Postęp w widzeniu komputerowym
Od okoģo 1970 r. Badania nad widzeniem komputerowym staģy się wysoce rozwiniętą specjalnoķcią sztucznej inteligencji, ģącząc inne wyspecjalizowane obszary, takie jak przetwarzanie języka naturalnego, robotyka, reprezentacja wiedzy i rozumowanie (by wymieniæ tylko kilka z nich). Opiszę niektóre waŋne postępy w dziedzinie widzenia komputerowego w tym okresie. Niektóre z nich zostaģy opracowane z myķlą o okreķlonych zastosowaniach w kilku dziedzinach, takich jak rozpoznanie lotnicze, kartografia, robotyka, medycyna, analiza dokumentów i nadzór.
Wyszukiwanie poza linią
Wczeķniej opisaģem niektóre techniki filtrowania w celu poprawy jakoķci obrazu oraz wyodrębnienia krawędzi i linii w obrazach. Ale moŋna zrobiæ znacznie więcej, aby wyodrębniæ wģaķciwoķci sceny przy uŋyciu konkretnych informacji o warunkach, w jakich obrazy są uzyskiwane, oraz ogólnych informacji o wģaķciwoķciach obiektów, które mogą znajdowaæ się na scenie.
Ksztaģt z cieniowania
W tak zwanym ruchu "powrót do podstaw" badacze zaczęli badaæ, w jaki sposób moŋna wykorzystaæ informacje o fizyce i geometrii odbicia ķwiatģa od powierzchni do ujawnienia trójwymiarowych wģaķciwoķci sceny z pojedynczego dwuwymiarowego obrazu. Liderem tego badania byģ Berthold K. P. Horn . Jego doktorancka rozprawa opracowaģa matematyczne metody okreķlania ksztaģtu obiektu na podstawie jego cieniowania. Tak jak ludzie postrzegają odpowiednio zacieniowany obraz koģa jako kulę, tak moŋna stworzyæ komputerowy system wizyjny.Korzystając z informacji o wģaķciwoķciach odblaskowych powierzchni i geometrii procesu obrazowania, zrobiģ to Horn. Podstawową ideę techniki Horna moŋna wytģumaczyæ, odwoģując się do rysunku na którym w najmniejszym kawaģku powierzchni ķwiatģo jest oķwietlane žródģem ķwiatģa pod kątem równym i względem kierunku, który wskazuje prostopadle od powierzchni.
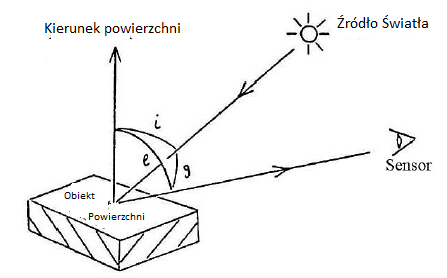
Zaģóŋmy, ŋe czujnik ķwiatģa (taki jak kamera telewizyjna), pod kątem g względem kierunku žródģa ķwiatģa i pod kątem e względem kierunku powierzchni, zbiera ķwiatģo odbite od powierzchni. Iloķæ ķwiatģa zebranego z tej ģatki powierzchniowej zaleŋy od tych trzech kątów, iloķci oķwietlenia i wspóģczynnika odbicia wģaķciwoķci powierzchni. (Horn przyjąģ coķ, co nazwalibyķmy "matową" powierzchnią). Poniewaŋ iloķæ zebranego ķwiatģa zmienia się w ten sposób, obraz wydaje się "zacieniony". W pewnych okolicznoķciach i przy pewnej manipulacji matematycznej kierunek powierzchni moŋna obliczyæ, jeķli znane są inne wielkoķci. Następnie, znając kierunek dla wielu, wielu maģych powierzchni, moŋna obliczyæ ogólny ksztaģt powierzchni (przy zaģoŋeniu, ŋe powierzchnia jest względnie gģadka bez nagģe nieciągģoķci). Horn jest obecnie profesorem informatyki i elektrotechniki w MIT i nadal pracuje nad kilkoma tematami związanymi z wizją komputerową. Jego praca dyplomowa wywoģaģa lawinę aktywnoķci w obszarze ksztaģtu z cieniowania. "Kilka osób rozszerzyģo pomysģ ksztaģtu z cieniowania na próbę obliczenia ksztaģtu na podstawie rzeczy innych niŋ cieniowanie, na przykģad z wielu obrazów (stereo), ruchu, tekstury i kontur. I, jak zobaczymy na następnych kilku stronach, wykonano waŋną pracę przy wydobywaniu czegoķ więcej niŋ tylko ksztaģtu obiektów.
