Reprezentacja wiedzy
Aby system byģ inteligentny, musi posiadaæ wiedzę o swoim ķwiecie i ķrodki do wyciągania wniosków lub przynajmniej dziaģania na podstawie tej wiedzy. Zarówno ludzie, jak i maszyny muszą zatem mieæ sposoby na reprezentowanie tej potrzebnej wiedzy w strukturach wewnętrznych, niezaleŋnie od tego, czy są zakodowane w biaģku, czy w krzemie. Kognitywistyczni i badacze AI rozróŋniają dwa gģówne sposoby reprezentacji wiedzy: proceduralną i deklaratywną. U zwierząt wiedza potrzebna do wykonania wyszkolonego dziaģania, takiego jak uderzenie piģką tenisową, jest nazywana proceduralną, poniewaŋ jest zakodowana bezpoķrednio w obwodach neuronowych, które koordynują i kontrolują to okreķlone dziaģanie. Analogicznie, systemy automatycznego lądowania w samolotach zawierają w swoich programach kontroli wiedzę proceduralną o ķcieŋkach i prędkoķciach lądowania, dynamice samolotu i tak dalej. W przeciwieņstwie do tego, kiedy odpowiadamy na pytanie, takie jak "Ile masz lat?", Odpowiadamy deklaracyjnym zdaniem, na przykģad "Mam dwadzieķcia cztery lata". Kaŋda wiedza, która jest najbardziej naturalnie reprezentowana przez zdanie deklaratywne, nazywana jest deklaratywną. W badaniach AI (i ogólnie w informatyce) wiedza proceduralna jest reprezentowana bezpoķrednio w programach, które wykorzystują tę wiedzę, podczas gdy wiedza deklaratywna jest reprezentowana w symbolicznych strukturach, które są mniej więcej oddzielone od wielu róŋnych programów, które mogą wykorzystywaæ informacje w tych strukturach. Przykģadami struktur symboli wiedzy deklaratywnej są te, które kodują logiczne stwierdzenia (takie jak McCarthy zalecany do reprezentowania wiedzy o ķwiecie) oraz te, które kodują sieci semantyczne (takie jak Rafael lub Quillian). Zazwyczaj reprezentacje proceduralne, specjalizujące się w konkretnych zadaniach, są bardziej wydajne (podczas wykonywania tych zadaņ), podczas gdy deklaratywne, które mogą byæ uŋywane przez wiele róŋnych programów, są bardziej przydatne. W tym rozdziale opiszę niektóre pomysģy przedstawione w tym okresie w celu uzasadnienia i reprezentowania wiedzy deklaratywnej.
Odliczenia w logice symbolicznej
Arystoteles zacząģ logikę od analizy sylogizmów. W dziewiętnastym wieku George Boole rozwinąģ podstawy logiki zdaņ, a Gottlob Frege poprawiģ ekspresyjną moc logiki, proponując język, który mógģby zawieraæ elementy wewnętrzne (zwane "terminami") jako częķæ zdaņ. Póžniejsze osiągnięcia róŋnych logików daģy nam tak zwane dziķ rachunek predykatów {ten sam język, w którym McCarthy zaproponowaģ reprezentację wiedzy potrzebnej inteligentnemu systemowi. Oto przykģad jednego z sylogizmów Arystotelesa, wyraŋonych w języku rachunku predykatu:
1. (∀(x)[Man(x) ⊃ Mortal(x)]
(Wyraŋenie "∀(x) "jest sposobem pisania " dla wszystkich x"; oraz wyraŋenie "⊃" to sposób pisania "implikuje to." "Man (x) "to sposób pisania "x to czģowiek "; a "Mortal (x)" to sposób pisania "x jest ķmiertelny. "Zatem caģe wyraŋenie jest sposobem pisania "dla wszystkich x, x jest męŋczyzną, co oznacza, ŋe x jest ķmiertelny" lub, równowaŋnie, "wszyscy ludzie są ķmiertelni")
2. Czģowiek (Sokrates)
(Sokrates jest męŋczyzną.)
3. Dlatego Mortal (Sokrates)
(Sokrates jest ķmiertelny).
