Rozpoznawanie wzorców
Większoķæ uczestników letniego projektu Dartmouth byģa zainteresowana naķladowaniem wyŋszych poziomów ludzkiej myķli. Ich praca polegaģa na pewnej introspekcji dotyczącej tego, jak ludzie rozwiązują problemy. Jednak wiele naszych zdolnoķci umysģowych wykracza poza naszą zdolnoķæ introspekcji. Nie wiemy, jak rozpoznajemy džwięki mowy, czytamy kursywę, odróŋniamy filiŋankę od talerza lub identyfikujemy twarze. Robimy te rzeczy automatycznie, nie myķląc o nich. Nie mając wskazówek z introspekcji, wczeķni badacze zainteresowani automatyzacją niektórych naszych zdolnoķci percepcyjnych oparli swoją pracę na intuicyjnych pomysģach dotyczących postępowania, na sieci prostych modeli neuronów i na technikach statystycznych. Póžniej pracownicy uzyskali dodatkowe informacje z badaņ neurofizjologicznych dotyczących widzenia zwierząt. W tej częķci opiszę pracę z lat 50. i 60. XX wieku nad tzw. rozpoznawaniem wzorców. To zdanie odnosi się do procesu analizy obrazu wejķciowego, segmentu mowy, sygnaģu elektronicznego lub innej próbki danych i zaklasyfikowanie go do jednej z kilku kategorii. Na przykģad do rozpoznawania znaków kategorie odpowiadaģyby kilkudziesięciu literom alfanumerycznym. Większoķæ prac nad rozpoznawaniem wzorów w tym okresie dotyczyģa materiaģów dwuwymiarowych, takich jak drukowane strony lub zdjęcia. Moŋna byģo juŋ skanowaæ obrazy w celu przeksztaģcenia ich w tablice liczb (zwanych póžniej "pikselami"), które następnie mogģy byæ przetwarzane przez programy komputerowe, takie jak Dinneen i Selfridge. Russell Kirsch i wspóģpracownicy z National Bureau of Standards (obecnie Narodowy Instytut Standardów i Technologii) równieŋ byģ jednym z pierwszych pionierów przetwarzania obrazu. W 1957 r. Kirsch zbudowaģ skaner bębnowy i wykorzystaģ go do zeskanowania zdjęcia swojego trzymiesięcznego syna Waldena. Mówi się, ŋe jest to pierwsza zeskanowana fotografia, mierząca 176 pikseli z boku. Za pomocą swojego skanera eksperymentowaģ z programami do obróbki zdjęæ dziaģającymi na komputerze SEAC (Standards Eastern Automatic Computer).
Rozpoznawanie znaków
Wczesne starania o postrzeganie obrazów wizualnych koncentrowaģy się na rozpoznawaniu znaków alfanumerycznych na dokumentach. Pole to staģo się znane jako "optyczne rozpoznawanie znaków". Sympozjum poķwięcone informowaniu o postępach w tym temacie odbyģo się w Waszyngtonie w styczniu 1962 r. Podsumowując, w tym czasie istniaģy urządzenia umoŋliwiające doķæ dokģadne rozpoznawanie czcionek staģych (pisanych na maszynie lub drukowanych) na papierze. Byæ moŋe stan rzeczy najlepiej wyraziģ jeden z uczestników sympozjum, J. Rabinow z Rabinow Engineering, który powiedziaģ: "W naszej firmie myķlimy, ŋe moŋemy przeczytaæ wszystko, co jest drukowane, a nawet niektóre rzeczy, które są napisane. Jedynym haczykiem jest to, ile dolarów trzeba wydaæ? ". Znaczącym sukcesem w latach 50. byģ system rozpoznawania atramentu magnetycznego (MICR) opracowany przez naukowców z SRI International (zwany wówczas Stanford Research Institute) do czytania stylizowanych znaków atramentu magnetycznego na dole czeków. MICR byģ częķcią systemu SRI ERMA (Electronic Recording Method of Accounting) sģuŋącego do automatyzacji przetwarzania czeków oraz zarządzania rachunkami i zarządzania księgowaniem. Wedģug strony internetowej SRI "W kwietniu 1956 r. Bank of Ameryka ogģosiģa, ŋe General Electric Corporation zostaģa wybrana do produkcji modeli produkcyjnych ... W 1959 r. General Electric dostarczyģ pierwsze 32 systemy obliczeniowe ERMA do Bank of America. ERMA sģuŋyģ jako komputer księgowy i system obsģugi czeków do 1970 r" . Większoķæ metod rozpoznawania w tym czasie polegaģa na dopasowaniu znaku (po jego wyizolowaniu na stronie i przekonwertowaniu go na tablicę zer i jedynek) z prototypowymi wersjami znaku zwanymi "szablonami" (równieŋ przechowywanymi jako tablice na komputerze) . Jeķli znak pasuje do szablonu dla "A", powiedzmy, wystarczająco lepiej niŋ inne szablony, dane wejķciowe zostaģy zadeklarowane jako "A." Dokģadnoķæ rozpoznania ulegģa pogorszeniu, jeķli znaki wejķciowe nie byģy prezentowane w standardowej orientacji, nie byģy tej samej czcionki co szablon lub miaģy niedoskonaģoķci. Artykuģy z 1955 r autorstwa Selfridge i Dinneen zaproponowaģy kilka pomysģów na wyjķcie poza dopasowywanie szablonów. Praca Olivera Selfridge'a i Ulricha Neissera z 1960 r. posunęģa tę pracę dalej. Ten artykuģ jest waŋny, poniewaŋ byģ udaną, wczesną próbą uŋycia przetwarzania obrazu, ekstrakcji funkcji i wyuczonych wartoķci prawdopodobieņstwa w rozpoznawaniu znaków odręcznie wydrukowanych. Znaki zostaģy zeskanowane i przedstawione na "siatkówce" 32 x 32 lub tablicy zer i jedynek. Zostaģy one następnie przetworzone przez róŋne operacje odnawiania (podobne do tych, o których wspominaģem w związku z artykuģem Dinneena z 1955 r.) W celu usunięcia przypadkowych kawaģków