Szkic 21/2-D
Mimo ŋe widz widzi tylko dwuwymiarowy obraz trójwymiarowej sceny, David Marr zauwaŋyģ, ŋe mimo to widz jest w stanie wywnioskowaæ (a tym samym postrzegaæ) na podstawie cieniowania obrazu i innych gģębokoķci trójwymiarowe atrybuty sceny, takie jak ksztaģty powierzchni, ksztaģty zamykające inne ksztaģty, nagģe zmiany między gģadkimi powierzchniami i inne informacje o gģębokoķci. Marr nazwaģ przedstawienie tych atrybutów "szkicem 2 1/2-D" (poniewaŋ nie byģ w peģni trójwymiarowy). Zgodnie z teorią widzenia Marra (opisaną w jego ksiąŋce), następnym krokiem przetwarzania wizualnego, po stworzeniu pierwotnego szkicu plam i krawędzi, jest wykonanie tego szkicu 2 1/2-D. Przykģadowy szkic pokazano na rysunku na którym strzaģki skierowane prostopadle od powierzchni są nakģadane na pierwotny szkic obrazu, z którego są wywnioskowane.
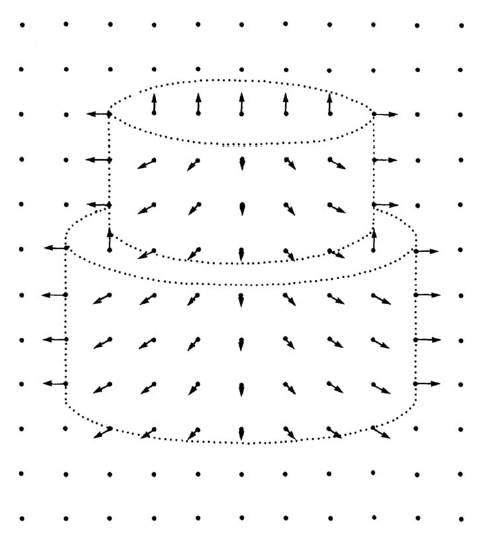
Wreszcie, wedģug Marra, informacje ze szkicu 2 1/2-D, wraz z przechowywanymi informacjami o ksztaģtach obiektów, zostaną wykorzystane do zlokalizowania okreķlonych obiektów na obrazie, a tym samym do stworzenia trójwymiarowego modelu sceny. Niedģugo opiszę, co miaģ do powiedzenia na temat tego procesu.