Instrukcja 3, po "Dlatego", jest przykģadem dedukcji logicznej. McCarthy zaproponowaģ, aby wiedzę, jakiej inteligentny agent moŋe potrzebowaæ w konkretnej sytuacji, moŋna wywnioskowaæ z ogólnej wiedzy przekazanej mu wczeķniej. Zatem w przypadku sztucznej inteligencji w stylu McCarthy potrzebujemy nie tylko języka (byæ moŋe rachunku predykatów), ale takŋe sposobu na dokonanie niezbędnych dedukcji na podstawie wyciągów w języku. Logicy opracowali róŋne metody dedukcyjne oparte na tak zwanych "reguģach wnioskowania". Na przykģad jedna waŋna zasada wnioskowania nazywa się modus ponens (z ģaciny dla "trybu, który potwierdza"). Stwierdza się, ŋe jeķli mamy dwie logiczne instrukcje P i P ⊃Q, uzasadnione jest wydedukowanie instrukcji Q. Do lat 60. powstaģy programy, które mogģyby wykorzystywaæ reguģy wnioskowania do udowodnienia twierdzeņ w rachunku predykatów. Gģównymi z nich byli Paul Gilmore z IBM, Hao Wang z IBM, i Dag Prawitz, 3z Uniwersytetu Sztokholmskiego. Chociaŋ ich programy mogģyby udowodniæ proste twierdzenia, udowodnienie, ŋe te bardziej zģoŋone wymagaģyby zbyt wielu poszukiwaņ. Dr Harvard student, Fisher Black), póžniej wspóģtwórca równania Blacka -Scholesa dla opcji cenowych, wykonaģ wczesną pracę nad wdroŋeniem niektórych pomysģów McCarthy′ego.
Ale to byģy doktorant Stanforda, badacz SRI, C. Cordell Green, zaprogramowaģ system QA3, który w peģni zrealizowaģ zalecenie McCarthy′ego. Chociaŋ nie byģo trudno przedstawiæ ķwiatową wiedzę jako logiczne stwierdzenia, w czasie pracy Blacka brakowaģo skutecznej mechanicznej metody wyciągania wniosków z tych stwierdzeņ. Green byģ w stanie zastosowaæ nową metodę efektywnego rozumowania opracowaną przez Johna Alana Robinsona. Na początku lat szeķædziesiątych angielski (i amerykaņski) matematyk i logik John Alan Robinson opracowaģ metodę dedukcji szczególnie dobrze dostosowaną do implementacji komputerowej. Opieraģa się on na zasadzie wnioskowania, którą nazwaģ "rozdzielczoķcią". Chociaŋ peģny opis rozdzielczoķci wymagaģby zbyt wielu szczegóģów technicznych, jest to reguģa (jak jest modus ponens), której aplikacja tworzy nową instrukcję z dwóch innych instrukcji. Na przykģad: rozdzielczoķæ zastosowana do dwóch instrukcji: ¬P ∨ Q, a P tworzy Q. (Symbol ¬ "jest sposobem pisania "not", a symbol "∨"jest sposobem pisania "or"). Rozdzielczoķæ moŋe byæ uwaŋane za anulowanie P i ¬P w dwóch instrukcjach. (Rozdzielczoķæ jest rodzajem uogólnionego modusa ponens, co widaæ z faktu, ŋe ¬P ∨ Q jest logicznie równowaŋne z P ⊃ Q.) Ten przykģad byģ szczególnie proste, poniewaŋ stwierdzenia nie miaģy wewnętrznych terminów. Kluczowym wkģadem Robinsona byģo pokazanie, w jaki sposób moŋna zastosowaæ rozdzielczoķæ do wyraŋeņ ogólnych w rachunku predykatów, wyraŋenia takie jak: ¬P(x)∨Q (x) z terminami wewnętrznymi. Zaletą rozdzielczoķci jest ŋe moŋna go ģatwo wdroŋyæ w programach, aby dokonaæ dedukcji z zestawu dzienników oķwiadczenia. Aby to zrobiæ, naleŋy najpierw przekonwertowaæ instrukcje na specjalną formę skģadającą się z tego, co logicy nazywają "klauzulami".(Lužno mówiąc, klauzula jest formuģą, która uŋywa tylko ∨ i oraz ¬ chociaŋ niektórzy, na przykģad John McCarthy, narzekają, ŋe konwersja moŋe wyeliminowaæ wskazówki o tym, jak najlepiej wykorzystaæ wyciągi w logicznych wnioskach).