szumu, luk, linii pogrubienia i wzmocnienia krawędzi. "Oczyszczone" obrazy zostaģy następnie sprawdzone pod kątem występowania "cech" (podobnych do cech, o których wspomniaģem w związku z artykuģem Selfridgea z 1955 r.). W sumie uŋyto 28 funkcji -takich jak maksymalna liczba przypadków linia pozioma przecinaģa obraz, względne dģugoķci róŋnych krawędzi i czy obraz miaģ "wklęsģoķæ skierowaną na poģudnie". Przywoģując system Pandemonium Selfridge′a, moŋemy myķleæ o procesie wykrywania cech jako wykonywanym przez "demony". Na wyŋszym poziomie hierarchii niŋ demony cechowe byģy "demony rozpoznające" - po jednym na kaŋdą literę. (Wersja tego systemu przetestowana przez Worthie Doyle z Lincoln Laboratory zostaģa zaprojektowana do rozpoznawania dziesięciu róŋnych ręcznie drukowanych znaków, a mianowicie: A, E, I, L, M, N, O, R, S i T.) Kaŋde rozpoznanie demon otrzymaģ jako dane wejķciowe od kaŋdego z demonów wykrywających cechy. Ale po pierwsze, dane wejķciowe do kaŋdego demona rozpoznającego zostaģy pomnoŋone przez wagę, która uwzględniaģa znaczenie wkģadu odpowiedniej cechy w podejmowaniu decyzji. Na przykģad, jeķli cecha 17 byģa waŋniejsza niŋ cecha 22 przy podejmowaniu decyzji, ŋe znakiem wejķciowym jest "A", wówczas dane wejķciowe do rozpoznającego "A" z cechy 17 byģyby waŋone bardziej niŋ dane wejķciowe z cechy. Po tym, jak kaŋdy demon rozpoznania zsumowaģ sumę swoich waŋonych danych wejķciowych, ostateczny "demon decyzyjny" zdecydowaģ na korzyķæ tego, ŋe postaæ ma największą sumę. Wartoķci wag zostaģy okreķlone w procesie uczenia się, podczas którego analizowano 330 obrazów "treningowych". Zliczenia zestawiono w tabelach, ile razy wykryto kaŋdą cechę dla kaŋdej innej litery w zestawie szkoleniowym. Te dane statystyczne wykorzystano do oszacowania prawdopodobieņstwa wykrycia danej cechy dla kaŋdej litery. Te oszacowania prawdopodobieņstwa wykorzystano następnie do waŋenia cech sumowanych przez rozpoznające demony. Po szkoleniu system zostaģ przetestowany na próbkach ręcznie drukowanych znaków, których jeszcze nie widziaģ. Wedģug Selfridge′a i Neissera: "Ten program sprawia, ŋe tylko okoģo 10 procent mniej jest poprawnych identyfikacji, niŋ czytelnicy ludzcy robią {na pewno przyzwoitą wydajnoķæ."
Sieci neuronowe
Perceptrony
W 1957 r. Frank Rosenblatt (1928-1969, psycholog z Cornell Aeronautical Laboratory w Buffalo w stanie Nowy Jork) rozpocząģ pracę nad sieciami neuronowymi w ramach projektu o nazwie PARA (Perceiving and Recognizing Automaton). Motywowaģ go wczeķniejsza praca McCullocha. Pitts i Hebb zainteresowali się tymi sieciami, które nazwaģ perceptronami, jako potencjalnymi modelami ludzkiego uczenia się, poznania i pamięci. Kontynuując na początku lat 60. jako profesor na Cornell University w Ithaca w Nowym Jorku, eksperymentowaģ z wieloma róŋnych rodzajów perceptronów. Jego praca, bardziej niŋ Clarka i Farleya oraz innych pionierów sieci neuronowych, byģa odpowiedzialna za zainicjowanie jednej z gģównych alternatyw dla metod przetwarzania symboli w AI, a mianowicie sieci neuronowych. Perceptrony Rosenblatta skģadaģy się z McCulloch {Elementy neuronowe w stylu Pittsa, takie jak ten pokazany poniŋej 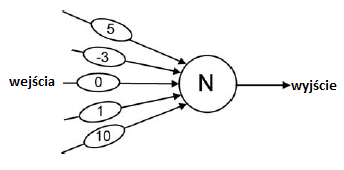
Kaŋdy element miaģ dane wejķciowe (przychodzące od lewej strony w górę), \ wagi "(pokazane przez wybrzuszenia na liniach wejķciowych) i jedno wyjķcie (wychodzące w prawo). Dane wejķciowe miaģy wartoķci 1 lub 0, i kaŋde wejķcie zostaģo pomnoŋone przez związaną z nim wartoķæ wagi. Element neuronowy obliczyģ sumę tych waŋonych wartoķci. Na przykģad, jeķli wszystkie dane wejķciowe do elementu neuronowego na rysunku byģy równe 1, suma wynosiģaby 13. Gdyby suma byģa większa niŋ (lub po prostu równa) "wartoķæ progowa", powiedzmy 7, powiązana z elementem, wówczas dane wyjķciowe elementem neuronowym będzie 1, co byģoby w tym przykģadzie. W przeciwnym razie wynik wyniósģby 0. Perceptron skģada się z sieci tych elementów neuronowych, w których wyjķcia jednego elementu są danymi wejķciowymi dla innych. (Jest tu analogia do Pandemonium Selfridge'a, w którym demony ķredniego poziomu otrzymują "krzyki" demony niŋszego poziomu. Cięŋary na liniach wejķciowych elementu neuronowego moŋna traktowaæ jako analogiczne do "kontroli siģy" zwiększającej lub zmniejszającej siģę w Pandemonium.) Przykģadowy perceptron pokazano poniŋej.
[Rosenblatt narysowaģ schematy perceptronów w formacie poziomym (styl elektrotechniczny), z wejķciami po lewej i wyjķciami po prawej. Tutaj uŋywam stylu pionowego ogólnie preferowanego przez informatyków do hierarchii, z najniŋszym poziomem u doģu i najwyŋszym u góry. Aby uproķciæ schemat, wybrzuszenia wagi nie są pokazane.] Chociaŋ przedstawiony perceptron, z tylko jedną jednostką wyjķciową, jest zdolny tylko do dwóch róŋnych wyjķæ (1 lub 0), wiele wyjķæ (zestawy 1 i 0) moŋna uzyskaæ przez uģoŋenie dla kilku jednostek wyjķciowych.
