, z efektami podobnymi do malowania natryskowego w niektórych konfiguracjach. Ostateczna rodzina rozwiązaņ opiera się na wykorzystaniu systemów cząsteczek wdroŋonych przez Model Systemu Cząstek wodospadu dostarczany z biblioteką modeli NetLogo. Model ten zawiera regulacje dotyczące siģy cięŋkoķci, wiatru i lepkoķci, aby lepiej symulowaæ spadek przepģywu wody i wody. Kod zostaģ zaadaptowany do modelu Water Flowing Uphill w roztworze "czynniki cząsteczkowe 1". Mimo ŋe woda zdąŋyģa juŋ pģynąæ pod górę, robi to w bardzo nieoczekiwany sposób, w jakiķ sposób radząc sobie z tunelowaniem w otaczającej ziemi, niczym prawdziwym ŋyciem. Czytelnicy są zachęcani do samodzielnego znalezienia rozwiązania tego problemu, a przy okazji obserwowania, jak radzą sobie z rozwiązywaniem problemów. Trudnym aspektem tego problemu jest jednak niedopuszczenie do dziaģania modelu, poniewaŋ moŋna to zrobiæ doķæ ģatwo, przy odrobinie wysiģku. Prawdziwy problem polega na tym, aby komputer sam rozpoznaģ, na czym polega ten problem, i automatycznie generuje rozwiązania. Ta umiejętnoķæ musi zostaæ zaprogramowana na następną generację systemów sztucznej inteligencji, jeķli mamy wykonaæ kolejny krok w kierunku systemów AI z inteligencją poziomu ludzkiego. Byæ moŋe ostatecznym testem dla systemu sztucznej inteligencji jest to, czy moŋe on sam stworzyæ system sztucznej inteligencji.
Podsumowanie i dyskusja
Podkreķlono znaczenie okreķlania kryteriów projektowych, takich jak cele, zasady i cele dla systemów sztucznej inteligencji, a jako punkt wyjķcia do dyskusji zaproponowano kilka kryteriów projektowych. Nie wiemy jeszcze jednak, jak zbudowaæ system sztucznej inteligencji, pomimo pewnych pomysģowych rozwiązaņ o imponujących wynikach, o których mowa wczeķniej. Potrzebujemy nowych naukowców, obecnych studentów AI, którzy będą badaczami przyszģoķci, aby opracowaæ nowe rozwiązania lub sprawiæ, by byģy lepsze, aby je krytykowaæ, aby dowiedzieæ się, co jest z nimi nie tak i staraæ się opracowaæ lepsze symulacje coraz bliŋsze rzeczywistoķci. Jedną z moŋliwoķci jest to, ŋe przyszģy system sztucznej inteligencji wykona dla nas pracę. Wcielone podejķcie Brooksa do inteligencji oferuje moŋliwoķæ pojawienia się inteligencji poprzez zģoŋone interakcje agentów z ich otoczeniem. Lub, jeķli uda nam się zbudowaæ system sztucznej inteligencji o podobnych zdolnoķciach rozwiązywania problemów dla ludzi, system mógģby wymyķliæ, jak rozwiązaæ problem, poniewaŋ miaģby moŋliwoķæ generowania i testowania rozwiązaņ szybciej niŋ my. Kaŋda z tych moŋliwoķci wymaga jednak pewnych przeģomów, zanim zostaną one zrealizowane. Jako ostatnie sģowo moŋemy stworzyæ analogię między projektowaniem systemów sztucznej inteligencji a próbowaniem przepģywu wody pod górę. Moŋemy poķwięciæ wiele wysiģku naukowego, aby znaležæ rozwiązanie, które nie polega na zmianie problemu. Lub moŋemy uŋyæ iluzji i sprawiæ, ŋe wygląda tak, jakby woda pģynęģa pod górę. Oczywiķcie zawsze moŋemy stworzyæ wirtualne ķrodowisko, w którym prawa fizyki są tym, co sami decydujemy. Oczywiste jest, ŋe rozwiązania dostarczane przez model Water Flowing Uphill NetLogo są niewystarczające i nie symulują prawdziwego ŋycia, a zatem wymagają znacznej poprawy. Podobnie, obecne rozwiązania dla systemów sztucznej inteligencji są niewystarczające i wymagają poprawy, poniewaŋ nie osiągnęliķmy jeszcze ostatecznego celu Sztucznej Inteligencji, co najmniej tak zdefiniowanego zgodnie z wymienionymi powyŋej celami projektowania. Niektórzy twierdzą, ŋe stworzenie inteligentnego systemu inteligentnego moŋe byæ niemoŋliwe. Ale moŋe uda się stworzyæ system, który ma zģudzenie inteligencji. Lub tworzyæ inteligencję w wirtualnym ķwiecie lub poprzez posiadanie robota ucieleķnionego w prawdziwym ķwiecie. Dla niektórych moŋe to wystarczyæ; dla innych, za maģo; a jeszcze inni, za duŋo. Ale z naszych dąŋeņ z pewnoķcią odkrywamy nowe miejsca na granicy badaņ nad sztuczną inteligencją i zdobywamy nową wiedzę. Wyszukiwanie nigdy nie będzie kompletne, poniewaŋ po prostu zaproponuje inne ķcieŋki do odkrycia w niekoņczącym się zadaniu. Podsumowanie waŋnych pojęæ, które naleŋy wyciągnąæ z tego rozdziaģu, pokazano poniŋej:
• Istnieje wiele przepisów na inteligencję, które wymagają róŋnych skģadników.
• Umiejętnoķci konwersacyjne są waŋnym skģadnikiem inteligencji.
• Zdolnoķæ rozwiązywania problemów jest kolejnym waŋnym skģadnikiem inteligencji.
• Cele SMARTER są potrzebne przede wszystkim podczas projektowania systemów sztucznej inteligencji.
• Systemy AI zaczynają osiągaæ doskonaģe wyniki w wielu dziedzinach, ale w przypadku większoķci z tych systemów wciąŋ istnieje
wiele pracy do zrobienia, aby osiągnąæ ludzkie wyniki konkurencyjne i nie tylko.
• The Mirror Test jest kontrowersyjnym testem na samoķwiadomoķæ.
• Wiarygodnoķæ jest proponowana jako kryterium testowania sztucznej inteligencji w ķrodowiskach wirtualnych