Pierwsze uŋycie rozdzielczoķci byģo w programach komputerowych w celu udowodnienia twierdzeņ matematycznych. (Technicznie rzecz biorąc, "twierdzenie" to dowolne zdanie logiczne uzyskane poprzez sukcesywne stosowanie reguģy wnioskowania, takiej jak rozdzielczoķæ, do czģonków podstawowego zestawu zdaņ logicznych, zwanych "aksjomatami ", oraz do stwierdzeņ wywodzących się z aksjomatów.) Grupy w Argonne National Laboratories (Lawrence Wos), na University of Texas w Austin (Woody Bledsoe) i na University of Edinburgh (Bernard Meltzer) wkrótce rozpoczęģy prace nad opracowywaniem programów dowodzących twierdzeņ na podstawie rezolucji. Programy te byģy w stanie udowodniæ twierdzenia, które wczeķniej zostaģy udowodnione "ręcznie", a nawet niektóre nowe, nigdy wczeķniej niepotwierdzone, matematyczne twierdzenia. Jeden z nich dotyczyģ przypuszczenia Herberta Robbinsa, ŋe algebra Robbinsa byģa logiczna, zostaģ udowodniony w 1996 r. przez Williama McCune′a, wykorzystując automatyczną weryfikację twierdzeņ. Jednak naszym problemem jest wykorzystanie metod dedukcyjnych w celu zautomatyzowania wnioskowania potrzebnego przez inteligentne systemy. Okoģo 1968 r. zaprogramowaģ Green (wspomagany przez innego studenta ze Stanford, Roberta Yatesa), w LISP, oparty na rozdzielczoķci system dedukcji o nazwie QA3, który dziaģaģ na wspóģdzielonym w czasie komputerze SRI SDS 940. (QA1, pierwszy test Greena, kierowany przez Bertrama Raphaela w SRI, byģ próbą ulepszenia wczeķniejszego systemu SIR Raphaela. QA2 byģ pierwszym systemem Greena opartym na rozdzielczoķci, a QA3 byģ bardziej wyrafinowanym i praktycznym potomkiem.) "QA" oznaczaģo "odpowiedž na pytanie", "jedną z motywujących aplikacji. Przedstawię krótki przykģad ilustrujący pytanie QA3 - zdolnoķæ zwijania zaczerpnięta z doktora Greenforda . Po pierwsze, do systemu przekazywane są dwie instrukcje, a mianowicie:
1. ROBOT (Rob)
(Rob jest robotem.)
2. (∀x) [MASZYNA(x) ⊃¬ ZWIERZĘTA (x)]
(x oznacza maszynę, co oznacza, ŋe nie jest zwierzęciem).
Następnie pytany jest system "Czy wszystko jest zwierzęciem? ", Próbując wydedukowaæ stwierdzenie
3. (∀x) ZWIERZĘTA (x)
QA3 nie tylko odpowiada "NIE, "stwierdzając, ŋe takie odliczenie jest niemoŋliwe, ale takŋe daje "kontrprzykģad" jako odpowiedž na pytanie:
4. x = Rob
(Oznacza to, ŋe ¬ANIMAL (Rob) zaprzecza temu, co miaģo byæ wydedukowane.)
Zastosowanie rozdzielczoķci, podobnie jak dowolnej reguģy wnioskowania, w celu wyciągnięcia pewnych konkretnych wniosków z duŋej liczby logicznych stwierdzeņ, wiąŋe się z koniecznoķcią podjęcia decyzji, do których dwóch stwierdzeņ, spoķród wielu moŋliwoķci, naleŋy zastosowaæ reguģę. Następnie trzeba podejmowaæ podobną decyzję raz za razem, aŋ, jak moŋna się spodziewaæ, ostatecznie uzyska się poŋądany wniosek. Podobnie jak w przypadku programów do gry w warcaby, rozwiązywania zagadek i dowodzenia twierdzeņ geometrii, programy dedukcyjne stoją przed koniecznoķcią wypróbowania wielu moŋliwoķci w poszukiwaniu rozwiązania. Podobnie jak w przypadku innych programów, opracowano róŋne metody wyszukiwania heurystycznego dla programów dedukcyjnych