Warstwa wejķciowa, pokazana na dole rysunku, byģa zazwyczaj prostokątnym ukģadem 1 i 0 odpowiadających komórkom zwanym "pikselami" czarno-biaģego obrazu. Jedną z aplikacji, którymi interesowaģa się Rosenblatt, byģo, podobnie jak Selfridge, rozpoznawanie znaków. Uŋyję prostej algebry i geometrii, aby pokazaæ, jak elementy neuronowe w sieciach perceptronowych moŋna "szkoliæ" w celu uzyskania poŋądanych wyników. Rozwaŋmy na przykģad pojedynczy element neuronowy, którego danymi wejķciowymi są wartoķci x1, x2 i x3 i których powiązanymi wartoķciami wagowymi są w1, w2 i w3. Gdy suma obliczona przez ten element jest dokģadnie równa jego wartoķci progowej, powiedzmy t, mamy równanie w1x1 + w2x2 + w3x3 = t:
W algebrze takie równanie nazywa się równaniem "liniowym. "Okreķla granicę liniową, czyli pģaszczyznę, w przestrzeni trójwymiarowej. Pģaszczyzna oddziela te wartoķci wejķciowe, które spowodowaģyby, ŋe element neuronowy miaģby wynik 1 z tych, które spowodowaģyby, ŋe miaģby wynik 0. Pokazuję typową pģaską granicę na rysunku
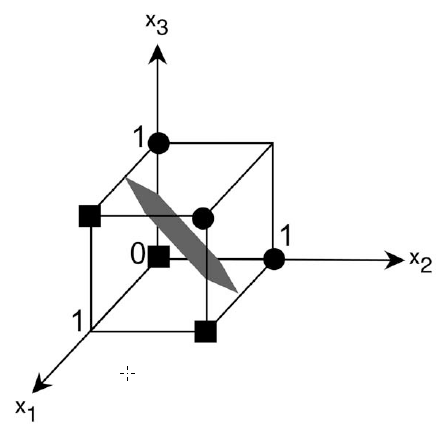
Wejķcie do elementu neuronowego moŋe byæ przedstawione jako punkt (to znaczy wektor) w tej trójwymiarowej przestrzeni. Jego wspóģrzędne to wartoķci x 1 , x 2 i x 3 , z których kaŋda moŋe wynosiæ 1 lub 0. Gure pokazuje szeķæ takich punktów, trzy z nich (powiedzmy maģe kóģka) powodujące, ŋe element ma moc wyjķciową 1, a trzy (powiedzmy maģe kwadraty) powodujące, ŋe ma moc wyjķciową 0. Zmiana wartoķci progu powoduje, ŋe pģaszczyzna poruszaæ się na boki w kierunku równolegģym do siebie. Zmiana wartoķci cięŋarów powoduje obrót pģaszczyzny. Tak więc, zmieniając wartoķci cięŋaru, punkty, które kiedyķ znajdowaģy się po jednej stronie pģaszczyzny, mogģy skoņczyæ się po drugiej stronie. "Szkolenie" odbywa się poprzez wykonanie takich zmian. Będę miaģ więcej do powiedzenia na temat procedur szkoleniowych. W wymiarach większych niŋ trzy (co zwykle ma miejsce), liniowa granica nazywana jest "hiperpģaszczyzną". Chociaŋ nie jest moŋliwe zwizualizowanie tego, co dzieje się w przestrzeniach o duŋych wymiarach, matematycy wciąŋ mówią o punktach wejķciowych w tych przestrzeniach oraz obrotach i ruchach hiperpģaszczyzn w odpowiedzi na zmiany wartoķci wag i progów. Rosenblatt zdefiniowaģ kilka rodzajów perceptronów. Nazwaģ ten pokazany na schemacie "czteropowģokowym perceptronem sprzęŋonym szeregowo". (Rosenblatt liczyģ dane wejķciowe jako pierwszą warstwę.) Nazywano to "sprzęŋeniem szeregowym", poniewaŋ moc wyjķciowa kaŋdego elementu neuronowego przekazywana byģa do elementów neuronowych w kolejnej warstwie. W najnowszej terminologii zamiast wyraŋenia "sprzęŋony szeregowo" uŋyto wyraŋenia "informacje zwrotne". Natomiast perceptron "sprzęŋony krzyŋowo" moŋe mieæ wyjķcia elementów neuronowych w jednej warstwie jako dane wejķciowe do elementów neuronalnych w tej samej warstwie. Perceptron sprzęŋony "krzyŋowo" moŋe mieæ dane wyjķciowe elementów neuronowych w jednej warstwie elementy neuronowe w warstwach o niŋszych numerach. Rosenblatt pomyķlaģ o swoich perceptronach jako o modelach okablowania częķci mózgu. Z tego powodu nazwaģ elementy neuronowe we wszystkich warstwach, ale w warstwie wyjķciowej, "jednostkami asocjacji" (A-units), poniewaŋ zamierzaģ je modelowaæ asocjacje wykonywane przez sieci neuronów w mózgu. Szczególnie interesujące byģy badania Rosenblatta to, co nazwaģ "perceptronem alfa". Skģadaģo się z trójwarstwowej sieci sprzęŋenia zwrotnego z warstwą wejķciową, warstwą asocjacyjną i jedną lub więcej jednostkami wyjķciowymi. W większoķci jego eksperymentów dane wejķciowe miaģy wartoķci 0 lub 1, odpowiadające czarnym lub biaģym pikselom na obrazie wizualnym przedstawionym na tak zwanej "siatkówce". Kaŋda jednostka A otrzymaģa dane wejķciowe (które nie zostaģy pomnoŋone przez wartoķci masy) z jakiegoķ losowo wybranego podzbioru pikseli i wysģaģa swój wynik , poprzez zestawy regulowanych wag, do koņcowych jednostek wyjķciowych, których wartoķci binarne moŋna interpretowaæ jako kod dla kategorii obrazu wejķciowego. Próbowano zastosowaæ róŋne "procedury szkoleniowe" w celu dostosowania wag jednostek wyjķciowych perceptronu alfa , W najbardziej dla tych (dla celów rozpoznawania wzorców) wagi prowadzące do jednostek wyjķciowych wynosiģy korygowane tylko wtedy, gdy jednostki te popeģniģy bģąd w klasyfikacji danych wejķciowych. Korekty byģy takie, aby wymusiæ na wyjķciu prawidģową klasyfikację dla tego konkretnego wejķcia. Ta technika, która wkrótce staģa się standardem, zostaģa nazwana "procedurą korekcji bģędów". Rosenblatt z powodzeniem wykorzystaģ ją w szeregu eksperymentów do szkolenia perceptronów do klasyfikowania sygnaģów wizualnych, takich jak znaki alfanumeryczne lub sygnaģów akustycznych, takich jak džwięki mowy. Profesor H. David Block, matematyk Cornell wspóģpracujący z Rosenblattem, byģ w stanie udowodniæ, ŋe procedura korekcji bģędów gwarantuje znalezienie hiperpģaszczyzny, która doskonale oddzieli zestaw danych treningowych, gdy taka hiperpģaszczyzna istniaģa. wykonane za pomocą symulacji komputerowych, Rosenblatt wolaģ budowaæ wersje sprzętowe swoich perceptronów (symulacje byģy wczesne na wczesnych komputerach, co wyjaķniaģo zainteresowanie budowaniem specjalnego sprzętu perceptronowego). MARK I byģ alfa-perceptronem zbudowanym w Cornell Aeronautical Laboratory pod sponsorowanie Oddziaģu Systemów Informatycznych Offce of Naval Research i Rome Air Development Center. Zostaģo to publicznie zademonstrowane 23 czerwca 1960 r. MARK I uŋywaģ regulatorów gģoķnoķci (zwanych przez inŋynierów elektryków "potencjometrami") do waŋenia. Mają one przymocowane do nich maģe silniki w celu wykonania regulacji w celu zwiększenia lub zmniejszenia wartoķci masy.
