Progi Zwalniające
Od najwczeķniejszych dni sztucznej inteligencji istnieli pesymiķci. Alan Turing przewidziaģ (i zająģ się) niektórymi z nich w swoim artykule z 1950 r. Tu opiszey niektóre z kontrowersji wokóģ AI - w tym niektóre nieprzewidziane przez Turinga. Opiszę takŋe kilka powaŋnych trudnoķci technicznych napotykanych w tej dziedzinie. Mniej więcej w poģowie lat osiemdziesiątych trudnoķci te sprawiģy, ŋe niektórzy byli raczej lekcewaŋący co do postępy do tego czasu i pesymistyczni co do moŋliwoķci dalszego postępu. Na przykģad zastanawiając się nad potrzebą specjalnego wydania czasopisma poķwięconego Deadalus AI w 1988 r. filozof Hilary Putnam napisaģ: "O co teraz tyle zamieszania? Dlaczego caģy problem z Deadalus? Dlaczego nie czekamy, aŋ AI coķ osiągnie, a potem pojawią się jakieķ problemy?" .Ataki i wyrazy rozczarowania spoza pola pomogģy wytrąciæ to, co niektórzy nazywają "zimą AI".
Opinie róŋnych obserwatorów
Umysģ nie jest maszyną
We wprowadzeniu do swojego zredagowanego tomu esejów zatytuģowanego "Umysģy i maszyny" filozof Alan Ross Anderson wymienia następujące dwie skrajne opinie dotyczące tego, czy umysģ jest maszyną, czy nie:
(1) Moŋna powiedzieæ, ŋe istoty ludzkie są jedynie bardzo skomplikowanymi częķciami mechanizmu zegarowego i ŋe nasze "umysģy" są po prostu konsekwencją faktu, ŋe mechanizm zegarowy jest bardzo skomplikowany, lub
(2) moglibyķmy powiedzieæ, ŋe kaŋda maszyna jest jedynie wytworem ludzkiej pomysģowoķci (w zasadzie tylko ģopatą) i ŋe chociaŋ mamy umysģy, nie moŋemy przekazaæ tej naszej szczególnej cechy czegokolwiek poza naszym potomstwem: ŋadna maszyna nie moŋe nabyæ tę wyjątkową ludzką cechę.
Większoķæ badaczy AI prawdopodobnie zgadza się z pierwszą z tych dwóch wypowiedzi. Z pewnoķcią tak (choæ nie uŋyģbym sģowa "tylko"). Marvin Minsky postawiģ tę pozycję najsilniej, gdy rzekomo powiedziaģ: "Umysģ jest maszyną mięsną". Jednak niektórzy filozofowie trzymają się drugiego poglądu. Najbardziej znanym z nich jest prawdopodobnie brytyjski filozof John R. Lucas. W eseju zatytuģowanym "Umysģy, maszyny i Godel". Lucas oparģ swój argument na dowodzie Kurta Godela, ŋe istnieją pewne prawdziwe stwierdzenia, których nie moŋna udowodniæ ŋadnym systemem mechanicznym, który jest zarówno spójny, jak i zdolny (przynajmniej) do wykonywania arytmetyki. Lucas zakģada, ŋe ludzie (a przynajmniej niektórzy ludzie) mogą "zobaczyæ" te stwierdzenia jako prawdziwe, nawet jeķli maszyny nie mogą ich udowodniæ. Kilka osób wskazaģo wady argumentu Lucasa, a Lucas twierdzi, ŋe odpowiedziaģ na przynajmniej niektóre z nich w swojej ksiąŋce "The Freedom of the Will". W artykule z 1990 r. odczytanym na konferencji w Turing w Brighton Lucas zdaje się osģabiaæ nieco swoją argumentację.
Zdarza mi się wierzyæ, ŋe ludzie podlegają wszystkim ograniczeniom Godelian dotyczącym maszyn, ale to dlatego, ŋe wierzę, ŋe ludzie są maszynami. Lucas nadal kģóci się ze swoim argumentem, poniewaŋ (sądzę) chciaģby wierzyæ, ŋe tak nie jest. W kaŋdym razie argument jest doķæ sterylny, poniewaŋ tak naprawdę nie ogranicza tego, co AI moŋe potencjalnie zrobiæ w praktyce. Nawet Lucas przyznaģ w swoim oryginalnym artykule, ŋe moŋemy byæ w stanie "konstruowaæ bardzo, bardzo skomplikowane ukģady, powiedzmy, zaworów i przekažników", "który byģby" zdolny do "robienia rzeczy, które uznaliķmy za inteligentne, a nie tylko bģędów lub losowych ujęæ , ale których nie zaprogramowaliķmy. Ale wtedy przestanie byæ maszyną. " (Wydaje się, ŋe tutaj próbuje wygraæ swój argument, posģugując się "maszyną"). Inŋynier Mortimer Taube równieŋ uwaŋaģ, ŋe ludzie nie są maszynami. W swojej ksiąŋce "Computers and Common Sense: The Mit of Thinking Macines" z 1961 r. [rzeciwstawiģ się wysiģkom zmierzającym do przekonania komputerów, przetģumaczenia języków ludzkich i nauki. Wiele rzeczy, które powiedziaģ, ŋe komputery nie byģyby w stanie zrobiæ, zostaģy juŋ zrobione.
Umysģ nie jest komputerem
A. Potrzebna jest nowa fizyka
Kilka osób wysunęģo argument, ŋe chociaŋ ludzie mogą byæ maszynami, inteligencja nie moŋe byæ wykazywana przez komputery - a przynajmniej nie przez wspóģczesne komputery wykonane z tranzystorów i innych zwykģych komponentów elektromagnetycznych i dziaģające w taki sposób. Brytyjskiego fizyka Sir Roger Penrose′a przekonują Godeliaņskie argumenty Lucasa dotyczące ograniczeņ komputerów. (Penrose sģynie z pracy w fizyce kwantowej, teorii względnoķci, struktury wszechķwiata i "przechyleņ Penrose′a"). On, podobnie jak Lucas, uwaŋa, ŋe komputery nigdy nie byģyby ķwiadome, ani nie miaģyby peģnego zakresu ludzkiej inteligencji. Ale Penrose wyobraŋa sobie, ŋe ograniczenia te dotyczą tylko maszyn opartych na obecnie znanych prawach fizyki. Aby uciec przed ograniczeniami Godela (jak uwaŋa Penrose, ŋe robią to mózgi), twierdzi, ŋe naleŋy się odwoģaæ do nowego rodzaju fizyki - takiej, który obejmuje coķ, co nazywa "poprawną grawitacją kwantową". Niestety, prawidģowa grawitacja kwantowa, cokolwiek to jest, pozostaje do odkrycia (lub raczej, wynalezienia). Penrose przedstawia te idee (wraz z bardzo angaŋującym materiaģem na temat fizyka) w dwóch ksiąŋkach: "Nowy umysģ cesarza" i "Shadows of the Mind: A Poszukiwanie brakującej nauki o ķwiadomoķci". Ja, podobnie jak wielu innych, jestem sceptyczny, ŋe nowa fizyka jest potrzebna do zrealizowania wszystkich ambicji sztucznej inteligencji . (Ale oczywiķcie jeszcze nie zdawaliķmy sobie z tego sprawy.) Penrose próbuje odpowiedzieæ na niektóre krytyki swoich poglądów w swoim artykule "Beyond the Doubting of a Shadow: A Reply to Comments on Shadows of the Mind".
B. Potrzebna jest celowoķæ
Argumentuje to amerykaņski filozof John Searle ,ŋe procesy obliczeniowe, jakie znamy, nie mają czegoķ, co ludzie mają - coķ, co on i niektórzy inni filozofowie nazywają "celowoķcią". Celowoķæ ma związek z przypisywaniem "znaczenia" przedmiotom i ich wģaķciwoķciom. Definicja Searle jest następująca: "Intencjonalnoķæ to cecha niektórych stanów mentalnych, poprzez które są one skierowane na lub o przedmiotach i stanach rzeczy na ķwiecie". Na przykģad wedģug Searle "przekonania, pragnienia i intencje są stanami umyķlnymi". Twierdziģby więc, ŋe jest moŋliwe do przedstawienia w komputerze wyraŋenie "John jest wysoki", powiedzmy jako logiczne wyraŋenie, takie jak "G33 (K077)", komputer nie moŋe wiedzieæ, ŋe G33 odnosi się do wģasnoķci "w ķwiecie" "wysokoķci" ani teŋ, ŋe K077 odnosi się do faktycznego Jana "na ķwiecie". Krótko mówiąc, procesom obliczeniowym brakuje "okoģo"; nie wiedzą, o co chodzi w ich symbolach. Przeciwnie, kiedy ludzie uŋywają sģów, wiedzą, o co chodzi w tych sģowach. Searle jest znany wķród badaczy i filozofów AI dzięki eksperymentowi myķlowemu, który zaproponowaģ na temat "zrozumienia". Nazwano go eksperymentem "Pokój chiņski". Searle pisze eksperyment myķlowy pisząc : Zaģóŋmy, ŋe jestem zamknięty w pokoju i otrzymaģem duŋą porcję chiņskiego pisma. Przypuķæmy ponadto (jak to jest w istocie), ŋe nie znam chiņskiego, ani w mowie, ani w piķmie, i ŋe nawet nie jestem przekonany, ŋe mógģbym rozpoznaæ chiņskie pismo jako chiņskie pismo inne niŋ, powiedzmy, japoņskie pismo lub bezsensowne kģótnie. Aby uczyniæ swój eksperyment istotnym dla sztucznej inteligencji w zakresie "rozumienia historii", Searle wyobraŋa sobie, ŋe jego pokój zawiera dwie partie chiņskich symboli, które nieznane Searle stanowią historię i ogólne informacje o takich historiach. Pokój zawiera równieŋ zasady napisane w języku angielskim, dotyczące manipulowania zestawami chiņskich znaków i generowania chiņskich znaków w wyniku takich manipulacji. Do takiego pokoju przybywa trzecia partia chiņskich symboli. Tak jak Searle to ująģ, ma w pokoju zasady (napisane po angielsku), które instruują mnie, jak oddawaæ niektóre chiņskie symbole z pewnymi rodzajami ksztaģtów w odpowiedzi na pewne rodzaje ksztaģtów podane mi w trzeciej partii. Nieznani mi ludzie, którzy dają mi wszystkie te symbole, nazywają [pierwsze dwie partie historią i jej podstawowymi informacjami], a trzecią partię nazywają "pytaniami". Co więcej, nazywają symbole, które im oddaję w odpowiedzi na trzecią partię, "odpowiedzi na pytania" oraz zestaw reguģ w języku angielskim, które mi dali, nazywają "program". Zaģóŋmy, ŋe po podczas gdy ja tak dobrze postępuję zgodnie z instrukcjami manipulowania chiņskimi symbolami, a programiķci potrafią tak dobrze pisaæ programy, ŋe z zewnętrznego punktu widzenia - z punktu widzenia osoby spoza pokoju, w którym jestem zamknięty -moje odpowiedzi na pytania są absolutnie nie do odróŋnienia od odpowiedzi rodzimych uŋytkowników języka chiņskiego, nikt, kto patrzy na moje odpowiedzi, nie moŋe powiedzieæ, ŋe nie mówię po chiņsku.