Rachunek sytuacyjny
Green zdaģ sobie sprawę, ŋe "odpowiadanie na pytania" byģo doķæ szerokim tematem. Moŋna zadawaæ pytania na prawie wszystko. Na przykģad moŋna zapytaæ: "Co to jest program do zmiany kolejnoķci liczb, aby byģy one coraz bardziej uporządkowane liczbowo?" Albo moŋna zapytaæ: "Jaką sekwencję kroków powinien podjąæ robot, aby zģoŋyæ wieŋę z klocków z zabawkami? "Kluczem do zastosowania QA3 do odpowiedzi na tego rodzaju pytania byģo uŋycie" rachunku sytuacji " McCarthy′ego. McCarthy zaproponowaģ wersję logikę nazwaģ "rachunkiem sytuacyjnym", w którym moŋna napisaæ logiczne instrukcje, które wyražnie okreķlają sytuację, w której coķ lub coķ jest prawdą. Na przykģad, jeden blok zabawki moŋe znajdowaæ się nad drugim w jednej sytuacji, ale nie w innej. wersja logiki McCarth′yego, w której sytuacja, w której coķ byģo prawdą, pojawiģa się jako jeden z terminów w wyraŋeniu stwierdzającym, ŋe coķ byģo prawdą. Na przykģad, aby powiedzieæ, ŋe blok A znajduje się nad blokiem B w pewnej sytuacji S ( uwzględniając fakt, ŋe moŋe się tak nie zdarzyæ w innych sytuacjach),
On (A; B; S);
by powiedzieæ, ŋe blok A jest niebieski we wszystkich sytuacjach,
(∀s) Niebieski (A; s);
i aby powiedzieæ, ŋe istnieje sytuacja, w której blok A znajduje się w bloku B,
(∃s) On (A; B; s):
Tutaj "(∃s) "jest sposobem pisania" istnieją pewne takie, ŋe… "
QA3 byģ w stanie nie tylko wydedukowaæ instrukcje, ale takŋe, gdy wydedukowaģ a tak zwane oķwiadczenie egzystencjalne (takie jak wģaķnie wspomniane), byģo w stanie obliczyæ wystąpienie tego, co rzekomo istniaģo. "Tak więc, kiedy wydedukowano oķwiadczenie (∃s) On (A; B; s), to obliczyģ równieŋ, dla której sytuacji odliczenie byģo waŋne. Green wymyķliģ sposób, w jaki wartoķæ tę moŋna wyraziæ w postaci listy dziaģaņ robota, które zmieniģyby pewną sytuację początkową w sytuację, w której stwierdzenie byģo prawdziwe. na przykģad QA3 moŋna wykorzystaæ do planowania dziaģaņ robota, a póžniej zobaczymy, jak zostaģ wykorzystany do tego celu.
Programowanie logiki
W ten sam sposób, w jaki QA3 moŋe byæ wykorzystywany do tworzenia planów robotów, moŋe równieŋ konstruowaæ proste programy komputerowe. W swoim artykule z 1969 roku Green napisaģ
"Podana tutaj formalizacja moŋe byæ uŋyta do precyzyjnego okreķlenia i rozwiązania problemu automatycznego generowania programów, w tym programów rekurencyjnych, wraz z równoczesnym generowaniem dowodów poprawnoķci tych programów. W związku z tym wszelkie programy pisane automatycznie tą metodą nie zawierają bģędów. "
Praca Greena nad programowaniem automatycznym byģa pierwszą próbą pisania programów przy uŋyciu instrukcji logicznych. Mniej więcej w tym czasie Robert A. Kowalski, Amerykanin, który wģaķnie uzyskaģ stopieņ doktora. na Uniwersytecie w Edynburgu, i Donald Kuehner opracowali bardziej skuteczną wersję metody rozdzielczoķci Robinsona, którą nazwali "rozdzielczoķæ-SL.