W 1959 roku Frank Rosenblatt przeniósģ swoją pracę perceptronową z Cornell Aeronautical Laboratory w Buffalo w stanie Nowy Jork na Cornell University, gdzie zostaģ profesorem psychologii. Wraz z Blockiem i kilkoma studentami Rosenblatt kontynuowaģ eksperymentalne i teoretyczne prace nad perceptronami. Jego ksiąŋka Principles of Neurodynamics szczegóģowo opisuje jego teoretyczne pomysģy i wyniki eksperymentów. Ostatni system Rosenblatta, zwany Tobermory, zostaģ zbudowany jako urządzenie do rozpoznawania mowy. [Tobermory to imię kota, który nauczyģ się mówiæ w The Chronicles of Clovis, grupie opowiadaņ Saki (H. H. Munro).] Kilka doktorantów studenci, w tym George Nagy, Carl Kessler, R. D. Joseph i inni, ukoņczyli projekty perceptronowe pod Rosenblattem w Cornell. W ostatnich latach pobytu w Cornell Rosenblatt zająģ się badaniem transferu pamięci chemicznej u robaków i innych zwierząt {temat caģkowicie usunięty z pracy nad perceptronem. Niestety, Rosenblatt zginąģ w wypadku podczas ŋeglugi w zatoce Chesapeake w 1969 roku. Mniej więcej w tym samym czasie co alfa-perceptron Rosenblatta, Woodrow W. (Woody) Bledsoe (1921 {1995) i Iben Browning (1918-1991), dwaj matematycy z Sandia Laboratories w Albuquerque w Nowym Meksyku, równieŋ prowadzili badania nad rozpoznawaniem znaków, które wykorzystywaģy losowe próbki obrazów wejķciowych. Eksperymentowali z systemem, który wyķwietlaģ obrazy znaków alfanumerycznych na mozaice 10 x 15 fotokomórek i próbkowaģ stany 75 losowo wybranych par fotokomórek. Wskazując, ŋe pomysģ moŋna rozszerzyæ na próbkowanie większych grup pikseli, powiedzmy N z nich, nazwali swoją metodę metodą "N-krotki". Wykorzystali wyniki tego próbkowania do podjęcia decyzji o kategorii litery wejķciowej
ADALINESY I MADALINES
Niezaleŋnie od Rosenblatt, grupa kierowana przez profesora inŋynierii elektrycznej Stanforda Bernarda Widrowa równieŋ pracowaģa nad systemy sieci neuronowych na przeģomie lat 50. i 60. XX wieku. Widrow niedawno doģączyģ do Stanford po ukoņczeniu doktoratu z teorii sterowania na MIT. Chciaģ wykorzystaæ systemy sieci neuronowej do czegoķ, co nazwaģ "kontrolą adaptacyjną". Jedno z urządzeņ zbudowanych przez Widrow nazwano "ADALINE "(dla adaptacyjnej sieci liniowej). Byģ to pojedynczy element neuronowy, którego regulowane cięŋary byģy realizowane przez przeģączalne (w ten sposób regulowane) obwody rezystorów. Widow i jeden z jego uczniów, Marcian E. "Ted" Hoff Jr. (który póžniej wynalazģ pierwszy mikroprocesor w firmie Intel), opracowali regulowaną wagę, którą nazywali "a" "memistor". Skģadaģ się z grafitowego pręta, na którym warstwa miedzi mogģa byæ powlekana i nieplaterowana - zmieniając w ten sposób jej opór elektryczny. Widrow i Hoff opracowali procedurę szkolenia dla ich elementu neuronowego ADALINE, który nazwano algorytmem adaptacyjnym najmniejszych ķrednich kwadratów Widrowa-Hoffa. Większoķæ eksperymentalnych prac Widrowa zostaģa wykonana przy uŋyciu symulacji na komputerze IBM1620. Ich najbardziej skomplikowany projekt sieci nazwano "MADALINE" (dla wielu ADALINE). Procedurę szkoleniową opracowaģ dla niego w Stanford student William Ridgway.