Pytanie Searle w istocie brzmi: "Czy moŋna powiedzieæ, ŋe pokój (zawierający Searle, zasady i serie chiņskich symboli)" "rozumie" chiņski? Searle twierdzi, ŋe odpowiedž brzmi "nie", poniewaŋ wszystko, co się dzieje, to "formalna manipulacja symbolami" bez zrozumienia, co oznaczają symbole. Innymi sģowy:
"Poniewaŋ formalne manipulacje symbolami same w sobie nie mają jakakolwiek celowoķæ; są zupeģnie bez znaczenia; nie są nawet manipulacjami symbolami, poniewaŋ symbole niczego nie symbolizują. W ŋargonie językowym mają tylko skģadnię, ale nie semantykę. Taka intencjonalnoķæ, jaką wydają się mieæ komputery, leŋy wyģącznie w gģowach tych, którzy je programują i tych, którzy ich uŋywają, tych, którzy wysyģają dane wejķciowe i tych, którzy interpretują dane wyjķciowe."
Przyznając, ŋe chiņski pokój "symuluje" zrozumienie, rozróŋnia symulacje od "prawdziwej". Napisaģ:
"Nikt nie przypuszcza, ŋe symulacje komputerowe alarmów spowodują spalenie dzielnicy lub ŋe komputerowa symulacja burzy mózgów nas opuķci. Dlaczego, u licha, ktoķ miaģby przypuszczaæ, ŋe komputerowa symulacja zrozumienia faktycznie coķ rozumie? …Do symulacji wszystko czego potrzebujesz to odpowiednie wejķcie i wyjķcie oraz program w ķrodku, który przeksztaģca to pierwsze w drugie. To wszystko, co komputer ma do robieniai. Pomylenie symulacji z powielaniem jest tym samym bģędem, niezaleŋnie od tego, czy jest to ból, miģoķæ, poznanie, ogieņ czy burze."
Searle's Chinese Room przypomina mi eksperyment Herba Simona w symulowaniu wykonania programu Logic Theorist (LT). LT zaczęģo się od ręcznej symulacji, wykorzystując dzieci Simona jako elementy komputerowe, jednoczeķnie pisząc i trzymając karty notatek jako rejestry zawierające zmienne stanu programu. Przypuszczalnie dzieci nie wiedziaģy nic o logice zdaņ, ale caģy zbiór, Simon, dzieci i kartki z notatkami, okazaģy się twierdzeniem. Najwyražniej "symulowanie" dowodu twierdzenia jest w zasadzie takie samo jak dowodzenie twierdzenia - tak jak symulowanie dodawania jest tym samym co dodawanie. Czy to moŋliwe, ŋe symulowanie zrozumienia jest tak samo jak prawdziwe zrozumienie? Istnieje kilka moŋliwych odpowiedzi na argumenty Searle i nie brakuje odpowiedzi! W swoim artykule Searle przewiduje wiele potencjalnych odpowiedzi, a dwadzieķcia osiem faktycznych odpowiedzi zostaģo opublikowanych wraz z oryginalną pracą Searle. Oto, co myķlę: wyobražmy sobie, ŋe moŋemy zajrzeæ do mózgu Searle′a, gdy jest on w stanie zrozumieæ pytanie zadane mu po angielsku. Są przypuszczalnie tryliony synaps zaangaŋowanych w pierķcienie i hamujących miliardy neuronów w skoordynowanym wysiģku, aby zrozumieæ sens pytania oraz skomponowaæ i udzieliæ odpowiedzi. Nie twierdzilibyķmy, ŋe jakakolwiek pojedyncza synapsa ani poģączone przez nią neurony rozumieją angielski. Proces "zrozumienia" nie jest pojęciem mającym znaczenie na poziomie szczegóģowoķci odpowiednim do analizy dziaģania neuronów. Analogicznie proces dowodzenia twierdzenia przez komputer (lub przez dzieci Simona) nie jest pojęciem znaczącym na poziomie pojedynczych tranzystorów (lub dzieci posiadających karty do notatek). Wyjaķniając zjawiska, mózgu lub komputerów (lub czegokolwiek innego), uŋywamy pojęæ dopasowanych do poziomu wyjaķnienia. Pojęcie "zrozumienia" jest pojęciem, które przydaģoby się zastosowaæ do dziaģaņ mentalnych oglądanych na poziomie "caģej osoby", a nie na poziomie komórek nerwowych. Podobnie, moim zdaniem, uŋyteczne byģoby stwierdzenie, ŋe zestawienie pokoju, Searle, zasad i chiņskich znaków rozumie chiņski. Ale co z sensem i celowoķcią? Jeķli piszemy G33 (K077) w pamięci komputera, czy to "coķ" znaczy? Zaleŋy to od tego, co jeszcze jest w pamięci komputera - szczególnie co jeszcze w pamięci jest powiązane z symbolami G33 i K077. Symbole i powiązania między nimi tworzą sieæ, a caģa sieæ zawiera znaczenia. Przypomnij sobie pytanie, na które M. Ross Quillian próbowaģ odpowiedzieæ w swojej rozprawie z 1966 r., A mianowicie: "Jakiego rodzaju format reprezentacji moŋe pozwoliæ na przechowywane znaczenie sģów , aby moŋliwe byģo ludzkie uŋycie tych znaczeņ? ".
Wedģug Quillian znaczenie terminu jest reprezentowane przez jego miejsce w sieci i sposób poģączenia z innymi warunkami. To ten sam pomysģ stosuje się w sģownikach, w których znaczenie sģowa jest podane przez odniesienie do związku tego sģowa z innymi sģowami. Znaczenie tych innych sģów jest z kolei nadawane przez ich relacje z innymi sģowami. Moŋemy więc myķleæ o sģowniku jako o duŋej sieci semantycznej sģów powiązanych z innymi sģowami. W niektórych przypadkach konieczne jest takŋe poģączenie symboli sieci z rzeczywistymi obiektami na ķwiecie za poķrednictwem urządzeņ sensorycznych i motorycznych komputera. Newell i Simon przewidzieli tę potrzebę w swoim artykule na temat hipotezy o fizycznym systemie symboli (PSSH). Hipoteza ta gģosi, ŋe fizyczny system symboli (taki jak komputer) ma niezbędne i wystarczające warunki dla inteligentnego zachowania. Newell i Simon napisali: "Fizyczny system symboli to maszyna, która z czasem wytwarza ewoluujący zbiór struktur symboli. Taki system istnieje w ķwiecie przedmiotów szerszych niŋ same symboliczne wyraŋenia."
Oto definicja Newella i Simona: "Wyraŋenie [zģoŋone z symboli] oznacza obiekt, jeķli biorąc pod uwagę wyraŋenie, system moŋe albo wpģywaæ na sam obiekt, albo zachowywaæ się w sposób zaleŋny od obiektu". Uwaŋam więc, ŋe Searle jest po prostu zdezorientowany kilkoma podstawowymi ideami w informatyce. Chociaŋ nie zostaģo jeszcze ustalone empirycznie, ŋe komputer (manipulujący symbolami i doģączany w razie potrzeby do jego ķrodowiska) moŋe byæ wykonany w taki sposób, aby wykazywaģ wszystkie aspekty inteligentnego zachowania, do których zdolni są ludzie, nie wierzę, ŋe eksperyment myķlowy Searle wątpiæ w moŋliwoķæ. Searle sam uwaŋa, ŋe niektóre systemy fizyczne mogą byæ inteligentne i rozumieæ róŋne rzeczy. Uwaŋa, ŋe ludzie są jednym z takich systemów. Napisaģ następująco:
"Czy maszyna moŋe myķleæ?"
Odpowiedž brzmi: tak. Jesteķmy wģaķnie takimi maszynami.
"Tak, ale czy artefakt, sztuczna maszyna mogģa myķleæ?"
Zakģadając, ŋe moŋliwe jest sztuczne wyprodukowanie maszyny z ukģadem nerwowym, neurony z aksonami i dendrytami i caģą reszt z tego, tak jak nasza mózg. ponownie wydaje się, ŋe odpowiedž na to pytanie brzmi oczywiķcie, tak.
Searle nie daje nam jednak pojęcia, co skģada się na neurony mózgu , to jest inne niŋ komputery, zģoŋone z tranzystorów, które nadają temu pierwszemu, ale nie drugiemu, celowoķæ. Twierdzi, ŋe aby maszyna mogģa myķleæ, ŋe musiaģaby mieæ "wewnętrzne moce przyczynowe" równowaŋne z mocami mózgu. Nie mówi tylko, czym mogą byæ te wewnętrzne siģy przyczynowe.
C. Silna i sģaba AI
W pracy Searle′a zdefiniowano definicje "silnej AI "i "sģabej AI", które są przydatne do rozróŋnienia dwóch rodzajów dziaģaņ AI. Silna sztuczna inteligencja wiąŋe się z twierdzeniem, ŋe odpowiednio zaprogramowany komputer moŋe byæ umysģem i moŋe myķleæ tak samo dobrze jak ludzie. Osiągnięcie silnej AI jest ostatecznym celem wielu badaczy sztucznej inteligencji. Artykuģ Searle próbuje pokazaæ, ŋe silna sztuczna inteligencja (przy uŋyciu komputerów) jest niemoŋliwa. Jednak praktykujący sģabą (lub ostroŋną) sztuczną inteligencję uŋywają programów jako narzędzia do badania umysģu poprzez formuģowanie i testowanie hipotez na jego temat. Sģaba sztuczna inteligencja wiąŋe się równieŋ z próbami tworzenia programów, które pomagają, a nie duplikaty ludzkich dziaģaņ umysģowych. Sģaba sztuczna inteligencja byģa juŋ (i nadal odnosi) sukcesy, podczas gdy poszukiwanie silnej sztucznej inteligencji będzie bez wątpienia trwaģo doķæ dģugo.