Latem 1972 r. Kowalski odwiedziģ Alaina Colmerauera, szef Groupe d'Intelligence Arti cielle (GIA), Centre National de la Recherche Scienti que i Universit e II Aix-Marseille w Marsylii . Kowalski napisaģ: "Podczas drugiej wizyty narodziģo się programowanie logiki, jak to powszechnie rozumiemy." Colmerauer i jego doktorant Philippe Roussel opracowali w 1972 r. nowy język programowania PROLOG . (Roussel wybraģ nazwę jako skrót dla "PROgrammation en LOGique ") .W PROLOG, programy skģadają się z uporządkowanej sekwencji instrukcji logicznych. Dokģadna kolejnoķæ, w jakiej te instrukcje są pisane, wraz z niektórymi innymi konstrukcjami, jest kluczem do skutecznego wykonywania programu. PROLOG wykorzystuje kolejnoķæ na podstawie kolejnoķci potrąceņ w rozdzielczoķci SL. Kowalski, Colmerauer i Roussel wszyscy podzielili się kredytem dla PROLOG, ale Kowalski przyznaje "… prawdopodobnie sģusznie jest powiedzieæ, ŋe mój wģasny wkģad byģ gģównie filozoficzny, a Alaina bardziej praktyczny". Język PROLOG stopniowo zyskiwaģ na znaczeniu dla rywalizującego z LISP, chociaŋ jest uŋywany gģównie przez ludzi AI spoza Stanów Zjednoczonych. Niektórzy amerykaņscy badacze, szczególnie ci z MIT argumentowali przeciwko PROLOG (i innym systemom dedukcyjnym opartym na rozdzielczoķci), twierdząc (z pewnym uzasadnieniem), ŋe obliczenia oparte na dedukcji nie byģy wydajne. Opowiadali się za obliczeniami kontrolowanymi przez osadzenie wiedzy o rozwiązanym problemie i jak najlepiej rozwiązaæ bezpoķrednio w programach ograniczających wyszukiwanie. To "proceduralne osadzanie wiedzy" byģo cechą języków PLANNER opracowanych przez Carla Hewitta i wspóģpracowników z MIT (Hewitt ukuģ zdanie "procesowe osadzanie wiedzy" w artykule z 1971 r.).
Sieci semantyczne
Sieci semantyczne byģy (i nadal są) innym waŋnym formatem reprezentujący wiedzę deklaratywną. Wspomniaģem juŋ o ich wykorzystaniu przez Rossa Quilliana jako modelu ludzkiej pamięci dģugotrwaģej. W latach 70. psycholog poznawczy Stanford Gordon Bower i jego uczeņ John Anderson przedstawili opartą na sieci teorię ludzkiej pamięci w ksiąŋce "Human Associative Memory". Zgodnie ze szkicem biograficznym Andersona ksiąŋka "natychmiast przyciągnęģa uwagę wszystkich, którzy wówczas pracowali w polu. Ksiąŋka odegraģa waŋną rolę w ustanowieniu zdaņ semantycznych jako podstawy reprezentacji w pamięci i rozpowszechnianie aktywacji poprzez ģącza w takich sieciach jako podstawa do wyszukiwania informacji z pamięci". Teorię częķciowo zaimplementowano w symulacji komputerowej o nazwie HAM (akronim od Human Associative Memory). HAM mógģ analizowaæ proste zdania zdaņ i przechowywaæ je w semantyczna struktura sieci w swojej nagromadzonej pamięci HAM mógģ odpowiedzieæ na proste pytania. Pod koniec lat 60. i na początku 70. zbadano kilka innych reprezentacji sieciowych. Robert F. Simmons, po przeprowadzce z SDC na University of Texas w Austin, zacząģ wykorzystywaæ sieci semantyczne jako obliczeniową lingwistyczną teorię struktur i operacji przetwarzania wymaganych do komputerowego zrozumienia języka naturalnego. Napisaģ: "Sieci semantyczne są prostymi -nawet eleganckimi - strukturami reprezentującymi aspekty znaczenia angielskich ciągów znaków w wygodnej formie obliczeniowej, która obsģuguje przydatne operacje przetwarzania języka na komputerach". W 1971 r. Stuart C. Shapiro, następnie z University of