Systemy MINOS w SRI
Sukces Rosenblatta z perceptronami w problemach z rozpoznawaniem wzorców doprowadziģ do wzmoŋenia wysiģków badawczych innych osób w celu powielenia i rozszerzenia jego wyników. W latach szeķædziesiątych byæ moŋe najbardziej znaczące prace w zakresie rozpoznawania wzorców z wykorzystaniem sieci neuronowych zostaģy wykonane w Stanford Research Institute w Menlo Park w Kalifornii. Tam Charles A. Rosen (1917-2002) kierowaģ laboratorium, które próbowaģo wytrawiæ mikroskopijne lampy próŋniowe na podģoŋu póģprzewodnikowym. Rosen spekulowaģ, ŋe obwody zawierające te lampy mogą byæ ostatecznie "podģączone" do wykonywania przydatnych zadaņ przy uŋyciu niektórych procedur szkoleniowych opisanych przez Franka Rosenblatta. SRI zatrudniģo Rosenblatta jako konsultanta do pomocy w projektowaniu eksploracyjnej sieci neuronowej. Kiedy w 1960 roku przeprowadziģem wywiad na stanowisko w SRI, zespóģ w laboratorium Rosen pod kierownictwem Alfreda E. (Teda) Brain (1923-2004) wģaķnie zakoņczyģ budowę maģej sieci neuronowej o nazwie MINOS. (W mitologii greckiej Minos byģ królem Krety i synem Zeusa i Europy. Po ķmierci Minos byģ jednym z trzech sędziów w podziemiu). Brain uwaŋaģ, ŋe symulacje komputerowe sieci neuronowych są zbyt wolne do praktycznych zastosowaņ, co prowadzi do decyzji o budowie zamiast programowania. (Komputer IBM 1620 uŋywany w tym samym czasie przez grupę Widrowa w Stanford do symulacji sieci neuronowych miaģ podstawowy cykl maszynowy wynoszący 21 mikrosekund i maksymalnie 60 000 "cyfr "pamięci o swobodnym dostępie.) W celu regulacji cięŋarów MINOS zastosowaģ magnetyczny urządzenia zaprojektowane przez Brain. Rosenblatt pozostawaģ w bliskim kontakcie z SRI, poniewaŋ byģ zainteresowany wykorzystaniem tych urządzeņ magnetycznych jako zamienników swoich potencjometrów napędzanych silnikiem. Entuzjazm i optymizm Rosen odnoķnie potencjaģu sieci neuronowych pomógģ mu doģączyæ do SRI. Po moim przybyciu w lipcu 1961 r. dostaģ szkic ksiąŋki Rosenblatta do przeczytania. Zespóģ Brain dopiero zaczynaģ prace nad budową duŋej sieci neuronowej, zwanej MINOS II, kontynuacją mniejszego systemu MINOS. wspierany przede wszystkim przez Korpus Sygnaģowy Armii USA w latach 1958-1967. Celem pracy MINOS byģo "przeprowadzenie badaņ naukowych i eksperymentalnych badaņ technik i sprzętu cechy odpowiednie do praktycznego zastosowania w graficznym przetwarzaniu danych dla potrzeb wojskowych. "Gģównym celem projektu byģo automatyczne rozpoznawanie symboli na mapach wojskowych. Podjęto równieŋ próby innych zastosowaņ - takich jak rozpoznawanie pojazdów wojskowych, takich jak czoģgi, na zdjęciach lotniczych i rozpoznawanie ręcznie drukowanych znaków - w pierwszym etapie przetwarzania przez MINOS II obraz wejķciowy byģ replikowany 100 razy za pomocą matrycy plastikowej 10 x 10. Kaŋdy z tych identycznych obrazów zostaģ następnie przesģany przez wģasną optyczną maskę wykrywającą cechy, a ķwiatģo przez maskę zostaģo wykryte przez fotokomórkę i porównane z progiem. Rezultatem byģ zestaw 100 wartoķci binarnych (wyģączone - wģączone). Wartoķci te stanowiģy dane wejķciowe do zestawu 63 elementów neuronowych ("jednostek A" w terminologii Rosenblatta), kaŋdy o 100 zmiennych wagach magnetycznych. 63 wyjķcia binarne z tych elementów neuronowych zostaģy następnie przetģumaczone na jedną z 64 decyzji dotyczących kategorii oryginalnego obrazu wejķciowego. (Zbudowaliķmy 64 równie odlegģe "punkty" w szeķædziesięciu trójwymiarowych przestrzeniach i przeszkoliliķmy sieæ neuronowa, dzięki czemu kaŋdy obraz wejķciowy tworzy punkt bliŋszy wģasnemu punktowi prototypu niŋ innemu. Kaŋdy z tych prototypowych punktów byģ jedną z 64 "sekwencji rejestru przesuwnego o maksymalnej dģugoķci" o 63 wymiarach).
W latach 60. grupa sieci neuronowych SRI, zwana wówczas
Grupa Learning Machines badaģa wiele róŋnych organizacji sieciowych i procedur szkoleniowych. Poniewaŋ komputery staģy się zarówno bardziej dostępne, jak i potęŋniejsze, coraz częķciej korzystaliķmy z symulacji (w róŋnych centrach komputerowych) na komputerach Burroughs 220 i 5000 oraz na IBM 709 i 7090. W poģowie lat 60. otrzymaliķmy wģasny edytowany komputer, SDS 910 (SDS 910, opracowany w Scienti c Data Systems, byģ pierwszym komputerem, w którym zastosowano tranzystory krzemowe). Uŋyliķmy tego komputera w poģączeniu z najnowszą wersją naszego sprzętu sieci neuronowej (teraz z wykorzystaniem zestawu 1024 soczewek wstępnego przetwarzania), poģączenie nazwaliķmy MINOS III. Jednym z najbardziej udanych rezultatów w systemie MINOS III byģo automatyczne rozpoznawanie ręcznie drukowanych znaków na arkuszach kodujących FORTRAN. (W latach 60. programy komputerowe byģy zwykle pisane ręcznie, a następnie konwertowane na karty dziurkowane przez operatorów uderzeņ kluczowych). Pracami tymi kierowali John Munson
(19391972), Peter Hart i Richard Duda. Neuronowa częķæ MINOS III zostaģa wykorzystana do stworzenia rankingu moŋliwych klasyfikacji dla kaŋdej postaci z miarą siģy dla kaŋdej postaci. Na przykģad, pierwszy znak napotkany w ciągu znaków moŋe zostaæ rozpoznany przez sieæ neuronową jako D o sile 90 i jako O o sile 10. Ale akceptując najbardziej pewną decyzję dla kaŋdego znaku nie moŋe powstaæ ciąg znaków, który jest prawnym oķwiadczeniem w języku FORTRAN {wskazując, ŋe co najmniej jedna decyzja byģa bģędna (przy zaģoŋeniu, ŋe ktokolwiek napisaģ oķwiadczenie na arkuszu kodowym napisaģ oķwiadczenie prawne). Zaakceptowanie drugiego lub trzeciego najbardziej bezpiecznego wyboru dla niektórych znaków moŋe byæ wymagane do utworzenia prawidģowego ciągu znaków. Caģkowitą stęSenie peģnego ciągu znaków obliczono, dodając stany poszczególnych znaków w ciągu. Następnie potrzebny byģ sposób uszeregowania tych liczb liczb caģkowitych dla kaŋdego z moŋliwych ciągów wynikających ze wszystkich róŋnych wyborów dla kaŋdego
znaku. Spoķród tego rankingu wszystkich moŋliwych ciągów system następnie wybraģ najbardziej pewny ciąg prawny. Jednak, jak napisaģ Richard Duda, Problem znalezienia pierwszego, drugiego, trzeciego
najbardziej zģoŋonego ciągu znaków nie jest wcale trywialnym problemem. Kluczem do skutecznego obliczenia rankingu byģo zastosowanie metody zwanej programowaniem dynamicznym. Ilustracja próbki oryginalnego žródģa i ostatecznego wyjķcia pokazano poniŋej.