Obrazy wewnętrzne
Dwóch naukowców z SRI, Jay Martin Tenenbaum i Harry Barrow (niedawno przeprowadzony z Edynburga), opracowali niektóre techniki przetwarzania obrazu caģkiem podobne do tych, które zastosowano przy tworzeniu szkicu 2 1/2-D. Zauwaŋyli, ŋe wartoķæ intensywnoķci na kaŋdym pikselu obrazu wynikaģa z splątanej kombinacji kilku czynników, w tym wģaķciwoķci oķwietlenia otoczenia oraz wģaķciwoķci odblaskowych i geometrycznych obiektów na scenie. Uwaŋali, ŋe czynniki te moŋna rozplątaæ, aby odzyskaæ waŋne trójwymiarowe informacje o scenie. Barrow i Tenenbaum zaproponowali, aby kaŋdy z tych czynników (z których wszystkie w intensywnoķci zaleŋnej) byģ reprezentowany przez wyimaginowane obrazy, które nazywali "obrazami wewnętrznymi". Obrazy te miaģy skģadaæ się z siatki "pikseli" nakģadających się na rzut sceny i zarejestrowanych na obrazie o intensywnoķci. Jednym z wewnętrznych obrazów byģ na przykģad obraz iluminacyjny. Skģadaģ się z pikseli, których wartoķci stanowiģy iluminacje padające na piksele wyķwietlanej sceny. Wartoķci te oczywiķcie nie byģy znane, ale Barrow i Tenenbaum zaproponowali, ŋe moŋna je oszacowaæ na podstawie obrazu intensywnoķci i na podstawie innych wewnętrznych obrazów. Jako przykģady pokazuję zestaw takich wewnętrznych obrazów poniŋej
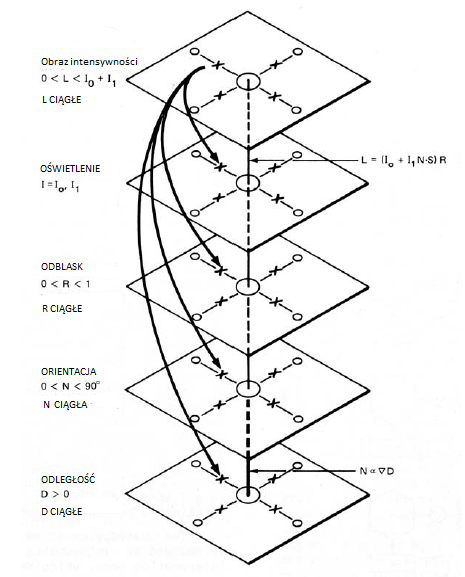
Rzeczywisty obraz wartoķci intensywnoķci pokazano na górze. Znana wartoķæ piksela na tym obrazie zaleŋy od nieznanych wartoķci pikseli na wewnętrznych obrazach poniŋej. W rzeczywistoķci wartoķci pikseli na wszystkich obrazach, wewnętrzne i rzeczywiste, są od siebie zaleŋne. Strzaģki w górę odzwierciedlają ten fakt. (Powinny równieŋ pojawiæ się strzaģki w górę.) W oparciu o wartoķci pikseli na niektórych obrazach, wartoķci innych moŋna obliczyæ przy uŋyciu znanych zaleŋnoķci fizycznych, ograniczeņ między obrazami i innych rozsądnych zaģoŋeņ. Te wartoķci z kolei pozwalają na obliczenia innych. Dlatego te obliczenia "propagują" wartoķci pikseli w caģym zestawie obrazów wewnętrznych (podobnie jak wpģyw poziomów w architekturze tablicy na inne poziomy). Jak póžniej Barrow i Tenenbaum podsumowali swoją metodę: "Przewidywaliķmy ten proces odzyskiwania jako zestaw oddziaģujących równolegģych obliczeņ lokalnych, bardziej jak rozwiązanie ukģadu równaņ równoczesnych przez relaksację niŋ jak sekwencję etapów przekazywania danych". Barrow i Tenenbaum wykorzystali równieŋ niektóre ze swoich pomysģów na temat obrazów wewnętrznych, aby rozwiązaæ problem interpretacji rysunków linii jako powierzchni trójwymiarowych. Barrow i Tenenbaum zamierzali, aby ich praca byģa przydatna nie tylko w widzeniu komputerowym, ale takŋe jako potencjalny model procesów "przedogniskowego" widzenia u ludzi. Jednak w "retrospektywie" z 1993 r. Na temat ich pracy, którą napisali. Pomimo dojrzaģoķci wizji obliczeniowej i szybkiego rozwoju systemów neuronowych, przed nami jeszcze wiele do zrobienia, aby zbliŋyæ się do celu, jakim jest zrozumienie percepcji wzrokowej. Aby to zrobiæ, będziemy musieli skorzystaæ z tego, czego nauczyliķmy się w wielu dziedzinach, w tym neuronauki, sieci neuronowych, psychologii eksperymentalnej i wizji obliczeniowej.