D. Potrzebne są "procesy globalne"
Hubert L. Dreyfus profesor filozofii na Uniwersytecie Kalifornijskim w Berkeley, rozpocząģ karierę nauczyciela filozofii na MIT. Najpierw spotkaģ się tam z przedsięwzięciem AI, a na początku lat 60. wraz z bratem Stuartem wziąģ udziaģ w rozmowie z autorem Herbem Simonem. Kilka rzeczy na temat sztucznej inteligencji i tego, co usģyszeli podczas rozmowy, potęgowaģo braci Dreyfus. Mniej więcej w tym czasie RAND Corporation w Santa Monica w Kalifornii pomyķlaģa, ŋe posiadanie na pokģadzie filozofa wraz z komputerowcami byģoby dobrym pomysģem. Stuart, specjalista od badaņ operacyjnych, który pracowaģ w RAND, poleciģ Huberta. Tak więc Hubert spędziģ lato 1961 r. w RAND jako konsultant badający badania nad sztuczną inteligencją. Krótko po lecie Hubert napisaģ artykuģ zatytuģowany "Alchemia i sztuczna inteligencja", w którym między innymi doszedģ do wniosku, ŋe ostateczne cele badaņ nad AI są równie nieosiągalne, jak cele alchemii. W swojej pracy Dreyfus oceniģ postęp AI w czterech obszarach, a mianowicie: granie w gry, rozwiązywanie problemów (w tym dowodzenie twierdzeņ), tģumaczenie języka i rozpoznawanie wzorców.Napisaģ:
"Ksztaģtuje się ogólny wzorzec: wczesny, dramatyczny sukces oparty na ģatwoķci wykonywania prostych zadaņ lub niskiej jakoķci pracy nad zģoŋonymi zadaniami, a następnie malejące zwroty, rozczarowanie, aw niektórych przypadkach pesymizm. Twierdziģ, ŋe typowym przypadkiem byģa maszyna do dowodzenia twierdzeņ geometrycznych Gelerntera: Nie ma bardziej uderzającego przykģadu "zadziwiającego" wczesnego sukcesu i równie zadziwiającego niepowodzenia w jego realizacji. "I odpowiadając na twierdzenie AI, ŋe poczyniono postępy, napisaģ . Zgodnie z tą definicją [postępu], pierwszy czģowiek, który wspiąģ się na drzewo, mógģ domagaæ się namacalnego postępu w walce na księŋyc ".
Wedģug Dreyfusa jednym z powodów tej stagnacji byģo to, ŋe badania nad sztuczną inteligencją opierają się na zaģoŋeniu, ŋe myķlenie moŋe byæ analizowane jako niezliczony zestaw prostych, okreķlonych operacji (takich jak zastosowanie reguģ do niezliczonego zestawu danych). Twierdziģ, ŋe "myķlenie obejmuje procesy globalne, których nie moŋna zrozumieæ w kategoriach sekwencji lub nawet równolegģego zestawu dyskretnych kroków." Te procesy globalne manifestują się na trzy sposoby. Pierwszy to "skrajna ķwiadomoķæ", mózg korzysta z dostępu do nieskoņczonych "otwartych informacji charakterystycznych dla codziennych doķwiadczeņ". Ķwiadomoķæ poboczna pozwala ludziom jednoczeķnie rozwaŋaæ szczegóģy i duŋy obraz. Kolejny globalny proces dziaģa w ludzkim myķleniu, kiedy odróŋniamy to, co istotne, od tego, co nieistotne. Trzeci to "kontekst globalny", który pozwala nam zmniejszyæ dwuznacznoķæ. Poģączenie tych umiejętnoķci pozwala na to, co nazywa "pogrupowanym grupowaniem" - co robi mózg, gdy rozpoznaje zģoŋone wzorce, takie jak na przykģad ludzkie twarze. Dreyfus twierdziģ, ŋe programy komputerowe nie są w stanie zastosowaæ tych globalnych procesów, które są niezbędne dla inteligentnego zachowania. Dreyfus stwierdziģ, ŋe mózg przetwarza informacje w zupeģnie inny sposób. Napisaģ, ŋe informacje w mózgu są "przetwarzane globalnie, tak jak analog rezystorowy [rodzaj komputera analogowego] rozwiązuje problem minimalnej ķcieŋki przez sieæ". Ponadto powiedziaģ, ŋe "ciaģo odgrywa kluczową rolę w moŋliwym inteligentnym zachowaniu. "Kilka innych osób podkreķliģo znaczenie "ucieleķnienia" dla postępu w sztucznej inteligencji, a wkrótce będę miaģ więcej do powiedzenia na ten temat przyszģoķci (jak sądzono na początku lat 60.), Dreyfus napisaģ, ŋe tylko eksperymenty mogą okreķliæ, w jakim stopniu nowsze i szybsze maszyny, lepsze języki programowania i sprytna heurystyka mogą nadal przesuwaæ granice. Niemniej jednak dramatyczne spowolnienie w obszarach, które mamy i ogólne niepowodzenie w wypeģnianiu wczeķniejszych prognoz sugeruje, ŋe granica moŋe byæ juŋ blisko. Nie naleŋy przyjmowaæ komentarzy Dreyfusa na temat sztucznej inteligencji, które sugerują, ŋe uwaŋaģ, iŋ sztuczna inteligencja na poziomie ludzkim jest niemoŋliwa - po prostu myķlaģ (i wciąŋ myķli) niemoŋliwe jest zastosowanie metod, które filozof John Haugeland nazwaģ "dobrą staroķwiecką sztuczną inteligencją" (GOFAI), a mianowicie taką, która wykorzystuje wyszukiwanie heurystyczne i dyskrecję e zbiory symbolicznie reprezentowanych faktów i zasad. Przyznaģ, ŋe w zasadzie "moglibyķmy symulowaæ inteligentne zachowanie, gdybyķmy mogli zbudowaæ lub symulowaæ urządzenie, które funkcjonowaģo dokģadnie tak, jak ludzki mózg. "Ale pomyķlaģ, ŋe takiej symulacji nie da się zrealizowaæ w praktyce." Nie znamy równaņ opisujących fizyczne procesy w mózgu, a nawet gdybyķmy to zrobili, on równania opisujące najprostszą reakcję zajęģyby zbyt duŋo czasu. "Podsumowanie jego pracy zakoņczyģo się" Znaczący rozwój sztucznej inteligencji musi czekaæ na zupeģnie inny rodzaj komputera. Jedynym istniejącym prototypem jest maģo zrozumiaģy ludzki mózg."Gģówne idee jego artykuģu RAND zostaģy przedstawione i rozwinięte w kilku ksiąŋkach i artykuģach Dreyfusa. Ksiąŋka Pameli McCorduck, Machines Who Think, ma doskonaģy rozdziaģ o Dreyfusie, wyszczególniając jego argumenty i doķæ kontrowersyjne interakcje między nim a naukowcami AI. Poniewaŋ tak dobrze omawia tę kwestię, skoncentruję się na jego pomysģach na temat potrzeby "ucieleķnienia", jak opisano w kilku jego ostatnich artykuģach
E. Potrzebne jest "bycie tam"
Myķlę, ŋe gģówną kwestią Dreyfusa jest to, ŋe inteligencja u ludzi wywodzi się z ich "bycia w ķwiecie", a nie dlatego, ŋe kierują nimi reguģy. Stosowanie reguģ w programach AI (tak jak u ludzi) moŋe pozwoliæ na zachowanie wģaķciwe, ale nie zachowanie eksperckie. Oto kilka fragmentów adresu, który Dreyfus podaģ w 2005 roku:
"…w naszych formalnych instrukcjach zaczynamy od zasad. Zasady, wydaje się jednak, ŋe ustępują miejsca bardziej elastycznym reakcjom, gdy się stajemy wykwalifikowani … Faktyczne zjawisko sugeruje, ŋe aby zostaæ ekspertami, musimy przejķæ z oderwania od przestrzegania zasad na więcej zaangaŋowany i specyficzny dla danej sytuacji sposób radzenia sobie. …Ogólnie rzecz biorąc, zamiast polegaæ na zasadach i standardach do podjęcia decyzji lub w celu uzasadnienia swoich dziaģaņ ekspert natychmiast reaguje na aktualną konkretną sytuację…"
.
"Systemy eksperckie" oparte na zasadach, tak zwanych inŋynierów wiedzy pozyskiwanych od ekspertów, byģy w najlepszym wypadku kompetentne. Wydaje się, ŋe zamiast uŋywaæ reguģ, których juŋ nie pamiętali, jak przypuszczali badacze AI, eksperci zostali zmuszeni do zapamiętania reguģ, których juŋ nie uŋywali. Rzeczywiķcie, o ile ktokolwiek mógģ powiedzieæ, eksperci w ogóle nie przestrzegali ŋadnych zasad. Wedģug Dreyfusa przejķcie od zwyczajnie kompetentnego zachowania do zachowania eksperckiego wymaga "bycia w ķwiecie" poprzez posiadanie ciaģa osadzonego w ķwiecie. Ucieleķnieni agenci, tacy jak ludzie, "mogą mieszkaæ na ķwiecie w taki sposób, aby uniknąæ nieskoņczonego zadania sformalizowania wszystkiego" (jak bezskutecznie próbują to robiæ programy AI). Pogląd Dreyfusa na tę potrzebę ucieleķnienia opiera się na filii szkoģy filozoficznej zwanej "fenomenologią". Dreyfus napisaģ, ŋe fenomenologia egzystencjalna Martina Heideggera, która podkreķla "nasze praktyczne zaangaŋowanie w ludzi i rzeczy jako nasz podstawowy sposób bycia", jest podstawą jego krytyki GOFAI. Twierdzi, ŋe aby AI mogģa odnieķæ sukces, potrzebowaģaby modelu naszego szczególnego sposobu bycia osadzonym i wcielonym, tak ŋe to, czego doķwiadczamy, jest dla nas znaczące w szczególny sposób, w jaki jest. Oznacza to, ŋe musielibyķmy uwzględniæ w naszym programie model ciaģa bardzo podobnego do naszego z naszymi potrzebami, pragnieniami, przyjemnoķciami, bólami, sposobami poruszania się, pochodzeniem kulturowym itp. Inni opowiadający się za ucieleķnieniem wskazują, ŋe niektóre "obliczenia" potrzebne inteligentnemu agentowi moŋna by osiągnąæ dzięki dynamicznym interakcjom między częķciami jego ciaģa a otoczeniem. Na przykģad Rolf Pfeifer, Max Lungarella i Fumiya Iida napisali: "Wcielona perspektywa, poniewaŋ dzieli kontrolę i przetwarzanie na wszystkie aspekty czynnika (jego centralny ukģad nerwowy, wģaķciwoķci materiaģowe ukģadu mięķniowo-szkieletowego, morfologia czujnika, oraz interakcja ze ķrodowiskiem), stanowi alternatywną drogę do zmierzenia się z wyzwaniami, przed którymi stoi robotyka. Zadania kontrolera w klasycznym podejķciu są teraz częķciowo przejmowane przez morfologię i materiaģy w procesie samoorganizacji…" Ale nawet gdyby ciaģo byģo potrzebne, jego forma wydaje się zaleŋeæ od tego do czego powiązany system AI jest uŋywany. Korpusem HAL 9000 byģ caģy sterowany przez niego statek kosmiczny. Wstrząsający robot miaģ ciaģo, które najwyražniej byģo odpowiednie do jego potrzeb. Gdyby kiedykolwiek powstaģ "konwersacyjny Google", który mógģby prowadziæ dialog z uŋytkownikami na temat zawartoķci wszystkich stron internetowych, jego "ciaģem" byģby caģy Internet i procedury potrzebne do uzyskania do niego dostępu.