Po przeszkoleniu częķci sieci neuronowej systemu, caģy system (który zdecydowaģ się na najbardziej pewny ciąg prawny) byģ w stanie osiągnąæ dokģadnoķæ rozpoznawania wynoszącą nieco ponad 98% na duŋej próbce materiaģu, który nie byģ częķcią tego, na co szkolono system. Rozpoznawanie odręcznych postaci z takim poziomem dokģadnoķci byģo znaczącym osiągnięciem w latach szeķædziesiątych. Rozszerzając swoje zainteresowania poza sieci neuronowe, Learning Machines Group ostatecznie przeksztaģciģo się w Centrum Sztucznej Inteligencji SRI, które do dziķ jest wiodącym przedsiębiorstwem badawczym zajmującym się AI.
Metody statystyczne
W latach pięædziesiątych i szeķædziesiątych istniaģo kilka zastosowaņ metod statystycznych do problemów z rozpoznawaniem wzorców. Wiele z tych metod byģo bardzo podobnych do niektórych technik sieci neuronowych. Przypomnij sobie, ŋe wczeķniej wyjaķniģem, jak zdecydowaæ, który z dwóch tonów będzie obecny w gģoķnym sygnale radiowym. Podobną technikę moŋna zastosowaæ do rozpoznawania wzorów. Do klasyfikowania obrazów (lub innych danych percepcyjnych) zwykle reprezentowano dane wejķciowe za pomocą listy wyróŋniających "cech", takich jak te uŋywane przez Selfridge'′a i jego wspóģpracowników. Na przykģad w rozpoznawaniu znaków alfanumerycznych jedną z pierwszych cech wyodrębniono z obrazu znaku, który ma zostaæ sklasyfikowany. Zazwyczaj cechy miaģy wartoķci liczbowe, takie jak liczba razy, gdy linie o róŋnych kątach przecinaģy znak lub dģugoķæ obwodu najmniejszego koģa, które caģkowicie otaczaģo znak. Wybór odpowiednich funkcji byģ często bardziej sztuką niŋ nauką, ale miaģ kluczowe znaczenie dla dobrej wydajnoķci. Potrzebujemy trochę elementarnej notacji matematycznej, aby pomóc opisaæ te statystycznie zorientowane metody rozpoznawania wzorców. Zaģóŋmy, ŋe lista funkcji wyodrębnionych ze znaku to {f1; f2; … ; fi;… :; fN}. Skrócę tę listę za pomocą pogrubionego symbolu X. Zaģóŋmy, ŋe istnieje k kategorii, C1; C2;… ; Ci; … ; Ck, do którego moŋe naleŋeæ znak opisany przez XUŋywając reguģy Bayesa w sposób podobny do opisanego wczeķniej, reguģa decyzyjna jest następująca:
Zdecyduj na korzyķæ tej kategorii, dla której p(X |Ci)p(Ci) jest największe, gdzie p(Ci jest prawdopodobieņstwem a priori kategorii Ci i p(p(Cii) to prawdopodobieņstwo X dla Ci. Prawdopodobieņstwa te moŋna wywnioskowaæ, zbierając dane statystyczne z duŋej próbki znaków.
Jak wspomniaģem wczeķniej, badacze w rozpoznawaniu wzorów często opisują proces decyzyjny w kategoriach geometrii. Wyobraŋają sobie, ŋe wartoķci cech uzyskanych z próbki obrazu moŋna przedstawiæ jako punkt w przestrzeni wielowymiarowej. Jeķli mamy kilka próbek dla kaŋdej powiedzmy dwóch znanych kategorii danych, moŋemy reprezentowaæ te próbki jako rozproszenie punktów w przestrzeni. W rozpoznawaniu znaków rozproszenie moŋe wystąpiæ nie tylko dlatego, ŋe obraz postaci moŋe byæ haģaķliwy, ale takŋe dlatego, ŋe postacie z tej samej kategorii mogą byæ rysowane nieco inaczej. Pokazuję dwuwymiarowy przykģad z funkcjami f1 i f2 na rysunku.
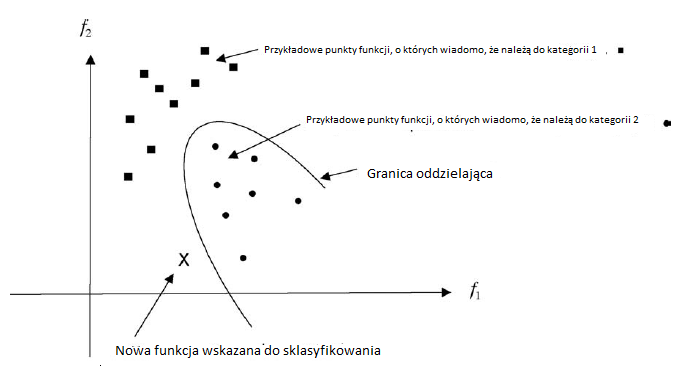
Na podstawie rozproszenia punktów w kaŋdej kategorii moŋemy obliczyæ oszacowanie prawdopodobieņstw potrzebnych do obliczenia prawdopodobieņstw. Następnie moŋemy wykorzystaæ prawdopodobieņstwa i wczeķniejsze prawdopodobieņstwa do podjęcia decyzji. Pokazuję tutaj granicę, obliczoną na podstawie prawdopodobieņstw i wczeķniejszych prawdopodobieņstw, która dzieli przestrzeņ na dwa regiony. W jednym regionie decydujemy się na kategorię 1; z drugiej wybieramy kategorię 2. Pokazuję takŋe nowy punkt funkcji, X, który ma zostaæ sklasyfikowany. W tym przypadku pozycja X względem granicy narzuca, ŋe klasyfikujemy X jako czģonka kategorii 1. Istnieją równieŋ inne metody klasyfikacji punktów charakterystycznych. Ciekawym przykģadem jest metoda \ najbliŋszego sąsiada. W tym schemacie, wynalezionym przez E. Fixa i JL Hodgesa w 1951,nowy punkt cechy jest przypisany do tej samej kategorii, co ten przykģadowy punkt cechy, do którego jest najbliŋej. na powyŋszym rysunku nowy punkt X zostaģby sklasyfikowany jako naleŋący do kategorii 2. przy uŋyciu metody najbliŋszego sąsiada.