Znajdowanie obiektów w scenach
Rozumowanie scen
Jeszcze przed opracowaniem metod ksztaģtowania z cieniowania i innych metod odzyskiwania informacji o gģębokoķci ze scen wielu badaczy pracowaģo nad metodami wyszukiwania obiektów w scenach. Na początku lat 70. Thomas Garvey ukoņczyģ doktorat Stanforda, jego praca byģa na temat systemu lokalizacji obiektów, takich jak biurka, krzesģa i kosze na ķmieci, na zdjęciach scen biurowych. Jak napisaģ Garvey w swoim streszczeniu:
"System wykorzystuje informacje o wyglądzie obiektów, o ich wzajemnych powiązaniach oraz o dostępnych czujnikach do stworzyæ plan lokalizacji okreķlonych obiektów na zdjęciach scen pokoju"
W powiązanych pracach Barrow i Tenenbaum opracowali system o nazwie MSYS, sģuŋący do wnioskowania o scenach "w których žródģa wiedzy konkurują ze sobą i wspóģpracują, dopóki spójne wyjaķnienie tej sceny nie pojawi się w drodze konsensusu". MSYS przeanalizowaģ obrazy scen biurowych i podjąģ próbę znalezienia najbardziej prawdopodobnej interpretacji regionów na obrazie (blat biurka, oparcie krzesģa, podģoga, drzwi itd.), Biorąc pod uwagę szereg interpretacji kandydatów i ich prawdopodobieņstwa. Znając relacje między regionami (takie jak oparcia krzeseģ zwykle sąsiadują z siedzeniami krzeseģ), MSYS próbowaģ znaležæ najbardziej prawdopodobny ogólny zestaw interpretacji regionów. Niektóre regiony w scenie zostaģy wykryte i oznaczone moŋliwymi interpretacjami. Jak napisali Barrow i Tenenbaum, rozumowanie MSYS moŋe przebiegaæ następująco:
Regiony PIC, WBSKT i CBACK nie mogą mieæ WALL albo DOOR,
poniewaŋ ich jasnoķæ jest znacznie mniejsza niŋ u góry
krawędž obrazu pionowo nad nimi, co narusza [wiedzę
o jasnoķci ķcian i drzwi]. W związku z tym region PIC
musi byæ PICTURE, WBSKTT musi byæ WASTEBASKET, i
CBACK musi byæ CHAIRBACK. Region LWALL i RWALL muszą byæ WALL, poniewaŋ sąsiadują z regionem PIC, a DRZWI nie mogą przylegaæ do OBRAZU. Region DR nie moŋe byæ WALL, poniewaŋ wszystkie regiony oznaczone WALL muszą mieæ tę samą jasnoķæ. Dlatego regionem DR musi byæ DOOR.