Róŋnice między mózgami a komputerami
Oprócz Dreyfusa kilku krytyków sztucznej inteligencji zwróciģo uwagę, ŋe "mózg nie jest komputerem", a zatem ludzie, którzy próbują zrobiæ z komputerem to, co potrafi mózg, muszą się koniecznie zawieķæ. Krytycy ci często podkreķlają takie rozróŋnienia, jak następujący:
• Komputery mają prawdopodobnie setki jednostek przetwarzających, podczas gdy mózgi mają tryliony.
• Komputery wykonują miliardy operacji na sekundę, podczas gdy mózgi potrzebują tylko tysięcy.
• Komputer ulega awariom, a mózgi są odporne na awarie.
• Komputery uŋywają sygnaģów binarnych, podczas gdy mózgi dziaģają z analogowymi.
• Komputery robią tylko to, co nakazują im programiķci, a mózgi są kreatywne.
• Komputery wykonują szeregowe operacje, podczas gdy mózgi są masowo równolegle.
• Komputery muszą byæ logiczne, podczas gdy mózg moŋe byæ "intuicyjny."
• Komputery są zaprogramowane, a mózg się uczy.
Oprócz tego, ŋe wiele z tych rozróŋnieņ nie jest juŋ aktualnych, porównania zaleŋą od tego, co rozumie się przez "mózg", a co przez "komputer". Jeķli nasze rozumienie mózgu dotyczy neuronów skģadowych, ich gazillionów aksonów, dendrytów i poģączeņ synaptycznych, i jeķli rozumiemy komputer w kategoriach szeregowych, operacja "styl von Neumanna" -czytanie, przetwarzanie i pisanie bitów - wszystko to odbywa się za pomocą obwodów tranzystorowych, no cóŋ, oczywiķcie mózg nie jest tego rodzaju komputerem. Nie rozumiemy jednak "obliczeņ" przez odniesienie tylko do niskiego poziomu, von Neumann - opis stylu. Moŋemy to zrozumieæ na jednym z wielu poziomów opisu. Na przykģad obliczenia mogą byæ rozumiane jako bardzo duŋa liczba jednoczeķnie aktywnych "žródeģ wiedzy " asynchronicznie odczytujących, przeksztaģcających i zapisujących zģoŋone wyraŋenia symboliczne na " Tablicy" lub jako zbiór demonów przetwarzających symbole i sieci neuronowych uģoŋonych w Sieæ w stylu pandemonium. Byæ moŋe nasze stopniowo rosnące zrozumienie dziaģania mózgu doprowadzi nawet do innych uŋytecznych modeli obliczeniowych. Pomysģy na temat tego, czym moŋe byæ "obliczanie" stale się rozwijają, więc ci, którzy twierdzą, ŋe mózg nie jest komputerem, będą potrzebowaæ ķciķlej mówiąc o tym, jakim komputerem nie jest mózg. (W koņcu, jeķli niektórzy ludzie, na przykģad Lucas, mogą ograniczaæ to, czym moŋe byæ maszyna, wydaje się sprawiedliwe, ŋe inni mogą rozszerzyæ definicję tego, co komputer moŋe byæ.)
Ale czy powinniķmy?
Oprócz krytyki sztucznej inteligencji opartej na tym, co ludzie twierdzą, ŋe nie moŋe tego zrobiæ, istnieją równieŋ krytyki oparte na tym, co ludzie twierdzą, ŋe nie powinna tego robiæ. Niektóre osoby "nie powinny" wspominaæ o niewģaķciwoķci maszyn próbujących wykonywaæ zadania, które są z natury skoncentrowane na czģowieku, takich jak nauczanie, doradztwo i wydawanie opinii sądowych. Inni, jak wspomniani wczeķniej Computer Professionals for Social Responsibility, nie chcą widzieæ technologii sztucznej inteligencji (ani ŋadnej innej technologii w tym zakresie) wykorzystywanej w dziaģaniach wojennych, w inwigilacji lub do zadaņ wymagających ludzkiej oceny opartej na doķwiadczeniu. Ponadto są tacy, którzy, podobnie jak luddyķci z XIX wieku w Wielkiej Brytanii, martwią się o maszyny zastępujące ludzi, a tym samym powodujące bezrobocie i dyslokacja gospodarcza. Wreszcie, są tacy, którzy obawiają się, ŋe sztuczna inteligencja i inne technologie komputerowe odczģowieczą ludzi, zmniejszą potrzebę kontaktów międzyludzkich i zmienią to, co znaczy byæ czģowiekiem. Joseph Weizenbaum, czģowiek, który napisaģ program ELIZA, pisaģ i wykģadaģ na temat niebezpieczeņstw związanych z powierzeniem komputerom obowiązków, które jego zdaniem powinny zostaæ pozostawione ludziom. Niektórzy twierdzą, ŋe powodem jego niepokoju byģ fakt, ŋe byģ zaskoczony i zszokowany faktem, ŋe niektórzy ludzie mylili rozmowy z ELIZĄ z rozmowami z prawdziwą osobą. W swojej ksiąŋce "Computer Power and Human Reason: From Judgement to Calculation" Weizenbaum argumentowaģ, ŋe "istnieje róŋnica między czģowiekiem a maszyną, i istnieją pewne zadania, których nie naleŋy wykonywaæ, niezaleŋnie od tego, czy komputery mogą byæ W swojej ksiąŋce Weizenbaum podkreķliģ znaczenie ķrodowiska kulturowego, w którym czģowiek dorasta, ŋyje i pracuje. Ŋadna maszyna nie doķwiadcza (ani nie mogģaby doķwiadczyæ) pochodzenia ludzkiego, dlatego ŋadna maszyna nie powinna byæ dozwolona podejmowaæ takie decyzje lub udzielaæ porad, które wymagają między innymi wspóģczucia i mądroķci wywoģanej przez takie tģo. Podkreķla ten punkt, mówiąc, ŋe brak doķwiadczenia w tych "domenach myķli i dziaģania" dotyczyģby równieŋ "sposobu, w jaki ludzie odnoszą się do siebie nawzajem, a takŋe maszyn i ich relacji z czģowiekiem". Tak więc, przypuszczam, ŋe pomyķlaģby, ŋe podobnie jak niewģaķciwe byģoby, aby maszyna podejmowaģa decyzje sądowe, tak samo byģoby niewģaķciwe, gdyby osoba wychowana w Ameryce podejmowaģa decyzje sądowe w Japonii. Co więcej, wyķmiewa pomysģ, ŋe maszyna moŋe uzyskaæ niezbędne tģo, nadając jej ludzkie ciaģo i aparat sensoryczny. Napisaģ, ŋe "najgģębsza i najwspanialsza fantazja, która motywuje pracę nad sztuczną inteligencją ... …to nic innego jak zbudowanie maszyny na wzór czģowieka, robota, który ma mieæ dzieciņstwo, uczyæ się języka jak dziecko. , aby zdobyæ wiedzę o ķwiecie, wykrywając ķwiat za pomocą wģasnych organów, a ostatecznie kontemplowaæ caģą domenę ludzkiej myķli ". Weizenbaum wraz z rodziną uciekģ z nazistowskich Niemiec w 1936 roku. Doķwiadczenie to nie mogģo wyostrzyæ jego silnego poczucia odpowiedzialnoķci spoģecznej. Napisaģ na przykģad, ŋe.
"Samo pytanie: "Co sędzia (lub psychiatra) wie, ŋe nie moŋemy powiedzieæ komputerowi?" jest potworną nieprzyzwoitoķcią. To, ŋe w ogóle musi zostaæ wydrukowane, nawet w celu ujawnienia swojej chorobowoķci, jest oznaką szaleņstwa naszych czasów.
…
[Odpowiednie kwestie] nie mogą zostaæ rozwiązane poprzez zadawanie pytaņ zaczynających się od "moŋe". Granice stosowalnoķci komputerów są ostatecznie moŋliwe do ustalenia tylko w kategoriach. Najbardziej elementarnym wglądem jest to, ŋe skoro nie mamy obecnie sposobów na uczynienie komputerów mądrzejszymi, nie powinniķmy teraz powierzaæ komputerom zadaņ wymagających mądroķci."
Mimo ŋe Weizenbaum ma trochę wątpliwoķci co do pytania "moŋe", uwaŋam, ŋe naprawdę wierzyģ, ŋe maszyny "nie mogą" tak jak "nie powinny". Bo jeķli maszyny naprawdę potrafią osądzaæ z caģym "wspóģczuciem i mądroķcią", z jaką ludzie mogą, dlaczego nie mieliby tego robiæ? Oprócz obaw związanych z wykorzystaniem jakiejkolwiek technologii do celów aspoģecznych (takich jak wojna), prawdziwym zagroŋeniem, jak sądzę, jest przedwczesne uŋycie maszyn: myķlenie, ŋe są w stanie wykonaæ zadanie, zanim naprawdę będą w stanie to zrobiæ. Inną osobą, która cofnęģa się przed perspektywą "przejęcia" maszyn, jest lekarz, biolog i eseista Lewis Thomas. W jednej z jego sģynnych kolumn "Notes of a Biology-Watcher" w The New England Journal of Medicine napisaģ
Najgģębiej przygnębiające ze wszystkich pomysģów na przyszģoķæ gatunku ludzkegoi jest pojęcie sztucznej inteligencji. Ambicja ŋe ludzie ostatecznie zakoņczą swój sukces jako ewolucyjny nadzorca produkujący komputery o takiej zģoŋonoķci i pomysģowoķci, by byæ mądrzejszym niŋ są i ŋe te urządzenia przejmą i poprowadzą miejsce ludzkiej poprawy, a moŋe póžniej, dla ulepszenia maszyny, uderza gģęboko w bģąd, moŋe nawet zģo.