Wisconsin w Madison, wprowadziģ strukturę sieci o nazwie MENS (MEmory Net Structure) do przechowywania informacji semantycznych. System pomocniczy o nazwie MENTAL (MEmory Net That Answers and Learns) wspóģdziaģaģ z uŋytkownikiem i MEMS. MENTAL pomógģ MEMS w wydedukowaniu nowych informacji z juŋ zapisanych. Shapiro przewidziaģ, ŋe MENTAL będzie w stanie odpowiedzieæ na pytania uŋytkowników przy uŋyciu informacji przechowywanych w MEMS. Shapiro póžniej przeniósģ się do State University of New York w Buffalo, gdzie wraz z kolegami kontynuuje rozwój serii systemów zwanych SNePS (Semantic NEtwork Processing System). SNePS ģączy cechy reprezentacji logicznych z reprezentacjami sieciowymi i jest wykorzystywany do rozumienia i generowania języka aturalnego oraz innych aplikacji. W swoim doktoracie Roger C. Schank rozpocząģ badania nad językoznawstwem na uniwersytecie w Teksasie w Austin, które nazwaģ "pojęciowymi reprezentacjami zaleŋnoķci dla zdaņ w języku naturalnym". Następnie, jako profesor w Stanford i Yale, on i koledzy kontynuowali rozwijanie tych pomysģów. Podstawą pracy Schanka byģo jego przekonanie, ŋe ludzie przeksztaģcają zdania w języku naturalnym na "struktury pojęciowe", które są niezaleŋne od konkretnego języka, w którym zdania zostaģy pierwotnie wyraŋone. Twierdziģ, ŋe te struktury pojęciowe są sposobem rozumienia informacji w zdaniach i na przykģad, kiedy tģumaczy się zdanie z jednego języka na inny, najpierw reprezentuje jego treķæ informacyjną jako strukturę pojęciową, a następnie wykorzystuje tę strukturę do uzasadnienia tego, co zostaģo powiedziane, lub do odtworzenia informacji jako zdania w innym języku Kiedy umieķciģ to w jednym ze swoich dokumentów, "…wszelkie dwie wypowiedzi, które moŋna powiedzieæ, ŋe oznaczają to samo, niezaleŋnie od tego, czy są w tym samym czy w róŋnych językach, powinny byæ scharakteryzowane tylko w jeden sposób przez struktury pojęciowe". Notację Schank wykorzystano dla jego struktur pojęciowych (czasami nazywaną" zaleŋnoķcią pojęciową " wykresy ") ewoluowaģy nieco w latach 70. Na przykģad rysunek, zaczerpnięty z jednego z jego artykuģów, pokazuje, jak reprezentowaģby zdanie" John rzuciģ oģówkiem Samowi.
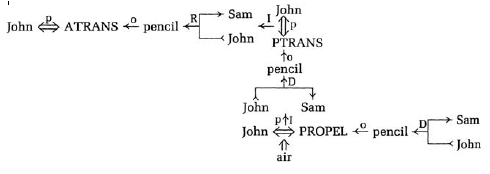
Struktura ta wykorzystuje trzy z "prymitywnych dziaģaņ jakie Schank zdefiniowaģ jako te reprezentacje: ATRANS, co oznacza przeniesienie wģasnoķci; PTRANS, co oznacza przeniesienie fizycznej lokalizacji, oraz PROPEL, co oznacza zastosowanie siģy do obiektu. Schank zdefiniowaģ kilka innych prymitywnych dziaģaņ które reprezentują ruch, opiekę, mówienie, przekazywanie pomysģów i tak dalej. Rozszerzone dosģowne odczytanie tego, co reprezentuje ta struktura, brzmiaģoby: "John przyģoŋyģ siģę fizyczną do oģówka, co spowodowaģo, ŋe przeleciaģ on w powietrzu z miejsca Johna do miejsca Sama, co spowodowaģo, ŋe Sam go posiadaģ" lub coķ w tym rodzaju. Schank, podobnie jak wielu innych zainteresowanych językami reprezentacyjnymi, zauwaŋa, ŋe reprezentacje te moŋna wykorzystaæ bezpoķrednio do dokonywania dedukcji i odpowiadania na pytania. Na przykģad odpowiedzi na pytania typu "Jak Sam zdobyģ oģówek?" I " Kto byģ wģaķcicielem oģówka po tym, jak John go rzuciģ? " są ģatwe do wydobycia. Chociaŋ struktury sieci są zilustrowane graficznie w artykuģach na ich temat, zostaģy one zakodowane przy uŋyciu LISP do przetwarzania komputerowego.