Korzystanie z szablonów i modeli
Wiele wczesnych prac nad rozpoznawaniem obiektów opieraģo się na uŋyciu "szablonów" obiektów, które moŋna dopasowaæ do obrazów. Martin A. Fischler i Robert A. Elschlager opracowali ten pomysģ, wykorzystując "rozciągliwe szablony", które pozwoliģy na bardziej zaawansowane techniki dopasowywania. Uŋyli ich do znalezienia obiektów takich jak twarze lub szczególne cechy terenu na fotografiach zawierających takie obiekty. Proces zaleŋaģ od ogólnej prezentacji poszukiwanego obiektu, a następnie proces dopasowania tej reprezentacji do fotografii. Ich reprezentacje polegaģy na rozbiciu obiektu na kilka prymitywnych częķci i okreķleniu dopuszczalnego zakresu relacji przestrzennych, które te "prymitywne częķci" muszą speģniæ, aby obiekt byģ obecny. Aby obiekt byģ obecny na zdjęciu, "wymagane jest, aby prymitywy wystąpiģy (lub przynajmniej wystąpiģ jakiķ znaczny ich podzbiór), a takŋe aby występowaģy w ramach okreķlonej relacji przestrzennej …" .Jak zauwaŋyli Fischler i Elschlager, zwykle zdarza się, ŋe ustalenie, czy niektóre częķci występują, zaleŋy od tego, czy caģy obiekt występuje, i odwrotnie. Gģównym wkģadem ich pracy byģo opracowanie dynamicznej programistyczna metoda radzenia sobie z tą cyrkulacją.
Wczeķniej opisaģem pracę Davida Marra nad procesami tworzenia pierwotnego szkicu i szkicu 2 1/2-D. Byģy to pierwsze dwa etapy teorii widzenia Marra. Twierdziģ, ŋe etapy te mogą odkryæ waŋne informacje o ksztaģcie bez szczególnej wiedzy o ksztaģtach obiektów, które mogą znajdowaæ się na scenie. Napisaģ:
"Większoķæ wczesnych procesów wizualnych bezpoķrednio wyodrębnia informacje o widocznych powierzchniach, nie zwracając szczególnej uwagi na to, czy są one częķcią konia, czģowieka czy drzewa. . . . Jeķli chodzi o pytanie, jaką dodatkową wiedzę naleŋy zastosowaæ, wiedza ogólna musi byæ wystarczająca {wiedza ogólna osadzona we wczesnych procesach wizualnych jako ogólne ograniczenia, wraz z geometrycznymi konsekwencjami faktu, ŋe powierzchnie wspóģistnieją w trójwymiarowym przestrzeņ."
Twierdziģ, ŋe szczególna wiedza na temat ksztaģtów powinna byæ wykorzystana w trzecim etapie. Na tym etapie wykorzystuje się trójwymiarowe modele obiektów. Zaproponowaģ zastosowanie hierarchii modeli, w których model brutto jest rozkģadany na podsekcje, a te na podelementy i tak dalej. Na przykģad ksztaģt czģowieka moŋna wymodelowaæ jak poniŋej
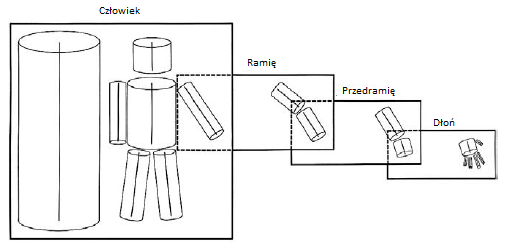
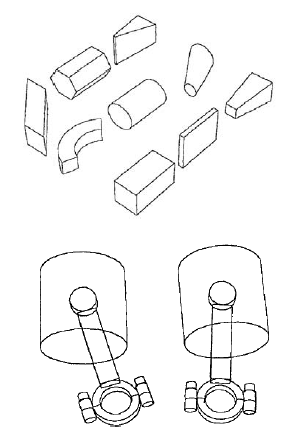
Kaŋde pudeģko odpowiada modelowi 3D i jego podmodelowi. Po lewej stronie pudeģka znajduje się model zorientowany na oķ; po prawej stronie pokazano, jak ten model jest przedstawiany jako podmodele. (Kierunki osi moŋna dopasowaæ do t pasujących częķci obrazu.) W tym trzecim etapie porównanie modeli tego rodzaju z informacjami o ksztaģcie i innymi informacjami trójwymiarowymi zawartymi w szkicu 2 1/2-D pomaga zidentyfikowaæ i zlokalizowaæ obiekty w scenie. Dla Marra wizja byģa "procesem odkrywania z