&hellip
O tym mówią ludzie o sztucznej inteligencji: mechaniczny mózg ze zdolnoķcią do spojrzenia w przeszģoķæ i dokonania dokģadnych prognoz dotyczących przyszģoķci, a następnie rozģoŋenia okropnych planów zmiany tej przyszģoķci w dowolny sposób i większoķæ przeraŋająca wszystkich, zdolne do poczucia, ŋe coķ robią.
…
Moim zdaniem jest to absolutnie ohydna perspektywa, a gdybym myķlaģ, ŋe to naprawdę coķ nieuchronnie czeka przed nami, spędziģbym caģy dzieņ na proteķcie. "
Chociaŋ byģo wielu innych autorów, którzy ostrzegali przed niebezpieczeņstwem niewģaķciwego korzystania z komputerów w ogóle, a zwģaszcza z inteligentnych maszyn, wspomnę jeszcze o jednym, samozwaņczym "neo-luddycie". Theodore Roszak jest wybitnym pisarzem i myķlicielem spoģecznym - w swojej ksiąŋce The Cult of Information , stwierdziģ, ŋe rosnący kult, zauroczony "informacją" i "przetwarzaniem informacji", ma wyniszczające skutki kulturowe - "zwģaszcza jeķli chodzi o nauczanie mģodzieŋy". Roszak napisaģ, ŋe jest "sprzymierzeņcem wszystkich powaŋnych studentów i uŋytkowników technologii informatycznych, którzy mają racjonalnie zrównowaŋony pogląd na to, co komputery mogą, a czego nie powinne", ale twierdzi, ŋe "tworzy tajemnicę informacji [uniemoŋliwiģ] podstawowe intelektualne rozróŋnienie między danymi, wiedzą, osądem, wyobražnią, wglądem i mądroķcią ". Twierdziģ, ŋe istnieje "istotna róŋnica" między przetwarzaniem informacji a myķleniem. Poniewaŋ zdolnoķæ [komputera] do przechowywania danych w pewnym stopniu odpowiada temu, co nazywamy pamięcią u ludzi, oraz poniewaŋ zdolnoķæ do przestrzegania logicznych procedur w pewnym stopniu odpowiada temu, co nazywamy rozumowaniem u ludzi, wielu czģonków kultu [informacji] doszedģem do wniosku, ŋe niektóre komputery dziaģają nieco odpowiadając temu, co nazywamy myķleniem. Roszak konkluduje jednak, ŋe komputery nie mogą tak naprawdę "myķleæ". Niebezpieczeņstwo polega na tym, ŋe ci, którzy zostaną przekonani (lub oszukani w przekonaniue), ŋe mogą niewģaķciwie wykorzystywaæ komputery w zadaniach wymagających myķlenia, a nie tylko "przetwarzania danych". Uwaŋam, ŋe Roszak ma tutaj uzasadnioną troskę - nie jestem jeszcze w stanie wykonaæ wszystkich zadaņ, do których moglibyķmy się staraæ. Ale Roszak równieŋ napisaģ. Nie ma moŋliwoķci, aby komputery kiedykolwiek dorównaģy lub zastąpiģy umysģ, z wyjątkiem tych ograniczonych funkcjonalnych aplikacji, które wymagają przetwarzania danych i myķlenia proceduralnego. Zasadniczo wyklucza się taką moŋliwoķæ, poniewaŋ zaģoŋenia metafizyczne leŋące u podstaw wysiģku są faģszywe. Tutaj się nie zgadzam. Nie znam ŋadnych "metafizycznych zaģoŋeņ" sztucznej inteligencji poza tym, ŋe mózg jest rodzajem maszyny i dlatego powinniķmy byæ w stanie to zrozumieæ i zbudowaæ coķ, co dziaģa bardzo podobnie. Ponadto nie znam wiarygodnych dowodów na to, ŋe to metafizyczne zaģoŋenie jest faģszywe. Chociaŋ nie uwaŋa, ŋe komputery mogą staæ się umysģami, martwi się dodatkowym niebezpieczeņstwem, ŋe "moŋliwe jest odkupienie umysģu i jego zastosowaņ w sposób, który moŋe byæ naķladowany przez maszynę. Następnie mamy mechaniczną karykaturę, która wyrównuje aktywnoķæ w dóģ na niŋszy standard ". Roszak ma co najmniej dwie dobre rzeczy do powiedzenia na temat AI - jedną negatywną, a drugą pozytywną. Jeķli chodzi o wynik ujemny, mówi. Istnieje ironiczna, ale bardzo cenna jakoķæ AI we wszystkich jej postaciach. Wysiģek, aby symulowaæ lub przewyŋszyæ ludzką inteligencję, odkrywa subtelnoķci i paradoksy dotyczące ludzkiego umysģu, których moglibyķmy sobie nie wyobraziæ. Poprzez heroiczne niepowodzenia AI uczy nas, jak naprawdę dziwna jest prawdziwa inteligencja. Z jednej strony pozytywnie komentuje, ŋe jedno z AI poczyniģo znaczący postęp. Często, pytając specjalistów o ich pracę, programiķci mogą wypróbowaæ procedury, zaģoŋenia, wartoķci, które następnie moŋna formalnie okreķliæ. Rezultatem jest system ekspercki, jedno z niewielu praktycznych zastosowaņ sztucznej inteligencji. Edward Feigenbaum uwaŋa takie systemy za bramę do następnej ery inteligencji maszynowej; nazywa to "przetwarzaniem wiedzy", a nie zwykģym przetwarzaniem danych. Cokolwiek rozumie przez "wiedzę", z pewnoķcią stanowi bardziej zģoŋone podejķcie do myķlenia niŋ kiedyķ w tej dziedzinie.
Inne opinie
Informatyk Donald Knuth napisaģ, ŋe jest zaintrygowany, ŋe sztucznej inteligencji udaģo się do tej pory zrobiæ zasadniczo wszystko, co wymaga "myķlenia", ale nie udaģo się zrobiæ większoķci tego, co ludzie i zwierzęta robią bez myķlenia "- ŋe , jakoķ jest o wiele trudniejsze! Wierzę, ŋe wiedza zdobyta podczas tworzenia programów AI jest waŋniejsza niŋ korzystanie z programów .John R. Pierce, stwierdziģ, ŋe w odniesieniu do sztucznej inteligencji, pasuje hasģo: "Sztuczna inteligencja to prawdziwa gģupota".
…
Nie lubię sztucznej inteligencji, poniewaŋ uwaŋam, ŋe jest niesprawiedliwa dla komputerów. Ale potem ludzie sztucznej inteligencji opracowali LISP, co jest caģkiem dobre. List nie rozwinąģ się ani w tym sloganie, ani dlaczego AI jest "niesprawiedliwe wobec komputerów" ". Holenderski informatyk Edsger W. Dijkstra sģynąģ z wielu innowacji w informatyce, w tym z algorytmu wyszukiwania najkrótszych (lub najtaņszych) ķcieŋek na wykresach. Popieraģ takŋe tak zwane "programowanie strukturalne", metodologię, która znacznie poprawiģa efektywnoķæ pisania (i rozumienia) programów. Napisaģ do sztucznej inteligencji, która argumentuje: "Ale my jesteķmy tylko maszynami do manipulacji symbolami, prawda?" moŋna tylko odpowiedzieæ: "Nie ma tak ķlepych jak ci, którzy nie zobaczą!" Analogia jest tak pģytka, ŋe moŋna ją opisaæ jako typowo ķredniowieczne myķlenie.
Oprócz obaw o "zawyŋone twierdzenia AI", wielu naukowcyów uwaŋa AI za rodzaj "pobocznej aktywnoķci", która nie byģa zgodna z rygorystycznymi standardami naukowymi i dziedziną, w której ŋyli szarlatani. Jeden z badaczy ostrzegģ przed przyģączeniem się do badaņ nad sieciami neuronowymi. Twierdziģ, ŋe takie badania byģy przedwczesne. Oawy związane z "szacunkiem" wywarģy oszaģamiający wpģyw na niektórych badaczy AI. Sģyszę, jak mówią: byæ krytykowanym za jego lotnoķæ. Teraz, gdy poczyniliķmy znaczne postępy, nie ryzykujmy utraty szacunku ". Jednym z rezultatów tego konserwatyzmu byģa zwiększona koncentracja na "sģabej AI" - odmianie poķwięconej dostarczaniu pomocy ludzkiej myķli - i z dala od "silnej AI" - odmianie, która próbuje zmechanizowaæ inteligencję na poziomie ludzkim. To szkoda, poniewaŋ chociaŋ uwaŋam, ŋe cele sģabej sztucznej inteligencji są waŋne i godne, zbudowanie artefaktu naķladującego zdolnoķci ludzkiego mózgu byģoby ogromnym osiągnięciem naukowym - wartym ryzyka, a wcale nie "nieprzyzwoitoķcią" , "zģo", "ohydne" ani "co do zasady niemoŋliwe".