Skrypty i ramki
Graficzne reprezentacje wiedzy, takie jak sieci semantyczne i struktury koncepcyjne, ģączą powiązane ze sobą byty w grupy. Takie grupowanie jest wydajne obliczeniowo, poniewaŋ powiązane rzeczy często uczestniczą w tym samym ģaņcuchu rozumowania. Uzyskując dostęp do jednego z takich podmiotów, moŋna równieŋ ģatwo uzyskaæ dostęp do tych pobliskich. Roger Schank i Robert Abelson rozwineli ten pomysģ, wprowadzając pojęcie "skryptów". Skrypt jest sposobem reprezentowania tego, co nazywają "wiedzą specjalistyczną", to znaczy szczegóģową wiedzą o sytuacji lub zdarzeniu, przez które przeszliķmy wiele razy. Kontrastują one wiedzę szczegóģową z "wiedzą ogólną", z której ta ostatnia jest obszerną wiedzą podstawową lub zdrową, przydatną w wielu sytuacjach. Ich "restauracyjny" skrypt ("wersja Coffee Shop") staģ się ich najbardziej znanym ilustracyjnym przykģadem. Skrypt skģada się z czterech "scen", a mianowicie: wchodzenia, zamawiania, jedzenia i wychodzenia. Jego "Rekwizyty" to: Tabele, Menu, F-Food, Czek i Pieniądze. Jego "Role" to S-Klient, W-Kelner, C-Cook, M-Kasjer i O-Wģaķciciel. Jego "Warunki wejķcia" to S jest gģodny, a S ma pieniądze. Jego "Wyniki" są takie, ŋe S ma mniej pieniędzy, O ma więcej pieniędzy, S nie jest gģodny, a S jest zadowolony (opcjonalnie). Poniŋej pokazan ich scenariusz dla sceny "Zamawianie".
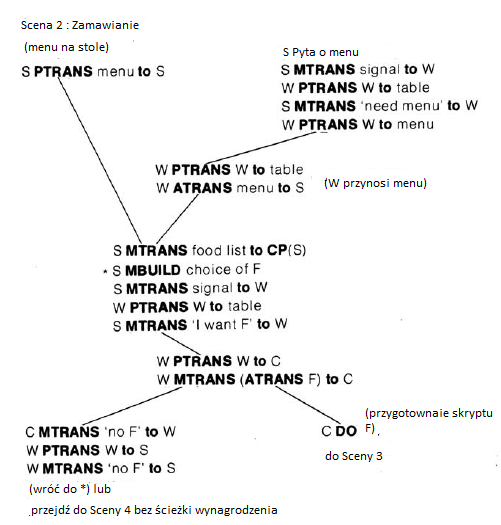
Oprócz akcji PTRANS (przeniesienie lokalizacji) i ATRANS (przeniesienie posiadania), ten skrypt uŋywa jeszcze dwóch swoich prymitywnych dziaģaņ, mianowicie MTRANS (przekaz informacji) i MBUILD (tworzenie lub ģączenie myķli). CP (S) oznacza "procesor koncepcyjny" S, w którym zachodzi myķl, a DO oznacza "dziaģanie pozorowane" okreķlone przez następujące. Linie na diagramie pokazują moŋliwe alternatywne ķcieŋki skryptu. Na przykģad, jeķli menu jest juŋ na stole, skrypt zaczyna się w lewym górnym rogu; w przeciwnym razie zaczyna się w prawym górnym rogu. Wierzę, ŋe większoķæ scenariusza nie wymaga wyjaķnieņ, ale pomogę, wyjaķniając, co dzieje się w ķrodku. S przenosi "listę ŋywnoķci" do swojego centralnego procesora, gdzie jest w stanie mentalnie zdecydowaæ (zbudowaæ) wybór ŋywnoķci. S przekazuje następnie informacje do kelnera, aby podszedģ do stoģu, co robi kelner. Następnie S przekazuje informacje o swoim wyborze jedzenia kelnerowi. Trwa to do momentu, aŋ kucharz powie kelnerowi, ŋe nie ma zamówionego jedzenia lub kucharz przygotuje jedzenie. Trzy pozostaģe sceny w scenariuszu restauracji są podobnie zilustrowane w ksiąŋce Schank i Abelsona. Moŋliwych jest kilka innych wariantów skryptu restauracji (dla róŋnych rodzajów restauracji itp.). Skrypty pomagają wyjaķniæ niektóre z powodów, które robimy automatycznie po usģyszeniu historii. Na przykģad, jeķli usģyszymy, ŋe John poszedģ do kawiarni i zamówiģ lasagne, moŋemy rozsądnie zaģoŋyæ, ŋe lasagne byģa w menu. Jeķli póžniej dowiemy się, ŋe John musiaģ zamiast tego zamówiæ coķ innego, moŋemy zaģoŋyæ, ŋe w kawiarni nie byģo lasagne. Schank i Abelson przedstawiają anegdotyczne dowody, ŋe nawet maģe dzieci tworzą takie skrypty i ŋe ludzie muszą mieæ ich duŋą liczbę, aby umoŋliwiæ im nawigację i uzasadnienie napotkanych sytuacji. Schank rozwinąģ póžniej skrypty i pokrewne pomysģy w innej ksiąŋce, w której przedstawiģ ideę "pakietów organizacji