obrazów tego, co jest obecne na ķwiecie i gdzie ono jest". Marr nie byģ pierwszym, który zaproponowaģ uŋycie walców jako modeli częķci obiektów. W dokumencie konferencyjnym IEEE z 1971 r. Thomas O. Binford przedstawiģ ideę "uogólnionych cylindrów" (czasami nazywanych "uogólnionymi stoŋkami"). W póžniejszym artykule zdefiniowano je w następujący sposób: "Uogólniony stoŋek jest okreķlony przez pģaski przekrój, kręgosģup krzywej przestrzennej i zasadę zamiatania. Reprezentuje objętoķæ zmiecioną przez przekrój [niekoniecznie okrągģy] jak jest tģumaczony wzdģuŋ [osi zwanej kręgosģupem], utrzymywany pod pewnym staģym kątem do kręgosģupa i przeksztaģcany zgodnie z zasadą zamiatania. " Binford miaģ kilka doktorów Stanforda, którzy uŋywali modeli, aby pomóc w identyfikacji obiektów w scenach. Spoķród nich mógģbym wymieniæ Geralda J. Agina, Ramakanta Nevatię i Rodneya A. Brooksa, z których wszyscy przyczynili się do tak zwanego widzenia, opartego na modelu rodzaju obiektów. ACRONYM zastosowaģ te modele, aby pomóc w identyfikacji i lokowaniu obiektów na obrazach. Niektóre przykģady rodzajów uogólnionych stoŋków, które moŋna wykorzystaæ jako elementy konstrukcyjne modeli i obiektów modelu, pokazano tu:
Inne poglądy na temat tego, na czym polega wizja, konkurują z tymi Marra i innych, którzy próbowali wykorzystaæ widzenie do rekonstrukcji caģych scen. Niektórzy, szczególnie ci, którzy zajmowali się robotyką, twierdzili, ŋe celem widzenia byģo dostrzeŋenie tego, co jest potrzebne do kierowania dziaģaniem. Wiele procedur widzenia w Shakey zostaģo wbudowanych w jego programy akcji. Profesor Yiannis Aloimonos z University of Maryland jest jednym z badaczy opowiadających się za "celowym" lub "interaktywnym" podejķciem. Twierdzi, ŋe celem widzenia jest dziaģanie. Kiedy widzenie jest "rozpatrywane w poģączeniu z dziaģaniem, staje się ģatwiejsze". Wyjaķnia, ŋe opisy czasoprzestrzeni, których potrzebuje system, nie mają ogólnego przeznaczenia, ale są celowe. Oznacza to, ŋe te opisy są dobre dla ograniczonych zestawów zadaņ, takich jak zadania związane z nawigacją, manipulacją i rozpoznawaniem. "W spoģecznoķci neuronaukowej, do której Marr chciaģ się przyczyniæ, byli Patricia S. Churchland, VS Ramachandran i Terrence J. Sejnowski, który póžniej napisaģ "Po co jest widzemnie? Czy idealna wewnętrzna rekonstrukcja trójwymiarowego ķwiata jest naprawdę konieczna?" Biologiczne i obliczeniowe odpowiedzi na te pytania prowadzą do koncepcji widzenia zupeģnie innej niŋ wizja czysta [zalecana przez Marr]. Interaktywne widzenie… obejmuje widzenie z innymi ukģadami sensorycznymi jako partnerami w pomaganiu w kierowaniu dziaģaniami ". W kaŋdym razie modele nadal odgrywają waŋną rolę w wizji komputerowej. (Jednak jeden wybitny badacz wizji powiedziaģ , ŋe "pozostaģoķæ widzenia opartego na modelu jest bliska zeru", a inny powiedziaģ , ŋe "najbardziej aktualne systemy robotyczne uŋywają hacków wizyjnych "zamiast ogólnych, opartych na nauce metod analizy scen.)
Program zrozumienia obrazu DARPA
Znaczna częķæ prac związanych z widzeniem komputerowym w Stanach Zjednoczonych byģa finansowana przez DARPA, a badacze widzenia mieli (jak zawsze) obawy dotyczące dalszego wsparcia. Tenenbaum przypomina, ŋe uczestniczyģ w spotkaniu DARPA w 1974 r., podczas którego omawiano przyszģoķæ badaņ nad widzeniem komputerowym. Oficer programu monitorujący prace wzrokowe wspierane przez DARPA, major lotnictwa David L. Carlstrom, byģ na spotkaniu i byģ zainteresowany poģączeniem róŋnych wysiģków w tej dziedzinie. Poniewaŋ DARPA od kilku lat wspiera prace w tej dziedzinie, Carlstrom potrzebowaģ nowej nazwy, która wskazywaģaby, ŋe DARPA zaczyna coķ nowego. Tenenbaum powiedziaģ, ŋe on zaleciģ Carlstromowi , aby nową inicjatywę nazwaæ "programem do rozpoznawania obrazów". (Przypomnijmy, ŋe trwaģy juŋ prace nad zrozumieniem mowy wspierane przez DARPA, więc fraza brzmiaģa "przyjazny dla DARPA"). W 1976 roku DARPA uruchomiģa program Image Understanding (IU). Staģo się to duŋym wysiģkiem zģoŋonym z wiodących laboratoriów badawczych wykonujących prace w tym obszarze, a takŋe "zespoģów" ģączących uniwersytet z firmą. Poszczególne laboratoria uczestniczyģy w MIT, Stanford, University of Rochester, SRI i Honeywell. Zespoģami uniwersytetów / przemysģu byģy USC-Hughes Research Laboratories, University of Maryland-Westinghouse, Inc., Purdue University {Honeywell, Inc., i CMU {Control Data Corporation. Odbywaģy się regularne warsztaty w celu przedstawienia postępów. Postępowanie jednego z nich odbyģo się w kwietniu 1977 r. i okreķliģo cele programu: "Program zrozumienia obrazu jest zaplanowany na pięæ lat badaņ w celu opracowania technologii wymaganej do automatycznej i póģautomatycznej interpretacji i analizy zdjęæ wojskowych i powiązanych obrazów" . Ostateczny cel DARPA dla programu IU zostaģ dobrze ujęty w ilustracji na okģadce tego postępowania, pokazanej na rysunku
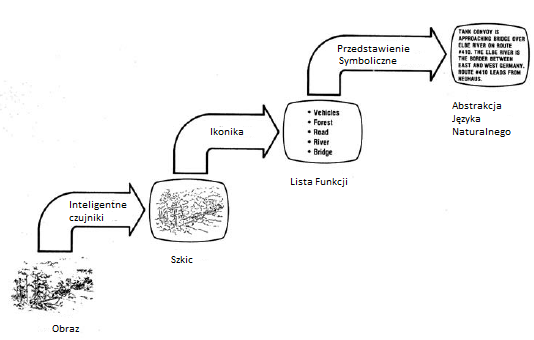
Jak pokazuje schemat, dowódcy wojskowi chcieliby, aby komputerowe systemy wizyjne mogģy analizowaæ fotografię i sporządziæ pisemny opis jej waŋnych elementów i ich relacji. Niektóre z badaņ wizji komputerowej, które juŋ opisaģem, takie jak praca nad szkicem 2 1/2-D, obrazy wewnętrzne, uogólnione cylindry i ACRONYM, byģy wspierane przez program IU. Ale zawsze istniaģo pewne napięcie między celami DARPA a celami osób prowadzących badania nad wizją komputerową. DARPA chciaģ, aby program produkowaģ systemy "polowe". J. C. R. Licklider podkreķliģ ten punkt na wstępnych warsztatach IU w marcu 1975 r .:
Pod koniec pięcioletniego okresu opracowana technologia musi byæ w stanie, w którym elementy DoD mogą ją wykorzystaæ aby rozwiązaæ ich specyficzne problemy, nie wymagając znacznego wysiģku badawczego, aby dowiedzieæ się, jak zastosowaæ technologię do konkretnych problemów. Z tego powodu pod koniec pięcioletniego okresu program musi wykazaæ, ŋe waŋny problem DoD zostaģ rozwiązany.