Problemy skali
Wybuch kombinatoryczny
Poniewaŋ wyszukiwanie odgrywa tak istotną rolę w sztucznej inteligencji, waŋne jest, aby powiedzieæ coķ o tym, jak niezwykle trudne mogą byæ problemy z wyszukiwaniem. Typowym problemem wyszukiwania jest zwykle rzucanie "drzewa" węzģów, takich jak drzewo gry w warcaby Arthura Samuela lub drzewo wyszukiwania z przesuwanymi kafelkami (osiem puzzli). Na przykģad, jeķli kaŋdy węzeģ w drzewie wyszukiwania ma trzy moŋliwe "potomne" węzģy (to znaczy "wspóģczynnik rozgaģęzienia" wynoszący 3), górna częķæ drzewa wyglądaģo by to tak
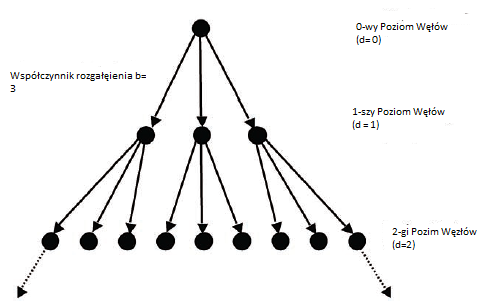
"Pierwszy poziom" drzewa ma trzy węzģy, drugi ma dziewięæ węzģów i tak dalej. W ogólnym przypadku dla drzewa ze wspóģczynnikiem rozgaģęzienia b poziom d-ty miaģby węzģy bd (to znaczy b pomnoŋone przez siebie d razy). Caģkowita liczba węzģów, które wygenerowaģby proces wyszukiwania, gdyby wygenerowaģ caģe drzewo ze wspóģczynnikiem rozgaģęzienia b aŋ do wszystkich węzģów na poziomie gģębokoķci d wģącznie, moŋna obliczyæ na b/ (b-1) (bd - 1). Czytelnicy, którzy przypominają swoją algebrę w szkole ķredniej rozpozna te wyraŋenia jako "wykģadnicze" funkcje d. Poniewaŋ liczba węzģów w drzewie wyszukiwania jest funkcją wykģadniczą jego gģębokoķci, wyszukiwanie jest nazywane procesem wykģadniczym. Gdyby program musiaģ przeszukaæ drzewo ze wspóģczynnikiem rozgaģęzienia 3 do poziomu gģębokoķci 10, aby znaležæ cel, musiaģby wygenerowaæ 88 572 węzģów. Takie liczby byģy w zakresie moŋliwoķci komputerów z lat 60. i 70., więc byģy w stanie rozwiązaæ niektóre z prostszych "problemów z zabawkami" AI. Ale bardziej realistyczne problemy obejmowaģyby drzewa wyszukiwania o znacznie wyŋszych czynnikach rozgaģęziających, mające cele na znacznie większych poziomach gģębokoķci. Na przykģad przeszukanie drzewa ze wspóģczynnikiem rozgaģęzienia od 10 do gģębokoķci 20 (drzewo odpowiadające tylko skromnie trudnemu problemowi wyszukiwania) wymagaģoby wygenerowania ponad 1020 węzģów, co jest caģkiem niemoŋliwe. (1020 to jeden, po którym następuje 20 zer, czyli 100 miliardów miliardów). Trudnoķæ takich wyszukiwaņ ma dwa aspekty: czas obliczeniowy i przestrzeņ dyskowa. Biorąc pod uwagę tylko chwilę obliczeniową, nawet jeķli moglibyķmy wygenerowaæ miliard węzģów na sekundę (co moŋe byæ ledwo moŋliwe do pomyķlenia), wygenerowanie drzewa z czynnikiem rozgaģęzienia i gģębokoķcią zajęģoby 100 miliardów sekund (ponad 3000 lat) wģaķnie rozwaŋaģem. Jeķli chodzi o przestrzeņ dyskową, nawet komputery osobiste są obecnie dostępne w duŋych iloķciach - typowe jest 100 gigabajtów (100 miliardów bajtów). Zakģadając, ŋe pojedynczy węzeģ wymaga okoģo jednego bajtu, wystarczyģoby odpowiednik okoģo miliarda takich komputerów, nawet dla naszego drzewa wyszukiwania o skromnych rozmiarach. Wykģadniczy charakter wyszukiwania oznacza, ŋe wraz ze wzrostem rozmiaru problemu (mierzonego albo przez wspóģczynnik rozgaģęzienia, albo gģębokoķæ drzew wyszukiwania), trudnoķæ obliczeniowa potrzebna do rozwiązania problemu drastycznie wzrasta - tworząc tak zwaną eksplozję kombinatoryczną". Oczywiķcie, nawet wczeķni badacze AI wiedzieli o wybuchach kombinatorycznych. To jest powód ich zainteresowania heurystykami. Niestety heurystyka nie zmienia wykģadniczego charakteru poszukiwaņ - w najlepszym razie redukuje czynnik rozgaģęziający. "Eksplozja" wciąŋ się zdarza {po prostu nie doķæ szybko. Na przykģad zmniejszenie wspóģczynnika rozgaģęzienia z 10 do 4 i ponowne przeszukanie do gģębokoķci 20. nadal wymagaģoby wygenerowania ponad 420 lub, z grubsza, jednego biliona węzģów. Krytycy AI skupili się na tym problemie w swoich pesymistycznych ocenach AI osiągnięcia i perspektywy. Na przykģad Sir James Lighthill (w swoim raporcie, o którym wspomniaģem w rozdziale 16), napisaģ, ŋe "jedna raczej ogólna przyczyna [AI] di spotkania, których doķwiadczyliķmy [to] brak rozpoznania konsekwencji wybuchu kombinatorycznego."Raport Lighthilla spowodowaģ, jak juŋ wspomniaģem, trudnoķci w finansowaniu badaņ nad AI w Wielkiej Brytanii.
Teoria zģoŋonoķci
Badacze AI nie są jedynymi ludžmi, którzy są zaniepokojeni obliczeniową trudnoķcią rozwiązywania problemów. Dziaģ informatyki zwany "teorią zģoŋonoķci" zajmuje się tym, ile czasu i ile miejsca w pamięci mogą zająæ róŋne programy (w najgorszym przypadku), aby rozwiązaæ róŋne rodzaje problemów. Pytają między innymi: "Jak rozmiar problemu wpģywa na czas i przestrzeņ potrzebne do jego rozwiązania?" Spójrzmy na kilka przykģadów. Czas, jaki zajęģoby programowi komputerowemu znalezienie największej liczby na liķcie liczb, jest proporcjonalny do wielkoķci tego problemu, a mianowicie liczby pozycji na liķcie. (Najgorszy przypadek miaģby miejsce, gdyby największy element byģ ostatnim elementem na liķcie; program musiaģby wówczas zbadaæ kaŋdy element na liķcie.) Mówi się, ŋe taki program zajmuje "czas liniowy". Podobnie program sprawdzający, czy dany element jest czģonkiem listy elementów, zająģby liniowy czas. (Ponownie najgorsze zdarzenie miaģoby miejsce, gdyby element byģ ostatnim elementem na liķcie). W obu przypadkach, gdybyķmy podwoili rozmiar, podwoiliķmy wymagany czas. Sortowanie listy nazwisk, na przykģad w kolejnoķci alfabetycznej, jest trudniejszym problemem. Programy do sortowania list róŋnią się pod względem czasu i stopnia skomplikowania w programowaniu. Rozsądnie proste programy sortujące wymagają czasu proporcjonalnego do kwadratu liczby elementów na liķcie. Oznacza to, ŋe dla tych programów sortowanie listy zawierającej 100 pozycji zajęģoby cztery razy więcej niŋ lista zawierająca tylko 50 pozycji. (Pomnoŋenie liczby elementów przez dwa zwiększa czas sortowania o dwa kwadraty lub cztery. Sortowanie moŋe byæ faktycznie wykonywane szybciej. Istnieją programy, które mogą sortowaæ listę w czasie proporcjonalnym do logarytmu wielkoķci razy wielkoķæ.) Programy, które moŋe (w najgorszym przypadku) zająæ czas proporcjonalny do wielkoķci problemu, kwadratu, szeķcianu lub innych "mocy" wielkoķci, przebiegaæ w tak zwanym "czasie wielomianowym". Same problemy moŋna oceniaæ wedģug zģoŋonoķci najmniej zģoŋonych programów, które są w stanie je rozwiązaæ. Na przykģad, jeķli istnieje program, który moŋe rozwiązaæ problem w czasie liniowym, ale ŋaden nie moŋe go rozwiązaæ szybciej, wówczas mówi się, ŋe problem ten ma zģoŋonoķæ liniową. "Sprawdzanie, czy lub ŋaden element nie jest czģonkiem listy elementów, jest to problem liniowej zģoŋonoķci. Przez P okreķlamy klasę problemów, które moŋna rozwiązaæ w czasie wielomianowym. Czģonkowie tej klasy obejmują obliczanie największego wspólnego dzielnika i ustalanie, czy liczba jest liczbą pierwszą. Niestety, jak juŋ wspomniaģem, procedury wyszukiwania stosowane w wielu programach sztucznej inteligencji wymagają czasu dziaģania, który jest wykģadniczy pod względem wielkoķci problemu. Na przykģad wyszukiwanie drzewa o wspóģczynniku rozgaģęzienia b do gģębokoķci d zajęģoby czas proporcjonalny do bd. Korzystając z mojego poprzedniego przykģadu, widzimy, ŋe wyszukiwanie drzewa ze wspóģczynnikiem rozgaģęzienia 3 do poziomu gģębokoķci 10 wymaga wygenerowania 88 572 węzģów. Jednak podwojenie gģębokoķci do 20 wymagaģoby przeszukania nie czterokrotnie 88 572 węzģów (co miaģoby miejsce, gdyby czas wyszukiwania byģ proporcjonalny do kwadratu gģębokoķci), ale 88 572 x 88 572 lub prawie osiem miliardów węzģów. Zģoŋonoķæ wykģadnicza jest znacznie gorsza niŋ zģoŋonoķæ wielomianowa! Amerykaņski informatyk Stephen Cook [oraz rosyjski, a teraz amerykaņski informatyk Leonid Levin] wnieķli znaczący wkģad w nasze zrozumienie zģoŋonoķci problemów i programów zastosowanych do ich rozwiązania. W szczególnoķci Cook (i Levin niezaleŋnie) zdefiniowali klasę zwaną niedeterministycznym wielomianem lub klasą problemów P. Jest to klasa problemów, w przypadku których rozwiązanie potencjalne moŋe zostaæ sprawdzone (ale niekoniecznie rozwiązane) w czasie wielomianowym. Na przykģad proponowaną sekwencję ruchów w celu rozwiązania ukģadanki z przesuwanymi kafelkami moŋna sprawdziæ, czy faktycznie rozwiązuje ukģadankę w czasie wielomianowym, ale (o ile wiadomo) znalezienie rozwiązania wymagaģoby czasu wykģadniczego. Problemy z przesuwanymi pģytkami, podobnie jak wiele innych problemów AI, naleŋą do klasy NP. Nie wiadomo, czy mogą istnieæ programy wielomianowe do rozwiązywania problemów w klasie NP. Gdyby tak byģo, NP równaģoby się P. Jak dotąd programy rozwiązywania problemów w klasie NP wymagają czasu wykģadniczego (w najgorszym przypadku). To, czy NP równa się P, jest jednym z najbardziej znanych nierozwiązanych problemów w informatyce. Wiele osób uwaŋa, ŋe NP nie równa się P, poniewaŋ w przeciwnym razie doszlibyķmy do tej pory. (Clay Mathematics Institute zaoferowaģ nagrodę w wysokoķci 1 000 000 $ za rozwiązanie pytania P kontra NP {to znaczy, ŋe są równe lub nie są równe.)