Waŋne opracowanie metody najbliŋszego sąsiada przypisuje nowy punkt do tej samej kategorii co większoķæ k najbliŋszych punktów. reguģa decyzyjna wydaje się prawdopodobna (w przypadku, gdy istnieje wiele, wiele punktów próbnych kaŋdej kategorii), poniewaŋ istnieje więcej punktów próbnych kategorii Ci bliŋej nieznanego punktu, X, niŋ punkty próbne kategorii Cj jest dowodem, ŋe p(X | Ci) p (Ci) jest większy niŋ p(X | Cj)) p (Cj) W oparciu o tę ogólną obserwację Thomas Cover i Peter Hart rygorystycznie przeanalizowali skutecznoķæ metod najbliŋszego sąsiedztwa. Kaŋda technika rozpoznawania wzorców, nawet wykorzystująca sieci neuronowe lub najbliŋszych sąsiadów, moŋe byæ uwaŋana za konstruowanie granic oddzielających w wielowymiarowej przestrzeni cech. Inną metodę konstruowania granic przy uŋyciu "funkcji potencjalnych" zasugerowali rosyjscy naukowcy M. A. Aizerman, E. M. Braverman i L. I. Rozonoer w latach 60. Niektóre waŋne wczesne ksiąŋki na temat stosowania metod statystycznych w rozpoznawaniu wzorców to George Sebestyen, Richard Duda i Peter Hart. Technologia rozpoznawania wzorów pod koniec lat 60. XX wieku zostaģa dobrze oceniona przez George'a Nagy'a (który wczeķniej byģ jednym z doktorantów Franka Rosenblatta).
Zastosowania rozpoznawania wzorów w rozpoznaniu lotniczym
Sieæ neuronowa i metody statystyczne rozpoznawania wzorców przyciągnęģy wiele uwagi w wielu firmach z branŋy lotniczej i lotniczej na przeģomie lat 50. i 60. XX wieku. Firmy te miaģy duŋy budŋet na badania i rozwój wynikające z umów z Departamentem Obrony USA. Wiele z nich byģo szczególnie zainteresowanych problemem zwiadu powietrznego, tj. lokalizacją i identyfikacją "celów" na zdjęciach lotniczych. Wķród firm prowadzących szeroko zakrojone programy badawcze poķwięcone temu zagadnieniu i powiązanych z nimi problemami byģ Dziaģ Aeronutronic Ford Motor Co., Douglas Aircraft Company (jak wtedy byģo znane), General Dynamics, Lockheed Missiles and Space Division oraz Philco Corporation (Philco zostaģ póžniej przejęty przez Forda pod koniec 1961 r.) Wspomnę o niektórych pracach w Philco , Laveen N. Kanal, Neil C. Randall i Thomas Harley pracowali zarówno nad teorią, jak i metodami statystycznego rozpoznawania wzorców. Opracowane przez nich systemy sģuŋyģy do przeglądania zdjęæ lotniczych pod kątem interesujących celów wojskowych, takich jak czoģgi. ilustracja jednego z ich systemów pokazano na rysunku
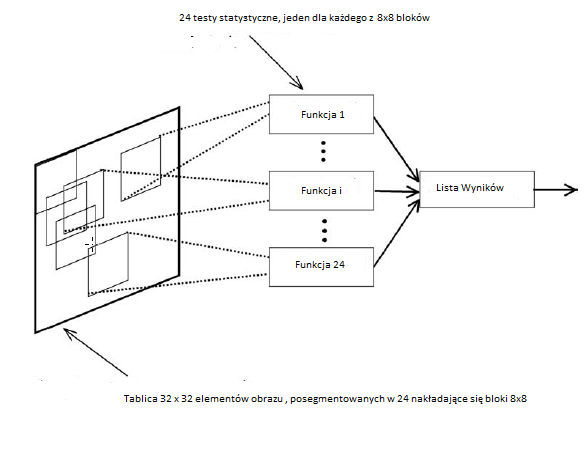
Aparat Philco zeskanowaģ materiaģ z 9-calowych negatywów zebranych przez samolot rozpoznawczy U2 podczas manewrów czoģgów armii amerykaņskiej w Fort Drum w Nowym Jorku. Niewielka częķæ zeskanowanego zdjęcia, prawdopodobnie zawierająca czoģg M-48 (w standardowej pozycji i rozmiarze), zostaģa najpierw przetworzona w celu wzmocnienia krawędzi, a wynik zostaģ przedstawiony systemowi wykrywania celu jako ukģad zer i jedynek. Pierwszy z ich systemów uŋywaģ tablicy 22 x 12; póžniej uŋywali tablicy 32 x 32, jak pokazano na powyŋszym rysunku. Tablica zostaģa następnie podzielona na 24 nakģadające się 8 x 8 "bloków cech". Dane w kaŋdym bloku obiektów są następnie poddawane testowi statystycznemu, aby zdecydowaæ, czy maģy obszar obrazu reprezentowany przez ten blok zawiera częķæ zbiornika. Testy statystyczne oparto na "próbce szkoleniowej" 50 obrazów zawierających zbiorniki i 50 próbek terenu niezawierającego zbiorników. Dla kaŋdego bloku cech 8 x 8 opracowano parametry statystyczne z tych próbek w celu ustalenia (liniowej) granicy w szeķædziesięciu - czterowymiarowa przestrzeņ, która najlepiej rozróŋnia próbki zbiorników od próbek nieczoģgowych. Korzystając z tych granic, system zostaģ następnie przetestowany na innym zestawie 50 obrazów zawierających zbiorniki i 50 obrazów niezawierających zbiorników. Dla kaŋdego obrazu testowego liczba cech bloki decydujące o "obecnoķci czoģgu" zostaģy obliczone, aby uzyskaæ koņcowy "wynik" liczbowy (np. 21 z 24 bloków zdecydowaģo, ŋe czoģg byģ obecny). Wynik ten moŋe byæ następnie wykorzystany do podjęcia decyzji, czy obraz zawiera czoģg. Autorzy stwierdzili, ŋe "wyniki eksperymentalne procedury klasyfikacji statystycznej przekroczyģy wszelkie oczekiwania". Prawie poģowa próbek testowych miaģa doskonaģe wyniki (to znaczy, wszystkie 24 bloki cech prawidģowo rozróŋniaģy zbiornik i zbiornik). Ponadto wszystkie próbki testowe zawierające zbiorniki miaģy wynik większy lub równy 11, a wszystkie próbki testowe niezawierające zbiorników miaģy wynik mniejszy lub równy 7. System wczesnego wykrywania zbiorników w Philco zostaģ zbudowany z analogowym zespóģ obwodów - nie zaprogramowany na komputerze. Jak póžniej opracowaģ Thomas Harley, lider projektu tego systemu, waŋne jest, aby pamiętaæ o technologicznym kontekķcie epoki, w której ta praca zostaģa wykonana. Wdroŋony przez nas system nie miaģ wbudowanych moŋliwoķci obliczeniowych. Cięŋarami liniowej funkcji dyskryminacyjnej byģy rezystory, które kontrolowaģy prąd pochodzący z (binarnego) žródģa napięcia w elementach rejestru przesuwnego. Prądy te zostaģy zsumowane i kaŋda cecha zostaģa rozpoznana lub nie w zaleŋnoķci od tego, czy suma tych prądów przekroczyģa wartoķæ progową. Te decyzje dotyczące funkcji binarnych zostaģy następnie zsumowane, ponownie w analogowym obwodzie elektrycznym, a nie w komputerze, i ponownie podjęto decyzję [zbiornik lub brak zbiornika] w zaleŋnoķci od tego, czy suma przekroczyģa wartoķæ progową
W innym systemie klasyfikacja statystyczna zostaģa wdroŋona przez program o nazwie MULTINORM, dziaģający na komputerze Philco 2000. W innych eksperymentach Philco zastosowaģ dodatkowe testy statystyczne, aby w większym stopniu obliczyæ niektóre bloki cech niŋ inne przy obliczaniu wyniku koņcowego. Kanal powiedziaģ, ŋe te eksperymenty z waŋeniem wyników bloków charakterystycznych "przewidywaģy ideę klasyfikacji maszyny wektorów noķnych (SVM) [...] przy uŋyciu pierwszej warstwy do identyfikacji próbek szkoleniowych blisko granicy między zbiornikami i innych czoģgi."
Oczywiķcie systemy te miaģy doķæ ģatwe zadanie. Wszystkie czoģgi byģy w standardowej pozycji i byģy juŋ odizolowane na zdjęciu. (Autorzy wspominają jednak o tym, w jaki sposób system moŋna dostosowaæ do radzenia sobie z czoģgami występującymi w dowolnej pozycji lub orientacji na obrazie. System uwaŋam za interesujący nie tylko ze względu na jego wydajnoķæ, ale takŋe poniewaŋ jest to system warstwowy (podobny do Pandemonium i do alfa-perceptronu) i poniewaŋ jest to przykģad, w którym oryginalny obraz jest podzielony na nakģadające się podobrazy, z których kaŋdy jest przetwarzany niezaleŋnie. Jak wspomnę póžniej, nakģadające się podobrazy odgrywają znaczącą rolę w niektórych modelach obliczeniowych kory nowej. Niestety raporty Philco zawierające szczegóģy tej pracy nie są ģatwo dostępne. Co więcej, Philco i niektóre inne grupy zaangaŋowane w tę pracę zniknęģy. Oto, co napisaģ mi Tom Harley o raportach Philco i o samym Philco:
Większoķæ prac związanych z rozpoznawaniem wzorów wykonanych w Philco w latach 60. XX wieku byģa sponsorowana przez Departament Obrony, a raporty nie byģy dostępne do publicznej dystrybucji. Od tego czasu sama firma naprawdę rozpģynęģa się w powietrzu. Firma Phil Motor zostaģa kupiona przez Ford Motor Company w 1961 r., A do 1966 r. Wyeliminowali laboratoria badawcze Philco, w których pracowaģ Laveen Kanal. Ford próbowaģ przenieķæ tą maģą grupę do rozpoznawania wzorów do Newport Beach w Kalifornii [lokalizacja firmy Aeronutronic Division, której grupa do rozpoznawania wzorów równieŋ się póžniej zģoŋyģa], a kiedy wszyscy postanowili nie iķæ, przenieķli ich do dziaģu komunikacji i powiedzieli aby zamknąæ nasze projekty rozpoznawania wzorców. Laveen ostatecznie przeszedģ na University of Maryland. W póžniejszych latach to, co byģo Philco, zostaģo sprzedane Loralowi, a większoķæ z nich zostaģa póžniej sprzedana Lockheedowi Martinowi.
Podejķcie do problemów AI związanych z sieciami neuronowymi i technikami statystycznymi nazwano "niesymbolicznymi" w celu zestawienia ich z pracą "przetwarzania symboli" przez osoby zainteresowane udowodnieniem twierdzeņ, graniem w gry i rozwiązywaniem problemów . Te niesymboliczne podejķcia znalazģy zastosowanie gģównie w rozpoznawaniu wzorców, przetwarzaniu mowy i widzeniekomputerowe. Warsztaty i konferencje poķwięcone szczególnie tym tematom zaczęģy się w latach 60. XX wieku. Podgrupa IEEE Computer Society (podkomitet ds. Rozpoznawania wzorców w komitecie ds. Pozyskiwania i przeksztaģcania danych) zorganizowaģa pierwsze "rozpoznawanie wzorców"
Warsztat ", który odbyģ się w Puerto Rico w paždzierniku 1966 r. Drugi (w którym uczestniczyģem) odbyģ się w Delft w Holandii w sierpniu 1968 r. W 1966 r. Ta podgrupa staģa się IEEE Computer Society Pattern Analysis and Machine Intelligence (PAMI) ) Komitet techniczny, który nadal organizowaģ konferencje i warsztaty. Tymczasem pod koniec lat 50. i na początku lat 60. ludzie przetwarzający symbole wykonywali swoją pracę gģównie na MIT, na Carnegie Mellon University, IBM i na Uniwersytecie Stanforda. przejdž dalej do opisu niektórych z tego, co zrobili.