pamięci "(MOPS), które opisują sytuacje w bardziej rozproszony i dynamiczny sposób niŋ skrypty. Póžniej "ponownie zapoznaģ się" z niektórymi z tych pomysģów w ksiąŋce na temat ich zastosowania w edukacji, dziedzinie, do której wniósģ znaczący wkģad. Schank i jego twierdzenia wywoģaģy wiele kontrowersji wķród badaczy AI. Cytowany filozof Daniel Dennett z Tufts University powiedziaģ: "Zawsze podobaģa mi się rola Schanka jako osoby zģoķliwej i jako pesymisty, partyzanta w dziedzinie kognitywistyki, zawsze zadającego duŋe pytania, zawsze gotowego odrzuciæ wģasne wczeķniejsze wysiģki i powiedzieæ byģy radykalnie niekompletne z interesujących powodów. Jest zģoķlwiy i dobrym". Myķlę, ŋe jego podstawowe wyobraŋenie o skryptach byģo prorocze. Wyprodukowaģ teŋ ķwietną grupę studentów. Strona internetowa "AI Genealogy" wymienia prawie czterech tuzinów studentów Schank, z których wielu przeszģo do wybitnych karier. Mniej więcej w czasie pracy Schanka Marvin Minsky zaproponowaģ, aby wiedza o sytuacjach byģa reprezentowana w strukturach, które nazwaģ "ramkami". Wspomniaģ o pomysģach Schanka (między innymi) jako przykģad odejķcia od "próby reprezentowania wiedzy jako zbioru oddzielnych, prostych fragmentów", takich jak zdania w języku logicznym. Jak je zdefiniowaģ. Ramka to struktura danych reprezentująca stereotypową sytuację, np. Przebywanie w jakimķ salonie lub pójķcie na przyjęcie urodzinowe dziecka. Do kaŋdej ramki doģączonych jest kilka rodzajów informacji. Niektóre z tych informacji dotyczą korzystania z ramki. Niektóre dotyczą tego, czego moŋna się spodziewaæ. Niektórzy zastanawiają się, co zrobiæ, jeķli te oczekiwania nie zostaną potwierdzone. Kolekcje powiązanych ramek są poģączone ze sobą w systemy ramek. Efekty waŋnych dziaģaņ odzwierciedlają transformacje między ramkami systemu. Są one uŋywane, aby się upewniæ jakie rodzaje obliczeņ ekonomicznych, aby przedstawiæ zmiany nacisku i uwagi oraz w celu uwzględnienia skutecznoķci "zdjęæ. "
W artykule Minsky'′ego opisano, w jaki sposób moŋna zastosowaæ systemy ramek do wizji i obrazów, rozumienia językowego i innych rodzajów rozumienia, akwizycji pamięci, odzyskiwania wiedzy i kontroli. Chociaŋ jego praca byģa bogata w pomysģy, Minsky nie wdroŋyģ ŋadnych systemów ramowych. Kilka lat póžniej niektórzy jego studenci i byli studenci wdroŋyli niektóre podobne systemy. Jeden, nazwany FRL (dla Frame Representation Language), zostaģ opracowany przez R. Bruce′a Robertsa i Irę P. Goldsteina. Daniel Bobrow i Terry Winograd (ten ostatni jest jednym ze studentów Paperta), wdroŋyli bardziej ambitny system o nazwie KRL (for Knowledge Representation Language). Systemy ramowe byģy zgodne ze stylem rozumowania, w którym moŋna zakģadaæ szczegóģy "niespecjalnie uzasadnione", a tym samym ominąæ "logikę", jak by to zrobiģ Minsky. Ten styl byģ juŋ wczeķniej uŋywany w systemie SIR Raphaela, a badacze opowiadający się za uŋyciem języków logicznych do reprezentacji wiedzy póžniej rozszerzyliby logikę na róŋne sposoby, aby dostosowaæ się równieŋ do tego stylu. Mimo to ostatnia sekcja (zatytuģowana "Krytyka podejķcia logistycznego") w pracy Minsky'ego na temat ram daje wiele powodów, dla których moŋna wątpiæ (wraz z Minskim) "w moŋliwoķæ skutecznego reprezentowania zwykģej wiedzy w formie wielu maģych, niezaleŋnych" prawdziwe "propozycje".