Trzežwa ocena
Te wyniki w teorii zģoŋonoķci spowodowaģy, ŋe niektórzy ludzie mieli powaŋne wątpliwoķci co do perspektyw sztucznej inteligencji. Jedną z najbardziej wnikliwych i moim zdaniem inteligentnych ocen napisaģ matematyk i informatyk Jacob T. Schwartz, o którym wspominaģem juŋ w związku ze swoją kadencją w DARPA. W swoim artykule zatytuģowanym "Granice sztucznej inteligencji" Schwartz napisaģ, ŋe niezwykģe moce ludzkiego mózgu wynikają ze sposobu, w jaki wykorzystaģ swoje ogromne zdolnoķci obliczeniowe i magazynowe "do organizowania informacji prezentowanych w stosunkowo nieuporządkowanej formie w wewnętrznie zorganizowanych strukturach, na których Schwartz twierdziģ, ŋe wyrafinowane, spójne kierunki symbolicznej i rzeczywistej akcji mogą byæ oparte. "Aby rywalizowaæ z mózgiem, czego AI potrzebuje i co AI na próŋno próbuje osiągnąæ, są to" spójne struktury zdolne do bezpoķredniego prowadzenia jakiejķ formy komputera akcja. . . generowane automatycznie na podstawie stosunkowo niezorganizowanych, rozdrobnionych danych wejķciowych. "Zdolnoķæ do generowania takich" zorganizowanych struktur "stanowiģaby ogromny przeģom, poniewaŋ komputery są juŋ" niezwykle nadludzkie "w rozwiązywaniu problemów, dla których mogą" zaakceptowaæ, zatrzymaæ i wykorzystaæ w peģni ustrukturyzowany materiaģ. "" Gdyby podstawową przeszkodę wynikającą z koniecznoķci szczegóģowego programowania [komputerów] moŋna byģo pokonaæ ", napisaģ," komputery mogģyby spoŋywaæ informacje zawarte we wszystkich bibliotekach na ķwiecie i wykorzystywaæ je z nadludzką skutecznoķcią "(obecnie oczywiķcie, oprócz bibliotek, w Internecie jest caģa informacja i dezinformacja.) Metody, których badacze AI uŋywali do automatycznego tworzenia struktury z fragmentów danych wejķciowych, oparte byģy na wyszukiwaniu heurystycznym - albo na poszukiwaniu logicznych dedukcji, albo na ķcieŋki w drzewach (i bardziej ogólnie na wykresach). Do odpowiedzi na pytania, w celu dostarczenia exp wykorzystano logiczne dedukcje (między innymi) porady i generowanie programów i planów. Poszukiwania ķcieŋek na wykresach wykorzystano do udowodnienia twierdzeņ w geometrii, do parsowania zdaņ i do tworzenia planów dla robotów. Wszystko to są przypadki tworzenia struktury (uŋywając terminu Schwartza) z nieustrukturyzowanego
wejķcia. Te "sukcesy" zostaģy jednak osiągnięte albo w przypadku trywialnie maģych problemów, albo w przypadku tych, których tematyka byģa ķciķle ograniczona. Niestety, jak sģusznie twierdziģ Schwartz, wszystkie dotychczasowe próby wygenerowania "ogólnie uŋytecznych struktur symbolicznych z bardziej niezorganizowanych i fragmentarycznych danych wejķciowych" niezmiennie zostaģy pokonane przez kombinatoryczną eksplozję. Podsumowaģ sytuację, powtarzając zarzut Dreyfusa, ŋe "
dotychczasowa historia badaņ nad sztuczną inteligencją [skģadaģa się] zawsze z bardzo ograniczonych sukcesów w poszczególnych obszarach, po czym natychmiast nie udaģo się osiągnąæ szerszych celów, przy których początkowe sukcesy wydają się na początku wskazaæ… "
Opinie Schwartza na temat AI miaģy konsekwencje, poniewaŋ byģ dyrektorem DARPA ISTO w latach 1987-1998 i przewodniczyģ pewnym ograniczeniom w badaniach nad AI. Chociaŋ ogólnie lekcewaŋyģ pracę AI, Schwartz napisaģ, ŋe moŋna oczekiwaæ, ŋe te obszary AI, do których stosuje się klasyczne techniki naukowe i algorytmiczne, będą postępowaæ szybciej niŋ obszary, które dotyczą gģębszych problemów, dla których dostępne są tylko mniej ukierunkowane podejķcia "Jako jeden przykģad przytoczyģ problem okreķlania, czy jeden lub więcej obiektów o znanym ksztaģcie poruszających się w ķrodowisku zawierającym przeszkody o innych znanych ksztaģtach moŋe przejķæ z jednej okreķlonej pozycji do drugiej bez kolizji z przeszkodą lub ze sobą . " Chociaŋ wyniki teorii zģoŋonoķci stanowiģy jeden z "skoków prędkoķci" w szybkim postępie AI w przód, badacze AI szybko odzyskali i znaležli róŋne sposoby rozwiązania problemu kombinatorycznej eksplozji. Wskazali na przykģad, ŋe wyniki zģoŋonoķci byģy oparte na wydajnoķci w najgorszym przypadku, a rozwiązania często moŋna znaležæ szybciej niŋ w najgorszym przypadku. Na przykģad wspomnę o pracy Richarda Korfa, badacza AI na University of California w Los Angeles. Korf jest znany ze swojej pracy nad rozwiązywaniem bardzo trudnych problemów wyszukiwania. Często uŋywa przesuwanej pģytki i innych ģamigģówek jako laboratorium " drosophila" do eksploracji nowych pomysģów w poszukiwaniu. Pamiętasz, ŋe uŋyģem przykģadu ukģadanki z przesuwanymi kafelkami, aby zilustrowaæ heurystyczne procesy wyszukiwania. Ten, którego uŋyģem, skģadaģ się z oķmiu pģytek w ukģadzie 3 x 3; klasyczna wersja skģada się z piętnastu pģytek w ukģadzie 4 x 4. Moŋna sobie wyobraziæ większe wersje, takie jak dwadzieķcia cztery pģytki w ukģadzie 5 x 5. Ukģadanka 4 x 4 stanowi juŋ doķæ trudny problem dla wyszukiwania heurystycznego. W swoich komentarzach na temat trudnoķci związanych z skalowaniem procesów wyszukiwania Jack Schwartz napisaģ "wykres stanów [ukģadanki 3 x 3] skģada się z 9!, lub 362 880 [węzģów], więc nawet dla tak prostego problemu wyszukiwanie wykresów siģowych zaczyna byæ obciąŋające. Dla odpowiednich ģamigģówek 4 x 4, których przestrzeņ stanu obejmuje 16!, lub więcej niŋ 10 13 , węzģów, jest to caģkowicie niemoŋliwe do wykonania. "[Wģaķciwie Schwartz byģ wyģączony przez (nieistotny) czynnik 2 w oba przypadki: od 1879 r. wiadomo, ŋe jeķli zaczniesz od jakiejķ konkretnej konfiguracji początkowej, moŋesz osiągnąæ tylko 1/2 wszystkich moŋliwych konfiguracji. Zatem dla wersji z oķmioma pģytkami caģy wykres przestrzeni stanów skģada się dwóch oddzielnych niepowiązanych wykresów o rozmiarze 9! = 2 = 181; 440.] Jednak Korf nie tylko napisaģ heurystyczne programy wyszukiwania do rozwiązywania przypadków ukģadanki 4 x 4, ale w streszczeniu artykuģu z 1996 roku on i wspóģautor napisaģ. "Znaležliķmy pierwsze optymalne rozwiązania dla kompletnego zestawu losowych przykģadów Ukģadanki Dwudziestu Czterech, znanej wersji ukģadanki z przesuwanymi kafelkami w wersji 5 x 5. Nasz nowy wkģad w rozwiązanie tego problemu to silniejsza dopuszczalna funkcja heurystyczna.
…
[Obserwujemy], ŋe wraz z powiększaniem się problemów wyszukiwania heurystycznego, więcej potęŋnych funkcji heurystycznych staje się niezbędnych i opģacalnych."