Major lotnictwa Larry Druffel z DARPA objąģ kierownictwo programu IU w 1978 r. W listopadzie 1978 r. doradziģ: "Ostroŋnym podejķciem jest konsolidacja technik, które są wystarczająco dojrzaģe, aby przenieķæ się do agencji DoD". Do 1979 r. cele programu rozszerzyģy się o kartografię i mapowanie. "Memorandum of zrozumienia" (MOU) między DARPA a Agencją Definiowania Obrony (DMA) zostaģo zawarte w celu wsparcia wysiģków w zakresie automatycznego mapowania poprzez opracowanie DARPA / DMA . W listopadzie 1979 r. Druffel napisaģ :
"Trwają prace nad planem systemu demonstracyjnego w celu oceny dojrzaģoķci technologii IU poprzez automatyzację funkcji mapowania, mapowania i geodezji. Koncentrując się na konkretnej funkcje fotointerpretacji kartografii , system powinien oferowaæ caģoķæ spoģecznoķæ wykorzystująca obrazy moŋliwoķæ oceny przyszģoķci zastosowanie metodologii zrozumienia obrazu do ich specyfiki problemu"
Program "pięcioletni" nie zakoņczyģ się w 1981 r. Kontynuowano go pod kierownictwem dowódcy marynarki wojennej DARPA Rona Ohlandera, puģkownika siģ powietrznych Roberta L. Simpsona Jr. i innych do okoģo 2001 r. W 1985 r. Simpson podsumowaģ niektóre z jego osiągnięæ
"Początkowo pomyķlany jako program pięcioletni w 1975 r. przez ppģk. Davida Carlstroma, pierwsze kilka lat IU stworzyģo silną bazę technik widzenia na niskim poziomie i podsystemów opartych na wiedzy, które zaczęģy odróŋniaæ widzenie komputerowe od tego, co zwykle nazywa się " przetwarzanie obrazu." Na przeģomie lat siedemdziesiątych i osiemdziesiątych XX wieku, pod kierunkiem ppģk. Larry′ego Druffela, program widziaģ rozwój systemów wizyjnych opartych na modelach, takich jak ACRONYM, oraz demonstrację technik IU w bardziej znaczących demonstracjach koncepcyjnych, takich jak obraz DARPA / DMA zrozumienie testbed. Te demonstracje i ich potencjaģ do przyszģego uŋytku wojskowego uzasadniaģy kontynuację programu IU poza początkową pięcioletnią ŋywotnoķæ. Pod Cmd. Ron Ohlander, technologia IU nadal dojrzewaģa do tego stopnia, ŋe program komputerowy DARPA mógģ uzasadniæ duŋe zastosowanie, autonomiczny pojazd lądowy."
Jak powiedziaģ Ohlander, program IU zostaģ przedģuŋony poza przewidywany okres pięciu lat. Mówi się, ŋe juŋ w 1984 r. DARPA wydaģa na ten wysiģek ponad 4 miliony dolarów. Jednym z potencjalnych zastosowaņ byģa wizja komputerowa sterowanych robotami pojazdów wojskowych {element strategii DARPA Computing ". Jako rosnąca specjalnoķæ sztucznej inteligencji, artykuģy o widzeniu komputerowym, zaczęģy pojawiaæ się w nowych czasopismach poķwięconych temu zagadnieniu, w tym Computer Vision and Image Understanding oraz IEEE Transakcje dotyczące analizy wzorców i inteligencji maszyn W tym czasie podręczniki Fielda zawieraģy klasyfikację wzorców i analizę scen oraz dwie ksiąŋki zatytuģowane Computer Vision.