Obszar wyszukiwania dla ukģadanki 5 x 5 jest okoģo biliona razy większy niŋ dla ukģadanki 4 x 4. Ma okoģo 7,756 x 1024 węzģów. Wyszukiwanie jest równieŋ ģatwiejsze, jeķli moŋna zadowoliæ się "dobrymi" lub przybliŋonymi rozwiązaniami problemów zamiast nalegaæ na "najlepsze" rozwiązania. W następnym rozdziale opiszę kilka doķæ znaczących postępów w radzeniu sobie z duŋymi problemami wyszukiwania; postęp ten nieco przyspieszyģ. Jednak nawet przy tych sposobach rozwiązywania zģoŋonoķci ludzie AI zaczęli dostrzegaæ inne niedociągnięcia
Potwierdzone niedociągnięcia
Kiedy badacze AI zaczęli stawiaæ czoģa problemom o znaczeniu praktycznym, sami musieli przyznaæ się do kilku trudnoķci. Pojawiģy się w kilku obszarach zastosowania. Wspomnę tylko o kilku. Na przykģad, próbując udowodniæ nietrywialne twierdzenia matematyczne, programy dowodzące twierdzeņ szybko wyczerpaģy przestrzeņ niezbędną do przechowywania wyników poķrednich. Ale ludzie (przynajmniej niektórzy ludzie) są w stanie udowodniæ te twierdzenia. Jakie metody wykorzystują te programy komputerowe? Matematycy prawdopodobnie powiedzieliby, ŋe intuicja, osąd, doķwiadczenie, matematyczne wyrafinowanie i takie są kluczowe dla ich sukcesów. Jak dotąd dostarczenie komputerom takich moŋliwoķci okazaģo się trudne. W grze, chociaŋ MAC HACK VI i CHESS 4.6, by wymieniæ dwa przykģady, graģy caģkiem niezģe szachy, daleko im byģo do pokonania mistrzów ķwiata. W rzeczywistoķci w sierpniu 1978 r. na kanadyjskiej wystawie krajowej w Toronto David Levy pokonaģ aktualnego mistrza szachów komputerowych CHESS 4.7 z Northwestern University, wygrywając w ten sposób zakģad lata wczeķniej przeciwko Johnowi McCarthy′emu i Donaldowi Michie. Jak ująģ to Levy: "Udaģo mi się pokonaæ program doķæ przekonująco, przez trzy wygrane do jednego z jedną remisową grą (szósta gra nie musiaģa zostaæ rozegrana) i tym meczem wygraģem zakģad". Co odpowiada zdolnoķci mistrzowskiej? Jest maģo prawdopodobne, aby mistrzowie szachowi oglądali więcej pozycji szachowych niŋ komputery. Prawdopodobnie jednak patrzą dalej w drzewo gry wzdģuŋ najwaŋniejszych gaģęzi. Wydaje się, ŋe ich doķwiadczenie pozwala im oceniæ potencjaģ kandydujących pozycji, które są warte eksploracji, i zignorowaæ dalszą eksplorację bezwartoķciowych pozycji. Byæ moŋe myķlą takŋe bardziej strategicznie niŋ programy szachowe uwzględniające poszczególne ruchy szachowe. Inną grą, byæ moŋe bardziej wymagającą dla ludzi niŋ szachy, jest gra Go - gra planszowa, która powstaģa w Chinach ponad 4000 lat temu i jest dziķ bardzo popularna w krajach azjatyckich. W Go dwaj gracze naprzemiennie umieszczają czarne i biaģe kamienie na przecięciach siatki 19 x 19 dwóch zestawów linii rządzących na planszy. Nie będę tutaj opisywaģ zasad gry, z wyjątkiem stwierdzenia, ŋe (przynajmniej na wczesnych etapach gry) gracz stoi przed problemem decydowania, na której z prawie 361 (19 x 19) pozycji umieķciæ kamieņ. Nawet w przypadku najpotęŋniejszych procesów wyszukiwania przeszukiwanie drzewa, którego kaŋdy węzeģ ma prawie 361 bezpoķrednich potomków, nie wchodzi w rachubę. Ludzcy gracze muszą stosowaæ inne strategie i niezaleŋnie od tych strategii, wciąŋ są nieznani badaczom AI. Wielu badaczy AI uwaŋa, ŋe wydajnoķæ w Go jest lepszą miarą zdolnoķci AI niŋ jest występ w szachach. Mimo, ŋe systemy eksperckie skutecznie (a nawet z korzyķcią ekonomiczną) uzasadniają okreķlone problemy w medycynie, geologii, chemii i innych okreķlonych obszarach, uznaje się je za "kruche" (to znaczy rozpadają się w obliczu problemów poza ich obszarem wiedza specjalistyczna, a nawet problemy w obszarze ich wiedzy specjalistycznej, jeķli potrzebna byģa wiedza, która nie zostaģa zapewniona w ich zasadach. Nie wiedzą, czego nie wiedzą i dlatego mogą udzieliæ bģędnych odpowiedzi w przypadkach, w których ludzki ekspert byģby lepszy. Mówi się, ŋe John McCarthy, w interakcji z lekarskim systemem eksperckim MYCIN, wpisaģ pewne informacje o hipotetycznym pacjencie, mówiąc, ŋe byģ męŋczyzną, a takŋe, ŋe przeszedģ amniopunkcję. MYCIN zaakceptowaģ to wszystko bez reklamacji! To, ŋe pacjenci pģci męskiej nie zachodzą w ciąŋę, nie zostaģo uznane za częķæ "wiedzy eksperckiej", którą naleŋy podaæ MYCIN. Jednym z powodów, dla których systemy eksperckie są kruche, jest brak zdrowego rozsądku. Oprócz wiedzy eksperckiej, którą ludzie mogą zdobyæ dzięki edukacji i doķwiadczeniu zawodowemu, mają równieŋ duŋą wiedzę ogólną. Wiedzą na przykģad, ŋe tylko kobiety mogą zajķæ w ciąŋę, ŋe parasole chronią przed sģoņcem i deszczem, migrują niektóre ptaki, ŋe ŋywnoķæ moŋna kupiæ na rynkach i miliony innych faktów. Benjamin Kuipers, badacz AI i profesor na University of Michigan (wczeķniej University of Texas at Austin), w ten sposób okreķlili zdrowy rozsądek:
"Wiedza zdrowa to wiedza o strukturze ķwiata zewnętrznego, którą kaŋdy normalny czģowiek pozyskuje i stosuje bez skoncentrowanego wysiģku, co pozwala mu sprostaæ codziennym wymaganiom ķrodowiska fizycznego, przestrzennego, czasowego i spoģecznego z rozsądnym powodzeniem ."
Wiedzę ogólną nabywa się stopniowo w miarę dorastania dzieci i dojrzewania dorosģych. Na przykģad dziecko prawdopodobnie nie wie, ŋe maģe tabletki w maģych plastikowych butelkach mogą byæ niebezpieczne w przypadku poģknięcia (dlatego butelki te mają zakrętki zabezpieczające przed dostępem dzieci), nastolatki wiedzą wiele rzeczy, których zwykle oķmiolatki zwykle nie wiedzą, i wiedza, która umoŋliwia czytelnikowi "New Yorkera", powiedzmy, zrozumienie jego recenzji ksiąŋek i filmów, wykracza poza to, co zwykle wie nastolatek. Oczywiķcie ludzie w róŋnych krajach i kulturach będą mieli inny zdrowy rozsądek. Wydaje mi się, ŋe wiedzę o konkretnym czģowieku naleŋy uwaŋaæ za stale rosnące drzewo, którego podstawa i niŋsze gaģęzie stanowią "zdrowy rozsądek", a górne ramię obejmuje "wiedzę specjalistyczną" wyspecjalizowanych dyscyplin, których dana osoba mogģaby się nauczyæ . Metafora drzewa jest równieŋ przydatna do podkreķlenia, ŋe wiedza w górnych gaģęziach wykorzystuje pojęcia występujące w pniu i dolnych gaģęziach. Widzieliķmy , ŋe peģne zrozumienie zdaņ w języku naturalnym wydaje się wymagaæ zdrowego rozsądku informacji, które ludzie mają, ale komputery wciąŋ tego nie robią. Przeraŋająca perspektywa wyposaŋenia komputerów w zdrowy rozsądek doprowadziģa do dwóch zupeģnie przeciwnych reakcji. Niektórzy postrzegają ten problem jako wykluczający moŋliwoķæ AI (lub przynajmniej silnej AI) w dającej się przewidzieæ przyszģoķci. Inni jednak mówią: "Dajmy sobie z tym radę". (Będę mówiæ o pracy jednego z osób, z którymi się zabieramy w następnym rozdziale). Oczywiķcie nie ma juŋ naleŋy się spodziewaæ, ŋe jakikolwiek system sztucznej inteligencji zrozumie wszystkie zdania w języku naturalnym, niŋ moŋna oczekiwaæ, ŋe kaŋdy konkretny czģowiek zrozumie zdania w języku naturalnym na wszystkie tematy. Ludzie mają swoje ograniczenia, a programy AI teŋ je będą. Perspektywa ta nie powinna juŋ ograniczaæ nasze próby stworzenia inteligentnych programów, a nie edukacji inteligentnych ludzi.
"Zima AI"
We wczesnych latach osiemdziesiątych wielu sponsorów AI, zarówno w rządzie, jak i przemyķle, nie bardzo speģniģo oczekiwania co do tego, co AI moŋe dla nich zrobiæ. Niewątpliwie częķæ winy za ich nieuzasadniony optymizm moŋna obciąŋyæ samych badaczy AI, którzy byli zmotywowani do przesadnych obietnic. Niepowodzenie w dostarczeniu systemów pasujących do tych nierealistycznych nadziei, wraz z kumulującym się krytycznym komentarzem, o którym juŋ wspomniaģem, poģączyģo się w poģowie lat 80. pod koniec lat 80. XX wieku, aby stworzyæ coķ, co nazwano "zimą AI". Rzeczywiķcie na krajowej konwencji AAAI w 1984 r. kilku wiodących badaczy AI ostrzegģo o tej moŋliwoķci podczas sesji panelowej zatytuģowanej "Ciemne wieki AI" (Czy moŋemy ich uniknąæ, czy przetrwaæ?) Przewodniczący panelu, Drew McDermott z Yale University, rozpocząģ sesję od powiedzenia. "Pomimo wszystkich komercyjnych zgieģków wokóģ AI, jestem pewien, ŋe wielu z was zna gģęboki niepokój wķród badaczy AI, którzy byli juŋ od ponad czterech ostatnich lat. Niepokój spowodowany jest obawą, ŋe byæ moŋe oczekiwania dotyczące AI są zbyt wysokie i ŋe ostatecznie doprowadzi to do katastrofy.
… Myķlę, ŋe waŋne jest, abyķmy podjęli kroki w celu zapewnienia ŋe "Zima AInie dzieje się {poprzez dyscyplinowanie siebie i edukację spoģeczeņstwa".
Ale jeķli miaģy miejsce "dyscyplina" i "edukacja", byģy one niewystarczające, aby zapobiec niepokojącemu kryzysowi. Pod koniec lat osiemdziesiątych czģonkostwo w AAAI stopniowo spadaģo. Do 1996 r. Osiągnęģa poziom od 4000 do 5000 czģonków. Spadģa równieŋ reklama w magazynie AI - podobnie jak udziaģ rządu i przemysģu w eksponatach konferencji AI. Kilka firm AI zamknęģo drzwi, a badania nad AI w niektórych większych firmach z branŋy sprzętu komputerowego i oprogramowania zostaģy zakoņczone. Wedģug Alexa Rolanda, między 1987 a 1989 rokiem, budŋet DARPA na podstawowe badania AI i Strategic Computing spadģ z 47 milionów do 31 milionów dolarów. (Mimo to, wedģug Alexa Rolanda, budŋet CMU zostaģ zwiększony na program rozumienia mowy i program pojazdów autonomicznych w tym czasie). Ale zima trwaģa tylko przez sezon {sezon nie hibernacji, ale wznowione wysiģki, aby kontynuowaæ. Przebadano kilka nowych pomysģów, a starsze wzmocniono dodanymi mocami